
基于复数帧段特征的语音情感识别方法∗
2022-07-10 02:16:22张霞杨勇赵力
电子器件 2022年2期
张 霞 杨 勇 赵 力
(1.莆田学院机电与信息工程学院,福建 莆田 351100;2.东南大学信息科学与工程学院,江苏 南京 210096)
在日常生活中,语音是人类进行交流的重要媒介,语音信号在传达语句含义信息的同时,也传递了情感信息。同样一句话由于说话人表达的情感不同,听话者感知时就会有较大的语义差别。要想进一步提高人机交互能力,实现真正意义的人工智能,就需要赋予计算机像人一样地观察、理解和生成各种情感特征的能力,使计算机能够更加自动适应操作者[1]。过去的研究者在进行语音信号处理时,把语音中这部分信息作为噪声通过规则化处理给去掉了。随着近年来对情感识别研究的深入,研究者逐渐意识到这些情感信息的重要性,开始进行专门研究分析,并将研究成果应用到了各个领域,获得了很好的经济和社会效益。
语音情感识别中最重要的是分类算法,应用最广泛的模式分类器有:隐马尔可夫模型(Hidden Markov Model,HMM)、高斯混合模型(Gaussian Mixture Model,GMM)、支持向量机(Support Vector Mechine,SVM)及人工神经网络(Artificial Neural Network,ANN)等[2]。作为初期计算性能较好的算法,HMM 以一阶Markov 链为基础发展起来,有不可见状态和可见状态两种常规状态,是双重随机过程[3]。Nwe 等[4]通过HMM 对六种情感进行判断、预测,最终在缅甸语料库的识别率达到78%。GMM[5]是一种单状态的隐性马尔可夫模型,由于它结构简单所以被广泛用于各种语音信号分类中。GMM 作为统计模型能吸收不同语音信号的声学特性的变动[6],但由于该模型采用状态输出独立假设,影响了其描述语音信号时间上的帧间相关动态特性的能力。本文提出了一种采用相继的复数帧组成的特征参数矢量作为输入特征量的方法来弥补传统GMM 语音帧间相关动态信息利用不足的问题。然而要很好地利用复数帧段输入GMM的关键是要解决当输入特征参数矢量的维数增加时,GMM 输出概率密度函数协方差矩阵的估计误差以及计算量增大的问题。对此,提出一种基于主分量分析神经网络(Principal Components Analysis Neural Network,PCANN)[7]和GMM 混合结构的语音情感识别方法,在GMM 的前端增加了一个用于语音参数压缩的主分量分析神经网络,既改善了状态输出独立GMM 的缺陷,又解决了上述问题。
1 高斯混合模型GMM
一个具有M个成员的GMM 的概率密度可由M个高斯概率密度函数的加权求和得到,由下式表示[8-9]:
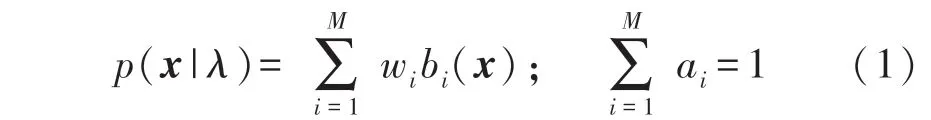
这里x是D维的输入随机向量;bi(x)(i=1,2,…,M)是第i个成员的高斯概率密度函数;wi(i=1,2,…,M)是i个成员权值系数。完整的GMM 可表示为:λ={wi,μi,Σi}(i=1,2,…,M),其中μi表示第i个成员的平均值向量,Σi表示第i个成员的协方差矩阵。每个成员密度函数是一个D维的高斯分布函数,可由如下表示:
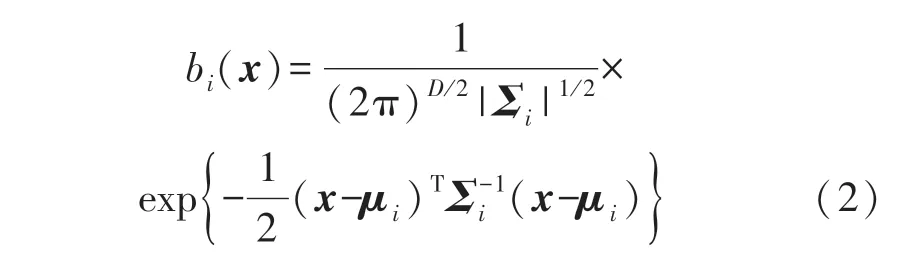
对于一个长度为T的测试输入时间序列X=(x1,x2,…,xT),它的GMM 似然概率可以表示为:

或用对数域表示为:
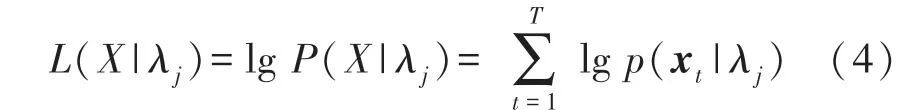
假设有N个未知类别,分类时运用贝叶斯定理,在N个未知类别的模型中,得到似然概率最大的模型对应的类别即为识别结果:
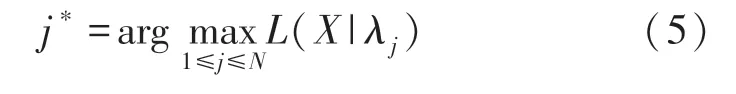
2 主分量分析神经网络的原理和算法
主分量分析(Principal Components Analysis,PCA)是一种机器学习算法[10]。主要是通过协方差矩阵将原来维数较高的具有一定相关性的数据,线性组合成维数较少的互不相关的数据[11-12]。利用复数帧段输入GMM 的关键是要解决当输入特征参数矢量的维数增加时,输出概率密度函数协方差矩阵的估计误差以及计算量增大的问题,在GMM 的前端增加了一个语音参数压缩的PCANN。图1 所示是能够提取前m个主分量的PCANN 结构图[7]。
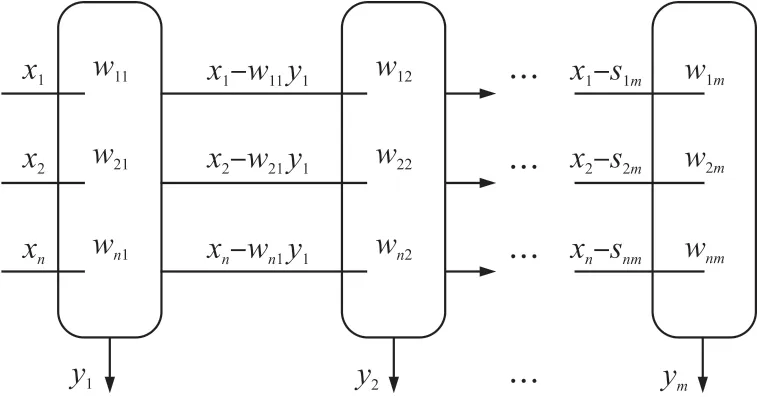
图1 提取m 个主分量的神经网络

式中:η为增益因子,η的选取决定网络收敛的快慢。k为迭代次数。可以证明,按照公式(6)进行权值迭代更新,网络收敛后,m个输出的权值向量位于样本协方差矩阵的前m个最大特征值对应的特征矢量方向上。利用上述算法提取的多个主分量,在理论上已经能保证各权向量的正交性,但实际应用中发现算法收敛太慢,迭代次数太多。因此实验中我们在训练一定次数以后强制进行一次正交化,从而既可使训练时间大大减少,又能保证得到较好的识别效果。权值的正交化采用格兰姆-施密特规则,设第i+1 个权向量经去冗余法提取后为:
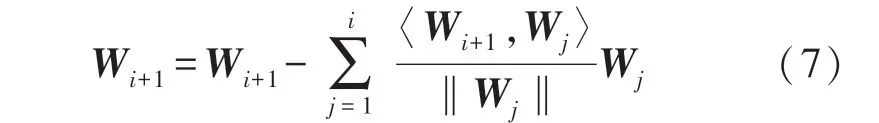
利用‖Wj‖=1,可得:
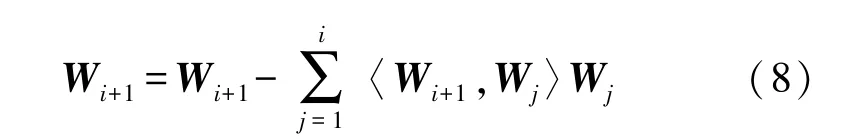
对其进行归一化可得:
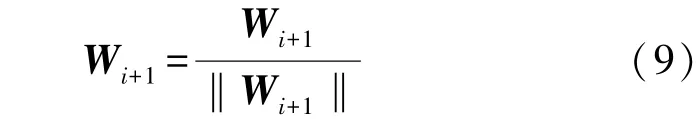
有了第i个权向量,即可得第i个主分量:yi=。
复数帧段GMM 的输入是由相继的复数帧特征参数矢量按顺序组合成的一个复合特征参数矢量,每个复数帧段特征参数的段移为一帧。这些复数帧段特征参数作为语音输入特征数据在模型训练和识别时使用。
3 实验和结果
本文使用的语音情感数据库是免费的柏林情感语音库,其采样频率为16 kHz,16 bit 量化[14]。该语音库分别由十名专业演员(5 男,5 女)在不同情感状态下(高兴、无聊、中性、悲伤、恐惧、厌恶、生气)朗读十句不同文本的德语组成。本实验选取其中的高兴、中性、悲伤、恐惧、厌恶、生气六种情感的语句各60 条。其中每种情感选30 条作为训练样本,另外30 条作为待识别样本,而且训练样本和待识别样本中,男女声音样本比例基本为1 ∶1,来验证复数帧段输入GMM 在语音情感识别中的识别效果。
语音情感识别特征选取部分语音韵律特征和音质特征及其衍生参数共23 个特征参数,构成用于识别的情感特征向量:特征1~5 维:短时幅度的均值、最大值、最小值、中值、方差;特征6~10 维:短时能量的均值、最大值、最小值、中值、方差;特征11~14 维:短时过零率的均值、最大值、中值、方差;特征15~18维:短时基音频率的均值、最大值、中值、方差;特征19~23 维:短时共振峰频率的均值、最大值、最小值、中值、方差。
评价上述PCANN/GMM 混合结构语音情感识别方法的识别实验主要是把传统的状态输出独立GMM 和PCANN/GMM 混合结构模型进行识别准确率比较。PCANN/GMM 模型的输入分别采用2 帧、4 帧和6 帧长度的复数帧。识别结果如表1~表4所示,识别率采用四舍五入法取整数。
由表1~ 表4 的识别测试结果可以看出,PCANN/GMM 的识别效果比状态输出独立GMM好,识别率均有所提高。2 帧、4 帧和6 帧宽度PCANN/GMM 的平均识别率分别为76.3%、84.2%和81.2%,几种情况中,对“生气”的情感识别率普遍较高。另外,4 帧宽度PCANN/GMM 的识别率最高,4 帧的语音长度能较好地描述帧之间的动态特性,帧数太少,不能较全面完整地利用帧间的特性,随着帧数的增加,帧之间的情感相关性随之减弱,有时甚至会发生情感的转变,从而影响识别率。
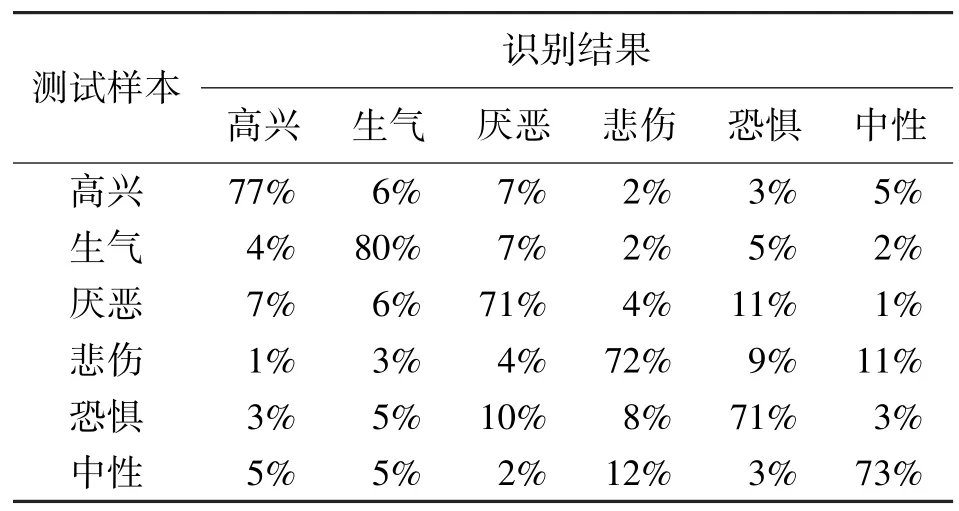
表1 状态独立输出GMM 情感识别结果
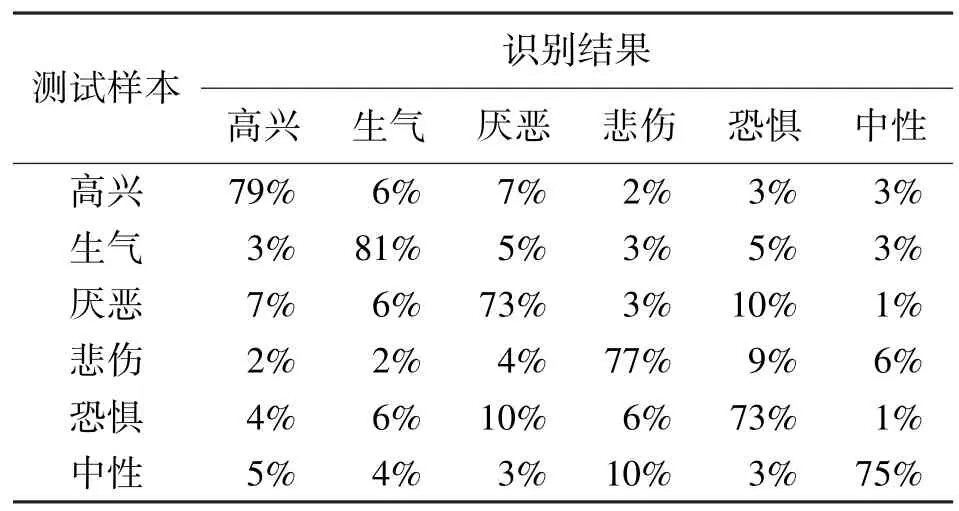
表2 2 帧宽度GMM 情感识别结果
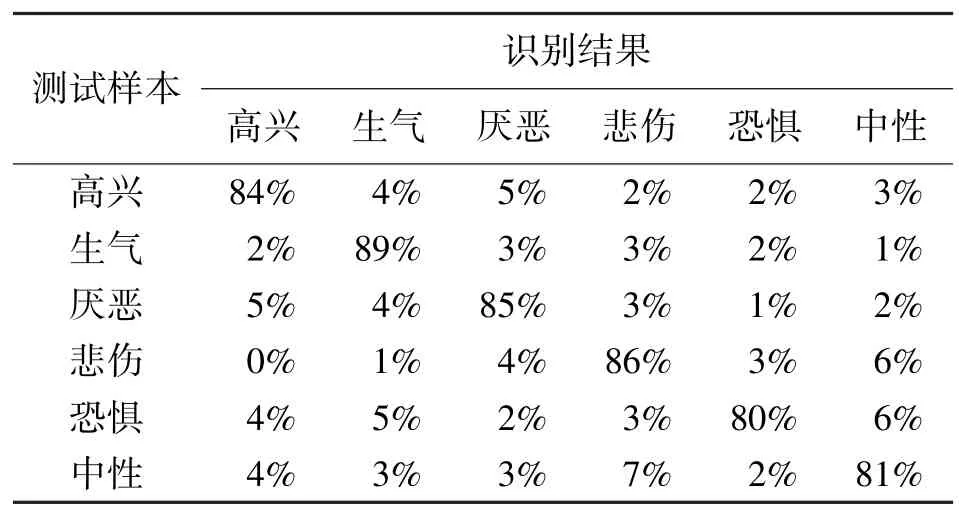
表3 4 帧宽度GMM 情感识别结果

表4 6 帧宽度GMM 情感识别结果
4 结论
语音情感识别作为情感计算中的一个重要方面,目的是要让计算机能够理解人类语音中所传递的情感信息。而由于情感信息的社会性、文化性,以及语音信号自身的复杂性,语音情感识别中尚有许多问题需要解决,特别是符合人脑认知结构与认知心理学机理的情感信息处理算法。本文将主分量分析神经网络与高斯混合模型相结合,研究了其在语音情感识别中的学习能力和识别效果。针对高兴、生气、厌恶、悲伤、恐惧和中性六种基本情感,提取了包括韵律特征与音质特征在内的23 个情感特征。语音情感识别实验证实了引入帧间相关动态信息方法的有效性。建立一个高效合理的语言情感识别模型仍是研究重点,今后需要进一步探讨主分量分析神经网络与高斯混合模型的结合,特别是优化神经网络的拓扑结构方面还存在许多尚未解决的问题。
猜你喜欢
中学生数理化(高中版.高考数学)(2021年11期)2021-12-21 05:34:28
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20 07:18:48
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20 07:18:46
新世纪智能(数学备考)(2020年12期)2020-03-29 02:15:34
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
制造技术与机床(2017年11期)2017-12-18 06:46:39
