
基于BP神经网络的海量信息存储系统设计
2022-07-19 09:53常洁
信息记录材料 2022年5期
常 洁
(中国水利水电第十一工程局有限公司 河南 郑州 450001)
0 引言
随着互联网技术的飞速发展,社会逐渐进入了信息时代,各行各业每时每刻都在产生海量的信息数据,面对如此庞大的信息数据[1],现有的信息储存管理技术受到了冲击。传统的信息储存系统内部的分散性较高,无法体现拓扑结构的高效性,不满足海量数据的存储需求,因此为了促进社会信息化发展[2],保证海量数据的高效存储调用,需要设计新的海量信息存储系统。
传统的信息存储系统往往是基于数据的集中管理要求设计的,虽然在一定程度上能完成数据的集中管控,但因其整体的国产性较低[3],信息存储时消耗的成本较高,除此之外在海量信息存储时,要求的信息调用速度较高,传统的信息存储系统往往无法实现无损压缩转换,因此不满足目前的海量信息存储需求。BP神经网络是一种特殊的逆向训练神经网络,可以无需确定信息之间的关系,完成期望值操作[4],其在信息处理中具有较高的应用价值,能实现高效信息转换,降低信息储存调用产生的误差,因此,本文基于BP神经网络设计了新的海量信息储存系统,为后续的信息管控提供依据。
1 硬件设计
1.1 CMDS储存器
在海量信息储存时,为了增加信息管理访问的合理性,需要使用CMDS储存器,实现信息的高效管理访问,传统的储存器往往使用类似光纤通道的结构进行储存,由于本文设计的系统面对的数据量较大[5],因此使用了交换式转换I/O矩阵通道对储存结构进行拓展。
CMDS储存器内部使用了InfiniBand交换结构设计了标准化连接模型,通过InfiniBand交换结构可以拓宽模型的链路通道,有效地解决数据堵塞问题[6],提高系统整体的数据处理性能。InfiniBand交换结构与CPU直接相连,在数据发送后[7],InfiniBand交换结构可以立即将其传输到相关的链路通道中,再将交换后的存储数据输入到CPU中。为了实现数据的高效管控,CMDS储存器还添加了SQL Server文件,进一步提高系统的整体储存容量。
1.2 ADμC812控制芯片
在系统海量信息采集时,需要进行集中管控,降低信息采集功耗,因此本文设计的系统添加了ADμC812控制芯片统一对系统的信息采集模块进行调控。ADμC812控制芯片是由AD公司研发的高效信息采集控制芯片[8],该控制芯片的内部增加了多个数据采集通道,因此该芯片即使不连接其他外设设备,也同样能实现高效信息控制采集。
为了增加ADμC812与系统的匹配度,本文设计的系统在该芯片内部添加了A/D转换中心,在A/D转换中心中能实现海量信息多路传输[9],分层采样,最大限度地增加系统的信息处理效率。在海量信息存储过程中,必须注意信息的分类问题,因此ADμC812控制芯片额外增加了自校准特性,将SFR读写中心与芯片内部的bit输出电压结合,即可完成海量信息有效分类。ADμC812控制芯片使用8 051内核,并以256 Byte与内核兼容。除了上述优势外,ADμC812控制芯片设置了12C总线接口,保证芯片的灵活控制功能,能有效降低信息采集功耗。
1.3 RISC处理器
为了保证海量信息储存系统的信息存储调用效率,本文设计的系统使用RISC处理器处理系统内部的指令。RISC处理器含有一种总线,其可以在同一空间有效地处理系统内部的指令[10]。RISC处理器采用单线指令处理法,一条指令处理完毕后再处理下一条指令。RISC处理器的使用成本较高,因此为了降低使用成本,本文设计的系统额外添加了多个微处理单元,与系统时钟结合共同完成海量信息储存系统的指令处理。
2 软件设计
2.1 采集处理海量存储信息数据
根据海量信息存储系统的要求,本文选取Hadoop和Hbase数据库来采集处理海量的存储信息数据。选用Name Node作为管理基础层,验证现存的储存节点,通过验证的节点才可以进入访问通道,读取需要处理的信息[11]。在实际信息采集的过程中,受信息类型的影响,很容易出现信息不兼容的问题,在使用Hadoop采集存储信息时很容易出现元数据膨胀问题,无法保证信息的存储效率,本文设计的系统将Hadoop与Hbase数据库进行整合,增加存储系统的处理弹性,提高系统存储的基础效率。
采集到相关的存储数据后,需要设计存储数据在系统中的存储格式,本文利用Hadoop集群将现有的数据流划分开,并在节点服务器中记录全部元数据信息,确保各个Name Node节点都能有效被响应,在用户查找存储信息时,根据各个节点响应效果对查找文件进行综合定位[12]。为了降低存储信息耗费的内存,本文使用SequenceFile技术进行信息压缩处理,进一步降低海量数据在信息存储系统中占据的空间,实现信息的有效采集处理。
2.2 基于BP神经网络构建海量数据存储控制中心节点
传统的信息存储系统缺乏控制海量信息的中心控制节点,数据存储的难度较高,本文设计的系统结合BP神经网络,使用梯度搜索技术设计了数据储存控制节点的参数计算式,见式(1)。
公式(1)中,D代表数据总量,E代表节点权重,该参数在实际使用过程中需要进行初始化处理,避免计算式存在局部最小值。为了保证系统的集中控制功能,本文设置了加速读取缓存层,该缓存层可以存储一段连续时间内的信息,判定信息的类型,进而将信息输入到各个节点上。
中心节点可以有效地分配系统中的缓存资源,保证节点资源的平均性,因此在构建中心节点时可以代入上文计算的数据储存控制参数,分析系统的数据及调度任务,再选择恰当的节点完成综合分配[13]。中心节点与系统内部的元数据信息有重要关系,也是提高系统性能的关键部分,元数据信息通常被储存在系统的内存中,维护系统的正常运行,因此在中心节点构建的过程中,可以询问信息的缓存时间,进行综合化配置,保证信息储存的高效性。
2.3 设计海量信息存储功能模块
根据中心节点的位置可以规划系统的任务调度步骤,设计海量信息存储的功能模块。研究发现,在信息存储过程中,各个信息的存储速度与信息预存节点的基础状态相关,因此结合海量信息的存储特点,设计了信息存储系统的功能模块。
(1)元数据管理模块。在元数据读取时通常需要使用Timer定时器来不断地读写和修改,因此为了反映各个时间段的数据关系,本文使用Meta Data Manager进行了元数据管理。该管理模块构建了多个索引存放结构,并通过ProvObjInfo完成数据映射,避免消耗过多的数据分配时间[14]。
(2)任务调度模块。在客户端发送请求后,需要根据系统的运行状况进行节点分配,完成各个节点的任务,中心节点可以根据客户端的请求指令将数据进一步解析,结合分配函数计算后传输到客户端中。
(3)客户端缓存模块。缓存模块是信息存储系统的核心模块,可以在LocationEntity中记录需要缓存的信息、分析缓存节点的位置,用户在查询过程中可以调用search Entity Location函数,实现信息的准确定位[15]。
2.4 实现海量信息存储
实现海量信息存储的最后一步就是设计有效的信息调度策略。在调度初期可以设计标准化储存架构,将总储存设备与信息传输通道相连,用户发送请求后文件服务器需要立即进行响应,编写驱动程序,待数据返回后便可结束此次调度。
为了增加海量信息的调度效率,本文设置了两个不同的调度通道,通道1可以接入局域网,向服务器提供储存服务,通道2可以实施设备通信,有效地增加了数据分流处理效率,降低了文件服务器的负荷。
3 系统测试
3.1 测试准备
选取DBPS测试平台进行系统测试,为了保证测试的稳定性,该测试平台使用C++搭建测试架构,并使用标准化g++4.8.2进行调节,在保证系统测试稳定性情况下,本文搭建交换局域网,拓扑结构见图1。
由图1可知,DBPS测试平台内部设置了10台服务器,各个服务器的源码不同,统一通过交换机与局域网相连,服务器CPU频率设为3.1 GHz,内存大小设置为64 G,CPU位数是64 bit,服务器使用SATA 500硬盘,其最大传输效率为1 000 Mbps。交换机传输速率为10/100/1 000 Mbps,内部共包含24个端口,并以全双工模式进行传输。本文搭建系统测试平台内部设置了缓存、储存节点,各个节点的参数配置见表1。

表1 节点参数配置
根据表1节点参数,可选取符合系统测试需求的海量储存信息,在测试过程中,使用creste命令创建不同的测试对象,接下来为选取对象设置添加属性,构建命令关联,提交给系统测试中心,系统按照指令提示完成测试操作,并输出测试结果。
3.2 测试结果与讨论
在上述搭建DBPS测试平台中分别使用本文设计系统完成信息储存操作,记录两个系统的存储耗时,测试结果见表2。
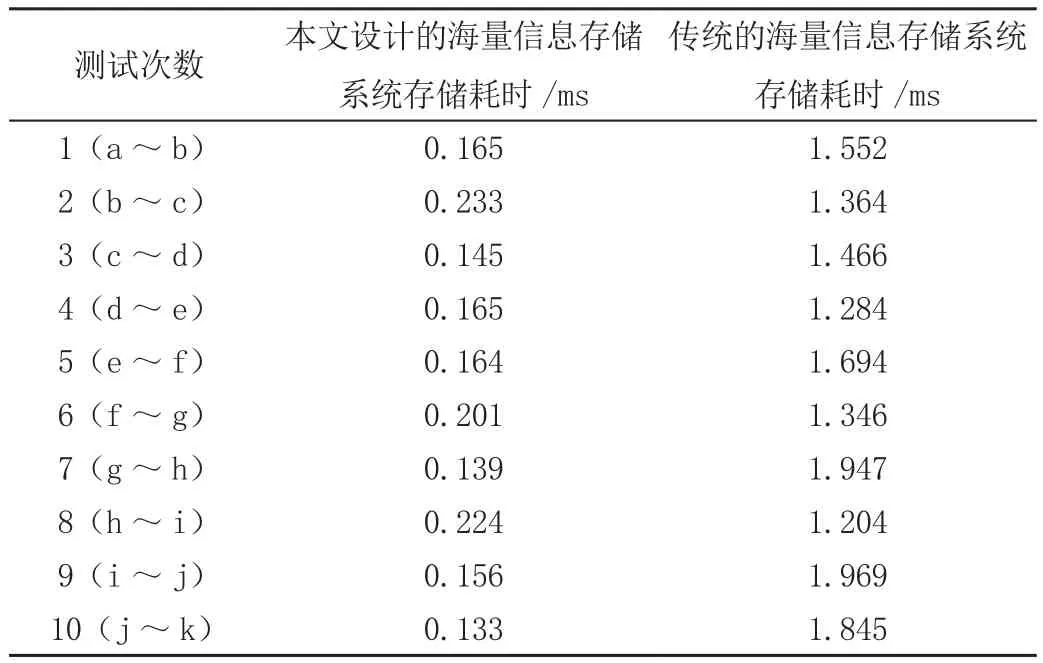
表2 系统测试结果
由表2可知,本文设计存储系统在连续几次信息储存操作中消耗时间均较短,证明设计的海量信息存储系统的性能良好,具有有效性,有一定应用价值。
4 结语
在信息化时代,各个领域的数据信息量都在急剧增长,传统的信息储存系统受集中管理限制已经无法满足目前的信息存储需求,本文基于BP神经网络,设计新的海量信息存储系统,进行系统测试,结果表明,本文存储系统的存储耗时较短,性能良好,有一定的应用价值,可以为后续的信息管控提供参考。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
九江学院学报(自然科学版)(2022年2期)2022-07-02
导航定位学报(2022年2期)2022-04-11
当代陕西(2019年14期)2019-08-26
智能计算机与应用(2019年2期)2019-05-16
发明与创新·大科技(2019年12期)2019-03-17
传播与制作(2018年9期)2018-11-15
劳动保护(2018年8期)2018-09-12
小猕猴学习画刊(2016年12期)2017-01-05
中学数学杂志(初中版)(2016年5期)2016-11-01
