
基于特征脸的Adaboost 检测算法与识别应用研究
2022-07-07 07:19张飞
大理大学学报 2022年6期
张 飞
(安徽广播电视大学阜阳分校,安徽阜阳 236000)
随着计算机技术的发展,机器视觉技术研究吸引了众多的目光,与此同时,人工智能技术的发展使其研究取得了长足的进步。目前机器视觉主要包括检测、识别和跟踪等研究方向,这些技术广泛应用于国防建设、医药卫生、社会网络安全监控等领域〔1〕。而人脸检测与识别正是机器视觉中一个重要的分支〔2〕。其中,人脸检测是通过人脸的位置、大小等数据,确认图像是否为人脸;而人脸识别则在人脸检测的基础上进行人脸特征的提取,包括大小、纹理、外貌等〔3〕。由于图像的背景复杂性、人脸姿态多样性,人脸检测需要考虑很多方面的问题,既要保证较高的检出率,又要保证较低的误检率〔4〕。基于Adaboost 的人脸检测算法通过Haar-like 特征和积分图函数实现特殊特征识别人脸〔5〕。但是,Adaboost的人脸检测算法存在误检率高的问题〔6〕。本文在Adaboost 的人脸检测算法的基础上,引入基于梯度方向金字塔(GDP)特征和支持向量机(SVM)学习算法的分类器作为最后一级分类器,弥补误检率高的缺陷,形成基于特征脸的Adaboost 人脸检测算法。
1 Adaboost 人脸检测算法及其改进
1.1 Adaboost 人脸检测算法基于Adaboost 的学习算法的基本思想是:选定一个很大的训练集,从中定义大量的Haar-like 特征。每个训练样本都赋予一个权重,进行T 次迭代,每次迭代后,对分类错误的样本加大权重,使得下轮分类时更加关注这些样本。最后根据每个特征分辨人脸的能力,选择很小一部分作为关键特征,从而产生一个强分类器。Adaboost 训练强分类器的算法描述如下〔7〕:输入:样本集{(x1,y1),(x2,y2),…,(xn,yn)},其中yi=0,1 分别表示负样本和正样本。算法步骤:
(1)初始化的权值:当yi=0 时,;当yi=1 时,。其中m 和l 分别是负样本和正样本的数量;
(2)令t=1 to T
①归一化权值,使Wt符合概率分布,

②对于每个特征j,训练一个分类器hj,这个弱分类器的分类结果只取决于j,此时分类误差和Wt有关,

③选出分类误差εt最小的弱分类器ht。
④更新权值:

其中如果Xi被分类正确,ei=0,反之ei=1,且βt=
输出:训练得到强分类器:

1.2 人脸检测算法的改进Viola 等〔8〕文章的发表被视作是人脸检测速度提高的一个转折点,综合Adaboost 方法和Cascade 算法构建了实时的人脸检测系统。主要内容包括:1)提出了积分图(integrated image),提高了计算Haar-like 特征的速度。2)采用级联结构进行训练。Adaboost 算法采用多个强分类器级联的方式进行快速的人脸检测,每级分类器使用特征均为Haar-like 特征,用同一种方法来组合若干个弱分类器,形成一个强分类器。这种级联结构对效率有很大的提高,但在准确率方面,由于特征和训练方法均为同一种方法,对检测带来一定限制。本文将人脸的检测看作一个两层的分类问题,首先利用Viola 等〔8〕提出的Adaboost 人脸检测算法进行人脸的初检测,由于该方法利用了多个分类器的级联结构,利用这一检测流程的特征。同时,引入基于GDP 特征和SVM 学习算法的分类器,作为检测流程的最后一级分类器。
首先对检测图像进行一定的预处理,并用迭代窗口获取待检测区域;然后利用Adaboost 自身训练得到的多级分类器进行人脸区域的检测;最后对初次分类结果提取GDP 特征,GDP 特征具有一定的优势,对光照并不敏感,利用SVM 学习算法训练好的分类器进行最后一级研判,实现人脸的检测。检测算法框架见图1。

图1 检测算法框架
算法步骤如下:
(1)GDP 特征定义:给定输入图像I(p),其中p=(x,y)表示图像中像素p 的位置。
①首先定义图像I 的金字塔为:

其中Φ(p)为高斯核参数(实验中使用0.5),↓2表示每层金字塔为其下层大小的一半,s 是金字塔的层数。
②归一化:金字塔每层σ 上的梯度方向定义为每个像素点归一化后的梯度向量:

③输出:图像I 的GDP 特征定义为:

(2)SVM 算法分类:对于样本集{(x1,y1),(x2,y2),…,(xn,yn)}(xi∈Rd,y∈{1,-1}),采用径向基函数(RBF)进行计算:
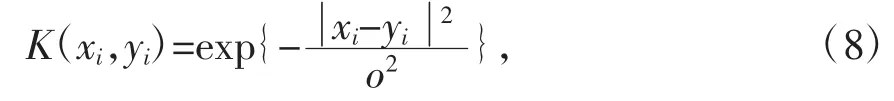
当满足

2 结果与分析
2.1 数据来源实验数据主要包括3 个部分:1)人脸检测分类器的训练集用的是Feret 人脸库(包含443 张人脸图片),对人脸图片进行一些预处理,包括归一化、灰度化等,将图片统一格式,这些人脸图片作为正样本,负样本是手工截取的一些非人脸图片,然后对这些样本进行寻训练,最后生成分类器,保存在XML 文件中。2)静态图片的测试集主要由第二代身份证照片(共500 张)和网络图片资源(40张图片,共包括625 个人脸)组成,视频中人脸检测的测试集主要是摄像头拍摄的视频,也包括一些网络视频资源。
2.2 测试结果分析对Feret 人脸数据库进行人脸检测实验,含人脸的图片共443 张,其中漏检测3张,将非人脸区域误检测为人脸的出现10 处,检出率为99.3%,漏检率为0.7%,误检率为2.3%。Feret人脸库的人脸姿态与第二代身份证的相似,但存在一些轻微的倾斜和旋转情况。
在第二代身份证图片检测识别实验中,其中漏检1 张,将非人脸区域误检测为人脸出现14 处,检出率为99.8%,漏检率为0.2%,误检率为2.8%。主要是因为第二代身份证拍摄条件要求比较严格,人脸的姿态是正面的,很少带有旋转和倾斜,且拍摄现场光照条件良好,背景单一,对检测的影响较小,故检出率较高。漏检测的主要原因是照片中人物年龄较大,脸部皱纹明显,且五官较小,其Haar-like特征不明显。图2 给出了部分检测正确、误检和漏检的例子。

图2 第二代身份证人脸检测结果
同时本文从互联网下载一些多人脸图片进行实验,其中人脸带有较明显的旋转和倾斜,图片背景复杂,且光照条件多变,图片本身清晰度也有较大差异,此外,包括很多远景人脸。实验共检测了40张图片,共包括625 个人脸,其中检测正确的有544个,漏检测81 个,误检测40 个,检出率为87.0%,漏检率为13.0%,误检率为6.4%。互联网图片资源清晰度不一致,而且图片中人脸姿态往往是倾斜和旋转的,图片背景和光照条件复杂多变,对人脸的检测带来较明显的影响。见图3。

图3 网络图片人脸检测的部分结果
最后对Adaboost 算法检测到的结果(包括正确和误检测的结果),利用GDP 特征进行重分类,分类过程将大部分误检测为人脸的非人脸区域去除,但有少量的人脸区域被误标注为非人脸,本文将这类情况归结为漏检测。人脸检测实验的结果见表1~2。

表1 Adaboost 算法人脸检测实验结果
实验结果显示,Adaboost + GDP 的算法与单一的Adaboost 算法相比,正确率有小幅度的下降,即漏检率略增加,但误检率下降较明显,原因如下:基于SVM 的学习算法本身对训练样本有一定的依赖,且对人脸提取的特征不同,实际结果也会有差别,分类效果并不能达到100%的正确率,故会将部分人脸误分类为非人脸。所以,通过在Adaboost 检测结果后再级联一层分类器,将人脸特征由原先的Haar-like 特征换成GDP,在提取人脸和非人脸样本的特征后,利用SVM 对正样本和负样本进行训练,得到分类器能够去除一些误检测的结果。
人脸检测与识别作为人脸信息处理的关键技术,近年来成为模式识别和计算机视觉领域内一项受到普遍重视的课题。本文通过Adaboost 人脸检测算法,对静态图片进行了人脸检测,同时利用GDP和SVM,对检测结果进一步分类,达到了实时的检测效果。

表2 Adaboost + GDP 算法人脸检测实验结果
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
计算机系统应用(2021年2期)2021-02-23
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
软件导刊(2017年4期)2017-06-20
数学学习与研究(2017年3期)2017-03-09
米娜·女性大世界(2016年8期)2016-08-17
