
基于VGGNet-plus 的路面裂痕自动分类识别方法
2022-07-10 02:16:24肖彭昊杨修伟范媛媛
电子器件 2022年2期
肖彭昊 杨修伟 范媛媛
(1.长江大学地球物理与石油资源学院,湖北 武汉 430100;2.郑州大学地球科学与技术学院,河南 郑州 450001)
路面裂缝作为道路中常见病害之一,是道路养护工作的重点和难点。目前,基于图像处理的方法是路面病害的常用检测方法[1]。
国外现有研究中,任亮[2]采用脊线检测方式对所有可疑裂缝目标进行一一标注,最大程度地保留明显的裂缝特征,通过Prim 算法来构造最小生成树将所有不连续裂缝相连,删除所有强制伪连接,通过填充操作增强裂缝并获得完整的裂缝结构。Li[3]提出基于边界框的自动化图像分割方法,该方法嵌入了多种子融合算法,结合车轮路径和车道标记的位置生成边界框,对裂缝的灾害严重性进行评估,取得了不错的分类效果。Saar 等[4]提出一种使用二级分段神经网络检测裂缝图像的道路路面测量系统,该方法的预测效果要优于贝叶斯以及最近邻分类器。Miguel[5]提出了基于线性SVM 的路面破损分类方法,该方法能将错误分类特征的影响降低,但是,除了使用分类器算法外,该方法的效果还取决于样本数量,正样本和负样本的比例以及样本的泛用性。Zhang 等[6]训练了一个基于监督学习的深度卷积神经网络,对收集的每个路面图像块进行分类,通过对智能手机收集的图像数据集进行评估,与手工提取特征对比,该方法裂缝检测性能更好,证明了将深度学习与路面裂缝识别相结合的可行性。Zhang等[7]提出了一种基于递归神经网络(Recurrent Neural Networks,RNN)的三维沥青路面全自动像素级裂缝检测方法,实现了序列生成和序列建模两个阶段的序列处理方式,通过对500 幅路面图像进行测试,取得了不错的效果。
在国内研究中,李刚等[8]提出基于径向基函数神经网络识别裂缝,该方法能很好地提取边缘特征,具有较强的抗噪能力。沙爱民等[9]建立卷积神经网络模型对设备采集后尺寸分割的路面图像进行训练,最终实现路面裂缝、坑槽病害识别。张采芳等[10]提出了基于特征分析的裂缝分类方法,在不构建分类器的前提下,利用方向特征调整阈值以确定类别,然后根据分布密度的特性,识别块状裂缝与龟裂裂缝。陈瑶等[11]利用爬壁机器人采集桥梁路面裂缝,使用小波变换以及二值图像路面形态学分析增强图像中的裂缝特征并提取裂缝特征,最后运用SVM 进行分类识别。李伟等[12]对预处理后二值化的路面裂缝图像以聚类方式进行识别,运用杠杆原理确定聚类后裂缝中心点位置,通过计算路面裂缝弧度辨别路面裂缝的类型,并对网状裂缝的毁坏程度进行了参数分析。钱彬等[13]将多属性特征构建在不同的结构,并嵌套到矩阵分解算法中,可以实现函数的自适应融合和原始灰度属性维度的减少,从而成为一个整体的目标函数。琚晓辉等[14]提出SVM-Adaboost 分类器对SVM 参数进行动态优化,自适应地调整训练样本分布,随着训练迭代次数的改变,最终由弱分类器多次迭代,生成分类误差最小的强分类器,有效提高分类器的性能。
本文提出的基于VGGNet-plus 网络模型的路面裂痕自动分类识别方法,是在传统的VGGNet[15]的基础上,增加了Dropout 层和残差层,并在每个卷积层后连接批量正则化层和LeakyReLu 层。该网络保留了VGGNet 简洁的网络结构,并且通过不断加深网络,使用小滤波器卷积层组合来提升性能,解决了训练量过多的问题,简化计算量的同时也加速了模型的收敛。本文针对训练样本有限的问题,提出了通过灰度处理,上下翻转,左右翻转,灰度二值处理,均值滤波,灰度gamma 处理,高斯滤波,中值滤波等方法来进行数据增容,不仅增加了数据的数量,同时对采集光照条件、角度、噪声等造成的影响具有更强的适应性和鲁棒性。
1 基于VGGNet-plus 的裂痕分类方法
本文所使用的路面裂缝图像数据集来源于道路检测车拍摄的路面视频和智能手机拍摄的路面图像。根据裂缝特征,将数据集分为纵向裂纹、横向裂纹、块状裂纹、龟裂裂纹、无裂纹5 类典型裂缝(图1)。该方法的关键步骤包括:数据增容,VGGNet-plus 网络搭建与训练,模型集成,裂痕自动识别。

图1 典型路面裂缝特征
1.1 数据增容
由于训练数据过少,我们首先通过灰度处理,上下翻转,左右翻转,灰度二值处理,均值滤波,灰度gamma 处理,高斯滤波,中值滤波等方法来进行数据增容,完成数据集的构造(图2)。通过数据增容,不仅增加了数据的数量,同时对采集光照条件、角度、噪声等造成的影响具有更强的适应性和鲁棒性。将增容后的样本数据通过VGGNet-plus 卷积神经网络进行裂缝辨别训练,获取训练后的神经元参数集合。

图2 数据增容方式
1.2 VGGNet-plus 分类识别网络结构
VGGNet-plus 网络结构如表1 所示。其中包括了5 个卷积层、5 个残差层、1 个平坦层以及3 个全连接层。残差层和卷积层内部结构如图3 所示。
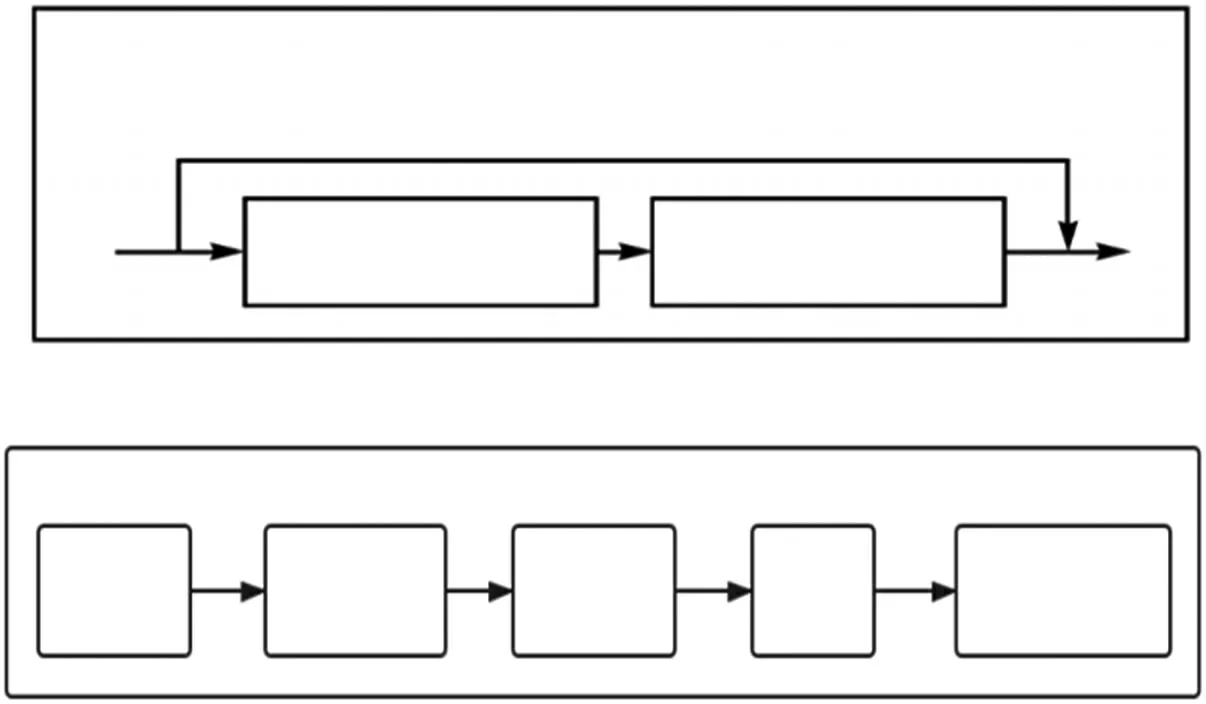
图3 残差层和卷积层内部结构
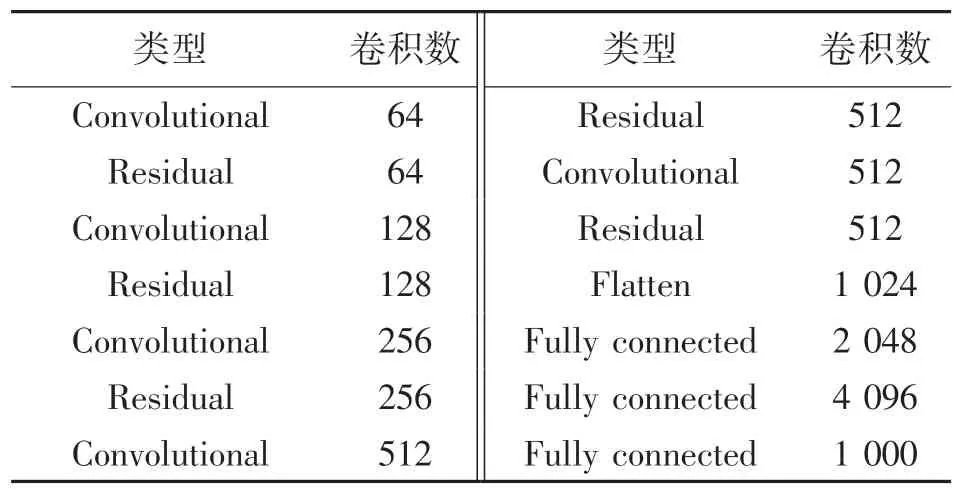
表1 VGGNet-plus 网络结构
每个卷积层中利用核大小分别为2×2 尺度的特征图进行最大池化,使用3×3 卷积核进行特征提取(体现在图上),各卷积层后都接有批量标准化层和LeakyReLu 层,简化计算量,同时加速模型收敛。残差层通过充分提取裂缝图像的属性来减少模型参数的数量,并解决了网络层数过深引起的计算量大的问题,将传统神经网络的逐层训练方式调整为逐阶段训练方式。然后通过3 个全连接层存储所有特征参数,加入dropout 层,每次训练丢弃一半的参数,从而防止模型过拟合。
1.3 模型训练与模型集成
模型训练利用Adam 优化算法取代传统的SGD算法,反向传播后迭代更新网络权重,通过梯度调整每个参数的学习率。通过模型集成中的Bagging 方法,在原数据集的基础上有放回选取,形成多个子训练集,然后把每个基模型预测的结果进行综合评估产生最佳的预测结果。
1.4 模型评价
混淆矩阵是衡量分类模型准确度中最直观,计算最简单的方法。它也是评估模型结果的度量标准,通常用于评估分类器的性能。除了混淆矩阵之外,本文还使用准确度和召回率指标来衡量网络模型的性能,并计算F1-score 以充分评估模型的影响(表2)。
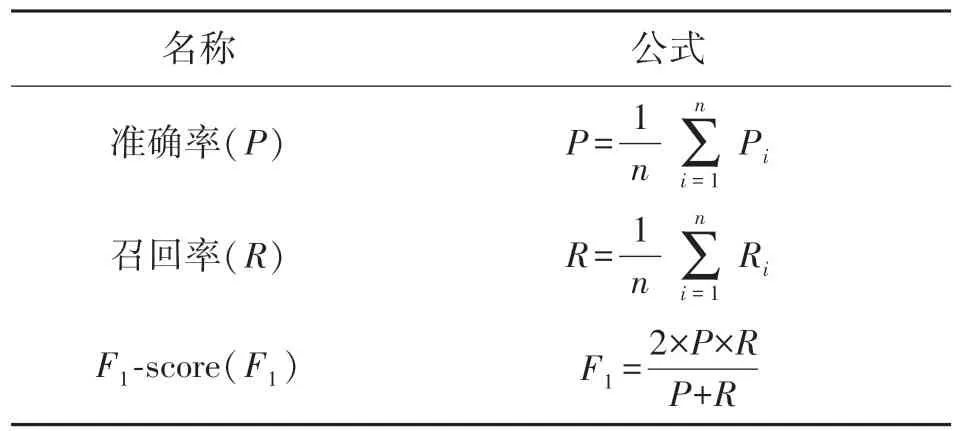
表2 准确率、召回率和F1-score 的计算公式
其中,准确率是正确识别和分类的目标与总体目标的比率,反映了模型区分图像背景的能力。准确率越高,意味着模型就可以更好地区分复杂背景。召回率是最终被正确归为其目标类别的图像数量占该目标类别图像总数的比例,反映了模型在图像中检索目标的能力。召回率越高,意味着模型的识别能力就越高。F1-score 是两者的综合表现,其分值越高,模型越可靠。
2 实验结果与分析
本文以道路检测车拍摄的路面视频和智能手机拍摄的路面图像为实验样本进行算法验证。其中,每类裂缝有800 个样本数据,我们通过数据增容,将数据集扩展为原来的12 倍,获得9 600 个样本。选取8 400 个作为我们的训练集,1 200 个作为测试集。训练过程中,随机选择训练集的90%作为训练数据,剩下的10%作为验证数据。
利用训练好的VGGNet-plus 网络对测试集进行测试比较,并绘制混淆矩阵、计算准确率、召回率和F1值(图4,表3)。可以看出,混淆矩阵对角线颜色较深,总体准确率、召回率和F1值分别为0.924、0.905 和0.883,纵向裂纹、横向裂纹、龟裂裂纹和无裂纹的准确率和召回率均达到了90%以上,表明模型测试效果较好。
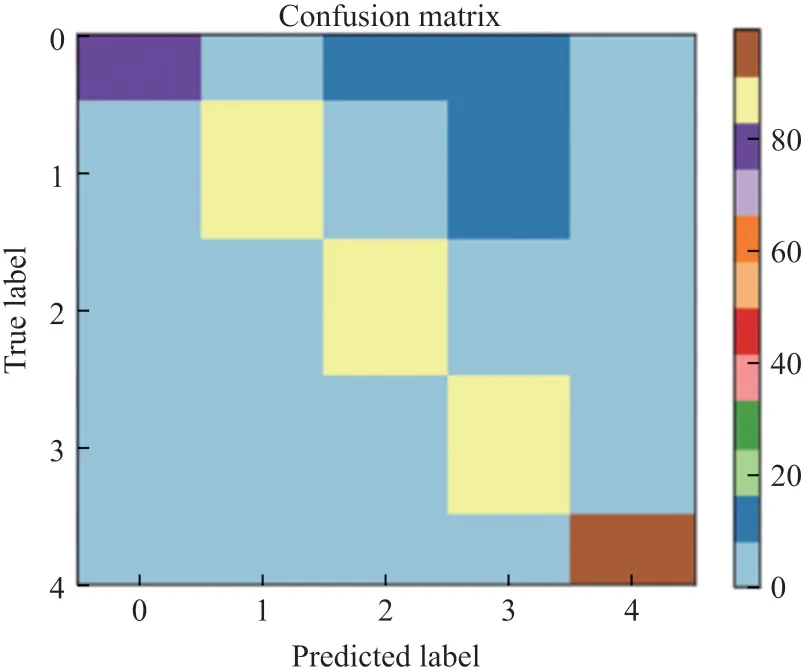
图4 VGGNet-plus 模型混淆矩阵
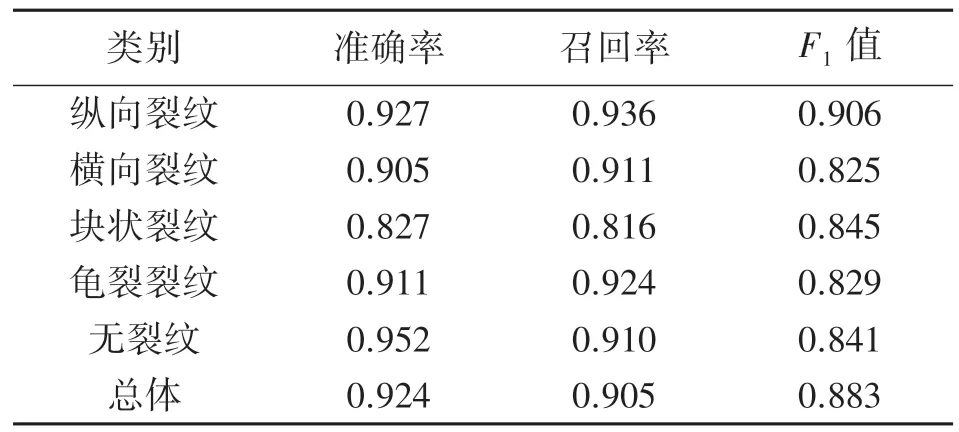
表3 VGGNet-plus 模型评价
为了突出本文方法的优势,选择了3 种经典图像分类方法在同等条件下进行对比,即AIexNet 算法、InceptionNet 算法以及VGGNet 算法。表4 为各种方法对裂缝图像进行分类的准确率、召回率、F1值以及耗时的对比。为了保证客观性,实验结果均为执行20 次实验得到的平均值。

表4 路面裂缝分类算法测试结果比较
从表4 中的各项评价指标可以看出,AlexNet 网络层数相对较浅,应对复杂环境下各种干扰因素的能力也相对较差,因此,识别结果和计算效率均是四类方法中最差的。InceptionNet 相比于AlexNet 既减少了参数量,又在一定程度上扩展其深度和广度,提高了非线性表达能力,识别结果和计算效率得到了一定的提升。VGGNet 使用多个相同的卷积核,使决策函数更有判别性,识别精度和训练耗时均优于AlexNet方法,但不及InceptionNet 方法。本文提出的VGGNet-plus 模型保留了VGGNet 模型的主要结构,并通过增加Batch_normalize(BN)层和LeakyReLu 层缓解梯度消失,梯度爆炸等问题,增加Dropout 层和残差层解决了因网络过深,参数过大引起的过拟合问题,从而加快训练速度,加速模型收敛。表4 结果也表明:本文提出的方法具有最高的精度以及最小耗时,优于AIexNet,InceptionNet 和VGGNet 模型。
4 结论
本文提出了一种基于VGGNet-plus 卷积神经网络识别路面5 种典型裂缝的方法,该方法在VGGNet算法的基础上,增加了Dropout 层和残差层,此外,各卷积层后都接有批量标准化层和LeakyReLu 层,解决训练参数过多,从而加快训练速度,降低计算量,同时加速模型收敛。本文通过对比AIexNet、InceptionNet、VGGNet 以及本文方法(VGGNet-plus),分析了各模型的优缺点,评价了各模型的图像识别能力、运行性能,证明本文方法的性能最佳。
本文提出的裂缝分类算法具有分类效果较优、训练速度较快、同时在小样本训练性能较佳等优势。但仍存在一些可改进的地方:
(1)增加更多的噪音数据,提高模型的泛化能力,增强其鲁棒性。
(2)使用TTA(Test Time Augmentation)集成学习,对同一个样本预测三次,然后对三次结果进行平均。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新悦读(2019年11期)2019-12-18 05:14:16
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
专用汽车(2015年4期)2015-03-01 04:10:02
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:31
电测与仪表(2014年15期)2014-04-04 12:05:20
