
基于改进Xception网络的手势识别
2022-06-28 02:55周梓豪田秋红
软件导刊 2022年6期
周梓豪,田秋红
(浙江理工大学信息学院,浙江杭州 310018)
0 引言
人类通过手掌和手指的不同姿势组合形成的具有特定含义的表达方式称为手势。手势识别是人机交互领域的研究热点,相关技术广泛应用于智能家居、自动驾驶、医疗保健和虚拟现实等领域,给人们的生活带来极大便利,应用价值不言而喻。手势作为人与人之间日常交流的重要方式,更是聋哑人交流的最主要方式,蕴含着丰富的信息。如果手势识别技术更加完善,现实生活中应用更加广泛,聋哑人便能更加轻松舒适地融入社会。因此,手势识别技术研究具有重要的现实意义。
1 相关研究
传统手势识别方法主要分为两类:一类是基于硬件设备的方法,例如Kim 等[1]使用由3 轴加速度计、磁力计和陀螺仪组成的手套采集到的数据进行三维建模并输出到显示器,对1~9 之间的数字识别准确率可达99%以上,但数据手套操作复杂、价格昂贵,普及性较差;另一类是基于机器视觉的方法,例如Tian 等[2]设计了一种基于图像处理的静态单反系统分割方法,并将其与形态重建相结合,可从复杂背景中分割手势图像;李文生等[3]提出一种高效的基于HSV 颜色空间的多目标检测跟踪方法,可准确进行动态多点手势识别。然而机器视觉方法普遍存在的问题是提取到的特征容易受到背景因素干扰,且处理速度较慢。
以上两类方法需要人工设计手势提取算法,可能会产生主观性和局部性等问题。卷积神经网络(Convolutional Neural Networks,CNN)能够自动提取手势的轮廓、肤色、纹理等深度特征,并且具有检测速度快、抗干扰能力强和识别准确率高等优点,因此在手势识别领域逐渐成为主流。许多学者通过重新设计主干网络,融合多尺度特征和残差连接等方法对经典CNN 进行改进,在提高识别准确率方面取得较多进展。例如,余圣新等[4]使用深度可分离卷积改进Inception 网络,并结合残差网络以防止梯度弥散,在MNIST 手写数字数据集上达到99.45%的识别准确率;周鹏等[5]基于语谱图对DenseNet 卷积网络进行改进,识别准确率明显提高;王龙等[6]结合肤色模型和CNN 对不同背景下的手势图像进行识别,取得了较高的识别准确率和较好的实时性;熊才华等[7]基于ResNet50 残差网络对Fast R-CNN 网络进行改进,并融合实例批处理标准化方法以适应不同的识别环境,对手势的识别效果和鲁棒性均有所改善;陈影柔等[8]提出一种基于多特征加权融合的静态手势识别方法,对手势图像数据集的识别准确率达到99%以上;包嘉欣等[9]通过椭圆分割、最大连通域和质心定位的方式提取出类肤色背景中的手势,并通过改进VGG 网络减少模型参数量,有效提高了手势图像的识别率;官巍等[10]将Fast R-CNN 替换为ResNet50,利用区域建议网络生成的候选框和特征图进行兴趣区操作,修改激活函数并进行参数调节,对手势的识别率高达97.57%;冯家文等[11]提出双通道CNN 模型,对两个相互独立通道输入的手势图像进行特征提取,融合不同尺度的特征,增强了模型的泛化性。以上改进CNN 网络取得了较高的识别准确率,但仍存在参数量巨大的问题。事实上,大部分CNN 难以兼顾识别准确率与参数量之间的平衡,庞大的网络结构和巨大的参数量满足不了其在资源受限的嵌入式和移动端环境中进行实时检测的要求。
针对CNN 存在的问题,参考林景栋等[12]提出的CNN结构优化技术,从平衡识别准确率和模型大小的角度出发,提出一种基于改进Xception 网络的手势识别方法。改进部分如下:使用密集连接代替残差连接,对深度可分离卷积模块进行密集连接,压缩网络深度,从而更加有效地利用模型参数,有效提高识别准确率;融合SE 模块,增强模型对重要特征的敏感度,同时抑制次要特征的作用;融合特征金字塔结构,通过对特征张量中不同感受野的使用对手势图像进行分类,进一步提高识别准确率。
2 网络结构
2.1 Xception网络结构
Xception 网络[13]是在InceptionV3 网络的基础上结合MobileNet 和ResNet 提出的CNN,该网络使用深度可分离卷积将特征张量中的空间相关性与跨通道相关性完全解耦,相较于Inception 能更充分地发挥网络参数的作用。Xception 网络结构如图1 所示,其具有36 个卷积层,分别为1 个降采样卷积层、1 个常规卷积层和34 个深度可分离卷积层;共分成14 个模块,最大通道数达到2 048 个,使得Xception 网络结构较深,参数计算量大,模型占用内存较大,不适合部署在移动端和嵌入式设备中进行实时检测。同时,Xception 网络缺少多尺度特征的融合,在特征提取过程中可能会由于感受野单一而造成特征损失。
2.2 密集深度可分离卷积模块
现有经典网络一般通过增加网络层数提升识别准确率。Xception 网络包含36 个卷积层,虽然深度可分离卷积模块的计算量相较于常规卷积模块已经缩小,但模型大小和计算参数量仍然较大,无法满足在移动端上进行实时检测的要求。因此,本文利用DenseNet 密集连接网络[14]的思想,对深度可分离卷积模块进行密集连接,通过将当前模块的输出特征张量作为其所有后续模块的输入,使各层之间直接相连,最大程度确保最大化层际的信息流动,从而形成密集深度可分离卷积模块。该模块是改进Xception网络的基本模块,结构示意见图2。密集深度可分离卷积模块的输出可表示为:
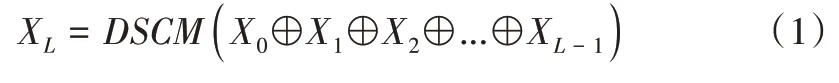

Fig.1 Xception network structure图1 Xception网络结构
式(1)和图2 中的X0均代表输入密集深度可分离卷积模块的特征张量,XL代表第L个深度可分离卷积模块的输出,DSCM(*)代表深度可分离卷积模块,⊕代表通道叠加操作。如图2 所示,第L个深度可分离卷积模块的输出由模块内位于其前继的所有特征张量通道叠加后再经深度可分离卷积模块解耦得到。
改进Xception 网络使用的密集深度可分离卷积模块有2 种,一种由3 个深度可分离卷积模块密集连接组成,另一种由2 个深度可分离卷积模块密集连接组成。密集连接结构可使特征得到再利用,同时通过适当增加层内通道数可更加充分地发挥网络参数的作用,在保证网络提取到更多手势信息的同时有效减小模型深度,以抑制过拟合现象。
2.3 基本卷积模块
2.3.1 降采样卷积模块和常规卷积模块
原始手势图像需归一化为224 × 224 × 3 大小的RGB图像,再进行标准化。将原始手势图像从0~255 之间的整数映射为0~1 之间的浮点数作为神经网络的输入,首先将其输入至降采样卷积模块,然后输入常规卷积模块中进行特征图像处理。这两种卷积模块结构相同,均由卷积层、批量归一化层和RELU 激活层依次连接组成,可表示为:
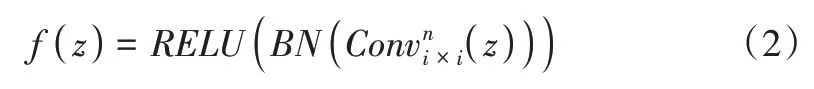
式中,z代表输入模块的特征张量,代表卷积核个数为n、步长为i×i的常规卷积函数,BN(*)代表批量归一化操作,RELU(*)代表RELU 激活函数。
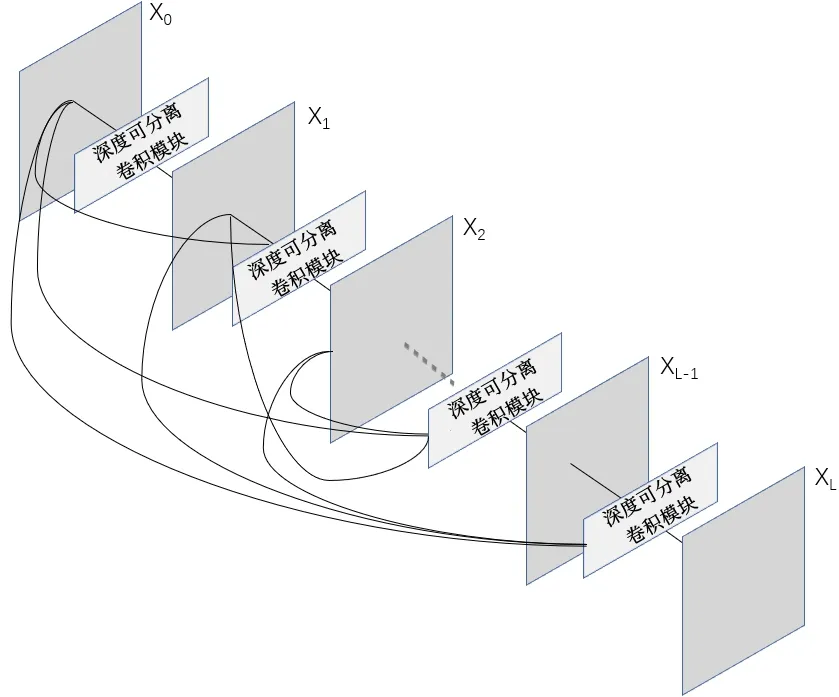
Fig.2 Dense depthwise separable convolution module structure图2 密集深度可分离卷积模块结构
在改进网络中,两种卷积模块的卷积核尺寸均为3 ×3,但卷积操作步长以及卷积核个数不同。步长为2 × 2 的卷积操作能够代替池化层进行降采样处理,增加模型的感受野。输出通道数为32 的缩小尺寸的特征张量,然后使用步长为1 × 1 的常规卷积整合空间特征和跨通道特征,并使用64个卷积核扩大通道数量,初步提取浅层特征。
2.3.2 深度可分离卷积模块
浅层特征张量通过一系列由深度可分离卷积模块组成的模块进行空间相关性与跨通道相关性之间映射的完全解耦。深度可分离卷积模块由RELU 激活层、深度可分离卷积层和批量归一化层组成。本文网络使用如图3 所示的2 种深度可分离卷积模块,二者的差异在于RELU 激活层的位置,密集深度可分离卷积模块由(a)类深度可分离卷积模块组成,靠近网络输出的为(b)类深度可分离卷积模块,RELU 激活层放在最后有助于图像分类。
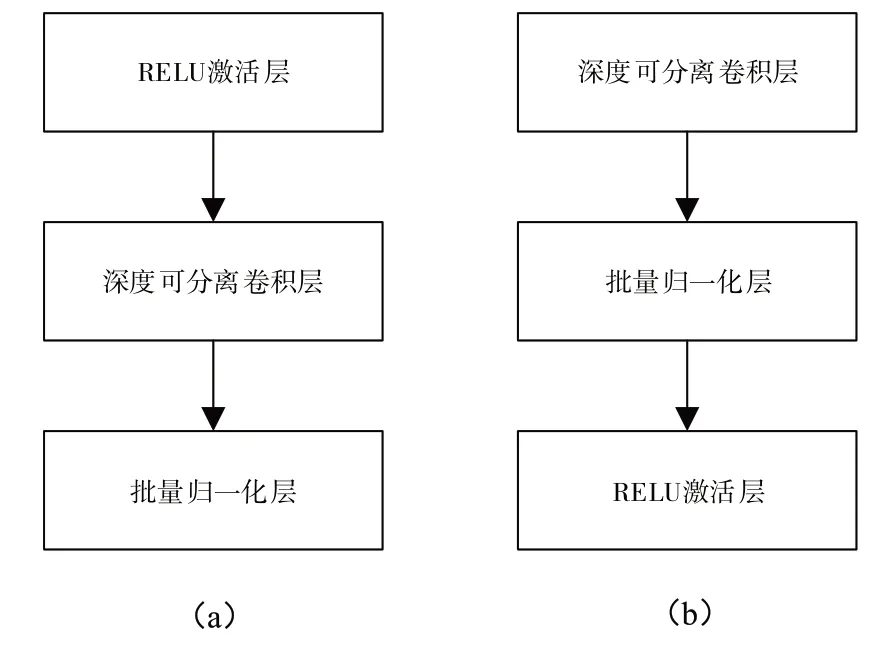
Fig.3 Depthwise separable convolution module structure图3 深度可分离卷积模块结构
本文网络使用的均为步长为1 × 1,卷积核尺寸为3 ×3 的深度可分离卷积层。与常规卷积相比,逐一对通道进行卷积操作能降低计算冗余度。例如使用K个尺寸为3 ×3 的卷积核对1 个尺寸为W×H×C的特征张量进行卷积操作,然后输出尺寸为W×H×K的特征张量。如果使用常规卷积进行操作,则参数量为C×K× 3 × 3;而使用深度可分离卷积进行操作,点卷积的参数量为C×K,深度卷积的参数量为K× 3 × 3,总计算量为K×(C+9),当K和C较大时,计算参数量能大大减少。
2.4 SE模块
注意力机制的合理使用对于提高CNN 的性能具有重要作用。SE 模块是注意力机制的一种,其思路简单、易于实现,同时很容易被嵌入到当前主流网络模型中[15]。SE模块可分为3 个部分,分别为压缩模块fsq、激励模块fex和重标定模块fscale,3个模块可分别由以下公式表示:

式中,GAP(*)代表全局平均池化函数,x代表压缩模块获得的全局描述,W(*)代表全连接函数,δ(*)代表RELU激活函数,σ(*)代表Sigmoid 激活函数,d代表激励模块获得的各通道权重。
改进网络中SE 模块的融合位置与结构如图4 所示。融合位置位于模块间的局部最大池化层之前,输入尺寸为H×W×C的特征张量,经过全局平均池化层得到每个通道的全局描述,尺寸为1 × 1 ×C。通过两个全连接层建模通道间的相关性,首先对通道进行降维,数量减少至输入的1/16,通过RELU 函数进行非线性激活;然后通过全连接层升维,恢复到原来的通道数量,使用Sigmoid 激活函数返回对应于每个通道0~1 之间的权重值;最后通过逐像素相乘操作将权重值加权至每个通道上。
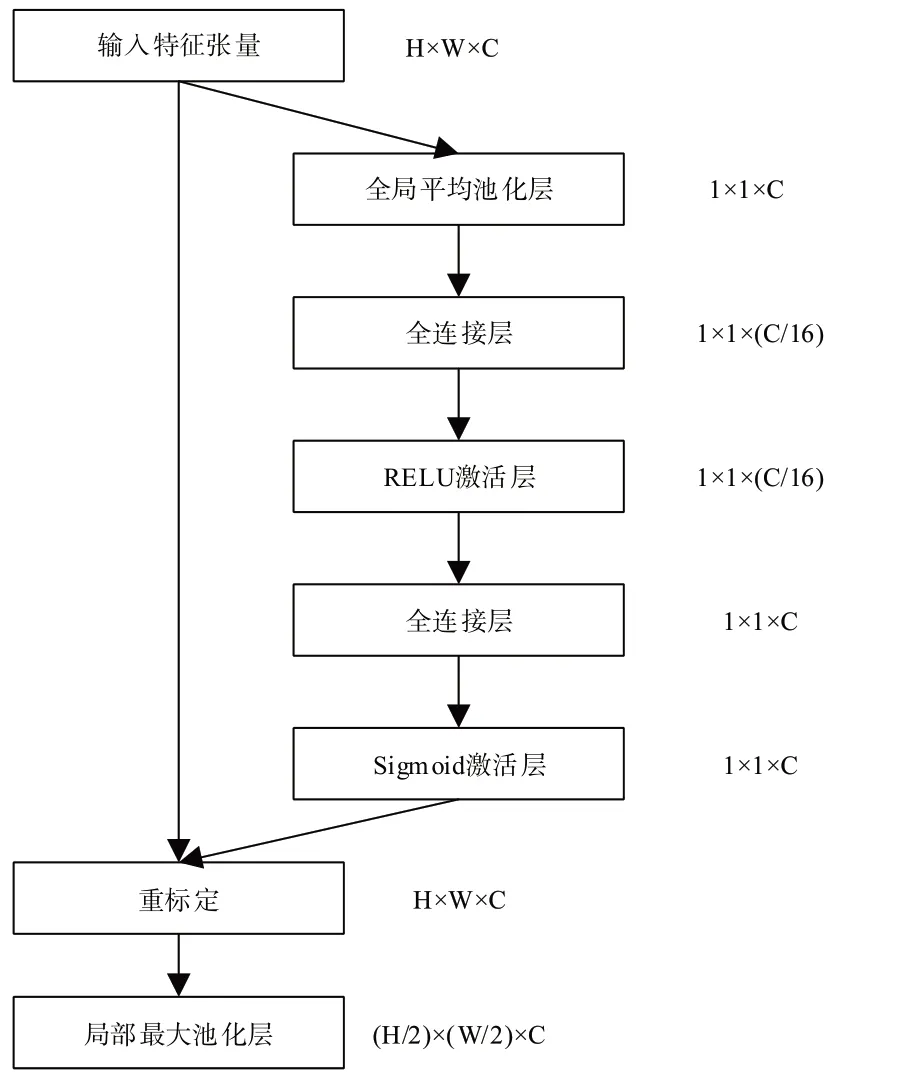
Fig.4 SE module fusion position and structure图4 SE模块融合位置与结构
2.5 改进Xception网络结构

Fig.5 Improved Xception network structure图5 改进Xception网络结构
Xception 网络结构较深,多次进行深度可分离卷积以及残差连接导致其计算参数量巨大,难以应用到移动端上进行实时监测;且Xception 网络缺乏融合多尺度特征,可能受限于单一感受野而损失提取特征,导致准确率无法继续提高。本文针对这些问题,对图1 所示的Xception 网络结构进行改进,改进后的网络结构如图5 所示。改进的地方如下:①将图1 所有的残差连接替换为密集连接,实现像残差连接一样的跳跃连接,能在密集压缩网络深度的同时提高识别准确率,可以减少深度可分离卷积模块数量与通道数,因此改进网络适当调节了卷积通道数量并消除了图1 结构中的中间部分;②将Xception 网络结构中部分由2个深度可分离卷积模块组成的模块替换为由3 个深度可分离卷积模块组成的模块,这是由于在密集连接中增加深度可分离卷积模块数量有助于产生更多直接信息流动,有利于提高识别准确率;③如图5 所示,将SE 模块融入网络结构中,在局部最大池化操作之前对特征张量进行特征重标定,提高网络对重要特征的敏感程度;④如图5 所示,在接近网络的输出部分对特征金字塔结构进行融合,通过逐点卷积层将第2 个SE 模块和局部最大池化层的输出通道数提升至728,作为第一融合特征张量;通过上采样层将第4 个密集深度可分离卷积模块的输出特征张量尺寸修改为28 × 28 × 728,作为第二融合特征张量。两个融合特征张量经过逐像素相加操作,获取到融合浅层、深层空间信息以及特征语义信息的特征张量用于图像分类。改进Xcep⁃tion 网络的配置见表1。

Table 1 Improved Xception network configuration表1 改进Xception网络配置
3 实验方法与结果分析
3.1 数据集与实验环境
本实验采用NUS-Ⅱ(National University of Singapore)开源手势数据集[16-17],共有2 750 张RGB 图像,包含10 类手势,分别代表字母A~J,每个类别有275 幅图像,由40 名不同种族22~56 岁的男性和女性在多种复杂背景下拍摄完成,且背景存在类肤色因素的干扰,数据集示例如图6所示。将该数据集按照7∶2∶1 的比例随机划分为训练集、测试集和验证集,并使用随机旋转、平移等实时数据增强方式避免过拟合。
模型训练环境为13GB 内存,NVIDIA Tesla P100 PCIE 16GB 显卡,初始学习率设置为0.001,最大迭代周期(Ep⁃och)设置为40,批处理大小(Batch Size)设置为16,并通过回调函数在训练过程中对学习率进行优化,以便更加快速地获得最优模型。回调函数监测的值为验证集准确率,当3 个迭代周期结束而验证集准确率没有提升时,则将学习率缩小为原来的一半。

Fig.6 NUS-Ⅱdataset example图6 NUS-Ⅱ数据集示例
3.2 实验结果分析
3.2.1 不同模块性能比较
为了验证改进Xception 网络各个模块的性能,在改进网络的基础上,对密集深度可分离卷积模块、SE 模块和特征金字塔结构进行消融比较实验,结果见表2。可以看出,当融合所有模块时,相较于Xception 网络,计算参数量大幅度减少,识别准确率提升了1.09%,参数量减少了4/5。同时,对于每一个单独模块的改进均使准确率有0.54%~0.72%的提升,且参数量大幅度减少。
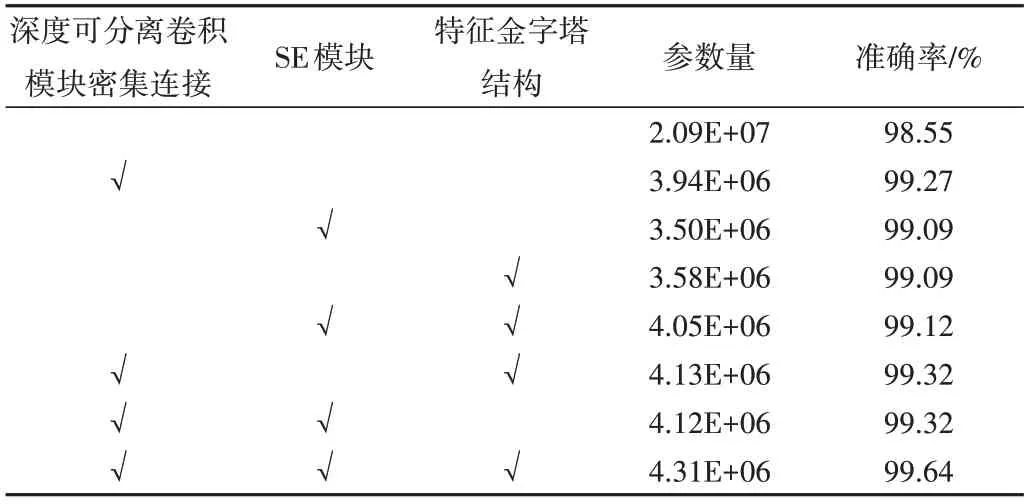
Table 2 Ablation comparison experiment result表2 消融比较实验结果
3.2.2 网络训练优化器比较
神经网络中的优化器可通过适当方法修改权重和学习率以达到最小化损失的目的,优化器的选择需要考虑准确率与训练时间之间的平衡。本实验分别在Adam、RM⁃Sprop 和Nadam 优化器下训练改进Xception 网络,比较这3种优化器下网络的验证集准确率曲线变化情况,结果如图7 所示。可以看出,使用Nadam 优化器进行网络训练的收敛速度最快,且波动程度最小;RMSprop 优化器训练前期波动比Nadam 大,训练后期逐渐趋于稳定,准确率甚至超过Nadam;Adam 优化器训练前期收敛速度较慢,训练后期仍然存在少许波动。使用Adam、RMSprop 和Nadam 优化器训练的网络在验证集上的准确率分别为99.45%、99.7%和99.64%,为兼顾训练时间与准确率的平衡,最终选择Nadam 作为改进Xception 网络的训练优化器。
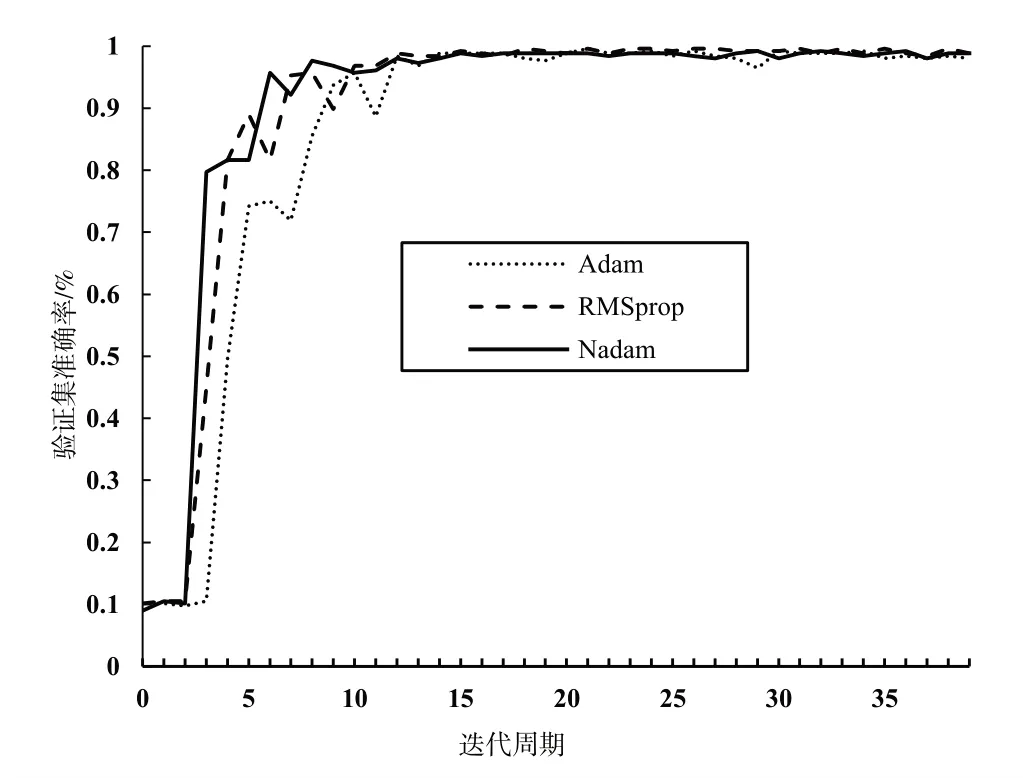
Fig.7 Comparison of validation set accuracy curves of different opti⁃mizers图7 不同优化器验证集准确率曲线比较
3.2.3 改进网络与其他网络比较
为了验证本文网络的可行性,在NUS-Ⅱ手势数据集上将其与原始Xception、ResNet50[18]、InceptionV3[19]和In⁃ceptionResNetV2[20]等经典CNN,以及MobileNet[21]和DenseNet121[22]等轻量级CNN 进行比较,综合考虑网络的训练时间、模型大小、模型参数量和测试集准确率评价其性能,结果见表3。

Table 3 Performance comparison results of different networks表3 不同网络性能比较
可以看出,ResNet50 的训练时间比本文网络减少了224s,但在模型大小、模型参数量和识别准确率方面,本文网络均远优于ResNet50。由于ResNet50 存在许多卷积层和残差连接,其模型大小和参数量均较大,而本文网络使用密集深度可分离卷积模块作为基本模块,模型大小仅为54.19MB,约为ResNet50 的1/5,参数量亦约为ResNet50 的1/5,但识别准确率比ResNet50 提高了2.73%。InceptionV3使用多尺度卷积、非对称卷积等代替常规卷积,能够在减少计算量的同时提升识别准确率,但InceptionV3 属于非常深的卷积网络,其训练时间在所有网络中最长,本文网络在各方面都表现出比InceptionV3 更好的性能。Inception⁃ResNetV2 综合了Inception 的多尺度卷积模块以及ResNet的残差连接两部分优点,获得了很高的识别准确率,与本文网络一样达到99.64%,但训练时间较长,网络深度十分大,模型大小达到673.27MB,参数量较多。DenseNet121 使用多个密集块稠密连接,比传统的级联连接效率更高,同时在瓶颈层和过渡层中压缩通道数,使得网络参数规模减小,但其在使用常规卷积的同时提取了空间和跨通道相关特征,比使用深度可分离卷积增加了计算参数冗余,且网络中缺乏不同尺度特征张量的融合,使识别准确率受到限制。因此,DenseNet121 的训练时间虽略短于本文网络,但综合模型大小、模型参数量和识别准确率来看,其性能逊于本文网络。MobileNet 同样使用了深度可分离卷积,结构简单,具有良好的实时性,其训练时间、模型大小和模型参数量在所有模型中均达到最优水平,但该网络的识别准确率仅为90.36%,在一些高精度分类任务中可能达不到要求。
部分网络在训练过程中的验证集准确率曲线如图8所示。可以看出,本文网络虽然存在密集连接,导致训练时间略微增加,但收敛速度较快,可以利用提前停止的方法在网络已经收敛时获得模型,抵消一部分影响。本文网络约在12 个Epochs 后验证集准确率曲线趋于稳定;Incep⁃tionResNetV2 收敛速度也较快,约在14 个Epochs 后准确率曲线达到收敛状态;其他网络则在15~30 个Epochs 后曲线才趋于稳定。

Fig.8 Comparison of accuracy curves of validation sets of some net⁃works图8 部分网络验证集准确率曲线比较
本文网络在识别准确率和收敛速度上与Inception⁃ResNetV2 网络相当,为了更加充分地比较两个网络的优缺点,以在NUS-Ⅱ手势数据集上的训练和测试结果为依据,单独列出训练时间、模型大小、每秒传输帧数(Frames Per Second,FPS)和收敛速度等进行比较分析,结果见表4。综合多方面因素可知,本文网络性能优于Inception⁃ResNetV2网络。

Table 4 Detailed comparison between InceptionResNetV2 network and the proposed network表4 本文网络与InceptionResNetV2网络详细比较
为了充分验证本文网络的泛化能力和鲁棒性,选择Xception、InceptionV3、MobileNet、ZFNet[23]作为对照网络,使用开源的Sign Language for Numbers 手势数据集[20]进行验证实验。该数据集共有11 种不同分类,其中包括10 种手势类别,代表数字0 到9;1 种非手势类别,代表非数字手势图像。每种类别各有1 500 张灰色图像,共有16 500 张灰色图像,按照7∶2∶1 的比例随机分为训练集、测试集和验证集。数据集示例见图9,比较实验结果见表5。由于Sign Language for Numbers 手势数据集中的背景比NUS-Ⅱ数据集简单,类肤色背景因素干扰也较少,本文网络识别准确率最高。
4 结语

Fig.9 Sign Language for Numbers dataset example图9 Sign Language for Numbers 数据集示例

Table 5 Results of the recognition accuracy of different networks on Sign Language for Numbers dataset表5 不同网络对Sign Language for Numbers 数据集识别准确率比较
本文提出一种基于改进Xception 网络的手势识别方法,通过深度可分离卷积模块的密集连接,在减少计算参数量的同时更加充分利用模型参数;通过SE 模块建模通道之间的相关性,重标定各个通道的重要性;融合特征金字塔结构,输出同时包含浅层和深层语义的特征张量用于分类;使用数据实时增强、动态学习率更新等方法优化网络训练。实验结果表明,本文网络能够适应多种复杂背景因素干扰下的手势识别任务,在参数量较少的同时达到良好的识别准确率,兼顾了训练时间、模型大小、模型参数量和识别准确率之间的平衡。由于本文网络是对Xception网络进行改进的小型网络,后续将在保证准确率的同时通过模型剪枝等方法对其进行压缩,以提高训练和检测速度,并尝试将其应用于移动端进行手势识别。
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
数学物理学报(2021年1期)2021-03-29
五邑大学学报(自然科学版)(2020年4期)2020-12-09
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
中国交通信息化(2018年5期)2018-08-21
山西大同大学学报(自然科学版)(2016年2期)2016-12-12
河南科技(2014年19期)2014-02-27
