
基于超分辨率特征融合的工件表面细微缺陷数据扩增方法
2022-07-07 08:22刘孝保阴艳超
计算机集成制造系统 2022年6期
刘孝保,刘 佳,阴艳超,高 阳
(昆明理工大学 机电工程学院,云南 昆明 650500)
0 引言
表面细微缺陷影响着工件产品的使用性、外观性和舒适性[1],因此表面细微缺陷检测成为工件缺陷检测的重要工作之一。近年来,针对工件缺陷检测的方法主要有传统物理检测方法与计算机视觉检测方法,其中传统物理检测方法主要解决工件内部缺陷问题,对操作人员的专业技能要求较高,且仅适用于部分材料工件;计算机视觉检测方法主要包括深度学习检测方法和传统数字图像处理方法等[2],该方法具有实时性、非接触性、客观性等特点。针对传统数字图像处理方法,赵君爱等[3]提出一种基于像元搜索算法的微小缺陷检测方法,用于分割弱小缺陷目标;刘磊等[4]利用主成成分分析法对缺陷图像特征数据进行降维计算获得新的主成分,并采用支持向量机(Support Vector Machine, SVM)建立制动防抱死系统(Antilock Brake System, ABS)齿圈缺陷检测模型;WIN等[5]针对镀钛表面小裂纹缺陷,改进Otsu阈值调节方法,对镀钛铝表面进行自动检测;冯毅雄等[6]利用缺陷特征完成轴件表面形貌重构,消除了水渍伪缺陷对检测过程的影响;JIAN等[7]采用基于轮廓的配准方法,实现移动过程中震动状态的手机玻璃屏(Mobile Phone Screen Glass, MPSG)图像对准,并结合减法与投影完成对MPSG图像缺陷的识别。上述几类传统数字图像处理方法对表面缺陷检测均存在预处理数据量大、识别精度不高、鲁棒性不强等问题。针对基于深度学习的缺陷检测,虢韬等[8]通过构建快速深度卷积神经网络(Faster Region-based Convolutional Neural Network, Faster-RCNN)网络模型识别绝缘子自爆缺陷;范佳楠等[9]通过构建Faster-RCNN识别工业CT图像缺陷;AKRAM等[10]针对光伏组件缺陷,采用光卷积神经网络(Convolutional Neural Network, CNN)实现其缺陷的自动检测,同时根据策略推广模型预测特定缺陷类型;李宜汀等[11]针对油辣椒灌装生产线的封盖面缺陷检测,在预处理阶段裁剪缺陷主体,然后融合稀疏滤波,通过提取多重特征输入卷积神经网络获得缺陷识别模型;郭亚萍等[12]基于SegNet网络重构表面缺陷检测问题,利用编码—解码结构实现特征的像素级分类。常用的深度学习表面缺陷检测模型对特征表征能力强、易于学习的明显特征具有较好的检测识别能力,而对缺陷目标在整张图像中像素占比小、信噪比极低、背景与目标特征区分不明显的细微缺陷,虽然可以增加网络深度和复杂性来获取更优的学习能力与模型效果,但是总体学习效果仍然欠佳,模型能效比有待提升。
为此,针对工件表面细微特征难以识别的问题,本文构建了一种基于超分辨率特征融合的数据扩增模型(data Amplification model for Super-Resolution feature Fusion, SRF-A)。该模型集成基于图像修复与图像融合的数据扩增,并融入图像超分辨率机制,形成包括缺陷样本数据层(Data)、超分辨率特征提取与样本修复层(Super Resolution-image Repair, SR-Re)、数据扩增层(data Merge-Amplification,M-A)的3层模型结构,着重解决了表面细微缺陷检测模型构建困难、图像特征不明显、工业应用困难的问题,为工件表面细微缺陷检测提供了一种新的思路与方法。
1 工件表面细微缺陷分析
表面缺陷检测是零件加工过程中必不可少的环节。因为表面缺陷以工件为载体,而工件工艺流程多样,生产环境复杂,表面缺陷种类繁多且成因各不相同,所以工件表面细微缺陷具有如下特点:
(1)图像特征不明显 图像特征主要包括颜色特征、纹理特征、形状特征和空间关系特征。针对细微缺陷,其颜色特征不明显,颜色直方图中细微缺陷的色彩像素点全局占比极小;在纹理特征上,纹理特征所表示的物理表面特性中,细微缺陷对图像纹理改变较小,且由于图像分辨率的原因,相同图像在不同分辨率下对特征的纹理表征偏差较大,二维图像对三维表面的表征会因图像分辨率等特性而出现失真;在形状特征上,细微缺陷区域的边界非常接近,因此,描述缺陷的轮廓特征和区域特征比较困难,常用的边界描述法、傅里叶形状描述法、几何参数法均因区域边界影响而不能很好地对其形状特征进行描述;在空间关系特征上,细微缺陷姿态不清晰,图像内容描述区分能力差,容易受噪声影响。因此,可采用图像超分辨率技术,通过增强细微缺陷特征来提高其表征能力。
(2)检测模型构建困难 常规卷积神经网络模型由卷积层、池化层、全连接层构成,其模型的构建过程实际上是特征学习与参数更新的过程,卷积层与池化层用于提取特征的高级表征,需要大量的训练数据,而且训练数据应该标签清晰、特征突出,而细微缺陷因为在图像中的特征占比小,图像特征模糊,所以在神经网络的学习过程中对细微缺陷特征的学习能力较弱,且训练过程不易收敛,模型参数更新困难。因此,可通过超分辨率特征融合来强化细微缺陷的结构与纹理信息,增强检测模型对细微缺陷图像特征的学习能力。
(3)检测(应用)困难 传统工件表面细微缺陷检测方法对操作人员技术水平和检测设备要求较高,但对细微缺陷检测的效果欠佳,因此现代工业对具有无接触性、准确率高、客观快速、自学习等特性的计算机视觉检测需求极大,然而细微缺陷具有图像特征不明显、样本获取困难与模型构建困难等特点,限制了其应用。为此,通过建立超分辨率特征融合数据扩增模型,在强化细微缺陷的结构与纹理信息的同时,增强神经网络的学习能力和模型构建能力,提高了工业应用的场景适应性与检测模型能效比。
2 基于超分辨率特征融合的数据扩增模型
针对工件表面细微缺陷检测中存在的问题,本文提出基于超分辨率特征融合的数据扩增模型(SRF-A),该模型重点解决了工件表面细微缺陷的检测模型构建困难、检测精度差、分类不准确问题,模型结构如图1所示。
SRF-A由Data层、SR-Re层和M-A层3层结构构成,其中:Data层负责划分初始样本,输入原始数据,输出包括表面细微缺陷的工件图像样本数据,并作为SR-Re层的输入;SR-Re层用于提取图像特征的超分辨率和修复原始样本,从而增强表面细微缺陷图像特征的超分辨率并获取无缺陷样本ND-S;M-A层通过融合SR-Re层提取的超分辨特征和无缺陷样本实现数据扩增。
深度学习模型的实际应用效果不仅取决于其模型本身的合理性,还取决于模型训练中的样本质量水平。由于工件表面细微缺陷的隐蔽性,容易在深度学习训练的采样过程中忽略细微特征而降低细微特征的学习能力。因此,SRF-A针对工件表面的细微缺陷特征,利用超分辨率特征融合对细微缺陷的超分辨率进行复原,在数据上强化细微缺陷的图像特征表示,并通过融合无缺陷样本,丰富细微缺陷的背景,完成数据扩增,提高常规深度学习模型对细微缺陷特征的更新学习和分类检测能力。在实际的工件表面缺陷检测过程中,采用本模型对训练数据进行预处理,能够丰富模型的训练数据、突出细微类别的图像表征,从而增强检测模型的构建能力,提升总体检测精度和分类准确率。
2.1 Data层样本划分
实验数据样本为单缺陷图像(即一张图像只包含一类标签特征),而SRF-A只针对细微缺陷样本,因此模型Data层需要将样本划分为细微缺陷和非细微缺陷,并将细微缺陷样本作为Data层输出。
划分样本时,需要提取图像中的缺陷特征区域,并计算缺陷特征区域最小外接矩形在整张图像中的像元占比,计算步骤为:首先完成样本的预处理裁剪,减少样本中无关背景的干扰;然后用灰度直方图阈值分割技术分割缺陷特征区域;提取分割后的缺陷特征区域,并统计缺陷区域外接矩形中的像元数量,计算缺陷区域像元数量占图像像元总数的比值,即缺陷特征区域像元占比。
将实验经验值0.333%作为样本中的细微缺陷划分标准,缺陷特征区域像元占比小于0.333%的样本划分为细微缺陷样本,否则划分为非细微缺陷样本。
2.2 样本修复
样本修复是指对样本中不符合正常样本数据概型分布的噪声数据进行修复与替代,使数据的分布特性更加接近自然数据[13],在SRF-A中,SR-Re层中并行结构右侧的样本修复模块(Re)通过修复Data层中样本图像的细微缺陷,为M-A层提供无缺陷样本ND-Si(i=1,…,n)。采用快速行进法[14](Fast Marching Method, FMM)修复工件表面细微缺陷的小尺度图像的原理如图2所示。

图中A为缺陷样本中的缺陷特征区域,∂A为缺陷区域边界,p为边界上一点,Bε(p)为点p的邻域,q为Bε(p)内部一点。对Bε(p)区域内部像素点进行加权平均以估算p点像素值,即:
R(p)=
(1)
G(p)=
(2)
B(p)=
(3)
式中:R(p),G(p),B(p)分别为彩色图像红、绿、蓝三通道的p点像素值;ω(p,q)为加权函数,用于衡量待修复像素点与相关邻域像素点的相关性,像素点距离p点法线方向越近,对p点像素修复贡献的权值越大,
ω(p,q)=direction(p,q)·distance(p,q)·
level(p,q),
(4)
式中:direction(p,q)为方向权值,保证距离p点法线方向越近的邻域像素点,对p点像素修复结果产生的影响越大;distance(p,q)为距离权值,保证距离p点越近的邻域像素点,对p点像素点修复结果产生的影响越大;level(p,q)为水平集距离权值,保证距离待修复区域越近的邻域像素,对待修复区域像素点修复结果的影响越大;d0和T0,分别为距离参数与水平集参数,d0=1,T0=1;T为缺陷特征区域像素点距离该区域边缘最短的距离。
2.3 超分辨率特征提取
因为细微缺陷特征不易识别,所以构建缺陷检测模型需要对细微缺陷的图像数据进行超分辨率重建,以保证缺陷特征在CNN的下采样训练过程中不会丢失。细微缺陷在图像中像元的占比虽然小,但是细微缺陷内部具有丰富的纹理与结构信息,如果直接采用线性插值法进行细微缺陷的超分辨率重建,则重建图像虽然尺寸较大,但是会丢失细微缺陷大部分的结构和纹理信息,为此采用超分辨率生成式对抗网络[15](Super-Resolution Generative Adversarial Networks, SRGAN)对细微缺陷进行超分辨率重建,较好地恢复了细微缺陷内部的结构和纹理。超分辨率特征提取(Super-Resolution Feature Extraction, SR-FE)模型结构如图3所示。
低分辨率图像生成高分辨率图像的原理是将训练集中的高分辨率图像与其对应的低分辨率图像作为训练数据,学习低分辨率图像到高分辨率图像的关系映射,并通过网络模型储存该类映射关系。超分辨率重建图像是通过学习到的映射关系,利用低分辨率图像生成高分辨率图像。
SR-FE模型首先提取缺陷样本(Si,i=1,…,n)中的缺陷特征(Fi,i=1,…,n)区域,输入SRGAN中的生成模型G-Model,完成对SRGAN的训练。将原始高分辨率缺陷样本作为真实数据输入SRGAN中的判别模型D-Model,对原始高分辨率缺陷样本进行图像四倍下采样,获得高分辨率缺陷样本对应的低分辨率缺陷样本,再将低分辨率缺陷样本输入SRGAN中的生成模型,生成超分辨率缺陷样本,并将其作为虚假数据,将原始高分辨率缺陷样本与虚假数据同时输入判别模型,利用SRGAN的博弈和反馈过程对生成模型和判别模型的参数进行更新。利用生成模型已经学习到的样本映射关系,将缺陷特征输入生成模型生成对应的超分辨率特征SR-Fi,完成对样本中细微缺陷超分辨率特征的提取。SRGAN的目标函数为
(5)

通过高分辨率缺陷数据训练生成模型,通过注意力矩阵tn(n=1,…,N)提取样本Sn中的缺陷特征fn,将fn作为生成模型的输入,输出四倍超分辨率缺陷特征SR-Fn,
SR-Fn=GθG(fn);
(6)
fn=Sn×tn。
(7)
式中:SR-Fn为超分辨率缺陷特征;GθG为已完成训练的生成模型;Sn为缺陷样本。
注意力机制的数学描述为从输入集合中获取特定子集,软注意力机制意为生成与样本矩阵大小相同、内部元素数值介于0~1的注意力矩阵,硬注意力机制意为生成与样本矩阵大小相同、内部元素数值为0或1的注意力矩阵,本文采用硬注意力机制提取样本中的缺陷特征。
注意力矩阵tn通过迭代法分割获取全局阈值,具体步骤如下:
(1)针对本文数据预定义参数t=5,作为后续比较对象。
(2)随机设定初始分割阈值a(a∈[avergegray±20],averagegray为图像平均灰度值)。
(3)利用初始分割阈值a将原始图像样本分割为两组像素的集合,即背景与前景。
(4)分别计算前景与背景的平均灰度值a1,a2,随后计算a1和a2的平均值a3。
(5)计算a3与随机初始分割阈值a的差值T。
(6)比较T与(1)中的预定义参数t,若T>t,则用a3替代初始分割阈值a,重复(3)~(5),直到T≤t,结束迭代,获取最优阈值[16]。
执行最新阈值分割前景和背景,获取注意力矩阵,如图4所示。图4b中分割出的前景在注意力矩阵中所有位置的值为1,背景在注意力矩阵中所有位置的值为0。

2.4 基于图像融合的数据扩增模型
数据扩增通过对原始数据进行一系列变换生成更多样本数据来增加样本数据的多样性、提高模型泛化能力。CNN训练学习图像特征需要大量训练数据,训练数据中的图像特征通过卷积池化等数学操作压缩提取,由于表面细微缺陷的图像特征不明显、像素占比小,容易在降采样过程中丢失细微特征,造成分类不准确、学习效率低下。本文采用超分辨率提取工件表面的细微特征,融合扩增修复样本与超分辨率特征,使表面细微缺陷数据不易在训练过程中丢失,从而提高模型对表面细微缺陷的学习能力,并提高模型分类的效果。基于图像融合的数据扩增(Data Merge Amplification, DMA)模型结构如图5所示。

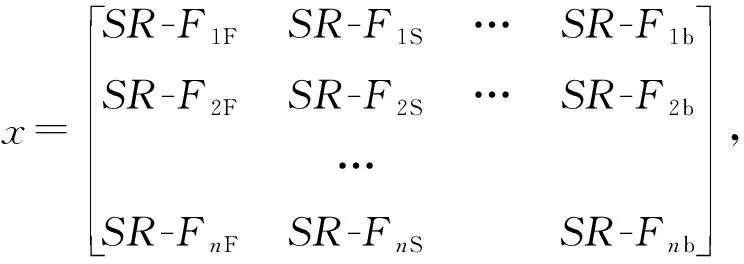
DMA模型属于SRF-A模型中的第3层M-A层,上接SR-Re层。DMA模型分为超分辨率特征层、单样本扩增层、无缺陷样本层、融合位置参数层、泊松融合层和新样本层。其中超分辨率特征层以图1中SR-Re层的SR-FE模型输出的超分辨率缺陷特征SR-Fi为输入数据;无缺陷样本层以SRF-A中SR-Re层的样本修复模块(Re)输出的无缺陷样本为输入数据s=[ND-S1,ND-S2,…,ND-Sn]T;融合位置参数层中位置参数position的选择可以丰富图像融合后的数据表征,属于图5 的内部结构参数,并不通过SRF-A的前两层获取;泊松融合层位于新样本层之前,属于泊松(Poission)图像融合关键算法区域,连接DMA模型融合位置参数position-i、SRF-A模型第2层产生的超分辨率缺陷特征SR-Fi和无缺陷样本ND-Si。
DMA模型首先以超分辨率缺陷特征SR-Fi作为输入数据,通过单样本扩增技术(图像翻转Flip、图像旋转Spin、…、图像模糊blurry)对超分辨率缺陷特征SR-Fi进行变换,获取变换数据x,在无缺陷样本中选择融合位置参数position-i(i-1,…,n),然后通过泊松图像融合[17]将无缺陷样本层数据s=[ND-S1,ND-S2,…,ND-Sn]T与单样本扩增数据x根据融合位置参数position-i进行超分辨率特征融合,获得扩增样本层数据d,
di,j=poisson(xi,j,si,1,position-i)。
(8)
2.5 工件表面细微缺陷数据扩增流程
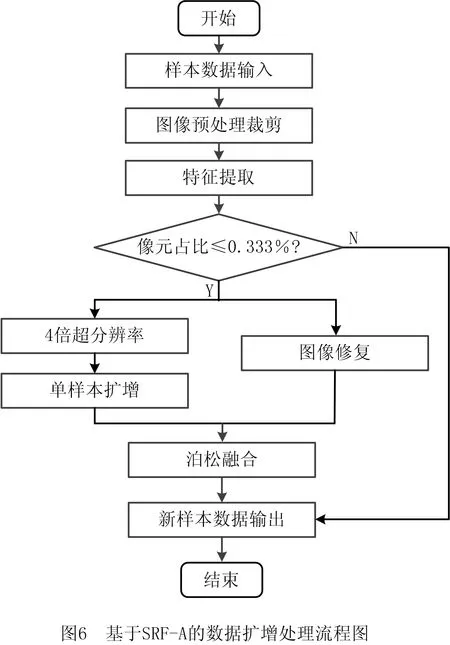
对于工件表面缺陷样本数据,原始样本空间存在数量较少的细微缺陷类别样本,导致样本空间不均衡,而且细微缺陷特征的像元在图像中占比过小,神经网络在训练过程中多次下采样后,细微缺陷的特征将被特征图丢失,导致分类模型构建失败,因此采用SRF-A处理初始数据,生成新样本空间。扩增流程如图6所示。
数据扩增具体步骤如下:
步骤1将原始铝型材待分类数据输入模型作为初始样本空间。
步骤2通过对原始样本数据进行预处理裁剪,去除大多数无关环境噪声的影响,获取工件主体部分以及主体部分所承载的表面缺陷特征。
步骤3采用图像阈值分割方法对步骤2经过预处理裁剪获取的图像进行目标缺陷的图像分割,获取缺陷区域。
步骤4通过多次实验确定像元占比判别阈值为0.333%,计算步骤3获取的铝型材表面缺陷像元数量与图像总体像元数量的比值,即表面缺陷区域的像元占比,并与0.333%比较,将像元占比小于等于0.333%的缺陷样本划分为细微缺陷样本,将像元占比大于0.333%的缺陷样本划分为非细微缺陷样本。
步骤5判定为细微缺陷样本的数据将通过左侧并行通路,分别进入并行通路的左侧分支与右侧分支。左侧分支对细微缺陷样本在步骤3获取的细微缺陷进行四倍超分辨率特征复原,并采用旋转、平移、噪声添加等单样本扩增技术,对细微缺陷的四倍超分辨率特征进行数据扩增;右侧分支修复缺陷区域的细微缺陷样本数据,获得无缺陷样本。判定为非细微缺陷样本的图像直接通过右侧通路,不进行任何操作。
步骤6将步骤5中右侧通路生成的无缺陷样本与左侧通路生成的细微缺陷四倍超分辨率特征进行泊松图像融合,获取包括超分辨率细微特征前景与铝型材工件背景的新样本。
步骤7接受步骤4判定的非细微缺陷样本和步骤6生成的融合数据新样本,获取包括超分辨率细微缺陷的新样本空间数据。
3 实验分析
为验证SRF-A对提升工件表面细微缺陷检测精度的有效性与可行性,使用铝型材常见表面缺陷数据集(https://tianchi.aliyun.com/competition/entrance/231682/information),选择数据集中的5类样本(脏点、凸粉、碰凹、擦花、无缺陷)作为实验数据。由于原始比赛数据存在标注错误,手动更正错误后,获取5类样本的数量分别为擦花26张、碰凹20张、凸粉64张、脏点54张、无缺陷42张,样本如图7所示。

3.1 实验数据准备
原始样本的小样本与非均匀状态会影响模型拟合和训练结果[18-19],因此需要采用数据扩增方法消除原始样本空间的不均匀分布,下面分别采用普通数据扩增方法与本文数据扩增方法进行实验数据的扩增与准备:
(1)普通数据扩增 首先采用普通数据扩增方法对原始5类样本进行数据扩增,将每一类标签样本扩充至400张(包括4类原始样本),其中用到的扩增方法有旋转、平移、缩放、镜像,设置旋转角度不超过20°,平移距离不超过图像尺寸40%,缩放尺寸不超过原始图像尺寸的10%。
(2)本文数据扩增 将上述5类样本中的4类缺陷样本划分为细微缺陷样本和非细微缺陷样本,本文数据集图像的原始分辨率为2 560×1 920,单幅图像的像元总数为4 915 200。提取缺陷连通区域的最小外接矩形,并计算该矩形的像元数量,像元数量小于128×128=16 384的样本(即像元占比<0.333%)被划分为细微缺陷样本,利用本文SRF-A对细微缺陷样本进行数据扩增,非细微缺陷样本按比例采用普通数据扩增。在用SRF-A对细微缺陷区域进行超分辨率提取之前,需要对SR-FE模型中的超分辨率模块(SR)进行训练,本文采用5类标签样本共206张图像训练SR模块中的SRGAN。
首先切分206张原始样本,获得21 840张128×128分辨率图像(高分辨率图像),作为SRGAN中D-Model的真实数据输入;其次对128×128分辨率图像进行四倍下采样,生成32×32分辨率图像(低分辨率图像),作为SRGAN中G-Model的输入;最后将G-Model的输出作为SRGAN中D-Model的虚假数据输入,训练SRGAN模型生成四倍超分辨率图像。细微缺陷的四倍超分辨率效果如图8所示。

由图8可知,经过训练后的SR模型对缺陷区域进行超分后,较好地保留了图像色彩信息和纹理结构,而且在对非训练数据进行超分时,能够重建低分辨率图像。样本划分如表1所示,数据扩增情况如表2所示。

表1 样本划分统计
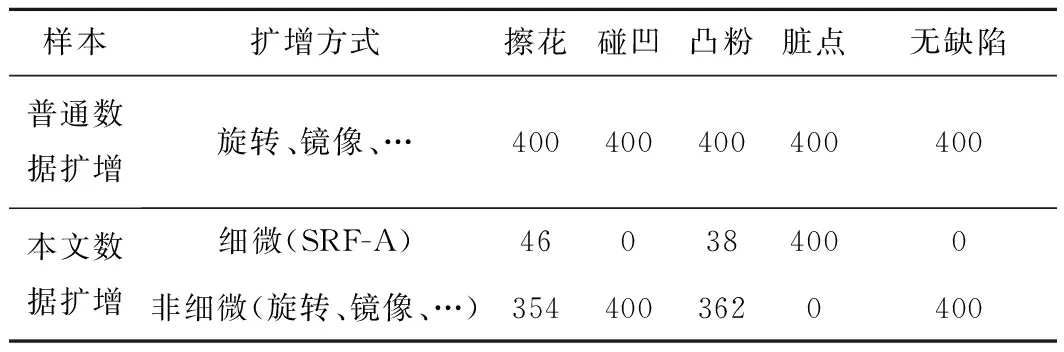
表2 数据扩增统计
3.2 实验环境搭建与网络构建
使用个人计算机为硬件平台,基于Windows 10操作系统,采用Keras平台作为深度学习后端(Keras版本为2.3.1),编程语言为Python 3.7.4。
采用经典CNN网络GoogLeNet和ResNet50分别构建两种分类网络,并通过多次实验调参优化数据模型参数,其网络参数设置如表3所示。
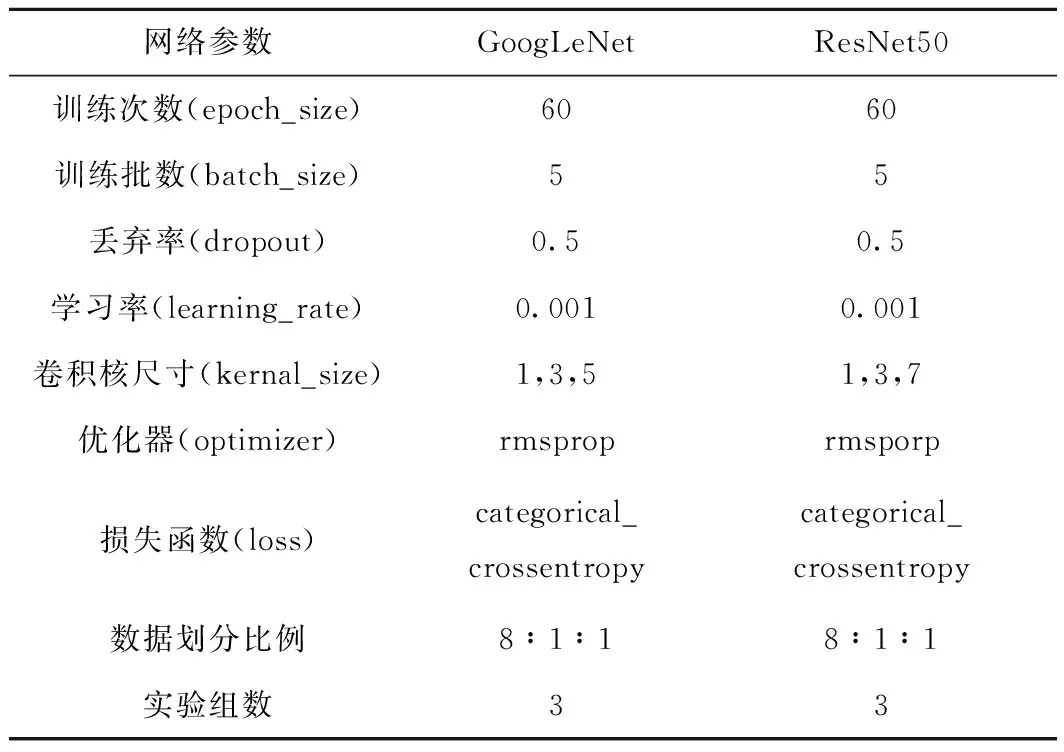
表3 神经网络训练参数设置
GoogLeNet网络于2014年提出,获得当年ImageNet挑战赛第一名,其能够以较小的参数量与相对更浅的网络层数获得更高的分类精度,具有其独特的优势。
ResNet网络于2015年提出,获得当年ImageNet挑战赛第一名,其通过残差学习的方式使得构建深层网络学习特征更加便捷。本文采用ResNet50网络结构构建50层残差网络。
3.3 实验验证与结果分析
为评估SRF-A的性能与有效性,根据文献[20]进行4.1节普通数据扩增与4.2节网络初始参数设置(训练周期为60、学习率为0.001,采用交叉熵损失函数),采用SRF-A进行3.1节的超分融合扩增。将3.2节构建的两种分类网络和3.1节准备的两种样本数据(普通数据扩增、超分融合扩增)对应的4种模型分别设置3组实验,共12组实验进行对比,实验标签1为擦花、2为碰凹、3为凸粉、4为脏点、5为无缺陷。最后分别取3组实验的平均值作图,平均准确率变化如图9所示,具体结果如表4所示。
从文献[20]可知,由于脏点这类小尺度缺陷的特征尺度细微且分布较广,网络对其识别能力较低。由图9可见,网络在训练20个轮次之前,两类方法的精度相差并不明显;在20个训练轮次之后,两类方法开始出现一定差异,本文方法的精度持续上升直至稳定,常规方法的精度提升效果不大。这是由于本文方法对样本中的细微缺陷进行超分辨率特征融合,使网络在20个训练轮次之后对数据仍然具有学习分类能力;常规方法则因细微缺陷样本在学习下采样过程中丢失了特征,导致与无缺陷样本区分时出现困难,而持续学习导致网络产生过拟合现象,降低了模型拟合非训练样本的能力。在GoogLeNet网络中,本文数据扩增方法的平均精度较普通数据扩增方法提高了8.1%;在ResNet网络中,本文数据扩增方法的平均精度较普通数据扩增方法提高了5.7%;结合表4单标签精度与表1样本划分统计,标签4脏点类缺陷的细微样本占比为100%,标签1擦花类缺陷的细微样本占比为11.5%,标签3凸粉类缺陷的细微样本占比为9.4%,这3类样本在GoogLeNet网络中的精度分别提升11.8%,10.5%,4.4%,在ResNet网络中的精度分别提升10.4%,7.8%,1.1%,可见细微样本占比与标签分类精度的提升有较为明显的相关性。
标签4为脏点类缺陷,在样本划分中全部属于细微缺陷,标签5为无缺陷样本,其采样特征图与细微缺陷卷积采样后的特征图相似性较高,因此在分类网络中标签4和标签5分类困难。采用本文方法处理后,标签4的精度提升最大,其次为标签5,而随着细微缺陷识别率的提高,网络对无缺陷样本的识别能力得到相应提升。
4 结束语
针对工业缺陷检测中表面细微缺陷检测存在的问题,提出一种基于超分辨率特征融合的工件表面细微缺陷数据扩增方法,该方法具有如下特点:①根据实验将缺陷特征像元占比0.333%为标准划分原始样本中的细微缺陷样本;②构建并行结构,分别融合SRGAN和图像修复,进行样本细微特征的超分辨率特征提取与无缺陷样本获取;③通过泊松融合进行图像扩增来丰富缺陷样本数据量,从而扩增细微缺陷样本数据,增强检测模型的泛化能力和学习能力,提高模型能效比。然而,本文方法在将细微样本的缺陷特征前景与无缺陷背景融合时,没有利用非细微缺陷特征背景丰富扩增后的样本,而且每类标签样本数据都服从其类间特有分布,因此下一阶段工作将融合Criminisi算法修复非细微缺陷样本图像,并利用类样本概率分布理论进一步支撑无缺陷样本与特征前景融合,优化样本结构,增强模型的学习能力和检测能力。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
杭州电子科技大学学报(自然科学版)(2022年4期)2022-08-23
智能制造(2021年4期)2021-11-04
河北北方学院学报(自然科学版)(2021年3期)2021-04-12
中学生数理化·高一版(2021年2期)2021-03-19
黑龙江科学(2020年4期)2020-04-08
家庭影院技术(2018年9期)2018-11-02
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
西南学林(2011年0期)2011-11-12
