
基于内容的英语录音教材标注研究与应用
2016-05-31 11:26闵捷钟岑岑沙沙
中国教育信息化·基础教育 2016年2期
关键词:文本分类
闵捷 钟岑岑 沙沙


摘 要: 英语录音教材在数量和种类上的飞速发展对其有效管理与利用提出了新的挑战,此时传统的人工标注和组织方式已不能满足数字出版以及教育信息化的需要。文章基于音频信号处理、机器学习等信息技术,提出基于内容的英语录音教材标注,运用自动与人工相结合的处理方法,从多层次、可扩展等角度构建描述录音内容的内容表征模型,并在教育信息化环境中探索该模型及标注框架的应用方式,以期为未来录音教材的建设和管理乃至数字化教育出版物的加工与发布提供参考。
关键词: 英语录音教材;内容标注;关键词检出;文本分类;数字教育出版
中图分类号:G434 文献标志码:A 文章编号:1673-8454(2016)04-00089-04
一、引言
在我国,录音教材是教科书体系中的重要组成部分[1],是纸质教科书中精选内容的音频化,在我国英语、语文、音乐等学科的教学中得到了广泛的应用,迄今已有五十余年的历史。尤其是对英语这一外语类学科的教学,录音教材以其规范的语言表达和内容质量,为教师提供了便捷的辅助工具,为学生创建了良好的听觉情境,对于听说读写等外语学习基本技能特别是听的培养和达成,起到了重要作用。
英语录音教材的产生经过了素材录制、内容编辑、技术加工等音像出版的主要环节[2],在此过程中,录音教材的编辑开发单位积累了大量的资源。最近三十年来,从教科书中的课文同步朗读到教辅中的听力测试,各类英语录音教材的总数量巨大、内容多样,如何对这些资源进行科学、高效的组织和管理,对于录音教材的编制与应用、数字化教育资源的开发和建设具有重要意义。长久以来,英语录音教材的管理主要是以录音磁带、光盘等载体为依托,将播音人员、出版单位、时长、主要内容等信息采用卡片形式通过手工来建立文本索引。然而,在数字技术飞速发展的今天,这种传统的基于人工的资源标注方式却变得日益局限。一方面,面对海量的录音教材,人工处理不仅耗时费力,而且易受疲劳、差错等人为因素影响。另一方面,目前的人工处理大多是对一些客观属性进行标引,而在智慧学习环境,更需要的是基于各种教学功能、内容语义和语音特征等信息为教师或学生提供个性化服务,现有的属性标引方式难以满足实际需求。
在这种情况下,本文基于音频信号处理、机器学习等信息技术,提出基于内容的英语录音教材标注方案,以期在尽量少的人工干预下,自动给出大量未知英语录音教材的多层级内容标签,并从教育信息化环境下的数字教材建设和录音教材数据库应用的角度尝试探索,从而为未来录音教材乃至数字化教育资源的建设和管理提供参考。
二、英语录音教材的内容描述
英语录音教材是将一定的教材内容以音频形式进行呈现的课程资源。相对于纸质教科书的文本形态,录音教材通过播音人员的演绎、背景音(乐)的插入、音频技术的处理等手段,试图营造出生动、真实的听觉环境,给人以亲近感,从而促进教师教学效果的提高、学生英语综合语言运用能力的培养。
从本质上看,英语录音教材仍归属为音频资源:作为一种重要的多媒体信息传播媒质,在人耳所能听见的频率范围内包括语音、音乐、环境音等类型。对于这些音频的内容,可以用反映其声学特点和人类听觉感受的低层特征以及贴近用户理解的语义特征来描述。
然而,不同于一般音频数据,英语录音教材面向教学的特殊地位决定了其语音部分是实现语言教学的重点。无论是内容的选择与录制还是素材的处理与集成,均围绕教学目标和教学内容进行。作为英语录音教材内容中的主体,录音教材的语音部分具有一定的规律性,从形式上看包括单词、语句、对话等基本单元,在不同的学段偏重不同;从语言内容上看,在传递词句等语言表层含义的同时,还隐含了主题、话题等高层语义信息,例如,与《义务教育课程标准实验教科书 英语(新目标) 七年级上》配套的录音教材中,就大体包括姓名、足球、晴朗等关键词,并涵盖天气、运动、生日、交际等主题。
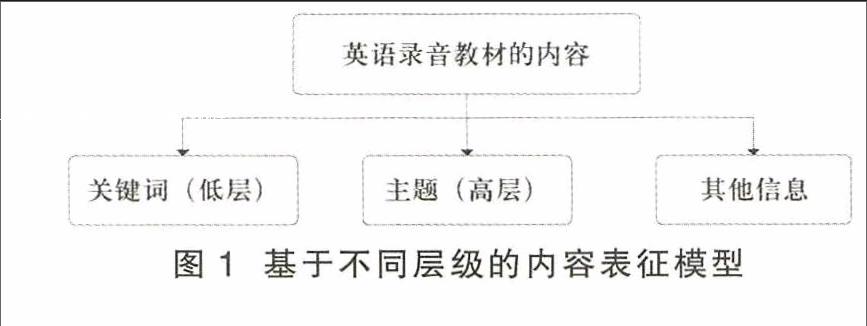
基于以上分析可知,英语录音教材的内容描述主要体现在以语言为主的语义层面,也就是说,对于一个基本单元,可以分别用关键词和主题两个层级的内容来表示语言低层和高层语义的信息。以此为基础,还可再辅以提示音类别、间奏音乐类型等其他信息,由此构建出的更为丰富的基于不同层级的内容表征模型(见图1),就可用于描述英语录音教材的内容。
三、基于内容的英语录音教材标注方案
基于内容的英语录音教材标注的目的在于,自动得到大量未标注英语录音教材(未知数据)的基于内容表征模型的标注结果(多层级内容标签),并以此作为接口用于实现资源管理以及后端的具体应用,在此过程中允许管理人员或用户进行人工干预,通过修正学习模型来提高标注性能(见图2)。
基于内容的英语录音教材标注本质上是一个机器学习问题,它借助于已准确标记的训练数据来构建学习模型,再以此为依据建立起未知数据与内容标签之间的映射关系。作为该过程的主体,英语录音教材语言部分的内容标注主要包括音频类型分割、关键词检出和文本分类三个关键模块(见图3),它们依次相连,并且相应的输出项组成了未知数据的多层级内容标签。这三个模块的具体设计如下。
1.音频类型分割
由上可知,英语录音教材包括语音、音乐、环境音等类型,音频类型分割模块的任务就是将这些类型区分开来,以供后端模块使用。该过程是依据所提取的能量、基频、过零率、梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)等低层特征完成的,一方面通过判断这些特征的突变点来实现音频的物理切分,另一方面对切分后的片段进行基于分类器的分类,将其归属为某些已经定义好的语义类别。
对于分类的类别,语音、音乐、静音等粗粒度类别是该过程所关注的首要问题。在此基础上,也可进行某一具体类型的精细分类,如提示音、间奏、自然声响等,甚至可进一步细化分层,例如,歌谣、纯音乐等音乐类型,音乐会、爆炸等音频事件等。这一部分的细化处理结果可作为英语录音教材的内容表征模型中的其他信息,并依据实际需求进行调整和扩充。
2.关键词检出
对于英语录音教材中的语音部分,首先需要给出其语言表述信息,而这可以通过语音识别技术来实现。
在英语录音教材的编制过程中,播音人员的专业素养、编辑的监控管理、制作人员的后期处理等手段使得教材中的发音、语速、语调等具有严格标准的规范,由此得到的录音资源具有标准式朗读效果,可作为内容标注中学习模型构建所需的训练样本。但实际上,考虑到鼓励学生接触多样化英语的教学目标、尽量营造真实情境的质量把控等实际要求[3],部分英语录音教材中会故意包含口音、情绪变化、口语化、背景音等干扰因素,此时,针对这种相对贴近实际的发音的语音识别技术,就会由于目标与学习模型不匹配等问题而产生较高的错误率,在这种情况下,相对于试图得到一词一句精准识别结果的连续语音识别,本文认为采用仅将输入语音用多个关键词进行描述的关键词检出技术则更为合适。
关键词检出是一种从无限制的语音流中识别出一组给定词(关键词)的语音识别技术,相对于早期经典的基于废料模型的处理方式,基于大词汇量连续语音识别(Large Vocabulary Continuous Speech Recognition,LVCSR)的关键词检出在大词表、任务无关的应用环境中体现了较高的准确性和灵活性。该框架先利用LVCSR将语音数据转化为覆盖多个候选结果的网格结构,再采用基于文本的匹配搜索在该网格中搜寻描述主要内容的关键词。这种两步式处理方式既通过将原始语音数据转化为基于网格的文本表示来降低了数据存储代价,又允许在无需重新进行模型训练的情况下增删关键词词表,对于未标注英语录音教材数量不断增长、内容不断多样的实际情况有较好的适用性。此时得到的网格结构将作为中间数据以满足未来的需求更新,而关键词信息将作为内容表征模型中的低层语义内容描述。
3.文本分类
该模块以关键词为输入项,输出对应语音数据的高层语义信息——主题。这是一个典型的模式识别问题,包括特征提取和模型分类两部分。其中的特征提取,即对每个已用关键词序列表示的语音数据进行基于文本的特征描述,在这里可采用经典的向量空间模型(Vector Space Model,VSM)来实现,也就是将关键词看成是离散单词,把每一个语音数据表示成向量形式,其中的向量元素描述了某个单词在该数据中的出现情况,可用TF-IDF(Term Frequency-Inverse Document Frequency)[4]等方法表示。在得到VSM之后,便可根据已经定义好的文本类别标注信息采用支持向量机、神经网络等算法来构建类模型,并通过计算未知数据与模型之间的距离来实现分类。
至此,除了表示低层内容的关键词,主题作为高层语义内容的描述,也被赋予给了每一个语音数据。此二层信息便构成了英语录音教材的内容表征模型的主体部分。
上述三个模块给出了基于内容的英语录音教材标注的基本框架,但是待处理数据的复杂性、模型的鲁棒性和适用性、语义概念的主观性等问题还是会使得完全自动的标注方法的性能不够理想,因此不可避免的要加入人工干预。这主要需要两方人员的努力:一方面,应在后端应用模块为实际用户留有交互接口,允许人工对标注有误的数据进行标记,并反馈给标注模块;另一方面,为管理人员构建友好易用的管理界面,用以对上述标注有误的数据、具有代表性的未知数据进行人工标注,再将这些新的训练数据送入标注模块以进行学习模型的更新和优化,而这一过程可通过相关反馈、在线更新学习等算法来实现。
四、英语录音教材数据库在教学中的应用
基于内容的英语录音教材标注技术可用于生成一个可支持智慧学习环境的录音教材数据库。与传统的录音教材相比较,录音教材数据库能够为教师、学生提供更为全面的内容服务。
仍以英语学科为例,首先录音教材数据库可以为学习者提供个性化的学习资源服务。所谓的个性化学习资源服务,其核心问题是能够判断学习者现有的学习水平,并且能够提供与其现有水平相适应的学习内容。对一般的英语学习者来说,学习英语时都有明确的水平划分指标,如义务教育英语课程标准中将英语划分为五级,对每一个级别都有明确的听、说、读、写等要求,并对二级和五级水平给出了学生应掌握的单词表。基于课程标准的水平分级,我们就对经过内容标注的录音教材内容进行难度分析。可以通过对文本内容中的单词分析、背景声音、内容长度、语速等因素解析其对应听力难度水平。显然,录音内容中出现的单词属于哪一个等级水平、背景声音对主声音内容的干扰程度、语言速度等可以综合反映某一段录音教材内容的难度。通过这样的难度分析,我们一方面可以在学习者完成一次听力练习后识别其实际水平,另一方面也能够依据每段录音内容的难度级别,进一步为不同英语水平的学习者推送具有针对性的学习资源。
如果配合语音识别和语音分析引擎,录音教材数据库还可有效服务于学习者口语学习。到目前为止,在教育领域中通过计算机进行有效的语言、语音评价,仍需要基于标准录音素材来进行,录音教材数据库则提供了海量的标准语音素材。在口语学习方面,基于内容标注,录音教材数据可以辅助语音评价系统对学习者的口语情况给出更科学的评价结果,以及对学习者的口语能力提出强化和改进方案和标准语音范例,最终实现面向用户口语能力提升的教学过程。
基于内容标注的录音教材数据库还能够结合其他类型的课程资源,特别是结合数字教科书形成完整的语言学科学习解决方案。在教育部《2014年教育信息化工作要点》和《2015年教育信息化工作要点》中,均提出了:鼓励开发与教材配套的基础性数字教育资源和满足广大师生需求的个性化数字教育资源。标注好的录音内容可以作为传统教科书出版向数字教材转型的基础。例如,录音教材数据库可以和纸质教科书内容的结合,通过光学字符识别(Optical Character Recognition,OCR)技术和关联标识方法,形成集文字、图片、声音为一体的点读教材,通过这一方式可以弥补传统教科书在英语学科听、说方面的不足。录音教材数据库的另一种与教材的结合方式,是基于纸质教材的数字版本,整合适宜信息化环境中使用的英语数字教材。基于内容标注的录音教材数据库不仅可以与教材原有的文、图内容一起形成覆盖英语听、说、读、写的数字教材,更可以通过其多层级内标签为学生、教师提供个性化内容,解决传统教材个性化、针对性不强的缺陷。
五、总结与展望
在教育信息化的背景下,录音教材在数量和种类上的飞速发展对其有效管理与利用提出了新的挑战,而传统单一、人工的标注和组织方式已经不能满足实际需求。本文所提出的基于内容的英语录音教材标注研究与应用,以英语学科为例,运用了自动与人工相结合的处理方法,从多层次、可扩展等角度构建英语录音教材的内容表征模型,并在教育信息化环境下简要探讨该技术所形成的录音教材数据库的一些应用方式。这无论对录音教材还是其他形式的数字化教育资源的建设与管理,乃至数字化教育出版的加工与发布,都能具有较高的参考和借鉴价值。
在本文研究的基础上,随着未来教育信息化的整体发展,录音教材在数字化、碎片化、结构化等方面仍有进一步研究的必要。笔者认为,可能形成突破的研究方向包括以下三个方面。
在本研究的内容表征模型中,主要讨论了以英语学科语言学习要求为出发点的内容标注,并将重点放在了语音部分的处理。而随着经济、文化的国际化趋势不断增强,未来的英语教育可能会对录音内容的标注提出更高的要求。例如,加入基于说话人识别的播音人员标签、基于情感分类的情感标签等。这方面的标注信息除了要在本文所研究的内容表征模型中留出了接口外,更需要面向具体的学习情景和学习内容进行更深入的分析。
在人工干预的处理方面,本文中提到的引入人工干预是为了学习模型的更新和改进。但是这种人工干预本身带有一定的主观性,并且随着录音素材的数量增加,会导致人工工作量的递增。随着大数据技术的发展,未来通过建立具有自动判断、自动修正的录音内容标注大数据模型已成为可能。基于大数据模型,计算机不但可以自己找到已有标注中存在的差错,更可能发现内容表征模型自身的不足,并提出修正方式。
录音教材内容加工的标准化是另一个值得深入研究的问题。如本文中涉及的多层级内标签、后端应用模块接口等在实际应用中需要标准化。传统录音教材,无论是磁带或CD等形式,都早已实现标准化。考虑到录音教材今后仍是语言教学中影响范围极大的核心课程资源,当其必须进一步完成数字化、结构化、碎片化发展时,显然非标准化的录音教材将在教学应用中造成诸多问题。这也意味着通过进一步的标准研究来满足录音教材在管理、应用方面的新需求是一个必须解决的课题。
参考文献:
[1]教基二〔2014〕8号.中小学教科书选用管理暂行办法[Z].
[2]唐舒岩.数字技术条件下语言类录音教材产品的音频编辑加工模式[J].海峡科学,2013(8):62-64.
[3]武桂香.英语录音教材内容质量把控初探[J].课程·教材·教法,2013,33(6):62-76.
[4]G.Salton,C.Buckley.Term-weighting approaches in automatic text retrieval[J]. Information Processing and Management,1988,24(5):513-523.
(编辑:鲁利瑞)
猜你喜欢
科技创新与应用(2017年6期)2017-03-23
电脑知识与技术(2016年30期)2017-03-06
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
湖南大学学报·自然科学版(2016年4期)2016-08-12
软件(2015年5期)2015-08-22
