
基于EM 算法与Gauss 混合模型的地铁站点类型分析
2022-06-28 06:07曾险峰
都市快轨交通 2022年1期
韩 荔,李 想,曾险峰
(1. 广州铁路职业技术学院,广州 510430;2. 西南交通大学交通运输与物流学院,成都 610031)
1 研究背景
地铁是城市客流主要的承载工具,是调节交通结构、缓解拥堵的重要手段。地铁站点承载着不同区域的各种社会经济活动,根据区域条件、交通功能、周边土地规划性质被划分为不同类型[1]。准确分析站点类别,掌握不同类站点的客流特征,有助于管理者及时调整与优化线网运营状态,为站点周边土地开发提供条件,增强站点吸引力,对城市以公共交通为导向的开发(TOD)模式等交通规划的推进有着重要作用。
交通大数据能够有效分析交通特征,可用于交通特征识别中的诸多问题,如研究旅行行为、旅行链重建和转移检测、目的地推断和OD(原点/目的地)矩阵、聚类分析等[2]。相比传统调查方法,交通大数据具有动态性强、覆盖范围广等诸多优势。在城市轨道交通领域,AFC 数据能有效记录乘客出行信息,可用于分析城市活动强度与时间分布[3]、不同城市区域的时空特征[4],以及地铁站点周边土地利用类别对地铁出行需求的影响[5]。
作为站点分类的主要考虑因素之一,客流特征受到广泛研究。Mahrsi 等[6]根据法国Rennes 地区站点进站客流分布,通过聚类方法将站点分为14 类,并分析了站点出行用户的流动性。Anne-sarah 等[7]提出了一种两层Gauss 混合模型,利用自动售检票(AFC)数据重新划分不同客流类型,以协助政府调整运营服务。站点特征、交通衔接特征等诸多因素也被用于站点分类。傅搏峰等[8]在站点交通功能与场所特征的基础上,考虑土地利用性质与景观优势度,对郊区轨道交通站点进行类别划分。金磊等[9]总结了国内外地铁车站分类的既有方法,并结合交通重要性与所处城市区位进行再分类。
然而,上述方法多基于实践经验,随着客流特征与城市环境的不断复杂化,难以满足实际需求,因此多种聚类算法被应用。陈艳艳等[10]根据北京市不同站点客流特征,提出利用K-means 聚类进行站点分类,并对比站点周边的用地性质。李向楠[11]根据11 种不同站点的自身特点和环境特征,利用主成分分析与K-means 聚类算法,将站点分为5 类。余丽洁等[12]利用快速聚类法及多种谱聚类法,分别对西安地铁2 号线站点进行分类,最终发现NJW 算法能准确反映识别。李子浩等[13]通过对工作日与假日的客流规律进行聚类,将工作日站点分为职住交错偏居住型、办公区域、职住交错偏办公型,周末分为居住区域、商业中心和交通枢纽型、办公区域,提出车站客流风险的分析方法。
上述研究通过分析客流等诸多特征,实现了对站点的分类。然而现有研究中,多数仅考虑站点客流特征,或者仅根据站点周围用地性质差异,尚未对站点全部特征进行定量分析。此外,现有研究多通过用地类型来定性确定分类数量,分类过程较为主观,削弱了研究的科学性。
基于此,笔者利用成都市多个工作日地铁AFC 数据,充分挖掘站点客流曲线的形态特征及客流的时间分布特征,然后采用EM 算法与Gauss 混合模型,根据站点客流特征,对成都市156 个地铁站点进行聚类研究,最后根据分类结果,分析不同站点客流特征与土地利用性质的关联。下面通过关联对比交通空间行为和实体空间特征,从管理者的角度提供对城市空间进行研究的新思路,分析城市功能的实际空间分布结构,为地铁运营管理及组织优化提供依据,引导地铁TOD 模式良好发展,为城市交通发展规划提供依据,促进实现城市结构的“职住平衡”。
2 算法描述
根据EM 算法与Gauss 混合模型,对地铁客流时序分布特征进行分析,并通过迭代计算误差平方和判断聚类数量,从而实现站点聚类。
2.1 Gauss 混合模型
Gauss混合模型(Gaussian mixture model)将目标曲线分解为k 个Gauss 概率密度函数,通过量化各模型参数以分析研究目标。由于不同站点的客流时序曲线存在差异化分布特性,其多样性导致单种函数无法直接对其进行量化。对此,将不同站点客流时序曲线作为目标曲线,利用Gauss 混合模型进行分析,其公式如下:


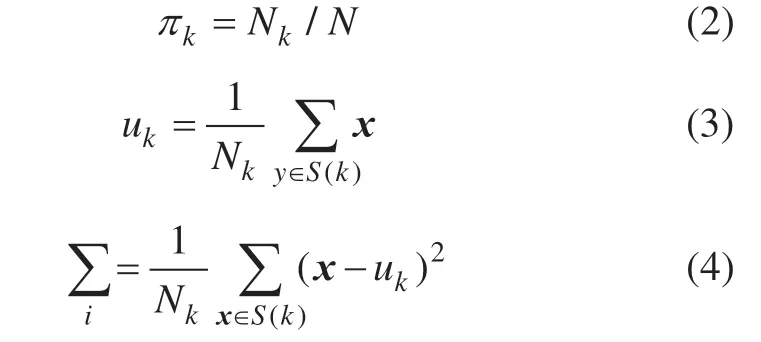
2.2 EM 算法使用
期望最大化算法通过估计观测数据与缺失数据值,迭代找寻目标的局部最优值。由于Gauss 混合模型均需要标定三类参数法直接确定,利用EM 算法,通过多次迭代实现参数标定,判断客流特征属于不同类别的概率。
n 个观测样本y=(y1,y2,…,yn)的极大化模型分布的对数似然函数如下:

式中:θ 为模型参数;z=(z1,z2,…,zm)是每个样本的隐含数据,zi即属于第i 个Gauss 概率密度函数的概率;Gauss 聚类数量m 由误差平方和确定。
根据Jensen 不等式,Qi(zi)是引入的分布,满足

最终,计算不同聚类数量下站点聚类结果的误差平方和,并综合考虑聚类数量与误差值,选择最合适的聚类数量,实现地铁站点聚类分析。
2.3 聚类变量选取
变量选取是影响聚类结果的重要因素,为准确描述地铁客流特征,针对成都市156 个地铁站点,根据地铁客流形态与结构,提取地铁客流极大值点数量、偏度、峰度、时间分布等10 类特征,进行站点聚类分析。
1) 极值点数量。各站点客流波峰数量可视为区分站点的标志之一,可通过地铁站点不同时刻的客流分布曲线得到。
2) 偏度。地铁站点存在早晚高峰,且分布不均匀,偏度是描述分布偏斜方向和程度的度量,能描述这种客流分布的差异。其中,偏度大于0 表示右偏,小于0 为左偏。
3) 峰度。不同站点的客流高峰存在差异,通勤客流较多的站点早晚高峰更为显著。峰度是描述这种分布陡缓程度的统计量,大于0 表示分布陡峭,小于0表示分布平坦。
4) 客流时间分布特征。由于地铁客流在全天不同时段上的分布具有差异性,利用高峰小时系数P 与客流时段分布均衡系数U 刻画客流的时间分布特征,有

式中,Qi表示站点第i 小时的客流量,Qd表示站点全天的客流量,H 为站点全天的平均客流量。表1 为站点聚类变量样例。

表1 站点聚类特征样例 Table 1 Samples of station characteristics for clustering
3 数据采集
本次研究选取成都地铁2019 年5 月共计21 个工作日、156 个站点的AFC 数据为研究对象,数据样例如表2 所示,字段包括进站刷卡时间、进站站点、出站刷卡时间、出站站点。
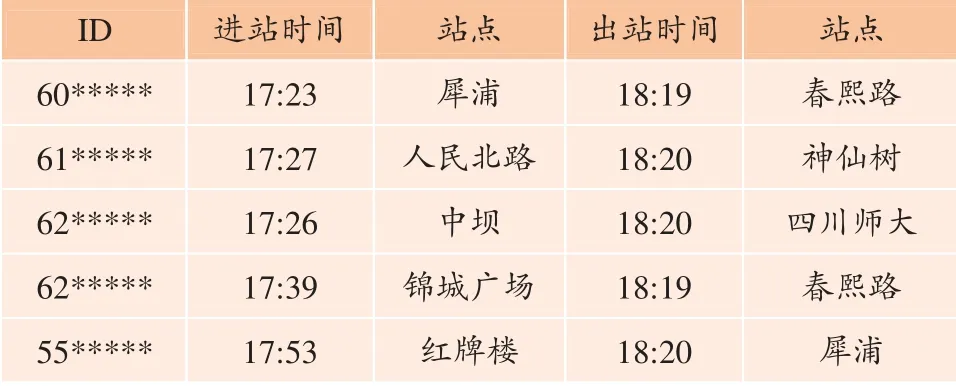
表2 成都地铁AFC 数据样例 Table 2 Sample of AFC data of Chengdu railway
完成数据采集后,将刷卡信息按时间进行汇总,获取不同站点全日18 h 的客流量。同时,为减少因其他因素所导致的客流波动,研究使用21 个工作日的平均客流量作为客流量数据值。最后,将不同点客流的极值点、偏度、峰度、客流时间特征、高峰小时系数等作为聚类的输入变量。为使不同量纲的原始数据能够具有可比性,利用Z-score 标准化对客流数据各列特征进行处理,保证原始数据各特征列的均值为0,标准差为1。
4 结果分析
4.1 聚类参数标定
肘部法则 (elbow method)是确定聚类数量的通用方法,通过计算不同聚类数量下的畸变程度(误差平方和),找寻最佳聚类数量。图1 为根据聚类簇数的误差平方和分布,随着聚类数量增多,分布曲线呈现快速下降,当聚类数量为7 时,出现畸变程度临界点,当聚类数量大于7 时,聚类数量趋于稳定。为保证聚类的有效性,聚类数量应相对较低,因此本研究将156 个站点分为7 类。

图1 误差平方和随聚类数量的变化 Figure 1 Sum of squares error as a function of the number of clusters
4.2 聚类结果分析
结合站点进出客流量小时分布曲线特征,7 类聚类站点被定义如下:居住导向型、就业导向型、职住错位型、错位偏居住型、错位偏就业型、交通枢纽型、综合型。不同类别的详细分类结果如表3 所示,其中错位偏居住型、职住错位型、错位偏就业型三类站点的数量最多,说明成都市存在显著的职住错位现象。

表3 EM 算法与Gauss 混合模型的聚类结果 Table 3 Result of EM algorithm and Gaussian mixture model
表4 为聚类结果的方差分析结果,其中F 值代表各变量的影响,重要程度依次为:出站高峰小时系数、进站偏度、进站高峰小时系数、出站偏度、出站峰度、进站峰度、进站客流时段分布均衡系数、出站分布均衡系数、进站极大值个数、出站极大值个数。
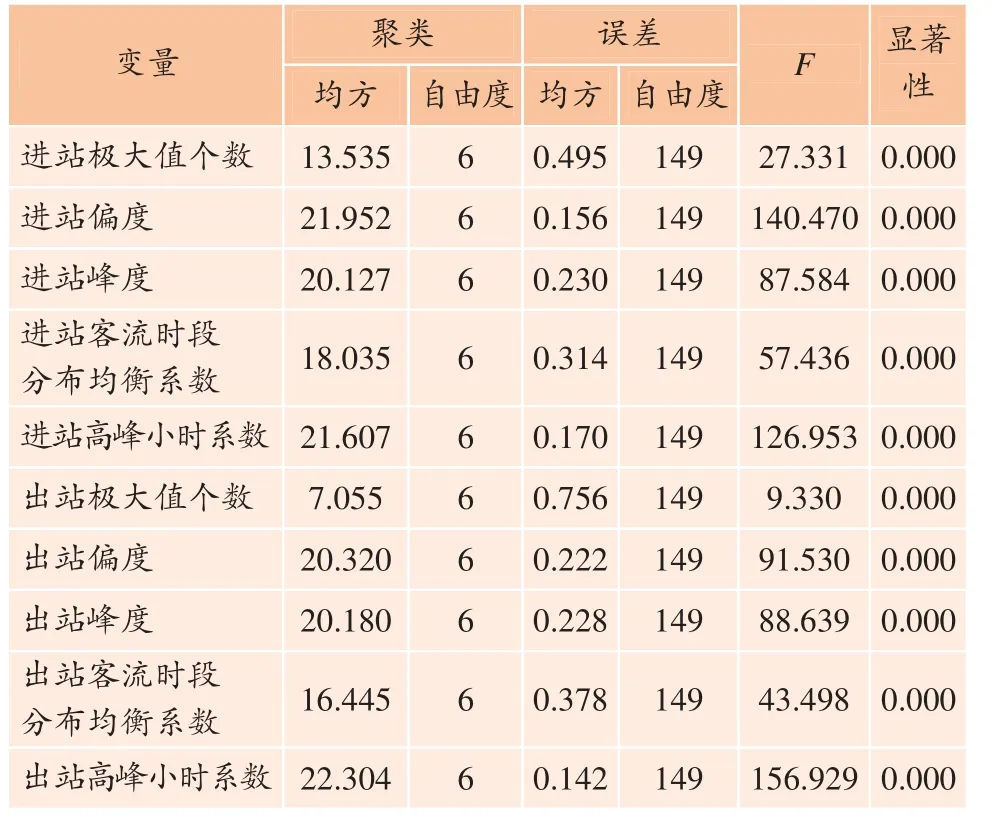
表4 EM 算法与Gauss 混合结果模型的方差分析 Table 4 Variance analysis of EM algorithm and Gaussian mixture model results
4.2.1 居住导向型站点
图2 为居住导向型站点的客流量时间分布曲线,各站点分布基本一致,具有显著的单峰特征。进站早高峰与出站晚高峰客流差异小,其中进站高峰位于8:00—9:00,出站高峰位于19:00—19:30。
居住导向型站点客流分布不均衡程度大,不均衡系数、高峰小时系数均最高。以五根松站、华阳站为例,地铁承载大部分在去往其他区域工作的客流,站点周边土地性质类型较单一,以居住属性为主,包含部分教育、绿地与医疗用地,基本没有办公用地,工作属性弱。
4.2.2 就业导向型站点
图3 为就业导向型站点的客流量时间分布曲线,各站点分布较为相似,高峰特征明显,其中进站分别存在8:00—9:30、18:00—19:30 的早晚高峰,出站存在9:00 附近的早高峰。
就业导向型站点与居住导向型站点相似,客流不均衡系数、高峰小时系数大,但进出站高分分布时段相反。以世纪城、天府三街为例,地铁承载大部分在此工作的客流,站点周边的工作属性强,基本不具备居住性质,包含大量的商业与工业用地,具有诸多办公区域与大型商业广场。
4.2.3 职住错位型站点
图4 为职住错位型站点的客流量时间分布曲线,各站点分布较为相似,进出站客流均具有明显的早晚高峰,高峰流量较为接近。进站高峰位于8:00—9:30、18:00— 19:30,出站高峰位于8:30—9:30、18:30—20:00,且各站点进站高峰呈现小范围波动,出站高峰更集中。
以三里坝、倪家桥为例,职住错位型站点相比居住、就业型站点,用地性质多样、用地分布相对均匀,包括居住、商业、绿地、医疗、教育等诸多用地。然而,该类站点附近居民的工作地点不在此处,同时附近工作人群也未在站点周围居住,职住分离显著。
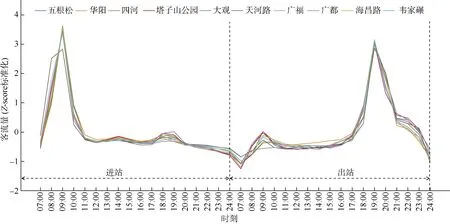
图2 居住导向型站点的客流量时间分布曲线 Figure 2 Time distribution curve of passenger flow in living-oriented stations
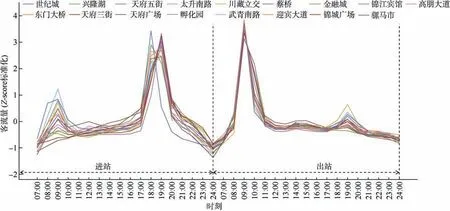
图3 就业导向型站点的客流量时间分布曲线 Figure 3 Time distribution curve of passenger flow in career-oriented stations

图4 职住错位型站点的客流量时间分布曲线 Figure 4 Time distribution curve of passenger flow in living-employment dislocation stations
4.2.4 错位偏居住型站点
图5 为错位偏居住型站点的客流量时间分布曲线,站点客流分布较为相似,有显著的进站客流早高峰、出站客流早晚高峰。进站高峰位于 8:00—9:30、18:00—19:30,出站高峰位于 9:00、19:30附近。
错位偏居住型是所含站点最多的类型,包含49个地铁站点,具有较大的客流分布非均衡系数与高峰小时系数。以一品天下、万年场为例,该类站点与职住错位型站点类似,周围用地性质较多,分布较为均匀,居住用地显著多于其他类型用地,造成进站晚高峰不显著,但仍存在一定的职住错位现象。
4.2.5 错位偏就业型站点
图6 为错位偏就业型站点的客流量时间分布曲线,与错位偏居住型站点客流相反,进站客流具有显著的早晚高峰,出站客流的晚高峰较低。相比上述几类站点,各站点客流分布相似度较低。进站高峰位于8:00—9:00、18:00—20:00,时间跨度长,出站高峰更集中,分别位于9:00、19:00 附近。
错位偏就业型站点同样具有较大的客流分布非均衡系数与高峰小时系数。以三瓦窑、市二医院为例,地铁承载较多到此地工作的乘客,形成出站早高峰与进站晚高峰。与职住错位型、错位偏居住型站点类似,具有较为多样的用地性质,且各类用地分布均匀,同时商业用地、工业用地显著多于其他类型,站点附近的工作性质更加多样化,存在职住错位现象。

图5 错位偏居住型站点的客流量时间分布曲线 Figure 5 Time distribution curve of passenger flow in partial living dislocation stations

图6 错位偏就业型站点的客流量时间分布曲线 Figure 6 Time distribution curve of passenger flow in partial employment dislocation stations
4.2.6 交通枢纽型站点
图7 为交通枢纽型站点的客流量时间分布曲线,出站客流分布基本一致,进站客流相似度较低,同时客流峰值偏低,没有显著的早晚高峰特征,进出站客流分别在18:00、9:00 左右达到最大值。
交通枢纽型站点主要承载前往综合交通枢纽的乘客,因此客流分布与枢纽运输班次显著相关。相比综合交通枢纽,该类站点附近的其他类型用地对客流作用不明显,客流非均衡系数最低。
4.2.7 综合型站点
图8 为综合型站点客流量分布时间曲线,相比其他站点,综合型客流分布差异较大,存在多个时间分布不规律的峰值,客流具有随机性。形态特征上,站点非均衡系数与高峰小时系数较低,客流分布较为均衡,客流量差异性较小;但该类站点进出站的极大值点最多,且偏度、峰度均值最小。以春熙路、宽窄巷子为例,这类站点周围的用地性质种类及分布最为均衡,医疗用地、绿地、商业用地及各种景点均较多。

图7 交通枢纽型站点客流量时间分布曲线 Figure 7 Time distribution curve of passenger flow in transportation junction stations

图8 综合型站点客流量时间分布曲线 Figure 8 Time distribution curve of passenger flow in synthesis stations
4.3 站点空间分布
图9 为不同类型地铁站点的空间分布结果。居住导向型站点主要分布在成都南部与东部的近郊区域,属于双流区与成华区,位于成都市“东进、南扩”规划发展的主要方向,城市建设迅速。就业导向型站点主要集中在以天府广场、金融城为中心的市中心与武侯区核心,区域配套设施完善,是成都市最主要的工作区域。错位型站点整体数量最多,空间分布最为广泛,大部分职住错位型站点位于2、3、4 号线的两端,少部分位于7 号线的环线附近,这体现了成都以往的单中心发展模式,造成较为严重的职住分离,大规模周边城区人口通勤出行距离较长。随着多中心城市规划目标的提出,职住分离的状况在后续将得到改善。错位偏居住型主要集中于成都地铁7 号线环线的东西两侧,呈现典型的环状结构,分布密集,集中于市中心周围;与错位偏就业型的占比相比,整体分布较为分散,位于二环与科学城附近,呈现中心偏南的分布,两种类型展现了成都市整体向南发展的特征。交通枢纽型与综合型客流受典型地标、景区的影响显著,诸如成都市各大医院,成都东客站与成都北站、机场等交通枢纽,以及宽窄巷子等著名景区。其他用地影响相对较低,整体分布规律不明显。

图9 不同地铁站点类型空间分布 Figure 9 Spatial distribution of different subway station types
5 结语
地铁作为城市交通主动脉,是调节交通结果的重要手段。准确识别车站类型,分析客流出行规律,对调整与优化线网运营,掌握站点周边土地开发,引导地铁TOD 模式发展有着重要的作用,可有效促进城市结构的“职住平衡”,为城市交通发展与规划提供支撑。笔者根据成都市21 个工作日地铁AFC 数据,基于客流曲线的极值、偏度、峰度及客流时间分布特征,利用肘部法则确定最优聚类数量,然后利用EM 算法与Gauss 混合模型,对成都市156 个地铁站点进行聚类分析,研究结果表明:
1) 为保证聚类合理性与有效性,误差平方和与聚类数量均应相对较低。本研究利用肘部法则,将成都市的156 个地铁车站分为7 种不同类型,包括居住导向型、就业导向型、职住错位型、错位偏居住型、错位偏就业型、交通枢纽型、综合型。
2) 本研究基于EM 算法与Gauss 混合模型分析客流特征,证实了客流时序曲线特征的分析方法,其中极值点、偏度、峰度、客流时间特征等能有效体现客流分布。
3) 从地铁站点类型的空间分布上来看,城市中心城区的区域功能齐全,站点类型多样;但城市外围站点的车站类型较为单一,并且多数为错位型站点,需要进一步优化职住空间。
4) 本研究为数据驱动城市规划提供了良好的范例。通过分析地铁客流数据,一方面直接把握居民出行的时空规律,为管理者快速、动态把握与调整线网运营提供依据,另一方面也侧面反映了成都城市功能的空间分布结构,为分析城市空间结构及演变提供全新的视角。
后续研究将引入更多元的特征值,添加与交通设施更紧密相关的信息,如站点周边土地利用性质、人口岗位等社会经济信息,以便更全面地分析不同城市区域的地铁站点差异,准确获取并对比城市区域板块的功能。同时,将结合非工作日的客流数据,更全面地识别出地铁站点的类型,分析地铁客流与站点功能在工作日和非工作日的变化。
猜你喜欢
制冷与空调(2022年2期)2022-06-01
现代电子技术(2021年15期)2021-08-06
数学大王·中高年级(2019年5期)2019-06-09
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
祖国(2018年6期)2018-06-27
阅读(科学探秘)(2018年8期)2018-05-14
新高考·高一数学(2016年3期)2016-05-19
新高考·高一数学(2016年3期)2016-05-19
新高考·高一数学(2016年3期)2016-05-19
