
基于EMPI心肌病专病数据库的构建
2022-06-27 06:45尚诗袁骏毅岑星星
中国医疗设备 2022年6期
尚诗,袁骏毅,岑星星
上海交通大学附属胸科医院 信息中心,上海 200030
引言
心肌病是一组异质性心肌疾病,严重的心肌病会引起心血管性死亡或进展性心力衰竭。随着人们生活条件的提高,饮食结构发生变化,加上多数人缺乏锻炼,造成心肌病发病率呈逐年上升趋势,及早确诊和预防显得尤为重要。规范治疗过程、评定病情程度、指导急性心肌梗死患者治疗和用药等有效措施的实现,离不开对大量相关临床数据的研究和探讨[1]。医疗行业以惊人的速度生产和收集数据,但不同的电子健康记录以不同的结构收集数据,包括结构化数据、非结构化和半结构化数据,使得医生做回顾性研究时费时费力[2]。Kruse等[3]指出,利用大数据进行专病研究的分析和挖掘,有助于提高对疾病机制的理解,实现个性化医疗保健。本文以上海市胸科医院为研究背景,心肌病专病数据库(简称专病库)为研究对象,明确结构化模板和数据标准,分析数据的入库来源和管理方式,使得医疗数据被进一步深度利用,为心肌病临床研究提供支持。
1 建设过程
上海市胸科医院是集医疗、科研、教学为一体的三级甲等专科医院,拥有海量的医疗数据,但分散在不同的业务系统中,并且部分数据以文本的形式进行存储,使得大量的医疗数据无法满足科研需求。专病库建立的目的是:① 将分散在不同系统的数据整合为一个逻辑完整的信息整体,实现跨系统、跨业务的协同[4];② 将文本数据结构化,满足医疗相关人员的需要。
1.1 设计前期
采取讨论的方式,对临床医学、流行病与卫生统计学、信息技术等多学科专家针对数据集来源和结构化模板进行需求调研。
1.2 设计过程
专病库设计过程中参照相关标准,保证数据的可用性和可靠性,设计过程中参考了国际疾病分类ICD-10、手术与操作分类ICD-9-CM-3、HL7ChinaCDA、国家标准(如行政区域代码)、院内标准(如科室代码)以及心肌病相应的字典表(如肥厚型心肌病室间隔消融治疗方式)等规范[5]。
1.3 数据集确认
明确数据来源,字段集来源于超声系统、电子医嘱系统、随访系统等18个院内业务系统,涉及门诊病历、检查报告、出院小结等19个医疗记录单,确保数据的可靠性。
1.4 专病库形成
心肌病专病库具体设计形式为“模块-子模块-字段”三级数据结构,共分为患者人口学信息、就诊记录、病例信息、检查、病理、医嘱、诊断、治疗、不良事件和随访10个模块,下设33个子模块,共包含362个数据字段,每个字段对于数据类型、数据长度和可否为空等均有相应的设定,以保证数据集的标准化和可溯性[6]。专病库字段集来源于超声系统、电子医嘱系统、随访系统等18个院内业务系统,涉及门诊病历、检查报告、出院小结等19个医疗记录单。数据集结构如图1所示。
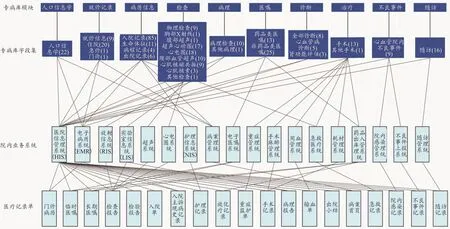
图1 数据集来源架构分析
2 系统架构
将原始数据形成医院临床数据中心(Clinical Data Repository,CDR),在此基础上通过后结构化、数据脱敏等治理过程,形成专病库的数据集。专病库采用微服务结构的分布式网络架构[7],使得原有的单个业务系统拆分为多个可以独立部署、设计、运行的组件,组件之间通过服务完成交互和集成[8]。相比于面向服务体系结构的分布式网络架构,微服务在围绕服务的概念创建架构方面提供了更清晰、定义更良好的方式[9]。在CDR的基础上利用数据治理、数据质控建立了符合疾病特点和科研需求的专病库,专病库系统架构图如图2所示。

图2 专病库系统架构图
(1)CDR架构。主要包括两项:① 通过编码映射、信息整合等操作将医院信息系统(Hospital Information System,HIS)、 放 射 信 息 系 统(Radiology Information System,RIS)等院内业务系统产生的数据和测序平台等产生的实验数据进行汇总统编,打破数据壁垒,实现信息互联互通;② 将数据集进行过滤抽取,确定心肌病病种数据集定义范围。
(2)数据治理过程中利用自然语言处理(Natural Language Processing,NLP)、基于转换器的双向编码表征(Bidirectional Encoder Representations from Transformers,BERT)的条件随机场(Conditional Random Fields,CRF)模型等机器学习方法实现对文本数据的后结构化处理。结构化的数据以患者主索引(Enterprise Main Patient Index,EMPI)为唯一标识进行数据关联,通过建立脱敏算法中间映射表进行去隐私化和加密处理,得到标准化数据集。
(3)数据质控是对数据的真实性、准确性、完整性、关联性、一致性进行管理。以EMPI为监测主线,六西格玛改进模型改善监测管理流程[10],定期生成质量监测报告。
(4)将通过质控管理的数据正式入库,形成由人口信息学、就诊记录、病历信息等10个模块组成的心肌病专病库。
(5)应用层分为数据挖掘、科研管理、科研项目执行、智能预测4个方面。为便于科研人员和医生后续操作,数据可选择以SAS、SPSS形式导出[11],接口采用WebService格式封装,符合微服务的封装形式,可实现异构的程序相互访问。
3 数据分析
3.1 数据治理
专病库的数据治理过程包括CDR建设、后结构化处理、数据关联和数据脱敏4个方面。
(1)CDR建设。院内于2018年完成了CDR的建设,以行业标准疾病代码、药品字典为映射集合,通过数据清洗、设立统一编码和编码映射等处理进行信息汇集,达到信息互联互通、数据标准化的目的。
(2)后结构化处理。对于非结构化或半结构化的数据,后结构化处理决定了医疗文本数据的可利用率和准确性[12],通过对病历、病理等文本数据预处理、序列标注完成前期准备工作,采用BERT预训练的词嵌入手段,以Bi-长短期记忆网络-CRF模型作为基准特征提取模型,结果显示多个实体标签的预测准确率和召回率达到1,且“症状”这一相对其他实体类型较为复杂的命名实体取得了87.16%的准确率和72.50%的召回率,后结构化处理过程如图3所示。相比于其他NLP算法,BERT模型是将预训练模型和下游任务模型结合在一起,即在进行下游任务时仍然用BERT模型,而且BERT模型天然支持文本分类任务,在做文本分类任务时不需要对模型做修改[13]。
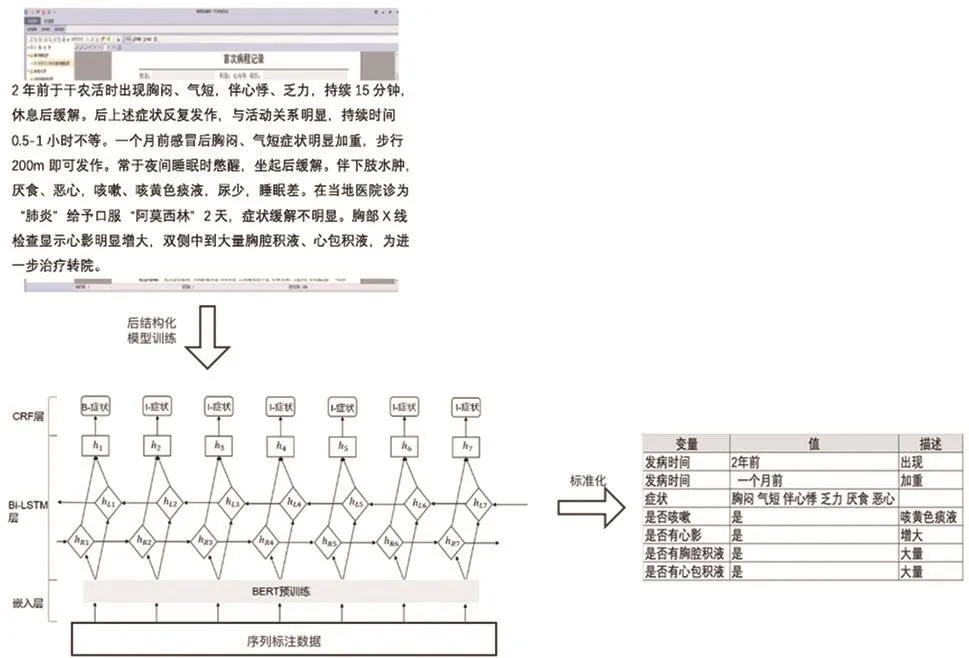
图3 后结构化处理过程图
(3)数据关联。由于院内业务系统中各编码更新时间不同,出现一对多或多对一的场景,如同一药品名称对应一个院内代码但对应两个医保编码,需要进行数据关联,将数据进行归一化处理,根据时间顺序和其他逻辑合并,通过计算信息增益的方式决定处理方向。
(4)数据脱敏。由于医疗数据涉及患者隐私,入库前需进行数据脱敏处理,数据脱敏是指将数据中较敏感的信息做进一步变形、转换和混淆的漂白处理,从而达到保护患者隐私的目的,保证隐私信息的安全性和可靠性[14]。2020年,国内制定了《中华人民共和国个人信息保护法(草案)》,强调隐私信息保护的重要性。为更好地保留复杂语义下高敏感度的属性值,采用对敏感属性值进行分类加权后,使用DES对称加密算法实现数据脱敏,脱敏后以EMPI或患者在医院就诊的身份号为关联字段。
3.2 数据整合
随着医院信息化的进一步发展,对于医疗信息互联互通的要求随之提高,院内业务系统中建立患者身份的唯一标识显得尤为重要。EMPI是指采用微软特有算法和技术在信息系统中表达患者身份的唯一识别,是医疗数据可以共享的基础。唯一标识的建立过程为:① 每个患者创建一个唯一标识符,作为各业务系统进行信息传递时的标志;② 与相关系统医疗记录的标识之间建立映射,确保同一患者分散在不同系统中的医疗信息可以完整且准确地关联、整合在一起。EMPI架构如图4所示。此外,EMPI还提供了搜索引擎,可以智能地协助医务人员对患者进行有效搜索;同时,也会存储患者属性的部分子集,以便作为患者检索“单一最佳纪录”的权威来源。EMPI的关键组件是匹配引擎,通常配置的属性包括姓名、生日、性别、身份证号和地址等,匹配引擎的准确性和性能是决定EMPI解决方案价值的关键因素。
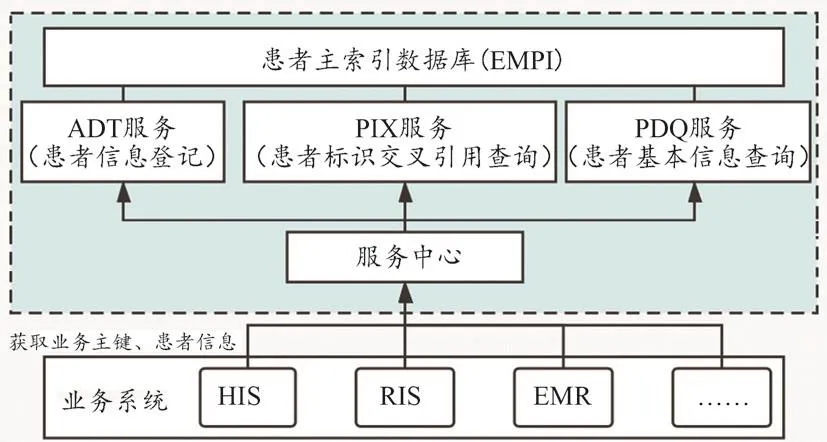
图4 EMPI架构图
3.3 数据质控
质量控制是对数据的真实性、准确性、完整性、关联性和一致性进行管理,决定了专病库的可用性和可靠性。由于源数据或数据拉取的问题,数据入库前仍存在主要诊断选择错误或名称不规范、确诊日期未填写等现象。采用DMAIC模型改善监测管理流程,数据质控分为数据智能质控、数据核查补录、生成质量监测报告和数据定时更新4个方面[15]。
(1)数据智能质控以EMPI为监测主线,数据字典表作为参考标准,梳理数据中的名称、编码等规范性错误。后结构化数据采用上下文联动的方式,根据语义关系进行数据更改或填充;对于不合理数据(如性别为男但有月经史)进行智能化更正后,同时也将业务系统中的源数据进行修改。
(2)数据核查补录是人工随机抽取少量数据,与院内系统中的病案首页等业务报表比对核查,判断是否存在数据不对应或不合理。
(3)生成质量监测报告。经过以上两个步骤,生成心肌病入库数据的质量检测报告,包括质量汇总、完整度等评分细项,并将质检报告交由医务部考量。
(4)数据定时更新。生成数据质量问题的具体原因,做到数据可回溯,利于有关部门针对问题进行更正,避免再次发生,提高数据入库效率[16]。
4 建设成效
参照国际疾病分类标准,心肌病患者是指诊断名称中包含心肌病或ICD-10诊断编码为I42的患者,专病库已完成自2012年1月至2021年9月心肌病患者数据的导入工作,共12023例。其中男性8121例,女性3902例,平均年龄(64.85±13.61)岁,诊断名称为扩张型心肌病5511例、缺血性心肌病2152例、肥厚型梗阻性心肌病973例,占总患者数的71.83%。由于专病医疗数据的特殊性,针对专病库的使用设定了相应的管理机制,科研人员通过院内OA办公系统提出提取科研数据申请,经科室领导、科教部、临床研究中心批准后可导出相应脱敏后的心肌病数据,专病库的应用界面如图5所示。到目前,专病库已配合完成2项心肌病临床研究,专病库中提供了患者住院号、性别、年龄、诊断记录、检查检验记录、手术记录等患者信息和临床数据,便于研究人员做回顾性或其他临床数据分析。基于专病库,科研人员开始尝试建立心肌病预后模型,如对心肌病确诊前的文本数据进行分类预测,研究成果有助于对患者实现更为精准的差异性治疗。专病库的实现一方面利用机器学习方法将病历病理等文本数据后结构化,提高了医疗数据的收集范围,全面发挥医疗数据的作用;另一方面简化研究人员手工统计数据和预处理的操作,有利于提高数据的准确性和研究人员的工作效率,增加了时序数据,可以有效避免多源数据相互矛盾的现象。
图5 专病库应用界面
5 讨论
近年来,“互联网+健康医疗”观念逐渐深入,建立互联互通、开放共享的医疗大数据平台成为焦点。就专病库的有效性而言,将原本大量不规律的临床文本通过处理形成专病数据库,为临床研究和疾病研究提供了信息服务和数据支撑,使得医生做回顾性研究更加方便快捷。就专病库的优越性而言,在院内CDR的基础上经过后结构化、去隐私化等处理建立了以EMPI为唯一索引的心肌病专病数据库,EMPI使得数据更加清晰,方便研究人员通过数据将EMPI进行分类,有利于推进该病种的基础学科研究。就专病库的创新性而言,增加了医疗数据利用率,有利于医生对心肌病进行风险评估并进行预后评价。
目前专病数据集处在病种扩展阶段,对出现的原始数据中一对多或多对一的映射问题,需及时改进院内业务系统。未来,随着人工智能在医疗领域不断深入,后结构化精度不断提高,建立依托于大数据、数据挖掘等技术面向医生、患者、科研人员和行政管理人员的医疗大数据综合服务平台指日可待。
猜你喜欢
基层中医药(2022年2期)2022-07-22
中国典型病例大全(2022年11期)2022-05-13
中国典型病例大全(2022年9期)2022-04-19
中华临床免疫和变态反应杂志(2021年6期)2021-11-19
医学概论(2021年9期)2021-09-16
健康必读(上旬刊)(2020年11期)2020-12-28
中华养生保健(2020年4期)2020-11-16
保健文汇(2020年7期)2020-08-21
保健与生活(2020年13期)2020-07-24
中国医药科学(2017年5期)2017-05-20
