
基于改进YOLOv3 的SAR 舰船图像目标识别技术
2022-07-15 19:23姜浩风梅少辉
上海航天 2022年3期
姜浩风,张 顺,梅少辉
(西北工业大学电子信息学院,陕西 西安 710072)
0 引言
舰船是水上交通运输的重要载具,对水面舰船的监测与管理是各国海事部门的一项重要工作。合成孔径雷达(Synthetic Aperture Radar,SAR)技术是一种主动式微波遥感探测技术,它利用脉冲压缩和合成孔径同时提高雷达距离向和方位向的分辨率,从而获得全天候、全天时、大面积、高分辨率SAR 图像。SAR图像自动目标识别(Automatic Target Recognition,ATR)技术旨在自动从SAR 图像中判断出有无目标信息,提高SAR 图像的解读效率与准确度。SAR 系统可安装于飞机、卫星等平台,并且可全天候、全天时观察地面和海洋表面,因此SAR 图像ATR 技术对海洋监测领域的水面舰船检测与识别具有重要价值。
近年来,SAR 图像ATR 技术已经在全世界得到深入研究,并形成了固定的三级流程:检测、鉴别和分类。检测模块主要基于检测算法获取包含SAR 图像目标的切片,鉴别模块对于目标切片剔除虚警值,分类模块选取最佳决策机制判断类别。
传统的SAR 图像舰船检测算法为基于统计建模的恒虚警率(Constant False Alarm Rate,CFAR)算法,包括双参数CFAR 算法、基于分布的CFAR 算法,以及最佳熵自动门限法、多极化方法等。此类方法均需要对原始图像进行预处理,如杂波过滤、海陆分割,在检测过程中也需要根据先验知识对部分虚警目标进行过滤。目前,随着人工智能领域的快速发展,卷积神经网络(Convolutional Neural Network,CNN)可以实现对图像高层特征的主动提取,避免了人工选取特征的复杂工作,具有良好的分类准确度和鲁棒性,为SAR 图像目标检测提供了新的途径。
在自然图像的分类识别任务上,研究人员提出了一些非常典型的深度学习网络模型,例如AlexNet、VGG、Googlenet、ResNet、DenseNet、Inception、MobileNet、SqueezeNet等。目前成熟的目标检测模型大多基于这一系列网络架构,例如twostage 的R-CNN、Fast R-CNN、Faster R-CNN检测算法与one-stage 的YOLO系列检测算法。对于SAR 图像的舰船检测,深度学习在检测速度与检测精度上都优于传统的检测方法,YOLOv3相比其他目标检测模型,在保证准确率的同时进一步提高了检测效率。本文在YOLOv3 网络的基础上,用稠密网络模块代替用于提取中小尺度特征的残差网络模块,改进网络对于较小尺度SAR 舰船目标的检测性能,使用综合交并比(GIoU)度量损失代替交并比(IoU)边界框回归损失,提升边界框的检测精度。
1 网络模型及算法
1.1 YOLOv3 网络
YOLOv3 网络是一种单阶段目标检测网络,与两阶段目标检测网络相比,单阶段目标检测网络具有更快的检测速度。YOLOv3 网络采用Darknet 53作为主干网络以提取输入图像的特征,同时结合了多种优秀的方法如多尺度检测、残差网络等,进一步提升了网络性能。YOLOv3 首先将输入图像调整至416×416 的大小,再将其分割成×的网格,网格中每个单元格负责检测中心点落在该单元格中的目标。每个单元格会检测3 个不同尺度的边界框并预测其置信度。预测量包括、、、与置信度,其中、为边界框中心坐标在和方向的相对偏移量,和为边界框的宽和高,置信度通过阈值对预测结果进行取舍,表示边界框中预测目标类别的准确性。
1.2 DenseNet 网络
密集连接网络(DenseNet)由HUANG 等于2016 年提出,该网络并未参考ResNet 的思想,通过残差级联实现增加网络层数,从而提升网络性能;也未参考Inception 的思想,通过扩展网络宽度提升网络性能,而是着眼于特征方面,将特征在多个通道上以不同的方式进行连接实现特征重组,从而保证其特征信息的全面性,提高特征复用率。
通过对特征的重组利用不仅在一定程度上减轻了梯度弥散问题,而且在减少了参数数量的同时加强了特征的有效传递。对于一个层的网络结构,DenseNet 网络将0 层至(-1)层的输出进行非线性变换:式中:H(·)为非线性变换函数;[,,…,x]为将0 层~(-1)层输出的特征进行拼接;x为第层的变换结果。
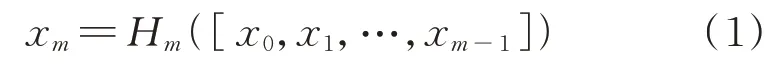
DenseNet 以这种稠密连接的方式最大化地使用特征信息。因此本文采用DenseNet 网络中的稠密模块来加强网络对于特征的提取。
1.3 YOLOv3 与DenseNet 网络的融合策略
ResNet 网络与DenseNet 网络都是应用于分类任务中,两者的框架结构极为相似,其网络都是由若干个单元模块堆叠而成,且单元模块都是由激活函数层、卷积层与批归一化层组成。因此,在原有结构的基础上,将残差模块(Residual Block,Res Block)替代为稠密模块(Dense Block),并改变其连接方式即可完成替代工作,如图1 所示。其中Conv2D 代表卷积模块,Contact 代表全连接模块,Upsampling 代表上采样模块。将YOLOv3 网络中对尺度26×26 和52×52 进行预测输入的两组残差模块替换为自定义的密集连接模块,构建出一个带有密集型连接模块的特征提取网络,使尺度26×26和52×52 在进行预测之前能够接收密集连接块输出的多层卷积特征,增强特征的传递并促进特征复用和融合,进一步提升检测效果。
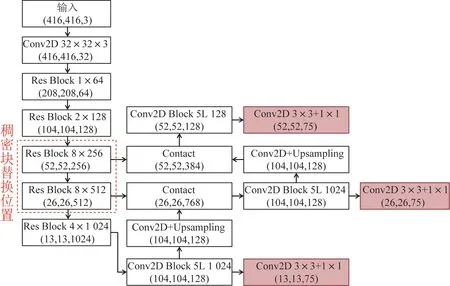
图1 YOLOv3 结构图及稠密块位置Fig.1 Diagram of the YOLOv3 architecture and the dense block position
稠密模块中通道维数的变化过程如图2 所示,在第1 组Dense Block中共有8 个Dense Block Unit,分别代替对应位置的Residual Block Unit。Dense Block 的输入为52×52×256 的特征图,为了减少计算负担,在后7 个Dense Block Unit 中的输入前分别执行1×1 的卷积操作实现降维,即每次增加的通道数为128:


图2 稠密模块维度变化Fig.2 Dimension change of the dense block
式中:H(·) 为BN+ReLU+Conv(1×1)+BN+ReLU+Conv(3×3)的组合函数表达,即附加Bottleneck layer 的Dense Block 的非线性组合函数;,,…,X为每次线性组合操作后的结果。输入特征图经8 组非线性函数组合获取到52×52×1 280 特征图,随后,将其与特征交互部分中上采样获取的52×52×128 特征图进行拼接操作,得到52×52×1 408 的特征图,以此作为输出应用于检测小尺度的目标。
第2 组Dense Block 的输入通道数为512,通道变化做出相同的降维预处理,即每次增加的通道数为256,经过8 组Dense Block Unit 后输出26×26×2 560 的特征图,并将其与特征交互部分经上采样获取的26×26×256 特图执行拼接操作,经通道合并后输出26×26×2 816 特征图用于中型尺度目标检测。改进之后的模型YOLOv3 网络结构如图3 所示。

图3 改进后的模型结构Fig.3 Structure of the improved model
1.4 多尺度先验框
随着输出特征图数量和尺度的变化,先验框的尺寸也需要进行相应调整。YOLOv3 延续了YOLOv2的方法,采用-means聚类得到先验框的尺寸,为每种下采样尺度设定3 种先验框,共聚类出9 种尺寸的先验框:(10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59×119)、(116×90)、(156×198)、(373×326)。
在检测中,不同大小的目标分配不同尺度的先验框,最小的13×13 特征图具有最大的感受野,应用较大的先验框(116×90)、(156×198)、(373×326),适合检测较大的目标。中等的26×26 特征图具有中等感受野,应用中等的先验框(30×61)、(62×45)、(59×119),适合检测中等大小的目标。较大的52×52 特征图具有较小的感受野,应用较小的先验框(10×13)、(16×30)、(33×23),适合检测较小的目标。不同尺度下的特征图与先验框如图4所示。

图4 不同尺度下的特征图与先验框Fig.4 Characteristic diagrams and a priori frames at different scales
在目标检测的过程中,如果目标中心落在某网格中,即由该网格负责预测。YOLOv3 的输出结果通过预测不同网格的锚点所对应的偏移量完成检测目标预测框的回归,如图5 所示。
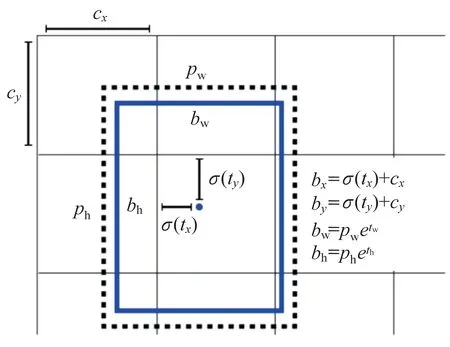
图5 边框预测Fig.5 Frame prediction
图中:c、c为负责预测网格的左上角坐标;t、t为被测目标中心相对网格左上坐标的偏移量;、为预设的先验框映射到特征图中的宽和高;b、b为最终得到的边框中心坐标;、为其相对特征图的宽与高。(·)sigmoid 函数将,压缩到[0,1]区间内,确保目标中心处于执行预测的网格单元中,防止偏移过多;、为尺度缩放的参数,经过指数运算还原后参与、的运算。
1.5 GIoU 改进
YOLOv3 模型使用IoU 即交并比作为衡量检测定位性能的主要指标,IoU 计算公式如下:
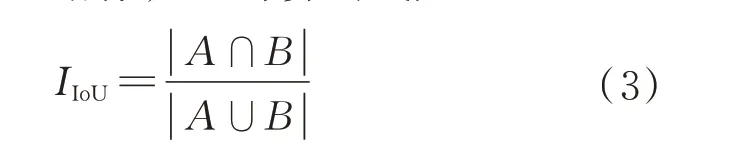
式中:、分别为预测框与真实框的位置信息。
损失函数定义为

IoU 作为指标存在2 个问题:1)若两框没有相交,即=0,此时IoU 无法反映预测框与真实框之间的距离,同时损失函数无法进行梯度的反向传播,故无法通过梯度下降的方式进行训练。2)IoU仅能量化地表示两框之间的重合度大小,无法表示两框的空间位置关系。
针对以上2 个问题,HAMID 等提出了 使用GIoU 作为新的指标,计算公式如下:

式中:为包含与的最小同类形状,其损失函数为
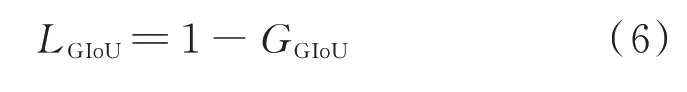
GIoU 继承了IoU 的尺度不变性,同时相较与IoU 仅关注重合区域,GIoU 还关注了非重合区域,可以更好地反映预测框与真实框的重合程度。
2 实验过程及结果
2.1 数据集介绍
本实验采用中国科学院空天信息研究院数字地球重点实验室研究员王超团队公开的SAR 图像船舶检测数据集。该数据集包括多源、多模式SAR 图像,以我国国产高分三号SAR 数据和Sentinel-1 SAR 数据为主数据源,数据及其标注格式适用于目标检测任务。目前,该深度学习样本库包含43 819船舶切片及其标注信息,数据集样例如图6所示。
图6 SAR 舰船数据集样例Fig.6 Examples of the SAR ship dataset
2.2 模型训练
本实验的训练环境为:Ubuntu16.04 系统,python3.7,pytorch1.7.1 框架,cuda10.1,cudnn8.0,GPU为GTX1080Ti。
本实验采用监督学习的方式,通过损失函数计算网络输出值与期望值之间的误差,通过误差反向传播调节网络内部的各项参数来减小误差,使网络逐渐收敛。在训练过程中选择SGD 优化器,权重衰减(Weight Decay)设置为0.000 5,冲量(Momentum)设置为0.9,学习率设置为0.001,训练50 000 批次后,损失函数趋近于0,表明模型收敛,对训练数据的拟合程度较好。损失函数曲线如图7 所示。

图7 网络训练损失曲线Fig.7 Network training loss curve
2.3 实验结果
本实验采用的评价指标为主流的类平均准确率(Mean Average Precision,mAP)与每秒传输帧数(Frames Per Second,FPS)。mAP 是所有检测目标类别的平均值(Average Precision,AP),衡量模型在各类别上识别效果的平均水平。FPS 用于衡量模型的检测速率。本实验采用Faster R-CNN 与原版YOLOv3 作为对比算法,实验中训练样本与验证样本的比例为9∶1,测试结果见表1。

表1 测试结果对比Tab.1 Comparison of the test results
由表1 可知,改进后的YOLOv3 框架的检测性能在准确率上优于Faster R-CNN 与原版YOLOv3,相较原版YOLOv3 模型,改进后模型的mAP 提高了1.4%,在检测速度上与原版YOLOv3 一致,这是因为改进的方法并未对YOLOv3 做模型结构与参数量上的简化。改进后的YOLOv3 采用稠密模块替换残差模块来提高对小目标的检测精度。由于海面目标多为小型舰船,因此改进后的YOLOv3 比原版具有更高的检测精度,检测结果图像如图8 所示。

图8 SAR 舰船检测结果Fig.8 Results of the SAR ship detection
3 结束语
本实验针对SAR 图像自动目标识别问题展开了研究,设计了一种基于改进YOLOv3 架构的SAR舰船检测模型。该模型通过将网络中部分残差模块替换为稠密连接模块,改进了网络对于小尺寸目标的检测性能,通过用GIoU 取代IoU 提高预测框的检索准确度。
实验结果表明,改进后的YOLOv3 框架基于其对小目标检测的优秀性能,在SAR 舰船检测的任务上取得了较好的结果。
猜你喜欢
客联(2021年9期)2021-11-07
成都理工大学学报·社会科学版(2017年4期)2017-09-08
社会科学(2017年4期)2017-06-07
同学少年·作文(2017年1期)2017-06-05
岁月(2016年5期)2016-08-13
现代企业(2016年7期)2016-05-14
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
环球时报(2009-09-16)2009-09-16
雕塑(2000年2期)2000-06-22
