
基于深度学习的多模态情感识别综述
2022-07-07 06:37:32张伟东
西安邮电大学学报 2022年1期
刘 颖,艾 豪,张伟东
(西安邮电大学 通信与信息工程学院,陕西 西安 710121)
情感识别作为人工智能领域的热门研究方向,是构建智能人机交互系统的重要环节,其在意外风险事故防范[1]、金融市场的预测[2]、商业评论的分析[3]和犯罪预测[4]等领域有着广泛的应用。在情感识别研究发展的过程中,研究者通常使用文本、语音或者视觉(人脸)等3种单模态信息进行情感预测。在利用单模态信息进行情感识别时,信息来源都来自于某单一模态,所以在一些情况下存在不足。例如,当单模态数据量较少时,网络的训练可能会出现过拟合现象,不仅如此,有时单模态数据甚至会提供错误信息,从而影响到最终预测结果[5]。因此,开展多模态情感识别的研究尤为必要。
基于传统机器学习的多模态情感识别,常用的方法有基于朴素贝叶斯(Naive Bayes,NB)、随机森林、支持向量机(Support Vector Machines,SVM)、决策树学习和最大熵(Maximum Entropy,ME)等。文献[6]提出了一个基于表情面部、手势和语言的多模态情感识别框架,数据库是一个包含8个情感和10个主题的多模态语料库GEMEP[7](Geneva Multimodal Emotion Portrayals)。为了降低学习复杂度,采用Kononenko最小描述长度准则[8]对特征进行离散化且使用交叉验证方法对语料库进行训练和测试。文献[9]提出了一种用于微博情感识别的跨媒体词袋模型(Cross media word Bag Model,CBM),该模型将文本和图像视为一个整体,由文本和图像的特征组成信息的特征,利用Logistic回归进行分类。在情感识别任务中,传统机器学习方法首先从信号中提取手工设计的特征,然后用这些特征训练分类器。但是,这种手工设计的特征并不能充分表征情感信息,限制了传统方法的系统性能。传统机器学习想要构建高性能的机器学习模型,需要特定的领域、技术和特征工程,不同领域的知识库是完全不同的,所以结构不够灵活且适应性很差。自从2012年Geoffrey Hinton领导的小组在著名的ImageNet图像识别大赛中,采用深度学习模型AlexNet[10]夺冠以来,深度学习被应用于各个领域。深度学习神经网络结构灵活,适应性更强,更易于转换。使用神经网络提取特征,可以避免大量人工提取特征的工作,节约成本。不仅如此,深度学习还可以模拟词与词之间的联系,有局部特征抽象化和记忆功能。正是这些优势,使得深度学习在情感识别中发挥着举足轻重的作用。
在多模态情感识别发展过程中,学者从不同的角度对现有的技术进行了总结。文献[11]对情感进行了定义,讨论了情感识别的应用并对文本、语音、视觉以及多模态情感识别的现有技术进行了归纳总结。文献[12]对情感计算任务进行了分类,同时通过时间线对情感识别的发展进行了梳理,最后对单模态到多模态的情感识别技术进行了综述。文献[13]将情感识别任务分为核心任务和子任务两部分。核心任务包括文档级情感分类、句子级情感分类和方面级情感分类,子任务包括多领域情感分类和多模态情感分类。
该研究对基于深度学习的多模态情感识别进行讨论总结。第1部分介绍了基于深度学习的文本、语音和人脸等3种单模态情感识别。第2部分总结了现有的多模态的情感识别数据集。第3部分将基于深度学习的多模态情感识别按照融合方式的不同分为基于早期融合、晚期融合、混合融合以及多核融合等4种情感识别方法,并在第4部分对不同方法进行对比分析。最后,在第5部分对全文进行了总结,并对情感识别技术未来的发展趋势进行展望。
1 基于深度学习的单模态情感识别
在情感识别领域,与传统的机器学习相比,深度学习更高效、更能提取出深层次的语义特征。随着深度学习的发展,卷积神经网络(Convolutional Neural Networks,CNN)、记忆神经网络(Memory Neural Networks,MNN )、循环神经网络(Recurrent Neural Network,RNN)、图神经网络(Graph Neural Networks,GNN)、深度置信网络(Deep Belief Networks,DBN)、胶囊网络[14](Capluse Networks)以及Transformer[15]网络均在情感识别领域取得了优异的效果。下面将对基于深度学习的文本、语音和人脸情感识别分别进行简要概括。
1.1 基于深度学习的文本情感识别
传统的文本情感识别方法主要包括人工构建情感词典的方法和基于有监督学习的机器学习模型,这两种方法不仅耗费大量的人力,而且在大数据时代任务完成效率和任务完成质量均较低。深度学习可以通过构建网络模型模拟人脑神经系统对文本进行逐步分析,特征抽取且自动学习优化模型输出,以提高文本分类的正确性。
基于深度学习的文本进行情感识别时,首先需要对文本序列送入词嵌入(Word Embedding)模型,由词嵌入模型将其编码为词向量(Word Vector)作为后面神经网络的输入。早期用于表示文档词汇表的方法是独热编码(One-Hot Encoding),这种方法的问题是词向量大小随着语料库大小的增加而增加,更重要的是这种编码方式不能捕捉单词之间的联系。现在比较常用的词嵌入模型有Word2vec[16]、Glove[17]以及BERT[18](Bidirectional Encoder Representations from Transformers)。
Word2vec其本质是一种单词聚类的方法,是实现单词语义推测和句子情感识别等目的的一种手段,两种比较主流的实现算法是连续词袋模型(Continuous Bag-of-Words,CBOW)和Skip-Gram。前者是利用周围词估计中心词,缺点是周围词的学习效果要差一些,后者是根据中心词估计周围词,优点是学习效果要好一些,但是学习速度慢。Glove通过语料库构建词的共现矩阵,然后通过共现矩阵和Glove模型对词汇进行向量化表示。相比于Word2vec,Glove更容易并行化,速度更快,但是Glove算法本身使用了全局信息,所以更费内存。BERT作为Word2vec的替代者,本质上是通过在海量语料的基础上运行自监督学习方法为单词学习一个好的特征表示,BERT使用Transformer作为算法的主要框架,能更彻底的捕捉语句中的双向关系。除此之外,常用的词向量模型还有ELMo[19](Embedding Language Model)和GPT[20](Generative Pre-Training)。
在得到词向量之后,通常需要对特征进行聚类和筛选,以得到更高级的情感特征表征。文献[21]借鉴了胶囊网络的思想,通过为每个情感类别构建胶囊,提出了基于RNN的胶囊用于情绪识别。方面级情感分类任务是对给定一个方面(Aspect),研究多模态文档在该方面的情感极性。文献[22]提出了利用胶囊网络通过路由算法构建基于向量的特征表示和聚类特征(Cluster Features),交互式注意力机制在胶囊路由过程中引入以建模方面术语与上下文的语义关系。文献[23]也将胶囊网络用于方面级情绪识别,取得了优异的效果。
基于RNN、长短期记忆网络( Long Short-Term Memory,LSTM)和门控循环单元( Gated Recurrent Unit,GRU)这种循环结构的网络模型在文本情感识别任务上已经取得了优异的效果,但是RNN 固有的顺序属性阻碍了训练样本间的并行化,对于长序列,内存限制将阻碍对训练样本的批量处理。为此,文献[24]提出了Transformer网络。Transformer使用了自注意力机制(Self-Attention),该机制可以产生更具可解释性的模型,可以从模型中检查注意力分布,各个Attention Head可以注意到不同子空间的信息。Transformer突破了RNN不能并行计算的限制,相比于CNN,Transformer计算两个位置之间的关联所需的操作次数不随距离的增长而增长。在此基础上,文献[25]提出一个分层Transformer框架,其中低层Transformer用来对单词级的输入进行建模,上层Transformer用来捕获话语级输入的上下文关系。
1.2 基于深度学习的语音情感识别
语音情感识别近年来受到广泛关注,在人机交互和行车驾驶安全上[26]发挥着重要的作用。为了得到更好的实验效果,通常首先将语音数据先进行预处理,然后进行特征提取,提取到的特征维度可能过高,需进一步降维操作。最后,通过分类器进行情感分类。
1.2.1 常用特征工具与降维
随着深度学习技术逐步完善,在海量复杂数据建模上有很大优势。传统的基于机器学习的语音情感识别所提取的语音特征通常包括波形、信号能量、F0、快速傅里叶变换( Fast Fourier Transform,FFT)频谱、语音质量、倒频谱(Cepstrum)、线性预测倒谱系数(Linear Prediction Cepstral Coefficients,LPCC)、梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)、共振峰、语速和小波等。相较于传统机器学习,深度学习能提取到高层次的深度特征,常用于语音特征提取的神经网络有深度神经网络(Deep Neural Networks,DNN)、CNN、DBN、RNN、LSTM和胶囊网络等,常用语音特征提取工具[27]如表1所示。
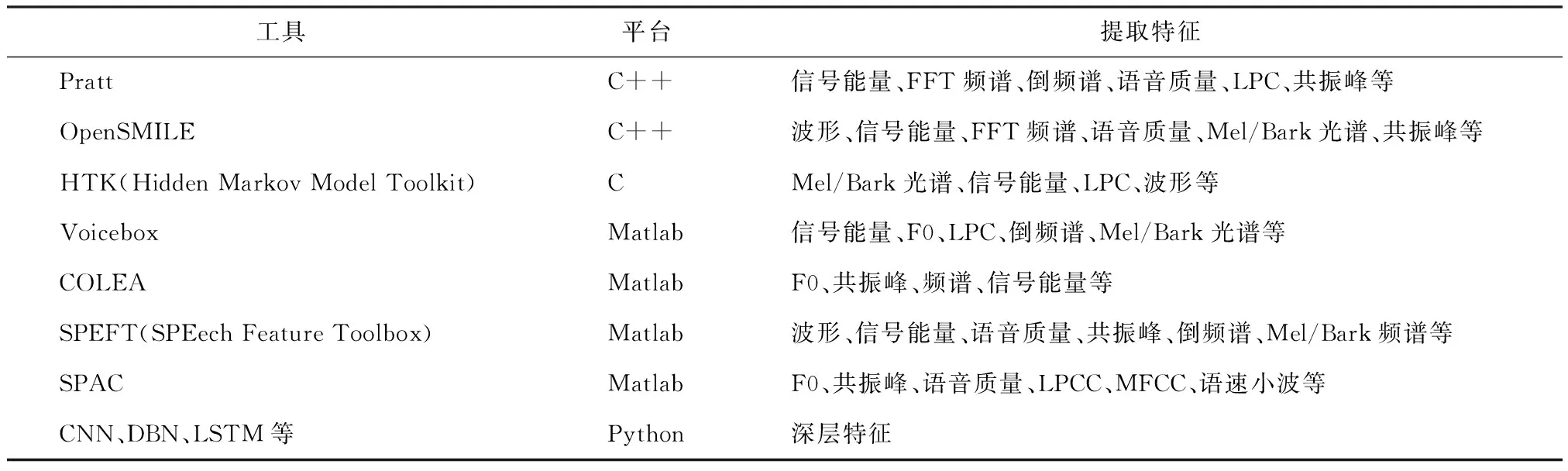
表1 常用语音特征提取工具统计表
目前,除神经网络以外,比较主流的语音特征提取工具包括Praat[28]和OpenSMILE[29]两种。由于这两款工具图形用户界面(Graphical User Interface ,GUI)操作简洁、功能完善和其跨平台的特性,所以很多学者在进行多模态语音情感识别时会采用这两款语音特征提取工具提取特征。但是通过这两款工具提取到的语音特征维度很高,通常需要进行降维操作,例如主成分分析[30](Principle Component Analysis,PCA)和线性判别分析[31](Linear Discriminate Analysis,LDA)等。
1.2.2 深层特征提取
考虑到神经网络能提取到更丰富的声学情感特征,文献[32]采用CNN从语谱图中提取图像特征,从而改善MFCC丢失信息而造成识别结果准确率低的问题,最后通过多核分类器得到了很高的识别精度。DBN情感表征能力强,无监督特征学习能力强,文献[33]采用贪婪算法进行无监督学习,通过BP(Back Propagation)神经网络反向微调,找到全局最优点,再将DBN算法的输出参数作为深度特征,并在此过程中,采用随机隐退思想防止过拟合。
CNN的Max-pooling操作只保留最活跃的神经元,这样可能会丢失比较重要的空间信息,所以文献[34]在胶囊网络的基础上提出了采用两个循环连接的胶囊网络提取特征,增强空间敏感度,取得了比CNN-LSTM体系结构更好的分类精度。除此之外,文献[35]以类似于RGB图像表示的3个对数梅尔光谱图作为深度卷积神经网络(Deep Convolutional Neural Network,DCNN)的输入,通过ImageNet预训练的CNN模型学习光谱图通道中的高级特征表示,将学习的特征由时间金字塔匹配策略聚合得到全局深度特征,进一步提升对有限样本特征提取的有效性。
1.3 基于深度学习的人脸情感识别
人脸情感识别对人机交互有重大意义,要让计算机更好地理解人类表达,人脸情感识别不可或缺。通常将人脸表情分为高兴、悲伤、愤怒、惊讶、恐惧和厌恶等6种基本表情。在进行特征提取前,为了让识别结果更好,通常先进行图像预处理,然后检测出人脸部分,再对人脸部分进行特征提取。人脸表情识别的主要步骤是表情特征提取和情感分类,传统的机器学习特征提取方法包括局部二值模式[36](Local Binary Pattern,LBP)、主动外观模型(Active Appearance Model,AAM)、主动形状模型(Active Shape Model,ASM)、尺度不变特征转换(Scale Invariant Feature Transform,SIFT)和Gabor小波变换[37]。传统机器学习是手工提取特征,费时费力,且由于人脸语义信息比其他图像更为丰富,手工提取特征可能会漏掉重要的语义信息。深度学习能提取深度特征,深度特征更丰富,包含的语义信息更完整,因此,利用深度学习进行人脸情感识别成为研究的热点。
常用于人脸表情识别的神经网络有CNN、DBN、生成对抗网络[38](Generative Adversarial Networks,GAN)、深度自编码器[39](Deep Autoencoder,DAE)和LSTM等。GAN因其强大的生成能力,在文献[40]中被用来将非正面化的人脸正面化,达到多角度进行人脸表情识别。GAN虽然具有很强的生成能力,但是也存在训练困难,超参数不容易调整的问题。深度自编码器是一种无监督学习的神经网络结构,输入输出相同维度,但是也存在易陷入局部最优的问题,虽然无监督逐层贪心预训练能在一定程度解决这个问题,但是随着隐藏层个数、神经元数量和数据复杂的增加,梯度稀释越来越严重,且训练极其繁琐。对于各种网络的局限性,学者们通常结合几种神经网络提取特征,在最后分类器的选择上也不尽相同,有些利用神经网络的Softmax层进行分类,而很多也选择SVM[41]或者AdaBoost[42]分类器进行分类。
1.4 小结
介绍了基于深度学习的文本、语音和人脸(视觉)等3种单模态情感识别的方法。对于文本情感识别,主要介绍了常用的词向量模型以及用来捕获上下文关系的相关网络模型。对于语音和人脸情感识别,介绍了相关特征提取工具包和特征提取神经网络,同时还对相关网络架构的性能进行了分析。
2 多模态情感数据集
对目前多模态情感识别领域相关任务常用的数据集进行梳理,主要分为双模态数据集(文本和图片)和三模态数据集(文本、图片和语音)。双模态情感数据集包括Yelp[43]、Twitters[44]和Multi-ZOL[45]等3种,三模态数据集包括CMU-MOSEI[46](CMU Multimodal Opinion Sentiment and Emotion Intensity)、CMU-MOSI[47](CMU Multimodal Corpus of Sentiment Intensity)、YouTube[48]、ICT-MMMO[49](Institute for Creative Technologies’ Multi-Modal Movie Opinion)、IEMOCAP[50](Interactive Emotional dyadic Motion Capture database)和MELD[51](Multimodal EmotionLines Dataset)等6种,分别如表2和表3所示。表中分别用T、I和S表示文本、图片和语音。

表2 双模态情感数据集

表3 三模态情感数据集
Yelp数据集一共有44 305条评论,244 569张图片,情感标签标注是对每条评论的情感倾向打1~5分等5个分值。Twitters数据集分为训练集、开发集和测试集,分别是19 816、2 410和2 409条带图片推文。该数据集的情感标签标注为讽刺或不讽刺。Multi-ZOL数据集一共有5 288条多模态评论,每条多模态数据包含1个文本内容、1个图像集,以及至少1个但不超过6个评价。对于每个评价,都有1~10分的情感得分。
CMU-MOSEI数据集包含3 228个视频、23 453个句子、1 000个讲述者和250个话题,总时长达到65 h。CMU-MOSI数据集总共随机收集了2 199个视频,这些视频的情绪极性强度标注为-3~+3,标签标注为愤怒、厌恶、悲伤、喜悦、中立、惊讶和恐惧等情感七分类,数字越大代表情绪越积极。YouTube数据集收集了300个视频,标签标注为积极、消极和中性等情绪三分类。ICT-MMMO数据集包含340个多模态评论视频,其中包括228个正面评论、23个中立评论和119个负面评论。IEMOCAP数据集总共包括4 784条即兴会话和5 255条脚本化会话,最终的数据标签标注为中立状态、幸福、愤怒、惊讶、厌恶、挫败感、兴奋、其他、恐惧和悲伤等情感十分类。MELD数据集包含9 989个片段,每个片段的标签标注不仅包含愤怒、厌恶、悲伤、喜悦、中立、惊讶和恐惧等情感七分类,也包含积极、消极和中性等情绪三分类。
3 基于深度学习的多模态情感识别
将基于深度学习的多模态情感识别任务按照融合方式不同分为基于早期融合、晚期融合、混合融合以及多核融合等4种情感识别方法。早期融合大都将特征进行简单的级联操作。晚期融合是让不同的模态先进行单独训练,再融合多个模型输出的结果。混合融合则是结合了早期融合和晚期融合的融合方法。多核学习则是通过多核映射,将多个特征空间组合成一个高维组合特征空间。
3.1 早期融合
早期融合又叫特征级融合,通常将特征进行简单的级联操作。文献[52]通过CNN提取图像和文本特征,应用于反讽数据集Twitter进行图像推文情绪分类任务,获得了86%的精确度。在此基础上,进一步利用CNN提取文本与图像特征,通过结合注意力机制和LSTM捕获文本和图像之间的联系,最终送入Softmax进行分类且获得了3%的性能提升。文献[53]提出GME-LSTM ( Gated Multimodal Embedding LSTM) 模型,在每个时间点引入了门控机制,在单词层就能完成多种模态信息的融合。
与简单的将不同模态特征进行级联操作不同,文献[54]针对在线视频中不稳定的口语以及伴随的手势和声音,将多模态情感识别问题作为模态内和模态间的动态建模,提出了一个新的张量融合网络(Tensor Fusion Network,TFN),采用端到端的学习方式,从模态内和模态间解决多模态情感识别问题。
在编码阶段,TFN使用1个LSTM和两层全连接层对文本模态的输入进行编码,分别使用1个3层的深度神经网络对语音和视频模态的输入进行编码。在模态嵌入子网络(Modality Embedding Subnetworks,MES)中有3个子网络,分别提取声音特征向量zα、文本特征向量zl和图片特征向量zv,表示为
(1)
得到3种特征向量之后,在张量融合层中通过三维的笛卡尔积将3种模态联系起来,得到融合后的向量
(2)
送入情感决策层。张量融合如图1所示。该网络采用交叉熵损失函数,取得了不错的效果。

图1 张量融合
文献[55]提出了MARN(Multi-attention Recurrent Network)模型。考虑到不同模态之间具有模态交互信息,该模型通过分层注意力机制关注这种模态间的交互信息。在编码阶段,对LSTM进行改进以增强多模态表示,且将模态融合和模态编码进行了结合。值得注意的是,该模型在每个阶段都会进行模态融合,所以需要在编码前进行模态对齐。MARN模型考虑到了模态间的交互信息,文献[56]则考虑了关注交互信息的范围,提出了MFN(Memory Fusion Network)模型,MFN使用增量记忆机制(Delta-Memory Attention,DMA)和多视野门控记忆(Multi-View Gated Memory,MVGM),同时捕捉上下文之间的联系和不同模态之间的交互,保存上一时刻的多模态交互信息。
文献[57]认为在以往利用文本、语音和视觉等3种模态信息进行情感识别的研究中,忽视了文本信息比语音和视觉信息更重要的事实。为此提出了一种文本信息起主导作用的框架。为了探索时间和通道的相关性,该框架利用时间卷积网络提取每种模态的高级表征,利用两个变体LSTM关注语音和视觉信息且增强文本信息的表示。对于Multi-ZOL数据集,文献[58]提出了多交互记忆网络(Multi-Interactive Memory Network,MIMN),该模型使用方面引导注意力机制指导模型生成文本和图像的注意力向量,并使用多模态交互注意力机制捕获多模态间和单模态内的交互信息。文献[59]提出了一种基于深度置信网络的语言表情多模态情感识别方法,通过CNN获得人脸表情特征,对于音频,通过频谱衰减和短时平均能量获取高级声学特征。为了提高两种模态特征融合的有效性,采用双模态深度置信网络(Bi-DBN)融合表情和语音特征且去除模态间的冗余信息,将得到的融合特征送入SVM进行最终的分类。
LSTM和GRU固有的顺序属性阻碍了训练样本间的并行化,对于长序列,内存限制将阻碍对训练样本的批量处理。为了克服这种缺陷且降低多模态情感识别任务中对标注数据的依耐性,文献[60]提出了基于Transformer自监督特征融合的多模态情感识别网络框架,该网络使用预训练的自监督网络提取文本、音频和视觉等3种模态信息的特征。同时,考虑到提取到的自监督特征具有高维性,因此采用一种新的基于Transformer和注意力机制方法捕捉模态间和模态内的上下文语义联系。
3.2 晚期融合
晚期融合也叫决策级融合,不同的模态先进行单独训练,再融合多个模型输出的结果。因为该方法的融合过程与特征无关,且来自多个模型的错误通常是不相关的,所以这种融合方法在多模态情感识别中应用很多。
文献[49]创建了ICT-MMMO数据库,该数据库是一个关于电影评论视频的数据库。对于语音征提取,是通过大量的低阶描述符(Low-level Descriptors,LLD)及其导数,并结合相应的统计函数捕获一个片段内的语音动态,利用OpenSMILE在线音频分析工具包进行语音特征提取。因为每个视频片段中只有一个人,而且被试者大部分时间都面对着摄像头,所以采用了从视频序列中自动提取视觉特征。通过Bag-of-Words(BoW)和Bag-of-N-Gram(BoNG)以及自动语音识别(Automatic Speech Recognition,ASR)系统进行文本特征的提取。为了对连续话语之间的上下文信息进行建模,利用双向长短时记忆网络(Bi-LSTM)对音频和视频特征进行情感识别,对于语言特征分类,使用线性支持向量机。音频和视频特征作为Bi-LSTM网络的输入,进而产生情感预测。MFCC特征利用ASR系统生成语言特征,通过SVM对得到的BoW/BoNG特征进行分类,而SVM为每个电影评论视频生成一个预测,由于这种异步性,所以采用晚期融合推断最终的情感估计。Bi-LSTM网络生成的总分是通过简单地平均每个话语对应的分数计算,最后的情感评估是语言(权重1.2)和视听(权重0.8)得分的加权和。为了将在语言知识数据库上的得分整合到上述方法中,通过Logistic回归将得分映射到[0,1]范围内。与文献[49]不同,文献[61]提出了一个深度多模态融合架构,如图2所示,其能够利用来自个体模态的互补信息预测说服力。

图2 基于晚期融合的深度多模态网络架构
该网络在最后利用DNN进行最终的情感预测,DNN的输入是采用单个模态分类器的置信度得分和其互补得分,最终预测取得了90%的精确度。类似地,文献[62]使用Word2vec对单词进行编码,利用DNN提取图像特征,通过逻辑回归对文本和图像进行情感预测,最后使用从标记数据中学习到的平均策略和权重融合概率结果。
文献[63]认为在以前的研究中,只是把话语当成一个独立的部分,而没有考虑话语前后的视频画面的关系。针对这种情况,基于LSTM的模型被提出,该模型能够捕捉话语环境中的上下文信息。利用Text-CNN 提取文本特征,首先将每一个句子都变成每一个单词向量的集合,使用Word2vec将这些词编码为维度为300维的词向量。对于语音信息,利用OpenSMILE在线音频分析工具包进行语音特征提取。对于图像,使用3D-CNN进行图像特征提取,然后使用Max-pooling 进行降维,得到一个300维度的特征向量。在得到文字、语言和视觉等3种模型的特征向量表示之后,再将这3种特征向量分别送入上下文LSTM捕获相邻语境之间的联系,最终得到每种模态的情感预测结果,并将这些预测结果继续送入到一个上下文LSTM中得到最终的预测结果。与利用文本、语音和人脸等3种模态进行情感识别不同,文献[64]利用人脸与脑电进行多模态情感识别,采用CNN提取人脸特征且利用Softmax进行最终分类,而因为脑电的非线性特性,利用SVM进行最终的分类,在晚期融合层采用多重投票的方式且结合阈值法计算出两种模态的最终分类结果,将得到的结果利用统计模拟法得到最后的多模态情感分类结果。文献[65]提出一个应用于音乐视频情感识别的网络架构,在数据预处理阶段,将视频中的原始音频声波转换为单声道,然后以窗口大小为2 048,频率为22 050 Hz进行二次采样,利用OpenSMILE进行音频特征提取。对于视频中的视觉信息,由于三维卷积能更好的捕获空间和运动信息,所以利用3D-CNN进行人脸特征提取,最后以晚期融合的策略送入分类器进行分类。
3.3 混合融合
多模态数据的早期融合并不能有效地捕捉所涉及模态的互补相关性,并可能导致包含冗余的输入向量一起输入到情感决策层中,对情感预测造成干扰。晚期融合不能有效地捕捉不同模态之间的相关性,混合融合则集成了早期融合和晚期融合的优点,在情感预测任务中取得了不错的效果。文献[66]提出了一种新的图像-文本情感识别模型,即深度多模态关注融合(Deep Multimodal Attention Fusion,DMAF),利用视觉和语义内容之间的区别特征和内在相关性,通过混合融合框架进行情感识别。该网络包含两种独立的单模态注意力模型和一种多模态注意力模型,两种单模态注意力模型分别学习视觉模态和文本模态,自动聚焦与情感最相关的判别区域和重要词语。对于文本内容,使用Glove上的预先训练好的单词特征初始化嵌入层(Embedding Layer)参数,每个单词都由一个300维的向量表示,文本内容长度不超过30,大于30的序列将被截断,小于30的用零填充。将得到的词向量通过LSTM捕获上下文关系,经过语义注意力机制之后进行情感预测。首先,视觉特征通过视觉几何组19[67](Visual Geometry Group,VGG19)模型进行提取,使用卷积层“Conv5_4”的输出作为区域特征,其维度为196×512,经过视觉注意力机制进行情感预测。然后,提出了一种基于早期融合的多模态注意力模型,利用视觉特征和文本特征之间的内在关联进行联合情感预测。最后,将得到的3种情感预测结果采用一种晚期融合方案进行最终的情感预测。文献[68]提出一种用于艺术绘画多模态请感识别框架,艺术绘画中包含图像与文本信息。图像信息利用CNN进行特征提取,而文本信息利用BERT构造一个句子的词向量,通过Bi-GRU捕获上下文关系。
基于RNN、LSTM和GRU这种循环结构网络模型在多模态情感识别任务上已经取得了优异的效果,但是RNN 固有的顺序属性阻碍了训练样本间的并行化,对于长序列,内存限制将阻碍对训练样本的批量处理。由此,文献[69]提出了一个基于Transformer的会话级多模态情感识别框架,该架构包含对于上下文无关的话语级特征提取和上下文相关的多模态特征提取两个关键步骤。架构中包含两个Transformer,一个Transformer用来捕获单模态特征之间的时间依耐性,另一个跨模态Transformer用来学习非对齐多模态特征上的跨模态交互作用。为了得到更有用的信息,通过注意力机制进行多模态特征融合,最后使用一个双向GRU捕获文本和语音两个方向上的语境信息,并结合Multi-Head Attention突出重要的语境话语。
3.4 多核融合
多核融合的方法来自于多核学习(Multi Kernel Learning,MKL),多核学习是一种特征选择方法,将特征分组,每组都有自己的核函数[70]。SVM分类器都是单核的,即是基于单个特征空间。在实际应用中往往需要根据经验选择不同的核函数,如高斯核函数、多项式核函数等。指定不同的参数,这样不仅不方便而且当数据集的特征是异构时,效果也不是很理想。正是基于SVM单核学习存在的上述问题,同时利用多个核函数进行映射的MKL应用而生。多核模型比单个核函数具有更高的灵活性。在多核映射的背景下,高维空间成为由多个特征空间组合而成的组合空间。组合空间充分发挥了各个基本核的不同特征映射能力,能够将异构数据的不同特征分量分别通过相应的核函数得到解决。多核学习过程如图3所示。
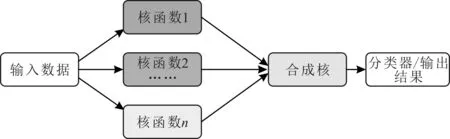
图3 多核学习过程
多核学习很擅长处理异构数据,因此也被用于多模态情感识别。文献[71]提出了基于深度卷积神经网络的文本特征和多核学习的话语级多模态情感识别。在一个带有手工标注情绪标签的训练语料库中训练一个CNN,将训练的CNN不作为分类器使用,而是将其隐藏层的输出值作为多核SVM的输入特征,从而提供更高的分类准确性。对于文本的预处理,使用Word2vec对单词进行预处理,每个单词处理成一个300维的向量,对于词典里面没有的单词,处理成新的随机向量。对于脸部特征点的提取,使用CLM-Z[72]人脸识别库,对每一帧图像提取68个面部特征点,使用OpenSMILE提取与音高和声音强度相关的音频特征。在模型中,将提取的特征用基于循环相关的特征子集和主成分分析进行特征选择降低特征维度,通过交叉验证确定MKL分类器的参数。选择8个核的配置,其中5个核函数采用径向基函数(Radial Basis Function,RBF),超参数Gamma设置成从0.01~0.05,RBF的Gamma参数控制单个训练点的影响距离,剩余3个核的核函数分别采用多项式的2、3、4次幂。最后使用MKL对多模态异构融合特征向量进行分类。
为了进一步提升情绪识别的准确性,文献[73]提出了一种卷积递归多核学习模型。为了捕捉视频上下内容的时间相关性,将时间t和t+1的每对连续图像转换成单个图像,利用CNN提取时间相关的特征,通过使用CNN学习到的输出特征向量的协方差矩阵初始化RNN的权值,最终情感类别输出为“积极”或“消极”。
3.5 小结
介绍了基于深度学习的多模态情感识别相关方法,按照融合方式的不同将这些方法分为基于早期融合、晚期融合、混合融合和多核融合。早期融合大都将特征进行简单的级联操作或者进行张量融合,不能有效地捕捉所涉及模态的互补相关性,并可能导致包含冗余的输入向量一起输入到情感决策层中,对情感预测造成干扰。晚期融合则不能有效地捕捉不同模态之间的相关性,混合融合则集成了早期融合和晚期融合的优点,但算法相对比较复杂。
4 不同方法对比
为了比较多模态融合方式对精度的影响及单模态的识别效果,分别对比不同方法在双模态数据集Twitter上的F1分数和精确度,如表4所示,F1分数是模型精确率和召回率的一种调和平均。为了比较不同方法网络结构在多模态情感识别中的表现情况,表5总结出了不同方法在三模态数据集IEMOCAP上的实验结果,最终F1分数和精确度都取平均值。

表4 不同方法在双模态数据集Twitter上实验结果对比

表5 不同方法在三模态数据集IEMOCAP上实验结果
由表4和表5可知:1)在单模态情感识别上,文本的表现要优于图像的表现。而在融合方式上,晚期融合的效果优于早期融合,混合融合的效果明显优于其他两种融合方式,但是算法相对更复杂。2)当融合方式相同时,CNN架构由于池化操作可能会失去重要的空间信息,所以效果相对较差。引入LSTM、GRU捕捉文本上下文的联系或者视频上下帧的关联能有效提高识别准确率,另外引入注意力机制,对不同模态的贡献分配不同的权重也能提高准确率。3)Transformer可以克服RNN并行计算效率太低的缺点,但是整体复杂度相对要高一些。
深度学习中常用于情感识别特征提取的神经网络的优缺点总结如表6所示。

表6 情感特征提取方法优缺点总结
5 结语
多模态情感识别旨在分析出人们对产品、服务、组织、个人、问题、事件和话题等实体的意见、情绪、情感、评价和态度,其在人机交互、舆情分析、灾害评估和金融市场预测等方面发挥着重大作用。目前,多模态情感识别任务大都采用深度学习进行建模,通过分析基于深度学习的多模态情感识别的研究现状,将基于深度学习的多模态情感识别按照融合方式不同分为早期融合、晚期融合、混合融合和多核融合等4种情感识别方法,并分别进行归纳总结。同时,对情感识别技术未来发展趋势进行展望,具体如下。
1)多模态情感识别太依赖于特定领域,泛化性不足。设计一个跟领域无关的多模态情感识别系统是需要解决的问题,例如用车评数据集训练出的模型分析斗鱼评论。
2)生理特征需要引入多模态情感识别,文本、语音和图像如果有一样数据没有表达人物的真实情感,对识别结果的影响是极其巨大的,即使引入注意力机制也不能有效解决,所以引入脑电、心率等生理特征非常关键。目前有一些学者引入了脑电等生理特征,如文献[79]基于面部表情、皮肤静电反应和脑电图提出了一种基于混合融合的多模态情感识别系统,但是对于引入生理特征方面的算法还非常欠缺和不成熟。
3)多模态情感识别对数据量要求较高,缺少任何单一模态的数据都会影响到最终的识别结果,引入小样本学习且精度不降低也是迫切需要解决的问题。
4)模型过于复杂。目前基于深度学习的多模态情感识别方法模型参数过多,模型的训练时间过长,如何精简网络结构也是需要关注的问题。
5)多模态数据的特征提取与优化。特征提取对于情感识别是最重要的一环,直接影响最终的识别结果,如何将提取到的特征进一步优化来提升模型的鲁棒性也是值得研究的,例如怎样高效的剔除冗余重复的情感特征。
猜你喜欢
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
噪声与振动控制(2015年4期)2015-01-01 07:08:21
计算物理(2014年2期)2014-03-11 17:01:39
