
基于改进OpenPose算法的猪只行为识别方法
2022-06-25 08:41:10李光昌刘飞飞李嘉豪
河南农业大学学报 2022年3期
李光昌,刘飞飞,李嘉豪
(1.江西理工大学机电工程学院,江西 赣州 341000;2.江西理工大学电气工程与自动化学院,江西 赣州 341000)
随着中国生猪养殖业向着规模化方向推进,生猪疾病防控难的问题逐渐显露。非洲猪瘟等传染性疫病频繁发生,造成众多生猪养殖企业经营困难,猪肉供需严重失衡,猪肉价格大幅上涨,对社会民生造成不良影响[1-3]。因此,及时快速了解猪只健康状态对其疾病防控十分重要。猪只行为是较为容易获取的生物学信息,同时也是衡量猪只健康状态的重要指标[4]。研究表明,猪只在极度疲乏或过热时会侧卧,在处于寒冷状态时会将四肢缩于腹下而趴卧,在呼吸困难时会犬坐[5-6]。基于此,利用人工智能技术对猪只行为进行识别[7-8],不仅可以及时发现异常猪只,解决人工监控带来的劳动强度大、主观性强等问题,而且也减少人与猪只的接触,降低传染性疾病发生的概率。
目前,国内外学者针对猪只行为识别的研究分为2类。一类是基于传统图像处理算法,通过图像预处理和图像分割等技术提取图像特征,利用支持向量机、神经网络等方法对猪只行为进行分类。该类方法对系统硬件性能要求较低,但是识别效果依赖于图像分割效果,易受光照等环境因素影响。谭辉磊等[9]提出基于轮廓的猪只饮水行为识别方法,该方法在识别速度以及识别质量上有一定的突破。VIAZZI等[10]对连续图像间的像素差异进行分析,提出了利用图像分析自动检测猪只之间攻击行为的方法。JONGUK等[11]使用Kinect深度相机提取猪只行为信息,并利用支持向量机分层检测攻击行为,降低了整体成本效益,提高了准确性。另一类是基于深度学习,通过对较深层次的卷积神经网络[12]模型进行训练,使得模型可以对猪只某类行为进行识别。该方法可以削弱光照等因素对识别结果的影响,但是模型训练与调优需要消耗大量时间。李菊霞等[13]提出了基于YOLO v4的猪只饮食行为检测模型,该检测模型在不同视角、遮挡程度以及光照条件下均能准确检测猪的饮食行为。季照潼等[14]采用YOLO v4对包括侧卧、站立在内的育肥猪的行为进行识别,有效克服了环境中不同光照强度和噪声的影响。上述2类方法都是对猪只个体的整体特征进行分析,导致模型的扩展能力减弱,例如YOLO、R-CNN系列等目标检测算法只能对预先设定好的行为进行识别[15-16];若要扩充识别的行为类别,需要对模型进行重新训练和调优,整个过程将消耗大量的时间。因此,本研究从分析猪只个体的关键点局部特征角度出发,将猪只行为识别过程进行分解。首先构建猪只姿态估计模型提取猪只骨骼关节点坐标,然后计算猪只关节点间距与骨骼关节角度特征,最后利用K-近邻算法[17](K-nearest neighbor,Knn)对猪只行为分类。
针对生猪规模化养殖中猪只行为识别效率低、多目标识别效果差以及实时性差的问题,本研究以江西省赣州市某猪只培育基地采集到的4 000幅猪只图像作为数据集,借鉴卡内基梅隆大学(carnegie mellon university,CMU)在2016年提出的OpenPose人体姿态估计算法[18]的核心思想,利用CSPDarknet网络[19]改进其特征提取网络,引入残差结构(residual block)[20]改进其分支网络,最终提出了实时多猪只目标行为识别方法,为猪只健康状态的快速判别提供依据,进而为推进中国生猪养殖智能化和规模化提供理论基础。
1 材料与方法
1.1 数据集准备
猪只图像数据采集于江西省赣州市某猪只培育基地。在猪舍中,使用海康威视的DS-2DC2402IW-D3/W型摄像机分别在1 d中的不同时间段以不同视角、不同遮挡程度和不同位置拍摄视频。拍摄时猪只距离镜头1~3 m,镜头中猪只数量在1~5只。在对采集到的视频按1 帧·s-1抽取图像,在抽取到的图像中均匀选出4 000幅清晰图像作为试验数据集。采用旋转、镜像、放缩等操作,将数据集图像拓展到12 000幅,同时将图像尺寸统一调整为360像素×520像素,以减少运算量,提高模型训练速率。通过长时间的观察并结合相关研究[5-6]发现,猪只在生长过程存在4种发生频次较高的行为,包括趴卧、侧卧、站立与犬坐,如图1所示。

图1 猪只4种常见行为Fig.1 Four common behavior of pigs
使用Lableme标注工具对猪的头部、颈部、背部、臀部、左前肘部、左前足部、右前肘部、右前足部、左后肘部、左后足部、右后肘部、右后足部以及猪的行为类别进行标注,标注信息逐个保存到Json类型文件中,标注示意如图2所示。由于自制数据集的数据量较少,本研究引入StanfordExtra狗数据集[21]作为姿态估计模型的预训练数据集。该数据集包含12 000幅带有2D关键点标注的野狗图像,其中被标记的关键点包括蹄部和肘部等,共计23个。本研究对该数据集进行了2次标注,扩充标注内容包括背部关键点和颈部关键点。
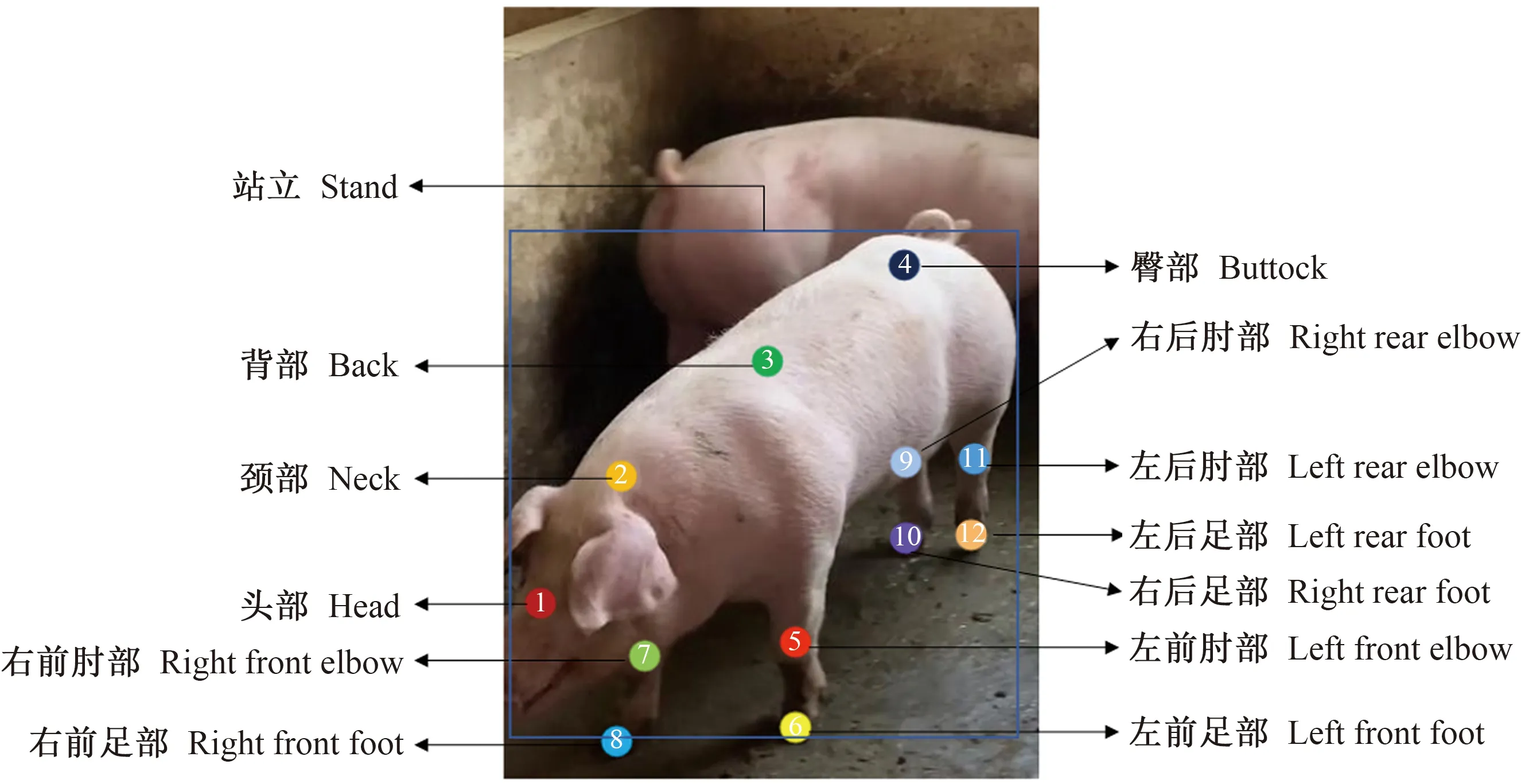
图2 猪只站立行为标注示意图Fig.2 Schematic diagram of pig standing behavior labeling
1.2 猪只行为识别流程
基于改进OpenPose的猪只行为识别方法流程如图3所示。首先将视频流中提取出的视频帧图像通过改进OpenPose姿态估计模型,提取到猪只骨骼关节点坐标,利用关节点坐标计算出关节点间距和骨骼关节角度,最后通过Knn算法对猪只行为分类。

图3 基于改进OpenPose的猪只行为识别方法流程图Fig.3 Flow chart of pig behavior recognition method based on improved OpenPose
2 猪只行为特征提取与分类
2.1 猪只姿态估计
2.1.1 OpenPose网络结构 OpenPose的网络结构分为2部分,如图4所示。一是特征提取网络,对输入图像进行特征提取生成特征图F(feature maps)。二是姿态预测网络,由6个阶段组成,每个阶段包含2个分支。分支1预测猪只身体上关键点的位置,分支2预测关键点间的亲和力。在每个阶段之后,来自2个分支的预测以及特征提取网络生成的特征图,被连接到下个阶段。最后在第6阶段输出关键点置信图(confidence map for parts,CMPs)以及肢体亲和度向量场(part affinity fields,PAFs)。
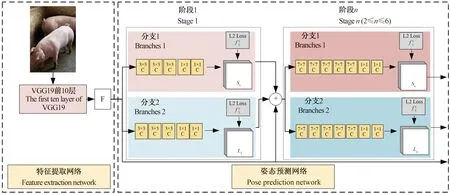
注:F表示特征提取网络输出的特征图;C表示卷积操作;Sn表示阶段n中分支1的输出特征图;Ln表示阶段n中分支2的输出特征图;表示阶段n中分支1的损失函数;表示阶段n中分支2的损失函数。Note:F represents the feature graph output by feature extraction network;C represents convolution operation;Sn represents the output feature graph of branch 1 of stage n;Ln represents the output feature graph of branch 2 of stage n; represents the loss function of branch 2 of stage n.图4 基于OpenPose的猪只姿态估计模型网络结构Fig.4 Network structure of pig pose estimation model based on OpenPose
模型中的每个阶段都会采用L2 Loss计算各个分支的损失,以使各分支的训练向着正确的方向进行,分支的损失函数如公式(1)和公式(2)所示。
(1)
(2)
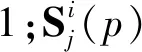
(3)
2.1.2 OpenPose网络改进 在OpenPose原模型中,采用 VGG19[22]前10层作为特征提取网络,其结构如图 5所示。VGG网络证明了增加网络深度可以在一定程度上提高网络的性能,但当网络达到一定的深度后,增加网络深度不仅不能提高性能,反而会造成网络的收敛速率变慢,检测性能变差。此外,在VGG网络输出中仅包含深层特征,使得输出中包含的小目标信息量较少,不利于足部关键点的识别。
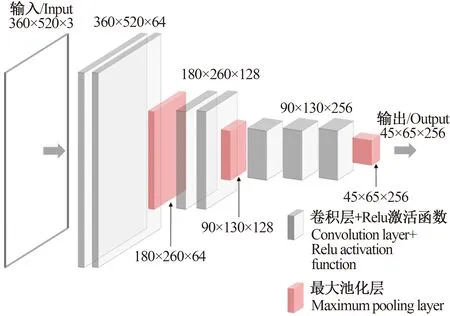
图5 OpenPose特征提取网络Fig.5 OpenPose feature extraction network
为解决上述问题,本研究使用修改后的CSPDarknet作为模型的特征提取网络,CSPDarknet主要由若干个跨阶段部分模块(cross stage partial,CSP)构成[23],CSP模块的结构如图6所示。
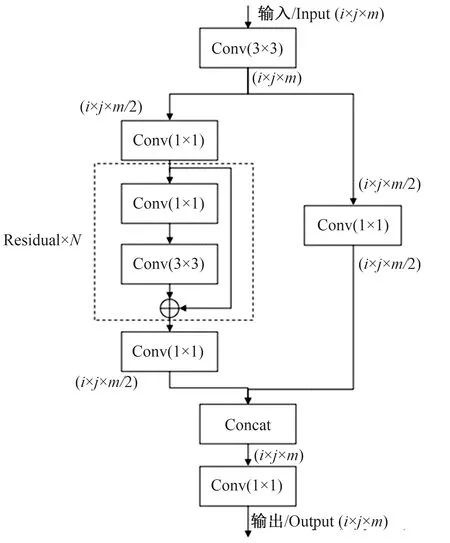
图6 CSP模块结构Fig.6 CSP block structure
CSP模块中使用了若干个1×1大小的卷积核进行卷积,同时加入残差结构(residual block),有效提高了模型的非线性,缓解了梯度消失和梯度爆炸问题,使得网络可以构建的更深。此外,CSP模块对深层特征和浅层特征进行融合,提高了对不同尺寸目标的识别能力。通过以上分析,本研究借鉴CSPDarknet网络结构的优点,改进OpenPose原特征提取网络,并且在特征提取网络的最后引入空间金字塔池化[24](spatial pyramid pooling,SPP),实现局部特征与全局特征的融合以及输出特征图尺寸的统一,改进后的特征提取网络如图7所示。
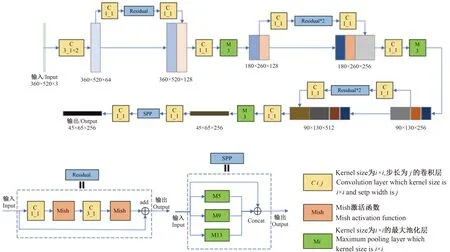
图7 改进后的特征提取网络Fig.7 Improved feature extraction network
卷积神经网络中,模型参数量只与卷积层和全连接层的相关参数有关,池化层与激活函数均不影响模型的参数量。假设1个卷积层的输入特征图的通道数为Cin,输出特征图的通道数为Cout,卷积核的大小为m×m,则该卷积层需要训练的权重参数数量S可由公式(4)计算。
S=Cin×Cout×m×m+D
(4)
由公式(4)可以计算出OpenPose原模型特征提取网络需要训练的参数数量为1 734 336个,改进后的特征提取网络其参数数量为1 394 368个,改进后的特征提取网络相较于原模型特征提取网络参数量减少了19.60%。
OpenPose原模型中,在每个阶段n(n≥2)中,使用了多个大小为7×7的卷积核,使得计算量增大,增加了训练难度。因此,本研究在保证感受野不变的情况下,引入残差结构,使用3个大小为3×3的卷积核代替1个7×7的卷积核,结构如图8所示。在OpenPose原模型中,各分支中7×7卷积层的输入特征图通道数与输出特征图通道数相等,在分支最后通过2个1×1的卷积层,将输出通道数降为与监督信息相对应的通道数。假设7×7卷积层的输入特征通道数为i,则7×7卷积层的参数量为49i2,使用图 8所示的结构,其参数量为31i2,参数量减少了36.7%
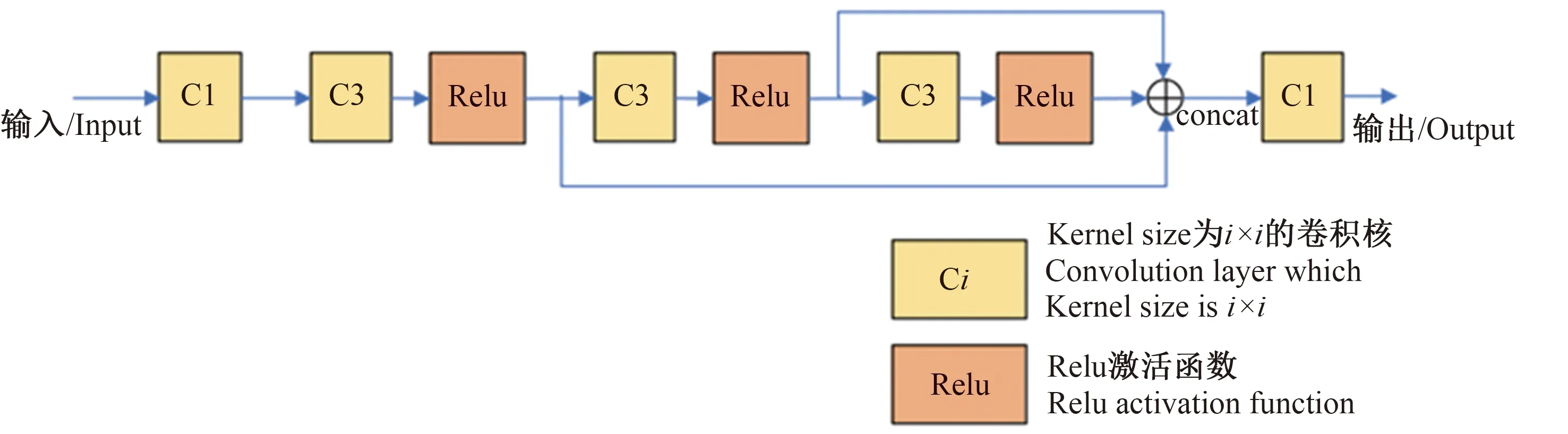
图8 残差结构改进7×7卷积核Fig.8 Residual structure improved 7×7 convolution kernel
2.2 关节点间距与关节角度特征提取
本研究选取了15组关节点间距和10组骨骼关节角度作为猪只行为的特征,各个特征定义如图9所示。以图9-b中2段骨骼AC与BC为例,其对应的关键点坐标分别为A(x1,y1)、B(x2,y2)和C(x3,y3),则关节角度θ可以由公式(5)计算。
(5)
对于关节间距可由公式(6)计算。
(6)
式中:Lk表示编号为k的关节间距,(xi,yi)与(xj,yj)表示关节点坐标。由于不同个体体型对关节间距存在影响,因此本研究对所有关节间距进行了归一化处理。归一化后关节间距Lk-Norm可由公式(7)计算。
(7)
式中:max(L)表示该个体的最大关节间距。
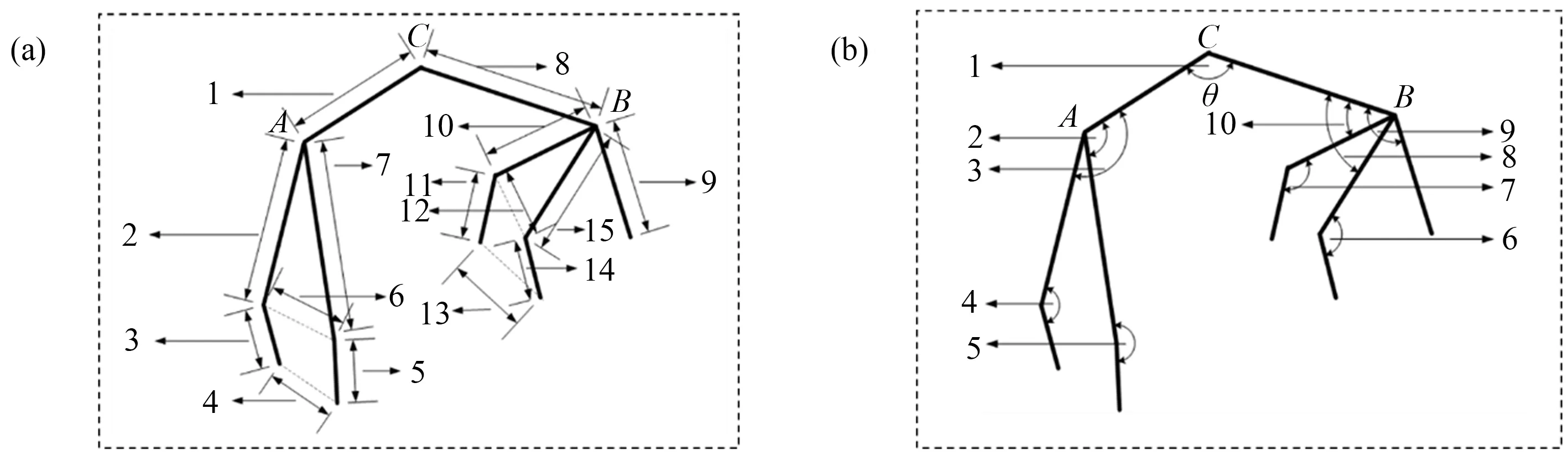
注:(a)表示关节点间距位置;(b)表示骨骼关节角度位置;不同数字表示选取的不同骨骼关节角度及关节点间距。Note:(a)represents the distance between joints;(b) represents the angle position of bone joint;Different numbers represent different bone joint angles and joint spacing.图9 站立行为特征示意图Fig.9 Schematic diagram of standing behavior characteristics
2.3 猪只行为分类
本研究采用Knn算法对猪只行为进行分类。Knn算法的思路简捷,当输入某未知样本时,和未知样本最接近的K个样本中,所占比例更多的类别决定未知样本的类别。本研究采用欧氏距离表示未知样本与已知样本的距离,n维特征空间中的2点x1(x11,x12,…,x1n)与x2(x21,x22,…x2n)之间的欧氏距离计算如公式(8)所示。
(8)
Knn算法中K取值的不同会影响最终对未知样本的分类结果。K取值过小时,邻域空间范围很小,学习的近似误差减小,估计误差增大;K取值较大时,则相反。在试验过程中本研究对所有样本特征的数值都采取归一化处理,并通过交叉验证的方法确定K值。K值确定流程如图10所示。
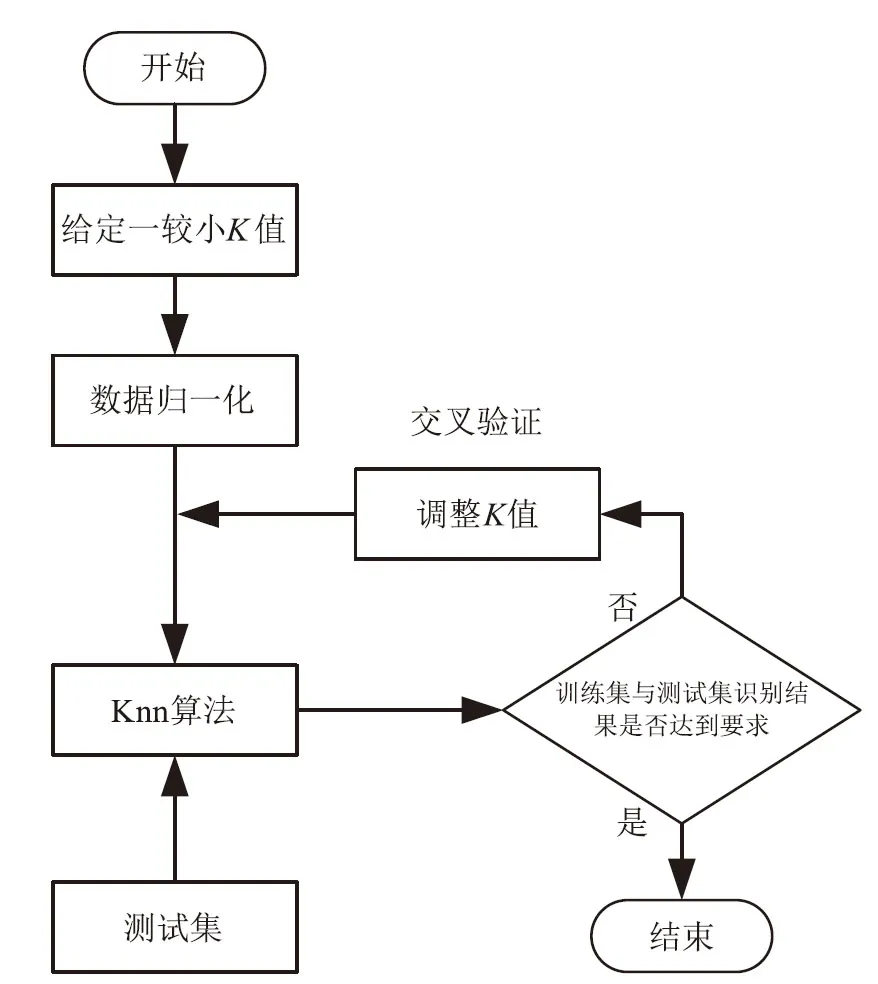
图10 K值确定流程Fig.10 K determination process
3 结果与分析
3.1 评价指标
本研究使用准确率(accuracy,Acc)、精确率(precision,P)和召回率(recall,R)作为模型的评价指标,各指标的计算如公式(9)—公式(11)所示。
(9)
(10)
(11)
式中:TP表示真正例,TN表示真反例,FP表示假正例,FN表示假反例。此外,本研究还使用固定时间帧数法计算模型的实时检测帧率(frames per second,FPS),对模型的运算速率进行评价。FPS计算如公式(12)所示。
(12)
式中:frameNum表示elapsedTime时间内处理的图像帧数,试验中elapsedTime取1 s。
3.2 试验平台与相关参数
模型训练平台,CPU采用Intel Xeon E3-1225 v6,GPU采用NVIDIA GTX 1080ti,显存11 GB,计算机内存为 16 GB,Tensorflow 版本为2.1.0,Python版本为3.6。模型训练相关参数如表1所示。
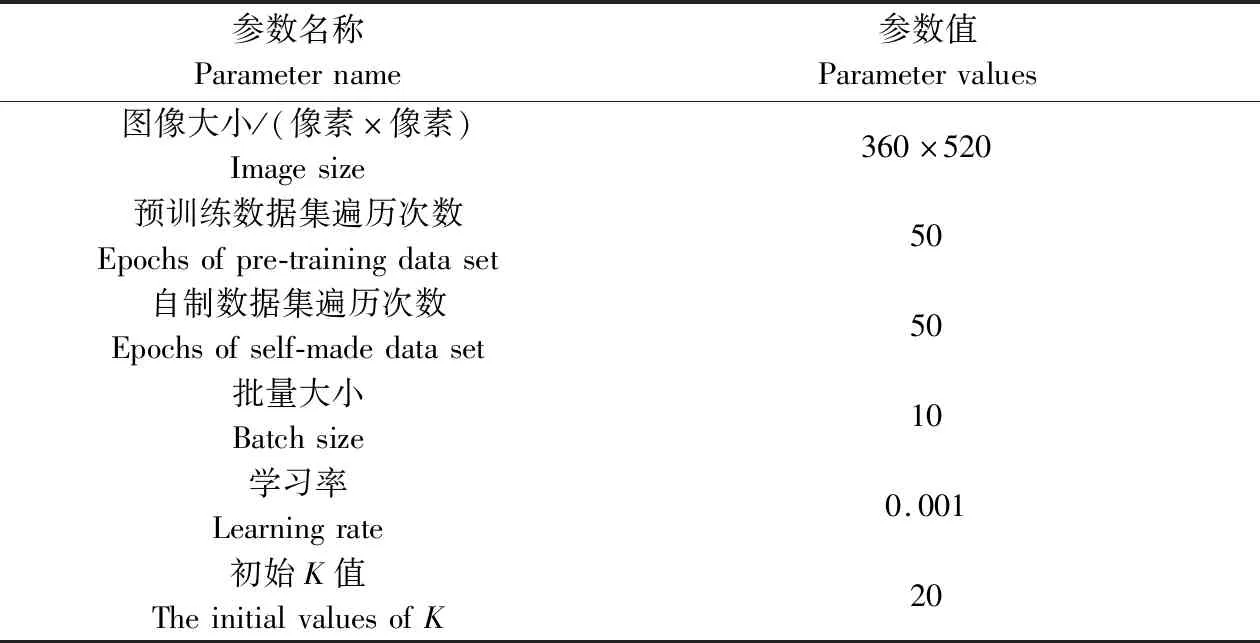
表1 模型训练参数说明Table 1 Description of model training parameters
3.3 与原姿态估计算法对比试验
与原姿态估计算法对比试验共分为4组。第一组使用OpenPose原模型,不进行预训练,直接使用自制数据集训练;第二组使用OpenPose原模型,在经过预训练后使用自制数据集训练;第三组使用改进后的模型,其余与第一组相同;第四组使用改进后的模型,其余与第二组相同。各组在自制数据集上训练过程中的损失曲线如图11所示。在测试集中多次随机筛选200幅图像进行测试,模拟不同环境并测试模型在不同环境下的性能,使最终得出的模型的适应性与鲁棒性更强。试验结果如表2所示,混淆矩阵中的每一列代表样本预测值,每一行代表样本的真实值,所有结果均取最优结果进行对比。改进OpenPose算法对猪只行为识别效果见图12。
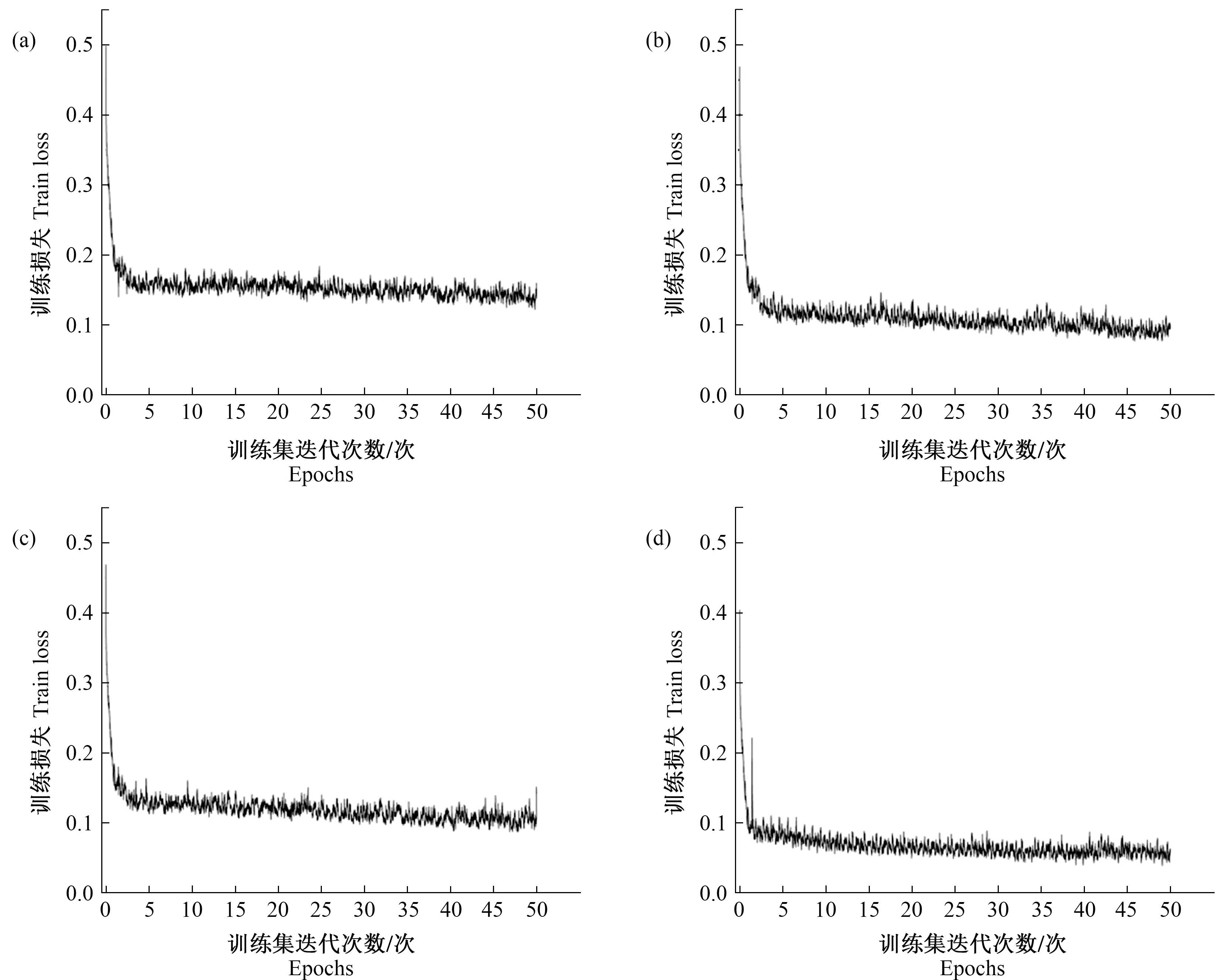
注:(a)为原模型损失曲线;(b)为预训练+原模型损失曲线;(c)为改进模型损失曲线;(d)为预训练+改进模型损失曲线。Note:(a) means the loss curve of the original model;(b) means the loss curve of pre-training + the original model;(c) means the loss curve of the improved model;(d) means the loss curve of pre-training + the improved model.图11 训练过程的损失曲线Fig.11 Training process loss curve

注:(a)为侧卧行为识别效果;(b)为站立行为识别效果;(c)为趴卧行为识别效果;(d)为犬坐行为识别效果。Note:(a) means the recognition effect of side lying behavior;(b) means the recognition effect of standing behavior;(c) means the recognition effect of lying prone behavior;(d) means the recognition effect of dog-sitting behavior.图12 猪只行为识别效果Fig.12 Behavior recognition effect of pigs
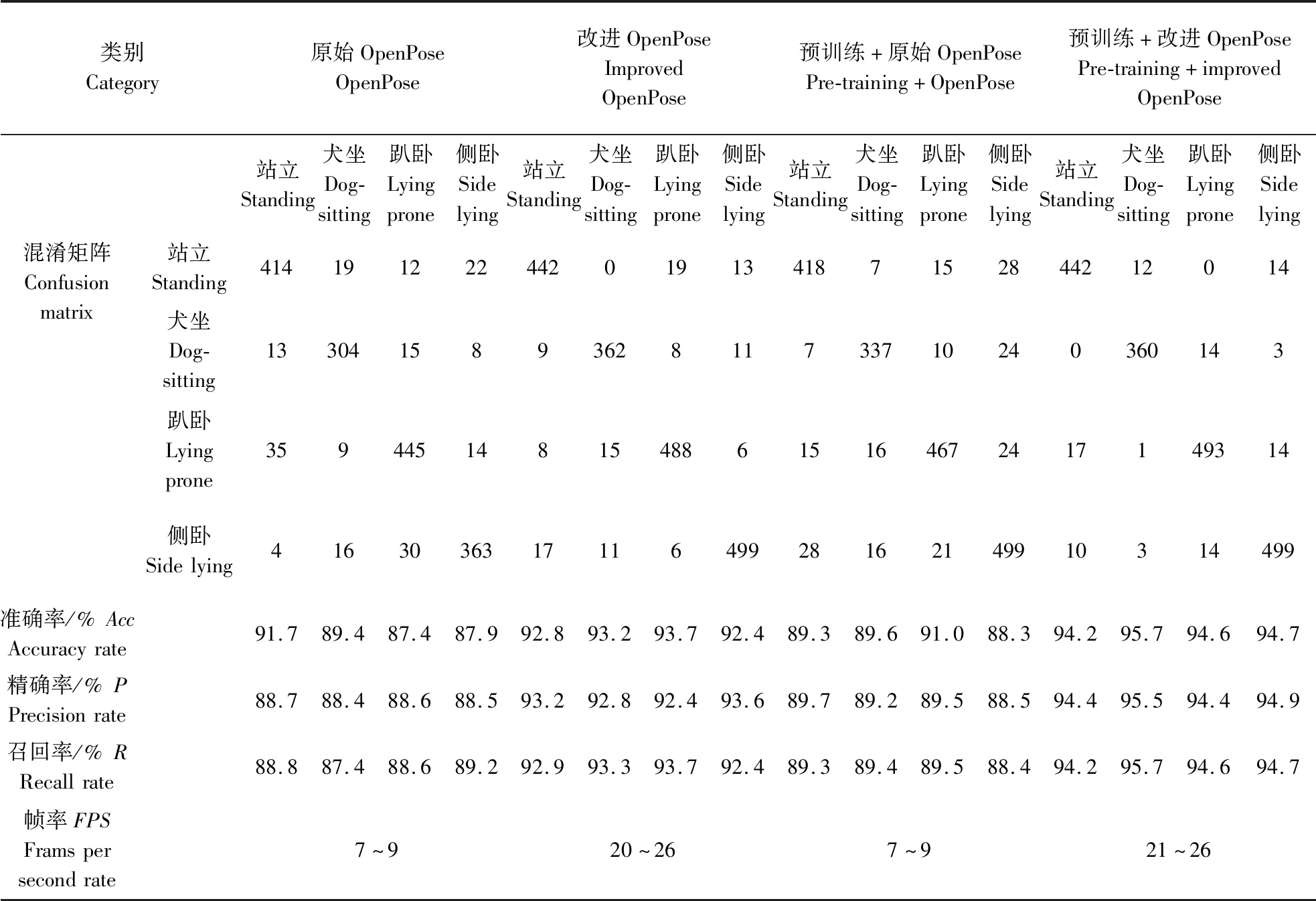
表2 猪只行为识别模型试验结果Table 2 Test results of behavior recognition model of pigs
由表2可知,改进OpenPose模型相比于原模型,猪只行为识别的平均准确率有明显提高。其中,改进OpenPose模型在经过预训练后,对行为的识别准确率提高到94%,FPS由原始模型的7~9提高到21~26;对模型进行预训练,使得模型的识别准确率普遍提高1%以上。试验结果表明,改进后的模型无论是识别的准确率还是识别的速率都优于原模型,此外,通过使用相关数据集对模型进行预训练,可以一定程度上提升模型的检测性能。
3.4 与其他姿态估计模型对比试验
选取DeepCut[25]、Associative Embedding[26]以及DeeperCut[27]姿态估计算法分别构建猪只姿态估计模型,在预训练数据集与自制数据集上训练,利用Knn算法进行行为分类。3种算法测试结果的混淆矩阵如表3所示。将本研究中改进OpenPose算法与上述3种算法进行识别准确率的对比,结果如图13所示。不同姿态估计模型对猪只行为的识别准确率都较高,不同模型之间对行为识别的精度差异较小;采用改进OpenPose算法对猪只行为的识别准确率有明显提升,均达到94%以上,相较于采用DeepCut等算法提高了4%以上。
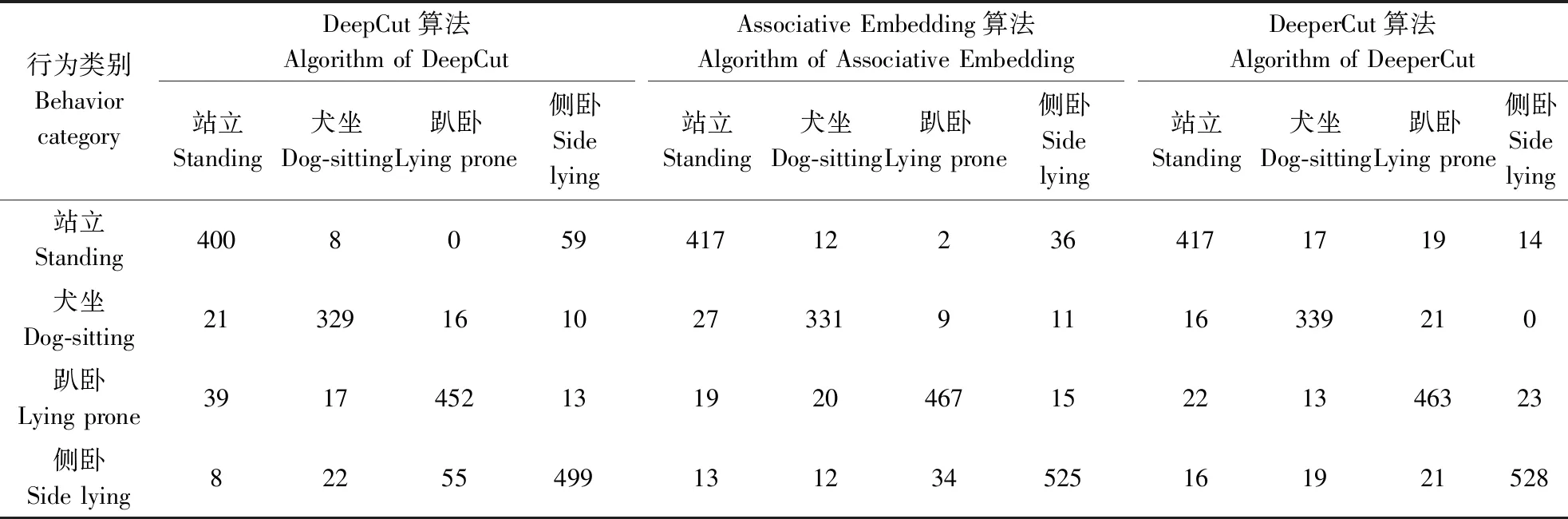
表3 3种模型试验结果的混淆矩阵Table 3 Confusion matrix of three model test results
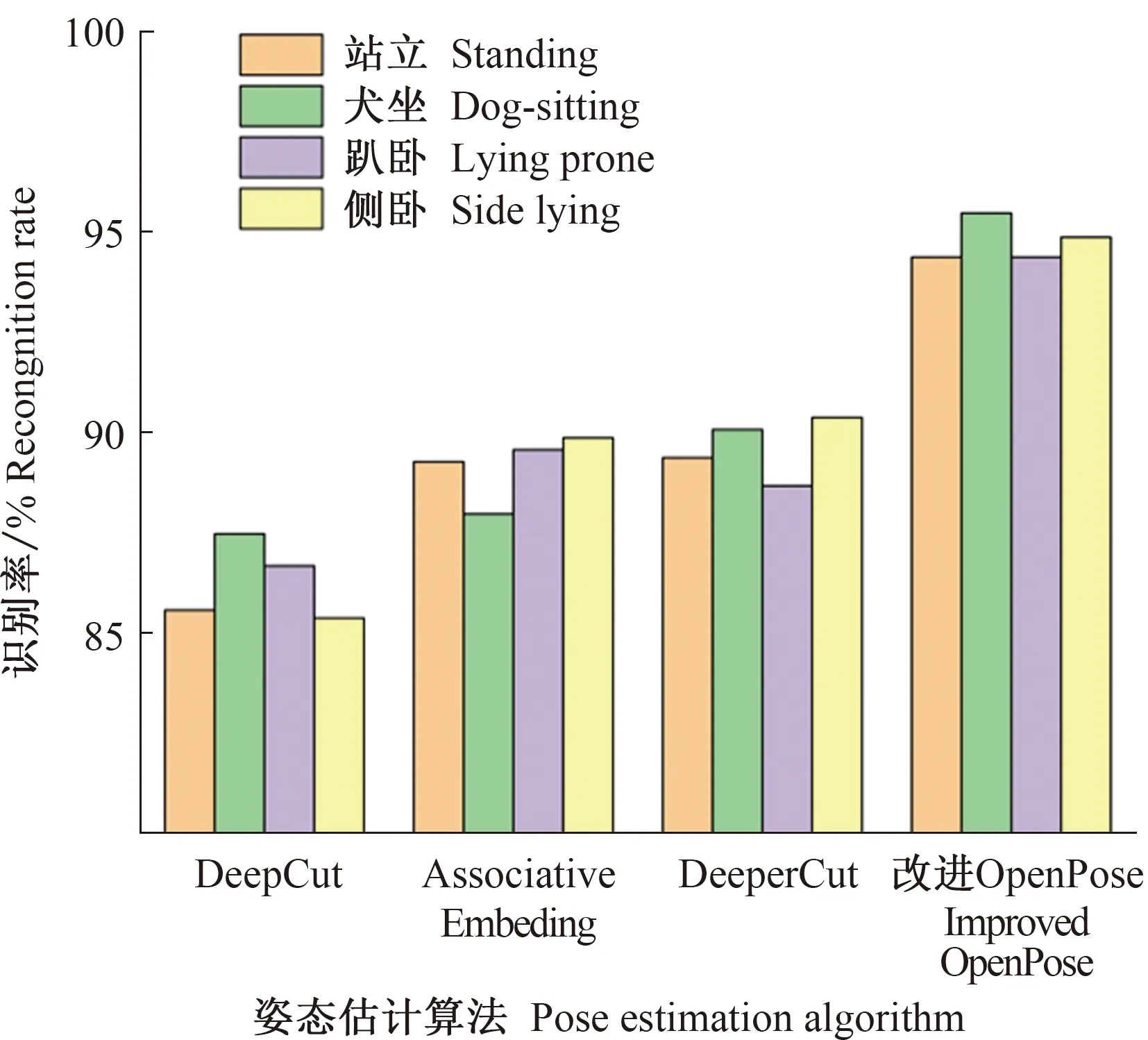
图13 不同姿态估计模型识别精度对比Fig.13 Comparison of recognition accuracy of different pose estimation models
4 结论与讨论
针对现阶段猪只规模化养殖中猪只行为识别效率低、实时性差和多目标检测效果差的问题,本研究提出了基于改进OpenPose算法的猪只行为识别方法。首先借鉴OpenPose人体姿态估计算法并对其改进,构建猪只姿态估计模型,之后在视频流图像中提取猪只骨骼关节点,计算关节点间距与骨骼关节角度描述猪只行为特征,最后利用Knn算法对猪只行为分类。试验结果表明,本研究对猪只行为的识别准确率达到了94%,FPS在21~26之间。相较于采用OpenPose原算法相比,采用改进OpenPose算法对猪只行为识别的准确率与速率均得到提高,推测是因为采用CSPDarknet改进模型的特征提取网络,使得特征提取网络输出中融合了多尺度特征,提高了模型对不同尺度目标的检测能力;同时改进模型相较于原模型参数量大大减少,使得检测速率提高。采用改进OpenPose算法与采用DeepCut、Associative Embedding和DeeperCut算法构建猪只姿态估计模型相比,对猪只行为的识别准确率普遍提高4%以上,主要原因是OpenPose模型使用关键点间连接方向上的线性积分定量描述关键点间的亲和力,充分利用了图像的空间语义信息,使得对关键点的预测与分组更精准。
本研究对猪只站立、犬坐以及趴卧的识别准确率分别达94.2%、95.7%以及94.6%,优于季照潼等[14]基于YOLO v4的识别结果,推测是在检测被遮挡的猪只时,前方的猪只会遮挡后方猪只的部分特征,从而致使基于YOLO v4方法的检测精度下降;而本研究中姿态估计模型会根据空间语义信息对遮挡的关键点进行预测,从而得到完整的骨骼信息用于对行为类别的判断。本研究基于深度学习技术对猪只行为识别,而深度学习模型的结构和人类视觉神经结构相似,对光照等环境因素有很高的适应性,较好解决了谭辉磊等[9]识别结果受光照等环境因素影响严重的问题。此外,相比于YOLO和R-CNN等方法只能对预先设定好的行为进行识别,本研究则可以通过在Knn样本空间中增加猪只某类行为对应的样本来实现对该类行为的识别,减少了扩展行为类别所消耗的时间。本研究能够满足生猪规模化养殖中对猪只行为自动化识别的农业需求,通过分析一段时间内猪只姿态的变化情况判断猪只的活跃程度,进一步为猪只健康异常状态的判别提供辅助决策信息,在今后养殖业智能化和信息化领域具有巨大应用潜能。
猜你喜欢
猪业科学(2022年11期)2022-12-17 08:43:54
中国畜禽种业(2020年4期)2020-12-16 13:52:34
学生天地(2020年3期)2020-08-25 09:04:16
河南畜牧兽医(2020年21期)2020-01-10 00:20:08
电子制作(2018年19期)2018-11-14 02:37:08
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
猪业科学(2018年5期)2018-07-17 05:56:18
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
