
基于语义连通图的场景图生成算法
2022-07-06 10:32姜有亮张锋军沈沛意
南京师范大学学报(工程技术版) 2022年2期
姜有亮,张锋军,沈沛意,3,张 亮,3
(1.西安电子科技大学计算机科学与技术学院,陕西 西安 710071) (2.中国电子科技网络信息安全有限公司,四川 成都 610041) (3.西安电子科技大学西安市智能软件工程重点实验室,陕西 西安 710071)
深度学习技术在目标检测、图像语义分割等基本视觉理解任务上取得了显著的成果,但对于对视觉信息的整体感知和有效表达仍然不够. 人们希望计算机可以理解图像中更深层次的语义信息. Johnson等人提出了场景语义结构图(scene graph,简称场景图)[1],这是一种对特定场景中语义信息的结构化文本表示,其中,节点表示物体,边表示物体之间的关系. 场景图生成是将输入的图像解析成一种结构化的文本表示,其核心任务是检测视觉关系,即检测关系三元组(主体、关系、宾语)[2-4]. 目前主流的场景图生成方法遵循两阶段流程[5],第一阶段由目标检测算法得到图像中的物体集合,并根据物体的信息提取关系特征,然后执行一个分类任务以确定每个物体对之间的关系.
场景图生成的基础任务是目标检测. 现有的目标检测算法有传统检测算法和基于深度学习的检测算法. 传统目标检测算法多基于滑动窗口的框架或是根据特征点进行匹配,已难以满足人们对目标检测效果的要求. 随着深度学习在图像分类任务上取得巨大进展,基于深度学习的目标检测算法逐渐成为主流,并取得了极大的成功. 目前基于深度学习模型的目标检测算法可分为两大类:一种是基于区域建议的目标检测算法,其将目标检测问题划分为两个阶段,第一阶段产生候选区域(region proposals),包含目标大概的位置信息,第二阶段对候选区域进行物体分类和位置精修,该算法的典型代表有R-CNN[6]、Fast R-CNN[7]和Faster R-CNN[8]等;另一种是基于回归学习的目标检测算法,其不需要区域建议阶段,可直接预测物体的类别概率和位置坐标值,比较典型的算法有YOLOv1-v3[9-10]、SSD[11]和RetinaNet[12]等.
图卷积神经网络(graph convolutional neural network,GCN)的出现是为了在非欧几里得结构数据上进行卷积操作. 目前图上的卷积定义可分为两类[13]:一是基于频域或谱域(spectral domain)的图卷积,通过傅里叶变换将结点映射到频域空间,通过在频域空间上做乘积来实现时域上的卷积,最后再将做完乘积的特征映射回时域空间;另一种是基于空间域(spatial domain)的图卷积,通过聚合邻居节点的信号对节点的特征做变换. 基于空间域的图卷积神经网络模型是近年来研究的热点,代表性的模型有GCNConv[14]、GAT[15]和GraphSAGE[16]等.
本文提出一种基于语义连通图的场景图生成算法,将关系检测过程分为关系建议和关系推理两步. 以目标检测算法得到的候选对象为节点集合,构建一个全连接图,并使用物体的类别信息和相对空间关系计算物体之间存在关系的概率,通过设置阈值来删除图中无效连接,得到稀疏的语义连通图. 为了融合物体的上下文信息,使用图神经网络对图节点的特征进行聚合. 最后根据语义连通图的连接关系,结合更新后的主语和宾语特征,以及两个物体联合区域的特征构建关系特征,预测语义图中的每条边对应的关系类别.
1 问题研究和意义
1.1 基本定义
场景图生成可以看成两阶段的语义检索过程,首先使用目标检测算法生成节点,然后检测物体间的视觉关系得到边.
定义1给定一张图像I,其对应的场景图用S表示,B={b1,…,bn}⊆R4是候选区域的集合,元素bi表示第i个区域的边界框.O={o1,…,on}⊆N是对象的集合,元素oi表示区域bi对应的物体的类别标签.R={r1→2,r1→3,…,rn→n-1}是关系的集合,元素ri→j对应一个视觉关系三元组ti→j={si,ri→j,oj},其中si和oj分别表示关系的主语和宾语.场景图生成过程可以分解为3部分[17]:
p(S|I)=p(B|I)p(O|B,I)p(R|O,B,I).
(1)
式(1)中,边界框组件p(BS|S)生成一组候选区域,这些区域包含了输入图像中的大部分关键对象.对象组件p(OS|BS,S)预测每个区域中物体的类别.这两部分可通过广泛使用的Faster R-CNN检测器来实现.关系组件p(RS|OS,BS,S)推断每个物体对之间的关系.
1.2 语义连通图
场景图生成的核心是检测视觉关系.检测一对物体间的关系有两种思路,一种是直接看作分类问题,即假设数据集中共有K种关系谓词,则有K+1种分类结果,其中+1表示两个物体间没有关系;另一种是先预测两个物体之间是否存在关系,若存在关系,则再进行K种关系的分类. 对于第一种方式,将任意两个对象关联为一个可能的关系会形成一个全连接图,通过删除一些在语义上弱依赖的对象之间的连接便形成稀疏的语义连通图. 语义连通图中的边表示两端的物体间的语义关联度更强,更易发生关系. 稀疏的语义连通图计算量小,精简了节点的邻接域,减少了干扰,使用图网络提取特征更合理高效.
2 基于语义连通图的场景图生成算法
2.1 网络整体结构
基于语义连通图的场景图生成算法的整体网络结构如图1所示,主要分为以下几个步骤:
(1)目标检测和特征提取:使用Faster R-CNN网络检测物体,并使用Faster R-CNN的输出构建物体节点的初始特征.
(2)关系提议:将任意两个对象关联为一个可能的关系以形成一个全连接图,然后使用一个关系建议模块删除不会发生关系的两个物体之间的连接,从而形成一个稀疏的语义连通图.
(3)特征增强:在语义图上使用图卷积网络模型对结点的特征进行更新和增强,使得结点融合上下文环境信息.
(4)联合区域视觉特征提取:对于有连接关系的物体对,将其联合边界框映射到特征图上,得到关系RoI,使用CNN提取关系RoI对应的视觉短语特征.
(5)物体和关系预测:根据细化的对象特征重新预测物体类别,将视觉短语特征、主语和宾语特征进行哈达玛乘积运算得到关系的特征,使用分类器对关系进行分类.

图1 整体网络结构示意图Fig.1 Overview of the model
2.2 特征提取网络
本文使用Faster R-CNN网络作为基础的目标检测模型. Faster R-CNN的输出包含物体的类别信息(类别概率向量)和物体边界框(bounding box,BBox)(代表物体在图像上的位置信息). 对于Faster R-CNN检测出的每个物体,可以得到3种初始信息:
(1)视觉特征:物体的视觉特征使用Faster R-CNN后端的两层全连接层输出的4 096维特征,vi∈R4096.
(2)空间特征:物体的边界框由(x,y,w,h)4个值表示,分别为中心点的横纵坐标及矩形框的长和宽,用正弦位置编码对位置坐标进行转化,然后使用一组可训练的参数以学习的方式转化相对位置特征,将 4维向量表示的位置特征映射到128维,即si∈R128.
(3)语义特征:语义特征是物体类别标签的词嵌入(word embedding),采用预训练的Word2vec将类别标签转化为对应词向量li∈R200.
2.3 关系建议网络
在所有O(n2)个物体对中,只有一小部分物体对可能具有关系.大量的连接会使训练和推理难以进行,且冗余的关系建议会降低召回性能.因此需要构建一个语义指导的关系建议网络,以删除全连接图中语义依赖性弱的物体之间的连接,从而构建高效的语义连通图.本文使用预训练的Word2vec模型学习单词嵌入,从而得到对象之间的语义依赖.词嵌入矩阵为We∈RC×m,每一行为一个物体类别标签的词嵌入向量,则物体i的语义嵌入可表示为:
ei=si·We,
(2)
式中,si∈RC为物体i的预测类别分布向量,是Faster R-CNN后端用于分类的全连接层的输出,C为数据集中物体类别数量.式(2)表示的词嵌入是一种软嵌入,考虑了Faster R-CNN模型给出的对象类别预测的不确定性,能够减轻对象分类误差带来的负面影响.
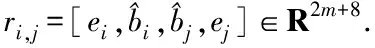
(3)
然后将关系表示ri,j送入多层感知机(multilayer perceptron,MLP). MLP的输出由Sigmoid函数正则化到[0,1]区间,即得到语义依赖分数SCi,j,该分数表示对象对(oi,oj)之间形成一个有意义的关系的可能性.选择语义依赖得分在top-K且大于阈值的对象对. 由于非极大值抑制(non-maximum suppression,NMS)[18]会降低关系提议的召回率,本文使用top-K来限制关系建议的最大数量,以提高训练的有效性,并使用分数阈值来减少冗余.
2.4 特征更新网络
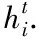
(1)GCNConv:GCNConv从图谱理论角度定义图结构上的卷积操作,其信息聚合的方式为:
(4)
(5)
式中,ej,i表示源节点i到目标节点j之间的边的权重.
(2)GAT:GAT将自注意力机制引入图网络,注意力机制可看作为在将一个节点的邻居的特征聚合到这个节点时为每个邻居节点分配的权重,其节点特征的更新方式为:
(6)
其中,注意力系数αij由下式计算:
(7)
式中,[.]表示拼接操作;Λ为向量变换,由全连接层实现.

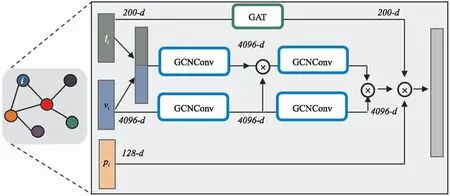
图2 特征更新网络结构图Fig.2 Illustration of the feature refining module
2.5 关系推理网络
图3 关系推理网络结构图Fig.3 Illustration of the relation reasoning module

3 实验与结果
3.1 数据集
Visual Genome[19]数据集是目前拥有最多的物体和视觉关系的开放数据集. 由于数据集中的注释是由众包工人完成的,很大一部分对象注释的质量很差,且有重叠的边界框和含糊不清的对象名称. 为了消除这些干扰,很多研究人员已经探索了多种半自动的方法(如类合并和过滤)来清除对象和关系注释,构建出很多过滤后的VG版本. 本文的实验使用VG150[20]和VG-MSDN[21]两个数据集. VG150对每张图像修正了22个边界框或对象名称,删除了7.4个边界框,合并了5.4个重复的边界框. 基准测试方法使用最常用的150个对象类别和50个谓词关系类别进行实验评估. 因此,每张图像对应一个大约由11.5个对象和6.2个关系构成的场景图VG150保留了VG数据集全部的108 077张图像. VG-MSDN对不同时态的词进行规范化,同样选取了150个最常见的物体种类和50个关系类别,同时删除边界框的短边小于16像素的物体的标注信息,经处理后剩余95 998张图像.
3.2 评价指标
本文评价指标为图像级的召回率Recall@K(R@K)[22],用以计算预测的关系三元组中置信度最高的前K个中包含的真实关系组合的比例.实验中K分别取50和100.具体计算方式为:给定N张图像,对于每张图像首先对所有预测的视觉关系按照得分进行排序,然后取得分为前K的预测.视觉关系的得分由包括主语对象的分类得分、宾语对象的分类得分和视觉关系谓词的分类得分相加而得.对于图像i,若其包含|GTi|组真实的关系标注,而模型正确预测到的关系组合为TPi=TopKi∩GTi,则召回率为:
(8)
3.3 任务设置
给定一幅图像,场景图生成任务包括对一组对象进行定位,对其类别标签进行分类,以及预测这些对象之间的关系. 对场景图生成模型的性能评估通常有多种不同的任务设置,本文将在以下3种任务中测试所提出的模型:
(1)谓词分类任务(predicate classification,PredCls):给定图像中物体的类别标签和边界框信息,检测物体对之间是否存在关系,并对关系进行分类;
(2)场景图分类任务(scene graph classification,SGCls):给定图像中的一组物体的边界框,预测物体类别,并检测物体之间的关系;
(3)场景图检测任务(scene graph detection,SGDet):给定一张图像,需检测出图像中的物体,并检测物体间的关系.
3.4 实验和结果
本文在VG150和VG-MSDN数据集上对所提出的场景图生成算法性能进行测试,并与现有算法进行比较,结果如表1所示.

表1 各种模型的结果对比Table 1 The results of various models
从表1可以看出,本文提出的基于语义连通图的场景图生成算法在两个数据集上都取得了较好的结果. 由于VG150数据集中选取的是出现频率最高的150种物体和50种关系,对于SGCls 和SGDet两个任务,同样的算法在VG150数据集上的结果更好一些. 在VG150数据集上,本文的算法在3个任务上都比其他算法在召回率上有大幅提升,提升约5%~10%,而在VG-MSDN数据集上与其他的算法效果不相上下. 在PredCls任务上,R@50提升明显,而其他指标稍低,推测在关系建议模块中删除的连接较多,可能误删了一些有效关系.
为了更直观地显示算法生成场景图的结果,在VG150数据集的测试集中随机选取了6张图像进行测试,并将结果可视化表示,如图4所示. 上方图像中标记了物体的类别和Bounding Box,下方是图像对应的场景图,其中绿色标记是算法输出的正确检测结果,红色标记是算法未检测到或是检测错误的物体和关系,检测错误的物体和关系在括号中给出了ground truth标签. 可以看出,大多数的物体和关系均可检测到,但物体分类错误的情况仍较多. 从第四张和第五张图像的测试结果可以看出,虽然物体分类错误,但关系仍可检测出来,说明模型在一定程度上还是可以学习到独立于物体的关系特征表示. 同时,检测错误的物体确实存在一定的干扰,如第五张图像中的两个检测错误的“person”,都有雨伞的遮挡.

图4 VG150数据集上的测试结果示例Fig.4 Some visualization test samples of ours model on VG150 dataset
4 结论
本文提出了基于语义连通图的场景图生成算法,借助物体的语义信息预测物体之间是否存在关系,同时使用图卷积神经网络融合物体节点的特征,并使用融合了上下文信息的物体特征组合构建关系特征,对关系类别进行推理. 经实验验证,本文算法在VG150和VG-MSDN两个数据集上都取得了有竞争力的结果.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
导航定位学报(2022年4期)2022-08-15
现代电子技术(2022年4期)2022-02-21
智能计算机与应用(2021年4期)2021-06-05
少儿画王(3-6岁)(2020年4期)2020-09-13
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
东方教育(2018年20期)2018-08-22
长江学术(2015年1期)2015-02-27
微型计算机(2009年4期)2009-12-23
