
多义词造句任务对负性解释偏差的测量 *
2022-07-18 06:53于冠琳郭佳怡张文彩
心理与行为研究 2022年3期
于冠琳 张 璐 郭佳怡 张文彩
(1 中国科学院心理研究所,中国科学院心理健康重点实验室,北京 100101) (2 中国科学院大学心理学系,北京 100049) (3 北京师范大学教育学部,北京 100875)
1 引言
人们生活的环境中充满了可以感知的信息,而想要将信息进行加工、使之可以被理解,进而指导人们的行为,就需要对这些信息做出解释。“解释”是为模糊刺激指派含义的心理过程(Wisco & Nolen-Hoeksema, 2010),而“解释偏差”就是个体倾向于对模糊信息做出负性解释的认知偏差(Beck & Clark, 1988; Clark & Wells, 1995)。解释偏差作为个体从以往经验中获得的习惯性思维模式(Eysenck et al., 1991),是焦虑、抑郁等一系列情绪障碍的关键临床特征(Mathews, 2012)和其产生及维持机制中的重要成分(Beck & Clark,1997; Jalal & Amir, 2014; Mathews & Macleod,2005),也是情绪障碍干预治疗中的重要靶点(Hirsch et al., 2016; Jones & Sharpe, 2017)。
在实证研究中,解释偏差测量范式的核心要素就是能够允许被试做出负性或非负性解释的模糊刺激材料。多义词作为自然语言中同时具有负性和非负性含义的词语,在缺乏语境信息的情况下天然具备语义上的模糊性(例如,patient具有“耐心”或“病人”的含义),因此研究者利用这一特征,通过观察被试对多义词的负性含义是否具有更强的偏好来测量解释偏差。为了方便在不同的实验任务中使用,French和Richards(1992)归纳了英语中同时带有负性和非负性含义的142个多义词,制成一份包含多义词各词义的负性程度和常用程度的多义词表,其他研究就可以直接根据词表选择各含义常用程度均等且负性含义与其他含义效价差异显著的多义词作为实验材料。目前未查阅到使用中文多义词来测量负性解释偏差的文献,因此本研究将首先归纳和评估中文里能够被用作解释偏差测量材料的多义词。
获得材料后需要为其匹配合适的测量任务。造句任务(Taghavi et al., 2000)是操作简便并可以有效隐藏测量目的的投射类任务,它要求被试使用词语创造一个完整的句子,但主试不会告知被试题目中给出的词语是多义词,当被试基于对多义词语义的解释来从无到有地构建句子,发生的“语义理解”和“语境创造”两个心理过程都是“用负性/非负性的方式对模糊内容做出解释”的过程,研究者就可以通过观察被试在句子中是否使用了负性语义和是否创造了负性语境这两个维度来测量其解释偏差。目前国内研究者对解释偏差的测量普遍使用译自国外或自主编订的模糊情境(张晓敏 等, 2019; Jin et al., 2014),为了探索多义词造句任务相较于现有范式的优势,本研究选取乱句重排任务(Wenzlaff & Bates, 1998)进行比较。乱句重排任务包含将词汇排序构建语句的过程和正负二分的计分特征,在形式上与多义词造句任务相似,但由于排序过程中会将两种解释都加以呈现,被试容易猜出任务目的,作答容易受到需求特征的影响(Schoth & Liossi, 2017)。因此本研究假设,多义词造句任务在具有优良信效度的同时还具有实验目的隐蔽性高的优势。
此外,虽然解释偏差与多种情绪障碍存在关联,但研究者通常会筛选具有症状特异性的材料以提高测量效度(Schoth & Liossi, 2017),相比于社交焦虑研究中已经相对成熟且症状特异性强的社交情境材料,多义词材料没有特定的内容指向,却正好与广泛性焦虑个体忧虑内容范围较广且泛化的特点相契合。广泛性焦虑以对未来可能发生消极事件的过度担忧和无法容忍不确定性为核心特点,因此广泛性焦虑个体倾向于为未来不确定事件做出负性或灾难化的解释(Hirsch & Mathews,2012),大量实证研究都发现广泛性焦虑人群相比于健康人群具有更强的解释偏差(Anderson et al.,2012; Eysenck et al., 1991; Hazlett-Stevens & Borkovec,2004),因此本研究将选取广泛性焦虑人群作为多义词造句任务的目标测量对象。
综上,本研究拟实现如下三项研究目的。首先,在研究1中,(1)归纳和评价可以用作解释偏差测量材料的中文多义词;(2)针对广泛性焦虑症状人群初步使用多义词造句任务测量解释偏差,筛选出对焦虑敏感的项目,并初步评价任务的可靠性和有效性。在研究1的基础上,研究2的研究目的是:(3)改进施测程序,实施正式的多义词造句任务,通过添加效标和与乱句重排任务的对比,验证多义词造句任务测量解释偏差的有效性和目的隐蔽性。
2 研究1:多义词造句任务的初步编制
2.1 研究方法
2.1.1 被试
预实验样本:参与多义词的初步筛选(评价两个义项的情绪效价和常用程度),为保证评价不受焦虑情绪的影响,选取广泛性焦虑量表(GAD-7)得分小于等于4分(M=1.43,SD=1.73)的本科生和研究生被试27名(女性14名,平均年龄21.32±2.52岁),被试自诉无精神疾病史,母语均为中文。
样本1:参与多义词造句任务的初步施测,根据GAD-7得分将62名本科生和研究生被试(女性40名,平均年龄22.05±2.24岁)分为健康组(GAD-7得分小于等于4分,33人)和焦虑组(GAD-7得分大于4分,29人),母语均为中文,具备正常的中文读写能力。
2.1.2 实验材料
从《现代汉语多义词词典(修订本)》(2001版)中选取了82个具有负性和非负性义项的多义词(例如,轻薄:①重量轻且厚度薄;②看不起、不尊重)。多义词负性义项的情绪效价需显著低于非负性义项,并且为了确定被试使用负性义项是由于解释偏差而非该义项在自然语言中更常用,负性义项的常用程度不能显著高于非负性义项。因此,在预实验样本中对多义词的两个义项分别进行情绪效价(1~7分对应“非常消极”到“非常积极”)和常用程度(1~7分对应“非常不常用”到“非常常用”)的7点评分,经过配对样本t检验筛选出72个符合上述条件的多义词,其负性义项的情绪效价均值显著低于非负性义项[M负=2.19,SD=0.37;M非负=4.11,SD=0.49,t(26)=32.00,p<0.001],且两义项的常用程度均值无显著差异[M负=5.49,SD=0.50;M非负=5.65,SD=0.45,t(26)=1.85,p=0.069]。将这72个多义词顺序随机打乱,组成“词语造句测试”。
2.1.3 研究工具
广泛性焦虑量表(GAD-7):包含7个项目,每个项目反映一条DSM-5中广泛性焦虑障碍的典型症状,采用0~3分(从“完全没有”到“几乎每天”)的4点计分表示出现症状的频率,其中文版具有良好的信效度(何筱衍 等, 2010),本实验中内部一致性系数为0.92~0.93。量表得分5分及以上的被试存在轻度及以上的广泛性焦虑症状,得分4分及以下可被认为是健康人群(Spitzer et al., 2006)。
2.1.4 施测程序与数据分析
样本1被试在问卷星上完成GAD-7后来到实验室,被告知将参与一次简单的语言能力测验。测验用纸笔方式呈现,被试需要快速将自己看到每个词语后第一反应所想到的句子写在横线上,并对词语的情绪效价进行7点评分(1~7分对应“非常消极”到“非常积极”,用于辅助主试辨别句子中使用了哪个义项,不计入统计分析),无时间限制且必须完成全部题目。所有数据采集完毕后,主试采用2点计分的方式对被试在每个句子中使用多义词语义和语境情绪效价按照如下标准进行辨别和计分:语义上,使用负性语义记1分、非负性语义记0分;语境情绪效价上,负性语境记1分、非负性语境记0分。因此多义词造句任务所测量的解释偏差分为语义分数、语境分数和总分三个指标,语义和语境分数分别来自该维度所有题目得分的和,总分则是该被试语义和语境得分的总和。使用SPSS26.0进行数据分析。
2.2 结果
被试所造例句及其类别示例见表1。62名被试语义维度的平均分为30.76±6.21分,语境维度的平均分为27.24±8.24分,总分的平均分为58.00±13.46分,三项得分均符合正态分布。

表1 被试所造句子及其类别举例
2.2.1 区分度
使用相关系数法计算每个题目的区分度。计算题目得分与GAD-7得分的相关,根据伊贝尔在1965年提出的评价题目性能的标准,性能合格的最低标准设定为r=0.2且p<0.05,检验后删除了相关系数不显著的38个题目,保留34个题目,且剩余题目区分度均高于性能合格的最低标准(0.2),具体见表2。

表2 项目区分度(r)及去留情况
2.2.2 信度
34个保留题目总分的内部一致性系数为0.82,语义和语境维度的内部一致性系数分别为0.76和0.82,信度良好。
2.2.3 构想效度
使用分组检验法,对焦虑组和健康组在测验总分、语义维度和语境维度得分的差异分别进行t检验。结果发现,焦虑组被试的测验总分[t(60)=2.47,p=0.016,d=0.64]和语境维度得分[t(60)=2.77,p=0.008,d=0.71]显著高于健康组,语义维度得分与健康组差异不显著[t(60)=1.38,p=0.072,d=0.36],见图1。焦虑组被试写出了更多负性句子,任务可以测得其更高的负性解释偏差,语义维度的差异虽未达到显著,但仍具有中等程度的效应量,因此将在研究2中进一步验证。
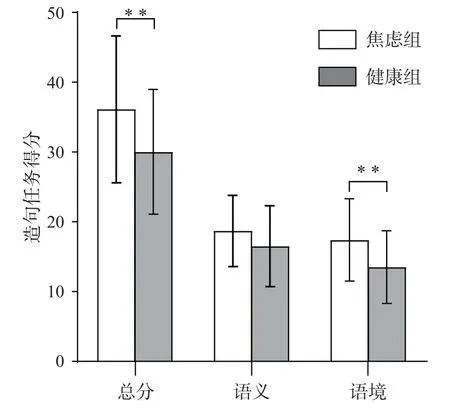
图1 焦虑组和健康组测验总分、语义维度和语境维度得分差异的t检验
3 研究2:多义词造句任务的有效性和隐蔽性
3.1 研究方法
3.1.1 被试
样本2:采用整群抽样,从广西某大学本科生中抽取非心理学专业的6个班级共222名被试(女性141名,平均年龄18.92±0.99岁),母语均为中文,具备正常的中文读写能力和计算机操作能力。
3.1.2 实验任务及工具
多义词造句任务:将34个多义词随机分为A、B两组,每组17个,录入问卷星使题目按随机顺序呈现。
乱句重排任务:包含40个与焦虑有关的题目(例如,“我担忧/思考我的未来”),随机分为A、B两组,每组20个,录入问卷星使题目按随机顺序呈现。
广泛性焦虑问卷(GAD-7):同研究1,本实验中该问卷的内部一致性系数为0.90。
状态焦虑问卷(STAI-S)(汪向东 等, 1999):使用状态-特质焦虑问卷的状态焦虑分量表,包含反映恐惧、紧张、忧虑等焦虑感受的20个描述句,被试需要根据当下的情绪体验进行4点评分(1~4分对应“完全没有”到“非常明显”),问卷得分作为状态焦虑的指标,本实验中该分量表的内部一致性系数为0.78。
积极消极情感量表(PANAS)(黄丽 等, 2003):包含描述积极消极情绪的形容词各10个,被试需要根据当下的情绪状态进行5点评分(1~5分对应“完全没有”到“非常多”),本研究使用消极情感分量表的得分作为消极情绪的指标,本实验中该分量表的内部一致性系数为0.89。
3.1.3 施测程序与数据分析
采用线上集体施测。被试使用电脑登录问卷星网页,被告知将参与两个语言能力测验并填写一些问卷。所有被试被随机分配到使用A或B组材料的实验任务。首先进行乱句重排任务,被试需要在3分钟内尽可能多地将每个题目中的乱序词语排列成句子,并把词语对应的序号按照排列好的顺序输入答案框中,结束后休息30秒。然后进入多义词造句任务,被试需要使用每个题目给出的词语来造句并输入答案框,同样限时3分钟。此外,为了增加认知负荷,在进行这两个任务时,被试需要记忆一组随机数字,并在每个任务结束后回忆数字作为干扰任务,以获得更真实的反应(回忆数字的对错不计入统计分析)(Rude et al.,2002)。完成任务后休息30秒,填写GAD-7、STAI-S、PANAS,并分别回答是否猜出了两个任务的测试目的,如果回答“是”,还需报告自己猜测的测试目的。
在计分上,对于多义词造句任务,招募3名心理学研究生作为评分者,他们的GAD-7问卷得分均低于4分且不知道研究目的。研究者制作了多义词语义和语境评分标准的手册,并对评分者进行了培训与试评练习,在确定充分理解评分规则后进行正式评分。3名评分者对多义词造句任务的语义和语境维度分别进行了独立评分(计分方式同研究1),由研究者汇总并求出均值。由于在规定时间内每名被试完成题目的数量不同(乱句重排任务平均完成10.61±3.74个题目;多义词造句任务平均完成7.20±3.50个题目),因此将被试在语义和语境维度上的得分分别除以完成的项目数,再相加得到总分,作为进入统计分析的数据。3名评分者在语义维度和语境维度上的肯德尔和谐系数分别为0.90(p<0.001)和0.78(p<0.001),评分结果较为一致。对于乱句重排任务,使用负性句子数占完成总句子数的比例作为任务得分进入统计分析。关于实验目的隐蔽性,研究者对被试是否猜对了实验任务的目的进行判断(猜对任务目的:如被试报告“测试我对一些词语会往好的想还是坏的想”“通过造句判断看待事物是否消极”等),分为被试主观报告是否猜出和主试判断是否猜对两个计数指标。使用SPSS26.0进行数据分析。
3.2 结果
3.2.1 随机分组有效性检验
独立样本t检验发现,A、B组材料在两任务的各指标上均无显著差异[t语义(220)=0.17,p=0.87;t语境(220)=0.79,p=0.43;t总分(220)=0.52,p=0.60;t排序(220)=-1.32,p=0.19],随机分组有效,因此将A、B组材料视同等价,合并分析。
3.2.2 构想效度
各任务和问卷得分均符合正态分布。
使用GAD-7得分分组,对多义词造句任务得分在焦虑组(88人)和健康组(134人)之间的差异进行t检验。结果发现,焦虑组被试的总分[t(220)=4.17,p<0.001,d=0.56]、语义维度得分[t(220)=3.24,p=0.001,d=0.44]和语境维度得分[t(220)=3.90,p<0.001,d=0.53]均显著高于健康组,说明焦虑组被试具有更高的负性解释偏差,与初步编制时的结果一致。使用状态焦虑得分的中位数分组(Md=51,高分组117人,低分组105人)进行t检验,发现高分组被试的总分[t(220)=3.60,p<0.001,d=0.49]、语义维度得分[t(220)=2.40,p=0.017,d=0.32]和语境维度得分[t(220)=3.85,p<0.001,d=0.52]均显著高于低分组,说明高状态焦虑被试更多使用了多义词的负性语义,写出了更多消极句子,具有更高的负性解释偏差。见图2。

图2 GAD-7焦虑组和健康组以及高低状态焦虑组测验总分、语义维度和语境维度得分差异的t检验
此外,使用消极情绪得分的中位数分组(Md=18,高分组115人,低分组107人)进行t检验,发现高低分组被试的总分[t(220)=1.79,p=0.074]、语义维度得分[t(220)=1.60,p=0.111]和语境维度得分[t(220)=1.48,p=0.14]的差异均不显著,说明改编后的多义词造句任务对焦虑中的解释偏差具有针对性,效度良好。
最后进行同证效度的检验,多义词造句任务总分与乱句重排任务得分的相关为0.29(p<0.001),语义维度相关为0.22(p<0.001),语境维度相关为0.28(p<0.001)。由此可见,多义词造句任务的各指标均与乱句重排任务得分之间存在低程度的显著相关,表明二者测量的内容既有显著的关联,又具有一定程度的异质性。
3.2.3 实验目的隐蔽性
在两个任务上主观报告猜出任务目的与实际猜对任务目的的被试数如表3所示。进行四格表卡方检验,发现主观报告猜出多义词造句任务目的的被试数显著少于乱句重排任务(χ2=106.71,p<0.001,rΦ=7.16),实际猜对多义词造句任务目的的被试数显著少于乱句重排任务(χ2=32.50,p<0.001,rΦ=2.18)。由此可见,与乱句重排任务相比,多义词造句任务的目的隐蔽性更高。

表3 主观报告猜出任务目的与猜对任务目的的被试数及比率
4 讨论
本研究归纳了同时具有负性和非负性含义、可以用来测量解释偏差的72个中文多义词,并针对广泛性焦虑症状筛选出34个对焦虑敏感的题目,形成了信效度良好且具有测量目的隐蔽优势的多义词造句任务。
首先,使用多义词作为实验材料具有简洁易操作的优势,对儿童或患有感觉运动障碍等疾病的人群可以采用纸笔作答或口头报告的方式进行测量,并且可以通过筛选来适应不同人群的测量需求,而模糊情境类材料若不根据被试群体特征单独编制材料则会容易出现测量效度低的问题(Schoth & Liossi, 2017)。并且,多义词在解释偏差干预研究中也发挥重要作用,目前使用解释偏差矫正训练的实证研究中,通常使用给予对错反馈的方式指导被试在模糊情境中选择非负性解释来“自下而上”地改善负性认知模式,但此类研究中,前后测与训练的材料具有高同质性,不足以真实客观地衡量干预后解释偏差的改变(刘冰茜, 李雪冰, 2018),特别是在只有模糊情境类材料的中文环境下。而本研究归纳的多义词丰富了解释偏差测量材料的类别,可以为干预效果的测量提供更可靠的证据。
将多义词材料与造句任务结合并改进后,多义词造句任务具有如下四点优势:(1)在计分方式上,语义理解和语境创造的心理过程分别对应任务的语义和语境维度,和其相加的总分都具有良好的信效度,这些指标较为完整地反映了解释的认知过程,可以根据研究需求单独选用一个指标或将几个指标联合使用。(2)在症状特异性上,以往研究认为广泛性焦虑个体对反映忧虑、潜在威胁和无法忍受不确定性相关的信息具有更强的解释偏差(Hirsch et al., 2016),这在本研究筛选出的多义词中有对应的体现,如“算账”“轻薄”“修理”等词的负性含义中带有潜在的威胁和暴力元素,“悬空”“漩涡”“漂泊”等词指向对不确定性的难以忍受,“曲折”“苦涩”“负重”则反映了过度忧虑时的心理感受,这些题目与焦虑症状的特征相匹配,提升了任务的效度。(3)在同证效度上,较低程度的显著相关指示两种任务具有一定的异质性,这可能是由于解释是一个包括“产生”和“选择”的较为复杂的认知过程(Everaert et al., 2017),多义词造句任务使被试激活、选择语义并自主产生语境实现造句,但乱句重排任务将两种解释直接呈现,只包含选择过程,所以两个任务测量到的心理特征会有所区别。因此,未来的研究需要根据不同实验目的来选择合适且有效的实验任务,以往的研究者也认为使用多种方法相结合的方式去测量解释偏差可能是更好的选择(Everaert et al., 2017)。(4)关于目的隐蔽性,多义词造句任务作为一种投射测试,其测量的更多是内隐和自动化的心理过程,以往研究认为自动化的解释偏差是“个体没有意识到自己的解释是有偏差的,或没意识到还存在其他解释”(Hirsch et al., 2016),造句任务可以通过让被试聚焦于造句过程来防止其主动搜寻其他解释或觉察自身偏差,从而较好地隐藏实验目的。并且,在干预研究中,使用目的隐蔽性高的造句任务也可以有效规避被试在大量训练后觉察实验目的所带来的期望效应的影响(刘冰茜, 李雪冰, 2018),有助于测得真实的干预效果。
本研究也存在一定局限。首先,本研究虽然归纳了72个多义词,但只针对广泛性焦虑筛选出了34个题目的多义词造句任务,而解释偏差作为一种消极的认知模式也普遍存在于社交焦虑、惊恐障碍、抑郁、慢性痛、神经性厌食症、酒精依赖等情绪障碍和身心疾病中,因此若要在其他人群中施测,还需针对人群特征进行筛选,避免由于材料选取不当带来效度问题。其次,个体对多义词各语义的理解程度及常用程度也会受到年龄、文化背景、受教育程度的影响(Schoth &Liossi, 2017),在中文里,多义词的比喻义和引申义也会随着语言的发展而变化,因此多义词材料也可能需要根据受测人群的年龄特征做出调整。
5 结论
本研究搜集了中文里可以用来测量解释偏差的多义词,针对广泛性焦虑人群评估了具有良好信效度的多义词造句任务,并与乱句重排任务对比,验证了其目的隐蔽性高的测量优势,为中文环境中测量解释偏差提供了另一种便捷高效的选择。
猜你喜欢
健康体检与管理(2022年4期)2022-05-13
校园英语·中旬(2022年3期)2022-04-23
作文大王·低年级(2021年9期)2021-09-10
作文周刊·小学一年级版(2021年4期)2021-04-06
中国药学药品知识仓库(2021年18期)2021-02-28
心理学报(2021年1期)2021-01-29
初中生学习指导·中考版(2020年2期)2020-09-10
小猕猴智力画刊(2017年11期)2017-12-07
北方文学·下旬(2016年10期)2017-03-03
东方教育(2016年15期)2017-01-16
