
基于多尺度标签传播的小样本图像分类
2022-07-12 02:44田晟兆陈端兵
计算机研究与发展 2022年7期
汪 航 田晟兆 唐 青 陈端兵,3,4
1(电子科技大学大数据研究中心 成都 611731) 2(中国石油西南油气田分公司通信与信息技术中心 成都 610051) 3(成都数之联科技股份有限公司 成都 610041) 4(四川省社会科学数字文化与传媒重点研究基地 成都 611731)
随着科技的不断发展以及大数据时代的到来,深度学习(deep learning)[1]作为机器学习领域中的一个重要分支,在技术层面上得到了快速发展,并在人工智能领域取得了重大突破,尤其是在计算机视觉[2]、语音识别[3]、文本分类[4]以及对抗博弈[5]等方面取得了巨大的成功.一般来说,深度学习的成功归因于3个因素:强大的计算资源(GPU,TPU)、先进的模型算法(卷积神经网络[2])和大型数据集(ImageNet[6],Pascal-VOC[7]).然而在某些特定的应用场景,例如医疗、军事[8]和金融等领域,由于隐私、安全性等原因,不太可能获得大量数据,即使存在大量数据,在对数据进行有效标注时将耗费大量人力、物力,无法获取足够的带标签的训练样本.在数据样本较少时,深度学习容易产生过拟合.与之相反,人类可以在数据样本较少的情况下快速学习新事物.例如:一个孩子从未见过斑马,但如果给他看过1张或几张斑马的照片后,当他去动物园看到真正的斑马后,可以马上认出动物园里的斑马是他曾经在图片上见到过的“斑马”.这就是人类与机器的区别,人类可以通过一组非常少的样本学习新事物,但机器需要大量的实例来学习事物特征.因此,如何利用少量样本,使深度学习模型能够有效学习和泛化,让机器学习的性能更加接近人类思维,成为目前深度学习领域中亟待解决的问题,该问题被称为小样本学习(few-shot learning, FSL).
为了解决小样本学习这一难题,研究人员提出了多种方法,这些方法大致分为2类:度量学习和元学习.一般来说,度量学习[9-17]是学习成对的相似性度量S(·),在这种度量下,相似的样本对具有较高的得分,不相似的样本对具有较低的得分;元学习[18-24]主张跨任务学习,并且所有任务均遵循相同的任务范式,通过在不同任务上学习后适应新任务,即在任务层面进行学习而不是在样本层面,并且学习与任务无关的模型,而不是特定于任务的模型.其中,度量学习可看作是元学习的一种特殊形式,通过元学习跨任务的形式进行相似性度量,使度量结果可以在不同的任务之间传递,并且2类方法都在小样本图像识别领域取得了不错的成果.但这些方法主要关注关系度量、外部知识转移和优化表示等,并没有解决小样本图像识别的根本问题:低数据(low-data),即缺少足够的训练样本或特征.为解决低数据问题,Liu等人[25]提出了标签传播网络(transductive propagation network, TPN),通过直推式学习方法假设查询集(未标记数据)为测试数据,并且将支持集和查询集数据通过嵌入网络映射到向量空间,计算其相似度,将标签从支持集传播到查询集,该方法为使用直推式学习的方法.随后Li等人[13]提出了深度近邻神经网络(deep nearest neighbor neural network, DN4),通过比较图像与类别之间的局部描述子(local descriptor)来寻找与输入图像最接近的类别,将其作为查询样本的标签.Xue等人[14]提出了区域比较网络(region compare network, RCN),学习支持集和查询集图像中相互关联的特定区域用于识别查询集的类别.Wang等人[15]提出了基于特征融合和加权多尺度决策网络(multi-scale decision network, MSDN),利用多尺度度量信息,通过投票对查询集进行分类;Chen等人[16]提出多尺度自适应任务注意机制网络(multi-scale adaptive task attention network, MATANet),通过生成不同尺度上的多个特征查看整个任务的上下文,学习不同尺度上与任务相关的局部特征,通过相似度量模块获得查询集分类结果.Yu等人[17]提出的回溯网络(looking-back network),通过在特征提取网络中利用其多层内部特征捕获其他信息,提高预测性能.在标签传播算法方面,Liu等人[25]开创性地提出了标签传播网络算法用于将支持集样本之间的相似度传播到查询集样本;Yu等人[17]在文献[25]的研究基础上,利用浅层卷积层提取的特征进行标签传播,但其传播的分类结果仅用于更新模型权重,并没有将其作为分类结果中的一部分,无法衡量浅层特征对分类结果的重要性.在多尺度算法方面,Li等人[13]认为将1张图片的特征信息压缩到1个特征图会损失许多有区分度的信息,即将1张图片通过卷积神经网络获得的表示图片的3维特征向量(C,H,W)进行flatten操作,其中C表示通道数,H表示高度,W表示宽度,用C×H×W个1×1的小特征图表示图像会丢失许多图像信息,而采用多个局部描述子可以有效避免信息丢失问题,因为每一个局部描述子都充分利用多尺度通道信息,即将图像特征reshape为(H,W,C)后,共有H×W个C维局部描述子用于表示图像特征.Xue等人[14]借鉴局部描述子的思想,通过对不同图像之间局部描述子的相似性比较获得相似性得分,从而推断数据类别.尽管局部描述子在通道上增加了对特征的度量,但其仅是在一个尺度大小上通过利用多通道信息,其分类结果仍具有一定偏差.而Wang等人[15]同样利用浅层卷积层提取的特征进行相似性度量,并将每一个浅层度量结果与深层度量结果结合,通过投票策略获得最终分类结果,但通过分析发现,往往深层特征的度量结果在投票中会占据主导地位.Chen等人[16]通过设计深层多尺度提取器提取多组深层特征,用多组深层特征度量取代浅层特征度量,并通过1维卷积自适应融合方式融合多组深层度量结果,获得最终分类结果,有效提高了分类准确率.
通过文献[13-17,25]的分析可以发现,小样本学习可以通过附加信息(即多尺度信息)缓解低数据带来的问题.目前常用的多尺度信息仅通过特征提取器中浅层卷积获得,该信息仅包括图像的浅层信息(如边角、纹理、颜色等),即目前大多数方法仅通过特征提取器中的不同卷积层获得多尺度的附加信息,该附加信息与深层信息相比,其无法表达特定图像复杂的特征.为了更好地获得图像的深层特征,并将深层特征用于相似度计算并与标签传播算法相结合,本文以标签传播算法为基础,提出了基于多尺度标签传播网络(multi-scale label propagation network, MSLPN)的度量学习模型,利用多尺度生成器生成不同尺度的特征,捕获多尺度附加信息,缓解低数据问题.具体而言,首先,通过多尺度生成器生成不同尺度的图像特征;其次,计算在各个尺度上的特征与特征之间的高斯相似度,并利用该多尺度度量信息进行标签传播,获得不同尺度下的标签传播分数;再次,集成不同尺度下的标签传播分数获得最终的标签传播分数和分类结果;最后,所有训练参数都通过反向传播进行端到端的更新.
本文的主要贡献包括3个方面:
1) 提出了一种新的度量学习方法,利用多尺度生成器生成不同尺度的特征,即从不同粒度上捕获图像的内在特征.与现有研究中仅通过特征提取器获得的特征相比,多尺度特征能从不同角度对支持集和查询集数据进行相似性度量.
2) 采用类似于关系网络[12]的度量模块对特征相似度进行度量,即在场景训练的过程中通过神经网络学习的方式进行相似性度量.该方式不仅能更好地适应小样本图像分类中的不同任务,还可以将其作为一个用于衡量样本与样本之间相似度的特定模块,取代传统的距离函数(如余弦距离、欧氏距离等)相似性度量方法.
3) 利用多尺度信息的标签传播结果,通过简单的加权计算方式获得最后的标签传播分数及分类结果.分类效果优于已有算法结果.
1 相关工作
1.1 基于度量学习的方法
在小样本学习中,度量学习的通用方法是在特征嵌入空间中,通过相似性度量模块对支持集和查询集的特征嵌入进行相似性比较,其中,相似性度量模块只要能够估计样本或特征之间的成对相似度即可.一般的相似性度量模块可以是简单的距离函数度量、复杂的网络度量或其他可行的度量方法.Koch等人[9]提出孪生神经网络(siamese neural network),通过共享权重的卷积神经网络度量样本之间的相似性,用于解决one-shot问题,该网络是将深度神经网络引入小样本学习的研究.Vinyals等人[10]提出匹配网络(matching network),通过使用不同的长短期记忆网络(long short term memory, LSTM)对支持集和查询集进行编码,并使用基于注意力的加权度量函数度量特征之间的相似度.Snell等人[11]提出原型网络(prototypical network),其核心观点为每个类别的数据在嵌入空间中都存在一个特征向量原型(类别中心点),通过计算支持集的特征均值来学习嵌入空间,以获得每类的原型表示,利用距离函数计算查询集与原型的距离获得分类结果.Sung等人[12]提出关系网络(relation network),采用可学习的卷积神经网络度量特征相似性,取代传统的非参数度量方法.文献[9-12]所提的方法都是基于图像级的特征计算,而Li等人[13]提出的深度最近邻网络、Xue等人[14]提出的区域比较网络、Wang等人[15]提出的多尺度决策网络、Chen等人[16]提出的多尺度自适应任务注意机制网络、Yu等人[17]提出的回溯网络,均表明丰富的低维特征比图像级特征具有更好的特征表示能力.
1.2 基于元学习的方法
元学习的主要思想是通过合理利用已有的知识或经验,指导模型在新任务中更快、更准确地学习.Santoro等人[18]提出基于记忆增强的神经网络LSTM模块和神经图灵机来控制网络与外部存储模块的交互,解决单样本学习问题.Finn等人[19]提出未知模型元学习算法(model-agnostic meta-learning, MAML),通过跨任务训练策略找到神经网络中对每个任务损失较为敏感的初始化参数,使基学习器能够利用少量的支持样本快速适应新任务类别.Ravi等人[20]采用优化的方法,利用基于LSTM的元学习器作为优化器来训练另一个分类器,帮助分类器学习一个较好的初始化参数,使模型能在新的小样本数据上快速收敛.Shyam等人[21]提出了一种基于注意力机制的循环神经网络来实现样本间的动态比较.Mishra等人[22]提出软注意力机制的时序卷积网络,将模型看到的所有任务存储到记忆模块中,即聚集先前看到的信息,最终通过该记忆模块精确定位特定信息并获得分类结果.
尽管基于度量学习和元学习的方法已经取得了突出的效果,但依旧存在一些不足.例如,在度量学习中,仅考虑任务中的每一个查询集样本和每一类支持集的关系,并没有考虑每一个查询集样本和每一个支持集样本的关系;而在元学习中,其复杂的记忆结构很难训练,训练过程复杂.与这些方法相比,本文提出的MSLPN算法,不仅能度量每一个查询集样本和支持集样本之间的相似度,而且还能在多个尺度上进行度量,充分获得图像的低维信息,并且该网络以端到端的方式进行训练,最后对不同尺度的多个相似度结果进行综合分析得到最终的分类结果.
2 多尺度标签传播算法
2.1 问题定义
目前,小样本学习通常采用元学习训练策略,即跨任务训练机制,每一个任务称为元学习任务并且遵循相同的训练范式N-wayK-shot.具体来说,元学习数据集分为基类数据和测试数据.基类数据中包含了很多类别,每个类别中有多个样本,并且基类数据不包含测试数据(即测试数据和基类数据类别不相交),且每类测试数据中仅包含几个样本.在训练过程中,从基类数据中随机抽取N个类别数据,并且每个类别仅有K个样本,这些样本构成一个元学习任务,作为元学习器(模型)的支持集输入,随后再从选定的N个类的剩余样本中抽取部分样本,作为元学习器的查询集输入(即预测样本).小样本学习的目的就是如何从一系列不同的元学习任务中进行学习,使元学习器学会如何区分这N个类别,并对查询集数据进行预测.在测试过程中,测试数据同样也分为支持集和查询集,通过将其输入元学习器对其查询集图像进行分类.
支持集S、查询集Q和元学习任务T分别定义为:
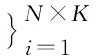
(1)
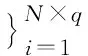
(2)
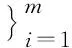
(3)
其中,xi和yi分别表示图像及其对应的标签,N表示图像类别个数,K表示支持集中每个类别包含的图像个数,q表示查询集中每个类别包含的图像个数,m表示元学习任务的个数.
2.2 多尺度标签传播网络
本文提出的多尺度标签传播网络如图1所示.该网络由5个部分组成:1)特征提取模块用于学习输入数据的局部特征表达;2)多尺度生成模块用于生成不同尺度的多组特征;3)关系度量模块用于度量不同尺度下的支持集和查询集的相似度;4)标签传播模块用于计算不同尺度下查询集图像的预测结果;5)分类策略模块是对不同尺度的标签传播结果进行综合计算获得查询集分类结果.其核心在于多尺度生成模块、关系度量模块和分类策略模块,其中多尺度生成模块用于生成不同尺度的图像特征,每个尺度的特征都能单独表示其提取图像的特征,并且能从不同粒度上反映图像的内在特征.通过多尺度生成模块,能获得更多的用于表示图像的特征来增加特征样本量,缓解低数据问题.而关系度量模块是对不同尺度的特征进行相似性度量,将多尺度生成模块获得的不同尺度的特征输入对应尺度大小的关系度量模块中获得相似性得分.关系度量模块能从不同尺度上反映查询集样本和支持集样本之间的相似度,并且每一个尺度的相似性得分结果均对最终的分类结果有一定影响.因此,分类策略模块通过加权计算方式获得最后的标签传播分数及分类结果,即融合多个尺度的预测分数,平衡不同尺度之间的预测结果,使预测正确的得分较高而预测错误的得分相对较低,并且该结构的输入是支持集和查询集的联和输入,即Input=Ti.
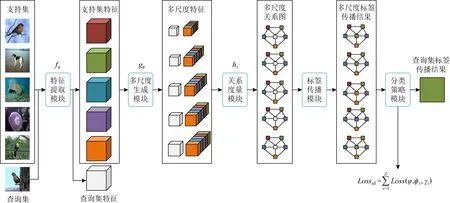
Fig. 1 Multi-scale label propagation network model (5-way 1-shot)图1 多尺度标签传播网络模型(5-way 1-shot)
2.2.1 特征提取模块
为了与目前最先进的方法进行比较,本文采用常用的4层卷积模块作为特征提取器.如图2所示,每一层卷积模块由卷积层(卷积核大小为3×3,通道数为64)、BatchNorm层和LeakyReLU非线性激活层组成,并且在前2个卷积模块中的激活层后增加2×2大小的最大池化层.
单张图片通过特征提取模块,可获得一个3维的特征向量fφ(xi)∈C×H×W.在本文中,将支持集和查询集同时输入特征提取器,可获得4维特征向量,其定义为fφ(S∪Q)∈(N×K+N×q)×C×H×W,其中,C表示通道数,H和W分别表示输出特征的高和宽.

Fig. 2 Feature extractor图2 特征提取器
值得注意的是,本文提出的方法是与体系结构无关的,即特征提取器可以是其他类型的网络结构,如ResNet-12[20].
2.2.2 多尺度生成模块
多尺度生成器是MSLPN的关键模块,该模块的目的是生成不同尺度的多组特征,其输入为特征提取模块的输出.本文提出的多尺度生成器借鉴Chen等人[16]的多尺度生成模块,如图3所示.该模块包含5个子模块:第1个模块对输入不做任何处理,直接将输入作为输出,保留原始特征信息;第2个模块为卷积模块,该模块卷积核大小为3×3,通道数为64;第3个模块为卷积模块,该模块卷积核大小为5×5,通道数为64;第4个模块为2层卷积模块,卷积核大小分别为1×7和7×1,通道数均为64;第5个模块为2×2大小的最大池化层.
单张图片通过多尺度生成模块,可生成5组不同尺度的特征向量gφ(fφ(xi))∈Cz×Hz×Wz,z∈{1,2,3,4,5}.在本文中,通过多尺度生成模块,可获得4维特征向量gφz(S∪Q)∈(N×K+N×q)×Cz×Hz×Wz,z∈{1,2,3,4,5}.
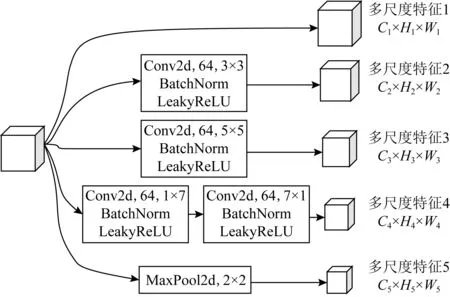
Fig. 3 Multi-scale generation module图3 多尺度生成模块

Fig. 4 Multi-scale relational network architecture图4 多尺度关系网络结构
2.2.3 关系度量模块
在标签传播网络TPN[25]中,该文作者在关系网络[12]的基础上提出了一种新的成对的相似性度量函数,其通过关系网络计算获得尺度参数,用于构建合适的相似度邻居图.
本文采用的策略与TPN类似,但本文中的关系度量模块不是单一的,而是多尺度的关系度量模块.因为不同尺度的特征嵌入的维度和信息内容是不同的,采用分尺度的关系度量模块可得到不同尺度下的尺度参数和特征相似度矩阵,使后续的标签传播可在不同尺度上同时进行,从而提升最终的分类效果.本文相似性度量函数定义为
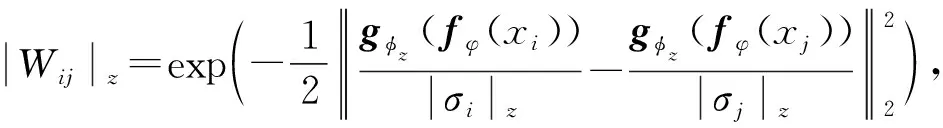
(4)
其中,|Wij|z∈(N×K+N×q)×(N×K+N×q)表示在尺度z下样本xi和xj的相似度,gφz(fφ(·))为尺度z下的样本特征,|σ|z为尺度z下的尺度参数,该参数通过对应尺度z的关系网络计算获得.多尺度关系网络结构如图4所示,该模块同样由5个子模块组成,每个子模块的输入为对应多尺度生成模块不同尺度的输出,且每一个子模块结构都是2层卷积模块(包括卷积层、BatchNorm层、LeakyReLU非线性激活层和最大池化层)和2层全连接层(神经元个数分别为8和1).值得注意的是,尺度参数是通过跨任务机制训练获得的,可很好地适应不同的任务,并且该关系网络结构可修改为其他类型的网络(多尺度关系网络结构中每一个子模块都是单独的卷积神经网络和全连接层,子模块参数之间不进行权值共享).
通过多尺度关系网络和相似性度量函数计算获得不同尺度下的相似性度量矩阵Wz后,与TPN设置相同,保留相似性度量矩阵中每一行前k个最大值来构造k-最近邻图(本文中k=20).随后,对该近邻图进行拉普拉斯正则化,获得最终的相似性度量矩阵Lz,即Lz=Dz-1/2WzDz-1/2,其中,Dz为对角线矩阵,其对角线元素(i,i)为Wz的第i行元素的和.
2.2.4 标签传播模块
在构建好不同尺度下的相似性度量矩阵后,通过标签传播算法[26]计算不同尺度下查询集样本的预测标签分数.
一般的标签传播定义为:令Y0∈(N×K+N×q)×N为初始化标签矩阵,当且仅当样本xi属于支持集且其标签yi=j时否则即初始化标签矩阵中只包含支持集样本标签,而没有查询集样本标签.随后,从初始化标签矩阵开始进行迭代标签传播,传播公式为
Yt+1=αLYt+(1-α)Y0,
(5)
其中,Yt为对应时间戳t的预测标签分数,L为正则化的相似性度量矩阵,α∈(0,1)控制传播的信息量,本文中α=0.99.并且,式(5)可近似化为闭合形式的解:
Y*=(I-αL)-1Y0,
(6)
其中,Y*为最终的预测标签分数,I为单位矩阵.
2.2.5 分类策略模块
本文通过最简单的分数加权方式,将标签传播模块得到多尺度下的预测标签分数进行加权,获得最终的预测分数.其目的是融合多个尺度的预测分数,平衡不同尺度之间的预测结果,使预测正确的得分较高而预测错误的得分相对较低.该加权方式为
(7)
并且最终的分类结果通过Softmax函数获得:
(8)
而损失函数为不同尺度下的交叉熵损失和:
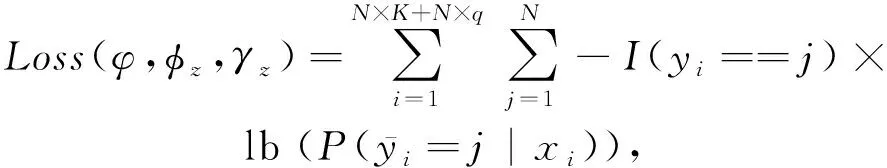
(9)
(10)
其中,I(·)表示推断函数,当且仅当条件为真时,I(·)=1,否则I(·)=0,yi表示样本的真实标签值,而φ,φz,γz分别表示特征提取模块、多尺度生成模块和多尺度关系度量模块中可训练的卷积神经网络参数,所有的这些参数都是通过跨任务训练并且以端到端的形式进行更新.
3 实验和分析
本文用2个经典的数据集miniImageNet和tieredImageNet对MSLPN的效果进行了测试,并和其他先进方法进行了对比分析.我们的实验源码可在https://github.com/wanghang-97/MSLPN获得.
3.1 数据集
数据集基本情况如表1所示:

Table 1 Basic Information of the Data Set表1 数据集基本情况
数据集miniImageNet作为ImageNet的一个子集,共包含100个类,每个类有600张图片.为了和其他小样本学习方法进行比较,本文同样根据Vinyals等人[10]提出的数据集分割方式将该数据集划分为64类训练集、16类验证集和20类测试集,并且所有的图片大小均调整为84×84.
与miniImageNet相似,数据集tieredImageNet同样是ImageNet的一个子集,但它拥有更多的类,并且具有更广泛的类别层次结构.该数据集共有34个大类,608个小类,共779 165张图片,可将其划分为20个大类训练集(共351个小类,448 695张图片)、6个大类验证集(共97个小类,124 261张图片)和8个大类测试集(共160个小类,206 209张图片).该数据集通过层次划分后,其训练集、验证集和测试集在语义上完全不同,该数据集在小样本学习中更具挑战性.同样,该数据集中所有图片大小也调整为84×84.
3.2 实现过程与实验设置
本文所有实验均在Ubuntu19.10系统, TITAN RTX(24 GB) GPU,PyTorch(1.5.1)深度学习框架环境下运行.
网络参数具体设置在2.2节进行了详细描述,本文在训练和测试阶段均按照标准的元学习跨任务机制,即在训练和测试的每一个任务中数据严格按照N-wayK-shot形式.具体来说,对3.1节所提的数据集均采用5-way 1-shot和5-way 5-shot的形式.在训练过程中,从训练集中随机抽取210 000个任务,每个任务为1个mini-batch,并且每100个任务作为一个Epoch,共2 100个Epoch,即训练次数为2 100次.利用跨任务机制训练MSLPN模型,并且每个5-way 1-shot(5-way 5-shot)任务中,除了每个类的1(5)张图片外,还会从每个类别中剩余图像中选取15(15)张图片作为查询集.即对于一个5-way 1-shot任务,在每一个训练集中将会有5张支持集图像和75张查询集图像.在测试过程中,从测试数据集中随机抽取600个任务,以Top-1的平均准确率作为评价标准,重复10次,并报告最终的平均精度.
在训练时,使用Adam优化器,初始学习率为0.001,其余参数为默认值,即betas=(0.9,0.999),eps=1E-08,weight_decay=0,amsgrad=False.对于miniImageNet数据,每训练10 000个任务后,即训练100次后,学习率降低一半;对于tiered-ImageNet数据,由于该数据集规模较大并且类别复杂,每训练25 000个任务即训练250次后,学习率降低一半.
值得注意的是,本文提出的MSLPN方法是以端到端的形式进行训练,不需要在测试阶段微调.
3.3 实验结果与分析
我们对提出的MSLPN方法与当前基准度量学习和元学习方法进行了比较,包括Matching Network[10],Prototypical Network[11],Relation Network[12],DN4[13],RCN[14],MSDN[15],MATANet[16],Looking-Back[17],TPN[25],MAML[19],Meta-Learner LSTM[20],SNAIL[22],并且所有的小样本学习方法的特征提取部分均是4层卷积神经网络,如本文2.2.1节所述.
遵循3.2节实验设置的描述,本文考虑5-way 1-shot和5-way 5-shot这2种设置进行比较,准确率为600个任务场景的平均值,并且置信区间为95%,在miniImageNet和tieredImageNet数据集上实验结果分别如表2和表3所示:
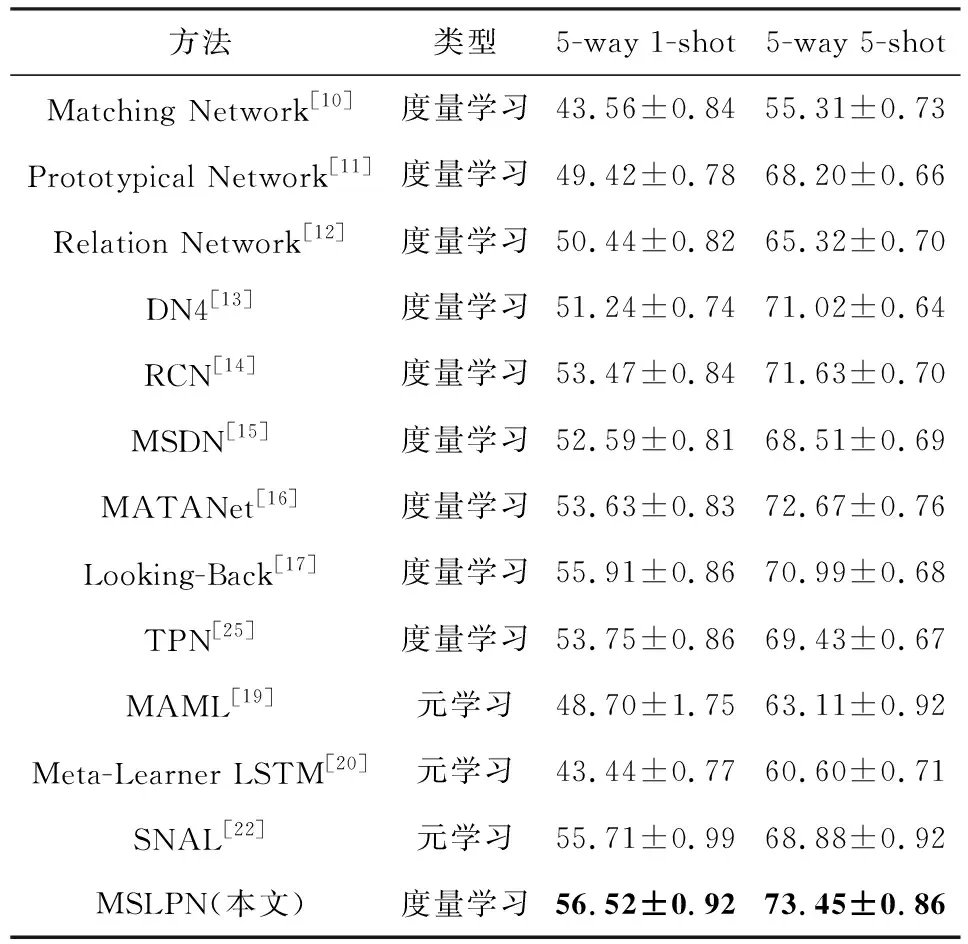
Table 2 Comparison of miniImageNet Experimental Results表2 miniImageNet实验结果对比 %
信区间的置信度;黑体数值表示最好的实验结果.
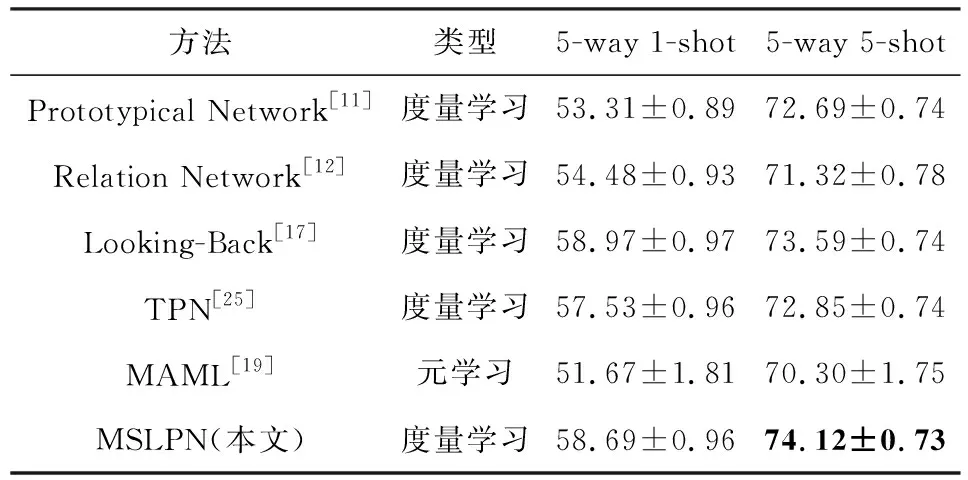
Table 3 Comparison of tieredImageNet Experimental Results表3 tieredImageNet实验结果对比 %
信区间的置信度;黑体数值表示最好的实验结果.
从表2和表3中可以发现,本文提出的多尺度标签传播算法在5-way 5-shot情况下,与所有基准方法相比,在2个数据集上均取得了最好的结果,并且与标签传播算法TPN相比,准确率分别提高了4.02%和1.27%,与Looking-Back方法相比,准确率分别提高了2.46%和0.53%;而在5-way 1-shot情况下,在miniImageNet数据集上,与所有基准方法相比,取得了最好的结果,与标签传播算法TPN相比,准确率提高了2.77%,与Looking-Back方法相比,提高了0.61%.而在tieredImageNet数据集上,其准确率超过了除Looking-Back方法外的所有基准方法,与标签传播算法TPN相比,准确率提高了1.16%.通过分析可知,本文提出的算法充分利用多尺度功能获得图像的低维信息,不仅能够解决图像低数据问题,而且还能使模型在不同尺度下获得有利于图像分类的有效特征信息,并且通过多尺度模块提取的特征在不同数据集中仍然具有较强的表示能力;同时,与已有算法相比,通过多尺度模块提取的图像低维信息,对于体积小且易混淆的物体能够捕获丰富的细节信息;并且,通过多尺度标签传播模块和加权分类策略获得的标签得分,不仅能够融合多个尺度的预测分数,还能平衡不同尺度之间的预测结果,使分类结果更加精确.因此,本文提出的模型可以获得更高的识别精度.
4 结论与展望
本文提出了一种基于多尺度标签传播网络(MSLPN)的小样本图像识别方法.该方法通过多尺度生成模块捕获输入数据不同尺度的局部描述信息,着重强调可学习的深度局部描述信息即数据的低维信息,通过该信息丰富图像特征,解决小样本低数据问题,提高预测准确率.本文结合标签传播算法,利用多尺度信息,通过加权形式获得最终的预测标签分数.在miniImageNet和tieredImageNet数据集上均获得了很好的结果,与TPN相比,在数据集miniImageNet上,5-way 1-shot和5-way 5-shot设置中的分类准确率分别提高了2.77%和4.02%;而在数据集tieredImageNet上,5-way 1-shot和5-way 5-shot设置中分类准确率分别提高了1.16%和1.27%.通过对实验结果的分析,本文提出的多尺度生成模块在小样本图像分类算法的度量学习方向能有效解决小样本低数据问题,提高预测准确率.在未来的小样本研究中,在获取图像特征时,仍然可以利用多尺度生成模块,通过提取不同尺度的图像特征来表示不同粒度的图像内在特征,不仅可以丰富图像特征,还能有效解决低数据问题.除此之外,受多尺度生成模块的启发,还可以从多维度的度量学习方法入手,通过集成不同的度量学习方法,修改分类策略模块,以简单的加权分类策略为基础进行扩展,设计灵活的度量学习模块和分类策略模块,提高分类准确率.
因此,未来工作展望主要分为3个方面:
1) 利用注意力机制替换简单的加权分类策略,研究每一个尺度下的局部信息对分类结果的影响;
2) 利用集成学习的思想,集成不同的度量学习方法,提高分类准确率;
3) 利用卷积图神经网络设计更高效的标签传播算法.
作者贡献声明:汪航提出算法主要研究思路和实验方案,完成实验并撰写论文;田晟兆完成文献调研、实验改进和论文修改;唐青负责实验实现和论文修改;陈端兵提出论文修改思路,指导论文写作,参与论文校对.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
上海文化(文化研究)(2022年3期)2022-06-28
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国信息化周报(2015年1期)2015-04-09
