
基于SSA-LSTM模型的短期电力负荷预测
2022-07-01 07:57:02赵婧宇周亚同
电工电能新技术 2022年6期
赵婧宇,池 越,周亚同
(河北工业大学电子信息工程学院,天津 300401)
1 引言
电力系统负荷预测可对未来一段时间的电力需求进行估计,从而根据负荷预测结果来安排机组组合计划、发电计划、联络线交换计划,组织电力现货交易。因此,准确的电力负荷预测对于电力系统安全、经济、高效地运行有着重要的意义[1]。短期电力负荷预测主要是指对未来一天、一周甚至几周时间内的用电负荷进行预测,是电网日常运营的重要组成部分。
对于短期电力负荷预测的研究方法,大致分为两类,包括传统电力负荷预测方法[2-12]和机器学习算法[13-16]模型预测方法。基于当下新型用电环境与影响用电因素复杂多样化的特点,机器学习算法模型成为学者们在电力负荷预测领域研究的焦点。
随着人工神经网络(Artificial Neural Network,ANN)的迅速发展,其各种模型及其变体被广泛应用于负荷预测领域,其中最具有代表性的是反向传播神经网络(Back Propagation,BP)。文献[16,17]针对传统BP算法模型易陷入局部极小值的问题,分别从梯度下降角度和改进神经网络的连接权值角度进行寻优,优化了网络性能并提高了预测精度;文献[18]对用电数据进行点预测与区间预测,其通过小波变换以及改进粒子群优化BP神经网络模型进行的点预测和其构建的区间预测模型都较传统BP模型在精度上有所提高。
循环神经网络(Recurrent Neural Networks,RNN)通过将数据的时序性与网络设计相结合,有效地突破了ANN无法利用数据间时序依赖关系进行预测的弊端,但是RNN在处理具有长时间跨度的非线性数据上时,又产生了梯度消失与梯度爆炸的问题。对此Hochreiter 和 Schmidhuber[19]提出了长短期记忆(Long Short-Term Memory,LSTM)神经网络对其进行改进,有效地解决了数据间的长期时序依赖问题。文献[20-23]分别采用了张量深度学习框架、双层LSTM神经网络、将LSTM的输出层与全连接层进行合并以及结合支持向量回归(Support Vector Regression,SVR)与LSTM构建混合模型的方式,在LSTM模型的搭建上分别进行不同的改进,以获得较为精确的预测结果。文献[24]将LSTM的输入数据通过卷积神经网络(Convolutional Neural Network,CNN)去融合多尺度特征向量进行改进。文献[25,26]分别通过粒子群算法(Particle Swarm Optimization,PSO)及改进算法对LSTM网络参数进行寻优,在人为设定网络参数与网络模型的预测精度方面较之前LSTM的提升算法均有显著的提高。
综上所述并结合现有算法,本文提出基于麻雀搜索算法-长短期记忆(Sparrow Search Algorithm-Long Short-Term Memory,SSA-LSTM)模型进行短期电力负荷预测,用以解决LSTM网络参数选取随机性大、选择困难的问题,同时提高负荷预测的精度。首先对历史用电负荷数据以及气候、节假日等影响因素数据进行预处理,然后构建麻雀群体,将待优化参数与麻雀种群维度相对应,将处理好的数据输入到模型中,在模型的训练过程中通过麻雀搜索算法(Sparrow Search Algorithm,SSA)进行参数寻优,将得到的最优参数用以搭建预测模型进行预测。与传统预测模型相比较,SSA-LSTM模型在一定程度上提高了预测的准确度,相较于PSO优化的LSTM模型,SSA-LSTM模型能够不受季节变化的影响,模型的预测精度更高。
2 预测模型原理
2.1 LSTM原理
图1为LSTM的基本单元,LSTM通过对其遗忘门、输入门、输出门等门控单元进行有效组合可以实现信息的保护和当前状态的更新,更新规则如式(4)所示。门控单元的实现如式(1)~式(6)所示:
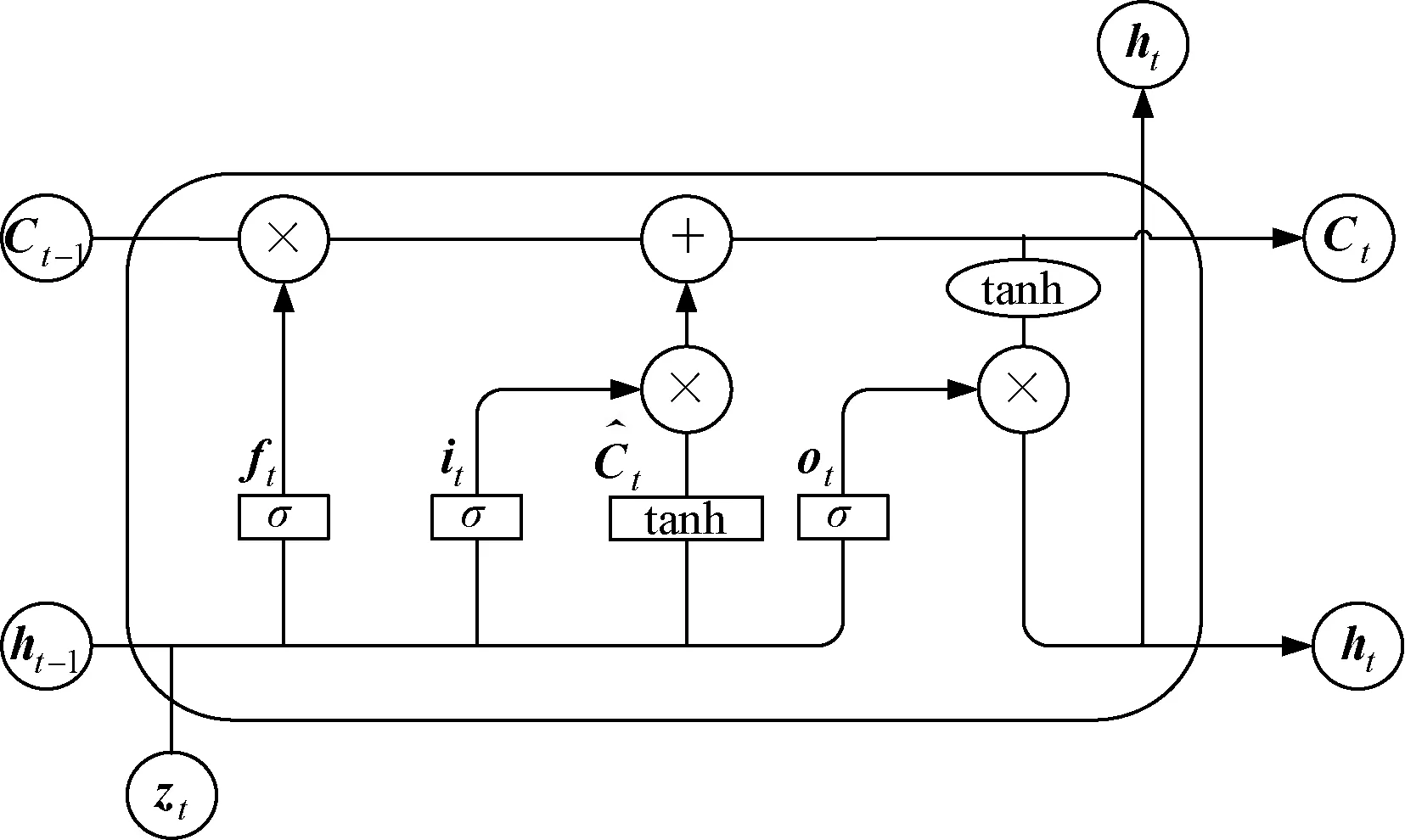
图1 LSTM结构示意图Fig.1 Structure diagram of LSTM
ft=σ(Wf×[ht-1,zt]+bf)
(1)
it=σ(Wi×[ht-1,zt]+bi)
(2)
(3)
(4)
ot=σ(Wo×[ht-1,zt]+bo)
(5)
ht=ot×tanhCt
(6)
式中,z为输入向量;h为输出向量;f为遗忘门;i为输入门;o为输出门;C为单元状态;t为时刻;σ、tanh分别为sigmoid、tanh激活函数;W为权重;b为偏差矩阵。
2.2 多输入多输出LSTM网络结构
图2为本文构建的LSTM的多输入多输出神经网络模型,通过截取预测日前N天的用电负荷数据,与预测日当天的天气等相关影响特征构建输入向量;构建包含两层隐藏层的堆叠LSTM模型,使得网络能够对输入数据进行深度学习;通过将之前时刻输出负荷值在时间轴上进行传递,可以有效地利用历史负荷数据进行当前负荷数据的预测。但是时间窗口N的大小、隐藏层所包含的基本单元个数,以及为了获取最小损失函数需要循环迭代次数、每次输入的样本数量都对预测的输出数据精度产生一定的影响,而每次通过手动调参又会浪费大量的时间且不一定可以调得最优参数,因此根据所需优化的超参数个数构建麻雀种群粒子维度,采用SSA算法对以上参数进行寻优。
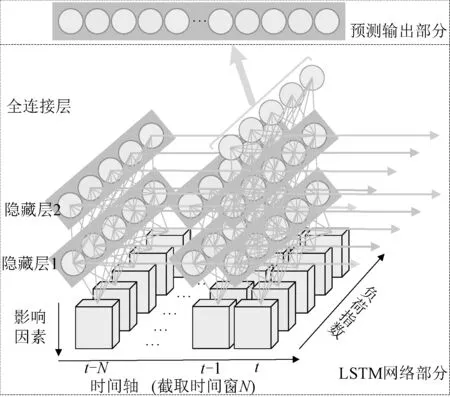
图2 LSTM神经网络结构图Fig.2 Structure diagram of LSTM neural network
2.3 SSA算法原理
麻雀搜索算法是由薛建凯[27]提出的新型群智能优化技术,其灵感来源于麻雀种群中的觅食行为和反捕食行为。算法将麻雀的种群分为发现者和加入者,通过构建的适应度函数对麻雀的适应度值进行计算,以此来实现麻雀个体之间的角色、位置变换,有效地避免了传统优化算法易陷入局部最优解的问题。
(7)
式中,X为随机初始化的麻雀种群;x为麻雀个体;d为种群的维数,在数值上与LSTM神经网络待优化参数个数相同;n为麻雀的数量。
(8)
式中,Gx为适应度矩阵;g为麻雀的适应度值,通过预测负荷数据与原始负荷数据的均方根(Root Mean Squared Error,RMSE) 进行计算。
(9)
式中,iter为当前迭代数;itermax为最大迭代次数;Xi,j为第i个麻雀在第j维中的位置信息,j=1,2,3,…,d;α∈(0,1];R2和ST分别为预警值和安全值,其中R2∈(0,1],ST∈[0.5,1],发现者发现了捕食者,会立即发出报警信号,如果报警值大于安全阈值,发现者就会根据式(9)进行位置更新,否则就继续进行之前的搜索工作;Q为随机数,服从正态分布;L为1×d且每个元素都为1的矩阵。
(10)
式中,Xp为当前发现者所占据的最优位置;Xworst为当前全局最差的位置;A为每个元素随机赋值为1或-1的矩阵,并且A+=AT(AAT)-1。加入者在觅食过程中会随时监视着发现者,一旦发现者发现了更好的食物,加入者会立刻与之争抢,如果加入者赢了,那么它们就将该发现者的食物据为己有,否则继续觅食。加入者按照式(10)进行位置更新,根据条件可知,当适应度较低的加入者没有获得食物时,就会进行位置变换,以获取更多的食物。
(11)
式中,Xbest为当前全局最优位置;β为步长控制参数,服从N(0,1)分布;K∈[-1,1];fi为第i只麻雀的适应度值;fg为全局最佳适应值;fw为全局最差适应值;ε为避免分母出现零而设置的常数。随机初始化的发现者与加入者根据式(11)去争抢食物资源并进行位置更新,直到达到最大迭代次数,找出全局适应度值最高的麻雀为全局最优解。
2.4 SSA-LSTM总体流程
LSTM网络结构的参数选择对负荷预测的准确性有很大的影响,因此对LSTM网络结构的关键参数进行寻优是十分必要的。麻雀搜索算法在收敛度和精度方面都表现出良好的性能,在处理非线性和多变量问题时也有一定的优势,因此本文采用麻雀搜索算法对LSTM神经网络结构的关键参数进行寻优。本文选取LSTM网络模型中的时间窗口大小、批处理大小和隐藏层单元数作为优化对象,用以架构麻雀搜索算法的粒子维度。模型整体结构如图3所示,模型优化过程如下:
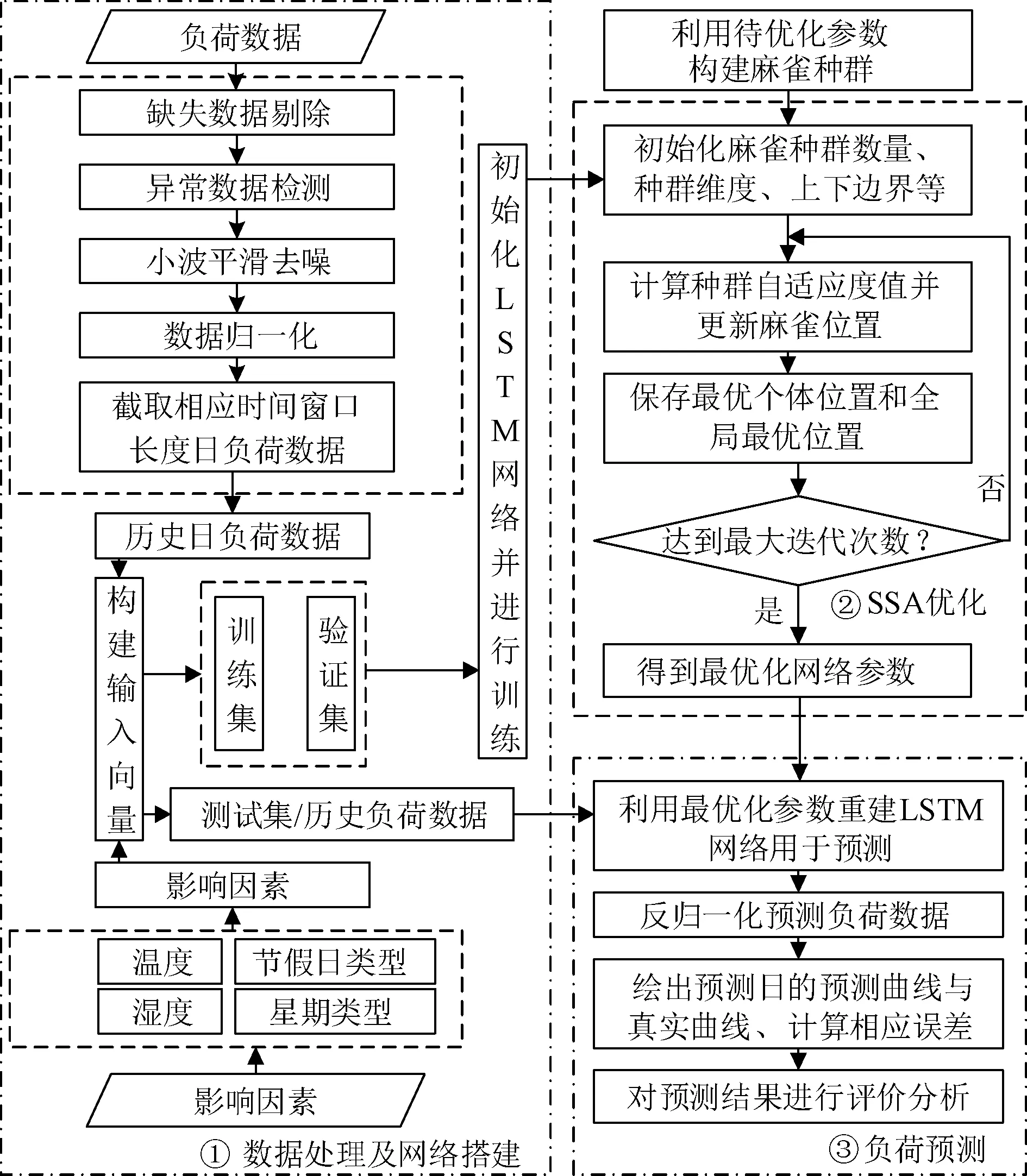
图3 预测模型整体结构Fig.3 Forecast model overall structure
(1)初始化:以LSTM网络的时间窗口大小、批处理大小和隐藏层单元数作为优化对象,确定麻雀种群大小、迭代次数、初始安全阈值,初始化SSA优化算法。
(2)适应值:利用LSTM算法的预测值和样本数据的均方根来确定每只麻雀的适应值。
(3)更新:利用式(9)~式(11)更新麻雀位置,得到麻雀种群的适应度值,并对种群中最优个体位置和全局最优位置值进行保存。
(4)迭代:判断是否满足终止条件或者是否达到更新迭代次数的最大值。如果是,则退出循环并返回最优个体解,即确定网络结构最优参数,否则继续循环步骤(3)。
(5)优化结果输出:以SSA算法输出的最优粒子值作为LSTM的时间窗口大小、批处理大小和隐藏层单元数值。
3 算例分析
3.1 数据选取
实验基于2016年电工杯A题所提供的数据集,该数据集包含了2012年1月1日至2015年1月10日的用电数据以及气象数据,该用电负荷数据以15 min为粒度,每天一共96个采集点数据,实验选取距今较近且数据较全的2014年负荷数据以及气象数据进行实验。
3.2 数据预处理
3.2.1 数据清洗
数据的质量为预测精度提供了有力的保障,但是在数据的采集过程中也存在着一些异常数据。对于缺失的负荷数据先用0值进行填充,此时缺失数据点被处理成了异常数据点,然后统一对数据集中的异常数据项进行辨别和修正。
负荷曲线中的异常数据通常表现为数据项取值突然升高或者降低,对这些异常数据运用均值填补法进行修正,公式如下:
(12)
式中,a、b分别为向前与向后所取的天数,一般取2~4;y(i,s)为第i天的第s个采样点的负荷数据。某条负荷曲线采样点缺失数据与异常数据的处理如图4所示。
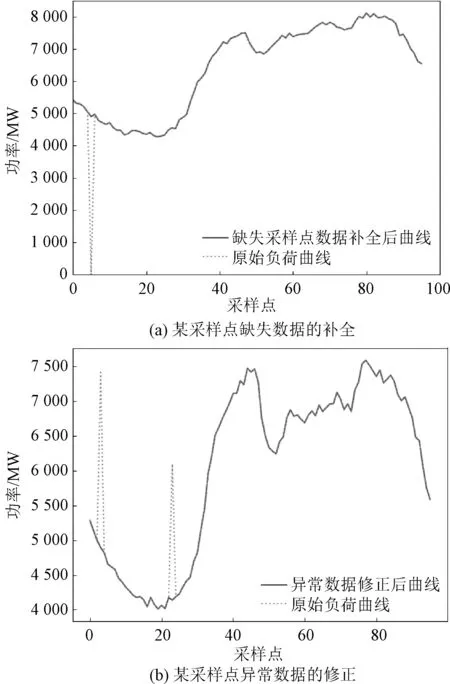
图4 缺失数据与异常数据的处理Fig.4 Handling of missing data and abnormal data
3.2.2 数据去噪
在数据采集过程中由于受到各种因素的影响,采集到的历史负荷数据往往是在真实的负荷值上叠加了一定的随机噪声,这些噪声会引起预测结果的偏差,因此对原始负荷数据进行了去噪处理。实验选取Symlet小波函数对数据进行去噪处理,部分去噪后数据与原始数据对比曲线如图5所示。
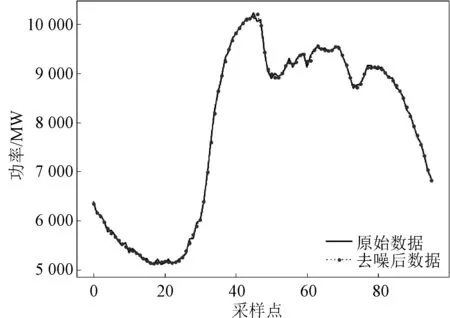
图5 数据去噪对比图Fig.5 Comparison chart of data denoising
3.2.3 数据归一化处理
由于用电负荷数据的数量级较大,会对神经网络的训练和计算效率产生影响,同时也为了提升算法的收敛速率,因此将数据进行归一化处理。本文采用min-max标准化方法将原始用电负荷数据归一化到[0,1]之间,表达式如下:
(13)
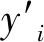
3.2.4 输入向量的构建
电力负荷数据是一种非线性、非平稳的时间序列,其需求量与许多影响因素有关,研究选取对负荷预测影响较大的平均温度、最高温度、最低温度、湿度、日期类型以及是否节假日等作为负荷预测的影响因素,结合前N日负荷序列的96点采样数据进行输入向量的构建。其中需对工作日、节假日等数据进行量化处理,例如对工作日置0节假日置1。
本文构造的输入向量为待预测日前N天的负荷数据[y(pre-N,1),y(pre-N,2),…,y(pre-1,95),y(pre-1,96)]并结合待预测日的影响因素,将其输入到神经网络中,网络输出为待预测日的96点负荷数据[y(pre,1),y(pre,2),…,y(pre,95),y(pre,96)]。
3.3 预测精度评价指标
使用平均绝对误差(Mean Absolute Error,MAE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、均方根误差(Root Mean Squared Error,RMSE)和平均误差(Mean Error,ME)来评估模型,如式(14)~式(17)所示:
(14)
(15)
(16)
(17)
同时本文以RMSE构建SSA的适应度函数,求解最佳粒子。同时通过评价指标对LSTM、PSO-LSTM、BP、PSO-BP、SSA-BP、SSA-LSTM等模型进行对比评估,验证本文所提出模型的先进性。
3.4 实验分析与负荷预测
实验模型在python3.8编译器下搭建,在2.40 GHz Intel(R) Core(TM) /i5-9300HF CPU /GeForce GTX 1650-GPU/8 GB内存的计算机上运行。
3.4.1 各个季节单日负荷预测
因各个季节气候不同,因此用电量也会有所变化,因此对四个季节分别建立模型并进行参数寻优。按照地球公转原则,截取2014年的3~5月为春季数据集,6~8月为夏季数据集,9~11月为秋季数据集,因数据集中只收录到2015年1月数据,故选取2013年12月、2014年1月、2月为冬季数据集分别进行实验。四个数据集中的数据60%用于训练,20%用于验证,20%用于预测。
经实验发现,在训练初期模型的预测精度随着网络层数的增加而提高,但是当LSTM神经网络层数大于2层时,模型的预测精度未发生明显提高且整体优化时间成倍递增,因此选择LSTM的网络层数为2层,Dropout为0.2,在LSTM最后加入一个全连接层,神经单元数量为96即预测的96个负荷数据,学习率为0.001。经网络模型寻优出来的四个季节模型参数见表1。
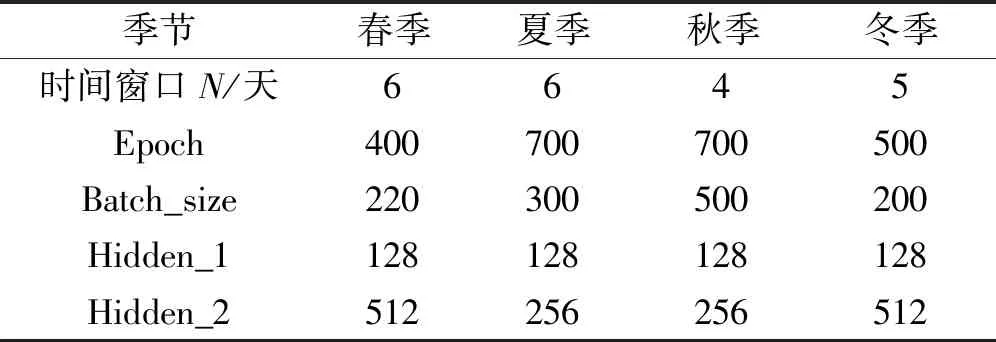
表1 各季节模型参数Tab.1 Model parameters for each season
利用寻优出来的参数进行模型的搭建,然后随机选取预测日进行负荷预测。实验分别对2014年2月21日、5月26日、8月28日、11月27日的负荷数据进行了预测,真实值与预测值对比结果如图6所示,每15 min为1个采样点。通过预测结果获得的MAE、RMSE、MAPE与ME见表2。
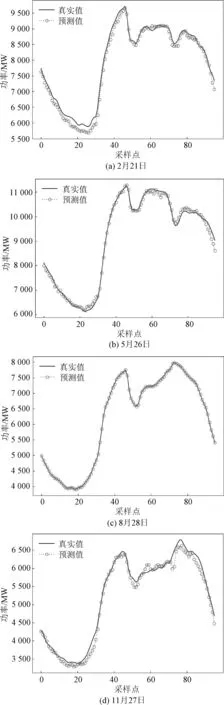
图6 预测结果图Fig.6 Forecast result chart
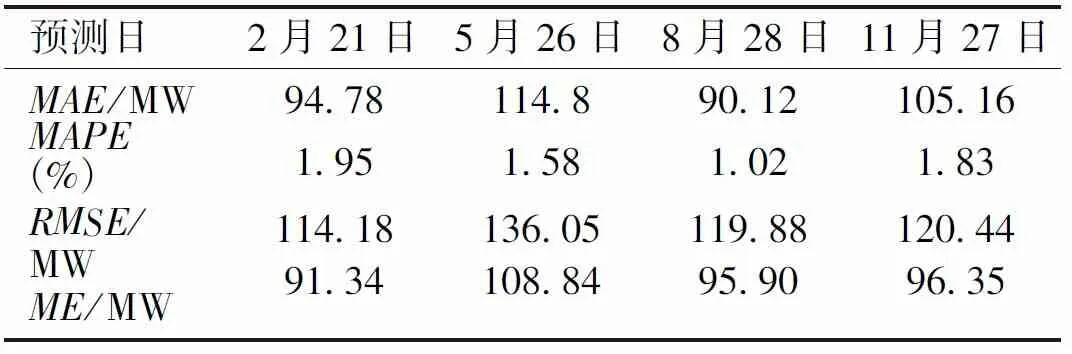
表2 2014年预测结果MAE、MAPE、RMSE、ME对比Tab.2 Comparison of MAE,MAPE,RMSE and ME predicted results in 2014
从图6可以看出,利用经SSA算法优化出的参数重新训练出的模型,在四个预测日的预测效果都比较好,与真实值更为接近,通过图6(c)可以看出,预测曲线几乎与真实曲线完全重合,有效地预测了短期内日负荷量未来的变化趋势,精准地把握了负荷变化的规律。由表2可得,从误差的实际情况来看,MAE控制在90.12~114.8 MW之间;从预测精度来看,RMSE控制在114.18~136.05 MW之间;从评估模型精度的角度来看,MAPE控制在1.02%~1.95%之间。综上所述,本文所提算法模型具有较高的预测精度。
3.4.2 模型对比分析
图7为四个预测日分别在LSTM、PSO-LSTM、BP、PSO-BP、SSA-BP、SSA-LSTM六种预测模型下的结果对比,表3为六种模型的预测指标。
从图7可以看出,通过SSA-LSTM模型预测出的用电负荷与真实用电负荷数据之间的拟合程度在随机选取的四个预测日中都较其他5种模型预测效果更好,与真实值的拟合程度更高。
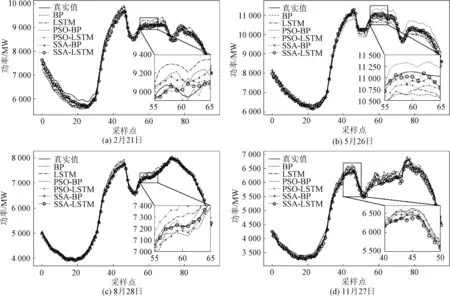
图7 四个预测日负荷预测结果对比Fig.7 Comparison of four daily load forecasting results
表3和表4为四个预测日分别在六种算法模型下的预测结果对比,通过表3和表4可以看出,SSA-LSTM模型预测精度的误差在1.02%~1.95%之间,而目前普遍应用的PSO-LSTM算法模型预测精度的误差在1.43%~2.06%之间,提升了0.09%~0.41%。且就六种对比算法整体拟合效果较好的图6(c)来看,SSA-LSTM的MAPE较目前存在的改进算法模型PSO-BP、PSO-LSTM分别提升了0.82%、0.41%,较SSA优化的对比算法模型SSA-BP提升了0.42%,表现出了较好的预测模型精度;MAE较其他三种优化算法模型分别降低了62.53 MW、44.43 MW、31 MW,较好地降低了预测误差;RMSE相较于其他三种优化算法模型分别降低了83.8 MW、60.54 MW、31.08 MW,表明所提算法模型在预测精度方面有较大的提升;通过预测模型的ME来看,模型整体性能稳定,未出现较大偏差。
此外,对比表3和表4中SSA-BP的MAE、MAPE、RMSE、ME评价指标,可以看出实验所搭建的SSA优化BP神经网络对比算法模型较PSO-BP神经网络模型有了改进,这表明通过SSA算法来寻优网络参数进行预测是优于目前应用较多的PSO寻优算法模型的。
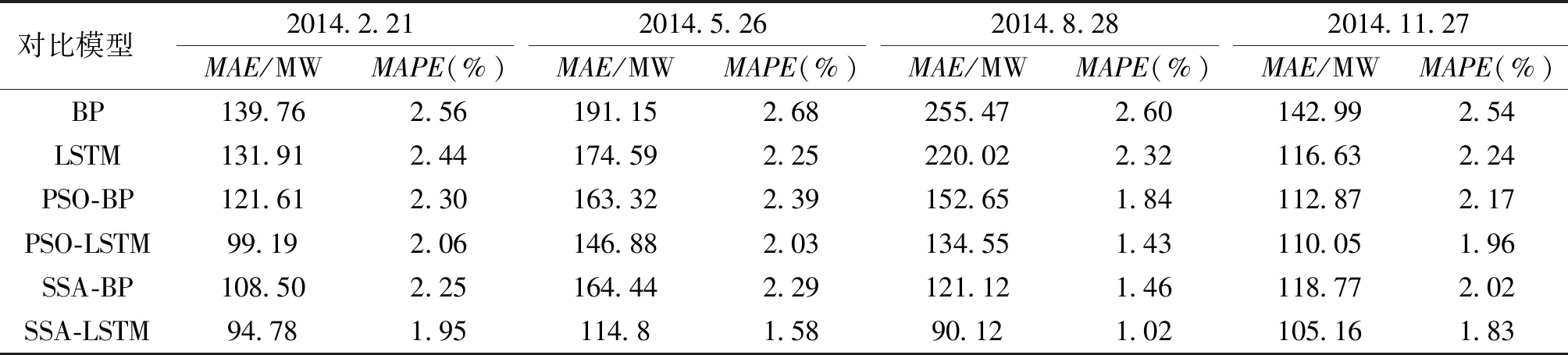
表3 对比模型的MAE、MAPETab.3 MAE and MAPE of comparison models
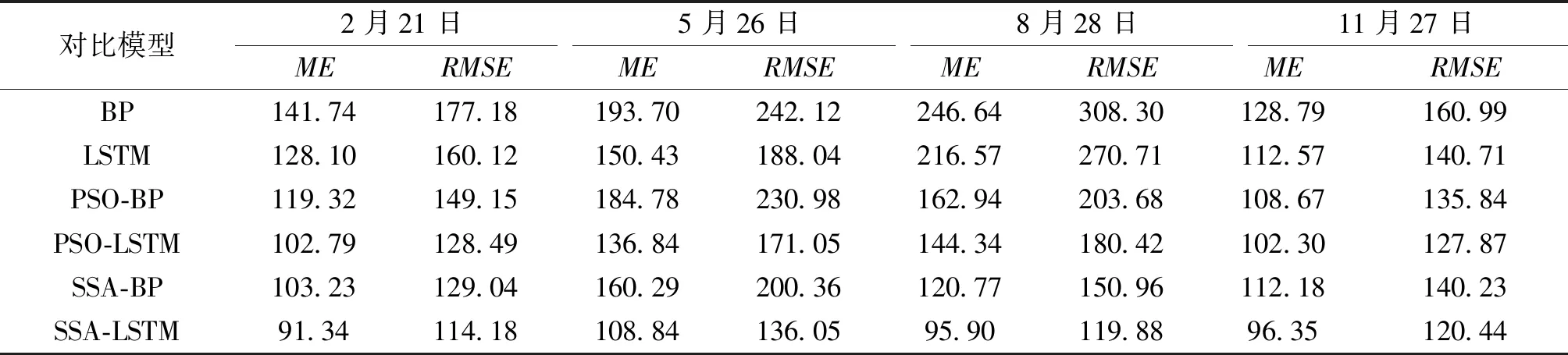
表4 对比模型的ME、RMSETab.4 ME and RMSE of comparison models (单位:MW)
由此可见,本文提出的SSA优化LSTM的多输出神经网络模型能够将历史用电负荷与相关影响因素等数据与网络结构深入匹配,较好地学习了历史负荷变化的规律,能够对未来的用电负荷做出更为准确的预测。
4 结论
本文提出SSA-LSTM模型,并结合2016年电工杯数学建模竞赛数据进行短期负荷预测,通过算例分析得到以下结论:
(1)通过对用电负荷数据集按照季节进行划分,选取预测日的温度、湿度以及节假日和工作日类型并结合历史用电数据进行输入序列的构建,并训练相应的模型,充分考虑了相关影响因素对负荷预测的影响,有效地提高了预测精度。
(2)本文通过SSA进行参数寻优并构建LSTM预测网络,使得输入数据与网络结构深入匹配,有效地解决了人工调参的耗时长且预测效果不佳的问题,并提高了预测精度。
猜你喜欢
经营者(2023年10期)2023-11-02 13:24:48
中国化肥信息(2021年12期)2021-04-19 12:25:22
中学生数理化·中考版(2020年12期)2021-01-18 06:59:44
电子制作(2019年19期)2019-11-23 08:42:00
作文小学中年级(2019年10期)2019-11-04 00:39:52
小学生必读(中年级版)(2018年10期)2019-01-04 05:11:10
新世纪智能(高一语文)(2018年11期)2018-12-29 11:32:06
趣味(语文)(2018年2期)2018-05-26 09:17:55
重型机械(2016年1期)2016-03-01 03:42:04
山东青年(2016年1期)2016-02-28 14:25:22
