
基于指针网络的突发事件抽取对抗学习方法
2022-07-13 02:38:42韩志卓李慧波肖若冰宋凯磊陈晓东
中国电子科学研究院学报 2022年3期
韩志卓,李慧波,和 凯,肖若冰,宋凯磊,陈晓东
(1.中国电子科技集团公司第五十四研究所,河北 石家庄 050081;2.河北远东通信系统工程有限公司,河北 石家庄 050200;3.中国电子科学研究院,北京 100041;4.新疆公安厅,新疆 乌鲁木齐 830000)
0 引 言
信息爆炸带来的海量信息源杂乱无章,价值信息无法利用,为提取文本中价值信息,信息抽取技术得以出现,旨在从冗余非结构化数据中抽取不同层次和粒度的信息并形成结构化数据,支撑下游任务的分析及应用,如知识问答、信息检索等[1]。
事件抽取作为信息抽取的关键技术之一,其目的在于将文本中重点关注的事件信息提取并结构化存储。其中,触发词识别用于识别事件中的核心指示词,事件要素抽取用于提取组成事件的关键词,如时间、地点、人物、动作等[2]。通过事件抽取获得的结构化数据对于后续信息服务如应急救援、舆情监控、事件监测等具有重要的支撑作用[3]。
目前,常见的事件抽取方法主要包括模式匹配、机器学习、深度学习及上述方法的混合。早期基于模式匹配的事件抽取方法是领域强相关的,模式获取需要专家知识且需要进行人工设计,成本过高。为解决上述问题,基于种子模式的自举信息抽取模式获取方法[4]、基于WorldNet和预料标注的模式学习方法[5]以及基于领域无关概念知识库的模式提取方法[6]等得以提出,但基于模式匹配的抽取方法由于领域强相关,该方法的可移植性较差。
基于机器学习的事件抽取方法的关键在于分类器的构建及语料特征的抽取。文献[7]提取词法、上下文、词典等特征,基于最大熵的多元分类方法完成事件要素的抽取,在抽取效率上获得较大提升。然而机器学习需要人为设计大量特征,特征模板的获取需要专家知识,成本较高,且无法获取长依赖关系的语义信息。因此,可自动获取特征及学习长依赖语义信息的深度学习成为近年来事件抽取的主流方法。
2015年百度研究院提出了BiLSTM-CRF模型,该模型在事件抽取过程中具有优越的性能,被学者所青睐[9]。2018年10月由Google AI研究院提出了一种预训练模型BERT,在11种不同NLP测试中创出SOTA表现,成为NLP发展史上的里程碑式的模型成就。文献[9]基于预训练模型BERT获取语料库中Embedding词向量作为后续BiLSTM-CRF算法的输入,进而完成中文实体识别且识别效果较好,然而BERT-BiLSTM-CRF模型在预测时算法复杂度较高且CRF算法进行解码预测时会导致实体片段的断裂。
为解决预测结果断裂问题,本文利用SPAN网络代替CRF模型,并融合对抗训练FGM算法及平滑标签损失函数,提出BERT-BiLSTM-SPAN-adv-lsr算法进行中文要素的识别,解决要素识别断裂问题且通过对抗训练及标签平滑的方法增强模型鲁棒性及对未知样本的识别泛化能力[10-11],最终通过实验验证本文所提算法的有效性。
1 相关工作
1.1 文本预训练模型BERT
文本Embedding特征向量的提取常用的方法为Word2Vec,然而该方法在提取Embedding向量过程中受窗口大小限制,语义信息提取不全面。BERT模型采用双向transformer编码器,不受窗口大小限制且可提取上下文语义信息,因此本文基于BERT预训练模型进行Embedding向量提取,为下游事件要素抽取提供基础,BERT模块结构图如图1所示。本文使用由Huggingface提供的bert-base-chinese作为BERT预训练模型,原因为该模型基于中文维基百科相关语料进行预训练,该训练语料与后续研究的由常见中文词语语料构成的中文突发事件CEC数据集具有较高相似性,预训练模型的泛化能力较好。由图1可知,对于给定的输入语句,BERT模块的输入可由四部分表示,分别为Token embeddings、Mask embeddings、Segment embedding、Start embedding、End embedding。Token embedding表示词向量,其中各个位置的值由Bert字典中该字符所在位置决定;Mask embedding用来指示各位置的值是否为填充值,1代表不为填充值;Segment embedding用于区分句子边界,同一句子中各个字符对应的值相同;Start embedding则用于表示要素的开始边界,End embedding则用于表示要素的结束边界。四部分的embedding结合后输入BERT模型中获取样本的特征Embedding向量作为后续模型的输入。
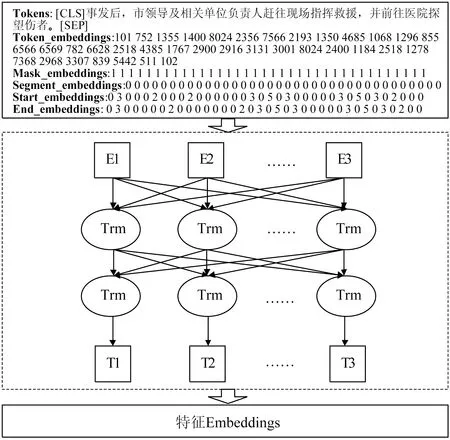
图1 BERT模块结构图
1.2 双向长短时记忆网络
循环神经网络(Recurrent Neural Network,RNN)在处理文本任务时,存在梯度消失的问题,且只能提取短期的文本信息,为解决上述问题长短时记忆(Long short-term Memory,LSTM)网络得以提出。LSTM的核心结构主要有输入门、输出门、遗忘门及记忆单元。LSTM模型的输出由输出门和记忆单元相乘得到,而输入门和遗忘门则用于提取有效信息,LSTM单元的计算公式如式(1)~(5)所示,但是LSTM模型无法同时捕获文本的上下文信息。
为解决LSTM存在的问题,本文采用双向长短时记忆(Bi-Directional Long Short Term Memory,Bi-LSTM)网络处理BERT模块产生的Embedding向量。Bi-LSTM算法的基本思想为对每个输入分别进行前向和后向LSTM。
it=σ(Wxixt+Whiht-1+WciCt-1+bi)
(1)
ft=σ(Wxfxt+Whfht-1+WciCt-1+bf)
(2)
Ct=ftCt-1+ittanh(WxCxt+Whcht-1+bc)
(3)
ot=σ(Wxoxt+Whoht-1+WcoCt-1+bo)
(4)
ht=ottanh(Ct)
(5)
式中:W为权重矩阵;b为偏置向量;σ、tanh为激活函数;i、f、o分别为输入门、遗忘门、输出门;C为记忆单元状态。
1.3 BERT-BiLSTM-CRF事件抽取算法
BERT-BiLSTM-CRF算法由BERT、BiLSTM、CRF三种算法组合而成。BiLSTM-CRF算法在事件抽取过程中相较于BiLSTM算法,通过CRF学习了输出标签的约束条件,使得输出标签组合更加合理。为进一步提升BiLSTM-CRF算法的事件抽取精度及缩短算法训练迭代周期,将BERT与BiLSTM-CRF算法进行组合形成BERT-BiLSTM-CRF算法,该算法增加前缀特征Embedding提取,其优势在于基于大量相关语料进行语义信息预学习,减少BERT-BiLSTM-CRF算法迭代周期且提升时间抽取精度,具体结构如图2所示。由CRF输出的状态转移矩阵可知,其中B-、I-、O为数据的标签,图表中数值的大小表示约束条件的强弱,由此可得下述BIO约束条件:
1)当前字标签为B-Time时,下一个字标签为I-Time的分数最高。
2)当前字标签为B-Location时,下一个字标签为I-Location的分数最高。

图2 BERT-BiLSTM-CRF事件抽取算法结构图
因此,可较为准确的提取除事件中的时间要素和位置要素,然而采用CRF算法作为算法后缀进行要素提取时,长序列要素提取存在要素断裂的问题。
2 基于指针网络的突发事件对抗学习算法
目前常利用BERT、BiLSTM、CRF三种算法进行组合的方式进行事件抽取,虽然BERT-BiLSTM-CRF算法可以较好地进行事件抽取工作,但其在抽取过程中仍然存在要素提取断裂、模型泛化能力弱的缺点。为解决上述问题,本部分提出融合对抗训练与标签平滑的BERT-BiLSTM-SPAN突发事件抽取方法。
2.1 指针网络SPAN
首先,利用SPAN指针网络取代CRF模型形成BERT-BiLSTM-SPAN模型,SPAN网络的作用在于减少事件抽取过程中要素断裂的情况,SPAN网络的结构如图3所示。BiLSTM序列输出作为SPAN网络要素“开始边界”网络层、要素“结束边界”网络层的输入;两个网络分别预测输入样本要素的开始边界与结束边界,如“开始边界”网络层输出中第一个“2”与“结束边界”网络层输出中第一个“2”代表提取出的事件参与者要素“市领导”。根据两个网络的预测结果进行BERT-BiLSTM-SPAN网络的总损失。
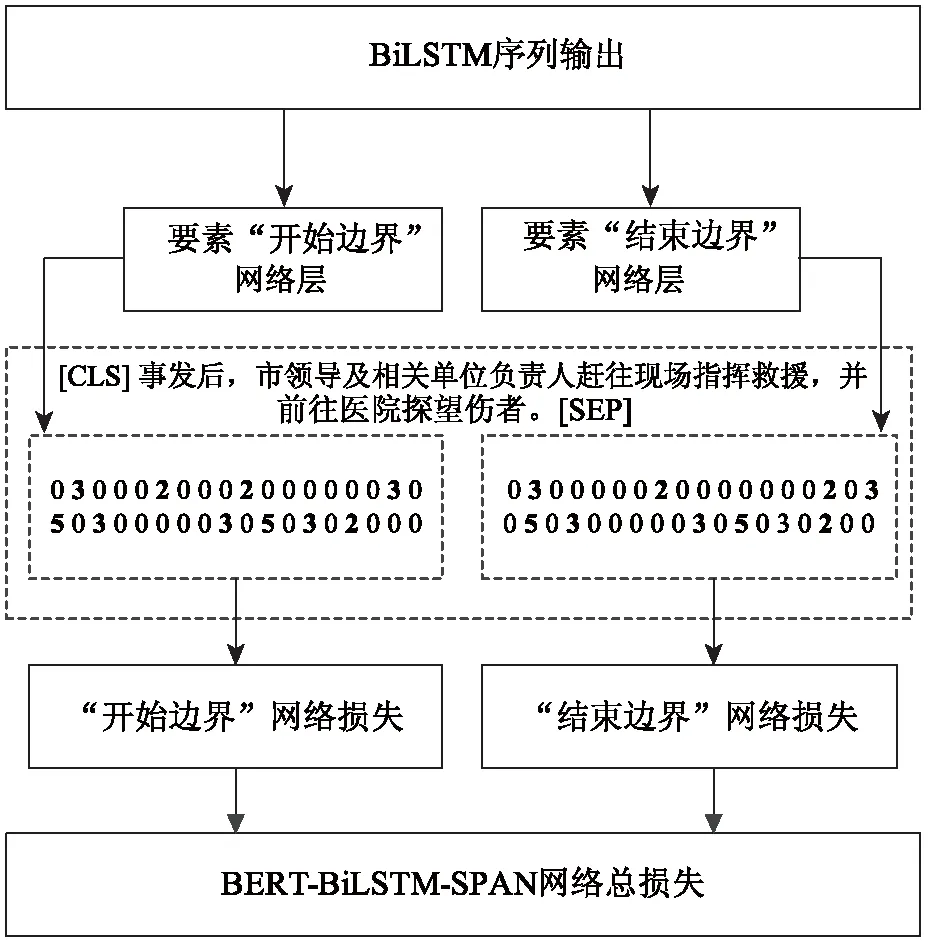
图3 SPAN网络结构图
2.2 对抗训练及标签平滑
在获取BERT-BiLSTM-SPAN网络后,通过增加对抗训练及标签平滑增加模型的鲁棒性及泛化能力。对抗训练的主要思想为通过向样本中增加扰动,使得模型面对具有扰动样本时仍具有正确识别能力,提升模型的防御力。本文利用快速梯度法(Fast Gradient Method,FGM)进行对抗训练,其主要利用的公式如式(6)~(7)所示,其中g为梯度,γadv为计算的扰动。
标签平滑的主要思想则为通过向样本中添加噪声,避免模型预测正负样本的差值过于巨大,防止过拟合,从而增加模型的泛化能力,其主要利用的公式如式(8)~(9),其中α为超参数,通常取0.1,K为类别种类数目,该公式通过减少各类别之间的差值增加模型的泛化能力。
g=xL(θ,x,y)
(6)
γadv=εg/‖g‖2
(7)
(8)
(9)
2.3 BERT-BiLSTM-SPAN突发事件抽取算法
基于指针网络的BERT-BiLSTM-SPAN算法整体结构如图4所示。

图4 融合对抗训练的BERT-BiLSTM-SPAN突发事件抽取方法总体流程图
该模型中输入为BIOS标注的句子,输出为该句子提取的要素边界,共包含四个模块,分别为BERT模块、BiLSTM模块、SPAN模块、对抗训练+标签平滑模块,其工作流程为:
1)CEC数据集进行BIOS打标处理,并加入[CLS]、[SEP]标志;
2)基于标注数据,利用预训练模型BERT进行Embedding特征提取;
3)基于Embedding特征,利用BiLSTM模型学习文本上下文信息;
4)基于BiLSTM输出,利用SPAN网络预测要素边界;
5)未达到迭代条件时,基于对抗训练及标签平滑对BERT-BiLSTM-SPAN网络进行迭代优化;
6)达到迭代条件时,获取最优突发事件要素提取模型;
7)当新的突发事件样本到来时,基于突发事件要素提取模型完成对该样本要素边界预测,提取各样本要素。
3 实验结果及分析
3.1 数据集
本文基于中文突发事件语料库(CEC)进行事件抽取。CEC数据集基于XML语言进行要素标记,其具体数据集格式如图5所示。CEC数据集中包含各类要素,本文着重提取其中五类要素,Denoter为事件指示词、Participant为事件参与者、Time为事件发生时间、Object为事件主体、Location为事件发生地点。根据CEC数据集XML标注格式,本文以BIOS标注体系为基础对CEC数据集进行打标,其中“B-”为要素信息起始字符标签,“I-”为要素信息内字符标签,“O”为非要素信息字符标签,“S-”为单字符要素信息标签。

图5 CEC数据集示例
3.2 评价指标
事件抽取的目的在于抽取各类事件中的关键要素,并采用严格的指标计算方式,即事件要素中所有字符完全抽取时才进行正确计数。本文采用精准率、召回率、F1进行指标评价。在CEC语料库中,要素抽取结果统计信息如表1所示。

表1 要素抽取结果统计表
设标准要素表为ST,提取出的要素集合为T,则被抽取出的要素个数如式(11)所示,准确率ρ、召回率R、F1的计算公式如式(12)~(14)所示。
(10)
(11)
(12)
其中α=|ST∩T|
(13)
3.3 实验结果及分析
3.3.1实验环境及参数配置
本实验使用Pycharm作为开发环境,操作系统为Linux 3.10.0,内存为128 G,硬盘12 T,Pycharm开发环境如图6所示。其中bert系列模型均在深度学习平台Pytorch中训练,实验中使用bert系列参数为Huggingface提供的bert-base-chinese预训练模型参数,具体如表2所示。

表2 模型参数配置
图6 pycharm登录及开发环境展示
3.3.2事件要素抽取
本部分将BERT-BiLSTM-SPAN事件要素抽取模型与当前广泛使用的抽取方法进行对比,如表3所示。BERT-BiLSTM-SPAN-ce算法将CRF部分修改为SPAN指针网络,损失函数使用交叉熵损失函数(ce);BERT-BiLSTM-SPAN-lsr算法则将损失函数修改为标签平滑损失函数(lsr);BERT-BiLSTM-SPAN-adv-lsr算法在前者的基础上融入对抗训练(adv)部分。
由表3可知,本文所提出的BERT-BiLSTM-SPAN系列算法在精准率、召回率、F1三个指标上均高于目前广泛使用的事件抽取算法,其中BERT-BiLSTM-SPAN系列算法较于BERT-BiLSTM-CRF算法在精准率、召回率、F1三个指标上分别平均提高5.02%、14.63%、9.80%。三类评价指标均大幅提升的原因在于SPAN指针网络可以更加有效的预测事件要素的边界,对要素进行提取,而BERT-BiLSTM-CRF算法在提取要素过程中存在事件要素断裂的情况。

表3 各算法实验结果对比
在BERT-BiLSTM-SPAN系列算法中,BERT-BiLSTM-SPAN-lsr算法精准率最高,相较于BERT-BiLSTM-SPAN-ce算法在精准率提升1.25%;BERT-BiLSTM-SPAN-adv-lsr算法在召回率、F1两个评价指标中最高,相较于BERT-BiLSTM-SPAN-ce分别提升4.80%、2.33%,指标提升的原因在于标签平滑损失函数(lsr)及对抗训练(adv)可有效降低模型过拟合,提升模型的泛化能力,即在未知样本上提取要素的能力。
为进一步验证本文所提事件抽取算法BERT-BiLSTM-SPAN-adv-lsr的性能,结合交叉验证从模型评价指标F1分数的显著性上进行分析。具体为采用 5折交叉验证法去计算两个模型预测结果的平均F1分数,并基于Z检验验证平均F1分数是否具有显著性差异,Z值结果如表4所示。当Z值大于小于1.96时,无明显差异;Z值大于1.96且小于2.58时,具有较为显著差异;Z值大于2.58时,具有显著差异,因此据表3~4可得,本文所提出的BERT-BiLSTM-SPAN算法相较于BERT-BiLSTM-CRF算法具有较为显著差异,即分类性能较为显著提升;相较于HMM、LSTM算法具有显著差异,即分类性能显著提升。
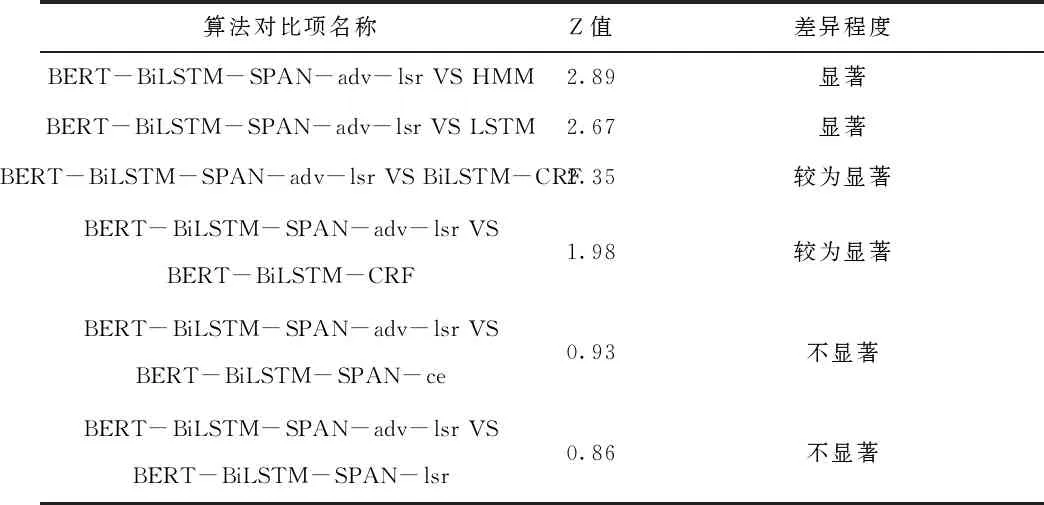
表4 算法性能显著性比较
由表3得,BERT-BiLSTM-SPAN-adv-lsr算法在事件要素抽取过程中整体性能最好,表5为该算法下各事件要素抽取的精准率、召回率、F1结果;表6为该算法及BERT-BiLSTM-CRF算法下要素识别示例对比。BERT-BiLSTM-SPAN-adv-lsr算法下“记者”、“罗甸县”、“发稿”三类要素则为模型识别的多余要素,“截至22时记者发稿时”要素未识别;BERT-BiLSTM-CRF算法下,“记者”、“罗甸县”、“发稿”三类要素则为模型识别的多余要素,“截至22时记者发稿时”、“罗甸县”要素未识别,且存在要素识别断裂现象,如“2时”、“车”、“甩”。因此,本文所提算法可有效解决要素提取断裂问题且泛化能力更强。

表5 各事件要素在算法BERT-BiLSTM-SPAN-adv-lsr下的提取效果
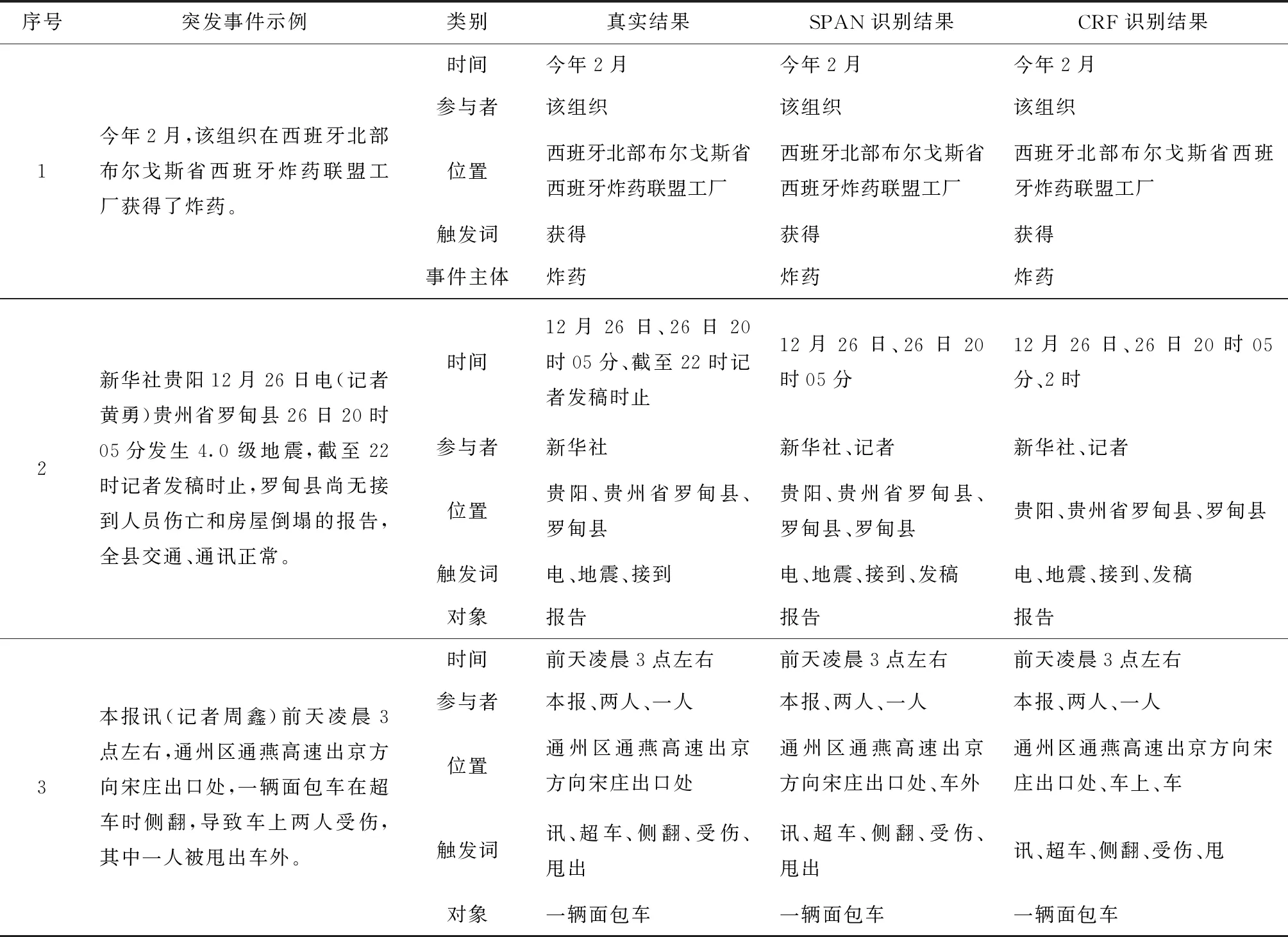
表6 BERT-BiLSTM-SPAN-adv-lsr、BERT-BiLSTM-CRF算法下预测示例
4 结 语
本文提出的融合对抗训练的BERT-BiLSTM-SPAN突发事件抽取方法,相较于传统的事件抽取方法,基于BERT预训练模型自动获取句子embedding特征向量,无需人为设计特征,利用SPAN网络解决要素抽取过程中要素断裂的问题,并且加入对抗训练及平滑标签增加模型的鲁棒性及未知样本的识别泛化能力。实验结果也验证了BERT-BiLSTM-SPAN方法的有效性。进一步工作拟完成词汇增强工作,进一步提升模型性能。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
当代水产(2020年4期)2020-06-16 03:23:30
车迷(2018年11期)2018-08-30 03:20:32
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
海峡姐妹(2018年3期)2018-05-09 08:21:02
现代园艺(2017年22期)2018-01-19 05:07:22
河北书画研究(2017年1期)2017-08-22 12:11:50
数学学习与研究(2017年3期)2017-03-09 18:12:42
公民与法治(2016年10期)2016-05-17 04:12:58
山东青年(2016年2期)2016-02-28 14:25:36
