
基于改进MobilenetV2网络的声光图像融合水下目标分类方法∗
2022-07-07 07:23:28巩文静李宝奇刘纪元
应用声学 2022年3期
巩文静 田 杰 李宝奇 刘纪元
(1 中国科学院声学研究所 北京 100190)
(2 中国科学院大学 北京 100049)
(3 中国科学院先进水下信息技术重点实验室 北京 100190)
0 引言
水下目标成像及分类可以通过不同的成像技术实现,利用光学传感器获得的图像分辨率较高、目标较为直观[1],在目标分类研究中有重要应用。Gleason等[2]使用监督分类的方法对水下光学图像中的目标和海床进行分类,将海床的局部地形或高度作为附加特征添加到分类器中,具有一定的有效性;Pramunendar等[3]提出了一种应用于反向传播神经网络的图像增强模型,通过选择合适的插值方法和反向传播神经网络结构提高图像分辨率,取得了较高的分类准确率;王士龙等[4]提取目标的边界矩,利用改进的FCM 聚类算法较好地实现了对水下目标的分类识别。
虽然以上利用光图实现水下目标分类已经取得了一定成果,但是受成像条件复杂性的影响,水下光成像作用距离近,图像对比度较差。由于声呐的探测距离较远,成像范围较大[5−6],声成像技术的不断发展使得利用声呐图像进行目标分析成为可能[7−9]。Sinai等[10]利用C-V轮廓算法将声呐图像分割为目标及阴影两部分,通过人工提取几何特征来实现水下目标分类;Williams[11]利用卷积神经网络将水声图像分为有目标和无目标两类,取得了满意的效果;朱可卿等[12]使用高斯混合模型对声图的阴影部分进行提取,设计融合分类器实现对水下沉底小目标的分类,分类性能较好。
然而,受声呐自身技术参数的限制以及水下噪声、混响的影响,声成像的清晰度较低,且声图获取较为困难。现有水下目标分类方法的研究大多依靠单一的光学或声学图像数据集,通过人工提取特征或使用卷积神经网络完成对目标的分类。但是,单一数据集对目标的描述具有一定限制,且卷积神经网络模型较为复杂,网络的计算和分类速度较慢。因此,如何降低模型复杂度,节约计算资源,获得更好的分类效果,都是亟待解决的关键问题。
为了改善网络的分类性能,适应小样本背景下的水下目标分类任务,主要从以下角度解决上述问题。首先,选择轻量化的MobilenetV2 网络并对其结构进行改进,减小网络的参数量,进一步提高网络运算效率。其次,在改进网络的基础上设计并行网络结构,将采集的声、光学图像真实数据集同时输入网络,采用中间层融合策略,利用融合特征得到最终的分类结果。该方法规避了单一数据集对目标描述的限制,充分利用声、光学两种图像各自的优势以及MobilenetV2网络参数少、轻量化的特点,在节约网络计算资源的同时,提高了算法的分类准确率。
1 改进MobilenetV2网络
1.1 MobilenetV2网络模型
MobileNet 是Google 于2017年提出的新型轻量化网络[13],MobileNetV2 与其相比,具有较少的网络参数数量和更低的运算成本,相比普通的全卷积网络能够减少8~9 倍的计算量,网络性得到了进一步改善,与VGG16 等常用网络相比具有低消耗和实时性等优点,符合目标分类任务的要求[14]。MobileNetV2网络包括普通卷积(Conv)、反向残差结构的深度分离卷积(Bottleneck)和平均池化(Avgpool)几部分,网络结构如图1所示。

图1 MobileNetV2 网络结构Fig.1 Network structure of Mobilenetv2
Bottleneck结构是MobileNetV2网络的核心部分,每个Bottleneck 由两个普通卷积和一个深度分离卷积(Dwise)组成[15]。该结构首先通过1×1的卷积进行维度扩展,再用3×3 的深度分离卷积提取特征,最后使用1×1 的卷积来压缩数据[16],两个普通卷积分别使用ReLU6和Linear函数进行激活,深度分离卷积使用标准化BN 层[17]和线性整流函数ReLU6[18]进行正则化和激活。图2(a)和图2(b)分别表示步长为1 和步长为2 时的Bottleneck 网络结构,当步长为1 时,需要将该网络结构的输出与上一层的输出进行叠加,实现不同位置的信息整合。

图2 Bottleneck 网络结构图Fig.2 Bottleneck network structure
1.2 改进的MobileNetV2网络
MobilenetV2 网络使用ImageNet 数据集进行训练,数据集图片数量达到140 万张,而水下目标图像采集较为困难,获取的数据数量较少,直接使用原网络进行训练无法得到较好的拟合效果,且ImageNet 数据集共包含图像1000 个类别,目标种类与水下目标差别悬殊,无法直接进行迁移学习。MobilenetV2 网络第9 层的输出通道由320 增加到1280,通道数的增加会消耗更多的计算资源;网络使用平均池化Avgpool 降采样来减少特征数量,更多地保留图像的背景信息,不完全适用于水下目标分类任务。
因此,为了增强网络在水下场景的适用性,充分发挥深度分离卷积在特征提取中的优势,提高目标分类的精确度,本文在MobileNetV2 网络的基础上进行了如下改进:(1) 为了在训练网络时进一步减少计算资源、节约内存空间,在保证精度的前提下充分考虑参数量和运算成本,借鉴文献[14]的方法,通过多次实验对比,本文去掉第9层之后的网络层,并将该卷积层通道数由1280改为128。(2) 为了适应水下目标分类任务,在保留目标特征信息的同时提升网络的收敛速率,本文使用Flatten层进行数据降维,将三维的输出转化为一维后,添加Dropout层改善网络拟合,丢弃率设为0.5,最后增加一个全连接层,得到最终的分类结果。
图3为改进MobileNetV2 网络的结构示意图,网络包括特征提取和分类两个部分。特征提取网络包括1 个普通卷积、7 个具有反向残差结构的深度分离卷积和1 个普通卷积,通过Flatten 层将三维特征图转换为一维后,使用Dropout层改善网络拟合。分类网络使用全连接层结构,从而得到每一个目标属于各个类别的概率。
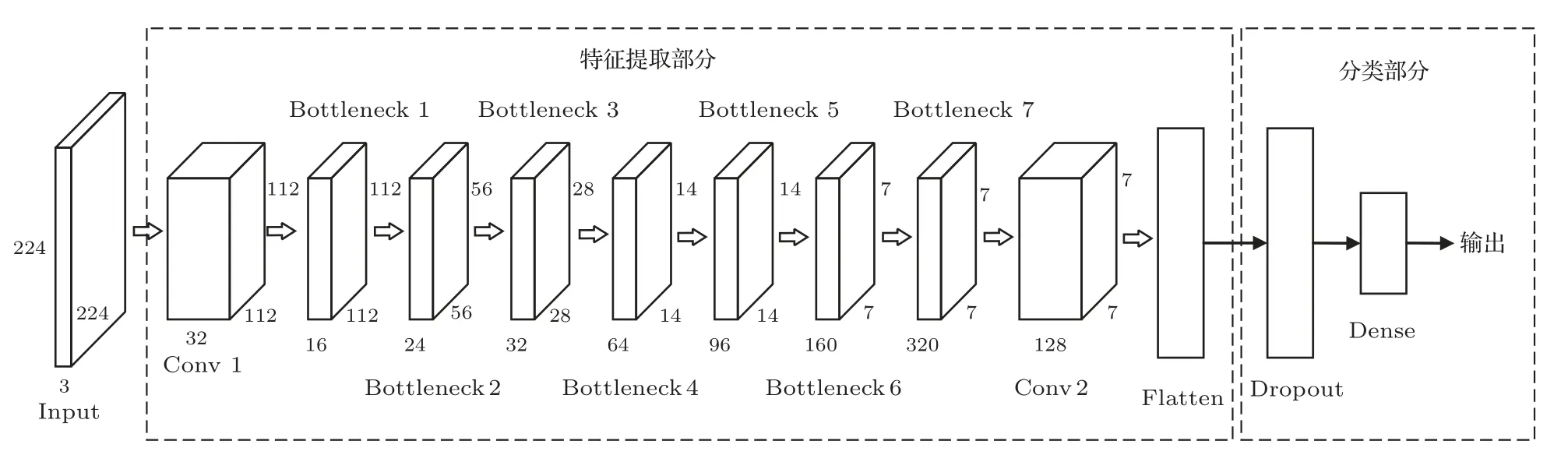
图3 改进Mobilenetv2 网络结构图Fig.3 Network structure of improved Mobilenetv2
网络的参数量和计算量作为两个重要的指标,通常用来对网络模型的复杂度进行评估,参数量对应的是算法的空间复杂度,表示对计算机内存资源的消耗;计算量对应时间复杂度,关系到网络的运算时间。参数量和计算量主要来网络中的自卷积层和全连接层,计算过程可以表示为

其中,P和F分别代表模型的参数量和计算量,下标cnn 和dense 分别表示卷积层和全连接层,Ml和Kl分别表示输入图片的尺寸和网络使用的卷积核大小,Cl−1和Cl为卷积运算中输入、输出特征图的通道数,D1、D2为网络中的卷积层与全连接层个数。使用式(1)~(2)对原始及改进后的MobileNetV2网络模型进行复杂度计算,计算结果如表1所示。

表1 原始及改进MobileNetV2 网络复杂度Table 1 Network complexity of original and improved Mobilenetv2
MobileNetV2 网络模型需要训练的参数数量约为3.4 M,改进后网络模型的参数数量约为1.9 M,与原始网络相比,模型参数数量减少了近一倍。与此同时,改进的MobileNetV2 网络计算量为230 M,相比原始网络的计算量也有一定数量的减少。由此可见,改进后的网络复杂度有所减小,能够提高网络运算效率,进一步节约计算资源。
2 声光图像融合分类网络
声学图像能够大范围获取,效率较高,光学图像的高分辨率能够实现对目标细节的描述。为了实现二者的优势互补,提出一种声光图像融合分类网络模型。目前,对异源图像的联合处理网络主要有输入前融合和输入后融合两种[19],前者是将图像进行融合处理后再输入特征提取网络,此种方式通常需要改变第一层卷积的数量,使得训练结果变差;后者是对图像进行特征提取之后,将特征提取网络的中间层信息融合[20],能够保证网络训练的准确性。
本文使用输入后融合的思想,将水下目标的声、光两种图像并行输入网络进行特征提取,在某一层将两个模块输出的特征图进行融合,实现两种图像的信息交流。特征提取使用的网络主干为1.2 节中改进的MobileNetV2 网络,在网络的特征提取过程中,图像的原始信息更多地体现在网络的浅层特征当中,网络的深层特征较为抽象,具有更多的分类信息。因此,根据网络的结构特点,本文选择在网络的深层位置进行特征融合,将网络最后一个卷积层的输出作为待融合特征,使用融合操作的结果实现水下目标分类,从而达到更高的分类准确率。
融合分类网络模型如图4所示,该网络由特征提取、特征融合、融合特征提取、分类4 个部分组成。声学图像和光学图像分别送入改进的MobileNetV2网络,特征提取部分包括一个普通卷积、具有反向残差结构的深度分离卷积及其之后的卷积层。在网络的最后一个卷积层位置,将输出的特征图按通道对应实现特征融合,这里应用的融合算法是通道拼接(concatenate),融合过程的数学表达式为

图4 基于改进MobileNetV2 的融合分类网络Fig.4 Fusion classification network based on improved Mobilenetv2

其中,Xoptical和Xacoustic表示输入的光学图像和声学图像;和表示光学图像和声学图像从输入到最后一个卷积层之间的特征提取网络;H2代表融合操作的通道拼接算法;output 为融合后输出的新特征,用以实现目标分类。分类过程可以表示为
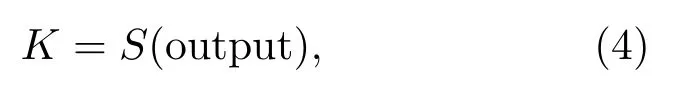
其中,K为分类结果,S代表Softmax 分类函数,将网络最后一层的输出转化为输入图像属于各类别的概率,公式为

3 数据获取及预处理
水下目标声图由成像声呐获得,三维成像声呐具有图像的深度信息,同时可以获得更清晰的目标轮廓[21],因此使用前视三维声呐获取声图。本文所用的水下目标数据集由千岛湖实验获得,实验装置布放如图5所示。数据采集装置由一个绿激光水下摄像机和一个前视三维声呐组成,二者成对获取水下目标图像。其中,绿激光水下摄像机型号为WWA-6226,波长为532 nm,分辨率1920×1080,最大可视范围设置为8 m;声呐设备为高频三维成像声呐,工作频率为300 kHz,带宽30 kHz,波束开角45◦,波束数目为128×128,实验过程中最大工作深度设置为30 m。
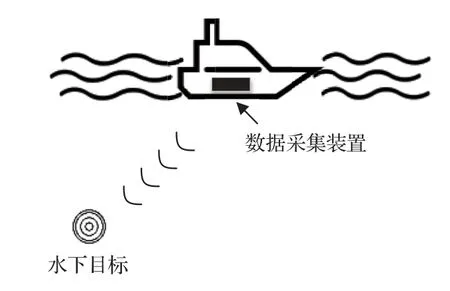
图5 实验装置布放图Fig.5 Layout of experimental apparatus
三维成像声呐得到的数据为三维图像,携带方位、距离和散射强度等信息。数据获取过程中,受水下复杂环境以及设备自身限制的影响,可能包含一定的噪点,首先使用式(6)所示过程对归一化后的原始数据进行滤波处理。
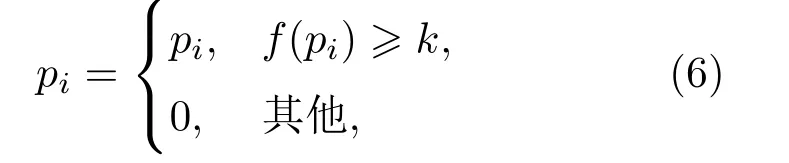
其中,pi=(xi,yi,zi)为三维图像中每个点的坐标,f(pi)为该点的散射强度,k为滤波阈值。将原始三维图像及滤波后的图像以点云形式进行可视化,效果如图6所示。
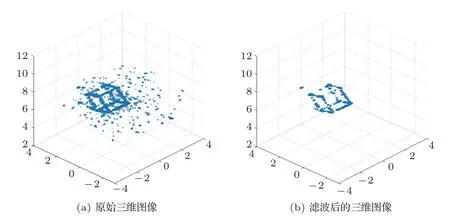
图6 水下三维图像可视化效果图Fig.6 Visualization of underwater 3D image
为了方便数据处理,将三维图像距离向上散射强度最强的点投影到二维平面,用其深度值作为该点的像素值,得到目标的深度图。将摄像机拍摄的图像作为光学图像数据集,三维图像处理后得到的深度图作为声学图像数据集。两个数据集中的图像成对存在,数据格式为三通道RGB图像,共2196张,包括铁框、蛙人、绳子、绳子拖曳的小球、桥墩5类水下目标,部分数据集图像如图7所示。

图7 部分实验数据集图像Fig.7 Images of some experimental data sets
4 实验结果与分析
为了验证所提网络在水下目标分类任务中的可行性,设计了以下实验。首先采集水下目标图像,制作实验数据集。(1) 在光学图像数据集上进行实验,对比VGG16、Resnet50、MobileNetV2以及改进的MobileNetV2网络对5种水下目标的分类性能,验证了改进MobileNetV2 网络在水下目标分类任务中的适用性;(2) 利用改进的MobileNetV2 网络以及提出的声光图像融合分类网络模型对水下目标进行分类,验证融合网络结构对水下目标分类准确率的提高;(3) 使用不同融合算法在不同位置进行融合,利用融合网络对目标图像进行分类,讨论融合位置及融合算法对分类准确率的影响;(4)在数据缺失的条件进行融合网络的分类实验,记录网络的分类准确率,验证网络的鲁棒性。以下实验使用的所有网络均基于Keras 深度学习框架搭建,并利用CUDNN进行加速处理。实验计算机CPU 为6核i7-10750H、Win10操作系统、GPU为RTX2070。
在采集的5 类水下目标图像中,随机抽取20%的目标数据作为测试集,余下的作为训练集。为了确保目标分类的准确性,在抽取数据时需要将声学图像和光学图像数据一一对应。训练集和测试集的样本组成如表2所示。
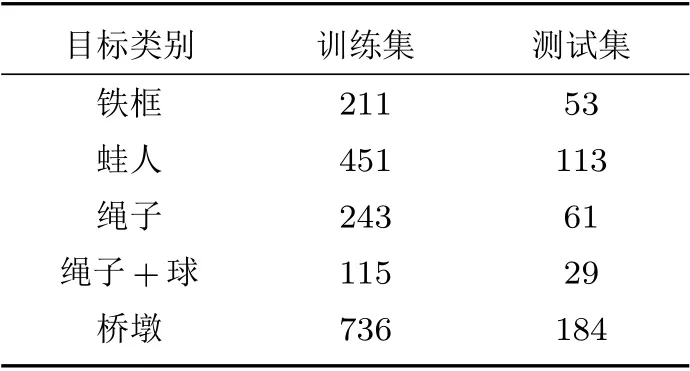
表2 训练集和测试集样本数量Table 2 Sample number of training set and test set
4.1 不同分类网络在本文数据集上的分类性能
分别使用VGG16、Resnet50、MobileNetV2 以及改进的MobileNetV2 网络对本文数据集(以光学图像为例)进行分类,验证几种分类网络对水下目标的分类性能。将水下目标图像输入网络进行训练和测试,在网络训练前,应用高斯分布G(µ,σ2)对网络中的所有参数进行随机初始化,其中µ=0,σ=1。采用Optimizers 优化器对整个网络的参数进行优化,学习率设为0.00001。在训练数据中每次随机抽取16张图像训练网络,迭代次数为100,网络采用代价函数选用分类交叉熵。几种模型的分类结果可见表3,其中,分类时间是测试过程中对一张图像得出分类结果所用的平均时间。
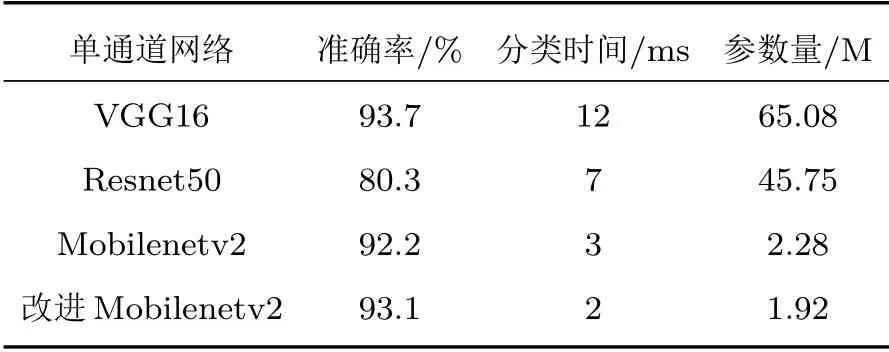
表3 目标分类网络性能比较Table 3 Comparison of performance of target classification network
由表3可以看出,分类准确率最高的是VGG16网络,可以达到93.7%,但是其分类时间最长,参数量最大,计算代价较高。Resnet50 网络的分类时间和计算代价有所减少,但分类准确率较低,MobilenetV2网络与之相比准确率有所提高,在参数量上也具有一定优势。综合考虑分类准确率、时间、参数量几种指标,MobilNetV2 网络要优于另外两种网络模型。相比于原始MobilNetV2网络,改进后的网络得到的分类准确率更高,且分类时间、参数量均有减小,说明本文做出的改进对模型性能有一定的提升,更加适用于水下目标分类任务。
4.2 融合前后网络性能比较
分别使用改进的MobileNetV2 网络对声学图像和光学图像进行分类,之后应用本文提出的融合分类网络将对应的声学图像和光学图像成对输入网络进行训练和测试,对水下目标图像进行分类。网络超参数的设置均与前述实验一致,训练过程曲线如图8所示。
由代价函数变化曲线可以看出,几种模型的函数值在整个训练过程中不断下降,最终都逐渐趋于平稳,改进后的MobileNetV2 网络在两个数据集上具有较小的损失值,融合网络的损失值最小,相比单通道的分类网络具有更好的性能。图8(b)为训练过程不同分类模型的分类准确率变化曲线,将测试集输入训练好的网络进行分类,检验模型的分类性能,改进前后与融合网络在本文数据集上的分类准确率如表4所示。
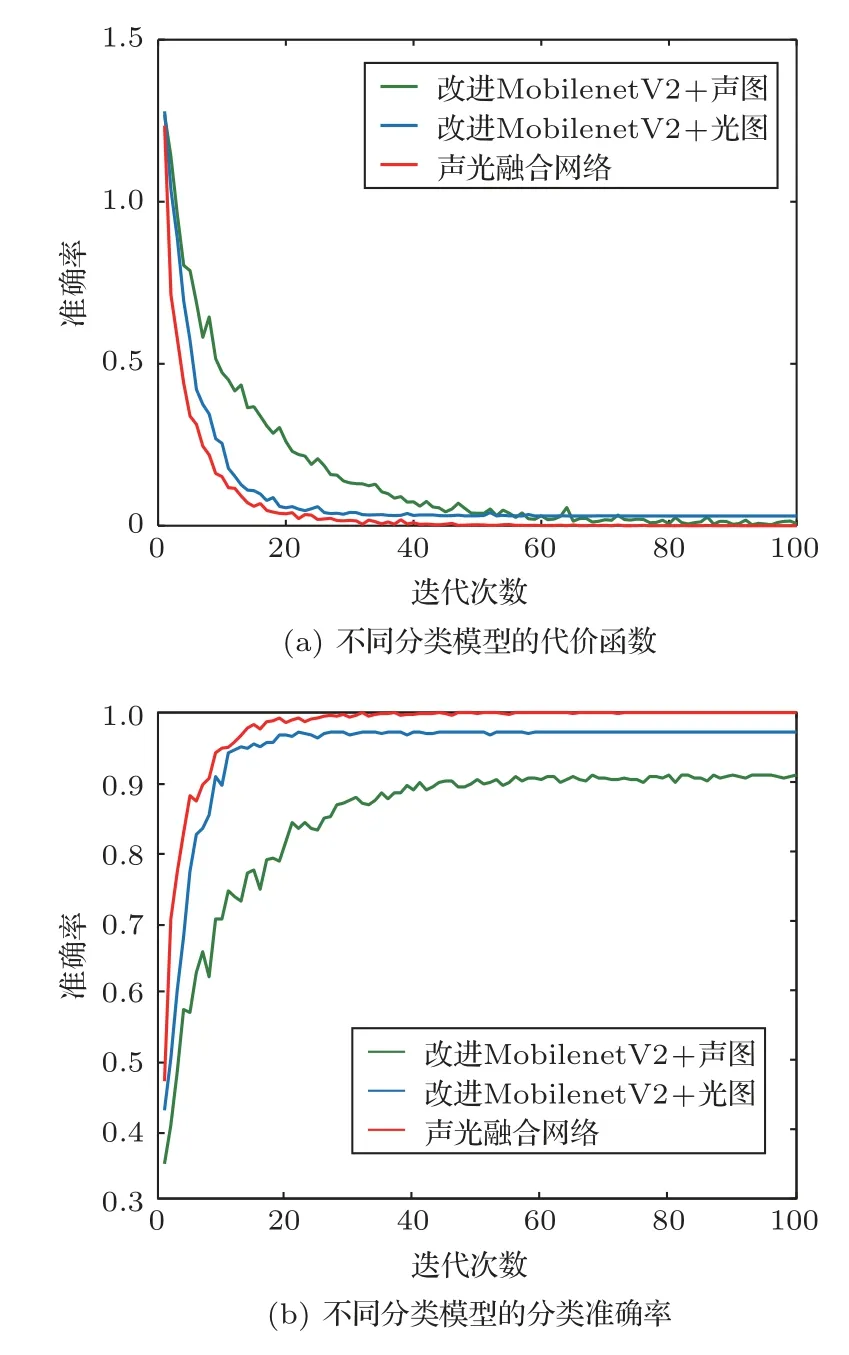
图8 训练过程变化曲线Fig.8 Change curve of training process
由表4可以看出,改进MobilNetV2 网络对两种图像的分类准确率分别为87.9%和93.1%,网络模型的拟合情况较好,能适应水下目标分类的小样本数据。本文提出的融合分类网络对水下目标图像的分类准确率达到96.5%,相比融合前的网络模型对声学图像和光学图像的分类准确率分别提高8.6%和3.4%,具有良好的分类性能。
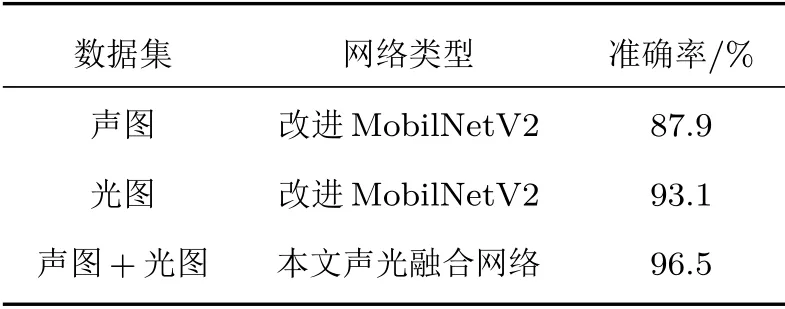
表4 不同网络的分类准确率Table 4 Classification accuracy of different networks
4.3 不同融合方式下网络性能比较
本文在对声光图像进行融合时使用的算法是通道拼接(concatenate),在网络的深层位置进行特征融合。除此之外,融合算法还包括直接叠加(add)、最大化运算(maximum)等,融合位置也可以选在网络的浅层部分。分别使用add、maximum、concatenate三种融合算法,在改进MobileNetV2网络的第一个卷积层后进行特征融合,将该融合网络记为浅层融合网络,本文提出的融合网络记为深层融合网络,利用声、光学图像分别在两种融合网络上进行实验,训练过程代价函数及准确率的变化如图9所示。

图9 融合网络训练过程变化曲线Fig.9 Change curve of fusion network training process
两种融合网络在不同的融合算法下代价函数值均下降并收敛,融合算法的选择对网络性能的影响不明显,深层融合网络的收敛速率更快。将测试集数据输入训练好的融合分类网络,得到最终分类结果,融合网络对水下目标的分类结果可见表5。
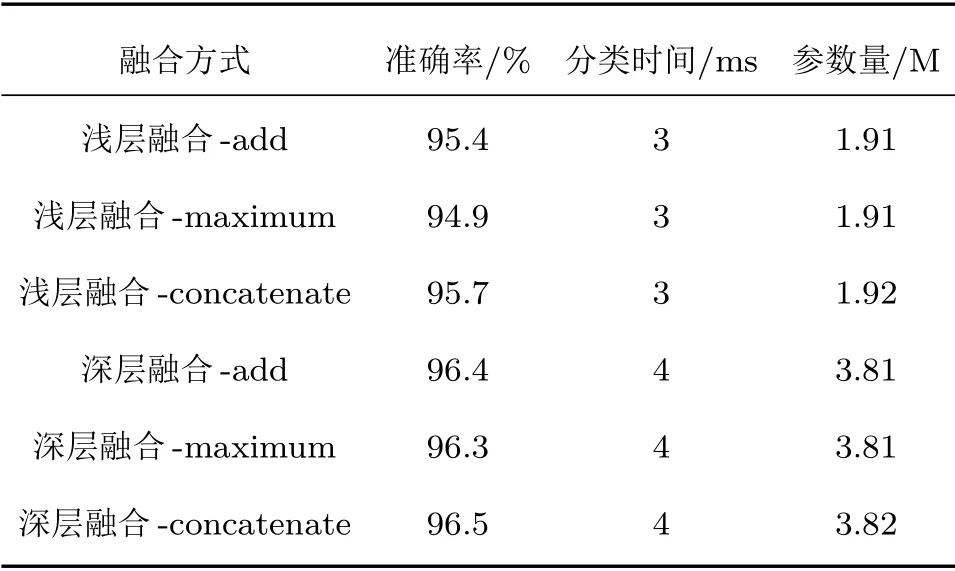
表5 不同融合网络对本文数据集的分类性能Table 5 Classification performance of different fusion networks on the dataset in this paper
由表5可以看出,浅层融合和本文提出深层融合的平均准确率分别达到95.3%和96.4%,相比使用单通道网络对水下目标图像的分类准确率均有明显提高,深层位置的融合网络分类准确率更高。由于深层融合需要的参数更多,运算成本也略有增加。同一融合位置下不同融合算法的选择对分类结果的影响较小。
4.4 融合网络鲁棒性实验
在实际水下应用中,由于水下摄像机和声呐的作用距离不同,远距离条件下只有声呐能够获取到有效数据,且水下环境的复杂性及实验过程的各种不可控因素可能会导致其中一台设备无法正常工作。考虑到最差的情况,假设其中一台设备失效,将该设备获得的图像记为一个全0 数组,另一设备获得的为正常图像,将其输入本文的融合网络进行测试,两种情况下不同数据集在网络中的分类结果如表6所示。

表6 不同数据集下的融合网络分类准确率Table 6 Classification accuracy of fusion networks under different data sets
由表6可以看出,在光图缺失的情况下,融合网络的分类准确率为85.7%,声图缺失情况下的分类准确率达到90.3%,相比正常数据下的分类准确率有所降低,原因可能是融合后的特征图中包含无效数据,对网络具有一定干扰作用。由此可见,当一台设备失效时,融合网络的分类准确率会受到一定影响,但是最低仍能达到85%以上,而普通的单路网络在此种情况下会失去分类能力,说明本文提出的融合网络具有一定的容错能力和鲁棒性。
5 结论
本文主要以下从两个角度改善网络的分类性能,以适应小样本条件下的水下目标分类任务。首先,将改进的MobilenetV2 网络作为基础网络,以减小网络训练过程的计算开销和内存占用,使用实验采集的真实数据进行网络训练,改善网络拟合效果。其次,将改进网络作为融合网络的分支,使用中间层融合策略将水下目标的声、光学图像特征图进行融合,实现各自的优势互补,进一步提高分类准确率。实验结果表明,与其他常用分类模型相比,MobilenetV2 网络的分类准确率较提高,在参数量上和分类时间上也具有一定优势。改进的MobilenetV2 网络与原网络相比,参数量及计算资源消耗减少,分类准确率进一步提高,在水下目标分类任务中具有更好的性能。相比融合前的网络,融合网络模型的学习曲线收敛更快,且准确率更高,在add、maximum、concatenate三种融合算法下,融合网络的分类准确率均有不同程度的提升。在单路数据缺失的情况下,融合网络的分类准确率仍能达到85%以上,具有一定的鲁棒性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
