
基于FVOIRGAN-Detection 的车辆检测
2022-07-04 08:06杨坚华花海洋
光学精密工程 2022年12期
张 浩,杨坚华,花海洋
(1. 中国科学院光电信息处理重点实验室,辽宁 沈阳 110016;2. 中国科学院沈阳自动化研究所,辽宁 沈阳 110016;3. 中国科学院机器人与智能制造创新研究院,辽宁 沈阳 110169;4. 中国科学院大学,北京 100049)
1 引 言
目标检测是计算机视觉的基本课题之一,也是自主车辆感知系统的重要组成部分[1-7]。目前,目标检测方法中使用了摄像机和激光雷达传感器。该相机可以在高帧速率下工作,在光线充足的天气下提供远距离密集信息。然而,作为一种被动传感器,它受到光照水平的强烈影响,而可靠的目标检测系统不应受到光照因素的影响。激光雷达通过自身的激光脉冲感知环境,因此它只受到外部照明条件的轻微影响。此外,激光雷达还提供精确的距离测量。不过它们的范围有限,提供的数据也很少[8]。通过对两个传感器优缺点的分析,不难看出同时使用两个传感器可以提高整体可靠性。
在过去的几年中,已经出现了大量通过融合多个传感器信息来解决目标检测问题的方法[8-15]。其中对于点云的处理,目前大多数方法是将点云投影到可见光图像生成深度图、强度图等图像,再与可见光图像融合。例如,Schlosser等人[16]根据基于激光雷达的深度图计算了水平视差、高度和角度(Horizontal disparity,Height,Angle,HHA)数据通道,利用HHA 特征与可见光图像进行后期融合取得了良好的效果。Gupta等人[17]也根据深度图计算了HHA 通道信息,然后利用卷积神经网络(Convolutional Neural Network,CNN)分别提取可见光图像和HHA 的特征信息。最后,利用支持向量机分类器进行目标检测。Asvadi 等人[9]提出将三维激光雷达点云信息的投影转换为二维深度图像和强度图像,并采用决策级融合方法实现各种模态检测的高级集成。
但是这种处理方式,会损失点云重要的三维空间信息。很多三维目标检测提出了运用BEV(Bird Eye View)图的想法。Chen 等人[10]和Liang 等人[11]使用基于体素的激光雷达表示,将点云体素化为3D 占用栅格,通过把高度切片处理为特征通道,将得到的3D 体素作为BEV 表示。其保留了点云完整的空间信息不受损失,但是这样数据量会变得庞大,且点云与可见光图像之间的对应变得复杂。针对这些问题,本文提出了FVOIRGAN-Detection 的多源信息融合检测网络,这种方法可以自适应地保留点云的原始空间信息,并提高了可见光图像纹理信息的利用程度。本文方法主要贡献如下:
第一,本文提出了FVOI(Front View Based on Original Information)的点云处理新思路,将点云投影到前视视角,并把原始点云信息的各个维度切片为特征通道,不但保留了点云的原始信息,而且降低了数据量,减小了与可见光图像的对应复杂度。之后通过特征提取网络提取原始点云中有利的信息,得到点云的前视二维特征图,并将其与可见光图像进行融合。
第二,在融合过程中,为了使得融合图像更好地保留可见光图像的纹理信息,本文引进了相对概率的思想[18],用鉴别器鉴别图像相对真实概率取代绝对真实概率,使得可见光中有利于目标检测的纹理信息可以更好、更真实地保留[19]。
2 FVOIRGAN-Detection
2.1 CrossGAN-Detection
CrossGAN-Detection 运用生成对抗网络[20]处理多源信息融合检测的问题,该方法由GAN和目标检测网络组成。目标检测网络在训练过程中充当GAN 的第二个鉴别器。该方法利用内容损失函数和双鉴别器为发生器提供直接可控的引导,通过交叉融合自适应学习不同模式之间的关系。
CrossGAN-Detection 网络结构如图1 所示,该网络是一个具有双鉴别器(检测器和鉴别器)的生成性对抗网络。输入为可见光图像、空间特征图和强度特征图。在训练过程中,检测器的作用是促使发生器朝着有利于目标检测的方向训练,其与发生器的关系是正反馈的;鉴别器的作用是促使发生器在主观设定方向上进行训练,这是一种对抗性鉴别器。在检测过程中,去除鉴别器,生成器承担信息融合任务,检测器承担目标检测任务。

图1 CrossGAN-Detection 的网络结构Fig.1 Network architecture of CrossGAN-Detection
为了同时保持可见光图像丰富的纹理信息、空间特征图的空间信息和强度特征图的强度信息,推动融合朝着有利于目标检测的方向发展,引入了生成对抗网络的融合思想并添加一个目标探测器作为鉴别器。鉴别器用于区分融合图像和可见光图像,检测器用于检测融合图像的目标。因此,提出的框架建立了生成器和鉴别器之间的对抗。在对抗过程中,融合图像逐渐获得丰富的图像纹理信息[21],增加了融合图像的信息多样性,不仅增加了目标检测的可用信息,提高了目标检测的效果,同时也降低了目标检测网络过拟合的风险。同时,它在发生器和检测器之间建立了正反馈对抗。在对抗过程中,由于两个鉴别器的作用,融合图像越来越有利于目标检测,检测器的检测能力也越来越强。此外,为了防止在鉴别器的作用下通道信息的丢失,为发生器设计了内容损失函数:
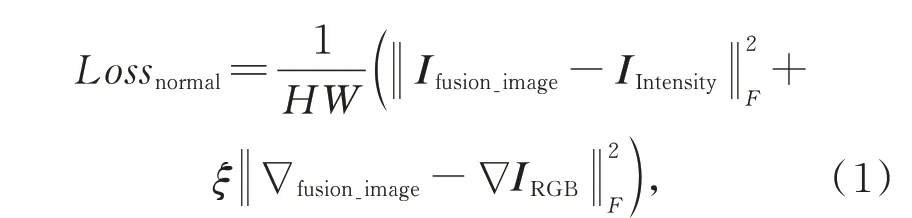
其中,H,W分别表示输入图像的高度和宽度,F表示矩阵Frobenius 范数,∇表示梯度算子,ξ是控制两项之间权衡的正参数。第一项旨在保留强度特征图IIntensity的反射率信息,第二项旨在保留可见光图像IRGB中包含的梯度信息。
在现有方法中,融合仅由检测结果控制。与该框架相比,它缺少一个鉴别器。这种缺乏将导致模型学习的不可控问题。由于融合与检测之间的关系是正反馈的,因此融合过程只受目标检测结果的引导,容易产生偏差。在融合框架中融合了哪些信息以及这些信息是否真的有助于目标检测是值得考虑的两个问题。在加入GAN后,利用鉴别器和内容损失函数将真正有利于目标检测的信息融合到融合图像中,从而为整个网络设置正确的方向,指导学习过程,防止学习过程中的偏差,提高模型的稳定性。
2.2 基于FVOI 的点云处理
针对将点云投影到可见光图片方法的信息损失,Liang 等[11]使用基于体素的激光雷达表示,将点云体素化为3D 占用栅格,其中体素特征通过每个激光雷达点上的8 点线性插值计算。这种激光雷达表示能够有效地捕捉细粒度点密度线索,通过把高度切片处理为特征通道,将得到的3D 体素作为BEV 表示,能够在2D BEV 空间中进行推理,从而在不降低性能的情况下显著提高效率。3D BEV 表示非常巧妙地满足各方面需求,但是其大多数三维体素是空的,这就造成了其数据量巨大的问题,浪费了内存且降低了处理效率,而且其与可见光图像对应起来复杂度也较高。最重要的是对于二维目标检测来说,3D BEV 的表示形式不合适。对此,本文提出了基于FVOI 的点云处理方法来配合二维目标检测。
如图2 所示,为基于FVOI 的点云处理网络框架。首先FVOI 的过程是将点云上的点投影到可见光图像,将平面上的点像素化为栅格,然后通过把原始点云信息的各个维度切片为特征通道,将得到点云的二维表示(4×w×l),其也可以在不降低性能的情况下显著提高效率,而且相比于3D 的BEV 表示(channels×h×w×l),大大减小了数据量。最重要的是,经过点云投影到可见光图像这一步骤,FVOI 已经建立了点云与可见光图像之间的对应关系。

图2 基于FVOI 的点云处理网络框架Fig.2 Network architecture of point cloud processing based on FVOI
如图2,在对点云的二维表示进行特征提取的过程中,由于空间信息和强度信息是不同类别的信息,所以分为两个信息流分别进行提取点云的空间信息和强度信息。此外,由于点云数据本身比较稀疏,在卷积计算的过程中稀疏的点云数据极易损失,因此在特征提取的过程中加入了残差的思想。最后,由于可见光图像是三通道的,为了使得生成的特征图更好地与可见光图像进行融合,分别生成三通道的空间特征图和三通道的强度特征图,使得每一类信息有着相同的初始权重。
2.3 相对概率的鉴别器思想
经过对CrossGAN-Detection 的分析,很容易得知其利用生成器与鉴别器的对抗对可见光图像的纹理信息进行提取,鉴别器是为了区分可见光图像和融合图像,生成器是为了生成让鉴别器区分不开的融合图像。例如,当鉴别器鉴别一个可见光图像的输出是p时,同时也鉴别融合图像输出概率是p,那么这时候就可以认为鉴别器已经区分不开可见光图像和融合图像,生成器效果已经达到最优,融合图像已经获得了可见光图像真实的信息。但是根据CrossGAN-Detection 的损失函数来看,生成器在这时候还要继续优化其参数进而生成接近于D(Ifusion_image)=1 的融合图像,这就出现了过度优化的问题,D(Ifusion_image)=1的融合图像在鉴别器鉴别下已经非常接近可见光图像,但是真正意义上其已经脱离了D(IRGB)=p的真实可见光图像。
图3 为相对概率工作原理的示意图,在欠优化区域和过度优化区域的融合图像融合的纹理信息都是不够真实的,因此为了基于鉴别器的能力水平来训练生成器,本文加入了相对真实概率的思想。

图3 相对概率工作原理示意图Fig.3 Schematic diagram of working principle of relative probability
加入相对概率后的鉴别器和生成器损失函数修改为:

其中:f是端到端的函数,在本文方法中f(x)=x,R是可见光图像的分布函数,F是融合图像的分布函数。在相对概率思想的影响下,可以保证生成器可以最大程度地提取到可见光图像真实的纹理信息,而不是脱离鉴别器的鉴别能力提取到一些伪真实的纹理信息。从而提升整个网络的目标检测能力。
3 实验验证
本文使用平均精度(AP)[22]在KITTI[23]数据集的验证分割集[24]上评估提出的方法。

其中:rn为第n个recall 值,ρ(r͂)为在recall 值为r͂时的precision 值。
3.1 实验设计
本实验基于Python 3.6 和tensorflow-1.14,使用NVIDIA GTX-2080TI 进行训练。在实验中,batchsize 大小设置为2,并使用Adam 优化算法进行迭代。初始学习率为0.000 1,然后通过余弦退火衰减为0.000 001。在训练过程中,在192×576、224×672和256×768 中随机选择输入图像的大小,并且随机剪切和翻转输入图像以进行数据增强。
3.2 数据集
KITTI 数据集由德国卡尔斯鲁厄理工学院和丰田美国理工学院共同创建。它是世界上最大的自动驾驶场景下的计算机视觉算法评估数据集。该数据集用于评估计算机视觉技术的性能,如车辆环境中的立体图像、光流、视觉里程计、三维目标检测和三维跟踪。KITTI 包含从城市、农村和高速公路场景收集的真实图像数据。每个图像中最多有15 辆车和30 名行人以及不同程度的遮挡和截断。整个数据集由389 对立体图像和光流图、39.2 km 视觉测距序列和200 K 多个3D 标记对象的图像组成,以10 Hz 的频率采样和同步。标签分为汽车、厢式货车、卡车、行人、行人(坐着)、自行车、有轨电车和杂项。
3.3 消融分析
为了验证本文所提出的两个模块的有效性,将CrossGAN-Detection 作为Baseline 进行了消融分析。
如表1 所示,Baseline 为CrossGAN-Detection,在此基础上分别加入FVOI 的点云处理方法和相对概率的鉴别器思想,本文方法在简单、中等、困难类别分别比Baseline 高1.01%、0.71%、0.57%,结果表明FVOI 的点云处理方法和相对概率的鉴别器思想都有利于提高目标检测的精度。

表1 KITTI 验证集上Car 类2D 目标检测性能消融分析:平均精度Tab.1 Ablation analysis of 2D Car detection performance on KITTI verification set:average accuracy
由于以上AP指标都是在IOU=0.7 的时候测得,为了更好、更全面地验证本文方法的优越性,分析了AP随着IOU变化的曲线图。如图4所示,为AP与IOU关系图,实线表示的是Cross-GAN-Detection 方法的AP指标随着IOU的变化情况,虚线表示本文方法的AP指标随着IOU的变化情况。从图中可见,本文方法曲线一直在Baseline 的上方,可见本文方法相比于Cross-GAN-Detection 方法不仅在IOU=0.7 的情形下表现较好,而是在各种IOU情形下都有着显著的优越性,进一步全面证明了本文方法的有效性。

图4 KITTI 验证集上的AP 与IOU 关系Fig.4 Relationship between AP and IOU on KITTI validation set
3.4 光照条件受限的场景
KITTI 数据集主要包括在相当理想的光照和天气条件下捕获的示例。在这种情况下,摄像机图像本身提供了丰富的信息和丰富的识别线索,配合深度图像可以进行准确的车辆检测。因此,通过上述实验,可能很难完全理解充分利用点云的空间信息的好处以及相对概率思想的作用。考虑到这一点,从验证集中提取了14 组具有挑战性的场景,特别是显示阴影和强光反射的图像。
如表2 所示,数据在14 组光照条件不好的挑战性场景下测得,在此场景下,可见FVOI 的点云处理方法起到了重要作用,相比原始方法提升了1.92%,说明充分利用点云的空间信息有利于弥补光照条件不好的劣势,提高目标检测的效果。然而,在单独加入相对概率的鉴别器思想时,网络的性能下降2.57%,原因是相对概率的鉴别器思想原理是更真实地提取可见光图像的纹理信息,而在光照条件不好的情形下,提取的信息是失真的,其对网络性能进而造成了不好的影响。但是本文的方法结合了FVOI 的点云处理方法和相对概率的鉴别器思想,充分地利用了点云的空间信息和可见光图像的纹理信息,平衡二者的关系,在光照条件不好的情形下相比单独使用每种方法更能发挥出好的效果,相比原始方法提升了2.37%。
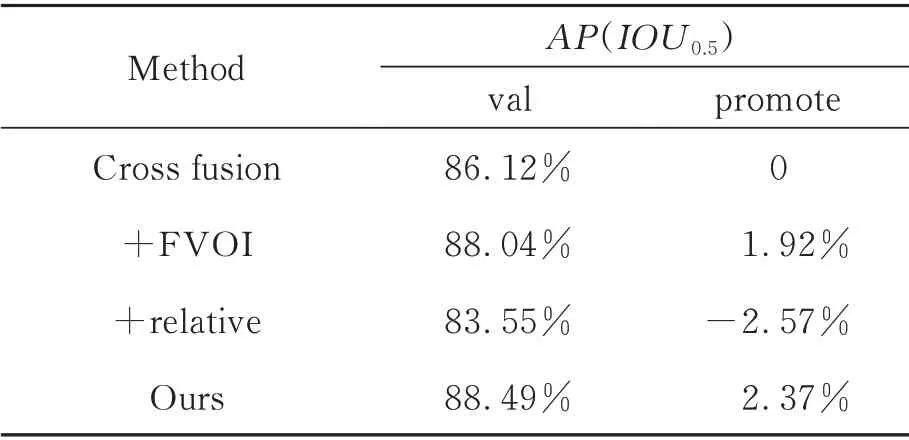
表2 KITTI 挑战性场景Car 类2D 目标检测性能消融分析:平均精度Tab.2 Ablation analysis of 2D Car detection performance on KITTI challenging scenarios:average accuracy
如图5 所示,第一列是真实标签,第二列是CrossGAN-Detection 方法的检测结果,第三列是本文方法的检测结果。红色椭圆框表示Cross-GAN-Detection 方法的误检目标,红色方框表示CrossGAN-Detection 方法检测精度较低的目标。可以看出,在光照条件有限的情况下,Cross-GAN-Detection 方法进行目标检测会面临误检和检测精度低的问题,而本文方法充分利用了点云的空间信息和可见光图像的纹理信息,平衡了二者的关系,解决了这些问题,提高了目标检测的准确性。
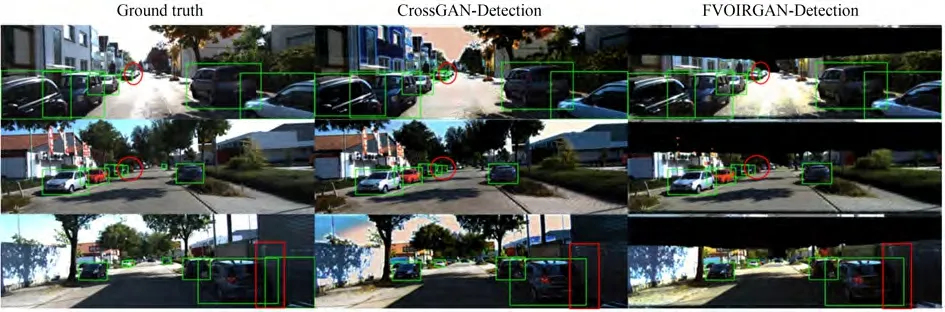
图5 挑战性场景下目标检测结果对比示例Fig.5 Comparison example of target detection results in challenging scenes
同时为了证明本文的相对概率的思想可以更好地提取纹理特征,我们利用灰度共生矩阵提取了融合图像的相关性特征值(COR),相关性是纹理特征比较有代表性的一种表达,其度量空间灰度共生矩阵元素在行或列方向上的相似程度,相关值大小反映了图像中局部灰度相关性。

其中:(a,b)为灰度共生矩阵元素坐标,PΦ,d(a,b)为该坐标的元素值,结果如表3 所示。

表3 纹理信息提取性能比较:相关性特征值Tab.3 Comparison of texture information extraction performance:correlation eigenvalue(COR)
如表3 所示,本文提出的方法提取纹理特征与真实可见光图像更为接近,验证了本文方法的有效性。
3.5 性能对比
为了证明本文的方法优于现有方法,在KITTI 的验证分割集上将其与其他先进的融合检测方法进行了比较。
表4 给出了Car 类目标三个检测难度等级上的平均准确率,所提方法FVOIRGAN-Detection与近几年多模态信息融合检测方面的一些SOTA 算法进行比较。从表中可以看出,本文提出的方法在简单类别中比其他高级方法具有显著的优势,并且在中等和困难类别中与其他方法几乎相同。

表4 KITTI 验证集Car 类2D 目标检测性能比较:平均精度Tab.4 Comparison of 2D Car detection performance on KITTI verification set:average accuracy
4 结 论
本文提出了一种新的多源信息融合检测算法FVOIRGAN-Detection,用于融合摄像机图像和激光雷达点云进行车辆检测。一方面,本文提出了FVOI(Front View Based on Original Information)的点云处理新思路,将点云投影到前视视角,然后通过把原始点云信息的各个维度切片为特征通道,不但保留了点云的原始信息,而且降低了数据量,减小了与可见光图像的对应复杂度。之后通过特征提取网络提取原始点云中有利于目标检测的信息,得到点云的前视二维特征图,并将其与可见光图像进行融合。另一方面,在融合过程中,为了使得融合图像更好地保留可见光图像真实的纹理信息,本文引进了相对概率的思想,用鉴别器鉴别图像相对真实概率取代绝对真实概率,提高融合图像对可见光图像中的纹理信息的复原程度,更好地提高目标检测的效果。
通过性能比较,FVOI 的点云处理方法和相对概率的鉴别器思想都对CrossGAN-Detection方法起到了很好的提升作用。在KITTI 的验证分割集上,本文方法优于现有方法。本文还考虑了光照条件受限下的场景,进一步证明了该方法的有效性。
猜你喜欢
通信学报(2022年10期)2023-01-09
北京工业大学学报(2022年9期)2022-09-15
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
