
面向“15分钟生活圈”社区结构的表示学习
2022-07-05 08:36孙焕良彭程刘俊岭许景科
计算机应用 2022年6期
孙焕良,彭程,刘俊岭,许景科
面向“15分钟生活圈”社区结构的表示学习
孙焕良,彭程,刘俊岭*,许景科
(沈阳建筑大学 信息与控制工程学院,沈阳 110168)(*通信作者电子邮箱liujl@sjzu.edu.cn)
利用城市大数据发现社区结构是城市计算中重要的研究方向。有效表示面向“15分钟生活圈”社区的结构特征可以细粒度地评价生活圈社区周围的设施情况,有利于城市规划建设,创造宜居的生活环境。首先,定义了面向“15分钟生活圈”的城市社区结构,并采用表示学习方法获取生活圈社区的结构特征;然后,提出了生活圈社区结构的嵌入表示框架,框架中利用居民的出行轨迹数据确定兴趣点(POI)与居民区的关系,构建反映不同时段居民出行规律的动态活动图;最后,对构建的动态活动图采用自编码器进行表示学习得到生活圈社区潜在特征的向量表示,从而有效概括居民日常活动所形成的社区结构。针对生活圈社区便利性评价、相似性度量等应用,利用真实数据集进行了实验评估,结果表明,分POI类别的日周期的潜在表示方法优于星期周期的潜在表示方法,且前者的归一化折损累计增益(NDCG)比后者最少提升了24.28%,最多提升了60.71%,验证了所提方法的有效性。
表示学习;城市社区;15分钟生活圈;社区结构;自编码器
0 引言
城市社区结构反映了社区居民与周围生活设施、兴趣点(Points Of Interest, POI)之间的关系[1]。现有对城市社区结构的研究可以分为两大类:一类是通过对静态的城市POI分布进行分析来探索城市空间配置[2-5];另一类是通过对城市居民活动规律进行分析来识别城市区域功能,探索城市区域间的差异[6-7]。现有相关工作大多从宏观角度研究城市社区结构[6-8]。
目前,我国将现有居住区的近距离生活圈内设施品质提升作为规划建设的重要目标[9]。2018年住建部《城市居住区规划设计标准》中强调通过生活圈来划分居住单元,重点规划建设“15分钟生活圈”内的设施,以提升居民的生活质量。其中,“15分钟生活圈”社区是指从居民区步行15 min可达的空间区域,简称为生活圈社区。对生活圈社区结构进行量化分析可以从细粒度角度发现居民区周围设施分布情况,学习生活圈社区结构特征,对完善社区周围设施、便于城市建设和创造宜居的生活环境具有重要意义。
本文研究生活圈社区结构的表示方法,通过生活圈社区居民在周围POI活动情况,采用表示学习技术发现生活圈社区结构。
图1为生活圈社区结构示例,其中:图1(a)为北京市区某生活圈社区附近的POI分布情况,是半径为1 km的圆周范围,中心为生活圈社区,周围分布为不同类别的POI,如商场、学校、餐馆和生活服务等;图1(b)为该生活圈社区结构图,表示为星型结构,中心为生活圈社区,四周为必要的POI,用线与中心连接。生活圈社区结构展示了其周围必要的POI及居民对这些POI依赖的程度。

图1 生活圈社区结构图示例
实现生活圈社区结构的有效表示具有挑战性,主要体现在:1)生活圈社区周围分布大量的POI,仅统计POI数量并不能准确地描述生活圈社区结构,确定对居民日常生活必要的POI是一个挑战;2)在居民日常生活中,不同POI的重要程度有差异,例如一个超市的重要性要大于一个银行网点,因此评价POI的重要性也是具有挑战性的工作;3)居民在生活圈内的活动具有周期性,构建生活圈社区活动图并进行POI嵌入表示也是一个挑战。
为了解决以上问题,本文比较分析了百度地图路径查询、出租车轨迹及共享单车轨迹数据,采用行程距离较短可以反映居民日常活动轨迹的共享单车数据来构建居民活动图;利用居民区到POI的轨迹数据标记生活圈社区必要的POI,结合居民访问POI的频率、居民区与POI的距离及POI的类别确定POI的重要性。
为了构建生活圈社区活动图,本文分析了不同时段居民的出行规律,获取相对稳定的活动模式生成动态活动图。对构建的动态活动图集合采用自编码器表示学习,得到了生活圈社区潜在特征的向量表示,有效概括了居民日常活动所形成的社区结构。
本文主要工作如下:
1)定义了面向“15分钟生活圈”的社区结构,用于描述居民区周围不同类别POI的必要性与重要性;
2)提出了生活圈社区结构的嵌入表示框架,框架中利用共享单车数据构建生活圈社区活动图,采用自编码器表示学习方法对POI进行嵌入表示;
3)针对生活圈社区便利性评价、相似性度量等应用,利用真实数据集进行实验评估,验证本文方法的有效性。
1 问题定义
以下给出相关定义,并形式化所提出的问题。
定义1给出的生活圈社区结构为一个星形图,如图1(b)所示:中心为生活圈社区,四周分布着不同类型的POI。每个POI有位置、类型及重要性等属性,为居民提供日常生活相关的服务,居民可以短距离地出行访问这些POI。
居民在生活圈社区周围的活动是动态的,同时呈周期性变化[10]。例如,在工作日的早上居民大多上班,活动范围在公交站和地铁站附近,而在周末的早上居民会在市场周围活动。因此,为了更好地描述生活圈社区结构,定义了生活圈社区活动图,见定义2。
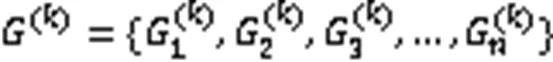
现有的社区结构表示方法,如文献[8]中提出的表示方法无法直接应用于生活圈社区结构的表示。现有社区结构表示关注大范围城市社区结构,通过构建社区内反映各POI间联通关系的图结构进行表示学习。本文研究面向“15分钟生活圈”社区,更关注生活圈社区周围的POI分布,通过构建生活圈社区与POI间的星形活动图进行表示学习。
2 相关工作
2.1 城市社区结构与功能划分
随着感知技术和计算环境的成熟,以城市大数据为基础的城市计算得到广泛关注,城市社区结构与功能计算是城市计算重要的研究方向[11]。
在城市社区结构方面,文献[3]中使用街景图片和POI对社区结构进行描述;文献[8]中提出了一个集体嵌入框架,从人类移动的多个周期性时空图中学习社区结构。
在城市功能区发现方面,文献[4]中使用skip-gram模型和t-SNE技术,利用城市POI数据探索城市区域功能并实现可视化;文献[6]中利用POI和出租车轨迹发现了城市的区域功能;文献[7]中提出了一个概率潜在因素模型学习一个地区的城市功能组合。
本文属于社区结构发现方向,现有相关工作如文献[6,8],主要关注大范围城市社区结构的表示,对POI之间的联通性或者POI的类别进行嵌入学习。本文研究针对居民的日常生活圈社区结构,通过构建生活圈社区与POI星形图进行表示学习。
2.2 表示学习
表示学习是一种无监督学习方法,旨在从复杂的高维数据中提取有效的低维特征,可以分为词向量表示[12]、图表示学习[13]、时空图表示学习[14]。
表示学习最初的应用为自然语言处理领域,文献[12]中提出了基于神经网络的表示学习模型word2vec用于提取单词的语义特征。
图表示学习旨在学习一个低维向量用于表示顶点或图[15]。图表示学习算法可分为概率模型、流形学习方法与基于重构的算法。其中,概率模型的方法是通过无监督学习层次的特征;流形学习算法采用基于训练集最近邻图的非参数方法[16];基于重构的算法采用自动编码器的方法通过一系列非线性映射将原始特征表示中的实例投影到低维特征空间中,最小化原始和重构特征之间的损失[17]。
时空图表示学习是时空环境下图表示学习的发展[13]。如文献[8]中提出了一个集体嵌入框架学习社区结构。
本文提出的生活圈社区结构表示是一种时空表示学习,重点考虑了居民区周围POI必要性与重要性,通过对居民不同时间段与不同类型POI的活动来学习生活圈社区结构。
3 生活圈社区结构的嵌入表示方法
3.1 框架结构
本文的重点是开发一个生活圈社区结构图的表示学习框架,以获取由居民活动产生的生活圈社区结构的动态变化,具体结构如图2所示。该框架由两个部分组成:第一部分通过POI、居民出行轨迹和居民区数据构建了多个生活圈社区活动图;第二部分将生活圈社区活动图进行嵌入,并使用自动编码器对活动图进行表示。
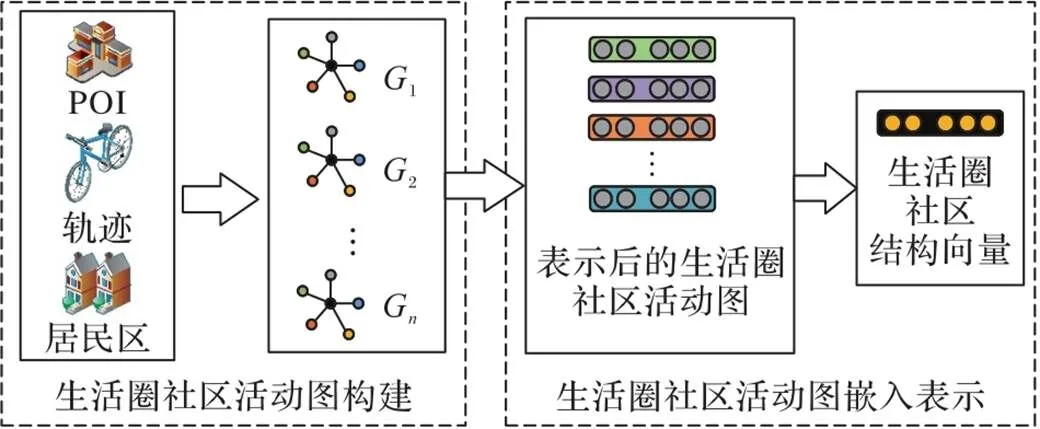
图2 生活圈社区结构表示学习框架
3.2 生活圈社区活动图的构建
本文定义生活圈社区活动图用于反映居民的活动规律,需要确定哪些POI是所在生活圈社区必要的POI,以及这些POI的重要性;同时,需要发现居民周期性的活动规律。因此,本文在构建生活圈社区活动图时采用如下策略:首先,利用共享单车轨迹数据建立生活圈社区与POI的关系;其次,发现居民周期性的活动模式来划分生活圈社区活动图时间段;最后,根据POI与居民区的距离及领域知识对POI赋予权重。
3.2.1 生活圈社区与POI关系的建立
本文需要估计共享单车轨迹数据中居民到达某POI的可能性,并量化居民区与POI之间的移动连通性。因为居民骑行单车的下车点往往在POI附近,无法与POI重合;同时,居民倾向访问与下车点距离近的POI。因此,本文采用文献[17]中基于概率传播的方法来估计居民到达POI的概率,如式(1)所示:


3.2.2 生活圈社区活动图时间段划分
为了更好地了解居民活动规律,需要对生活圈社区活动图进行时间段划分,获取相对稳定的活动模式。文献[8]中将周一到周日的数据生成7个动态图,本文获取了更细粒度的时间片段,将每天的不同时段进行划分。借鉴了文献[18]中提出的主题模型方法来划分片段,即通过滑动窗口以KL散度(Kullback-Leibler divergence)为度量对窗口进行划分,如式(2)所示:


3.2.3 POI权重生成
为了能够更好地区别不同POI对生活圈社区的影响,需要对POI赋予权重,权重越大说明POI的重要性越高。本文考虑了三个影响权重的因素,包括居民访问的频率、与居民区的距离以及类别情况,提出了一种权重计算方法,如式(3)所示:




3.3 生活圈社区结构的嵌入表示
在构建了多个不同时段的生活圈社区活动图后,便可以进行活动图嵌入表示,以发现不同生活圈社区中居民的日常生活规律所形成的社区结构。具体的表示方法如图3所示。
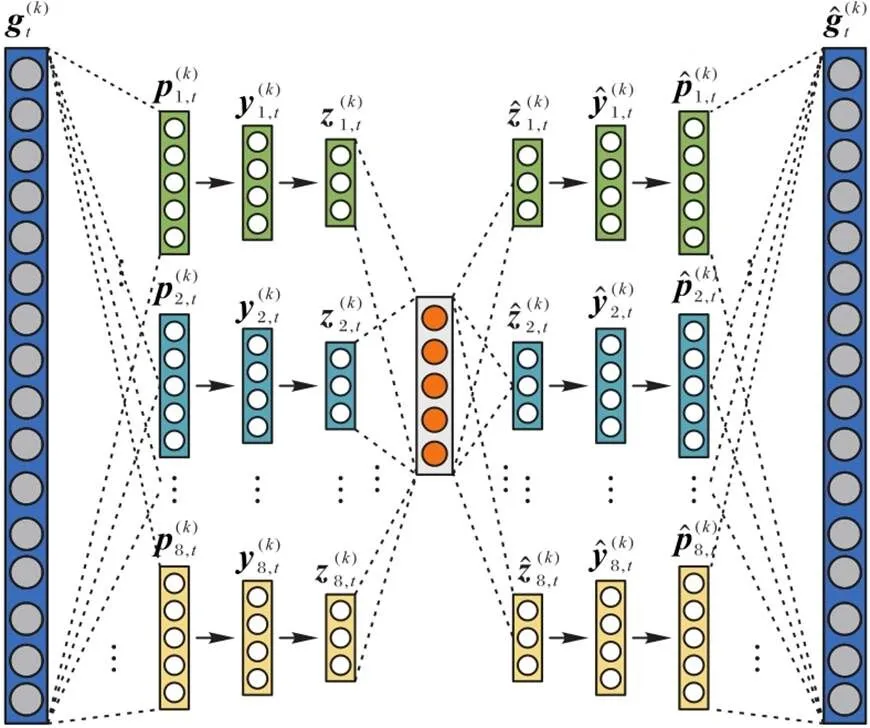
图3 生活圈社区结构的嵌入表示



4 实验分析
4.1 数据准备与实验参数
本文所采用的实验数据集均为真实数据集,如表1所示。第一个数据集是从房地产在线(www.soufun.com)网站获得的,共包含1.3万多个居民生活圈社区。第二个数据集为北京市POI数据集,通过调用腾讯地图API接口下载,共包括180多万19类的POI对象。第三个数据集为轨迹数据,包括百度地图路径查询轨迹、出租车轨迹及共享单车轨迹数据。其中:百度地图路径查询轨迹数据来自百度大脑交通数据集;共享单车轨迹数据来自数据竞赛社区www.biendata.xyz。

表1 实验数据集
为了发现生活圈社区人们日常活动规律,本文分析了轨迹数据的分布情况。对轨迹长度进行了统计,共享单车的平均骑行距离是842 m,出租车的平均行驶距离是11 016 m,百度查询的行程距离是15 302 m。出租车数据和百度查询数据出行距离过大,无法真实反映居民在生活圈社区的日常生活活动,所以本文选用行程距离与15分钟生活圈范围基本相符的共享单车轨迹数据,并且考虑到共享单车的普及性,选取北京五环内的地区作为研究区域。表1给出了所使用的北京市相关数据集的详细情况。在自编码器编码和解码过程中,文本设置编码和解码的层数都为3,自编码器训练轮数epochs为20,每次训练的样本数量batch-size为64。
4.2 生活圈社区便利性评价
用生活圈社区便利性来度量本文表示学习方法的效果,生活圈社区便利性是指生活圈社区居民对周围设施的满意度和可达性[5]。文献[5]中通过调查问卷及随机森林等技术标记了北京市各区域的便利性评分,便利性从低到高分为1到5共5个等级。利用现有的表示方法与本文的表示方法分别对生活圈社区进行表示,生成表示向量,并将文献[5]的标记结果作为所生成表示向量的便利性等级标签;接着将表示向量作为预测属性,利用五种现有学习排序算法对生活圈社区便利性进行预测,通过预测结果评价表示方法。
具体的表示方法如下,其中方法1、2为比较方法,3~5为本文提出的表示方法。
1)显性特征(Explict Feature, EF)方法:该方法将生活圈社区的19类POI每类的总数作为特征。
2)星期周期的潜在表示方法WLF(Weekly Latent Feature)[8]:该方法采用共享单车数据中生活圈社区与POI间的轨迹数据,将一周作为一个周期,每天生成一个生活圈社区活动图,再进行嵌入表示。
3)日周期的潜在表示方法DLF(Daily Latent Feature):将一天通过滑动窗口划分为多个时间段,不区分POI类别,构建生活圈社区活动图并进行嵌入表示。
4)分POI类别的DLF表示方法(Daily Latent Category Feature, DLCF):该方法在DLF方法基础上增加了POI类别,综合第2.2节提出的表示策略设计的方法。
5)DLCF+EF:将DLCF与EF组合形成的方法。
本文选取了五种学习排序方法验证本文表示方法的性能。具体学习排序算法包括:
1)Multiple Additive Regression Tree (MART)[20]:增强的树模型,使用回归树在函数空间中执行梯度下降。
2)RankBoost(RB)[21]:增强的成对排序方法,训练多个弱排序器,并将它们的输出组合为最终排序。
3)ListNet(LN)[22]:列表排序模型,以转换top-排序似然为目标函数,采用神经网络和梯度下降作为模型和算法。
4)RankNet(RN)[23]:使用神经网络对潜在的概率成本函数进行建模。
5)LambdaMART(LM)[24]:基于RankNet通过LambdaRank改进的增强树的版本,结合了MART和LambdaRank。
将以上五种表示方法和五种学习排序方法组合来进行比较,采用归一化折损累计增益NDCG@(Normalized Discounted Cumulative Gain)评价排序结果,NDCG@值越大,评价排序的准确性越高。如图4(a)~(d)所示,比较了五种表示方法和五种学习排序方法组合而成的25个组合的性能。通过实验发现潜在特征和显性特征结合时性能最优,本文提出的框架所学习的潜在特征也优于其他潜在特征学习表示,本文的框架的NDCG结果比其他框架最少提升了24.28%,最多提升了60.71%。结合生活圈社区的动态和静态结构的信息可以更加有效地表示生活圈社区,使生活圈社区的便利性评价更加准确。

图4 生活圈社区便利性比较
由图4可知,DLF优于WLF,原因是DLF对时间段的划分更加符合居民的活动规律,能更好地描述生活圈社区结构的特征;DLCF优于DLF,因为DLCF考虑了POI类别,因此能够更清晰地表示不同类别的POI在不同时段的特征;组合方法DLCF+EF优于DLCF,因为DLCF+EF将生活圈社区的静态的显性特征和动态的潜在特征相结合,能够更加全面地描述生活圈社区。
通过实验发现潜在特征和显性特征结合时性能最优,本文提出的框架所学习的潜在特征也优于其他潜在特征学习表示。结合生活圈社区的动态和静态结构的信息可以更加有效地表示生活圈社区,使生活圈社区的便利性评价更加准确。
4.3 生活圈社区相似性评价
生活圈社区表示可应用于居民生活圈社区的相似性分析。本文选取了朝阳区东四环附近3个真实生活圈社区,通过这3个生活圈社区的特征向量的余弦相似度来比较三者之间的相似性。生活圈社区1和2的余弦相似度为0.964 1,生活圈社区1和3的余弦相似度为0.889 7。表2给出了三个生活圈社区范围为1 km内的不同类别POI分布数量,分析其显性特征情况。

表2 生活圈社区POI分布
由表2可知,虽然生活圈社区1和2的POI分布相差较大,但是两者在潜在特征方面比较相似。调查发现两个现象可能导致它们潜特征相似:第一,在生活圈社区2的1 km范围内有一家大型商场,商场里包含着许多购物类、餐饮类和生活服务类POI,使得在相应类别POI数量与生活圈社区1有较大差异。然而,大型商场与生活圈社区2相隔3个交通岗使得居民访问数量较少,导致与生活圈社区1在相应类别POI分布的差异减小。第二,在生活圈社区1和2区域内均有重点中学,并且学校周围分布着很多餐饮类和生活服务类POI,居民的日常活动大部分集中在学校区域附近,因此即使POI分布差异较大,两者的潜在特征仍然比较相似。
生活圈社区1和3的POI分布数量十分相似,但其潜在特征差异较大。调查发现生活圈社区1的住宅区与3的住宅区距离相近,所以POI分布数量较为相似;然而,生活圈社区3的住宅离学校区域相对较远,使得居民活动轨迹并不在学校区域周围,表现为居民的访问量较少。因此,即使两者间的POI分布数量相似,但其潜在特征并不相似。
通过对生活圈社区潜在特征的学习,可以从动态的角度寻找相似的居民生活圈社区,发现不同居民区之间的潜在相似性,为比较生活圈社区的相似性提供了新方法。
5 结语
本文研究了面向“15分钟生活圈”的城市社区结构问题,提出了生活圈社区结构的嵌入表示框架。该框架由生活圈社区活动图及表示学习两部分组成。采用可以反映居民日常活动轨迹的共享单车数据来建立活动图中的关系,通过分析居民活动模式得到活动图时间片段,对构建的动态活动图采用自编码器表示学习,得到生活圈社区潜在特征的向量表示。使用归一化折损累计增益作为评价指标对生活圈社区的便利性进行评价,验证了所以出框架的优越性。接下来,对生活圈社区范围进行更为细粒度的划分和进行表示学习的研究将是我们进一步工作的重点。
[1] JIANG S, ALVES A, RODRIGUES F, et al. Mining point of interest data from social networks for urban land use classification and disaggregation[J]. Computers, Environment and Urban Systems, 2015, 53:36-46.
[2] 宋正娜,陈雯,张桂香,等. 公共服务设施空间可达性及其度量方法[J]. 地理科学进展, 2010, 29(10):1217-1224.(SONG Z N, CHEN W, ZHANG G X, et al. Spatial accessibility of public service facilities and its measurement approaches[J]. Progress in Geography, 2010, 29(10):1217-1224.)
[3] LIU X J, LONG Y. Automated identification and characterization of parcels with OpenStreetMap and points of interest[J]. Environment and Planning B: Planning and Design, 2015, 43(2):341-360.
[4] LIU K, YIN L, LU F, et al. Visualizing and exploring POI configurations of urban regions on POI-type semantic space[J]. Cities, 2020, 99: No.102610.
[5] ZHANG X Y, DU S H, ZHANG J X. How do people understand convenience-of-living in cities? a multiscale geographic investigation in Beijing[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2019, 148:87-102.
[6] ZHANG C, ZHANG K Y, YUAN Q, et al. Regions, periods, activities: uncovering urban dynamics via cross-modal representation learning[C]// Proceedings of the 26th International Conference on World Wide Web. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2017:361-370.
[7] FU Y J, LIU G N, PAPADIMITRIOU S, et al. Real estate ranking via mixed land-use latent models[C]// Proceedings of the 21st ACM SIGKD International Conference on Knowledge Discovery and Data Mining. New York:ACM, 2015:299-308.
[8] WANG P Y, FU Y J, ZHANG J W, et al. Learning urban community structures: a collective embedding perspective with periodic spatial-temporal mobility graphs[J]. ACM Transactions on Intelligent Systems and Technology, 2018, 9(6): No.63.
[9] 庄晓平,陶楠,王江萍. 基于POI数据的城市15分钟社区生活圈便利度评价研究-以武汉三区为例[J]. 华中建筑, 2020, 38(6):76-79.(ZHUANG X P, TAO N, WANG J P. The evaluation of the convenience of 15-minute community life circles based on POI data: taking three districts of Wuhan as an example[J]. Huazhong Architecture, 2020, 38(6):76-79.)
[10] LI Z H, DING B L, HAN J W, et al. Mining periodic behaviors for moving objects[C]// Proceedings of the 16th ACM SIGKD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2010:1099-1108.
[11] BURGES C, SHAKED T, RENSHAW E, et al. Learning to rank using gradient descent[C]// Proceedings of the 22nd International Conference on Machine Learning. New York: ACM, 2005:89-96.
[12] BURGES C J C. From RankNet to LambdaRank to LambdaMART: an overview: MSR-TR-2010-82[R/OL]. (2010-06)[2021-06-20].https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/MSR-TR-2010-82.pdf.
[13] ZHANG Y, CAPRA L, WOLFSON O, et al. Urban computing: concepts, methodologies, and applications[J]. ACM Transactions on Intelligent Systems and Technology, 2014, 5(3): No.38.
[14] COURVILLE A, BERGSTRA J, BENGIO Y. Unsupervised models of images by spike-and-slab RBMs[C]// Proceedings of the 28th International Conference on Machine Learning. Madison, WI: Omnipress, 2011:1145-1152.
[15] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07)[2021-05-23].https://arxiv.org/pdf/1301.3781.pdf.
[16] OU M D, CUI P, PEI J, et al. Asymmetric transitivity preserving graph embedding[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016:1105-1114.
[17] HINTON G E, ZEMEL R S. Autoencoders, minimum description length and Helmholtz free energy[C]// Proceedings of the 6th International Conference on Neural Information Processing Systems. San Francisco: Morgan Kaufmann Publishers Inc., 1993: 3-10.
[18] FU Y J, WANG P Y, DU J D, et al. Efficient region embedding with multi-view spatial networks: a perspective of locality constrained spatial autocorrelations[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019:906-913.
[19] FU Y J, XIONG F, GE Y, et al. Exploiting geographic dependencies for real estate appraisal: a mutual perspective of ranking and clustering[C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014:1047-1056.
[20] MEI Q Z, ZHAI C X. Discovering evolutionary theme patterns from text — an exploration of temporal text mining[C]// Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2005:198-207.
[21] YE X Y, TAN H L, ZHANG Y Z, et al. Research on convenience index of urban life based on POI data[J]. Journal of Physics: Conference Series, 2020, 1646: No.012073.
[22] FRIEDMAN J H. Greedy function approximation: a gradient boosting machine[J]. The Annals of Statistics, 2001, 29(5):1189-1232.
[23] FREUND Y, IYER R D, SCHAPIRE R E, et al. An efficient boosting algorithm for combining preferences[J]. Journal of Machine Learning Research, 2003, 4:933-969.
[24] CAO Z, QIN T, LIU T Y, et al. Learning to rank: from pairwise approach to listwise approach[C]// Proceedings of the 24th International Conference on Machine Learning. New York: ACM, 2007:129-136.
Community structure representation learning for "15-minute living circle"
SUN Huanliang, PENG Cheng, LIU Junling*, XU Jingke
(,,110168,)
The discovery of community structures using urban big data is an important research direction in urban computing. Effective representation of the structural characteristics of the communities in the "15-minute living circle" can be used to evaluate the facilities around the living circle communities in a fine-grained manner, which is conducive to urban planning as well as the construction and creation of a livable living environment. Firstly, the urban community structure oriented to "15-minute living circle" was defined, and the structural characteristics of the living circle communities were obtained by representation learning method. Then, the embedding representation framework of the living circle community structure was proposed, in which the relationship between the Points Of Interest (POI) and the residential area was determined by using the travel trajectory data of the residents, and a dynamic activity map reflecting the travel rules of the residents at different times was constructed. Finally, the representation learning to the constructed dynamic activity map was performed by an auto-encoder to obtain the vector representations of the potential characteristics of the communities in the living circle, thus effectively summarizing the community structure formed by the residents’ daily activities. Experimental evaluations were conducted using real datasets for applications such as community convenience evaluation and similarity metrics in living circles. The results show that the daily latent feature expression method based on POI categories is better than the weekly latent feature expression method. Compared to the latter, the minimum increase of Normalized Discounted Cumulative Gain (NDCG) of the former is 24.28% and the maximum increase of NDCG is 60.71%, which verifies the effectiveness of the proposed method.
representation learning; urban community; 15-minute living circle; community structure; auto-encoder
This work is partially supported by National Natural Science Foundation of China (62073227), National Key Research and Development Program of China (2021YFF0306303), Natural Science Foundation of Liaoning Province (2019-MS-264),Project of the Educational Department of Liaoning Province ((LJKZ0582).
SUN Huanliang, born in 1969. Ph. D., professor. His research interests include spatial data management, data mining.
PENG Cheng,born in 1994, M. S. candidate. His research interests include data mining, representation learning.
LIU Junling, born in 1972. Ph. D., associate professor. Her research interests include spatio-temporal data query, data mining.
XU Jingke, born in 1976. Ph. D., professor. His research interests include spatio-temporal database, data mining.
TP391
A
1001-9081(2022)06-1782-07
10.11772/j.issn.1001-9081.2021091750
2021⁃10⁃12;
2021⁃11⁃15;
2021⁃11⁃17。
国家自然科学基金资助项目(62073227);国家重点研发计划项目(2021YFF0306303);辽宁省自然科学基金资助项目(2019-MS-264);辽宁省教育厅项目(LJKZ0582)。
孙焕良(1969—),男,黑龙江望奎人,教授,博士,博士生导师,CCF高级会员,主要研究方向:空间数据管理、数据挖掘;彭程(1994—),男,辽宁营口人,硕士研究生,CCF会员,主要研究方向:数据挖掘、表示学习;刘俊岭(1972—),女,辽宁沈阳人,副教授,博士,CCF会员,主要研究方向:时空数据查询、数据挖掘;许景科(1976—),男,辽宁海城人,教授,博士,CCF会员,主要研究方向:时空数据库、数据挖掘。
猜你喜欢
科学与生活(2021年25期)2021-12-02
福建中学数学(2021年1期)2021-02-28
小资CHIC!ELEGANCE(2021年44期)2021-01-11
美与时代·城市版(2020年8期)2020-11-09
山西农经(2020年2期)2020-03-30
现代企业文化·理论版(2017年11期)2017-06-23
课堂内外(小学版)(2017年3期)2017-04-15
读与写·上旬刊(2017年1期)2017-03-23
上海党史与党建(2016年9期)2016-09-20
新西部·中旬刊(2016年6期)2016-07-05
