
基于图表示的智能车行人意图识别方法
2022-07-13 02:18吕超崔格格孟相浩陆军琰徐优志龚建伟
北京理工大学学报 2022年7期
吕超,崔格格,孟相浩,陆军琰,徐优志,龚建伟
(1. 北京理工大学 机械与车辆学院, 北京 100081;2. 上海汽车集团股份有限公司技术中心, 上海 201804)
行人是重要的交通参与者,其个体行为将对本车产生较大影响,对其意图的实时识别是智能车在城市驾驶环境的重要任务. 研发智能系统用于识别驾驶场景中的行人的过街意图,可以有效减少自动驾驶系统的冗余操作,在关键时刻正确发出碰撞预警警报. 随着机器视觉技术的进步,研究人员通过对驾驶场景中行人表现出的包括头部朝向变化[1]、肢体姿态变化[2]等在内的行为动作进行分析,对其过街意图进行识别或预测. 研究人员采用HOG 特征描述子、光流法等,对上述行人动作进行识别与表征.最近,人体姿态估计(human pose estimation)工作的不断发展为行人意图识别提供了更多的行人姿态信息,其骨架识别结果包含丰富的行人空间位置信息.FANG 等[3]通过分析骨骼节点之间的角度、距离等空间几何特征,对行人过街意图做出判断. 该方法在构造分类特征时,仍选择以特征向量的形式对行人信息进行表述,不能充分考虑行人动作序列在时间尺度与拓扑结构中所蕴含的丰富信息. FRANCESCO等[4]提出一种融合系统框架,通过对标注框及行人姿态估计信息进行预先融合对行人意图进行分类,综合考虑了时间空间尺度下行人的特征,但该框架缺乏对人车交互关系等隐含信息进行的充分表征与进一步挖掘. 图结构数据包含复杂网络结构及多样化节点信息,是构造和建模复杂数据的有效工具,而图表示学习(graph representation learning, GRL)是实现图信息挖掘任务的基础,所得特征将对算法实验结果产生重大影响. 近期,研究人员针对行人意图识别与行为预测开发了许多图表示学习方法,在这些方法中,图被用于描述和分析行人姿态在空间与时间尺度上的变化. PABLO 等[5]基于二维姿态识别信息与图神经网络对行人过街意图进行预测,形成预测和识别行人行为的有力工具.
本文针对城市交通环境下主车第一视角的行人数据,提出基于图模型的行人特征提取与意图识别方法框架,如图1 所示. 首先提出提取行人模型图数据特征的方法. 从骨架节点中选取用于动作表征的关键点,并将其建模为图模型节点,分别构建骨骼自然连接、骨骼拓扑关系连接及关节点时间尺度连接3 种连接关系,将其建模为图模型的边. 将姿态估计二维骨架节点位置坐标信息、主车与行人之间的距离以及主车车速建模为节点属性特征向量,通过具有属性的节点和连接边的形式,充分表征可用于判断行人过街意图的特征标识与人车交互关系,进一步提高模型真实性与可解释性,提高对行人过街意图判断的准确性. 其次,采用图分类方法构造行人意图识别模型. 基于图核方法(graph kernel method)对图数据之间的相似性进行度量,产生用于显示实例对之间相似性的核矩阵,将核矩阵嵌入基于核的机器学习模型中构造分类器,本文利用支持向量机(support vector machine, SVM)模型构建用于行人意图识别的分类器.
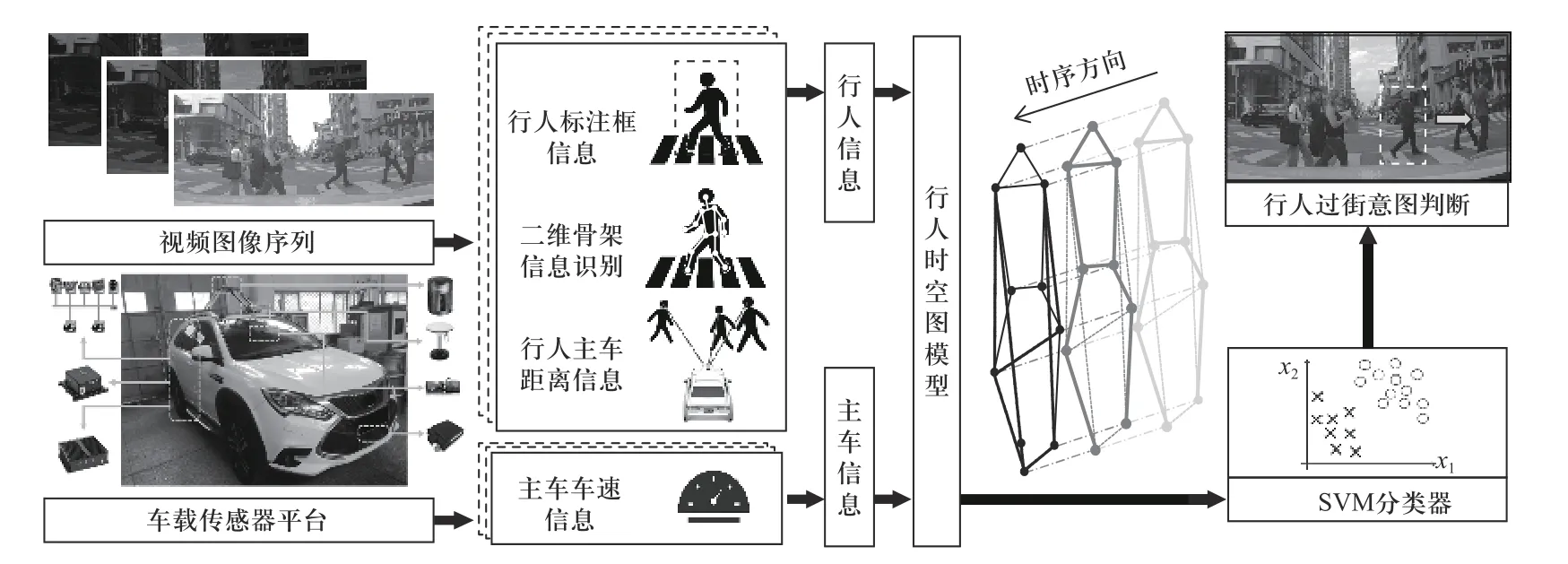
图1 基于图表示的行人意图识别方法框架Fig. 1 Framework of pedestrian intention recognition method based on graph representation
1 基于图表示的行人模型构建
1.1 行人时空图模型构建
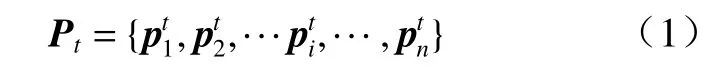
式中:t表示当前时刻;n为当前帧图像中可实现姿态识别行人总数;p为包含17 个节点二维像素坐标系坐标的34 维向量,第i个行人的节点坐标向量可以表示为
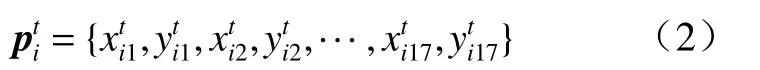
将所获取的行人骨架节点像素位置坐标向量进行重新整理获取坐标元组向量序列结构为
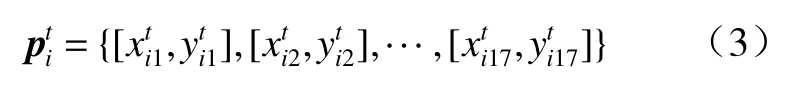
以便后续形成序列时提取节点坐标特征.
为简化基于图表示的行人模型,降低计算复杂度,进一步对姿态识别结果进行关键点选取. 由于动态特性及局部遮挡关系不同,不同的人体骨架关节点的识别稳定性与定位准确性存在明显差异,对全部关节点识别精度进行统计,选取精度高,稳定性好,且与人体姿态及意图判断的关联性强的节点作为后续构建图模型的关键点,如表1 所示,关键点编号如图2(a)所示. 其中,髋关节、膝关节与踝关节的坐标变化可以标志意图运动的起始与终止,鼻、肩关节与膝关节坐标及其变化可以标志人体朝向与实际运动方向.
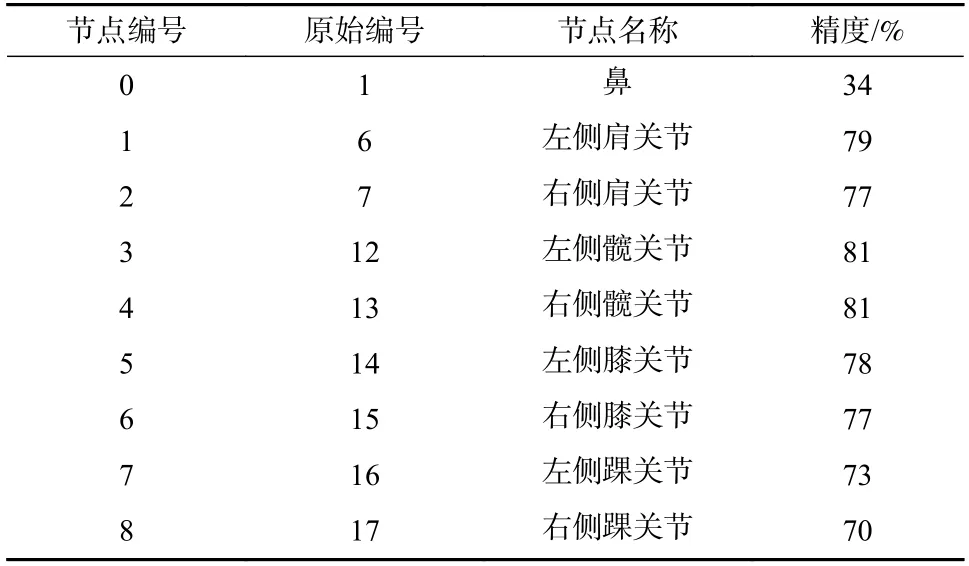
表1 行人骨架关键节点定义表Tab. 1 Definition table of key nodes of pedestrian skeleton
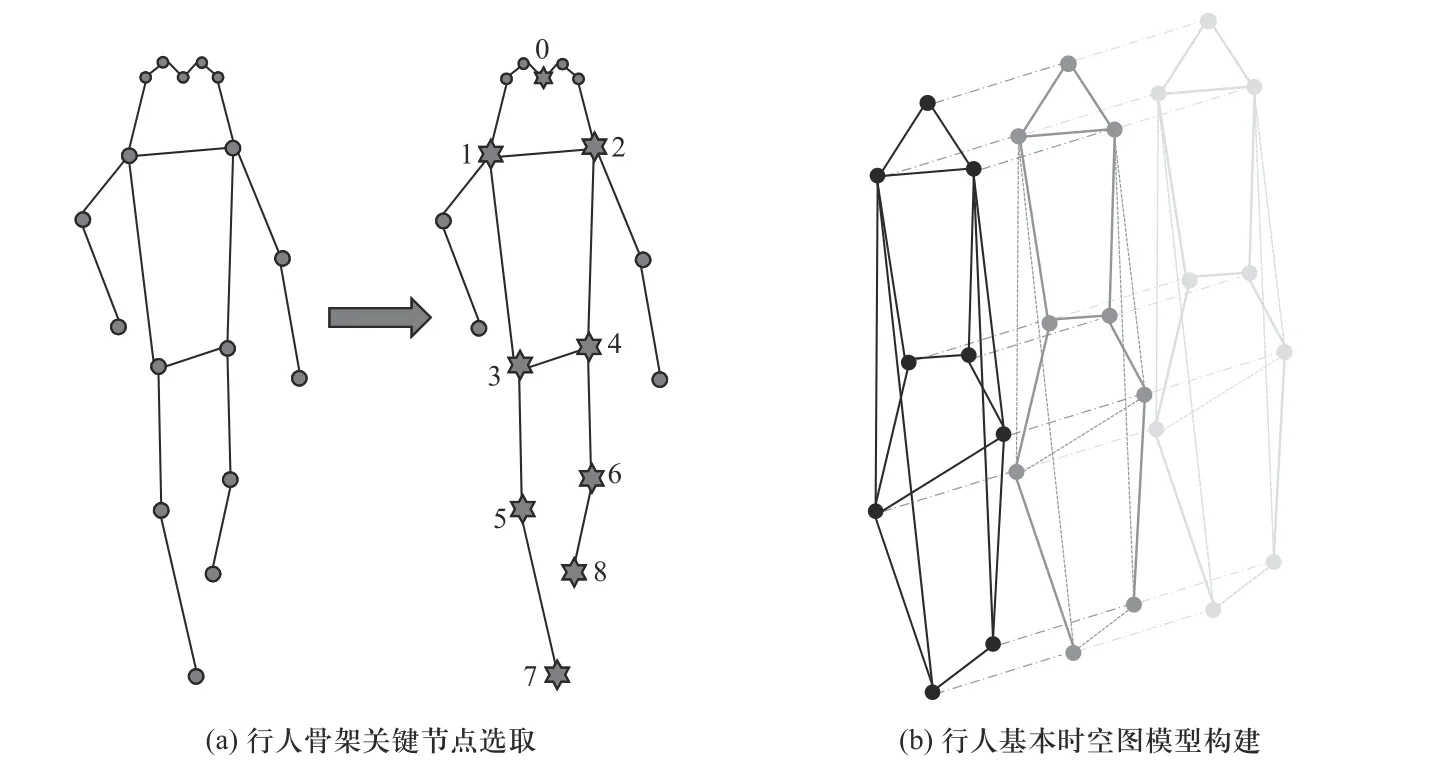
图2 行人时空图模型构建示意图Fig. 2 Diagram of the construction of pedestrian spatio-temporal graph model
基于上述骨架信息,利用采样长度为T帧、关键点总数为N的目标行人骨架信息所形成的序列定义无向图G=(V,E),构建行人时空图模型. 其中,V={vti|t=1,2,···,T,i=1,2,···N}为图中节点集合,包含长度为T的骨架信息序列中的全部节点,E为图中边集合,两节点之间具有边连接表示节点之间存在联系,本文对行人时空图模型中边的定义分层次进行,如图2(b)所示. 若第t帧第i个和第t′帧第j个节点之间存在边,记该边为e=(vti,vt′j). 首先,将同一帧图像内目标行人的全部骨架关键点按照人体自然骨骼连接情况进行连接以建立边,如边(vt1,vt2)所示,其次,在具有运动拓扑关联的骨架关键点之间建立边,如边(vt5,vt6)所示,最后,对同一目标行人对象在连续帧图像中具有相同节点名的骨架关键点进行连接以建立边,如边(vt1,v(t+1)1)所示. 综上所述,行人时空图模型边集合E由两个子集构成,边两端节点在同一帧图像中的边构成一个子集EI={(vti,vt j)|(i,j)∈PI},其中PI表示同一帧内全部人体自然骨骼连接对以及具有运动拓扑关联骨架关键点对的集合;边两端节点同名并在连续两帧内的边构成一个子集EE={(vti,v(t+1)i)},该集合内的边可以表示相应节点在所定义时间序列内的位置变化情况,包含了所选关键节点的轨迹信息.
1.2 行人时空图模型特征序列构建
行人时空图模型构建的关键技术在于观测特征的选取,即对图模型中节点进行标签或属性分配,以更直观的表述节点之间的联系,使模型对行人过街意图识别精度更高. 上述过程可以由属性分配函数进行定义,从离散的属性集合中为图模型的不同节点分配属性. 记图模型节点属性分配函数为f:V∪E→RD,其主要包括3 个模块:基于二维骨架节点信息的行人运动属性、行人与主车距离属性以及行人运动瞬时对应的主车车速属性.
1) 行人运动属性.
通过信息化系统,将项目建设中分散在个人手中的涉及财务、采购、招标、技术、申报、批复等资料,进行统一管理,并与项目建设同步,形成电子化档案库和目录,解决项目中资料归档问题,提高项目档案管理水平。

2) 行人与主车距离属性.

3) 主车车速属性.

2 基于图模型的行人意图识别
2.1 基于图核方法的图相似性度量
度量图之间的相似性是基于图的结构分析的关键步骤之一,而图核对结构化数据具有强大而灵活的表示形式,不仅能描述研究对象的特性,还能反映不同构成组分之间的结构信息. 使用图核方法(graph kernel method)将图的内积投影到高维希尔伯特空间中,是目前该问题最受欢迎的解决方案之一. 图核方法定义的特征空间及其内积投影过程如图3 所示.
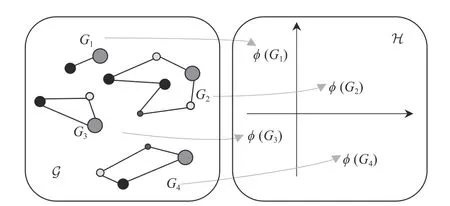
图3 图核方法内积投影示意图Fig. 3 Diagram of inner product projection of kernel method
图核方法是基于核函数的数据处理方法,通过核函数对所有输入数据对之间的相似性进行度量.核函数的选取是核方法应用中的关键,决定了不同图核之间的差异,体现在其比较和搜索图中组成部分的策略不同,以及对成对组成成分的具体比较方法的不同. 尽管不同内核在细节上各具特色,但他们都可以产生一个表征所有实例对之间相似性的核矩阵. 核矩阵可以嵌入基于核的机器学习方法中,如支持向量机(support vector machine,SVM),从而构建分类器实现识别或预测.
2.1.1 基于图信息传播策略的传播图核


2.1.2 基于嵌套子图结构的多维放缩拉普拉斯图核

第一步,将每个节点表示为一个分量对应于置换不变的局部顶点特征的D维向量,通过执行线性变换,将每个图表示为所选特征的分布,定义广义特征空间拉普拉斯图核为

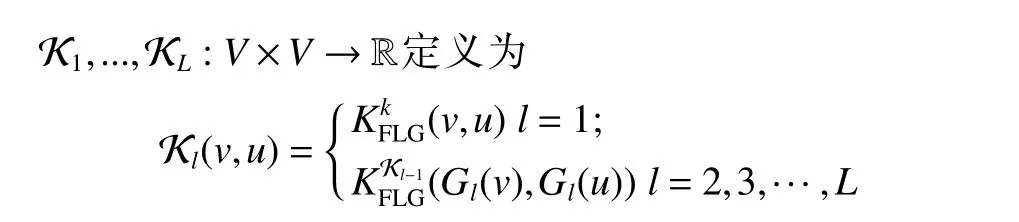
则两图之间多维放缩拉普拉斯图核定义为
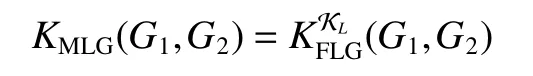
2.1.3 基于最短路径比较的图跳跃图核

2.2 基于SVM 的行人意图识别

其中,参数C用于控制式中由第一项决定的模型复杂度与第二项决定的经验风险之间的平衡.
3 实验验证
3.1 数据集与评价指标
PIE 数据集[9]常用于行人行为与意图的研究,画面尺寸为1 20×1 80像素,采样频率为30 Hz,不包含姿态骨架节点信息,包含具有行为意图标注的行人共1 840 个,其中898 人具有过街意图但未通过,512 人具有过街意图并通过,430 人无过街意图. 为验证基于图表示的智能车行人意图识别方法,本文使用PIE数据集对识别模型进行训练与测试,采用准确度、F1分数、精确度和回召率对行人意图识别结果进行评估.
3.2 数据预处理
本文关注基于骨架信息的时空图构建与行人意图识别问题. 首先将图像分辨率重新设置为960×540像素,利用PifPaf 工具逐帧对视频图像序列的中所有无显著遮挡的行人进行姿态估计,并提取所选关键节点在像素坐标系中的坐标. 然后从视频图像序列中截取目标行人从出现到消失的完整序列,依据采样长度T对序列进行裁剪,进一步构建行人时空图模型. 由于PIE 数据集存在的行人样本数量较少的问题,在截取视频序列后,对其以1 帧为间隔在时域上连续采样. 经过处理,从数据集中提取出2 100具有过街意图但未通过的行人样本序列,1 733 个具有过街意图并通过的行人样本序列,1 417 个无过街意的图行人样本序列.
3.3 实验与结果分析
3.3.1 实验设计
首先,为评价模型中不同信息的作用,比较不同节点属性特征选择策略对行人意图识别效果的影响,以及分析图核选择对行人意图识别效果的影响,本文在PIE 数据集上开展行人意图识别的实验. 通过设置不同节点属性特征组合,开展销蚀实验,本节共设置了3 组节点属性特征组合:(1)仅节点像素坐标系位置坐标(x,y);(2)节点像素坐标系位置坐标及主车行驶速度(x,y,veh_OBD_speed);(3)节点像素坐标系位置坐标、主车行驶速度以及以行人头部节点位置为基准计算主车视角下的人车相对距离以及主车行驶速度(x,y,veh_OBD_speed,d). 对于每组节点特征属性组合策略,分别使用3 种可以对具有连续节点属性的图模型进行处理与相似性验证的图核进行高级特征提取. 其次,为展现本文方法的有效性,并验证使用图模型的必要性,选取基于利用骨架节点坐标位置信息直接计算传统几何特征的方法作为基准方法,基于高斯核构建的SVM 多分类器(惩罚系数设置为c=0.8),与基于多放缩拉普拉斯图核的图分类器进行对比.
3.3.2 实验结果分析
在设置销蚀实验的基础上,本文选用传播图核、多维放缩拉普拉斯图核以及图跳跃图核进行对比测试,对所获取的全部样本,以5-折交叉验证的方式确定训练集与测试集,采样长度设置为T=18. 实验以p表示利用姿态识别算法获取的行人骨架信息,d表示利用原始图像与标注框信息定义的图上行人与主车的像素距离信息,veh_s表示车载传感器所获取的主车速度信息. 以GH、PK 以及ML 分别表示图跳跃图核、传播图核以及多放缩拉普拉斯图核,实验结果如表2 所示.
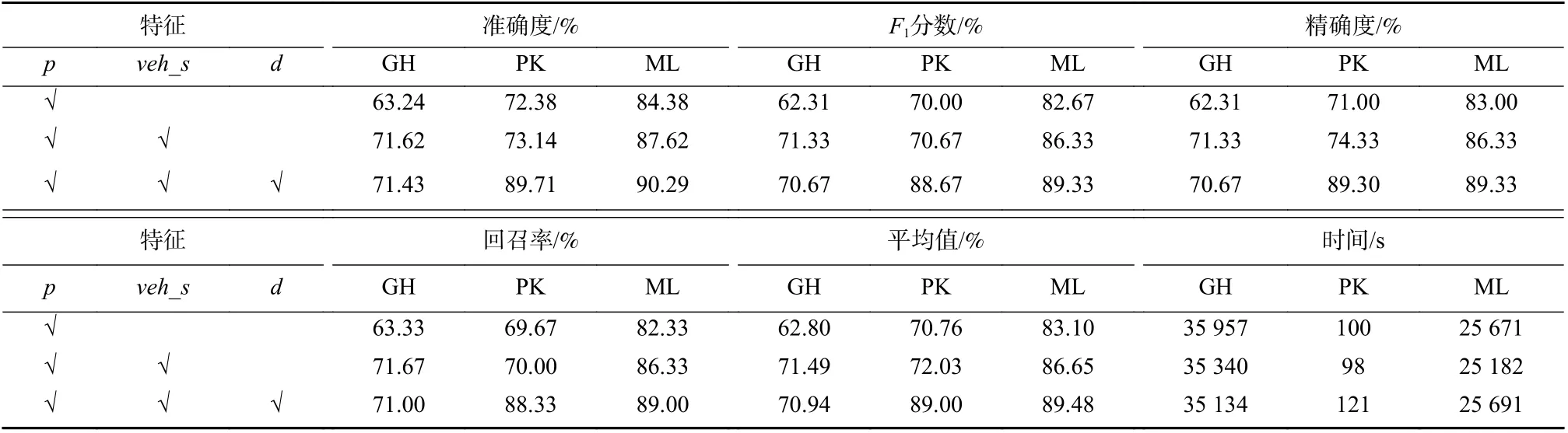
表2 基于图表示方法的行人意图识别模型销蚀实验Tab. 2 Abation experiments of pedestrian intention recognition model based on graph representation method
由表2 中实验结果可知,当只采用骨架关节点坐标特征作为分类依据时,基于图跳跃图核、传播图核以及多放缩拉普拉斯图核的图分类器所得行人过街意图的正确识别率分别为63.24%、72.38%及84.38%,其中,基于多放缩拉普拉斯图核的图分类器所得识别结果准确率最高仍不足85%. 识别准确率较低的可能原因为单一特征通常在分类识别任务中所呈现的一定程度的不稳定性. 在基于行人姿态对行人过街意图进行识别的基础上,通过增加图模型节点特征,结合主车行为及人车距离进一步分析,评价不同信息的作用. 以基于多放缩拉普拉斯图核的图分类器为例,通过添加主车车速特征,行人过街意图识别正确率提升至87.62%,通过综合行人姿态、主车车速特征以及行人与主车在图像中的像素距离特征,行人过街意图的识别正确率进一步提升至90.29%.可以看出,行人的行为动作为判断行人过街意图提供主要信息,同时,处在行人周边环境中的主车的车速及主车与行人之间的距离特征可以作为对行人过街意图判断的重要补充,与使用单一特征参数相比,能够在一定程度上提高识别结果的准确性.
当前很多研究通过直接分析行人姿态判断其是否有过街意图,未充分考虑行人动作在时间和空间的综合变化特征. 本文采用基于图表示的方法综合考虑行人的时空变换特征,结合车速、人车距离对行人过街意图进行判断. 绘制分类结果所得混淆矩阵图,如图4 所示,在考虑行人行为、车速及人车距离的情况下,对具有过街意图但未通过、具有过街意图并通过以及无过街意图的行人意图判断的准确率分别可达96%、87%和85%,而基准方法的意图判断准确率为65%. 可以看出,与基准方法相比,基于图表示方法的行人过街意图识别模型的正确率更高,表现出更优的效果.
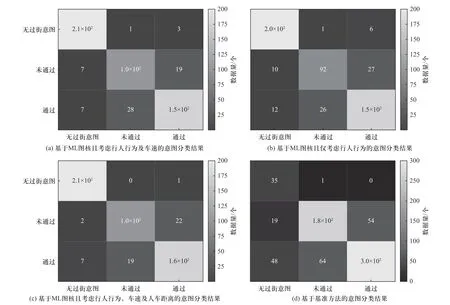
图4 分类结果混淆矩阵分析图Fig. 4 Confusion matrix analysis of classification results
在实验中,行人骨架姿态识别的准确性直接决定了行人特征图方法表征的准确性,从而对行人过街意图的判断产生影响. 选取PIE 数据集中的6 组行人样本,3 组行人具有过街意图并通过,2 组行人无过街意图,1 组行人具有过街意图但未通过. 在观察采样时间内,行人的骨架姿态识别结果如图5(a)所示,行人在主车第一视角下的位置与尺度变化,及过街意图识别结果如图5(b)所示.

图5 行人过街意图判断结果示例Fig. 5 Examples of pedestrian crossing intention classification results
在姿态识别算法中,骨架关节点检测结果受人车距离、交通环境的光线、遮挡、尺度变化、目标对象运动状态等因素的影响,存在误检或漏检的情况.在图5(a)中,以矩形框标示出对骨架关节点检测失败案例,在多人场景及目标对象产生明显动作变化的场景中,由于行人间遮挡与自身肢体运动交错的影响,无法准确地检测骨架关节点,可能对行人过街意判断结果产生影响. 在过街意图识别结果示意图中,图像为相应行人动作序列的最后一帧所对应场景,通过姿态识别结果序列对图结构数据中的节点与边要素进行可视化,构成采样时间内行人在主车视角下的姿态变化轨迹. 在图5(b)中,左图为3 个具有过街意图并通过的行人样本,右图上方为两个无过街意图的行人样本,下方为一个具有过街意图但未通过的行人样本,在图中分别绘制其姿态轨迹,颜色由浅至深表示行人随时间变化相对于主车的运动方向. 图像中央粗箭头表示主车行驶方向,白色细箭头表示具有过街意图并通过的行人的实际运动方向.从图中可见,当行人在一个完整动作序列中始终具有明显腿部动作变化或在垂直于主车行驶方向有明显位移时,行人表现为具有过街意图且正在穿越;当行人行为在接近动作序列结尾时趋于不变,行人表现为等待车辆通过.
4 结 论
本文提出一种基于图表示方法的智能车行人意图识别方法,用于判断行人的过街意图及穿越行为.该方法针对城市交通环境下主车第一视角的行人数据,利用姿态估计算法从视频截取片段中获取骨架信息数据,基于骨架关键点建立图模型节点与边,将行人骨架关键点位置坐标、与主车距离等特征的建模为节点属性,构建行人时空图模型. 通过引入图核方法对行人时空图模型进行高级特征提取,充分表征交通场景中行人的机构信息与人车交互关系,在此基础上训练基于SVM 行人意图识别模型,实现对目标行人对象的意图判断. 本文在自动驾驶数据集PIE 上对所提出方法进行评估,结果显示,行人过街意图分类准确率可达90.29%,所提出方法能够有效识别行人过街意图,能够应用于智能驾驶车辆的ADAS 系统,为自动驾驶提供更加丰富的决策依据,对提高智能车决策安全性具有重要意义.
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
电子乐园·上旬刊(2022年5期)2022-04-09
意林(2021年5期)2021-04-18
发明与创新·大科技(2020年6期)2020-06-22
扬子江(2019年1期)2019-03-08
农业工程技术·温室园艺(2017年3期)2017-07-13
小天使·一年级语数英综合(2017年6期)2017-06-07
诗选刊(2015年4期)2015-10-26
电影新作(2014年5期)2014-02-27
阅读(中年级)(2009年11期)2009-04-14
