
基于改进YOLO v5的非限定条件下车牌检测算法研究
2022-07-07 05:45贝新林
数字通信世界 2022年6期
贝新林
(亚信科技(中国)有限公司,江苏 南京 210000)
智能交通系统是将计算机视觉、GPS定位技术、电子信息技术和通信技术等相融合的管理系统,其中车牌识别[1]为交通管理系统提供了强有力保障,车牌识别系统通过采集大量的车辆图像,利用算法精准定位车辆的位置与大小、锁定车牌并识别出其中具体字符的一种图像处理技术。车牌识别系统可应用于各种场景,例如道路电子收费系统ETC、闸机车牌识别系统、智能停车场等。在这种光线充足、车辆位置较为固定、车速稳定的条件下系统更容易拍摄清晰稳定的图像,因此识别精度较高。相反,在一些光线不充足的场景,车辆位置不统一,车速较快会导致运动模糊,会导致识别精度不理想。因此如何找到一种普适条件下的高精度车牌检测算法是目前迫切需要解决的问题。
1 相关工作
传统的车牌识别方法包括图像获取、图像预处理、车牌检测、字符分割和字符识别五部分组成。传统方法一般基于特定场景识别,泛化能力弱。车牌识别技术本质上利用了CV领域中目标检测和OCR算法,基于深度学习的目标检测与OCR算法在实际应用中效果已经被证明好于传统机器学习算法,并且基于深度学习的方法一般会提供端到端的方法,其关键技术可分为车牌检测与车牌识别两个部分。国内外学者在这方面均有很多研究。SP Peixoto等人利用CNN等技术方案对车牌的字符进行识别[2];Silva等人采用YOLO算法对车辆、车牌以及字符进行检测[3],这种方法相比于传统方法准确度更高,但算法的应范围比较小,因为算法只能通过车辆的前视图来进行检测;2018年李朝兵等人提出了一种基于深度学习的车辆牌照识别算法[4];王燕等人在2020年提出基于Faster R-CNN 和 Inception ResNet v2的算法进行车牌检测[5]。
2 本文算法
本文解决了非限定条件下车牌检测问题。由于城市街道、高速公路、乡间道路自然环境复杂,摄像设备获取到的图像分辨率较低且存在模糊,这给车牌检测精度和速度带来了挑战。因此我们提出了一种基于改进YOLO v5的车牌检测算法,实现了自然环境中实时高精度车牌检测。
2.1 YOLO v5算法
YOLO系列算法采用单阶段检测,相对于RCNN、Fast R-CNN、Faster R-CNN检测速度更快。YOLO v3是比较经典的单阶段结构,分为输入端、Backbone、Neck和Prediction四个部分;YOLO v4在前一版本基础上进行了创新,在输入端采用mo s a i c 数据增强,在Backbone上进行了一系列的改进,它采用了CSPDarknet53、Mish激活函数、Dropblock等方式,SPP和FPN+PAN的结构被用于Neck中,CIOU Loss和DIOU NMS操作被用于输出端;YOLO v5与YOLO v4不同点在于设计了两种CSP结构并且在工程化方面做了更多的改进。
2.2 改进的YOLO v5算法
2.2.1 改进神经网络结构
YOLO v5目标检测算法在实时性和精确度之间都有较好的性能表现,不过在检测一些特征不明显或者小目标时候存在一定的误差,在自然环境下车牌模糊或者远离摄像头区域拍摄的情况时有发生,因此需要提高被检测目标的特征提取能力来解决上述问题,本文将YOLO v5 CSP中的 Res unit残差网络块进行替换,采用DenseNet 网络中的密集卷积块(Dense block),密集卷积块的结构示意图如图1所示。
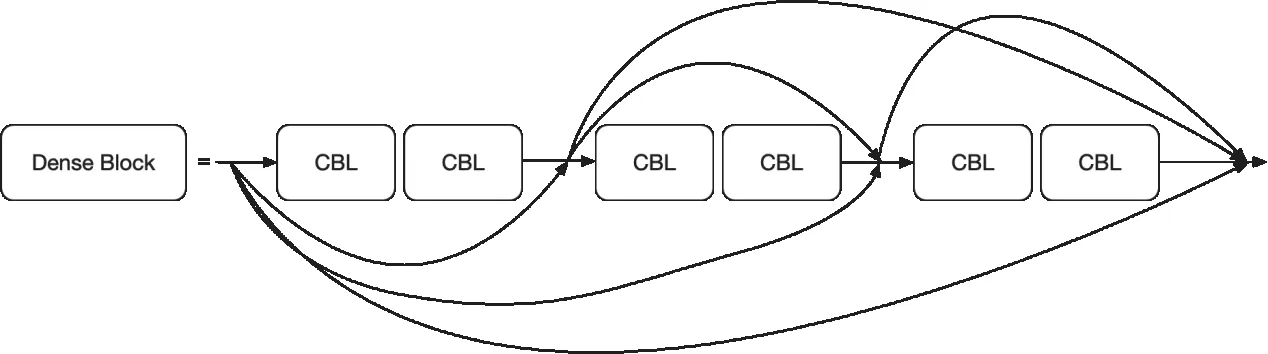
图1 Dense block结构
在传统的卷积神经网络中,网络有多少层就会有多少个连接,而密集卷积块对此进行了改变,它的输入是前面所有层的输出,假设网络有N层,那么密集卷积层则有个连接。 在YOLO v5中原始残差网络的第N层输出为其中,是非线性变化,它将第N-1层进行非线性变化得到第表示第N-1层的输出。本文采用密集卷积块的方式,实现了第N层对前N-1层输出的特征图进行网络融合,这样达到提高特征提取的能力,其输出为
2.2.2 改进Bounding Box
YOLO v5算法在目标检测过程中引入候选区域框机制,候选区域框是一个具有固定高度和宽度的初始区域。如果候选框参数初始化就能接近于事实的边界,那么在模型训练过程中会有更高的效率,最后得到的预估边框界会则更接近事实边界。因此在初始时,设置好候选框参数必然会决定目标检测的速度和精确度。YOLO v5算法在原始状态下需要对候选区域相关参数进行超参数设置,本文利用基于密度聚类的算法实现对候选框高度框进行设置,从而实现初始候选框的设定,使用DBSCAN的优势是可以自适应地给出聚类结果,并且对噪声不敏感,能够发现任意形状的簇。
2.2.3 改进Loss Function
在YOLO v5模型中交并比Loss Function采用GIoU,作为距离时,L=1-GIoU具有非负性、不确定性、对称性以及三角不等性,GIOU除了关注重叠区域不同,还关注非重叠区域,能够更好地反应重合度,它对误差越大的候选框惩罚越大,不同比例的候选框在这种方式的作用下能够取得很好的检测效果,公式为

但是GIoU没有考虑目标与anchor之间的距离、重叠率以及尺度,并且训练过程会发散,这样会导致GIoU回归策略可能会退化为IoU的回归方式。产生这种现象的原因是因为当IoU取值为0时,GIoU 使得检测框和目标框快速产生重叠,而后Loss Function惩罚措施迭代失效,这会导致把检测框与目标框之间的包含而不重叠的情况也认为是正确的。为改进这种方法本文引入新的Loss Function,并在其中加入了影响因子,在检测框宽高比的数据上进行了度量,进一步使用了更加符合回归机制的LDIoU_P,公式为

式中,b和 分别表示检测框和目标框的中心点;ρ表示检测框和目标框之间的欧式距离;覆盖检测框和目标框之间最小矩形的斜距用c表示;平衡参数表示为μ;参数m用于确保一致性。
2.2.4 改进训练数据集
国内车牌识别研究大多数是基于CCPD数据集,该数据集中图像车头部分占比较大,另外在采集图像时虽然包含了多种背景、多种拍摄角度,但和真实的自然场景还有一定的差距,没有充分考虑倾斜、模糊、光照等影响条件。本文在三个方向对数据集进行了增强,首先从Stanford Cars数据集选取4200张包含全车身图像和已有的CCPD数据集进行混合训练,解决车身图像不够多样的问题;其次通过OpenCV对数据集进行数字图像处理并注入自然环境特征,如倾斜、模糊、光照等;最后解决了CCPD数据集在中文字符分布不均的问题,本文通过人工Data Augmentation来增强各个省份中文字符比例,缓解中文字符缺乏问题。
3 实验及评估
3.1 实验条件
算法实验的硬件环境:CPU型号为英特尔i9-9900k,GPU型号为 Nvidia GeForce RTX 2080Ti。软件环境:CentOS 7.5的操作系统、CU DA9.0、Python3.8、深度学习框架PyTorch1.9.0以及其他依赖的工具库。
3.2 实验数据集
本文采用混合多个数据集进行训练,其中CCPD数据集约300千张车辆图片,拍摄不清晰难识别图片约15千张,以及几千张的新能源车辆数据。Stanford Cars车牌识别数据集拥有16 185张图像来自于196类汽车,数据集分为8 144个训练样本和8 041个测试样本,其中每个类别已大致分为品牌、型号、年份等级别。
3.3 实验结果分析
算法验证阶段对改进YOLO v5进行训练,预训练模型选择yolo v5l。为了对算法效果进行对比评估,同时对Faster RCNN、YOLO v4和原始YOLO v5进行实验,并且统计了性能指标AP、mAP、IOU、时间等,评估结果如表1所示,与其他3种模型相比,本文提出的算法各项指标均处于前列。改进后的YOLO v5模型的mAP相比原始的YOLO v5提高了1.1个百分点,交并比提高了2.1个百分点,时间减少了0.05 s。
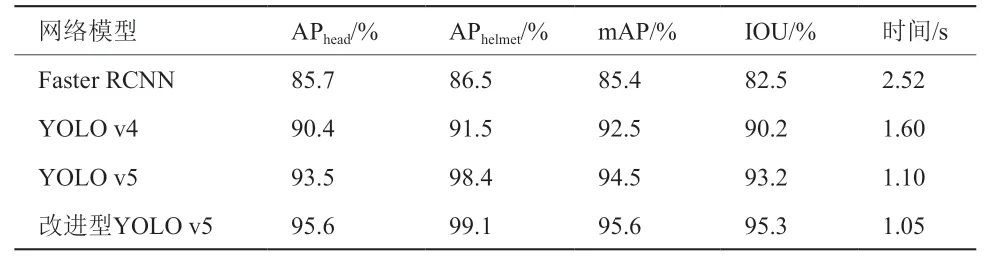
表1 车牌检测算法效果对比结果
综上所述,与其他3种模型相比,本文提出的算法有较高的mAP和较高的检测速度。实验证明基于改进算法的YOLO v5检测模型具有较高的实用性,可用于自然环境下的车牌检测。
4 结束语
本文提出了一种基于改进YOLO v5的车牌检测算法,对YOLO v5的特征提取网络、Bounding Box初始化方式、Loss Function、数据集增强方面进行优化,有效地提高了小特征提取,能适应自然环境下车牌检测。实验结果显示,本文提出的算法在保证检测速度、检测精度的同时,能更好地适应自然场景下的车牌检测。■
猜你喜欢
河北省科学院学报(2022年2期)2022-05-18
汉字汉语研究(2020年2期)2020-08-13
计算机技术与发展(2020年2期)2020-04-15
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
电子技术与软件工程(2019年4期)2019-04-26
火力与指挥控制(2018年3期)2018-04-19
小猕猴智力画刊(2017年5期)2017-05-25
