
人工电场算法优化的极限学习机大坝变形预测模型研究
2022-07-02 09:45李新华崔东文
人民珠江 2022年6期
李新华,崔东文
(1.云南兴电集团有限公司,云南 文山 663000;2.云南省文山州水务局, 云南 文山 663000)
提高水库大坝变形预测精度对于保障大坝稳定运行、确保人民生命财产安全具有重要意义。目前自回归法[1]、GM(1,1)法[2]、灰色马尔科夫法[3-4]、BP神经网络法[5-7]、支持向量法[8-10]、指数幂乘积法[11]、组合模型法[12]等模型及方法已成功应用于大坝变形预测。当前,BP神经网络和支持向量机(support vector machines,SVM)由于良好的预测精度和泛化能力,已广泛应用于大坝变形预测研究。然而,但在实际应用中,BP神经网络和SVM均存在缺点和不足:①BP神经网络训练时间长、收敛速度慢、易陷入局部最优;②BP神经网络需人为调节参数较多,如隐含层数量、隐含层传递函数、输出层传递函数、训练函数、最大训练次数等选取不当对BP神经网络预测性能影响较大;③ SVM存在惩罚因子、核函数参数、不敏感系数和交叉验证折数参数选取的困难,参数选取不当易导致SVM过拟合而降低外推能力。极限学习机(extreme learning machine,ELM)是近年兴起的一种隐层前馈神经网络(SLFNs)学习算法,具有计算速度快,泛化性能强、网络参数设置简单等优点,已在各行业领域及大坝变形预测[13]中得到应用。在实际应用中,ELM尚存在以下问题:①ELM输入层权值和隐含层偏置的随机选取在很大程度上制约了ELM预测或分类精度的提高。近年来,粒子群优化(PSO)算法[14]、人工蜂群(ABC)算法[15]、生物地理学优化(BBO)算法[16]、花授粉算法(FPA)[17]、差分进化(DE)算法[18]、蝗虫优化(GOA)算法[19]、黑猩猩优化算法(ChOA)[20]等尝试用于ELM输入层权值和隐含层偏置的优化,并获得了较好的实际应用效果,有效提高了ELM预测或分类精度;②隐含层数对ELM性能影响较大。隐含层数太少会导致ELM“欠拟合”,过多又会导致“过拟合”;③随机产生的输入层权值和隐含层偏置导致ELM连续每次运行的结果不一致,甚至存在较大差异。
为提高大坝变形预测精度,拓展智能算法在ELM输入层权值和隐含层偏置优化中的应用,本文研究提出一种人工电场算法(artificial electric field algorithm,AEFA)与ELM相结合的大坝变形预测方法。通过官地水电站72期大坝沉降数据构建延迟时间为1,嵌入维数为2、3、5维的3种ELM预测模型,利用AEFA优化3种ELM模型的输入层权值和隐含层偏值,分别构建3种不同嵌入维的AEFA-ELM大坝变形预测模型,并分别构建对应嵌入维的AEFA-SVM、AEFA-BP作预测对比模型。利用9种不同嵌入维的AEFA-ELM、AEFA-SVM、AEFA-BP模型对文献[21]实例大坝变形数据进行训练和预测。旨在验证AEFA-ELM模型在大坝变形预测中的可行性。
1 AEFA-ELM预测模型
1.1 人工电场算法
人工电场算法(artificial electric field algorithm,AEFA)是Anita等[22]于2019年受库仑静电力定律启发而提出的一种新型全局优化算法。该算法将待优化问题解视为电荷粒子,电荷粒子通过静电力相互吸引或排斥在搜索空间中移动来达到求解问题的目的。AEFA数学描述简述如下[22]。
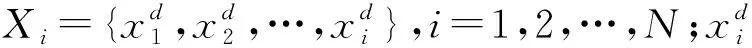
(1)
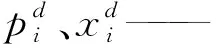
电荷粒子j在时刻t作用在电荷粒子i上的电力描述如下:
(2)
在d维搜索空间中,所有其他粒子在时刻t作用于第i个粒子的总电力描述如下:
(3)
式中 rand——[0,1]范围内均匀分布的随机数;N——电荷粒子总数;Fi——作用在第i个电荷粒子上的合力。
第i个粒子时刻t在第d维空间的电场描述如下:
(4)
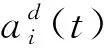
(5)
式中Mi(t)——第i个电荷粒子在时刻t的单位质量。
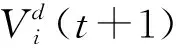
(6)
(7)
式中 rand——[0,1]范围内均匀分布的随机数。
1.2 极限学习机(ELM)
极限学习机(ELM)是一种广义的单隐层前馈神经网络,具有较快的学习速度和良好的泛化能力。给定M个样本Xk={xk,yk},k=1,2,…,M,其中xk为输入数据,yk为真实值,f(·)为激活函数,隐层节点为m个,ELM输出可表示为[23]:
(8)
式中oj——输出值;Wi={ωi1,ωi2,…,ωim}——输入层节点与第i个隐含层节点的连接权值;bi——第i个输入节点和隐含层节点的偏值;λi——第i个隐含层节点与输出节点的连接权值。
1.3 预测模型的建立及实现步骤
AEFA-ELM模型建立及预测实现步骤归纳如下。
步骤一利用实例大坝变形数据构建不同嵌入维的ELM模型,合理划分训练样本和预测样本,利用AEFA优化ELM输入层权值和隐含层偏置,建立不同嵌入维的AEFA-ELM模型,利用训练样本数据对AEFA-ELM模型进行训练。
步骤二利用训练样本均方误差构建优化目标函数:
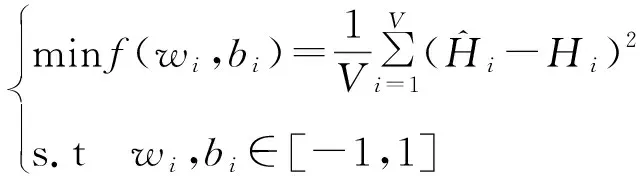
(9)
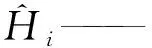
步骤三在搜索范空间随机初始化电荷粒子位置(X1(t),X2(t),…,XN(t)),设置种群规模N,最大迭代次数maxiter,随机初始化电荷粒子初始速度,设置ELM输入层权值和隐含层偏置搜寻范围,令当前迭代次数iter=0。
步骤四计算每个粒子在时刻t的适应度值(fit1(t),fit2(t),…,fitN(t))。
步骤五计算库仑常数K(t);选取时刻t最佳和最差电荷粒子适应度值对于应电荷粒子空间位置。
步骤六计算每个粒子时刻t的适应度值fiti(t);利用式(3)计算每个粒子时刻t的总电力Fi(t);利用式(5)计算加速度ai(t);利用式(6)、(7)更新电荷粒子在t+1时刻的速度和位置。
步骤七计算所有粒子在t+1时刻的适应度值,比较并保留当前最佳电荷粒子空间位置xbest。
步骤八令iter=iter+1,判断算法是否达到终止条件,若是,输出xbest,算法结束;否则转至步骤五。
步骤九输出xbest。xbest即为ELM最佳输入层权值和隐含层偏置。将参数xbest代入AEFA-ELM模型进行大坝变形预测。
2 实例应用
实例数据来源于文献[21]官地水电站大坝坝顶监测点T26在垂直方向上累积沉降位移值,样本获取时间段为2012年8月—2016年1月,共72组经预处理后的大坝累积沉降数据,见表1。采用SPSS软件自相关函数法求解延迟时间为1;对于最佳嵌入维数,目前普遍采用虚假最邻近法(FNN)、G-P法、C-C法等方法求解,但对于短序列样本,求解效果并不理想。在延迟时间为1的条件下利用试算的方法确定嵌入维数为2、3、5维时模型具有较好的预测精度。
因此,在延迟时间为1,嵌入维数为2、3、5维条件下分别构建大坝变形预测因子与影响因子的输入、输出矩阵,分别利用选取前60组、前59组、前57组大坝累积沉降位移数据作为训练样本,后10组累积沉降位移数据作为预测样本。
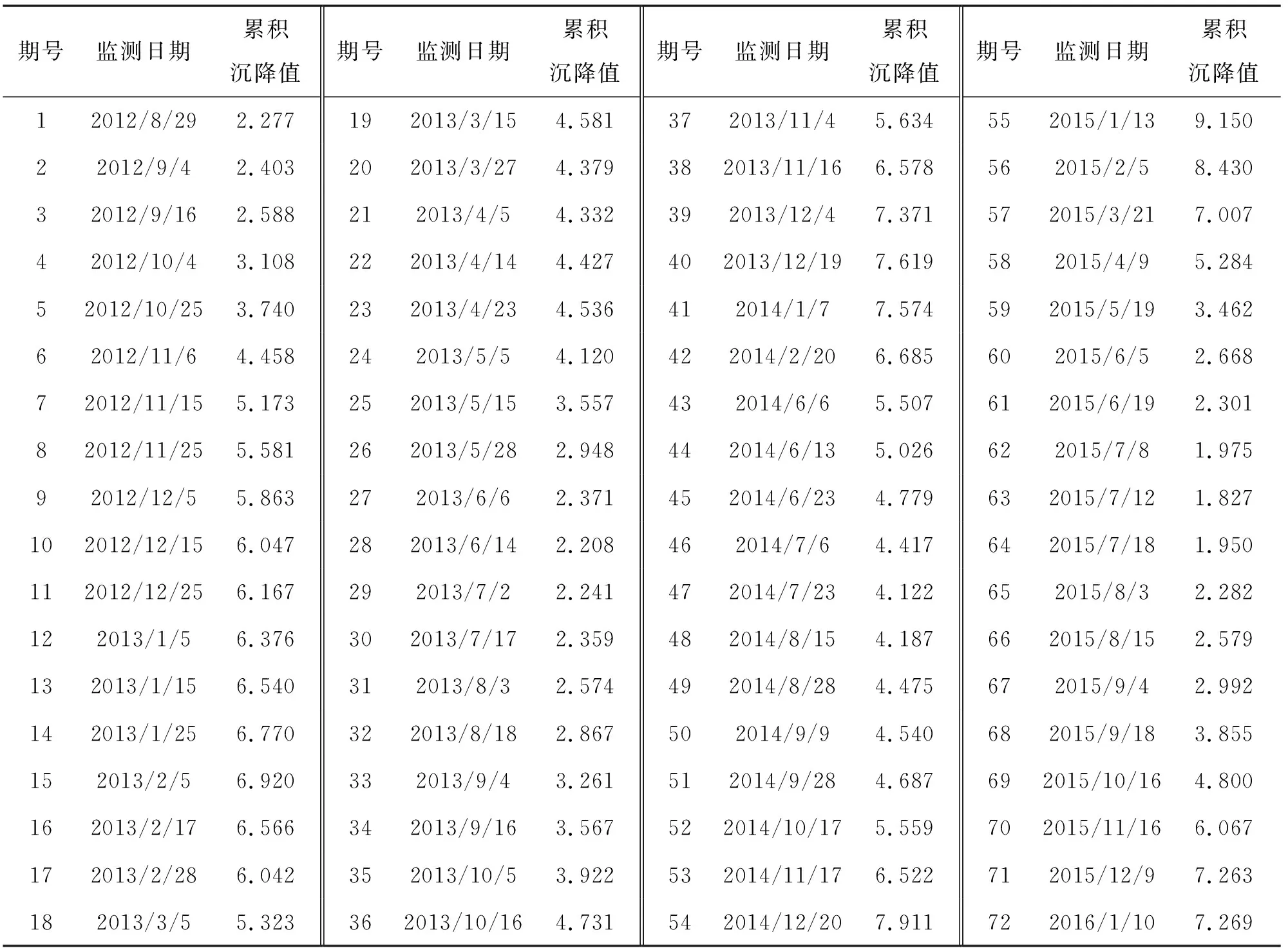
表1 大坝变形累积沉降值 单位:mm
参数设置。设置AEFA最大迭代次数maxiter=100,种群规模N=50;ELM激活函数选择sigmoid函数,输入层权值和隐含层偏置的搜索范围为[-1,1]。经试算,嵌入维为2维的ELM隐含层数设置为2、嵌入维为3维的ELM隐含层数设置为3、嵌入维为5维的ELM隐含层数设置为19时,ELM模型预测效果最好,AEFA优化ELM输入层权值和隐含层偏置维度分别为9、16、134维。SVM核函数为RBF,超参数搜索范围为[2-10,210],交叉验证折数V=2,优化维度3维。BP神经网络隐层数采用2倍的输入层节点数-1确定,隐藏层和输出层传递函数、训练函数分别采用logsig、purelin和traingdx,期望误差、最大训练次数分别为0.001、200,搜索范围为[-1,1]。所有输入数据均采用[-1,1]进行归一化处理。
预测及分析。分别构建AEFA-ELM(2、3、5维)、AEFA-SVM(2、3、5维)、AEFA-BP(2、3、5维)9种模型对实例大坝变形进行预测,并利用平均相对误差(MAPE)、平均绝对误差(MAE)、均方根误差(RMSE)进行效果评价,结果见表2;训练及预测误差见图1—4。
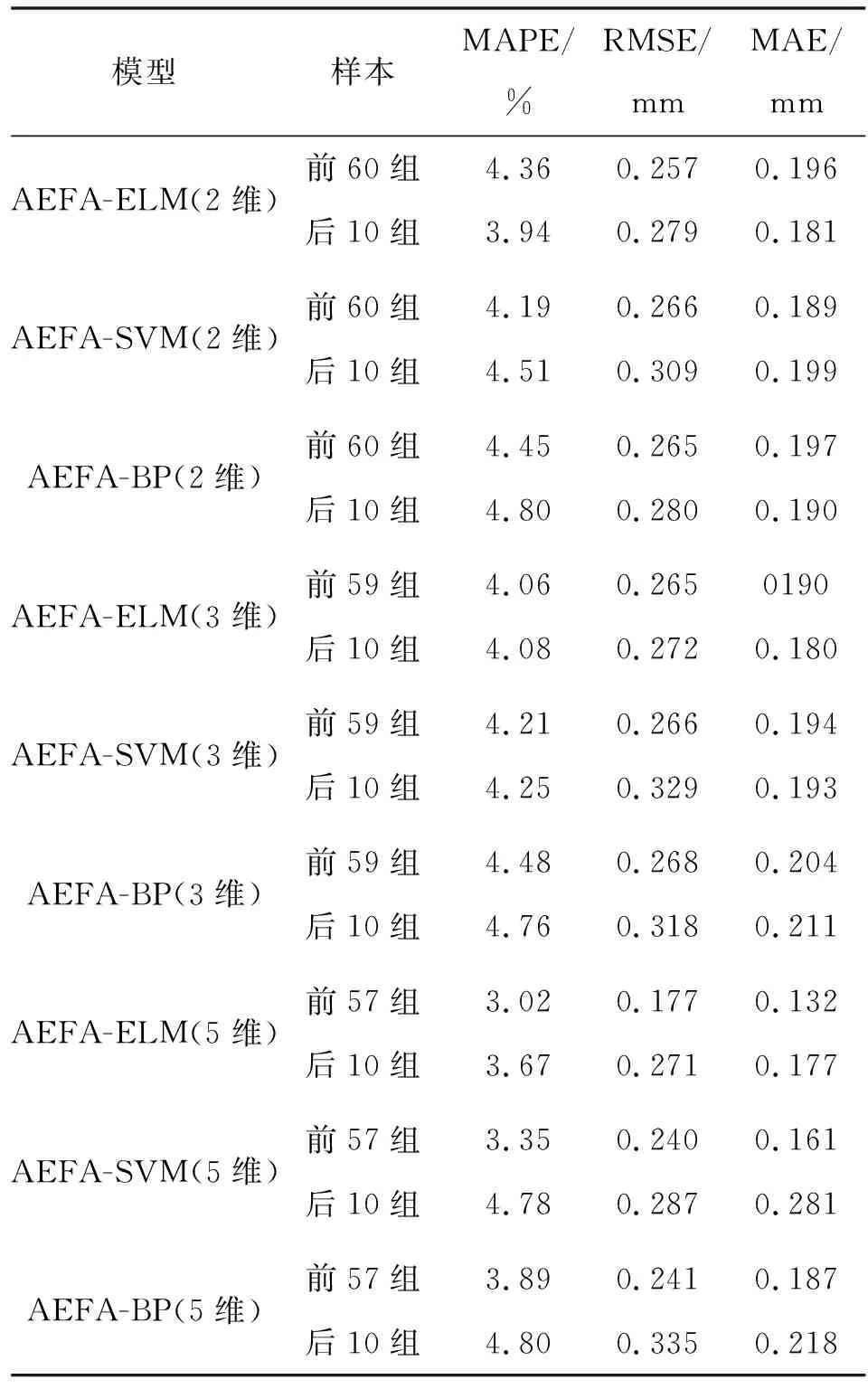
表2 实例大坝变形预测结果
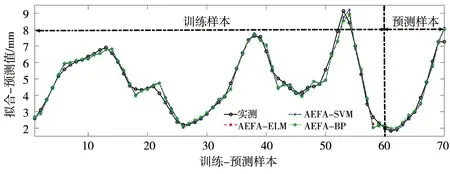
图1 训练-预测效果(2维)
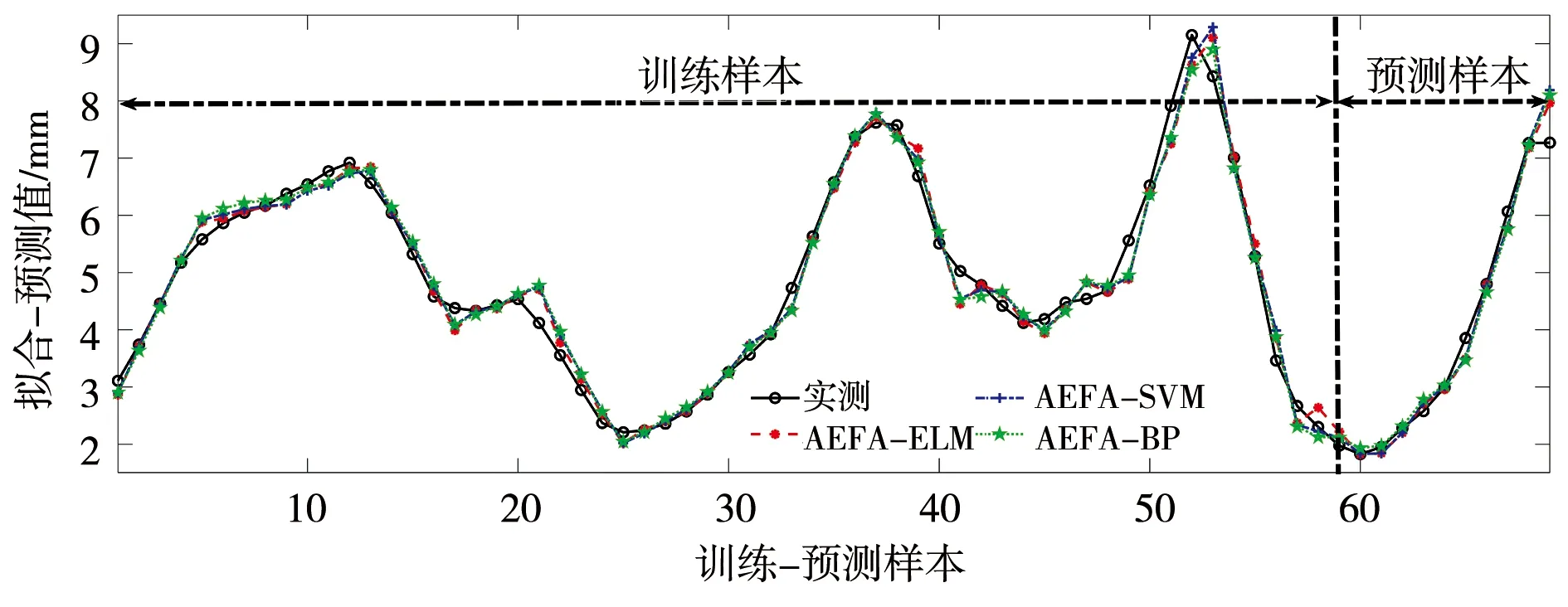
图2 训练-预测效果(3维)
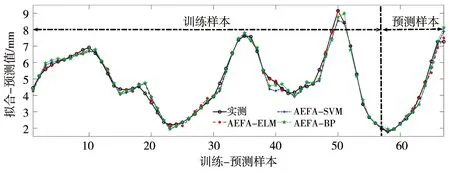
图3 训练-预测效果(5维)
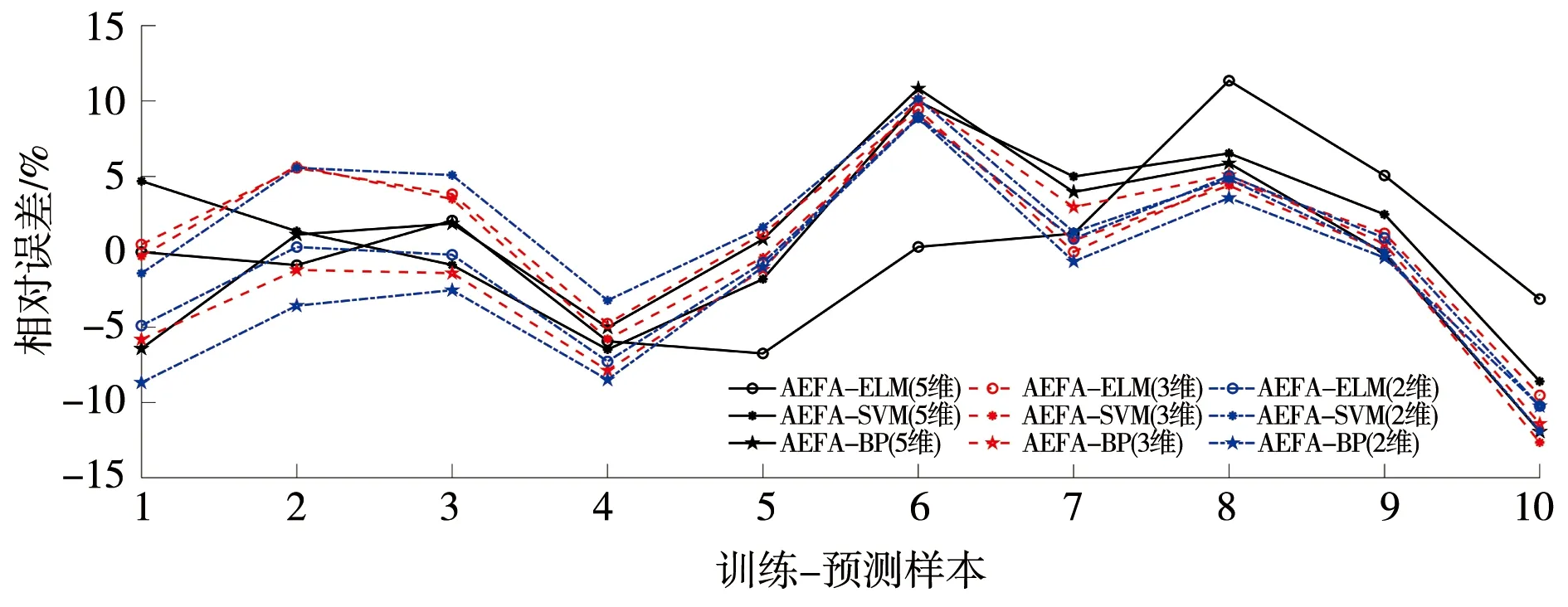
图4 预测样本相对误差
依据表2及图1—4可以得出以下结论。
a)AEFA-ELM(2、3、5维)模型对实例后10组大坝变形预测的MAPE分别为3.94%、4.08%、3.67%,RMSE分别为0.279、0.272、0.271 mm,MAE分别为0.181、0.180、0.177 mm,预测精度均优于AEFA-SVM(2、3、5维)、AEFA-BP(2、3、5维)模型,具有更小的预测误差和更高的预测精度。相对而言,AEFA-ELM(5维)模型的预测效果最好。
b)从拟合效果来看,仅AEFA-ELM(2维)模型的MAE精度略低于AEFA-SVM(2维)模型,其他AEFA-ELM(3、5维)拟合精度均优于对应嵌入维的AEFA-SVM、AEFA-BP;从预测效果来看,不同嵌入维的AEFA-ELM模型的预测精度均优于对应嵌入维的AEFA-SVM、AEFA-BP模型,表明AEFA能有效优化ELM输入层权值和隐含层偏置,有效提高ELM网络预测性能。
3 结论
介绍一种新型群体智能算法——人工电场算法(AEFA)。通过大坝累积沉降数据构建延迟时间为1,嵌入维为2、3、5维的ELM大坝变形预测模型,利用AEFA优化ELM输入层权值和隐含层偏置,建立不同嵌入维的AEFA-ELM大坝变形预测模型,并构建对应嵌入维的AEFA-SVM、AEFA-BP作预测对比模型。利用文献大坝变形实例数据对不同嵌入维的AEFA-ELM、AEFA-SVM、AEFA-BP模型进行训练及预测。结论如下。
a)不同嵌入维的AEFA-ELM模型对实例预测的MAPE、RMSE、MAE分别在3.67%~4.08%、0.271~0.279 mm、0.177~0.181 mm,预测精度均优于AEFA-SVM、AEFA-BP模型,具有更小的预测误差和更高的预测精度。
b)利用AEFA寻优ELM输入层权值和隐含层偏置,能有效提高ELM的预测精度和泛化能力。
猜你喜欢
智能计算机与应用(2022年9期)2022-09-28
汽车实用技术(2022年15期)2022-08-19
成都信息工程大学学报(2022年3期)2022-07-21
中国信息化(2022年5期)2022-06-13
北京汽车(2021年1期)2021-03-04
中学生数理化(高中版.高考理化)(2020年10期)2020-10-27
新高考·高一物理(2016年7期)2017-01-23
科技视界(2016年1期)2016-03-30
新高考·高一物理(2015年6期)2015-09-28
新高考·高一物理(2015年6期)2015-09-28
