
QGA-BP神经网络在农业信贷风险评估中的应用
2022-06-23 00:52郜佳蕾郜佳慧
台州学院学报 2022年3期
郜佳蕾,吴 迪,郜佳慧
(1.合肥财经职业学院 会计金融学院,安徽 合肥 230000;2.齐齐哈尔大学 计算机与控制工程学院,黑龙江 齐齐哈尔 161006;3.济南大学 教育与心理科学学院,山东 济南 250022)
0 引言
农业信贷简称“农贷”,是农业银行和其他农村金融机构对农业生产所需资金发放贷款的总称。其贷款对象是国营农业企业、集体农业企业和农户。农业信贷的风险和不确定性是农业生产企业信用评估的重要指标,但是它在可持续发展的经济分析中经常被忽视[1-5]。Singh等[6]认为忽视风险和不确定性会严重影响可持续性政策的制定。传统农业信贷风险评估仍旧十分依赖相关领域专家的人工操作,工作效率较低,无法满足自动化、信息化的时代需求。在探索信贷风险评估的新方式方面,Wu[7]提出了一种基于反向传播(Back-Propagation,BP)神经网络的风险预警新方法。该方法将BP神经网络和遗传算法(Genetic Algrithm,GA)[8]结合在一起,有效地降低了公司信贷风险,所得出的风险评估结果与专家的评估结果十分接近。GA的编码技术易于实现,传播机制简单,简化了复杂的进化过程,但在实际应用中,GA类似于启发式搜索算法的特点,会导致搜索时间长、速度慢、过早收敛等综合问题。
为了改进GA-BP神经网络存在的缺点,本文通过引入概率进化机制提出了一种量子遗传算法(Quantum Genetic Algorithm,QGA)与反向传播结合的QGA-BP神经网络模型,并将其应用于农业信贷风险评估中。
1 QGA-BP神经网络模型
如图1所示,QGA-BP神经网络模型共分为两个模块,第一部分为数据预处理模块,负责将搜集的数据集进行分组处理。第二部分为QGA-BP模块,该模块首先将预处理的数据输入到神经网络的输入层,并通过卷积操作对数据进行分析,然后将分析后的数据与正确的结果对比,如果与期望结果相符,则输出层会输出1并且停止训练;如果与期望结果不相符,则输出层会输出0并且继续迭代训练,直到输出层输出结果为1。

图1 QGA-BP神经网络结构图
1.1 量子遗传算法QGA
QGA是基于GA算法改进的一种新型优化算法[9-10]。首先,将量子态看作是一个原始的信息块;然后,将量子态的多态性表示为重叠状态,具体方式就是借助量子态向量,结合量子位编码对量子染色体进行标记。在标记过程中,每条染色体通过对应的量子旋转门来更新重叠状态,这种更新可以被看作为种群进化,从而求解出种群的最佳个体位置。
QGA解的形式由二进制串表示,每个串为0或1,根据量子位的概率振幅选择。具体的测量过程是在[0,1]的区间内随机生成一个数字。当得到的数值大于概率振幅的平方时,将测量结果设置为1,否则就把测量的结果设置为0。QGA避免了计算误差对量子位编码的影响,且消除了噪声的负面影响等[11-13]。
1.2 通过QGA优化BP神经网络
为了克服传统GA-BP神经网络的收敛速度慢和经常陷入局部最优解的问题,本文通过QGA来优化BP网络的权值,设计了QGA-BP神经网络模型,使模型的输出值尽可能地接近目标函数解,从而在特解空间寻找较好的搜索域。QGA-BP算法的操作过程如下:
(1)初始化人口Q(t0)。假设总体数为n,所有量子位的数m。,其中代表第t代的第i个个体。种群个体的所有量子位编码(α,β)T均初始化为。
(2)利用量子坍缩[14-15]的操作来处理初始种群。将确定的种群记录为,其中表示第t代个体的第t个测量值,以二进制字符串的形式表示,长度为m。
(4)QGA进入循环计算。保留Q(t0)中最好的个体估计,并将此个体更新为新的进化目标。当满足期望的最大迭代次数或误差平方和小于指定的精度时,会立即完成计算。
(5)如果算法不能提前退出迭代,将通过动态调整策略和灾难策略的变化原则,对个体进行更新,从而获得下一代的新种群。
(6)将迭代次数增加1次,继续进行量子坍缩操作。
1.3 模型在农业信贷风险评估中的应用
将QGA-BP神经网络模型应用于农业信贷风险评估中。农业信贷风险评估结果的编码若设置为[01],则表示风险正常;若设置为[10],则表示风险不正常。该模型的传递函数采用了Sigmoid函数,训练函数采用负梯度函数来定义,再根据数据集、传递函数和训练函数来训练模型。具体采用的数据样本为上海农业银行授权使用的农业信贷数据(主要包含我国华东地区23个城市及地区在2010—2020年期间农业相关企业的历史融资信息)。首先,将该数据集平均划分为100组,每组包含50条数据。然后,将该数据集作为非线性函数输出,从中随机选择70组即3500条数据作为训练样本,并将其余30组即1500条数据用于测试样本。每一组数据包含5个输入向量和2个输出向量,训练数据后可以得到模型。
根据样本的输入向量长度,将网络中的输入神经元数设置为I,并根据样本的输出向量长度,将输出神经元数设置为O。隐层神经元数M由经验公式确定:

其中,a是一个介于1到10之间的常数。经过200次训练后,三层网络模型的架构为5-10-2,学习率为0.0001,目标准确度为10-10,最大迭代次数为1000次。
2 应用实验
2.1 评价指标
采用夏普比率来衡量投资收益与风险的关系。夏普比率[16-17]表示每承受一单位风险,预期可拿到多少超额收益。夏普比率大于1,说明收益大于风险;小于1,说明收益小于风险,其定义如下:

2.2 实验环境与结果
在中央处理器为Intel(R)i5-9300H CPU@2.40 GHz、显卡为NVIDIA GeForce GTX 1050的笔记本电脑中完成了仿真工作。仿真软件为MATLAB 2019b。设置QGA的参数:染色体的长度为5×10+10×2+10+2=82,即82个变量参数。每个变量参数的基因位为20,每个变量参数值的范围为[−7.5,7.5],种群总数为40次,QGA的最大迭代次数为60次。
图2是QGA-BP神经网络目标函数的自适应收敛过程;图3是GA-BP神经网络目标函数的自适应收敛过程。从图2和图3可以看出,QGA-BP模型具有收敛速度快和不易陷入局部最优解的优点。迭代时间经过4 s进化后,个体的适应度值开始显著上升;到6 s时,个体的适应度值继续被优化;进化9 s以后,个体的适应度值基本趋于稳定,说明此时个体的适应度值已完全达到该操作的最优值。总的来说,QGA-BP模型的最优适应度值明显优于传统的GA的最优适应度值,更适合应用于农业信贷风险评估。
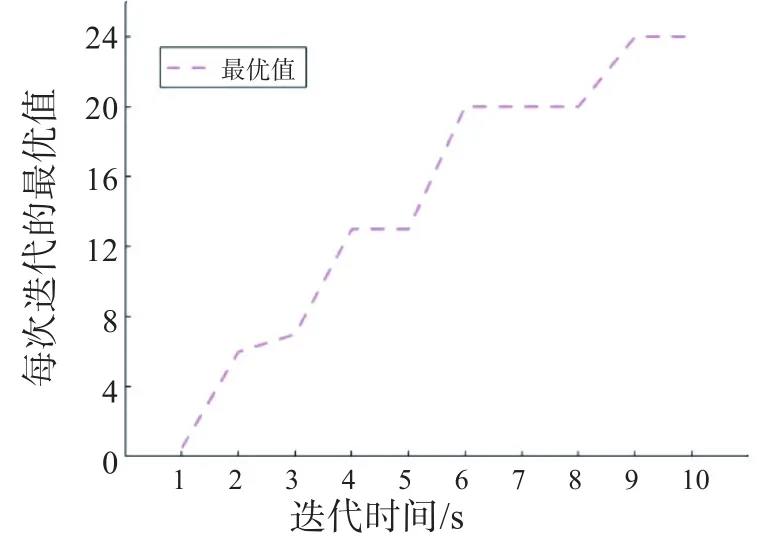
图2 QGA-BP的自适应收敛过程
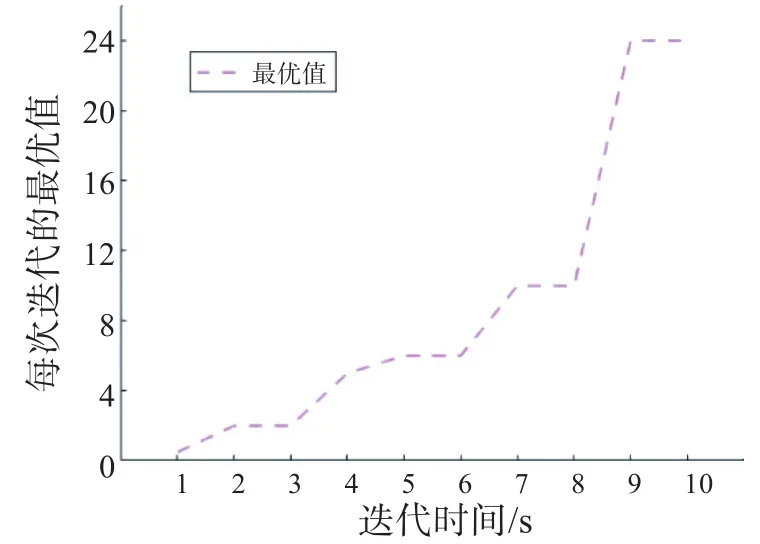
图3 GA-BP的自适应收敛过程
两种神经网络的自适应收敛曲线分别如图4和图5所示。可以看出,QGA-BP模型的训练误差从一开始就呈现线性下降的趋势,而且下降速度非常快。当迭代时间为15 s时,平方根误差达到最小,接近0,收敛速度和收敛精度均优于GA-BP神经网络。

图4 QGA-BP神经系统的训练误差

图5 GA-BP神经系统的训练误差
农业信贷评估的夏普比率对比结果如表1所示。

表1 QGA-BP网络和GA-BP网络对农业信贷评估的夏普比率
从表1可以看出,在应用于农业信贷风险评估时,QGA-BP神经网络的夏普比率明显高于GA-BP神经网络。总体来说,当QGA-BP模型应用于农业信贷风险评估时能够达到预估的结果,克服了GA-BP模型收敛速度慢和不成熟的问题,同时节省了计算量,提升了训练效率。
3 消融实验
因隐含层中存在大量的神经元,合理地设计神经元的个数不仅能减少计算量,加快计算速度,而且有利于QGA-BP模型对农业信贷风险的评估。因此,本文针对如何设置神经元的数量做了大量的消融实验,实验结果如表2所示。

表2 隐含层神经元个数对网络模型的影响
从表2中可以看出,为了研究每层神经元数量对网络模型的影响,选择了不同数量的神经元。对比表2的结果表明:神经单元的数量太少、网络的拟合能力不足将导致评估的风险值与实际的风险值差别太大。当隐含层数的数量继续增加时,评估的风险值与实际的风险值差值逐渐减小,但是神经元数量的增加会导致系统效率下降和训练所需时间的增加。因此,在QGA-BP模型中,将每层的单位数设置为480个比较合适。
4 结语
本文利用QGA对BP网络进行优化,并应用于农业信贷风险评估。通过实验数据验证了所提QGABP模型的有效性。结果表明:与传统的GA-BP模型相比,QGA-BP模型收敛速度快,解决了迭代冗余问题和任意陷入局部最优解的问题,有效提高了农业信贷风险评估的精度。后续研究中继续尝试将QGABP模型应用于企业财务、灾害风险评估等领域,从而进一步验证其适用性和鲁棒性。
猜你喜欢
量子电子学报(2022年1期)2022-02-25
信息技术时代·上旬刊(2020年1期)2020-09-10
小学科学(学生版)(2020年1期)2020-01-19
科学大众(中学)(2019年2期)2019-04-08
现代装饰(2018年5期)2018-05-26
西安工程大学学报(2016年6期)2017-01-15
大陆桥视野(2016年12期)2016-12-27
科技经济市场(2016年4期)2016-07-20
中国商论(2016年33期)2016-03-01
中国生化药物杂志(2015年4期)2015-07-07
