
基于BERT和层次化Attention的恶意域名检测
2022-07-13 02:38魏金花
中国电子科学研究院学报 2022年3期
张 凤, 张 微, 魏金花
(银川科技学院 信息工程学院,宁夏 银川 750003)
0 引 言
恶意域名的变种随检测手段的丰富不断增多,现有恶意域名大多利用域名生成算法(Domain Generate Algorithm, DGA)、IP-Flux或Domain-Flux等技术随机大批量生成恶意域名[1-2],并具有很强的隐蔽性和潜伏性[3]。因此,如何准确地检测出潜在的恶意域名,提前封堵,阻断其进一步的攻击,已成为网络安全领域问题之一。
现有恶意域名检测方法根据技术手段可以划分为基于域名黑名单的恶意域名检测、基于深度学习的恶意域名检测等两大类[4-8]。其中,基于域名黑名单的恶意域名检测方法主要根据历史数据与待测域名之间的字符相似度来给出合法性的判断。如文献[9]提出了一种基于词法特征的恶意域名检测方法,通过计算待测域名与恶意域名黑名单上域名间的编辑距离,给出待测域名合法性的判断。文献[10]利用历史数据中域名的关联信息判断待测域名的合法性。文献[11]利用并行与串行相结合的方式对待测域名进行预测。文献[12]提出了一种分阶段的恶意域名检测算法,首先,利用历史数据对待测域名进行首轮过滤并构造待测域名集;然后,对待测域名集中的每一域名进行深层次、细粒度的分类。文献[13]利用历史数据作为引诱器来追踪难以正面检测的恶意域名,实时定位恶意域名的访问记录,进一步追踪家族恶意域名。该类恶意域名检测算法虽直接有效,但检测精度过度依赖历史数据,对新变种或新出现的家族恶意域名检测精度不佳。
近年来,随着深度学习和自然语言处理等技术在计算机视觉和文本分类等领域的广泛应用[14],利用深度学习和自然语言处理等技术解决网络安全问题也逐渐受到研究学者的广泛关注。如文献[15]提出了一种基于词素特征的轻量级域名检测方法,根据域名包含的词根、词缀、拼音和缩写等特征构造决策树,快速判断合法域名与恶意域名。文献[16]提出了一种基于深度学习的恶意域名检测算法,通过提取域名包含的解析特征、字符特征和访问记录等多维度特征,构造分类器,实现待测域名的判定。文献[17]利用机器学习算法有效解决了域名生成算法产生的批量恶意域名隐蔽性强,难以检测的问题。文献[18]提出了一种基于卷积神经网络(Convolutional Neural Network, CNN)与LSTM相结合的恶意域名检测算法,利用CNN和LSTM提取域名在空间和时序维度上的构词特征,并结合gram作出最终待测域名合法性的判断。文献[19]采用门控循环(Gated Recurrent Unit, GRU)型循环神经网络并结合注意力机制,提出了一种DGA域名检测算法ATT-GRU,有效解决了DGA算法生成的恶意域名隐蔽性强,导致难以检测的问题。该类检测算法可以较好地解决新变种或新出现家族恶意域名检测不佳的问题,但域名字符串本身携带的信息有限,如何细粒度的利用有限字符串中的字符或单词信息强化合法域名与恶意域名的分类精度,成为基于深度学习算法的恶意域名检测方法中亟待解决的问题。
针对上述问题,本文提出了一种基于BERT和层次化Attention的恶意域名检测模型。该模型首先通过BERT预训练自然语言模型生成包含上下文语义新的词向量矩阵;然后,利用两层双向长短时记忆神经网络Bi-LSTM分别获得整条URL和包含单词的特征表示,并在整条URL中引入全局Attention机制,在所含单词中引入局部Attention机制,通过计算字符串中字符或单词的贡献程度,强化待测域名的分类效果;最后,利用Softmax分类器给出恶意域名的判断。
1 算法设计
本文提出的一种基于BERT和层次化Attention的恶意域名检测模型主要包括预训练BERT语言模型、Bi-LSTM构造和Attention机制引入等模块。
1.1 预训练BERT语言模型
BERT是2018年谷歌公司提出的一种自然语言处理模型,近年来被广泛地应用于自然语言处理(Natural Language Processing, NLP)任务中[20]。BERT模型结构如图1所示。图中,domaini={s1,s2,…,sn}表示域名domaini包含的单词,通过预训练的多层双向Transformer编码器生成对应的词向量矩阵Vi={v1,v2,…,vn}。
本文使用的BERT利用双向Transformer编码器来提取域名字符串中的字符特征表示。Transformer架构如图2所示。
图2中所示的Transformer编码器是基于自注意力机制的Seq2Seq模型,仅利用自注意力机制解决了传统CNN与RNN存在的时序和空间维度不兼顾的问题,同时强化了对于序列特征的位置信息建模的能力[21]。由于自注意力机制并不具备对位置信息的建模能力,而域名字符串等文本内容对于上下文信息等序列性特征要求较高[20]。因此,在模型编码阶段引入位置编码(Position Encoder, PE)。即将域名字符串经过位置编码后作为多头自注意力机制的输入,从不同层次、不同角度获取域名的字符特征信息。此外,为了加速模型收敛,采用残差结构规避信息记忆误差。

图2 Transformer结构
1.2 Bi-LSTM
合法域名与恶意域名在字符组成和结构等方面存在较大差异,且不同家族的恶意域名结构也有所不同[22];此外,域名在构造规则和字符组合等方面相对自由,但在字符与字符组合上仍存在上下文依赖关系[22]。因此,本文利用双向长短时记忆神经网络(Bi-directional Long ShortTerm Memory, BiLSTM)提取域名的上下文信息。BiLSTM模型是由两个LSTM网络通过上下叠加构成,如图3所示。

图3 Bi-LSTM网络结构
图3中,domaini={s1,s2,…,sn}表示域名集合中的第i个域名,首先利用BERT中的Transformer Encoder将domaini中的字符sj转换为字符向量v(sj),并将sj组成的域名映射为矩阵Vi,其中Vi={v(s1),v(s2),…,v(sn)};然后对域名矩阵Vi利用BiLSTM进行上下文特征提取,计算公式为
(1)
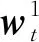
1.3 Attention机制
受人脑资源分配的启发,文献[23]提出了一种注意力机制Attention,通过聚焦重要性特征,弱化边缘信息的原理提高对重点区域的关注度。本文利用注意力机制计算域名字字符串所包含的单词和字符之间的重要性特征。Attention机制的结构如图4所示。

图4 Attention机制
Attention机制具体计算公式为
ei=μiδ(wizi+bi)
(2)
(3)
式中:ei表示zi的能量因子;y表示注意力机制的输出值;δ为tanh函数;μi和wi分别表示权重系数;zi表示隐藏层的初始状态;bi表示偏置。
1.4 恶意域名检测
恶意域名检测整体流程如图5所示。

图5 恶意域名检测流程
(1)输入层:将域名字符串转换为Bi-LSTM能够接受的序列向量。本文从360NetLab、Malware Domain List、Alexa和安全联盟等国内外各大网站上收集与整理合法域名和恶意域名,并去除域名中的顶级域名、协议等,提取二级、三级、四级等域名级,构造合法域名样本集和恶意域名样本集。
假设域名domaini由n个单词组成,即domaini={d1,d2,…,dn};每个单词d由m个字符组成,则第t个单词dt可以表示为dt={s1,s2,…,sm}。通过预训练的BERT自然语言模型可以获取每个字符的词向量表示。
(2)特征提取层:完成字符和整条URL的字符特征表示。
1)将经过BERT向量化后的每个字符si作为Bi-LSTM的输入,提取字符深层次特征。计算如公式(1)所示。
2)将步骤1)的输出作为局部Attention机制的输入,提取每个单词上下文信息中贡献值最大的字符特征。首先,借鉴文献[12]利用自然语言处理模型N-Gram滑动取词的方式,构造长度为l=[α-Δ,α+Δ]的滑动窗口,其中,α表示随机选择的中心字符,Δ为设定的窗口大小。根据公式(4)~(6)计算每个滑动窗口内中心字符与其余字符之间的相似度,并根据相似度值给每个字符赋予权重wi。
α=k·σ(pe1(x,y)δ(pe2(x,y)ht))
(4)
(5)
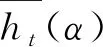
Wt=∑t,ihtwi
(6)
3)将步骤2)计算获得的Wt作为Bi-LSTM的输入,提取每个单词的深层特征表示,计算如公式(1)所示。并引入全局Attention机制对Bi-LSTM提取的特征进行强化,细粒度的提取贡献值最大的特征。计算公式为
hst=δ(wstht+bst)
(7)
(8)
式中:wst表示权重矩阵;bst表示偏置;δ表示tanh函数;hst表示的ht的隐藏层表示;Ds为随机初始化的上下文序列矩阵。
(3)输出层:利用Softmax分类器进行合法域名与恶意域名的分类。
p=soft max(wΠ+b)
(9)
式中:Π为t时刻特征提取层的深层特征表示;w为权重值;b为偏置。
2 实验与分析
2.1 实验环境与数据集
采用Pytorch框架,开发语言为Python 3.7,测试平台为Pycharm;设定多头个数为12。
从Alexa、Fofa、Malware Domain List和360NetLab等数据集中整理获得36.8万条域名。其中合法域名13.8万条,恶意域名23万条,按照7∶3划分为训练集与测试集。数据集信息如表1所示。

表1 数据集描述
2.2 评价指标
为验证本文算法的有效性,查准率Precision、查全率Recall、误报率FPR和F1分数进行评价。具体计算如公式(10)~(13)所示。其中,Precision和FPR验证模型的可信度;Recall验证模型的漏报情况;F1验证模型的综合表现,分数越高,模型检测性能越好。
(10)
(11)
(12)
(13)
式中:tp表示准确检测出的恶意域名总数;tn表示准确检测出的合法域名总数;fp表示将合法域名误报为恶意域名的总数;fn表示将恶意域名漏报为合法域名的总数。
2.3 多家族恶意域名检测结果与分析
为验证本文模型在多家族恶意域名数据集上的检测性能,分别在360Netlab包含的23种家族恶意域名和Malware Domain List(MD)数据集上进行测试验证,检测结果如表2所示。
由表2可知,本文算法在多家族恶意域名数据集上的检测性能表现良好,其中可对18种家族恶意域名保持查准率在96%以上,平均查准率为96.49%;17种家族恶意域名保持查全率在96%以上,平均查全率为96.27%;平均误报率为3.90%;F1-Score为94.13%。究其原因是本文模型采用双向长短时记忆神经网络Bi-LSTM可以有效捕获上下文语义信息,此外,局部和全局Attention机制可以对特征权重重新分配,凸显重要特征的决策能力,进一步提升模型对多家族恶意域名的泛化性能。

表2 多家族恶意域名检测结果 %
2.4 同类相关工作对比
(1)误报结果与分析
为验证本文模型的误报情况和查全率等的综合表现,采用受试者工作曲线(Receiver Operating Characteristic, ROC)曲线进行评估,其中ROC曲线中曲线下面积(Area Under Curve, AUC)越大,表明模型检测性能越好。图6给出了本文模型与当前主流恶意域名检测模型在相同的数据集下的ROC曲线。

图6 ROC曲线对比图
由图6可知,本文模型的AUC值最大,为99.17%,较对比模型中表现最高的文献[27]和文献[12]的AUC值分别提高约1.79%和4.05%,有效提高了多家族恶意域名检测的表现性能。
(2)综合性能对比
为验证本文模型与当前主流算法在综合检测性能方面的优势,在相同的评价指标下进行测试验证,不同模型的检测性能对比如表3所示。

表3 不同模型检能对比 %
由表3可知,虽文献[27]在查准率方面可达到96.63%的精度,文献[18]在F1-Score方面表现最佳,为94.66%,但本文模型在查全率和误报率方面优势明显,分别可以达到96.27%和3.90%,综合性能优势显然。
对比本文算法和文献[12,25]方法可知,根据单一或部分字符特征的组合决策能力尚不足以对域名生成算法或域名随机变换等技术产生形式多样的家族恶意域名进行高效检测;对比本文算法与文献[8,18,24,26,27]方法可知,层次化的Attention机制可以加强模型对于字符等序列特征的关注度,通过细化域名字符和单词对于检测特征的贡献度,提高模型对于合法域名与恶意域名的决策能力,验证了本文模型的设计初衷。
3 结 语
本文综合考虑检测性能,从域名字符和单词等层次化结构角度进行研究,提出了一种基于BERT和层次化Attention机制的恶意域名检测算法。该模型首先通过BERT生成包含上下文语义信息的词向量矩阵;然后,通过两层Bi-LSTM获得字符和单词表示,并分别引入局部注意力和全局注意力机制,强化字符或单词对于模型决策的能力。实验也验证了本文模型的综合检测性能。在僵尸网络、垃圾邮件等恶意域名防范工作中具有一定的实际应用价值。
猜你喜欢
汉字汉语研究(2020年2期)2020-08-13
江苏教育研究(2020年2期)2020-04-10
阅读(快乐英语高年级)(2020年8期)2020-01-08
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
智慧少年·故事叮当(2018年11期)2018-05-14
小学生时代·大嘴英语(2014年9期)2014-11-04
互联网天地(2012年6期)2012-03-24
海外英语(2006年8期)2006-09-28
