
基于YOLOv5算法的人体跌倒检测系统设计
2022-07-18 13:35:38周洪成徐志国
金陵科技学院学报 2022年2期
周洪成,杨 娟,徐志国
(金陵科技学院电子信息工程学院,江苏 南京 211169)
随着人们生活水平的不断提高,人身安全越来越受到重视,安防系统也愈发受到人们的欢迎。世界卫生组织的一篇报道记载,跌倒造成的死亡率仍居高不下,全球每年有30多万人死于跌倒,其中一半是60岁以上的老人[1]。老年人、幼儿、残疾人等发生跌倒行为,会引发危险。
为了应对这些危险,需要在传统监控安防系统的基础上研制一种新型的监控安防系统,及时检测出跌倒等危险行为,并发出警报预警,提醒用户对受伤人员采取有效的救治措施,从而保证人身安全。根据跌倒信号获取的装置不同,跌倒检测可分为三种:基于可穿戴设备的跌倒检测系统、基于环境信号的跌倒检测系统和基于视频监控的跌倒检测系统[2]。
Guo等[3]将网络连接到家庭自动化系统,从而实现了无线网络通信的功能。Qiu等[4]使用基于环境信号的跌倒检测系统,在实验场地中放置多个传感器,根据传感器传输的数据来判断目标的状态以及家庭安全情况。Chen等[5]以视频监控、人工智能检测和入侵报警为切入点,设计了一套基于图像处理的多功能远程监控家庭智能安防系统。Islam 等[6]和徐毅等[7]利用物联网技术,通过远程控制智能家居和远程监控,实现全方位的安全检测。综上所述,已有成果对于连续视频检测人体跌倒方面的研究并不多。为此,本文提出了一种基于YOLOv5算法的视频图像人体跌倒检测方法,该方法在检测到跌倒时安防系统会发出警报,提醒监护人对跌倒人员进行救治。
1 YOLOv5算法描述
目前,从图像中检测人物的方法大致分为两类:一类是提取人体运动学的显性知识作为行为判断的依据,例如:宽高比、重心等。这类方式存在很大的局限性,在分辨率低、光线过明或过暗、摄像头位置变动的情况下,都可能辨别不清人物的身体特征,从而不能实现人物跟踪[8]。另一类是基于深度学习的目标检测算法,如YOLOv5算法等。此算法使用深度学习技术,从图像中提取特征,根据训练好的模型来判断图像中是否有待检测目标。目标检测的结构一般分为两种(如图1所示):一种是second stage,另一种是first stage。它们的区别在于second stage具有区域方案过程,此过程类似于筛选过程,神经网络会根据候选区域提前生成位置和类别;first stage则是直接生成位置和类别[9]。

图1 基于深度学习的目标检测算法
基于深度学习的YOLOv5算法是一种使用卷积神经网络(convolutional neural networks,CNN)特征的学习方法,这种学习方法能够自动发现、检测及分类目标所需的特征,并通过卷积神经网络将原始的输入信息转化成更抽象、更高维的特征,从而满足实际生产生活中的大多数应用需求。
在检测出目标后,还需要一些参数来评价检测的效果[10]。其中TP(true positive)指被判定为正样本,事实上也是正样本;TN(true negative)指被判定为负样本,事实上也是负样本;FN(false negative)指被判定为负样本,事实上是正样本;FP(false positive)指被判定为正样本,事实上是负样本;AP(average precision)表示平均精确度;mAP(mean average precision)表示各个类别AP的平均值;精确度(precision,P)表示样本中正例被预测正确的目标数占所有预测为正例的比率,该值越接近于1,表明精确度越高[11],公式如下:
(1)
召回率(recall,R)表示预测样本中正例被预测正确样本数占所有正例样本数的比例,公式如下:
(2)
准确率(accuracy,ACC)表示预测样本中预测正确的样本数占所有样本数的比例,公式如下:
(3)
YOLOv5算法的网络结构主要包括4个部分:输入端、Backbone、Neck、Prediction。输入端通过Mosaic进行数据增强;Backbone主要包含Focus切片处理、跨阶段对等(cross stage parity,CSP)结构,起到切片下采样的功能;Neck采用了特征金字塔网络(feature pyramid networks,FPN)+路径聚合网络(path aggregation network,PAN)的结构;Prediction输出端由分类损失函数和回归损失函数组成,用来评判检测效果。本文基于YOLOv5算法的人体跌倒检测方案的基本思路为:首先分析YOLOv5算法的网络结构;然后通过YOLOv5算法网络模型对标注的数据集进行训练;最后对检测效果进行验证和分析,如图2所示。
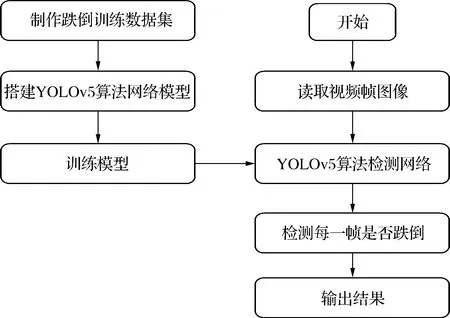
图2 基于YOLOv5算法的人体跌倒检测方案
2 基于YOLOv5算法损失函数的训练和验证
2.1 训练集中GloU损失函数、目标检测损失函数、分类损失函数的训练结果分析
训练集中GloU损失函数、目标检测损失函数、分类损失函数的训练结果如图3所示。从图3可以看出:在0~10迭代次数范围内,三种类型的损失函数均值几乎呈垂直下降趋势;在10~200迭代次数范围内下降幅度变缓,表明训练结果理想。
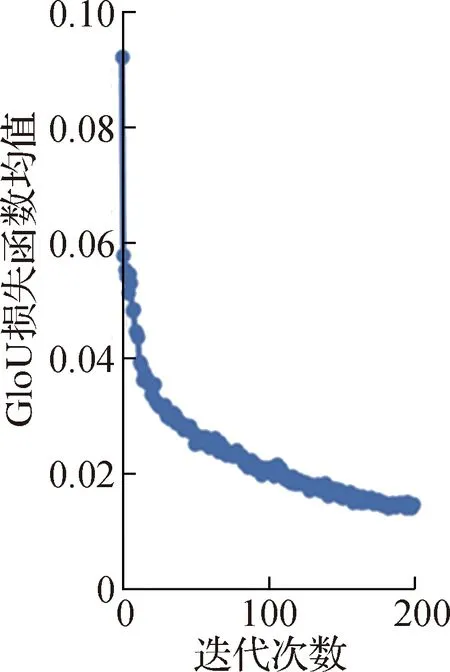
(a)GloU损失函数的训练结果
这三种类型的损失函数均值经过200次迭代后,其中GloU损失函数均值下降到0.015~0.017,表明最小外接矩形的贴合度和准确率均比较高;目标检测损失函数均值下降到0.01左右,表明目标检测准确率较高;分类损失函数均值下降到0.001左右,表明分类准确率较高。
2.2 验证集中GloU损失函数、目标检测损失函数、分类损失函数的验证结果分析
验证集中GloU损失函数、目标检测损失函数、分类损失函数的验证结果如图4所示。从图4可以看出:在0~10迭代次数范围内,三种类型的损失函数均值几乎呈垂直下降趋势;在10~200迭代次数范围内,GloU损失函数均值和分类损失函数均值继续缓慢下降,而目标检测损失函数均值明显上升。
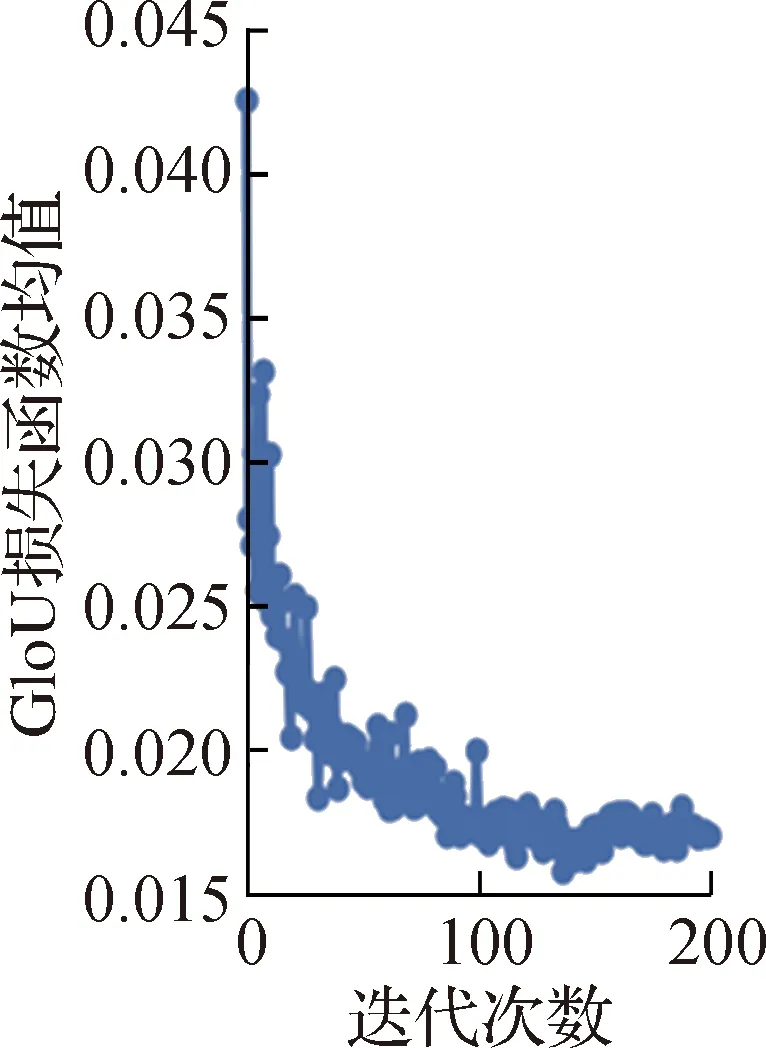
(a)GloU损失函数的验证结果
这三种类型的损失函数均值经过200次迭代后,GloU损失函数均值下降至0.017左右;分类损失函数均值下降至0.002 6左右,表明最小外接矩形贴合度和分类准确率较高,验证结果理想;目标检测损失函数均值达到0.016 7左右,表明目标检测准确率较高。
3 参数的训练
3.1 精确度、召回率的训练结果分析
训练结果主要观察精确度和召回率的波动情况,如果波动不大则表示训练效果好。图5位为精确度、召回率的训练结果。从图5可以看出:在0~10迭代次数范围内,精确度和召回率几乎呈垂直上升趋势;在10~200迭代次数范围内,精确度在0.82左右波动,召回率在0.78左右波动,波动范围不大,表明训练效果好。波动是因为每次训练卷积结果不一样,所以训练集中需要分出一部分到验证集中观察损失函数的变化情况,当损失函数不再改变时,表明此阶段是训练的最佳阶段。
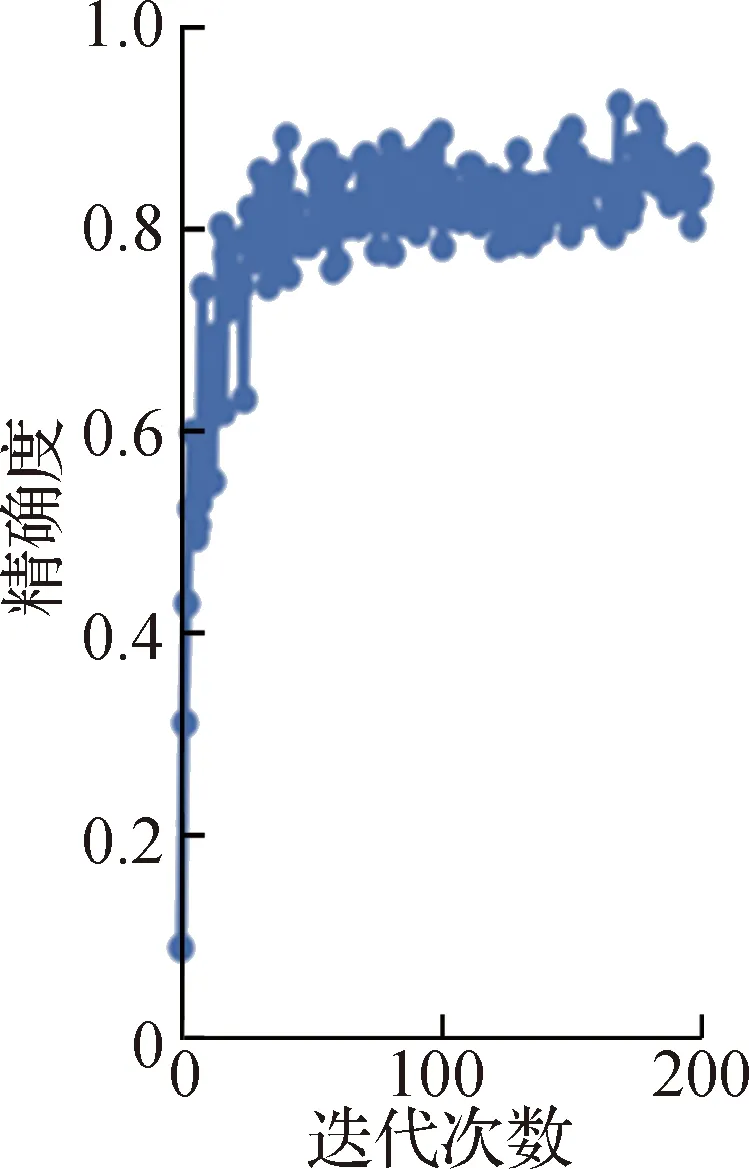
(a)精确度的训练结果
3.2 平均精确度均值(mAP)的训练结果分析
IoU表示正负样本的阈值,一般来说IoU阈值设置低,样本的质量就会变差;IoU阈值设置高,样本的质量就会变好,但是过高的IoU阈值会造成小尺度目标框的丢失。图6为不同IoU阈值下的mAP训练结果,由图6(a)可知:当IoU阈值为0.5时,在0~10迭代次数范围内,mAP的值几乎呈垂直上升趋势;在10~200迭代次数范围内,mAP的值在0.82左右波动。
由图6(b)可知:不同IoU阈值(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上mAP的平均值在0~10迭代次数范围内,几乎呈垂直上升趋势;在10~200迭代次数范围内,上升幅度变缓,经迭代200次后,mAP的平均值在0.68左右波动。
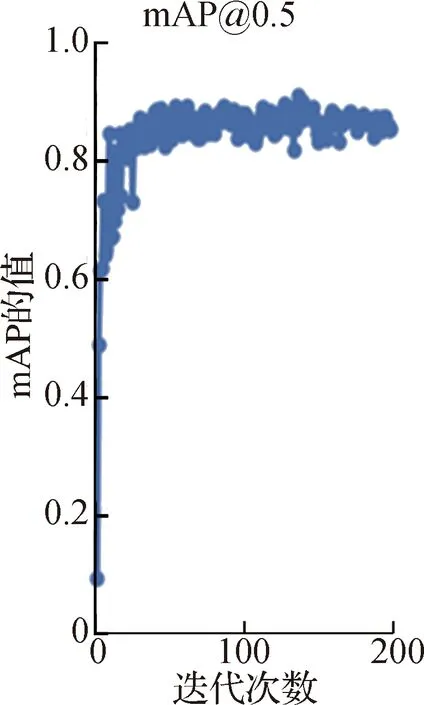
(a)IoU阈值为0.5时mAP的值
4 树莓派的实现
由于树莓派算力不够,可以通过加载FastAPI库编写代码来完成树莓派与电脑的连接。当程序运行时,树莓派将图片发送到电脑端,借助电脑的算力完成检测,电脑再将检测结果反馈给树莓派显示出来。图片中有多个或者单个目标人物站立、坐着或摔倒时,用本文算法检测都能被正确地识别出来并进行分类,具体的检测结果如图7—图9所示。

图7 目标人物站立时的检测结果

图8 目标人物坐着时的检测结果

图9 目标人物摔倒时的检测结果
5 实验结果分析
5.1 对站立、下蹲和跌倒动作识别精确度的比较分析
为了检验YOLOv5算法检测人体动作的真实精确度,共搜集了国内外300幅典型的图片来进行验证,检测出来跌倒动作的识别精确度能够达到92%,站立动作的识别精确度能够达到98%,下蹲动作由于处于跌倒和站立两动作之间,识别精确度仅有82%。
5.2 不同光线环境下对目标人物动作识别置信度的比较分析
在光线充足和阴暗环境下的目标人物动作识别结果的比较分析分别如图10和图11所示。结果显示,光线充足时图片的置信度要高于昏暗环境时图片的置信度,表明光线充足与否会对目标人物动作检测造成一定的影响。

图11 阴暗环境下的检测结果
YOLOv5算法只能检测出主要目标人物的动作,但并不能检测出边缘处一些小目标人物的动作,在训练时要针对一些小目标进行一定量的训练,如图12所示。

图12 小目标的检测结果
5.3 算法对比分析
为了直观地了解YOLOv5算法检测目标人物动作的性能,选择Faster R-CNN算法进行对比。通过同一种数据集训练模型,观察两种算法的精确度以及性能指标,结果发现:1)YOLOv5算法每帧检测只需要0.016 s,而Faster R-CNN需要0.785 s,因此YOLOv5算法比Faster R-CNN算法快得多(表1),Faster R-CNN算法不能满足实时检测需求;2)YOLOv5算法mAP的值比Faster R-CNN算法高36%(表1);3)YOLOv5算法每秒传输的帧数是Faster R-CNN算法的2.25倍;4)Faster R-CNN算法对运行配置的要求要比YOLOv5算法高;5)YOLOv5算法虽然不能识别出全部跌倒人员,但最小矩阵框选范围精确度很高,Faster R-CNN算法虽然能够识别出全部跌倒人员,但最小矩阵框选范围不够精确,因此YOLOv5算法更适合于最小矩阵贴合度较高的目标检测(图13)。

表1 算法对比分析

(a)YOLOv5算法的最小矩阵框选范围
6 结 语
本文基于YOLOv5算法设计了一种人体跌倒检测系统,能够检测出目标人物的跌倒、站立及下蹲动作。通过算法对比发现,YOLOv5算法检测人体动作的速度和精确度高于Faster R-CNN算法,YOLOv5算法更适合于最小矩阵贴合度较高的目标检测。虽然YOLOv5算法能够精确地检测出主要人物的动作,但不能识别出边缘上的一些小目标,因此在后续的研究中需要针对一些小目标进行一定量的训练。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
云南教育·中学教师(2020年11期)2021-01-07 08:26:28
山东煤炭科技(2020年1期)2020-03-06 06:43:28
今日农业(2019年15期)2019-01-03 12:11:33
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
