
基于小样本数据增强的科技文档不平衡分类研究
2022-06-27 13:51黄金凤高岩徐童陈恩红
预测 2022年3期
关键词:文本分类
黄金凤 高岩 徐童 陈恩红





摘 要:科学技术的飞速发展衍生出海量的科技文档,其有效管理与查询依赖于准确的文档自动化分类。然而,由于学科门类众多且发展各异,导致相关文档数量存在严重的不平衡现象,削弱了分类技术的有效性。虽然相关研究证实预训练语言模型在文本分类任务上能够取得很好的效果,但由于科技文档较强的领域性导致通用预训练模型难以取得良好效果。更重要的是,不同领域积累的文档数量存在显著差异,其不平衡分类问题仍未完善解决。针对上述问题,本文通过引入和改进多种数据增强策略,提升了小样本类别的数据多样性与分类鲁棒性,进而通过多组实验讨论了不同预训练模型下数据增强策略的最佳组合方式。结果显示,本文所提出的技术框架能够有效提升科技文档不平衡分类任务的精度,从而为实现科技文档自动化分类及智能应用奠定了基础。
关键词:文本分类;预训练模型;类别不平衡;数据增强
中图分类号:TP391.1文献标识码:A文章编号:2097-0145(2022)03-0023-08doi:10.11847/fj.41.3.23
Research of Imbalanced Classification for Technical Documents
Based on Few-shot Data Augmentation
HUANG Jin-feng, GAO Yan, XU Tong, CHEN En-hong
(School of Computer Science, University of Science and Technology of China, Hefei 230027, China)
Abstract:Recent years have witnessed the rapid development of science and technologies, which results in the abundant technical documents. Along this line, automatic classification tools are urgently required to support the management and retrieval of technical documents. Though prior arts have mentioned that the pre-trained models could achieve competitive performance on textual classification tasks, considering the domain-specific characters of technical documents, effectiveness of these pre-trained models might be still limited. Even worse, due to the imbalanced accumulation of documents for different research fields, there exists the severe imbalanced classification issue, which impair the effectiveness of classification tool. To deal with these issues, in this paper, we propose a comprehensive framework, which adapts the multiple data augmentation strategies, for improving the diversity and robustness of document samples in few-shot categories. Moreover, extensive validations have been executed to reveal the most effective combination of data augmentation strategies under different pre-trained models. The results indicate that our proposed framework could effectively improve the performance of imbalanced classification issue, and further support the intelligent services on technical documents.
Key words:text classification; pre-trained language model; class imbalance; data augmentation
1 引言
近年來,随着科研投入力度的不断加大,各学科研究的长足发展衍生出了海量的科技文档。以作为测度科技发展水平重要指标的科技论文产出情况为例,自2012年至今的10年来,SCI数据库收录的我国作者论文数量不断攀升,并于2019年突破50万篇。这一趋势既体现了科研领域蓬勃发展的新局面,也带来了科技文档有效管理与高效检索的巨大挑战。由于作者所提供的少量关键词信息难以适应层次复杂的标签体系和动态变化的分类标准,在实践中往往无法获得所需的精度。因此,借助机器学习技术,基于科技文档中的丰富文本进行自动化分类已成为应时之需。
事实上,由于自然语言表达本身有着复杂的语义结构、丰富的多样性和多义性,并且会随着不同的外部语境而发生变化,导致科技文档等长文本的理解与分类任务本身具有较高的困难性。近年来,随着BERT[1]等预训练语言模型[1~3]的提出,越来越多的研究者聚焦于预训练加微调的迁移学习方式进行文本分类。其中预训练语言模型按照设计的代理任务在海量的无标签语料中学习文本表征,获取语言中蕴含的结构信息。由此,通过使用预训练好的语言模型并在特定下游任务中微调训练,可以有效地将海量无标签语料中的信息泛化到下游任务,在各种文本分类中取得了不错的效果。
然而,科技文档由于其自身领域性和专业性的特点,在词语分布与表达结构上与通用语料存在较大差异。因此,基于通用语料的预训练语言模型往往在科技文档的表征学习任务上存在一定偏差,这在一定程度上削弱了其有效性。更为重要的是,由于各学科分支发展的差异性,不同领域的文档积累数量存在显著区别,从而导致了严重的不平衡分类问题。例如,据2019年中国科技论文统计分析显示,国内科技论文最多的
10个学科所发表的论文总数占全部国内科技论文的62.9%,其中排名第一的“临床医学”学科占总量的26.4%。显然,这种不平衡性会导致分类标签倾向于热门学科,从而导致冷门学科难以有效分类,限制了分类技术在科技文档管理与检索任务上的应用。
针对这一问题,本文通过引入和改进多种数据增强策略,提升了小样本类别的数据多样性与分类鲁棒性。具体而言,首先借助各类现有预训练语言模型,对科技文档的长文本进行初步的表征学习,进而将学习到的表征输入下游网络结构进行语义分类。其中为有效解决冷门学科小样本所面临的分类不平衡的问题,采用简单增强、混类增强等策略增强小样本数据,从而提升模型的泛化性能;同时,借鉴视觉领域所采用的知识蒸馏思想实现专家模型向小样本分类任务的数据增强指导。实验结果证实,本文所采用的策略组合能够有效缓解科技文档分类中的不平衡分类问题,从而提升整体的文档分类效果。在2021年举行的首届“人邮杯”高校人工智能挑战赛中,我们借助本方案的初步版本脱颖而出,最终获得该竞赛冠军。
2 相关文献综述
在本节中,我们将从两个方面总结与本文相关的文献,分别为文本分類技术及不平衡分类问题。
2.1 文本分类技术
文本分类是自然语言处理中的经典问题。近年来,随着文本语料的积累与深度学习技术的成熟,基于深度学习的文本分类方法逐渐成为主流。其中Liu等[4]针对RNN网络能够有效建模时间序列的历史信息和位置信息的优势,基于多任务学习,通过共享部分层RNN网络的权重,在不同文本分类任务中提升了效果。而Tai等[5]提出了树形LSTM模型,通过建模语句中的树形语法层次结构,在预测语句语义关联和语句情感的分类任务中取得了显著的提升。此外,Zhou等[6]提出将LSTM与CNN模型相结合并用于文本分类,借助CNN模型加强LSTM输出中的局部短期关联,使模型能够兼顾语言中的长短期依赖。近年来,基于注意力机制的文本分类模型也备受关注,例如Pappas和Popescu-Belis[7]使用层次化的注意力机制,建模语言中复杂的依赖关系,在多语言环境中共享了编码器和注意力模块权重,超过了单语言设置下的分类效果。然而,这些技术往往无法有效应对严重的不平衡分类问题,因此限制了其在科技文档分类任务上的有效应用。
2.2 不平衡分类问题
样本不平衡分类问题是有监督学习中的基础性问题,主要指不同类别样本数量差距过大,导致小样本类别训练数据不全面且缺乏多样性,在测试中难以有效识别。针对这一问题,Elkan[8]使用代价敏感学习,将不同的类别预测错误赋予不同的代价权重,调高模型将小样本类别预测为大样本类别的惩罚权重,这一定程度上能够缓解样本不均衡问题。由于样本不均衡问题的本质是部分类别没有足够的训练样本,很多基于数据增强的方法被提出来解决这一问题。例如,Zhang等[9],Wei等[10]通过同义替换的方式,将语句中的词语用同义词字典或者词向量中的近邻进行替换,扩大了小样本类别语料的数量和多样性。Goodfellow等[11]提出FGM方法,通过计算样本相对损失的梯度,对样本在梯度上升的方向做随机扰动,旨在让模型学习更难分类的样本,这种在样本空间中引入噪声的方式能够提升模型的鲁棒性。不仅是文本任务,在图片分类和目标识别任务中也存在着严重的长尾问题,例如Hu等[12]通过按照样本数量将所有类别切分为几个大类,保证大类中的类别样本数量相对均衡,模型按照降序每次增量学习一个大类,用小样本迁移学习的方式实现每一次增量学习。在本文中,我们将通过引入多种数据增强策略,并借鉴视觉领域处理长尾分类问题的知识蒸馏技术等多种手段,尝试解决科技文档的不平衡分类问题。
3 基础模型
在本节中,我们首先简要介绍面向文档分类任务的基础模型作为本文技术框架的预备知识,其中包括基本的预训练语言模型及其下游网络结构。
3.1 预训练语言模型
由于现阶段大多数自然语言处理任务的数据标注成本较为高昂,构建大规模的高质量标注数据集非常困难。近年来,在深度学习技术和丰富语料积累的支撑下,基于大规模无标注语料训练学习通用语言表示,再将其应用到下游任务,已成为当前研究的基本范式。本节将介绍经典BERT[1]模型作为预训练语言模型的代表,而其他预训练语言模型在基本思路上与其类似。
具体而言,BERT模型采用两阶段训练模式。第一个阶段为预训练阶段,基于两个无监督预测任务:遮挡语言模型和下一句预测,从语料中学习到一种通用语言表示。第二个阶段为微调阶段,在已经训练好的语言模型基础上引入下游网络架构,再基于具体下游任务对模型进行训练,使其在下游任务上能够取得良好的性能。
3.2 下游网络结构
在基于预训练语言模型学习到文本表征之后,可以通过将其输入到下游网络结构,利用分类任务中的有标注数据完成网络的训练,从而实现文本的有监督分类。本节将介绍三种代表性的下游网络架构,分别为线性分类器、CNN+线性分类器,BiLSTM+线性分类器。
(1)线性分类器。在BERT模型基础上,将学习到的表征(融合了文本的所有信息)输入到一个全连接层,模型通过特征的线性组合做出相应的分类决策。
(2)CNN+线性分类器。通过在BERT模型基础上加入CNN和全连接层,将BERT模型每层的输出结果输入到多层卷积神经网络,每层卷积操作之后再接一个最大池化操作。合并所有池化操作的输出结果,输入到一个全连接层,最终判别得到样本分类结果。
(3)BiLSTM+线性分类器。在BERT模型基础上加入一个双向的LSTM层和全连接层。具体的操作和上述方法类似,将BERT模型每层的输出结果输入到一个双向的LSTM层,然后将双向的LSTM层输出与BERT模型最后两层的输出拼接在一起,输入到一个全连接层,最终给出样本分类结果。
4 基于小样本增强的不平衡分类
如前所述,科技文档存在着严重的类别不平衡问题,削弱了现有分类技术的精度。在本节中,我们将介绍多种小样本数据增强的策略,以尝试解决数据类别不均衡的问题。
4.1 技术框架概述
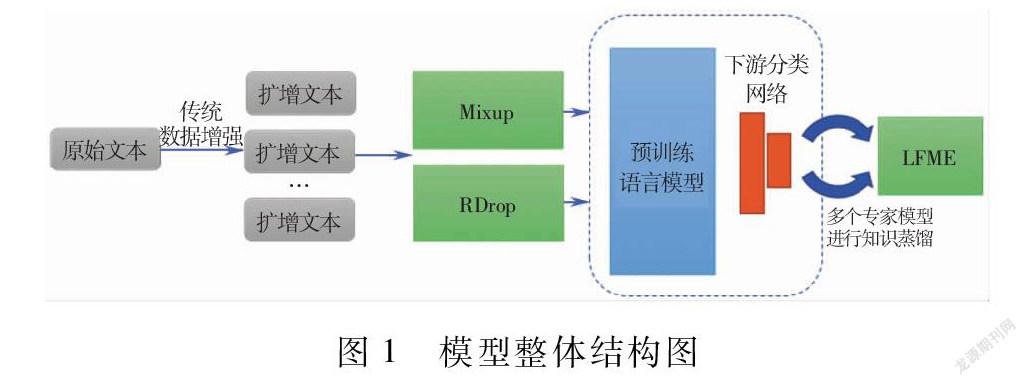
本文所采用的技術框架如图1所示。其中虚线框中的部分为上文所介绍的基础语言模型,包括预训练语言模型与相应的下游分类网络结构。如前所述,这一基础模型框架虽然可以在通用文本分类任务上获得较好结果,但在面临不平衡分类问题的科技文档分类任务上有一定的局限性。为此,本文拟通过引入多种数据增强策略,包括基于简单/混类增强的模型泛化策略和基于知识蒸馏的专家指导策略等。下文将分别介绍这些数据增强策略。
4.2 简单数据增强
由于各学科分支发展的差异性,部分冷门学科所积累的文档数据量小且缺乏多样性,难以将这些文档归类到正确的类别。我们期望增加这些小样本文档的数据量和样本丰富度,以帮助模型对其进行正确分类。为此,我们启发式地引入了简单数据增强[10](Easy Data Augmentation,EDA)策略,它包含一系列传统的数据增强方法,比如按照一定的概率对文本中的词语按照同义词字典进行文本替换,随机插入或者删除文本中的字词,随机交换文本中字词位置等方法来实现数据扩增,借助一些先验知识,基于文本经过少量变换不改变语义的假设,生成一批新的数据,从有限的数据中挖掘出等价于更多数据的价值,利用这些数据指导模型进行学习。
4.3 混类增强
目前对于文档分类任务,往往采用大规模深度神经网络加以实现,它们训练模型以使训练数据的平均误差最小化,即经验风险最小化[13](Empirical Risk Minimization,ERM)原则。但是,使用ERM方法训练后,神经网络可能会记住训练数据,而不是去泛化它,如果测试分布和训练分布略有不同,模型的预测性能可能会发生断崖式下跌。针对这一问题,我们期望增加模型的泛化能力,减少模型对噪声的敏感性,提升模型训练时的稳定性。对此,考虑增加样本的多样性,使得模型能够从丰富的样本数据中学习到一般规律,提升其泛化能力。
在上一节中,我们引入了简单数据增强策略,它可以实现对每一类的样本分别进行数据扩增,属于同类增强,但是这种方法与数据集密切相关,且需要一定的领域知识。针对这一局限性,我们希望能够实现一种简单且独立于数据集的数据扩增方式,通过挖掘出不同类不同样本之间的关系,构建虚拟的数据样本。基于上述启发,我们引入并改进了Mixup[14]的思想,按照一定的权重对训练集中随机抽取出的两个样本以及它们的标签进行加权求和,实现虚拟数据样本的构建。其中符号λ表示组合的权重,超参数γ控制特征-标签对之间的插值强度。
=λxi+(1-λ)xj(1)
=λyi+(1-λ)yj(2)
λ=Beta(γ,γ)(3)
最后,将构建好的虚拟数据样本输入模型进行训练,帮助模型优化。
4.4 正则化丢弃
同时,针对数据不平衡可能导致的过拟合问题,我们还将采用正则化丢弃(Regularized Dropout,RDrop[15])策略。它通过两次dropout的方式得到同一个输入的不同特征,构建对抗样本对,同时计算模型两次输出结果之间的KL散度,使得不同dropout得到的模型输出基本一致,从而提升训练和测试时模型的一致性,增加模型的鲁棒性,最终提升模型性能。
具体而言,在本问题中,训练数据可以表示为{(xi,yi)}Ni=1,模型表示为P(y|x)。RDrop的损失函数包括两个部分,一部分是基于每个模型的输出结果计算损失值
L(CE)i=-logP(1)θ(yi|xi)-logP(2)θ(yi|xi)(4)
另一部分是计算两个模型之间的对称KL散度
L(KL)i=12[KL(P(2)θ(y|xi)‖P(1)θ(y|xi))+
KL(P(1)θ(y|xi)‖P(2)θ(y|xi))](5)
最终的损失函数是对这两个部分的损失进行加权求和,通过最小化该目标即可实现优化求解
Li=L(CE)i+αL(KL)i(6)
4.5 多专家学习策略
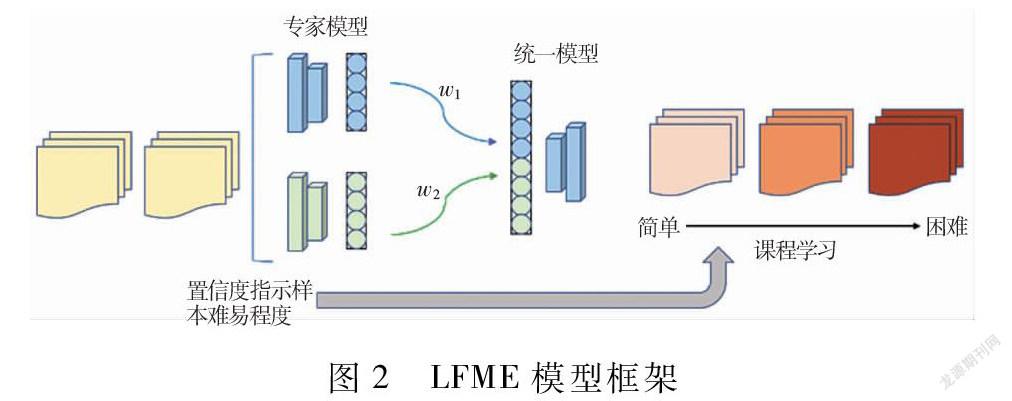
之前引入的各种策略都是在数据输入端,为提升模型鲁棒性和泛化性而进行的操作。然而,如前所述,科技文档存在严重的类别不平衡性,而这些模型并没有有效借助那些数据量较少的类别。事实上,我们发现在样本数较为平衡的原数据类别子集中训练的模型效果要比直接在所有类别中训练的模型效果好。为此,一种可行的策略是首先训练多个分类子任务,然后在分类子任务的指导下,训练对所有类别的分类任务,而这正是在视觉领域常用于解决不平衡分类问题的LFME[16]方法的出发点。为此,我们将LFME模型迁移到自然语言处理领域,其总体框架如图2所示。
具体而言,LFME方法先将所有类别按照样本切分为L个子集,并针对L个类别相对均衡的类别子集分别训练分类模型,从而得到L个专家模型,再通过知识蒸馏的方式将L个专家模型迁移为针对所有类别的统一模型。其中知识蒸馏损失的权重由统一模型在不同类别子集上达到的验证集准确率决定,验证集准确率越低,代表越需要向对应的专家模型学习,蒸馏损失如下
LKDl=-H(τ(z(l)),τ((l)))
=-∑|Sl|i=1τ(z(l)i)log(τ((l)i))(7)
τ(z(l)i)=exp(z(l)i/T)∑jexp(z(l)j/T)
τ((l)i)=exp((l)i/T)∑jexp((l)j /T)(8)
wl=1.0if AccMβAccEl
AccEl-AccMAccEl(1-α)if AccM>βAccEl(9)
LKD=∑Ll=1wlLKDl(10)
其中T为温度超参数,β为知识蒸馏的阈值超参数,AccEl为第l个专家模型的验证集准确率,AccM为当前统一模型在第l个样本子集的验证集准确率,wl会在每个训练周期结束后更新。
同時,LFME也进行了课程学习的设置,即从简单到困难学习,使模型能够平滑地收敛,其中样本的难易程度由专家模型给出的置信度决定。交叉熵损失如下定义
LCE=∑Ni=1v(k)iLCE(xi)(11)
v(k)i=(1-piNSminNSl)eE+piNSminNSl(12)
其中LCE为交叉熵损失函数,e为所处的训练周期序号,pi为专家模型得到的样本置信度,NSl为第l个类别子类的样本数量,NSmin为NSl中的最小值。最后,优化以下的总体损失函数
L=∑Ni=1viLCE(xi,yi)+∑Ll=1
∑Ni=1wlLKDl(M,Mexp;xi)(13)
5 实验验证与讨论
在本节中,我们将首先介绍实验验证所使用的数据集与数据处理过程,进而通过多组实验,讨论不同预训练语言模型、下游网络结构及相应的小样本数据增强策略的最佳组合方式,并通过案例分析讨论不同策略组合效果提升的可能原因及其潜在局限性。
5.1 数据集介绍
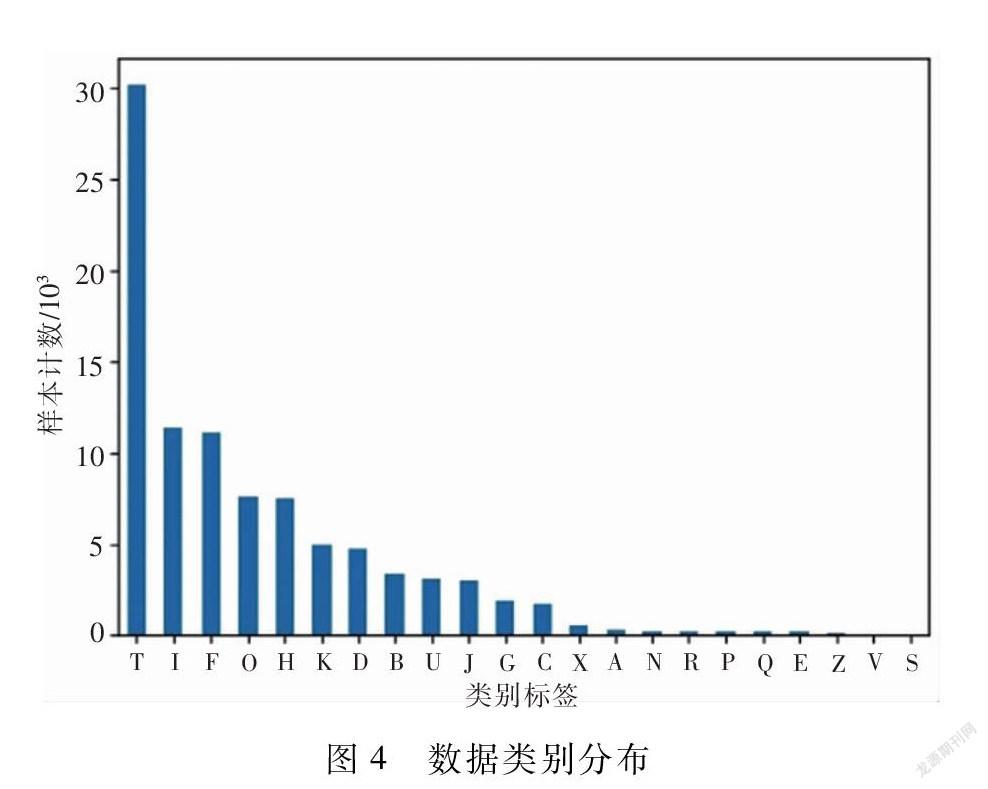
本文采用“人邮杯”有关测评的图书分类数据集近似科技文档数据,并通过分层抽样将原始数据集按照18∶1∶1的比例划分为训练集、验证集和测试集,三部分分别包含92549条、5142条和5141条记录。整体文本长度分布如图3所示,其中标题平均长度约为13,摘要平均长度约为240。样本类别总共22类,其分布如图4所示,可以看到数据存在严重的分布不平衡问题。例如,其中T类书籍在训练集中占比超过30%,而S类书籍在训练集中仅有13条。为进一步提升数据质量,我们对数据进行了简单的清洗,去除了数据集中存在的特殊字符、重复字符等。
5.2 实验设置
本次实验所使用的预训练语言模型均来自HuggingFace资源库,训练中使用的显卡型号为NVIDIA GeForce RTX 3090。具体的参数设置如下:对于一般的预训练语言模型,max_len设为200,对于长文本语言模型longformer,max_len设为456,学习率设为2e-4,batch_size设为32, dropout设为0.1, epoch设为20,混类增强方法中的γ设为0.25,RDrop方法中的α设为1,LFME方法中的温度超参数T设置为2,知识蒸馏的阈值超参数β设置为0.8。在训练LFME中的统一模型时,过采样小样本类别,使用类别独立的采样方式。
在实验过程中,我们采用了micro-f1和macro-f1作为文本多分类任务的评估指标。其中macro-f1侧重于小样本,能够更好地体现类别不均衡场景下小样本类别上的性能。
5.3 基础语言模型及其对比效果
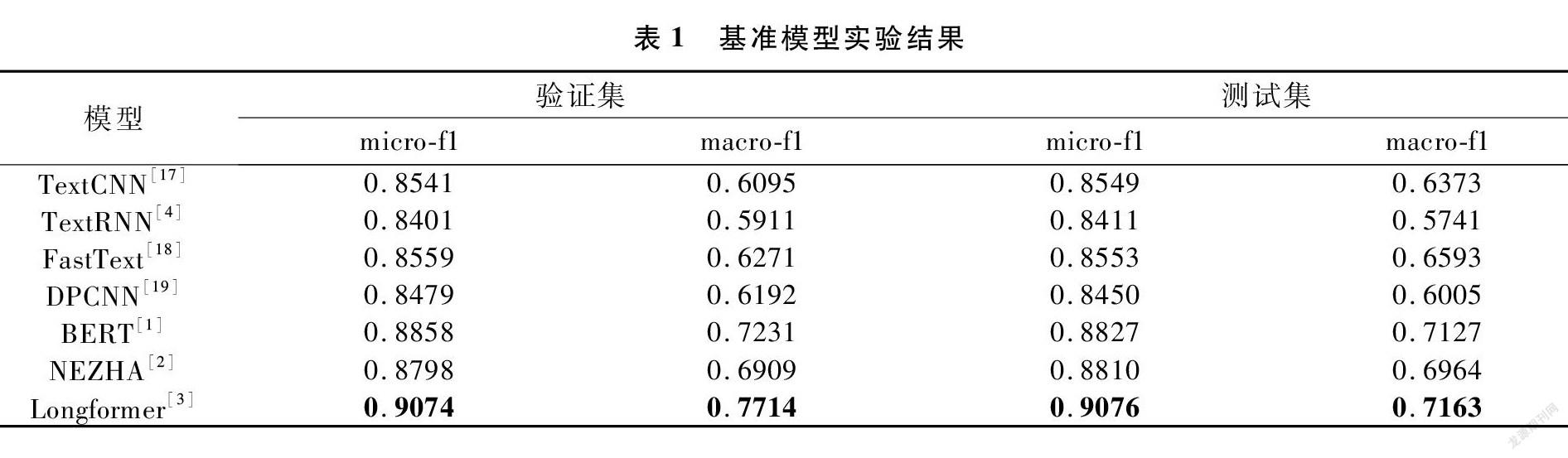
在本实验中,为了充分比较分析不同预训练语言模型与下游网络结构组合在科技文档分类任务上的效果,我们采用了多种预训练语言模型+线性分类器作为基准模型,其在验证集和测试集上的分类效果如表1所示。由实验结果可知,实验中采用的所有基于预训练语言模型的文本分类方法相对于传统的文本分类方法,在各项指标上均有大幅度的提升,说明相较于随机初始化词向量,在大规模无标注语料库上学习到的语言表征可以很好地迁移到下游任务,提升下游任务上的模型性能。同时,对于不同的预训练语言模型,可以发现Longformer模型的性能最好,推测与其采用了局部注意力机制,可以有效地对长文本信息进行建模相关。
5.4 下游网络结构对比
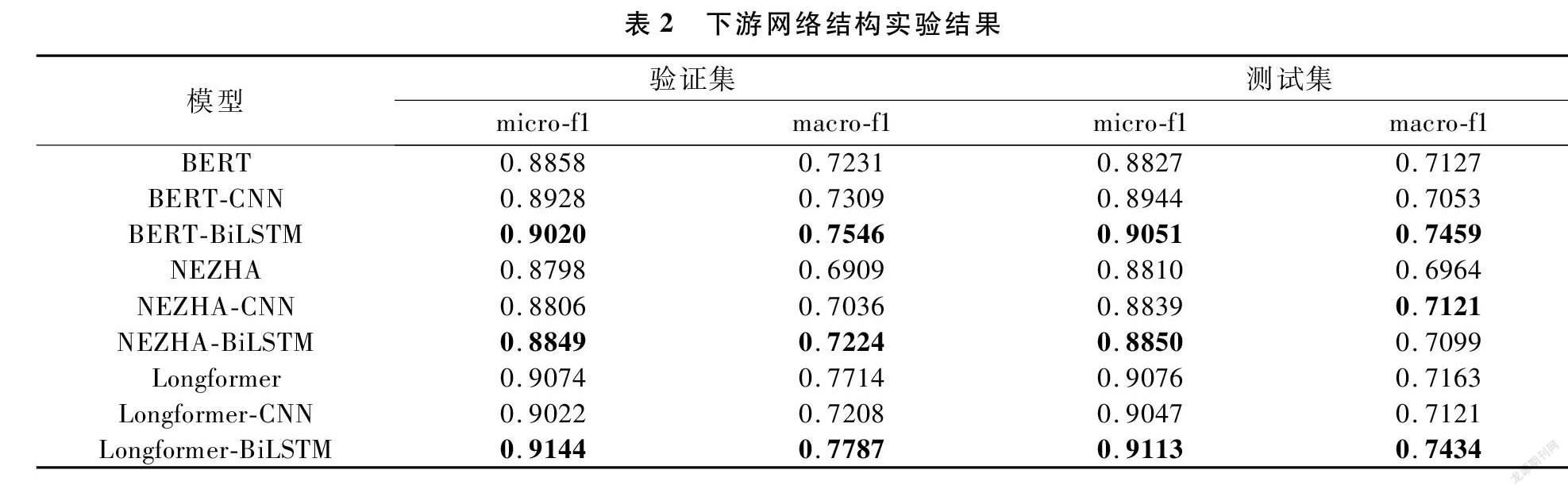
我们在多个预训练语言模型的基础上研究下游分类网络对预训练语言模型分类效果的影响,结果如表2所示,可以发现在BERT、NEZHA、Longformer三个预训练语言模型中,BiLSTM作为下游网络效果最好,而CNN下游网络相对于线性分类器没有明显提升。
5.5 小样本分类策略对比
针对前文所述的科技文档严重的样本不均衡问题,在本环节中,我们以Longformer为基准模型,在测试集上验证和对比在第4节中介绍的多种数据增强方法。
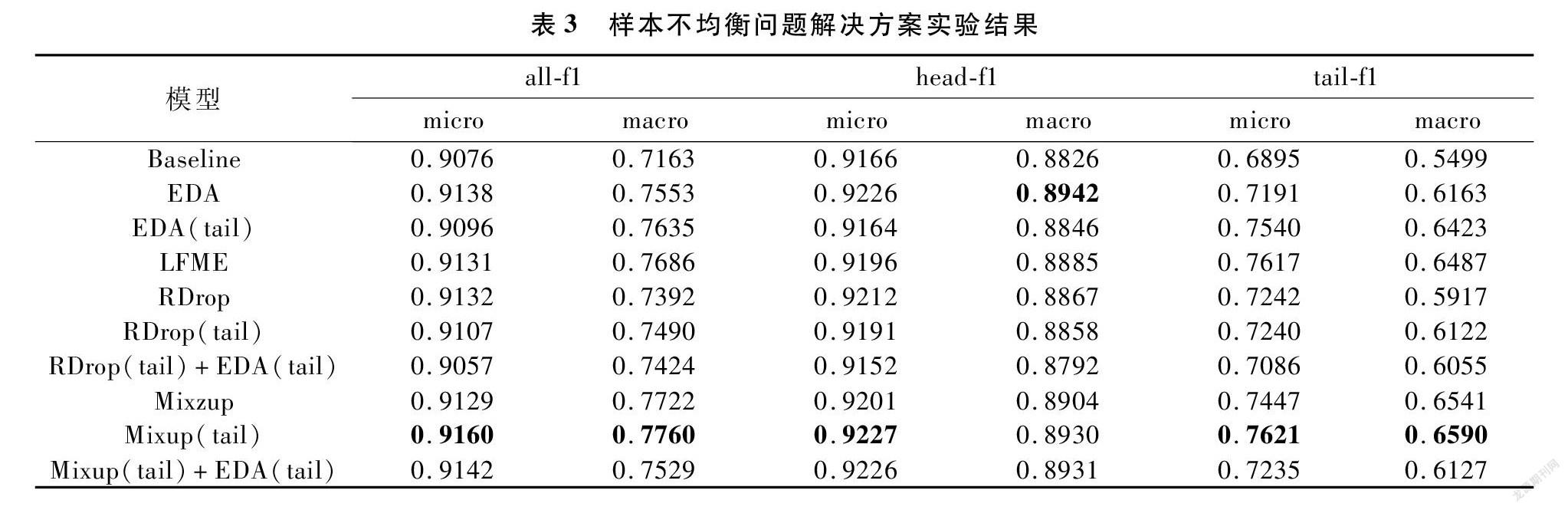
具体而言,我们将数据中的22个类别按照出现频次分成两部分,并将出现频次高的11个类别称为head,出现频次低的11个类别称为tail,其中tail类别只占总样本数的约5%。实验结果如表3所示,其中分别列出了在tail类别、head类别和所有类别中的f1-micro和f1-macro等指标,数据增强方法名称后有tail的代表仅仅在tail类别的样本中进行数据增强。
通过实验结果对比,我们发现LFME、RDrop、EDA、Mixup这四种数据增强方法,对比基线方法,在整体性能上均有不小的提升,通过分别评估head类别和tail类别中的f1-score,我们发现数据增强能够在不影响大样本类别分类效果的同时,极大地提升小样本类别的分类表现。对比第2行和第3行以及第5行和第6行,我们发现仅仅在占5%的tail类别样本中使用EDA或RDrop的方法,和与在所有样本上做数据增强相比,在整体性能上能获得差不多的提升,但在小样本类别中明显更优。对比第8行和第9行,在小样本类别上利用Mixup能在整体性能和小样本两方面获得更好的效果。对比第6行和第7行以及第9行和第10行,我们发现在RDrop或Mixup方法上叠加EDA会造成性能损失,我们推测是EDA生成的噪声数据被RDrop或Mixup放大所造成的。
5.6 消融实验
在前述策略组合的基础之上,我们对于LFME中的重要模块进行了消融实验,其在测试集上的实验结果如表4所示,其中“-课程学习”表示不根据专家模型区分样本的难易程度,即公式(11)中的v(k)i设置为0,而“-动态蒸馏权重”表示在head和tail合集中不根据准确率动态调整蒸馏权重,即公式(9)中的wl在前一半训练周期设置为1,后一半训练周期设置为0。实验结果验证了课程学习和动态蒸馏权重模块的有效性,在总体macro-f1和小样本指标上,LFME模型都优于消融后的模型。
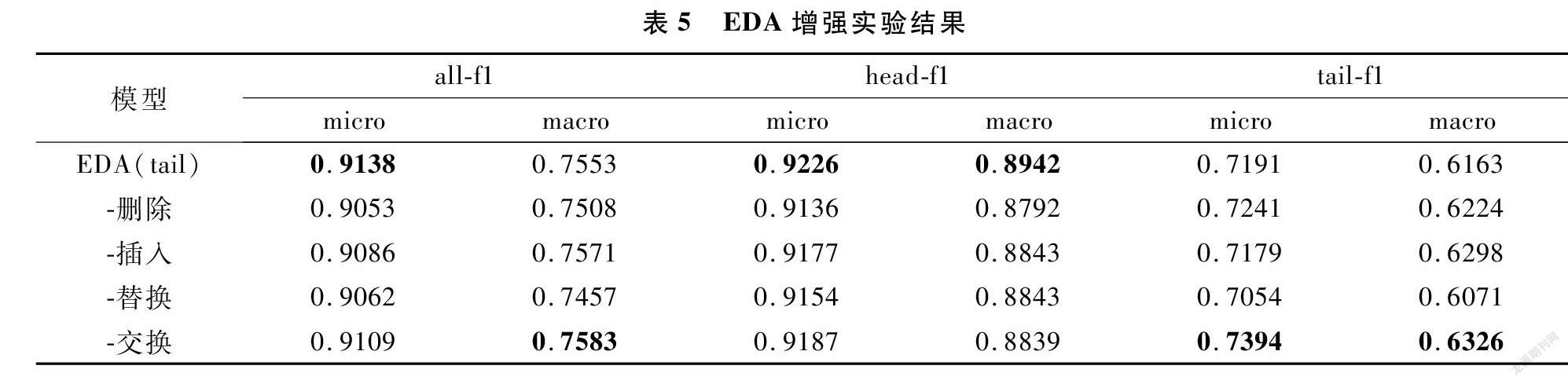
同时,对于EDA中插入、删除、替换和交换4种数据增强方式,我们通过删去一种增强方式而保留其他三种进行对比,验证EDA中每种增强方式的有效性,实验结果如表5所示。通过消融实验,我们验证了所有4种数据增强方式对小样本分类任务均有帮助,其中交换操作提升最少。
5.7 案例分析
最后,我们通过部分案例的分析,讨论在效果最好的预训练语言模型Longformer模型的基础上,Mixup和LFME两种策略在小样本分类问题上各自提升的可能原因及潜在的局限性。
[样例1]:
标签:C类图书(社会科学总论)
标题:国际大都市文化导论,《国际大都市文化导论》对国际都市文化的比较研究
摘要:置于全球视野之下,试图在全球化与全球新的城市世纪到来之际,比较研究不同全球城市精神文化的特点,进而揭示全球城市精神文化的共同本质及其深层价值…
在该案例中,该样本被Longformer基线模型错误分类为T类图书(工业技术),但在使用LFME方法后却可以被正确分类,而且能够达到0.93的置信度。我们预测的原因为,在一般的训练过程中,由于类别样本数量的失衡,不同类别辨别特征的学习速率存在着很大的差异,C类样本数量只占T类样本的1/16,模型在C类样本上的泛化能力不足。但在LFME方法中,C类样本作为tail子集中样本数量最多的分类,tail专家模型能够有效地识别C类样本,通过知识蒸馏用tail专家模型指导LFME统一模型学习,能够使得不同类别间的学习速率相对同步。并且在C类图书上LFME方法相对于基线模型在f1-score上能有4个百分点的提升,这也印证了我们的推测。
[样例2]:
标签:C类图书(社会科学总论)
标题:大国空巢:反思中国计划生育政策
摘要:《大国空巢:反思中国计划生育政策》曾于2007年在香港出过一版,书一出版就受到了广泛关注,并引发了激烈争论…
在该案例中,Longformer基线模型将该样本错误分类为D类图书(政治、法律),我们推測原因为,“政策”一词在D类训练样本中高频出现,导致模型只根据“政策”这一关键词进行判别。这一方面是由于“政策”在该案例的标题和摘要中多次出现,容易混淆模型,干扰模型接收其他有效信息;另一方面,C类图书数据量比较少,样本多样性不足,导致模型在C类样本上的泛化能力比较差。而通过Mixup进行混类增强,能够减少对错误标签的记忆,增加模型的泛化能力,使模型在训练和预测时性能比较一致。
6 结论与启示
本文研究了如何将预训练语言模型迁移到科技文档多标签分类任务上,并借助小样本数据增强技术解决科技文档不平衡分类的技术挑战。我们通过实验发现,在小样本上做数据增强和在所有数据上做数据增强的效果差不多,不过前者相对后者在训练时间上缩短了5倍。同时,本文通过引入和改进多种数据增强策略,提升了小样本类别的数据多样性,并通过多组实验讨论了不同预训练模型下数据增强策略的最佳组合方式。结果显示这一技术框架能够有效提升科技文档不平衡分类任务的精度,且大多数据增强策略都能帮助提升小样本分类效果。
借助于上述技术框架的初步版本,我们在首届“人邮杯”高校人工智能挑战赛中取得了冠军的成绩。在未来工作中,将进一步结合集成学习技术,在发挥各预训练模型与策略组合专长的基础上进一步提升整体方案的鲁棒性,并结合元学习等手段更有效地应对冷门学科中的小样本学习问题。
参 考 文 献:
[1]Vaswani A, Shazeer N, Parmar N, et al.. Attention is all you need[A]. Proceedings of the 31st International Conference on Neural Information Processing Systems[C]. Curran Associates, Red Hook, NY, USA, 2017. 6000-6010.
[2]Wei J, Ren X, Li X, et al.. NEZHA: neural contextualized representation for Chinese language understanding[J]. arXiv:
1909. 00204, 2021.
[3]Beltagy I, Peters M E, Cohan A. Longformer: the long-document transformer[J]. arXiv: 2004. 05150, 2020.
[4]Liu P, Qiu X, Huang X. Recurrent neural network for text classification with multi-task learning[A]. Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence[C]. NY, USA, 2016. 2873-2879.
[5]Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[A]. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)[C]. Association for Computational Linguistics, Beijing, China, 2015. 1556-1566.
[6]Zhou C, Sun C, Liu Z, et al.. A C-LSTM neural network for text classification[J]. arXiv: 1511. 08630, 2015.
[7]Pappas N, Popescu-Belis A. Multilingual hierarchical attention networks for document classification[A]. Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers)[C]. Asian Federation of Natural Language Processing, Taipei, Taiwan, 2017. 1015-1025.
[8]Elkan C. The foundations of cost-sensitive learning[A]. International Joint Conference on Artificial Intelligence[C]. Lawrence Erlbaum Associates Ltd, Seattle, Washington, USA, 2001. 973-978.
[9]Zhang X, Zhao J, LeCun Y. Character-level convolutional networks for text classification[A]. Advances in Neural Information Processing Systems[C]. Curran Associates, Montreal, Canada, 2015. 649-657.
[10]Wei J, Zou K. EDA: easy data augmentation techniques for boosting performance on text classification tasks[A]. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing[C]. Association for Computational Linguistics, Hong Kong, China, 2019. 6382-6388.
[11]Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[J]. arXiv: 1412. 6572, 2015.
[12]Hu X, Jiang Y, Tang K, et al.. Learning to segment the tail[A]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)[C]. IEEE, Seattle, WA, USA, 2020. 14042-14051.
[13]Vapnik V. Principles of risk minimization for learning theory[A]. Advances in Neural Information Processing Systems[C]. Curran Associates, Denver, Colorado, USA, 1991. 831-838.
[14]Zhang H, Cisse M, Dauphin Y N, et al.. Mixup: beyond empirical risk minimization[A]. International Conference on Learning Representations[C]. OpenReview.net, Vancouver, BC, Canada, 2018. 1-13.
[15]Wu L, Li J, Wang Y, et al.. R-drop: regularized dropout for neural networks[A]. Advances in Neural Information Processing Systems[C]. Curran Associates, New Orleans, LA, USA, 2021. 10890-10905.
[16]Xiang L, Ding G, Han J. Learning from multiple experts: self-paced knowledge distillation for long-tailed classification[A]. European Conference on Computer Vision[C]. Springer, Glasgow, UK, 2020. 247-263.
[17]Chen Y. Convolutional neural network for sentence classification[D]. Waterloo: University of Waterloo, 2015.
[18]Joulin A, Grave , Bojanowski P, et al.. Bag of tricks for efficient text classification[A]. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics(Volume 2: Short Papers)[C]. Association for Computational Linguistics, Valencia, Spain, 2017. 427-431.
[19]Johnson R, Zhang T. Deep pyramid convolutional neural networks for text categorization[A]. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)[C]. Vancouver, Canada, 2017. 562-570.
猜你喜欢
电脑知识与技术(2016年30期)2017-03-06
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
湖南大学学报·自然科学版(2016年4期)2016-08-12
中国教育信息化·基础教育(2016年2期)2016-05-31
软件(2015年5期)2015-08-22
