
改进ShuffleNet V2的轻量级农作物病害识别方法
2022-06-23 06:25邱卫根张立臣
计算机工程与应用 2022年12期
李 好,邱卫根,张立臣
广东工业大学 计算机学院,广州 510006
粮食安全问题一直是全球重点关注议题,我国“十四五”规划纲要明确提出“实施粮食安全战略”,强调确保国家粮食安全。受全球气候和环境因素影响,农作物病害频繁发生,对粮食生产产量和质量造成严重影响,是我国粮食安全和可持续稳定发展农业面临的重大困难挑战[1]。在传统的农业生产实践中,由于缺乏专业知识,农民一般都是根据经验通过肉眼观察来识别作物病害,不仅主观,而且成效甚微,易出现误判,农药使用不当,严重影响粮食的质量和产出,同时也带来经济损失及不必要的环境污染[2]。因此,对农作物病害及时准确识别和有效防治在农业生产管理和决策中发挥着至关重要的作用,有助于提升农作物的产量和质量,确保粮食安全。
近年来,深度学习技术因能自动提取作物病害叶片特征进行识别,避免人工特征提取依赖,在农作物病害识别的研究中取得了良好进展并广泛应用[3-5]。Mohanty等人[6]首次引入深度学习方法到农作物病害识别,基于AlexNet[7]和GoogLeNet[8]两种经典的CNN模型进行迁移学习,证明深度学习方法在农作物病害识别具有高性能和可用性,为后续研究提供了方向。Too等人[9]通过多种经典CNN模型进行迁移学习,如VGGNet[10]、Inception V4[11]、ResNet[12]和DenseNet[13],比较它们在公共数据集PlantVillage[14]上的病害识别性能,结果表明DenseNet提供了最好的分类结果。但以上方法中的网络模型深且复杂,在农业生产实践中不能有效部署在计算资源有限的低性能边缘移动终端设备,如农业生产者手中的新型“农业工具”手机、农业机器人、无人机等。
为了解决深度学习模型的移动部署问题,研究者们提出了各种轻量级架构[15-16],如Xception[17]、MobileNet[18-19]、ShuffleNet[20-21],以及常用的轻量化网络设计结构深度可分离卷积(depthwise separable convolution,DepthSepConv)和分组卷积(group convolution,GC),为农作物病害识别方法落地部署提供强有力的技术支撑。国内外有关农作物病害识别模型的移动部署,一般可通过手机等移动端上的app软件或小程序实现,近年来,在室内农业这方面可通过地面移动监测平台等智能机器进行落地部署;在室外农业这方面,无人机被认为是一种有效且高度推荐的工具[22],用于不同的农业应用,如农作物病害识别,作业效率高。针对上述研究,本文提出一种改进ShuffleNet V2的轻量级农作物病害识别方法。引入ECA注意力机制对ShuffleNet V2单元进行改进,提出一种Shuffle-ECA单元设计方法,并在PlantVillage[14]数据集中经过随机组合增强的5种作物26类病害数据上进行实验评估。与原ShuffleNet V2模型的病害识别比较表明,改进模型在保持轻量化的同时具有较高效的模型性能,可为设计适合在低性能设备部署的病害识别模型提供参考。
1 相关工作
1.1 深度可分离卷积
标准卷积(standard convolution)和深度可分离卷积(DepthSepConv)如图1所示,其中BN表示批量归一化,ReLU代表激活函数。
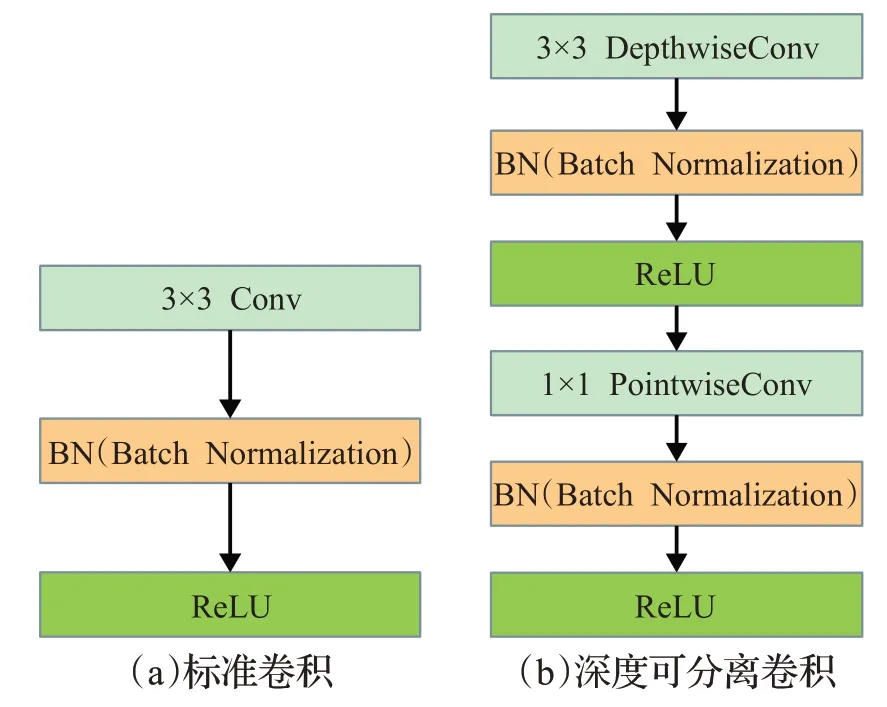
图1 标准卷积与深度可分离卷积Fig.1 Standard convolution and DepthSepConv
标准卷积的运算特点是每个卷积核的通道与输入通道相同,每个通道单独做卷积运算后相加。
标准卷积参数量(parameters,P)大小为:

式中,K×K为卷积核大小,C为输入特征图通道数,N为卷积核数量即输出特征通道数。
标准卷积计算量(FLOPs,F)大小为:
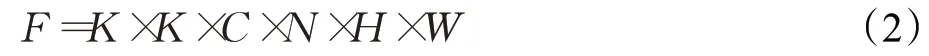
式中,H、W为输入特征图的长和宽。
深度可分离卷积分为深度卷积(3×3 DepthwiseConv)和点卷积(1×1 PointwiseConv),深度卷积中一个卷积核只负责一个通道的计算;点卷积会将上一步骤深度卷积输出的特征图在深度方向进行加权混合,生成新的特征图。
深度可分离卷积参数量大小为:

与标准卷积中每个卷积核都需要与特征图的所有通道进行计算相比,深度可分离卷积中深度卷积每个卷积核都是单通道进行计算,再在后面接上1×1卷积,由公式(5)可得,大大减少了计算量与参数量,又可以达到相同的效果。深度可分离卷积在MobileNetV1中被提出,渐渐成为轻量化网络设计的常用组件,使边缘设备、移动终端部署神经网络模型成为可能。
1.2 分组卷积与通道混洗
常规卷积与分组卷积如图2所示,常规卷积是一种通道密集连接方式(channel dense connection),会对输入特征(input features)的整体即每个通道都一起做卷积操作生成特征图,卷积核数量为N,则输出特征(output features)的通道数也为N,参数量P由公式(1)可得为K×K×C×N。
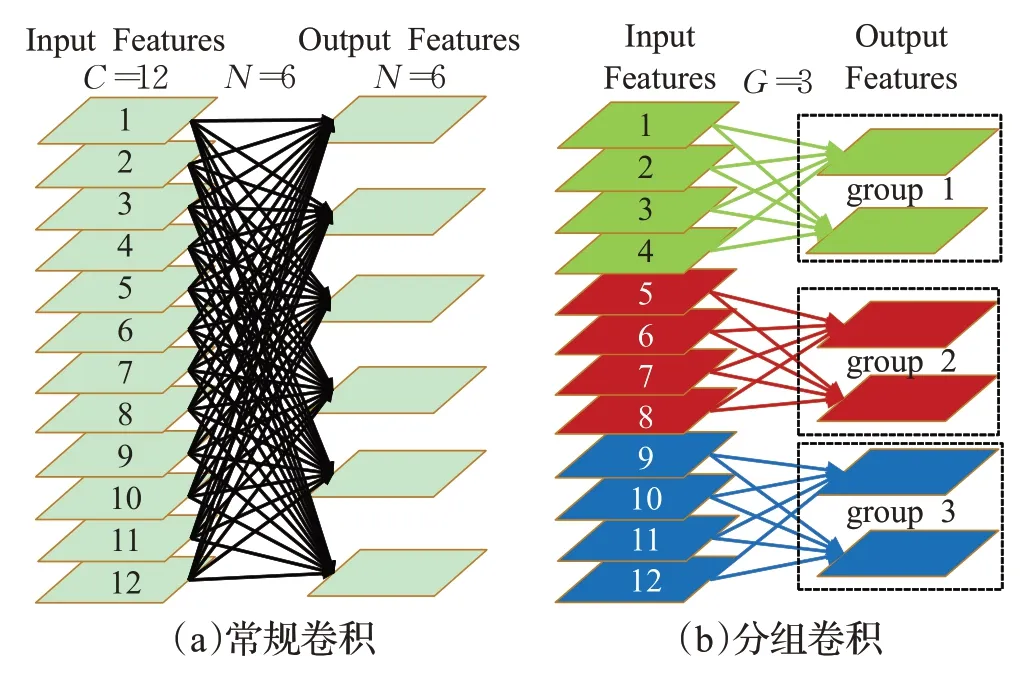
图2 常规卷积与分组卷积Fig.2 Conventional convolution and group convolution
分组卷积(group convolution,GC)把输入特征(input features)通道数C分成G组,同样卷积核也分为G组,每个卷积核的通道数为C/G,分组进行卷积后G组输出拼接得到通道数为N的大特征图(output features)。分组卷积参数量大小为:

式中,G为分组数。
由公式(1)和(6)可知分组卷积的参数量是常规卷积参数量的1/G,同理计算量也是常规卷积的1/G。
与常规卷积相比,分组卷积是一种通道稀疏连接方式,可以理解为Structured Sparse,每个卷积核的尺寸通道数为原来的1/G,从而可将其余部分的参数视为0,在减少参数量与计算量的同时起到减轻过拟合的效果[23]。
与深度可分离卷积相比,当组数G等于输入特征图通道数C时,深度可分离卷积可以理解为极限化的分组卷积,参数量将进一步减少。不同之处:分组卷积只进行一次卷积,不同组的卷积结果拼接即可;深度可分离卷积进行两次卷积操作,在深度卷积之后用1×1点卷积将卷积结果拼接起来。因此,两者参数量计算方式不同,如公式(3)和(6)。
分组卷积的缺点是不同组之间相互独立,信息没有交流,会降低网络的特征提取能力。因此,ShuffleNet V1提出对输出特征图做通道混洗(channel shuffle,CS)操作。如图3所示,将分组卷积后的输出特征(output features1)通过通道混洗操作将来自不同组的信息“均匀地打扰”,在不增长计算量的情况下,保证分组卷积之后不同组的特征图之间的信息相互交流,使通道充分融合。CS在Pytorch中实现过程也十分简单,先将通道数C所在维度拆分为(G,C/G)两个维度,接着两个维度通过矩阵转置变成(C/G,G),最后重新reshape成一个维度C,整个通道混洗过程实现完成。
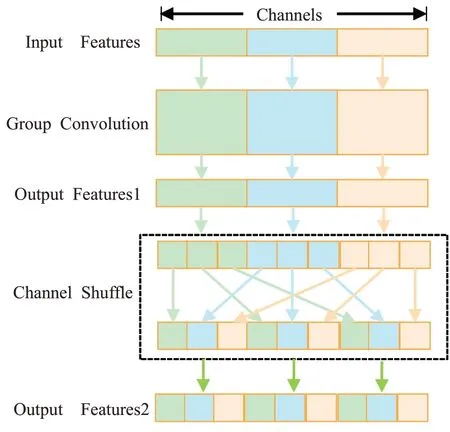
图3 通道混洗Fig.3 Channel shuffle
1.3 ShuffleNet V2单元
Ma等人[21]在ShuffleNet V2中提出4条设计高效且轻量化的网络准则,保持大通道数和通道数不变的情况下,既不使用过多卷积,又不过多分组,并由此在ShuffleNet V1基础上提出新的block设计,如图4所示的两个ShuffleNet V2基本单元模块 。
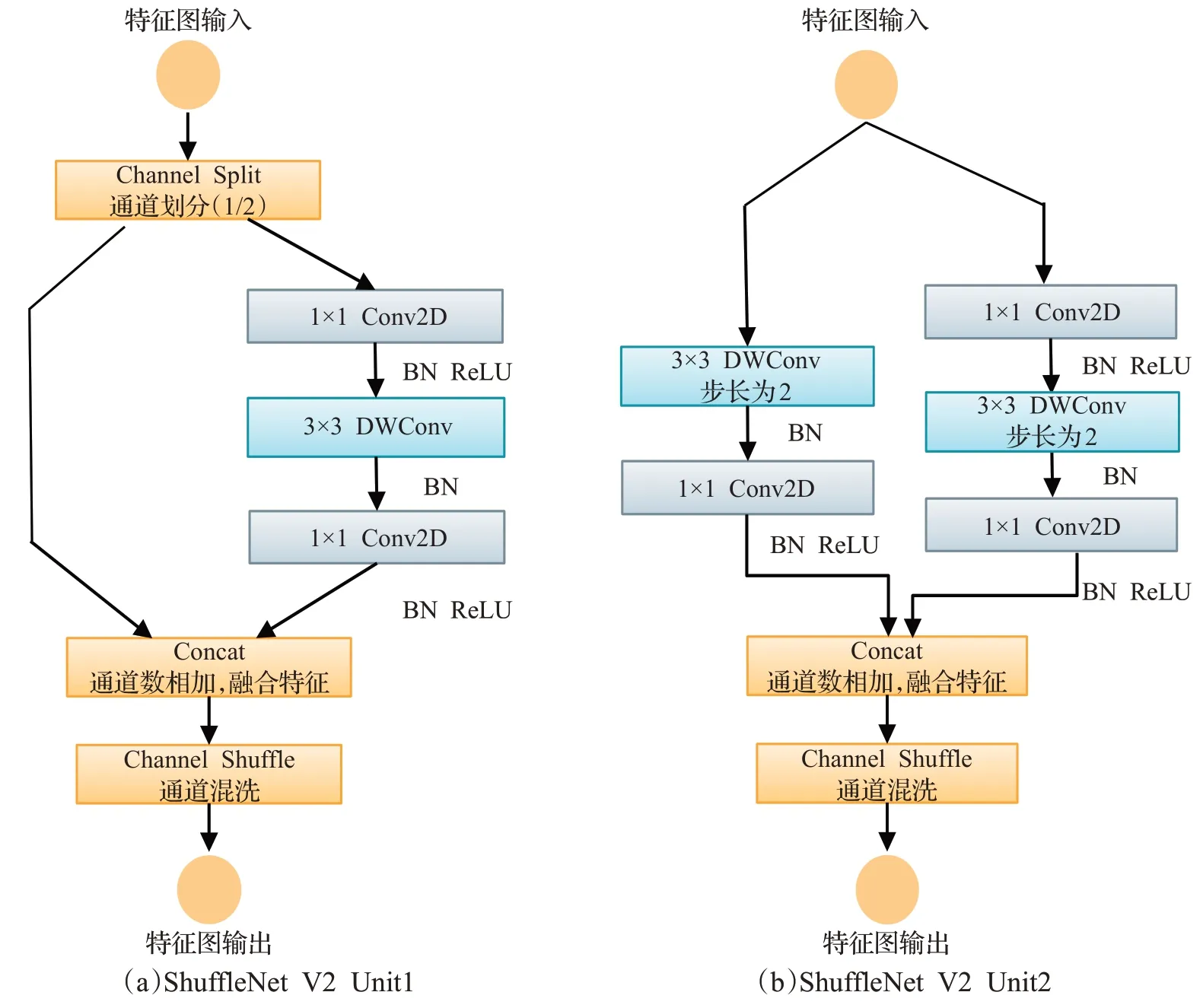
图4 ShuffleNet V2单元Fig.4 ShuffleNet V2 unit
如图4(a)所示,在ShuffleNet V2单元1中,先对输入的特征图进行通道划分(channel split),分成两个分支(branch),通道数各占1/2。左边分支不变,恒定变化;右边分支会经过3个步长为1的卷积,使用相同的输入通道数和输出通道数。其中两个1×1卷积是普通卷积,3×3卷积是深度可分离卷积中的深度卷积(DWConv)。当卷积完成后,两个分支会进行Concat操作,通道数相加,融合特征,最后使用Channel Shuffle进行不同组之间的信息交流,使通道充分融合。与单元1不同,如图4(b)所示,在ShuffleNet V2单元2中,开始不对通道进行通道划分,直接将特征图输入到两个分支。两个分支都使用步长为2的3×3深度卷积,对特征图的长(H)宽(W)进行降维,从而起到减少网络计算量的作用。接着,两个分支输出后进行Concat操作,通道数相加后是原始输入的2倍,增加了网络的宽度,起到在不显著增加FLOPs的情况下增加通道的数量,使网络提取特征能力更强。最后,同样进行通道混洗实现不同通道之间的信息交流。
ShuffleNet V2卷积设计特点:卷积输入输出通道相等时内存访问成本(MAC)最小,分组卷积通过通道之间的稀疏连接来降低计算复杂度,但分组数太多的卷积会增加MAC。因此,为使模型更高效关键在于保持等宽的通道且不使用密集的卷积操作和太多的组卷积,如图4所示ShuffleNet V2网络通过通道划分操作分成两个组,使用1×1卷积代替逐点组卷积,分支中卷积前后输入输出通道数不变,再对分支拼接后用通道混洗加强分支之间的信息交流。
2 模型设计
ShuffleNet V2 0.5×网络结构如图5(a)所示,输入特征图大小3×224×224,先采用24个步长为2的3×3普通卷积进行特征提取,接着使用最大池化层进行下采样;随后,连续使用3个由ShuffleNet V2 Unit2和ShuffleNetV2 Unit1组成的模块层,模块层中单元2与单元1的数量分别为1∶3、1∶7、1∶3;再使用1 024个步长为1的1×1卷积扩充通道数,通过大通道大卷积的大感受野来获取病害特征信息;最后在全连接层前使用全局池化层融合空间信息,防止过拟合,提高泛化能力。ShufflleNet V2 1.0×是在其基础上增加通道数量,即Stage2、Stage3、Stage4模块的通道数分别由48、96、192对应变为116、232、464。
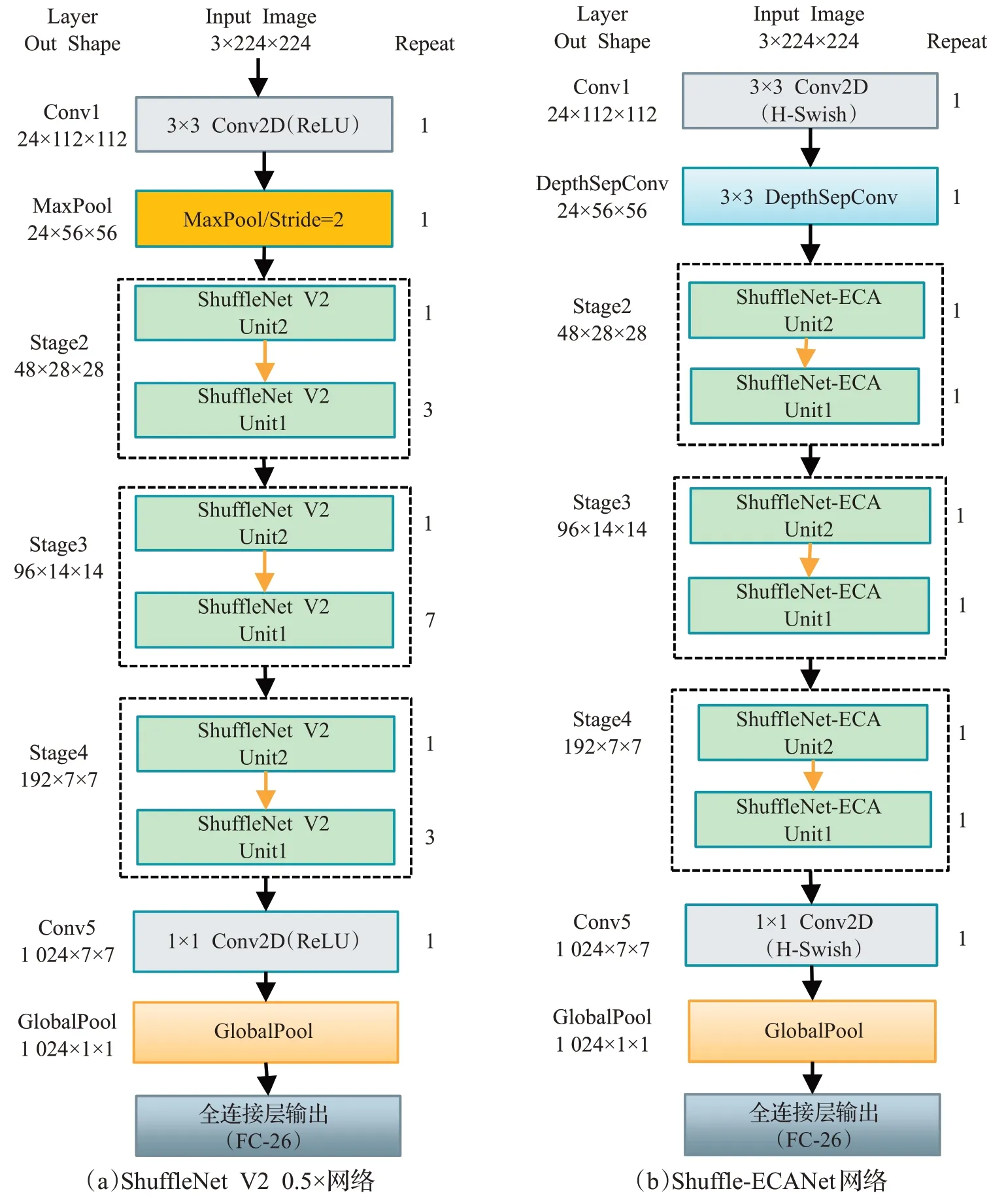
图5 网络模型结构图Fig.5 Architecture of network model
本文所提Shuffle-ECANet网络模型结构如图5(b)所示,与ShuffleNet V2 0.5×网络相比,使用引入ECA注意力改进提出的Shuffle-ECA Unit替换ShuffleNet V2 Unit;使用H-Swish激活函数替代ReLU激活函数以便减少每个Stage模块中ShuffleNet V2 Unit1使用个数,降低网络深度并保持性能;接着,为更好融合通道注意力不使用最大池化层,而使用计算量小的通道数为24、卷积核大小为3×3,步长为2的深度分离卷积,提出特征更丰富。
改进模型设计以图5(a)所示ShuffleNet V2 0.5×网络为原始模型,文中将其标记为模型0。接下来将从ECA注意力模块、H-Swish激活函数、网络结构调整三个方面详细分述改进模型设计。
2.1 ECA注意力模块
通道注意力机制(channel attention mechanism)可以有效提高卷积神经网络的性能,但大多注意力模块比较复杂,虽能带来准确率的提高,但计算负担也越大。因此,Wang等人[24]提出一种新的ECA(efficient channel attention)注意力模块,如图6所示。该模块在不降维的情况下,直接将输入的特征图进行全局平均池化(global average pooling,GAP),避免了降维对通道注意力学习的不利影响,接着通过执行数量为K的快速1D卷积实现对每个通道及其邻近K个通道的局部跨通道信息交互,避免对所有通道进行信息交流产生低效的冗余信息。其中K的值由通道系数C的映射自适应决定并成正比关系,可以有效避免实验中通过交叉验证手动调优K。
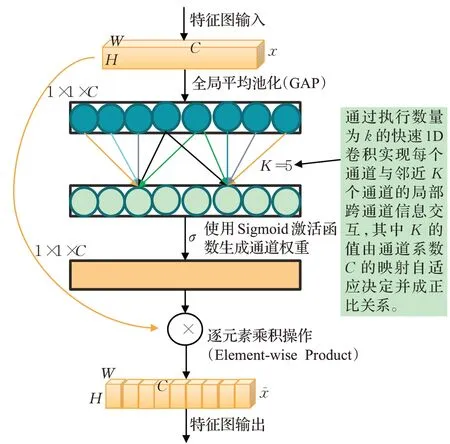
图6 ECA模块结构图Fig.6 Architecture of ECA module
如图7所示,提出的Shuffle-ECA两个基本单元以ShuffleNet V2单元结构为基础进行改进,分别加入高效通道注意ECA模块。该模块只涉及少量参数,适当的跨通道进行信息交互,可以在保持网络轻量化的同时带来明显的性能增益,显著降低模型的复杂度。因此,使用ECA注意力模块对模型0改进,改进模型标记为模型1。
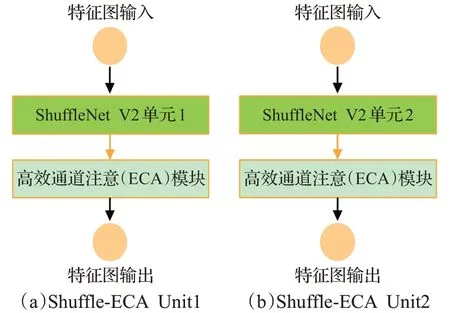
图7 Shuffle-ECA单元Fig.7 Shuffle-ECA unit
2.2 H-Swish激活函数
原始的ShuffleNet V2网络使用ReLU激活函数,公式如式(7)所示,函数图像如图8(a)所示。ReLU激活函数优点是计算简单高效,能有效缓解梯度消失和防止过拟合问题;缺点是一侧函数值为0,导致负的梯度被置零,并且该神经元有可能再也不能被任何数据激活,这种现象被称为神经元“坏死”。
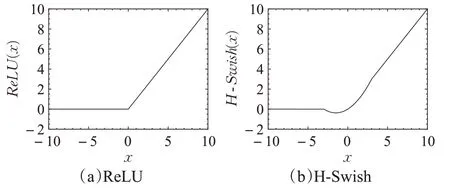
图8 ReLU与H-Swish函数比较Fig.8 ReLU and H-Swish functions comparison
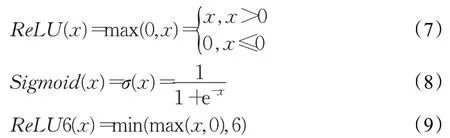
由公式(8)和(9)可得如下:
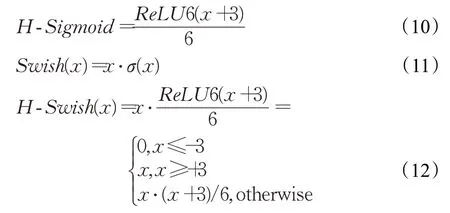
Swish激活函数如式(11),优于ReLU激活函数,显著提高了神经网络的准确性,但由于计算、求导复杂,对量化过程不友好,类比Sigmoid与H-Sigmoid激活函数,MobieNetV3[19]中提出近似的H-Swish激活函数,公式如式(12)所示,函数图像如图8(b)所示。该函数可以有效解决ReLU中会出现的神经元“坏死”问题,且求导简单,在实践中,表现性能优越,推理速度几乎不变。
因此,使用H-Swish激活函数替代ReLU激活函数对模型0进行改进,改进模型标记为模型2。
2.3 网络结构调整
ShuffleNet V2模型是针对ImageNet数据集的1 000类别进行分类设计的,而本文只需要对5种作物26类病害图像数据进行分类,分类任务相对简单,所需的网络模型深度不需要太深。因此,为了减少参数量和计算量的消耗,将模型0中Stage2、Stage3和Stage4中ShuffleNet V2 Unit1的堆叠个数都降为1个,改进模型标记为模型3。
模型0在网络初始3×3常规卷积之后,使用步长为2的最大池化层(MaxPool Layer)进行下采样,优点是降维,保留主要的特征同时减少参数量和计算量,防止过拟合;缺点是只保留特征提取中最大的那个值,其他特征值全部抛弃,可能会带来欠拟合,且不可学习。同时,也为更好融合上述中所提到的ECA注意力模块改进策略,因此对模型0进行改进,不使用最大池化层,在原始位置若采用步长为2的可学习卷积层进行下采样,则计算量过大,故使用计算量小的通道数为24、卷积核大小为3×3,步长为2的深度可分离卷积,提出特征更丰富,改进模型标记为模型4。
3 模型训练
3.1 实验数据及预处理
实验所用数据来源公开数据集PlantVilleage[14],从中获取苹果、玉米、葡萄、马铃薯和番茄5种常见农作物的25种病害(含5种健康)叶片图像数据。此外,考虑到现实场景下叶片图像背景复杂,增加一类无叶片的背景图像数据[25],共计26类,32 539张。
数据集划分,使用Python脚本随机将样本原始数据集按照4∶1的比例划分为训练集和测试集,数据分布如表1,各类病害数据分布严重不平衡。
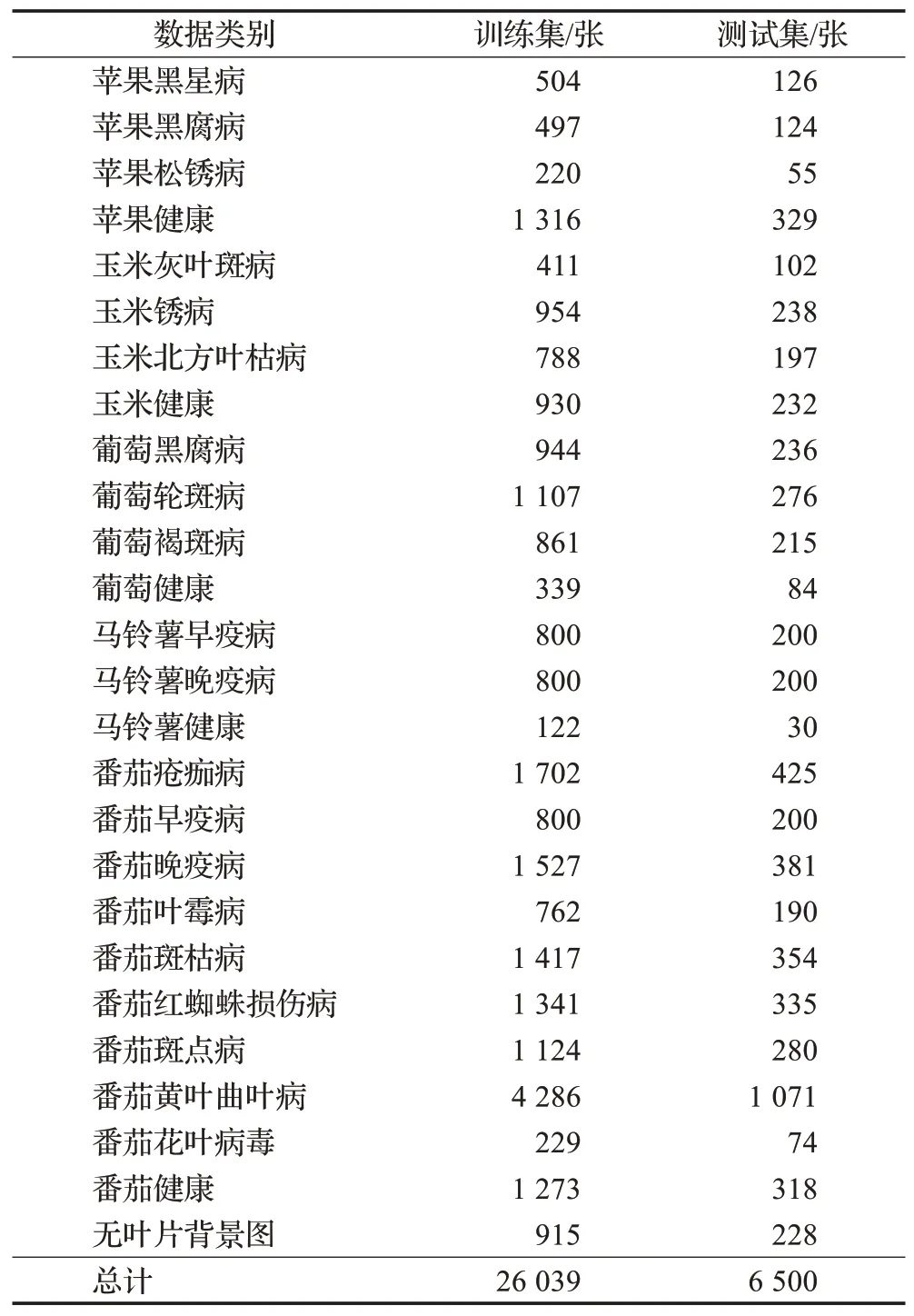
表1 数据分布Table 1 Data distribution
数据增强,使用图像平移、水平或垂直翻转、旋转、缩放、随机颜色(调整饱和度、亮度、对比度、锐度)和添加噪声这六种数据增强技术随机尺度的分别独立对训练集和测试集病害图像进行组合增强,增强效果示例如图9所示。数据增强适当扩充调整后,训练集每类病害图像达到1 800张,共计46 800张;测试集每类病害图像达到400张,共计10 400张;训练集与测试集比例大致保持4∶1,图像总计57 200张。

图9 增强效果示例图Fig.9 Augmented images
3.2 实验细节
实验在Ubuntu 20.04 LTS 64位系统下进行,具体采用Anaconda环境,使用Python3.7.3、Pytorch1.9.1、CUDA11.2搭建网络模型,在NVIDIA GeForce RTX 3080显卡上进行模型训练。
实验中采用随机梯度下降(stochastic gradient descent,SGD)优化器,其中参数设置为moment um=0.9,weight_decay=1E-4。输入图像通过随机水平翻转后随机裁剪到224×224,并统一进行了归一化处理。学习率初始值0.01,每训练10个epoch学习率降到原来的1/10,共进行了40个迭代epoch训练,设置批次batchsize大小为32。
3.3 实验结果及分析
如图10所示,通过对原始ShuffleNet V2 0.5×模型和本文所提改进模型Shuffle-ECANet在增强数据集上的损失(Loss)和准确度(Accuracy)的实验结果进行比较,可以看出改进模型的收敛速度优于原模型,更稳定,迭代停止时有更高的准确率和更低损失值,验证了所提出改进方法的可靠性和有效性。
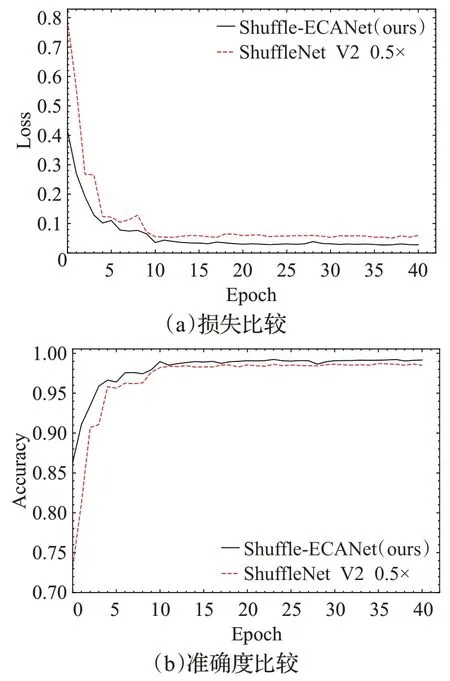
图10 原始模型与所提改进模型比较Fig.10 Comparison of original and proposed improved model
改进模型的消融实验结果如表2所示,模型0表示ShuffleNet V2 0.5×网络,模型1仅使用通道注意力ECA模块,在只增加了少量参数的情况下,准确率提高0.16个百分点;模型2仅替换激活函数,推理速度更快,准确率提高0.27个百分点;模型3仅减少ShuffleNet V2 Unit1模块使用次数,降低网络深度,减少参数量和计算量,但模型的病害识别效果保持良好,准确率提高0.21个百分点;模型4不使用最大池化层进行下采样,而使用深度可分离卷积,在仅增加部分参数量和计算量的情况下,准确率提高0.30个百分点;本文方法在模型0的基础上,同时采取模型1、模型2、模型3和模型4中的4种改进策略,相对于模型0,在Params、FLOPs和MAdd三个指标都降低的情况下,改进效果良好,准确率提升到99.24%。
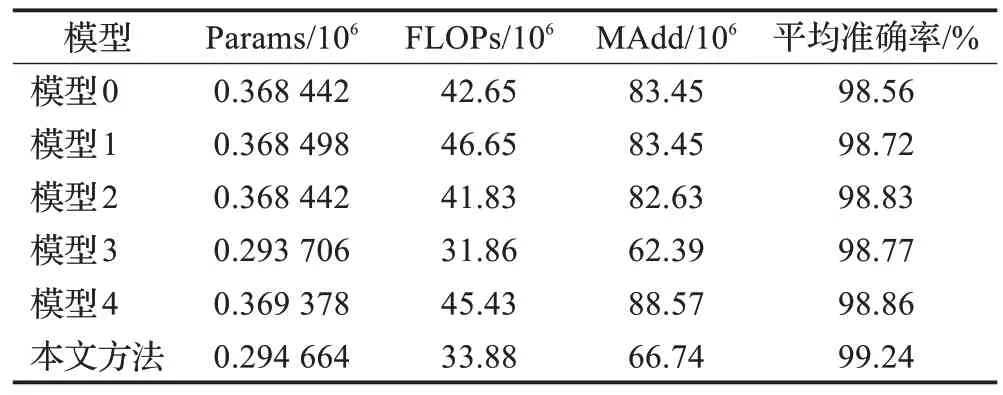
表2 改进模型之间的复杂度对比Table 2 Improved model complexity comparison
本文方法与其他模型对比实验结果如表3所示,本文方法1.0×网络模型在Params、FLOPs和MAdd三者指标量都最小的情况下,识别准确率优于ShuffleNet V2 0.5×和ShuffleNet V2 1.0×模型,识别性能与当前先进的轻量化模型MobileNetV3-Small相当;本文方法2.0×对应ShuffleNet V2 1.0×,在本文方法1.0×的基础上,增加模块单元的通道数,将Stage2、Stage3、Stage4这3个模块的通道数也分别从48、96、192调整为116、232、464,从而提取特征更丰富,模型继续保持轻量化的同时识别平均准确率提升到99.34%,充分体现所提改进模型的优越性。因此,本方法可以根据实际部署设备的计算性能进行适应性调整,具有较强的工程实用性,表现出较高的性价比。
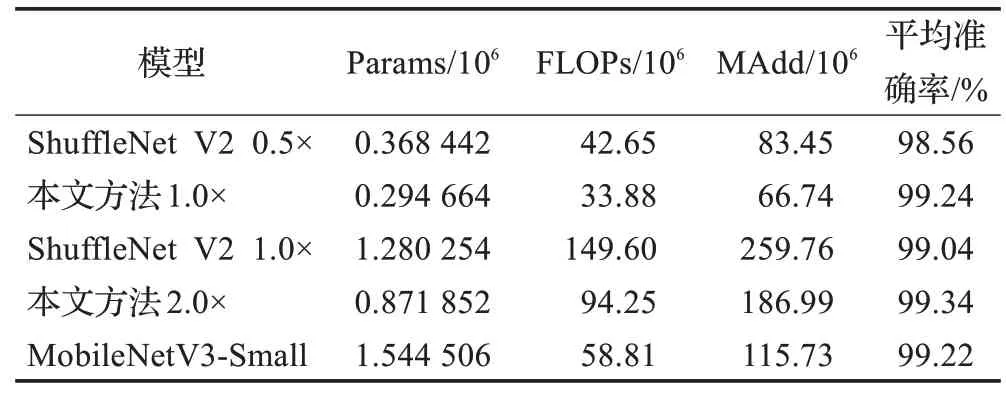
表3 不同模型之间的复杂度对比Table 3 Comparison of complexity between different models
如表4所示,改进模型与MobileNetV3-Small模型在测试集上进行26种病害识别准确率详细比较,可以看出改进模型对大部分病害的识别准确率是优于MobileNetV3-Small模型,在少数类别病害上各有优劣。两种模型都对马铃薯早疫病与晚疫病的细粒度识别效果很好,但是在少数相同类别的病害上识别准确率都较低,主要为玉米北方叶枯病与灰叶斑病、番茄早疫病与晚疫病。易出错识别病害图片如图11所示,可以发现这些病害叶片之间的病害特征相似度较高,有可能会导致模型出现错误病害识别。

图11 易识别错误样例Fig.11 Examples of easy to identify error
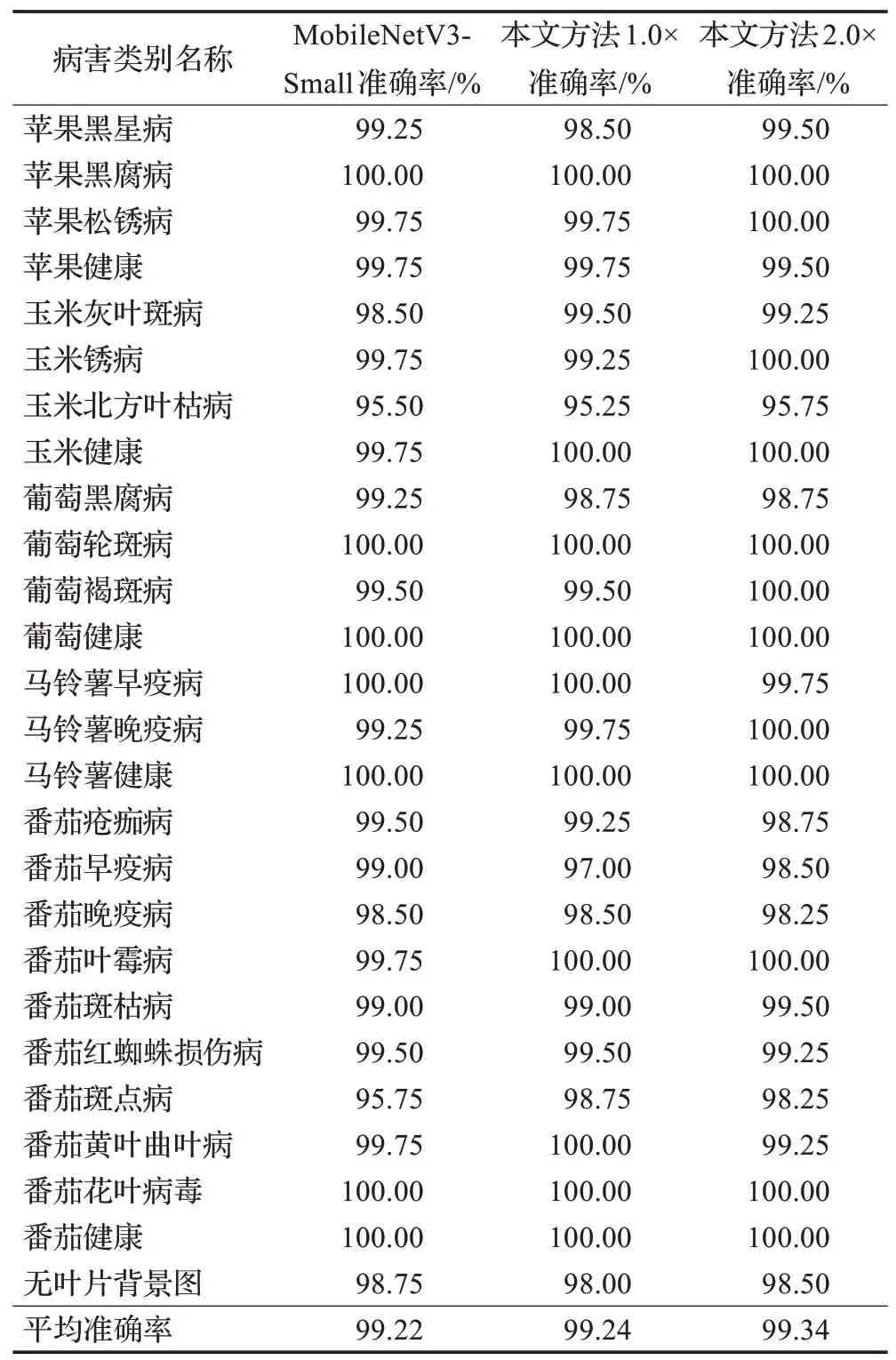
表4 测试集上各类病害识别准确率比较Table 4 Accuracy comparison of various diseases in test set
此外,表4中改进模型与MobileNetV3-Small模型在无叶片背景图上的识别准确率都较低,低于平均准确率。主要是因为在这额外增加的一类中加入了一些如图12所示的图片,可以看出这些图片背景中含有部分的叶片存在,从而模型识别出图片是含有叶片的,这也说明,本文提出的改进模型没有出现过拟合,表现出的病害识别能力较强。

图12 无叶片背景图类别Fig.12 Background without leaves images
4 结束语
本文提出一种改进ShufflleNet V2的轻量级农作物病害识别方法,用于解决农业生产实践中病害识别模型部署在计算资源有限,低性能的边缘设备与移动终端较难,实时快速准确识别较差的问题。该模型方法在参数量、计算量和准确率之间达到良好的平衡并使模型性能保持在较高水平,病害识别平均准确率达到99.24%,满足实际部署应用在低性能设备中轻量化网络和推理识别病害速度快的需求,为后续相关研究提供参考。下一步将重点研究如何在复杂背景下,对农作物病害进行细粒度识别,提升模型实际应用价值。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
