
基于深度学习的旱灾风险评估方法
2022-07-01 13:46:58冯岭,宋文辉,陈继坤
人民长江 2022年6期
冯 岭,宋 文 辉,陈 继 坤
(华北水利水电大学 信息工程学院,河南 郑州 450046)
0 引 言
干旱是降水或河川径流异常引起的水分短缺现象[1],而旱灾是世界上危害最广泛、最严重的自然灾害之一[2]。中国地处典型季风气候区,旱灾的影响尤为突出[3]。据《中国水旱灾害公报》统计,中国农作物平均年成灾面积近年来呈现出逐年增长的态势,从20世纪50年代的531.7万hm2,迅速增长至 90 年代的1 384.2万hm2。每年因旱灾损失粮食基本维持在300多亿kg,造成的工农业直接经济损失近千亿元[4]。因此,如何在旱灾发生前进行灾情风险评估,准确预测灾情的发生,保障粮食安全,是干旱相关工作者需迫切展开的工作。
传统的旱灾风险等级评估方法大多是通过定义各种指标对旱灾的风险等级进行评价。在指标方面,张伟杰等[5]基于标准化降水指数SPI,分别以月尺度、季节尺度、半年尺度、年尺度对内蒙古达茂草原近56 a间的干旱演变与趋势特征进行分析;聂明秋等[6]采用非参数法以渭河流域为研究对象,构建了综合干旱指数,分析了渭河流域综合干旱的演变规律,结合干旱风险因子探究风险的动态演变特征;任怡等[7]利用水资源供求指数、综合干旱指数对陕西省干旱时空分布进行了分析。
以上基于指标的方法通常只能对已发生干旱的强度进行分析,而无法对未来旱灾发生的可能性和风险等级进行预测。随着机器学习方法的发展,将多源数据与机器学习算法相结合已经成为当前旱灾风险等级评估的一个重要趋势,多元线性回归[8]、遗传算法[9]、人工神经网络[10]等机器学习模型和算法被用于对旱灾的风险等级进行评估。在这方面,Fung等[11]基于改进的支持向量回归模型,对马来西亚兰加特河流域下游的农业干旱进行预测;Djerbouai等[12]使用小波神经网络和随机模型,对北阿尔及利亚地区进行了干旱预测预报;Seibert等[13]通过比较3种不同的统计方法,即多元线性回归模型、人工神经网络模型、随机森林回归树模型,对水文干旱进行季节性预报;Khan等[14]利用支持向量机(Support Vector Machine,SVM)、人工神经网络和K近邻算法对巴基斯坦进行了干旱建模分析。尽管上述方法可以在一定程度上对未来发生的干旱风险进行预测和评估,但在这些方法中考虑的影响旱灾风险的因素较为单一,并没有将干旱影响因素与实际旱灾风险关联起来。
针对已有旱灾风险等级评估方法的不足,本研究旨在基于历史旱情文本数据和气象数据,建立一种数据驱动的短期旱灾风险等级评估方法。首先,对旱情文本进行预处理,提取干旱等级标签;其次,选取多个影响干旱的气象因素,通过深度学习算法来挖掘气象数据与历史灾情之间的关系;最后,建立基于数据驱动的多源多模态旱灾风险等级评估模型,以对未来发生旱灾的风险等级进行评估。以此可在旱灾发生前对旱灾进行预警,降低旱灾造成的负面影响,减少国家的经济损失。
1 材料与方法
1.1 研究区概况
河南省是中国的粮食与农业大省,而旱灾对河南省的影响尤为强烈。郑州市位于河南省中部偏北,地处南北气候过渡带,常年平均降水量为628 mm,降水量的年际变化大,年内分布不均匀。地形和气候的2个过渡带决定了郑州市旱涝灾害会频繁发生[15],故选择河南省境内的郑州市作为实例来研究旱灾风险。
1.2 数据来源
研究区的气象数据来源于中国气象资料共享服务网(http:/cdc.cma.gov.cn/)河南省县级以上区域18个气象站1951~2020年的逐月气象资料。
研究区文本数据来源于《中国气象灾害大典(河南卷)》干旱灾害篇章中的灾情记录文本。该文本中,记录了河南省地区从公元前1804年到公元2000年的历史旱灾。2000年以后的标签以河南省水利厅、农业厅发布的新闻报道为主,辅以网络报道期刊数据等。
基于上述2个数据集,以郑州市为例,根据1951~2017年的气象数据和灾情记录文本数据,对2018~2020年的旱灾风险等级进行了预测评估,最后对2021年旱灾情况进行了预测。
1.3 旱灾风险等级评估方法
旱灾风险评估主要是实现对未来可能发生旱灾的风险等级进行评估。在该方法中,综合考虑到了多种风险因素,比如:降水量、气温、平均相对湿度以及平均水汽压等,融合了气象监测数据和旱情历史文本数据;并基于机器学习和深度学习算法,构建了旱灾风险等级评估模型,以对未来一段时间内发生旱灾的可能性和严重程度进行评估。该模型的主要实现流程如图1所示。
旱灾风险等级评估的主要流程包括以下4个部分:① 旱灾风险等级评估模型训练集的构建;② 基于支持向量机的旱灾风险等级评估模型的训练;③ 基于长短期记忆神经网络(Long Short Term Memory Networks,LSTM)的未来气象特征值预测;④ 基于支持向量机的未来旱灾风险等级的评估。
(1) 基于气象监测数据和旱情历史文本数据,筛选可能对旱灾发生具有影响的气象特征,并抽取历史旱灾的风险等级标签,构建用于进行旱灾风险评估模型的训练数据集。
(2) 基于旱灾训练数据集,采用SVM分类算法,对旱灾风险等级评估模型进行训练。
(3) 对于已有的气象特征数据,采用LSTM预测其未来一段时间的特征值。
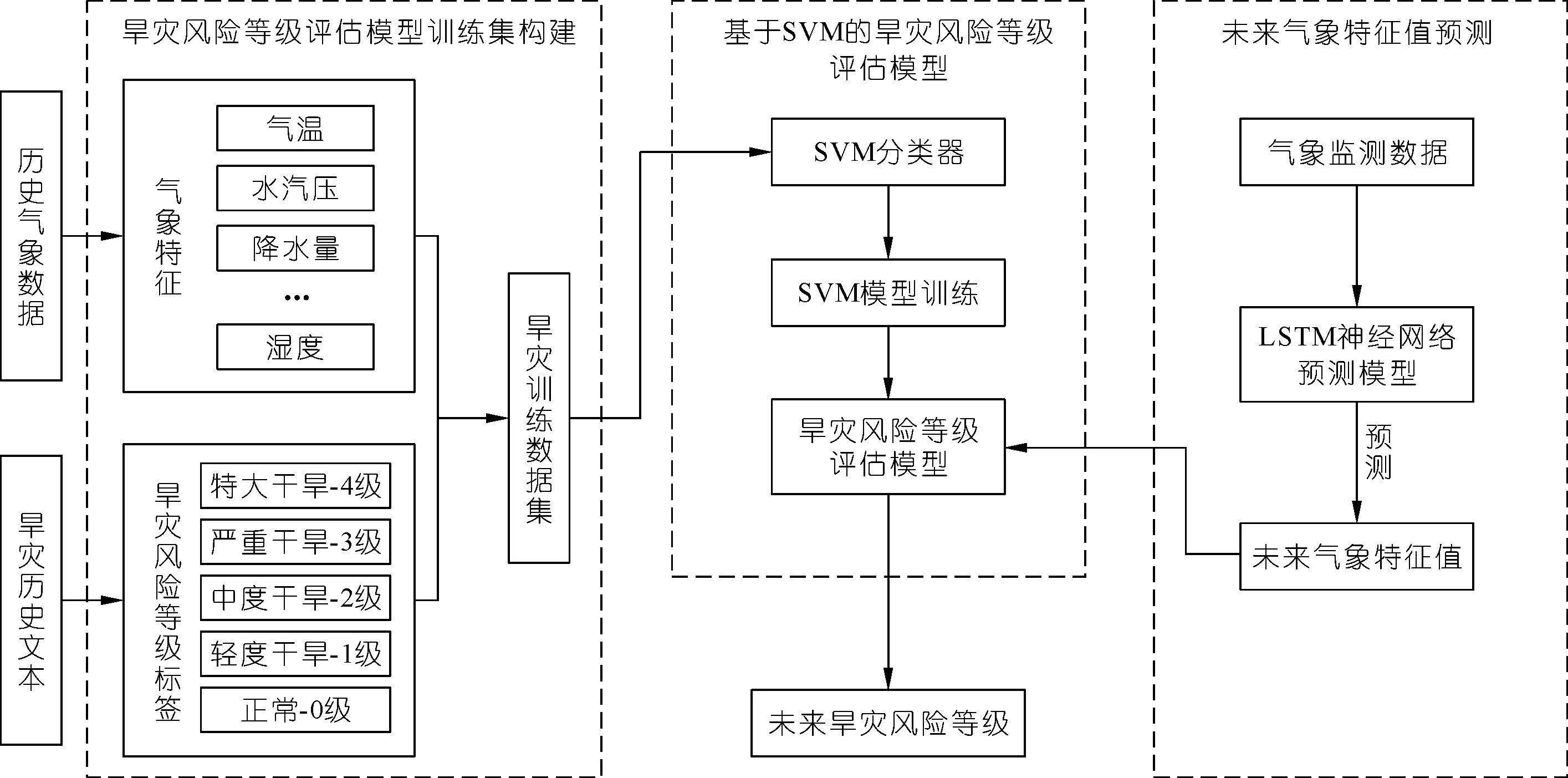
图1 旱灾风险等级评估技术路线示意Fig.1 Technical roadmap for drought risk assessment
(4) 将LSTM得到的一系列未来特征值,加载到训练好的旱灾风险等级评估模型,从而对未来可能发生的旱灾风险等级进行评估。
1.3.1构建旱灾训练数据集
为了获得有效的旱灾风险等级评估模型,首先需要构建旱灾风险等级评估的训练数据集。数据集包括标签集和特征集2个部分。对于标签集,基于历史灾情记录、国家或地区的干旱灾害统计报告等文本数据,采用文本抽取方法从中来抽取相应的旱灾等级标签。对于特征集,基于气象监测数据中的相关指标,从中筛选出用于旱灾风险等级评估的主要特征。
(1) 标签抽取。对于标签集,基于历史灾情记录、国家或地区的干旱灾害统计报告等文本数据,通过文本抽取和统计分析的方法,抽取各个城市历年发生的旱情信息,以用于构建特征集对应的旱灾风险等级标签。标签抽取的流程如图2所示。

图2 标签抽取流程Fig.2 Label extraction process
根据历史灾情文本,应首先构建地名词典以及干旱词典;然后,采用正则表达式以及模板匹配法对干旱灾情文本中的时间、地点以及干旱等级进行识别和抽取,以形成结构化的旱灾风险等级标签;最后,对抽取的标签进行人工校验,以保证所抽取标签的准确性。标签抽取的流程共包含以下3个步骤。
步骤1:构建地名词典和旱灾风险等级词典。在历史灾情文本中,通常采用“省、市、县”3个不同大小的粒度来表述旱灾发生的范围。对此,将城市作为研究粒度,即将“县”转换为对应的“市”。为了获得“省”“县”与“市”之间的关系,定义了地名词典。此外,根据历史灾情文本中对灾情的相关描述,从描述的严重程度以及当年的旱情实际情况,将旱灾风险划分为5个等级:正常、轻旱、中旱、重旱、特旱,并构建干旱等级词典,以用于旱灾风险等级标签的抽取。
步骤2:基于地名词典和旱灾风险等级词典,采用正则表达式和模式匹配法,从历史灾情文本中抽取旱灾发生的时间、城市以及旱灾的风险等级。在经过程序自动抽取后,为了保证所抽取标签信息的质量,对抽取的标签进行人工校验。
步骤3:将抽取的结构化标签保存为csv文件,以方便计算机读取。图3给出了标签抽取结果的示例图,由图3可以看出,每一条标签记录的格式为〈时间,城市,月份,旱灾风险等级〉。例如,〈1949,商丘,3,2〉表示1949年3月商丘发生了中度干旱。

图3 标签抽取结果示例Fig.3 Sample image of label extraction results
(2) 特征集构建。通过对历史灾情文本的抽取,得到用于构建旱灾风险等级评估模型的标签集合。但为了构建完整的旱灾风险等级评估模型,还需要获得与旱灾风险等级标签有关联的特征。将气象指标作为候选特征集,然后基于随机森林算法对各个指标的重要性进行计算,并将重要度较高的前k个指标用于构建旱灾风险等级评估模型,所采用的候选气象指标如表1所列。

表1 旱灾风险等级评估候选特征集Tab.1 Candidate feature set for drought risk assessment
表1中的指标的具体含义及其与旱灾的关系描述如下。
降水是影响干旱的重要因素,常见的干旱预报系统大多是依据降水量来对未来的干旱进行预测。例如,春播期降水量偏少,极易造成春旱。除此之外,在现有的干旱指标中,如标准化降水指数(SPI)、帕尔默干旱指数(PDSI)、地表水供给指数(SWSI)等都将降水量作为衡量干旱的主要因素;高温少雨会直接导致干旱的发生,尤其是夏季持续的高温天气会造成土壤水分大量蒸发、土壤墒情变差,导致十分严重的干旱。因此,可以考虑把气温作为评估旱灾风险等级的特征之一;气压跟天气有密切的关系,一般来说,地面上高气压的地区往往是晴天,地面上低气压的地区往往是阴雨天。气压通过影响天气,从而影响干旱。
风速与水分蒸发有着密切的关系,风可将蒸发物表面饱和度较高的空气吹走。因此,风速越大,水分蒸发越快,造成土壤失墒,导致干旱的发生;湿度越大,空气中含有的水汽越接近于饱和水汽压,也越容易形成凝结,从而形成降水影响干旱;日照与干旱有着一定关系。气候干旱的地区,常年是晴朗天气,日照时数就多。热带雨林气候区常年阴雨天气,日照时数就少。因此,日照时长与干旱存在一定的关联;水汽压与降水量之间存在线性关系,与蒸发快慢也有着密切的关系。白天温度高,蒸发快,进入大气的水汽多,水汽压就大;夜间情况相反。因此,水汽压也是影响干旱的一个重要因素。
对于以上候选特征,采用随机森林算法[16],基于袋外误差(OOB)理论来判断每个特征在随机森林中的每棵树上的贡献度,从而计算各个特征的重要度,并将排名前k个特征作为用于构建旱灾风险等级评估模型的特征。对于任意特征x的特征重要度Ix的计算公式如下:
(1)
式中:N代表训练样本的个数,ROOB1表示决策树对袋外数据进行分类,统计的正确分类的个数;ROOB2为决策树对扰动后的袋外数据进行分类,统计的正确分类个数[17]。如果加入扰动后,袋外数据准确率大幅度下降,说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
(3) 标签与特征的融合。 基于筛选出的用于构建旱灾风险等级评估模型的特征以及从历史灾情记录文本中抽取的标签,将表示同一城市同一时间的特征和标签进行融合,从而构成完整的旱灾训练数据集,所构建的旱灾训练集的示例如表2所列。
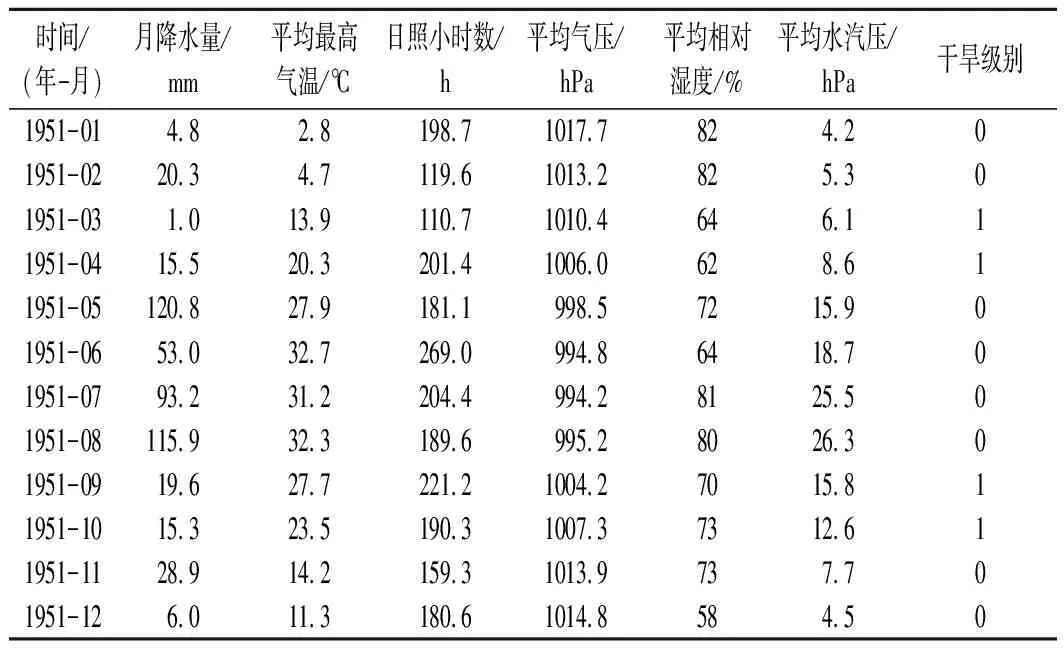
表2 训练数据集示例Tab.2 Example of training data set
1.3.2基于SVM的旱灾风险等级评估模型
根据前文中得到的训练数据集,采用分类算法来构建旱灾风险等级评估模型,并对模型中的未知参数进行训练。常见的分类算法包括K近邻[18]、决策树[19]、朴素贝叶斯[20]、支持向量机[21]等。其中,基于支持向量机的分类算法具有较好的学习泛化能力,可以解决非线性、高维数、局部极小点等分类中存在的问题。因此,本研究采用支持向量机分类器对旱灾预测模型进行训练,其训练过程如图4所示。

图4 基于SVM的旱灾风险等级评估模型Fig.4 Drought risk assessment model based on SVM
支持向量机算法的基本思想是在特征空间上找到最佳的分离超平面,使得训练集上正、负样本的间隔最大。假设训练数据集中的训练样本为(x1,y1),(x2,y2),……,(xi,yi),xi为用于进行旱灾风险等级评估的特征向量,yi为旱灾风险等级标签。对于线性可分的情况,支持向量机分类算法需要找到一个超平面,使2个异类支持向量到超平面的距离之和最大。
然而,由于训练样本往往不是线性可分的,因此,通常需要将样本从原始空间映射到一个更高维的特征空间中,使得样本在这个特征空间内线性可分,从而找到一个合适的划分超平面。样本数据经过高位映射后的超平面可以表示为
f(x)=wTφ(xi)+b
(2)
式中:w为加权向量,φ(xi)为映射函数,b为偏差。寻找超平面的过程即求优化问题的最优解过程,所得到的最优化问题是:
(3)
通过拉格朗日乘子法将原问题转化为对偶问题求解,即可得到用于旱灾风险等级评估的SVM分类器。
1.3.3基于LSTM的未来特征值预测
基于支持向量机分类算法得到旱灾风险等级评估模型后,当给定一组与旱灾相关的特征时,可基于这组特征对当前的旱灾风险等级进行评估。但为了对未来可能存在的旱灾风险进行预测,需要对未来的特征值即未来m个时刻的降水量、气温、水汽压等进行预测。鉴于在旱灾风险等级评估模型中采用的特征都为时序型特征,因此,可以采用时间序列模型对未来时刻的特征值进行预测。
长短期记忆神经网络[22]是一种常见的时间序列预测模型,它可以学习长期依赖信息,是当下比较流行的循环神经网络。近年来,随着深度学习的不断发展,LSTM已经在语音识别、机器翻译、负荷预测、交通流量预测等众多不同领域成功应用。由于该模型具有良好的时序预测能力,因此,可采用LSTM对旱灾相关特征未来m个时刻的特征值进行预测。LSTM单元结构如图5所示。
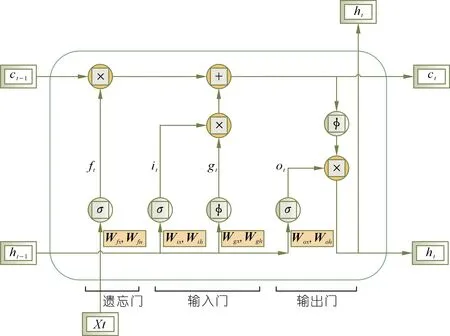
图5 LSTM单元结构示意Fig.5 LSTM unit structure diagram
LSTM 3个重要的门中,遗忘门ft决定了上一时刻的单元状态有多少保留到当前时刻;输入门it决定了当前时刻网络的输入有多少保存到单元状态;输出门ot决定了控制单元状态有多少输出到 LSTM 的当前输出值,gt代表输入单元。“门”以及输入单元的计算公式如下。
遗忘门:
ft=σ(Wfx·xt+Wfh·ht-1+bf)
(4)
输入门:
it=σ(Wixxt+Wihht-1+bi)
(5)
输入单元:
gt=φ(Wgxxt+Wghht-1+bg)
(6)
输出门:
ot=σ(Wox·xt+Woh·ht-1+bo)
(7)
输出:
ht=φ(gt⊗it+ct-1⊗ft)⊗ot
(8)
式中:Wgx,Wgh等是权重矩阵,b是偏置项,σ表示sigmod激活函数,φ表示tanh激活函数。“门”实际上就是一层全连接层,它的输入是一个向量,输出是一个0~1的实数向量,通过“门”来决定保留哪些信息。
由LSTM的原理可知,对于时序型数据,LSTM可通过“门”来记忆有用的信息,对数据未来值进行预测。旱灾风险评估研究中用于构建模型的气象数据均为时序数据。因此,对于选取的每个特征可采用LSTM来预测其未来一段时间的特征值。本文基于LSTM建立了适用于气象特征预测的深度学习预测模型,得到每个特征未来一段时间的特征值后,将预测的特征值输入到之前完成训练的旱灾风险等级评估模型中,即可对未来可能发生的旱灾风险等级进行评估。为了验证本研究中旱灾风险等级评估模型的有效性,将通过算例对所提出的方法进行分析验证。
2 结果与分析
2.1 旱灾训练集构建
旱灾训练集的构建包括标签集构建和特征集构建2个部分。
(1) 标签构建。为准确提取河南省历史干旱情况,基于《中国气象灾害大典(河南卷)》干旱灾害篇史料记载,根据上文标签抽取方法,将灾情划分特大干旱、严重干旱、中度干旱、轻度干旱和正常5个等级,分别用数字4,3,2,1,0来表示(若对应城市当年未记录发生旱灾,则标记为正常)。抽取的旱灾风险等级标签以月为粒度,当旱灾灾情记录文本中以季节来表述旱情情况时,将季节转换为对应的月。以郑州市为例,将1951~2011年的郑州历史旱灾发生情况以月为单位进行标签抽取,从而得到732条标签数据。本研究在抽取过程中所用到的地名词典以及干旱等级词典分别如表3和表4所列。
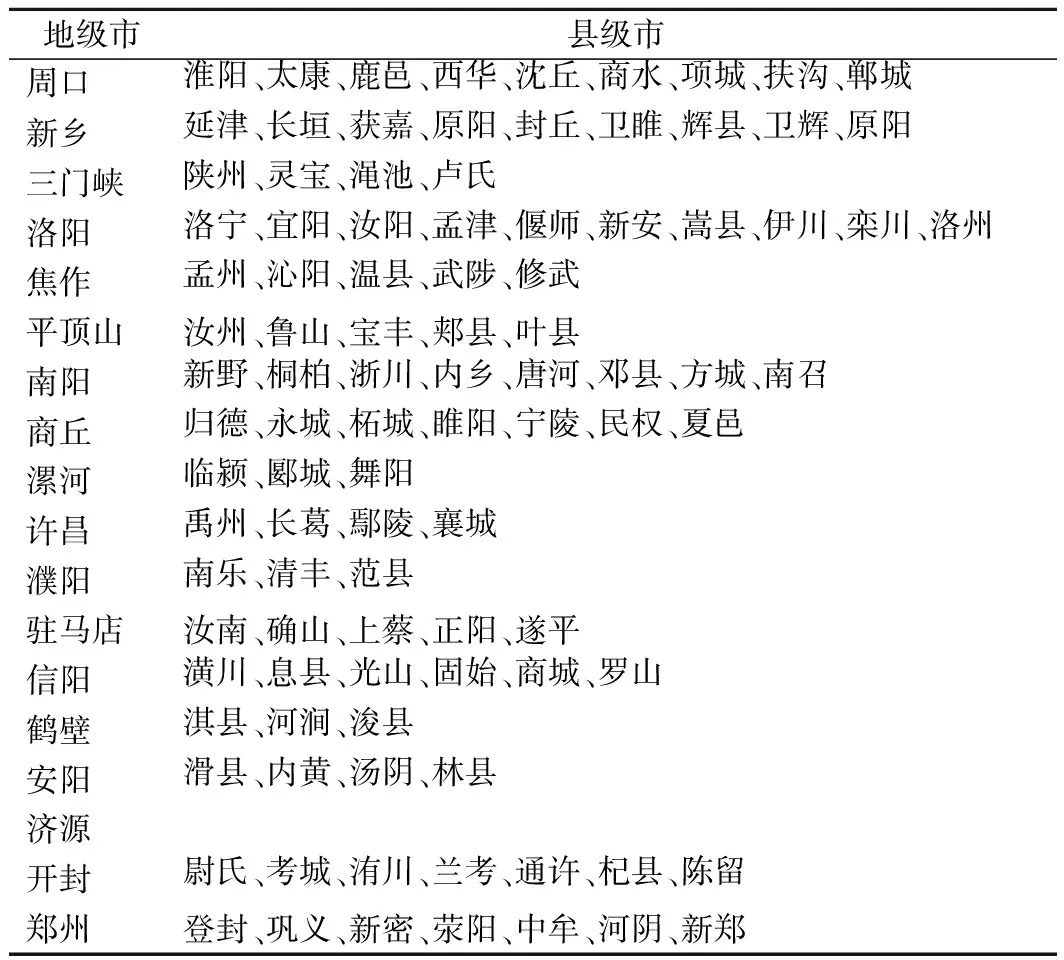
表3 地名词典Tab.3 Gazetteer

表4 干旱等级词典Tab.4 Dictionary of drought levels
(2) 特征筛选。对于表1中所列的候选特征集,采用随机森林算法计算各个特征的重要性,并按照重要度从大到小进行排序,得到了重要度最高的前6个特征,如表5所列。

表5 重要度最高的前6个特征Tab.5 The top 6 most important features
将这6个特征作为构建旱灾风险等级评估模型的特征。基于筛选出的构建旱灾风险等级评估模型的特征,以及从历史灾情记录文本中抽取的标签,将表示同一城市同一时间的特征和标签进行融合,从而构成完整的旱灾训练数据集。
2.2 旱灾风险等级评估模型
基于得到的旱灾训练数据集,采用支持向量机分类算法构建旱灾风险等级评估模型,并对模型中的未知参数进行训练。在该算例中,分别选择线性核、多项式核、高斯核作为SVM分类器的核函数,采用10折交叉验证法对旱灾风险等级评估模型进行训练,在训练过程中对SVM分类器的参数C和gamma进行调参优化。其中,C是惩罚系数,即对误差的宽容度,C越高,对误差要求越严格,容易出现过拟合;C越小,越容易出现欠拟合。gamma决定了数据映射到新的特征空间后的分布,gamma越大,则用于分类的支持向量越少;gamma值越小,则用于分类的支持向量越多。在训练过程中,不断地对参数C和gamma进行调参优化,最终得出核函数选取线性核且C=0.9时,SVM分类器在训练数据集上的效果最好,即可得到所需的旱灾风险等级评估模型。
2.3 未来特征值预测
为了对未来的旱灾风险等级进行预测,对于每一个用于构建旱灾风险等级评估模型的特征,如降水量、气温、水汽压等。首先,采用LSTM来预测该特征在未来m个时刻的特征值。在该算例中,基于LSTM模型,用前11个月的特征值来预测第12个月的特征值。例如,根据郑州市前11个月的气温,预测第12个月的气温,并在下一步将得到的第12个月的特征值加载训练好的旱灾风险等级评估模型中,从而对未来1个月的旱灾风险等级进行评估。
为了验证LSTM在未来特征值预测上的效果,选用1951~2000年共50 a郑州市的各个特征值的逐月数据,来构建LSTM模型,并对2001~2013年的每个月的特征值进行预测,预测曲线如图6所示。
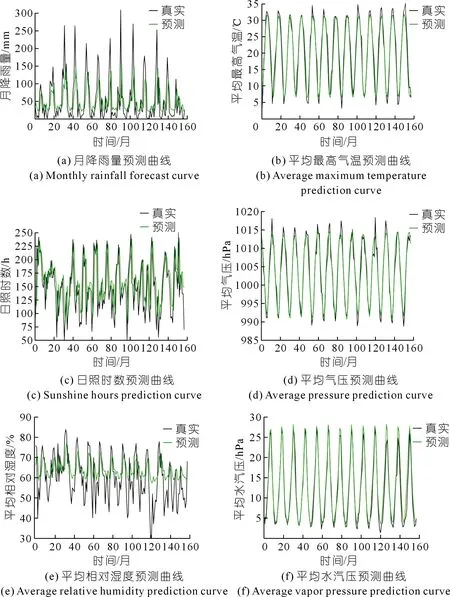
图6 6种特征预测曲线Fig.6 Six characteristic prediction curves
为了判断预测结果优劣,选取平均绝对误差(MAE)和决定系数(R2)作为评价指标。表6是对特征预测的评价,其中,平均绝对误差表示预测误差,数值越小表示预测精度越高;决定系数表示拟合优度,数值在0~1区间,数值越接近于1表示拟合越好。
(9)
(10)
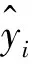
通过图6的特征预测曲线以及表6中列出的特征预测指标评价结果可以看出:对于选取的构建旱灾风险评估模型的6个特征,基于LSTM的特征值预测结果与真实值较为接近。在误差方面,平均绝对误差数值相对较小;在拟合优度方面,预测特征中有一半特征决定系数在0.90以上。因此,采用LSTM网络模型对各个特征的未来值进行预测是可行的。
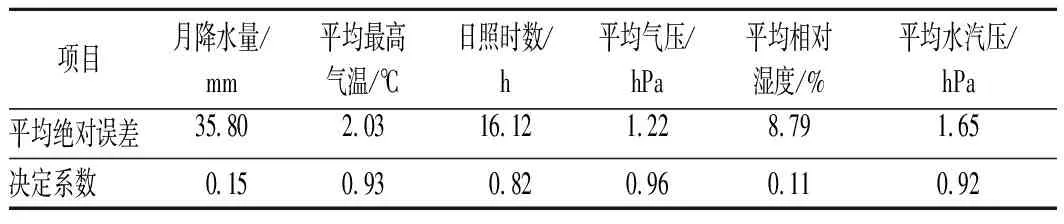
表6 特征预测指标评估Tab.6 Evaluation of feature prediction indicators
2.4 旱灾风险等级评估结果
通过LSTM预测得到了每个月的特征值,再将其加载到旱灾风险等级评估模型中,即可对每个月的旱灾风险等级进行评估。对于旱灾研究,在灾情记录文本中多以季节为单位来记录旱灾的发生情况。因此,将以月为单位记录的旱灾风险等级合并为以季节为单位的旱灾风险等级,并以当季最高的旱灾风险等级作为本季的旱灾风险等级。表7给出了对2018年冬到2020年秋的旱灾风险等级评估结果。

表7 旱灾风险等级评估结果Tab.7 Forecast results of drought risk levels
通过表7可以得出:在评估2 a的情况下,预测准确率为75%,证明本研究对于旱灾风险等级评估具有一定效果。另外,若将预测结果分为两类(正常与干旱)时,准确率会进一步提升到87.5%。结果显示:郑州市在2019年和2020年春季干旱较为严重,将预测的结果与历史资料中记载的真实结果进行比较,发现旱灾风险等级预测结果基本符合历史实际情况。另外,对2020年夏季预测结果进行误差分析,推测可能由于降水量预测小于实际值,且日照时长大于实际值导致最终误差。
3 结 论
本文基于历史旱情文本数据和气象数据,提出了一种新的旱灾评估思路,建立了数据驱动的多源多模态旱灾风险等级评估模型。通过对未来一段时间内可能发生的旱灾风险等级进行评估,可以得到如下结论。
(1) 气象数据可与文本灾情数据相结合,用于旱灾风险等级评估;
(2) 结合多种机器学习算法的优势,构建了旱灾风险等级评估模型,证明了大数据分析方法可用于研究旱灾问题;
(3) 算例评估结果显示,研究区春季干旱较为严重,基本符合实际情况。
此外,在初始选取评估特征时,考虑了气象、水文、墒情等多方面因素。但由于数据较难获取,仅基于气象特征来构建模型,可能由于风险因素不够全面,影响评估结果的准确性。随着旱灾风险因素的相关数据获取难度降低,采用此方法将得到更为准确的评估结果。
猜你喜欢
数学物理学报(2021年5期)2021-11-19 07:01:12
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:40
河北果树(2020年2期)2020-05-25 06:58:58
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
水利规划与设计(2017年5期)2017-06-09 08:56:18
黑龙江水利科技(2016年6期)2016-09-02 05:57:46
公民与法治(2016年10期)2016-05-17 04:12:58
东北电力大学学报(2015年1期)2015-11-13 05:20:25
计算机工程(2015年8期)2015-07-03 12:20:27
