
FastGR:一种基于神经协同过滤的群组推荐算法
2022-07-06 10:32尚文倩
南京师范大学学报(工程技术版) 2022年2期
尚文倩,曹 原
(1.中国传媒大学媒体融合与传播国家重点实验室,北京 100024) (2.中国传媒大学计算机与网络空间安全学院,北京 100024)
大数据时代,推荐系统作为一种解决信息过载问题的有效手段,被广泛应用于各大电商平台、新闻客户端、流媒体应用等. 在为用户提供个性化推送的同时,也提高了平台的收益.
目前,推荐系统的研究大多面向单一用户[1]. 国内外学者提出了很多经典模型,如FM[2]、Wide&Deep[3]、 DeepFM[4]、DIN[5]等,在工业界取得了杰出的成果. 然而这些模型无法直接应用于群组推荐问题.
在日常生活中,社交网络、电商团购等平台将用户由相同的兴趣、地理位置、社会关系等特性聚集在一起形成群组,群组内成员的偏好千差万别. 在深度神经网络未流行之前,一般采用预定义的策略(如均值策略)[6]解决群组偏好融合问题,但该方法不够灵活. 文献[6]提出的AGREE模型基于表示学习方法计算出用户和物品的嵌入向量后利用注意力机制在推荐不同的物品时动态地为组内用户分配不同的权重,相较于预定义策略显著提升了推荐效果,达到了业界顶尖水平. 但在执行群组推荐任务时对不同物品需要为组内每一位成员计算其注意力分数,群组偏好融合算法时间复杂度高,是制约整个模型效率提升的瓶颈.
本文设计了一种基于神经协同过滤的群组推荐算法(fast group recommendation,FastGR),在不损失模型推荐精度的前提下,优化群组偏好融合算法,加快训练与推理速度,从而提升模型效率.
1 相关工作
文献[7]提出的神经协同过滤(neural collaborative filtering,NCF)使用多层感知器代替基于矩阵分解协同过滤算法中的内积操作,其主要思想是通过神经网络训练用户和物品的嵌入向量,学习匹配函数,引入非线性特征,增强了模型的表达能力. FastGR基于NCF框架训练群组内用户嵌入向量和物品嵌入向量,并提出一种一维全域卷积(global convolution)聚合群组成员偏好特征得到群组嵌入向量,无需预训练即可达到现有主流模型的性能且训练速度显著加快. 文献[8]认为群组推荐可分为3个步骤:群组形成、群组建模和群组预测推荐,根据偏好融合发生阶段及融合内容的不同,将偏好融合方法分为3类:偏好模型融合、推荐结果融合和评分融合.
推荐系统中用户和物品的特征主要为高维ID类特征,其所导致的特征数据稀疏性、模型训练难度挑战就成为驱动表示学习的最直接源动力. 具体地,在输入数据(例如用户ID、物品ID)预处理后,由嵌入层把稀疏的ID转化为固定长度的嵌入向量(embedding),即用向量X=(X1,X2,…,XN)表示某一实体,方便模型处理. 目前最先进的AGREE采用了基于表示学习方法的NCF框架学习群组与物品交互行为,使用注意力机制对群组偏好进行融合. 本文在AGREE开源代码上实验时发现模型执行群组推荐任务过程中耗时较长,存在优化空间.
TextCNN[9-10]是一种文本分类模型,通过引入卷积神经网络[11],靠卷积核窗口抽取特征,将语句中的词向量聚合为句子向量,具有对文本浅层特征的抽取能力强、速度快及对语序不敏感的特性.
受TextCNN启发,本文在AGREE的基础上利用NCF学习群组内成员的嵌入向量,提出了一种全域卷积的方式融合群组偏好特征.
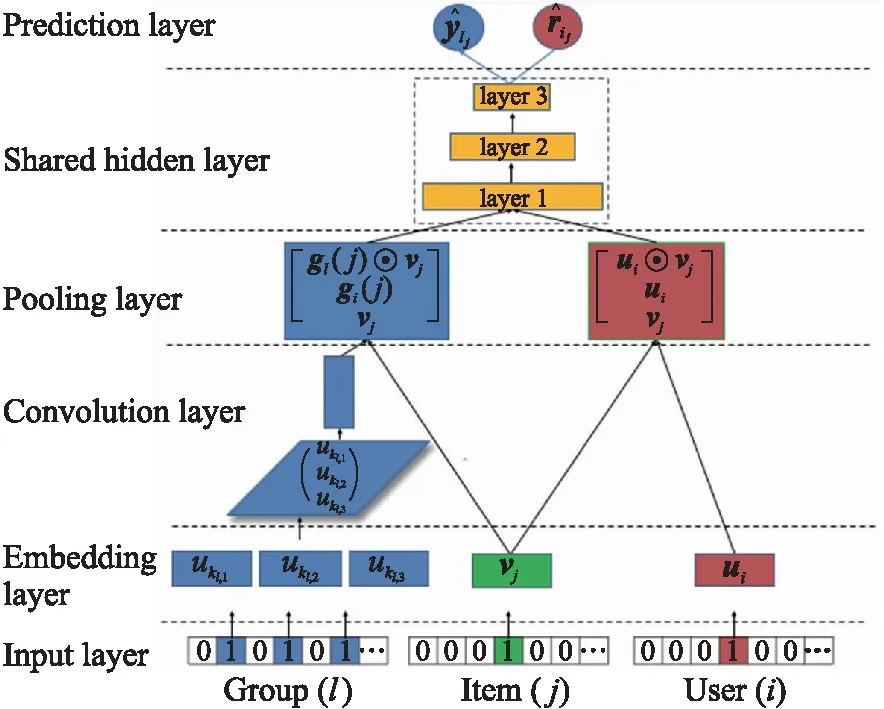
图1 基于神经协同过滤的FastGR模型结构Fig.1 Structure of FastGR based on NCF
2 基于神经协同过滤的群组推荐模型框架
FastGR与AGREE的不同之处在于群组偏好融合模块,用卷积层替代了注意力层. FastGR模型整体结构如图1所示.
(1)
通过共享隐含层,用户-物品与群组-物品的学习任务相互促进,协同优化.最后分别在预测层输出群组l对物品j的分数ylj、用户u对物品j的分数rij.
目标函数采用推荐系统中常用的基于回归的成对损失方法(regression-based pairwise loss):
(2)
式中,O代表训练集;三元组(l,j,s)表示群组l与物品j有过交互行为,而与物品s无交互行为(负样本).
3 基于一维卷积的偏好融合
3.1 用户嵌入向量聚合
组内成员用户偏好融合算法决定了群组推荐结果.AGREE模型基于表示学习框架得到组内成员与物品的嵌入向量后,利用注意力机制可以动态学习群组中用户所占的比重,最后由成员嵌入向量乘上该比重完成用户嵌入向量聚合. 这种偏好融合方法相较于传统基于预定义策略更加灵活,但在时间复杂度上还有很大的优化空间.
受TextCNN思想启发,一条语句由多个词语组成,而一个群组也是由多个用户组成,因此群组成员偏好的融合可以类似于句子中的多个词语嵌入向量聚合为句子嵌入向量. FastGR卷积层结构如图2所示.
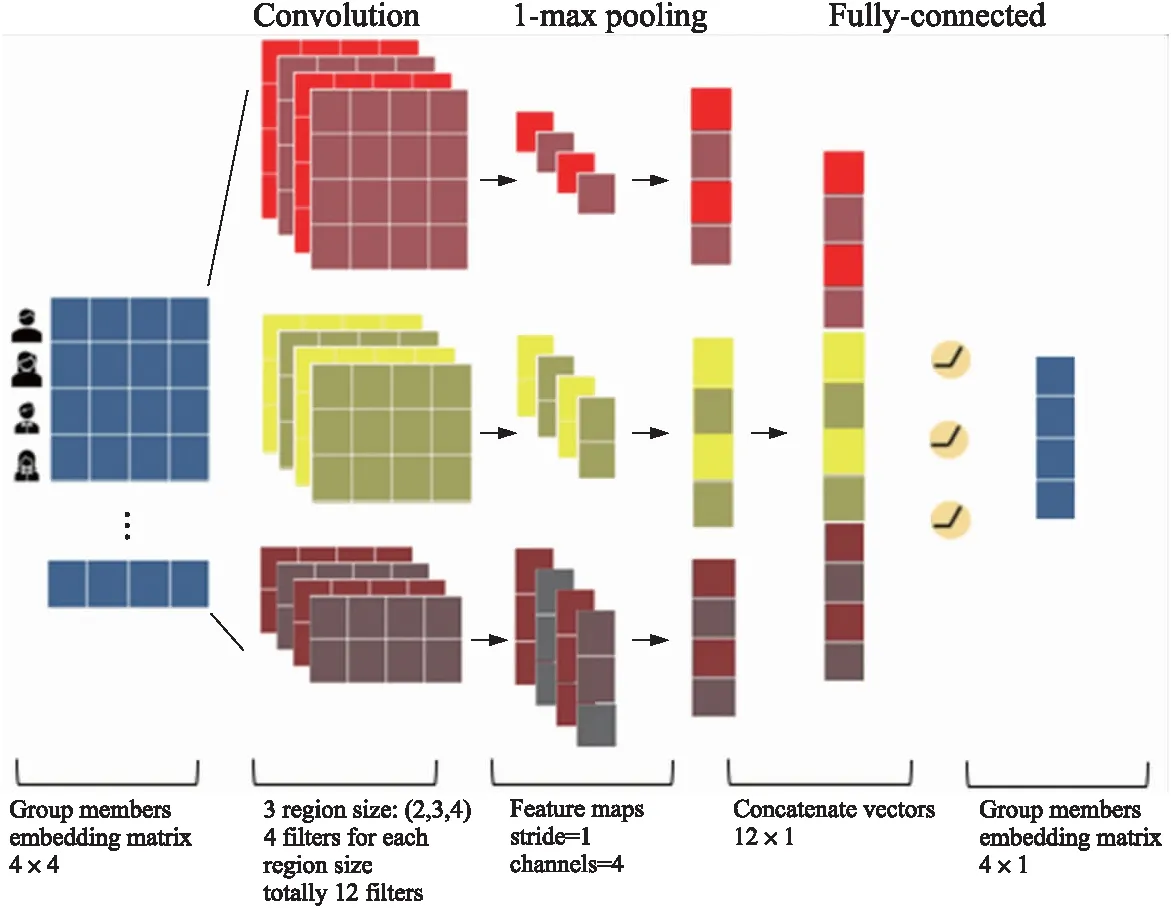
图2 FastGR群组成员偏好融合结构图Fig.2 Structure of FastGR group members prefer fusion
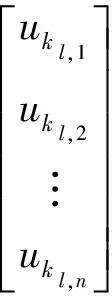
在NCF框架中可以由用户与物品的交互行为学习到用户的嵌入向量ui(其他框架如YoutubeDNN[11-13]等也可生成用户嵌入向量),之后将组内成员看作构成句子的词语,通过纵向拼接组内成员的嵌入向量ui得到一个二维矩阵u1∶n,如式(3)所示:
u1∶n=u1⊕u2⊕…⊕un.
(3)
假设某个组有n(n≥2)位成员,与TextCNN相似,采用多个窗口(n={2,3,4…n})的卷积核在成员嵌入向量堆积成的矩阵上做卷积运算得到用户i的Feature Mapci,如式(4)所示,其中w∈Rnk,窗口大小为n×k:
ci=f(w·ui:i+h-1+b).
(4)
使用1-max pooling[9]对提取到的Feature Map进行降采样c=max{c},以解决卷积核大小不同带来的Feature Map尺寸不一致问题.
考虑到卷积神经网络对局部特征敏感,无法有效捕获全局数据之间的长距离特征,FastGR卷积层采用全域卷积,最大卷积核尺寸(n×k,k为嵌入向量维度)与组成员矩阵保持一致(如图2中的红色卷积核),并借鉴文献[12]的思想,FGCNN[12]使用重组层进行特征生成缓解这一问题. 具体地,将池化后的Feature Map展平成一个向量,然后使用单层的全连接层进行特征组合,全连接层可以解决成员间不同排列顺序导致的模型性能不稳定问题,增加了模型的鲁棒性:
gl=f(wT·c+b).
(5)
由于卷积神经网络权重共享机制[14-15],卷积层提取到的特征具有平移不变性,对位置信息不敏感,且采用全域卷积提取整体特征,最后由全连接层进行特征重组,因此拼接顺序不影响特征提取[16-20].
融合得到的群组嵌入向量gl可与物品嵌入向量Vj拼接,经过多层隐含层,如式(6)进行高阶特征交互,最后由sigmoid激活函数映射到0到1之间,可以看作为群组l对物品j的分数,如式(7)所示:
(6)
(7)
式中,wh、bh、eh为分别为第h层的权重矩阵、偏置向量和输出神经元.
3.2 群组成员偏好融合策略比较
基于注意力机制的AGREE和基于一维全域卷积的FastGR在聚合群组内用户嵌入向量的算法如下所示,本节比较两种模型在速度上的优势.

二者训练时均采用mini-batch方法,上述算法伪代码即为单个小批次模型计算群组嵌入向量的步骤.
通过研究AGREE的群组偏好融合算法可以发现,制约模型训练速度的关键在于计算每一位组内成员的注意力分数,该操作在循环内部执行,循环次数为batch size,是一个超参数,此处设定为256. 对于每一次循环占用的时间假设为t:
t=tm+ti+ta+tg,
(8)
式中,tm为计算每个组的成员列表占用的时间;ti为嵌入层计算物品嵌入向量占用的时间;ta为注意力层计算注意力分数占用的时间;tg为嵌入层计算组嵌入向量占用的时间.
由此可计算出一个小批次占用的时间TAGREE:
TAGREE=batch size×t.
(9)
而FastGR仅需在循环内得到每个组的成员列表,并补齐至相同长度(此处采用补零填充),然后在循环外部根据组成员列表计算这一批次内所有组的成员嵌入向量后直接通过卷积层提取特征,一个小批次占用的时间TFastGR为:
TFastGR=batch size×tm+tc,
(10)
式中,tc为卷积层占用的时间,只需要计算一次.
可见,TFastGR远小于TAGREE,因而FastGR模型的速度要快于AGREE模型,训练耗时显著降低.
4 模型评价指标
为了更公平地与AGREE模型比较,本文在模型的各个维度上(如优化方法、学习率、负采样率等)都与AGREE保持一致,采用命中率(hit ratio,HR)和归一化折扣累积增益(normalized discounted cumulative gain,NDCG)作为模型的评价指标. HR衡量测试集中的项目是否出现在模型预测的top-K列表里,HR值越大,说明模型推荐命中的越多,反映了模型的准确度. NDCG衡量排序质量,即测试项目出现在top-K列表中位置越靠前得分越高.
(11)
(12)
式中,GT表示所有测试项目的集合;ZK是归一化系数,将DCG的值保持在0~1之间;ri表示处于位置i的推荐结果的相关性,若命中则ri为 1,否则为0.
5 实验结果及分析
在公开数据集上对比了NCF、GREE(AGREE移除注意力模块)、AGREE、FastGR群组推荐任务的性能和效率,以验证本文方法的可行性与高效性.
5.1 数据集
CAMRa2011为AGREE采用的公开数据集,包含了个人用户和群组观看电影的评分记录,通过将有过评分的项目标记为1即正样本、随机采样若干个未观看过的电影标记为0即负样本进行训练.
5.2 实验和结果
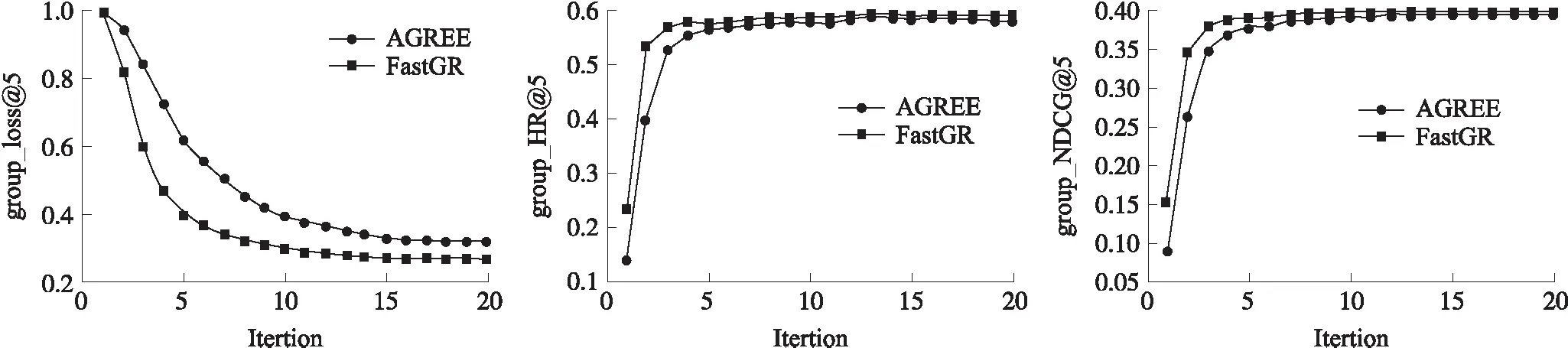
图3 模型性能比较Fig.3 Performance comparison on CAMRa2011
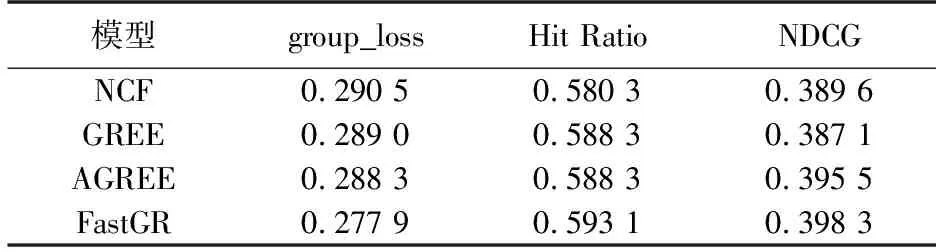
表1 在CAMRa2011上的实验结果Table 1 The performance results on CAMRa2011
本文基于PyTorch实现FastGR模型,其他基线模型NCF、GREE和AGREE为文献[6]的开源版本.
模型优化方法为RMSProp,嵌入层采用Xavier均匀初始化策略[6],top-K=5,采用学习率固定步长衰减策略,验证方法同AGREE一致采用leave-one-out进行评估. 如表1所示,在相同实验条件下,FastGR的HR提高了0.81%,NDCG提高了0.70%.如图3所示,本文分别从群组推荐任务的loss、HR、NDCG 3个指标比较两个模型20轮次迭代训练过程,可以看出FastGR在群组推荐任务中模型收敛更快,且性能上要好于AGREE. 从表2可以看出,FastGR在CPU和GPU上效率均优于AGREE,不同操作系统上训练速度均提升14倍左右.
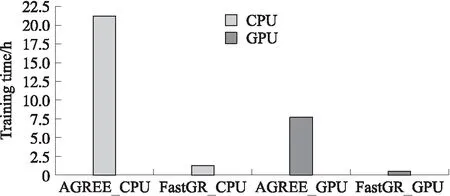
图4 模型效率比较Fig.4 Efficiency comparison on CAMRa2011
如图4所示,由于用户嵌入向量聚合模块重构后时间复杂度降低,模型训练速度得到了提升. 这是由于精简了模型结构并大大减少了运算量,这一改进使得模型部署上线工程难度降低,显著提升了模型效率.
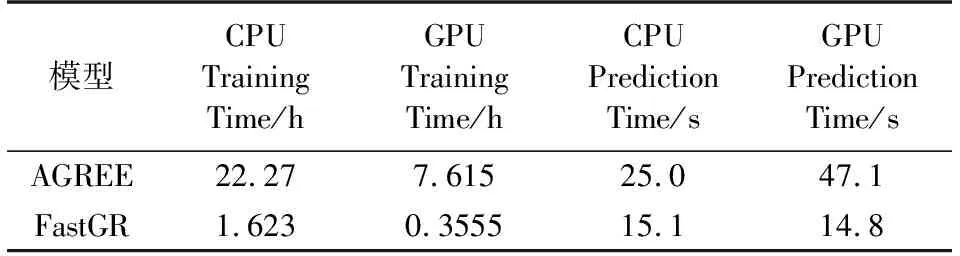
表2 在CAMRa2011上的训练与推理时间Table 2 Efficiency results on CAMRa2011
6 结论
如何为群组推荐系统设计更快速、更合理的偏好融合算法,本文在现有方法的基础上提出了一种基于神经协同过滤和一维全域卷积的群组推荐算法FastGR,通过神经协同过滤框架学习用户的嵌入向量,利用一维卷积来提取群组成员的特征从而实现偏好融合. 公开数据集上的实验结果表明,本文方法在群组推荐准确度尤其是效率方面优于现有方法.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
