
基于优化二叉树SVM 脱机手写体汉字粗分类研究
2022-07-08 03:31甘恒黎曙张松华郭婷
电子技术与软件工程 2022年8期
甘恒 黎曙 张松华 郭婷
(中国船舶重工集团公司第七〇五研究所昆明分部 云南省昆明市 650000)
1 引言
脱机手写体汉字不仅具有汉字类别多、字体结构复杂、字型变化多、相似字多的共性,还具有书写风格众多、书写不规范和随意性较大等特点,使得脱机手写体汉字识别成为目前模式识别研究领域最困难的问题之一。
近年来,一些新的方法理论运用到脱机手写体汉字识别领域,如神经网络、粗糙集等。脱机手写体汉字可以认为是一个无限样本的问题——同一个汉字不同人书写是不同的,即使同一个人两次书写两个汉字也是不同的。而实际情况下脱机手写体汉字分类识别问题只能通过有限样本来训练识别待识别样本。与神经网络、粗糙集相比支持向量机(SVM)在处理这类小样本时问题方面具有明显优势。同时汉字集是一个大集合,仅一级常用汉字就达到3755 个。在处理大类别问题时,识别器会出现识别率低、速度慢以及内存消耗巨大甚至根本无法实现。因此必须要首先对汉字集进行粗分类,将待识别汉字缩小到一个字符集中,然后再进行细识别。粗分类的正确率将直接影响到细识别的准确度。
本文通过对手写体汉字像素密度的研究,提出了一种优化二叉树粗分类的算法。目前采用粗分类的方法主要有:按汉字字型结构特征、按汉字部首特征等。按汉字字型结构特征进行粗分类存在某些字的字型结构不明确的问题。按汉字部首特征粗分类,存在某些部首特征难于提取。汉字像素密度特征具有易于提取且稳定,对手写体变形不敏感的特点。仅依照汉字整体的像素密度特征分类比较粗糙。本文对汉字图像进行小波分解,增加汉字横笔划、竖笔划、撇笔划和捺笔划特征的细节描述。采用小波分解后的密度特征,通过优化二叉树支持向量机进行粗分类。二叉树根据待识别汉字样本与分类类别间可能性大小,建立按可能性大小排列的二叉树。可能性大的类别靠近二叉树根节点,这样提高分类速度。仿真实验表明本文提出的方法有较好的分类效果与速度。
2 汉字像素密度及分布情况
2.1 像素密度的定义
设一个N×N 汉字二值图像为f(x,y),其中i={1,2,…,N}、j={1,2,…,N},二值化后图像象素点f(x,y)的值为:

2.2 汉字图像的小波分解
为了减少汉字大小、笔画粗细等对像素密度的影响,在小波分解前先进行了归一化、去孤立点、细化的预处理。通过一级db1 小波对汉字图像进行分解重构提取汉字横竖斜向信息,如图1 所示。通过汉字的横、竖、斜向像素密度增加细节描述,从而进行更一步分类。
由图1 可以看出汉字图像水平、垂直、斜向分量重构图在一定程度上刻画了汉字,横笔划、竖笔划、斜向笔划的特征。同时也可以看出,与印刷体汉字相比由于手写汉字的变形,引入了干扰。如图1 中由于变形“叶”字引入了斜向笔划的干扰信息。这也正是手写体汉字笔印刷体识别更加困难的原因之一。本文通过统计分析进一步研究手写体汉字变形的干扰特点。

图1: ‘叶’字小波分解重构图
2.3 汉字样本分布
本文定义,汉字预处理图像根据式(1)计算得到的值称为整体像素密度。水平、垂直、斜向分量重构图计算得到的值分别称为横笔划像素密度、竖笔划像素密度、斜向笔划像素密度。
由于每个汉字笔划数目的不同,每个汉字的繁简度也就不尽相同。在汉字图像上即表现为汉字的像素密度的不同。其中一个实际汉字“椽”其样本分布情况如图2-a。竖线表示 “椽”样本的整体像素百分比的一个均值,记为μ。可以看出汉字分布在其均值附近比较集中。通过统计大量脱机手写体汉字,一个汉字在3δ(δ 表示像素密度方差)范围内集中了92.5%的样本,4δ 为97.5%,5δ 为99.8%,近似于正态分布规律。为了简化计算本文用正态分布替代汉字的实际分布。记脱机手写体汉字的样本分布服从N(μ,σ),其中σ为汉字整体像素密度的标准差。
本文统计了GB2312 中3755 个一级汉字的整体、横笔划、竖笔划和斜向笔划像素密度平均值,其分布规律如图2 所示。可以看出汉字像素密度呈现出分布不均居、比较集中的特点,这给分类造成一定的困难。结合手写体汉字方差就可以得到其在整体密度区间上的分布情况。部分汉字的像素密度方差如图2(f)~(i)所示。
可以看出部分汉字整体像素密度方差较大,如图2-f 横坐标为3 对应的汉字“矗”。其整体像素密方差为1.22 为图中最大,整体像素密百分比度为6.47;横笔划像素密度方差为0.90;竖笔划和斜向笔划像素密度方差并不大,分别为0.35 和0.40。说明人们在书写“矗”时变形较大,且变形主要来自于横笔划。该汉字4δ 内样本覆盖了整体像素密度区间(图2-b)的48.3%,这样大部分汉字整体像素密度都与该汉字有交叠。若仅依靠整体像素密度这单一特征,将给分类造成了巨大的困难。但其竖笔划和斜向笔划方差并不大,即竖笔画和斜向笔画比较稳定。
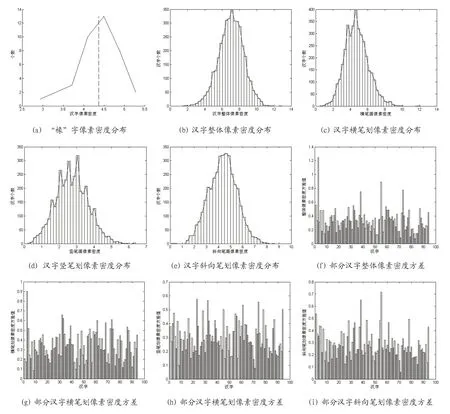
图2: 汉字像素密度方差图
3 粗分类方法
通过研究发现小波分解后整体、横、竖、斜向密度的综合特征比单一的汉字整体像素密度特征稳定。故本文采用能够表征整体横竖斜向密度的特征向量采用支持向量机进一步进行数据挖掘,进行脱机手写体汉字的粗分类。投影特征正好满足这一要求——投影特征的一范数正好是表达式(2),能够表征像素密度属性;同时小波分解后的水平、垂直、斜向分量重构图的分别进行水平、垂直、斜向投影(45°、135°投影),在一定程度上分别反映出了横、竖、斜向笔划的位置信息。故本文采用小波分解后的投影特征作为支持向量机特征向量进行粗分类——根据汉字整体图像以及小波分解水平、垂直、斜向子图投影特征,进行逐级的粗分类。如图3 所示。

图3: 粗分类示意图
3.1 支持向量机二叉树分类方法优化
SVM 解决的是二分类问题,而汉字粗分类研究的是多分类问题,因此须用多个二分类器组合解决多类分类问题,主要方法有一对一、一对多、决策导向无环图和二叉树等。为了加快分类速度,以及避免一对一、一对多出现分类盲区等问题,本文采用二叉树支持向量机进行粗分类。对于n 个类别的分类二叉树只需n-1 个分类器同时树形结构清晰,时间复杂度为O(nlog2n),比起其它几种算法显著提高。若待分类样本和分类类别间有特定关系的话,二叉树某些枝节是不需要访问的,同时二叉树结构还可以进一步优化。
常常在某些情况下,根据待识别样本某些属性可以知道其属于某些类别可能性比较大,而属于某些类别的可能性很小甚至或基本不可能。如本文识别汉字像素密度与分类类别间的距离越接近,则待识别汉字属于该类别的可能性越大;越远则可能性越小,远到一定程度后待识别汉字就基本不可能属于这些类别。因此可以根据这些特点优化二叉树的结构,加快识别速度,以有利于处理大类别大样本分类问题。同时将可能性大的类别靠近根节点,这样减少二叉树误差积累的影响。
文献针对故障诊断特点——类别间存在一定关系的连续时间过程。提出了一种剪枝二叉树SVMs 的方法,但其只能运用于类别间一定关系的连续时间过程。在某些情况下,待识别样本和分类类别间同样存在一定的关系。本文对该方法进行调整,使之用于汉字粗分类这类待识别样本与类别存在一定关系的非连续时间过程。先剔除与待识别汉字样本距离较远(即可能性较小)的类别,即从n 个类别中剔除i 个分类可能性较小的样本,根据相似度由大到小重新构造二叉树,使得原来的n-1 个SVMs 分类器减少到n-1-i 个,再进行分类。
其中本文在汉字识别中相似度及剪枝阈值定义如下:
3.1.1 相似度的定义
以待识别汉字与类别间的距离定义相似度,即:

3.1.2 剪枝的阈值
通过对大量汉字样本统计得出在3δ(δ 表示汉字样本像素密度的方差)范围内平均包含了汉字样本的90.0%,4δ 为98.5%,5δ 为99. 8%。本文将五倍最大方差外的样本进行剪枝,以加快速度。剪枝的阈值即:

Setp1:计算待识别汉字像素密度为ρ。以及待识别汉字与各子集的相似度sim,剪枝的阈值。按相似度由大到小构造一棵完整的二叉树,如图1 所示。
Setp2:先暂时剔除与待识别汉字相似度较远的样本集合,即剔除相似度小于阈值的集合进行剪枝。
Setp3: 将剪枝后二叉树与剪掉枝叶作为根节点重新组合生成新二叉树,如图4 所示。
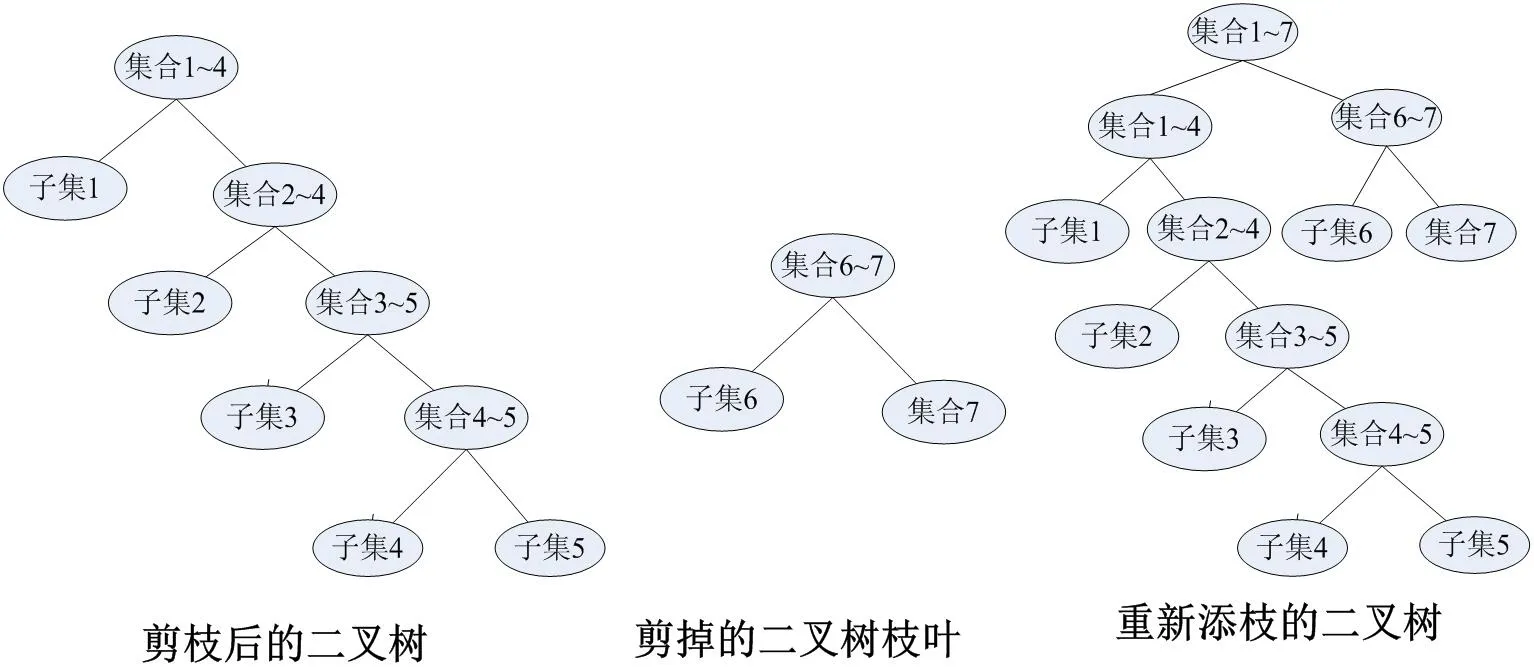
图4: 二叉树优化示意图
Setp4: 根据新构建二叉树分类识别,输出分类结果。
3.2 仿真实验
本文采用SCUT-IRAC HCCLIB 手写体汉字图像样本数据库第20 区94 个汉字每个字100 个样本在MATLAB 2011a平台下测试,支持向量机采用台湾大学编写的libsvm-3.12B版本。
以“椽”字作为待识别汉字(如图5),根据整体像素密度特征进行第一级粗分类为例。支持向量机分类模型建立及识别过程如下:

图5: 待识别字样本
进行二值化、细化、归一化、去孤立点预处理成64×64图像,计算每个汉字整体像素密度的期望和方差,统计结果如图6 和图7 所示。其中横坐标对应汉字,纵坐标表示汉字像素密度百分比的期望和方差。
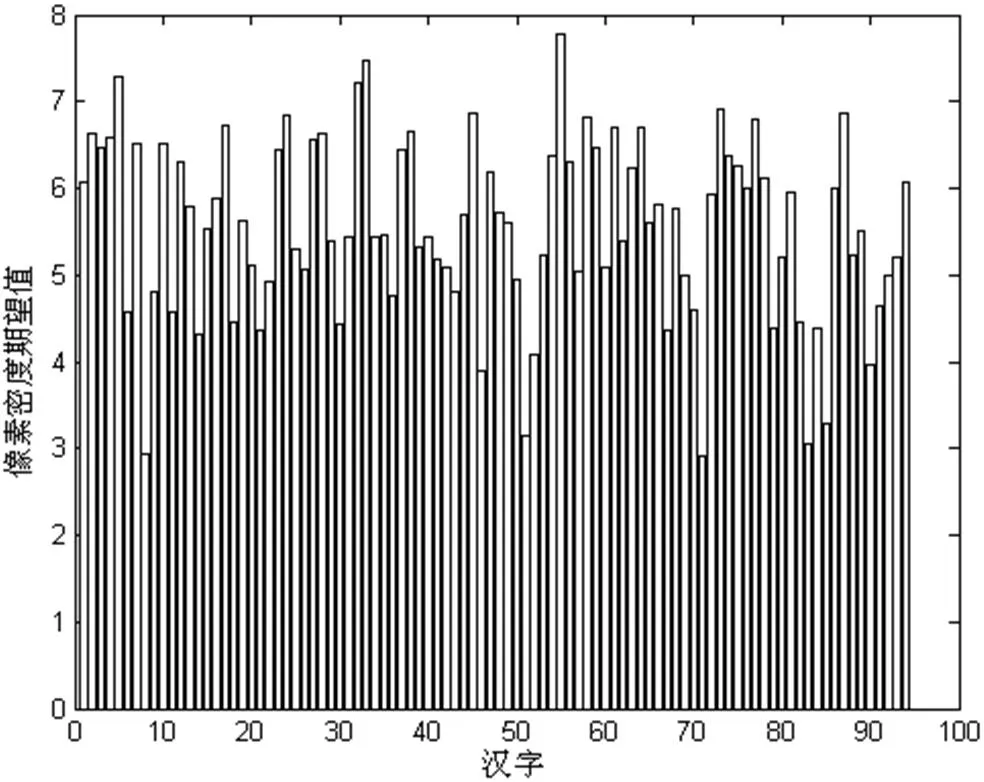
图6: 像素密度期望

图7: 像素密度方差
待识别“椽”字样本像素密度百分比为5.878。由汉字像素密度方差(图7)计算得到汉字样本的最大方差为0.521。由式(4)计算得到sim=0.2095。根据式(3)计算出相似度如表1。首先根据相似度,按Setp1 构建一颗完整。然后根据剪枝阈值剔除相似度小于0.2095 的类别——很简单、较简单、较复杂和很复杂四个类别。剪枝及添枝后的二叉树如图8 所示。其中k=1,……,7,分别对应汉字很简单、较简单、简单、适中、复杂、较复杂、很复杂七个类别。按照重新添枝后的二叉树进行识别,经仿真识别得到待识别汉字“椽”,属于k=5 的类别,即复杂类别。查询复杂类别汉字“椽”包括在该类别中,其整体像素密度期望值为6.410。待识别汉字通过仿真识别其类别与其实际汉字所属类别一致。
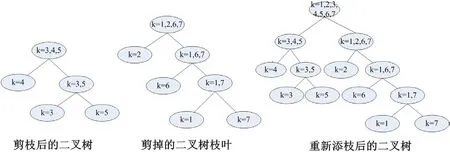
图8: 待识别字二叉树优化图

表1: 待识别字与类别相似度
通过对第20 区94 个汉字,其中60 个汉字作为训练样本,另外40 个作为待识别样本进行测试。采用本文中二叉树优化算法粗分类正确率平均为95.2%,每个汉字识别时间平均为0.092118 秒,粗分类后得到的汉字集合大小平均为10 个字。采用图1 结构二叉树非优化算法正确率平均为94.1%,每个汉字识别时间平均为0.122528 秒,粗分类后得到的汉字集合大小平均为10 个字。可以看出经过优化的二叉树支持向量机准确率得到提高,同时分类识别速度明显加快。
4 结束语
本文利用二叉树SVM 根据小波分解密度特征对汉字进行粗分类,同时给出了二叉树的优化算法。优化算法让可能汉字集靠近二叉树根节点,从而加速分类过程。从仿真结果可以看出该优化的二叉树算法识别率有所提高,同时识别速度加快24.6%,优化算法是有效的。根据小波分解密度特征对汉字进行粗分类准确率较高,可以有效的进行粗分类。
猜你喜欢
星星·诗歌原创(2023年1期)2023-05-30
星星·散文诗(2023年1期)2023-04-15
军事文摘·科学少年(2020年3期)2020-03-26
科技风(2020年3期)2020-02-24
中国篆刻(2019年6期)2019-12-08
水利规划与设计(2017年12期)2017-02-06
图学学报(2013年4期)2013-09-25
青年文摘·上半月(1985年2期)1985-11-01
