
可变尺寸循环注意力模型及应用研究
2022-06-23 06:25吕冬健王春立
计算机工程与应用 2022年12期
吕冬健,王春立
大连海事大学 信息科学技术学院,辽宁 大连 116026
细粒度图像识别已经被广泛地研究了多年[1-3]。细粒度图像识别技术非常适合于多媒体信息读取和内容分析,例如细粒度图片搜索[4]、服装搜索及推荐[5]、食物识别[6]、动物识别[7]、地标分类[8]等。根据研究重点的不同,细粒度识别可以划分为表示学习、部分一致性模型和对数据的强调三大类。第一类通过构造隐性的强大特征表示,例如双线性池化或压缩线性池化[9],对于细粒度图像识别的提升非常大。第二类通过让特征局部化来有效地处理较大的类内差异和细微的类间差异。第三类研究数据集图片尺寸的重要性[10]。通过使用更大图片的数据集在多种细粒度数据集上得到了较好的结果。
其中第二类的对齐方法自动地找到具有辨识力的部位并且对齐这些部位。非监督模板学习[9]寻找物体的相同几何模型部位用于细粒度图像识别。在对齐类别任务[11-12]中图片首先被分割然后物体根据不同部位提取的特征粗略地对齐。模型通过分割和部位局部化更新结果。最后,每个部位的特征被提取并用于分类。通过将发现的关键点对应到图片中的关键点,低级特征和高级特征被整合用于分类[13]。
从细粒度图片分类中得到的重要的启示是物体的局部特征在辨别物体类别中起到重要的作用。例如狗的头部特征在区别不同种类的狗中起到重要作用。受这一现象的启发,大部分的细粒度图片识别的方法[9,14]是首先定位目标物体或物体局部的位置,然后提取分类的特征。局部方法[14]主要使用非监督方式去识别物体的大体位置,其他方法[9]使用边界框或局部注释。但这些方式都存在一定的局限性:首先人为定义的局部区域并不一定对于分类任务是最优解,其次手工将物体裁剪并定义边界框是非常费时费力的,很难用于实践,而定义图片标签却容易得多。最后,非监督方式会生成大量的候选区域,处理这些候选区域会消耗大量计算资源。
受人类注意力启发,循环视觉注意力模型(recurrent visual attention model,RAM)被提出并运用在目标识别中[1]。RAM是一个递归选择机制的深度循环神经结构,它模仿人类视觉系统,能够抑制图片中不相关部分,并从复杂的环境中提取有辨识力的特征。其中神经网络通过注意力控制图片中局部区域的位置。视觉注意力模型是一种特殊类型的反馈神经网络[15]。反馈神经网络是一种使用高级特征去提取低级特征的特殊循环神经网络。反馈神经网络使用自顶向下和自底向上的方法计算网络中间层[16]。最近,将注意力模块融入网络中以提高网络的性能开始成为趋势,并在自然语言处理和图像处理方面取得了良好的效果[17]。Ba等人[18]利用RAM识别图片中的多个物体。因为细粒图片通常需要将局部区域之间进行比较,Sermanet等人[19]将RAM应用到细粒度图片识别。除了细粒图片识别,注意力模型也被应用在不同的机器学习领域中包括机器翻译[17]、图像捕捉[20]、图片问题回答[21]和视频活动识别。这显著提高了识别准确率[15],尤其是对细粒度物体的识别[16-17]。RAM也能够在有限的计算资源下处理高分辨率的图片,通过学习并确定重点关注的目标区域,使模型能够在有限资源下关注最有效的信息[22]。
除了注意力之外,当观察不同的物体时,人类会动态地选择注意力区域的大小。区域的大小取决于被观察的物体和所在的背景。这样的视觉注意力机制自然地胜任细粒度图片分类任务。因此许多基于视觉注意力的模型在近几年内被提出[14]。然而,这些视觉注意力模型很难一次性找到多个视觉辨识区域。并且注意到类间差别通常存在于物体的局部区域,例如鸟的嘴和腿。由于尺寸太小现有的模型很难将它们进行定位。因此,通过模型自主学习找到这些区域对于提升视觉注意力模型的准确度是有帮助的。受此启发,本文提出可变尺寸循环注意力模型(variable size recurrent attention model,VSRAM)。在每一个时间步,模型不只生成下次注意位置坐标,同时还生成下次注意力尺寸。这使得VSRAM拥有更大的灵活性并且减少了计算的区域从而节省了计算资源。
1 相关工作
循环注意力模型又称为部分可观察的马尔可夫决策过程(partially observable Markov decision process,POMDP)。在每一个时间步中,模型作为代理通过环境的观察执行一个动作并得到奖励。代理控制如何行动并且会影响环境的状态。在RAM中,动作对应于注意力的位置。观测是在图片中截取的局部(部分可观察)区域。奖励是衡量截取图片区域的质量。学习的目标是找到最佳的策略来通过环境的观察生成注意力使得积累的奖励最大。
循环注意力模型定义输入图片x和总共注意次数T。在每个时间步t∈{1,2,…,T} ,模型在位置lt-1截取一个局部区域φ(x,lt-1),其中lt-1是在上一个时间步中计算出来的。之后模型的循环神经网络更新内部状态ht:
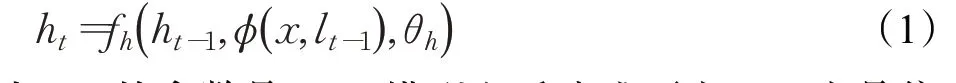
式中,ht的参数是θh。模型之后分成两支。一支是位置网络fl(ht,θl)控制位置的生成,参数是θl;另一支是基准网络fb(ht,θb),负责判断位置生成的质量,参数是θb。在训练过程中,位置网络根据策略π(lt|fl(ht,θl) )生成注意力位置。图1表示RAM的推理过程。
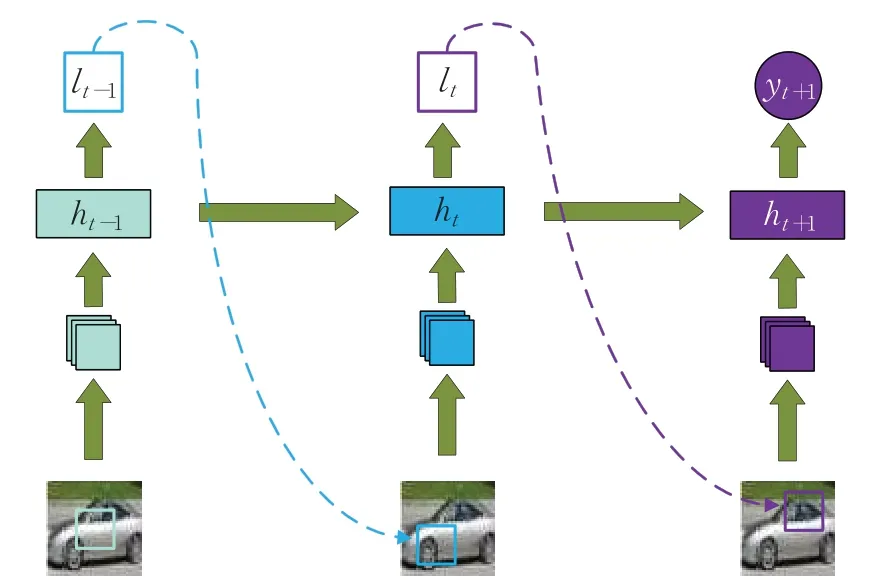
图1 循环注意力模型Fig.1 Recurrent attention model
目前在RAM中截取局部区域的策略是固定局部区域的尺寸,完全通过注意力关注图片的不同局部区域来完成图像识别功能。
2 可变尺寸循环注意力模型(VSRAM)
2.1 模型整体架构
VSRAM模型的结构主要包括6个部分:特征提取网络、视觉注意力网络、位置网络、尺寸网络、基准网络和分类网络。特征提取网络主要作用是将原图截取指定的位置和尺寸后的图片作为输入图片输入到特征提取网络中,其中位置lt和尺寸st是上一个时间步中生成的。本实验采用在ImageNet上预训练模型的VGG16作为特征提取器。视觉注意力网络采用隐藏状态大小为512的LSTM,输入图片特征向量gt和上一次的隐藏状态ht-1,输出本次隐藏状态ht。位置网络、尺寸网络、基准网络和分类网络都是全连接网络。输入ht输出对应的位置lt、尺寸st、基准bt,如果是最后一次则输出最后的分类结果。
2.2 思路
在推理中,模型根据上一时间步中生成的注意力位置lt和尺寸st从当前图片中截取出局部区域作为输入图片输入到位置网络fl(ht,θl)和尺寸网络fs(ht,θs)中,并根据各自的策略π(lt|fl(ht,θl))和π(st|fs(ht,θs) )生成注意力位置lt+1和尺寸st+1。
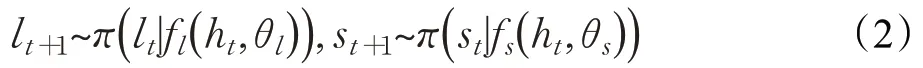
图2为模型的示意图。跟图1相比,在每个时间步中根据当前生成的隐藏状态ht生成下次输入图片的尺寸st+1。当视野中出现目标物体时,期望模型能够自动调整注意力区域的位置和尺寸,使模型能够在几次注意力中尽可能多的获取物体的特征,并且截取尽可能少的注意力区域,从而提高识别的准确度,节省计算资源。
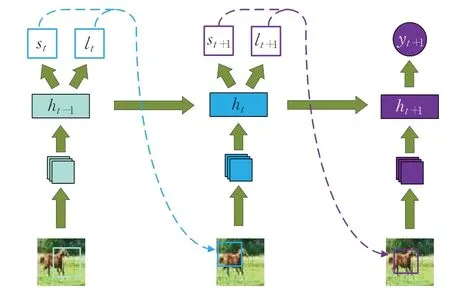
图2 改进后的循环注意力模型Fig.2 Improved recurrent attention model
2.3 位置和尺寸的动态学习
VSRAM是一个递归选择机制的深度循环神经网络,其中每一次递归的网络称为结构。循环神经网络模型和非循环神经网络模型的区别是在推理中循环神经网络模型结构同时依赖于输入x和参数θ。因为每次的输入尺寸s不同,所以结构S也不同。而非循环神经网络模型的结构S只由参数θ决定,跟输入x无关。
在每次循环的结构S中给定一个输入图片x,输入当前结构S中的RAM模型中生成隐藏状态ht,根据ht生成的下一次输入位置l和尺寸s,由尺寸决定下一次循环的结构S,因此选择计算结构S的概率是P( )
S|x,θ,当结构S的模型空间被定义后,这个概率可以使用神经网络来估计。在训练过程中网络结构的损失函数是因此整体的损失期望是:

期望的第一项与强化算法[23]相同,使模型的损失越来越小。第二项是固定结构神经网络的标准梯度。
在实验中,直接计算L对于θ的梯度是非常困难的,因为在训练中需要估计的结构有太多可能性。因此首先生成一组结构的数据,然后使用蒙特卡洛模拟[23]近似的计算梯度,M为VSRAM的递归次数,St为第i次递归的结构:
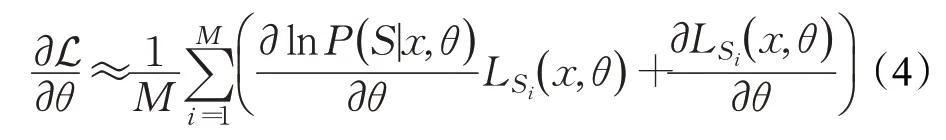
2.4 训练
尽管公式(4)中的损失可以直接被优化,但使用奖励函数R可以减少判别器的方差[15]。给定训练集图片和标签(xn,yn)n=1,2,…,N,N为数据集中图片的总数。通过计算如下梯度逐渐优化可变尺寸循环注意力模型网络参数:
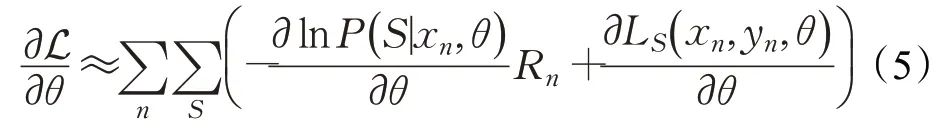
其中,θ={θf,θl,θa,θc}分别是循环神经网络、注意力位置网络、注意力尺寸网络和分类网络的参数。
对比公式(4)、公式(5)在第一项中使用奖励函数R取代给定结构Ls的损失。
公式(6)是结构S的生成策略:
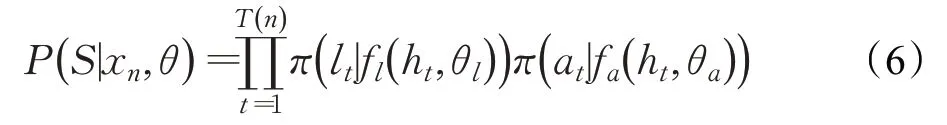
公式(7)给出了在T(n)次时间步中第n次的积累折扣奖励:

折扣因子γ控制着对做出正确分类和注意次数的取舍,在训练时分别训练两个模型使用不同的折扣因子(0.97和0.93)以作为对比。
rnt是第t次的奖励,如等式(8)所示:

其中,rp为正确率奖励。如果模型输出结果正确则奖励rp设为1,否则为0;rs为尺寸奖励,尺寸奖励rs的设置如等式(9)所示:

其中,si为输入图片的尺寸,st为模型生成的尺寸。模型生成尺寸的平方与尺寸奖励成反比,这样设置使模型趋向于选择n次递归中总面积最小的策略。由于给与模型正奖励rnt会导致模型无限趋向于选择小尺寸而忽略正确率,因此本文使用负奖励的奖励rnt设置方式(即错误识别扣1分,如果正确识别,总面积小的扣分少,总面积大的扣分多,但是正确识别扣分少于错误识别的扣分)。这样设置可以使模型在保证正确率的前提下选择生成总面积最小的尺寸策略。
3 实验结果及分析
3.1 数据集
使用三个经典的数据集评估VSRAM模型的性能:MNIST、Stanford Car和CUB-200-2001数据集。这三个数据集的统计信息如表1所示。这些数据集的示例图片如图3所示。MNIST数据集是机器学习领域中非常经典的一个数据集,由60 000个训练样本和10 000个测试样本组成,每个样本都是一张28×28像素的灰度手写数字图片。Stanford Cars数据集包含16 185张图片和196个汽车类别。类别注释包括上市时间、生产厂商、型号。例如:2012 Tesla Model S和2012 BMW M3 coupe。CUB-200-2001包含11 778张图片和200种鸟类别。其中训练集有5 994张,测试集有5 794张。它提供丰富的注解,包括图片标签、物体边界框、属性注释和关键部位区域。这些数据集在每一张图片中都包含了边界框,CUB-200-2001还包含了关键部位信息但是本实验中并未使用。从这些示例图片中可以看出图片内容比较复杂,并且有背景聚集,因此图片分类任务比较具有挑战性。
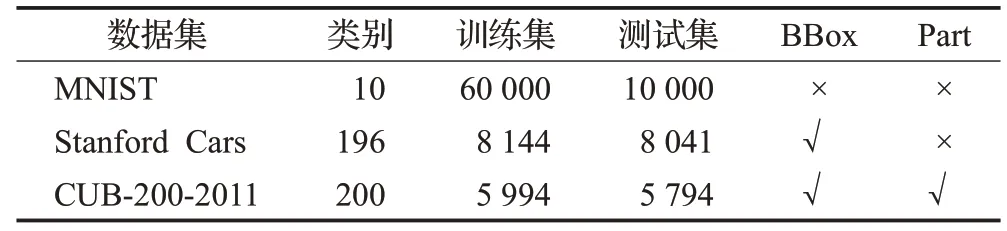
表1 数据集的统计信息Table 1 Dataset statistics

图3 数据集的示例图片Fig.3 Example from dataset
3.2 实验设计
所有图片首先标准化为尺寸256×256,然后在其中随机截取尺寸为224×224的图片作为输入图片输入到特征提取网络中。特征提取网络采用在ImageNet预训练的VGG16模型进行微调,其中VGG16只采用特征提取部分而不使用全连接层的分类部分。输入图片经过特征提取网络后输出1×1的特征向量。位置坐标和尺寸经过全连接层网络后得到的特征向量与图片特征向量合并后输入视觉注意力模型。视觉注意力模型采用LSTM,并且设置隐藏层为512。基准网络、位置网络、尺寸网络和分类网络都为全连接网络。
模型使用ADAM优化算法训练200个epoch,初始学习率设为0.003,当大于20个epoch准确率没有提升时,学习率降为原来的0.1。批处理大小设为64。虽然数据集提供了边界框和局部注释,本实验过程中并没有使用。
计算时间:本实验基于PyTorch。计算时间主要取决于输入图片的分辨率和主干网络结构,由于本实验中每个批处理中的输入图片均不一样,所以在提取图片特征时一次只能处理一张图片,因此处理速度比较慢。使用VGG16特征提取器处理一张图片的平均时间是35.36 ms。3步RAM耗时106.09 ms,因为需要循环3次也就是使用VGG16提取3次特征。
3.3 实验结果及分析
MNIST:训练两个使用不同的折扣因子的VSRAM模型。一个使用较小的折扣因子(discount factor)为0.93,另一个使用较大的折扣因子为0.97。较小的折扣因子鼓励模型看中短期的利益,在当前时间步获取较大的奖励。较大的折扣因子看中长远的利益,在几个时间步获得总的最大利益。因此第一个模型趋向于在单次时间步中选择较大的局部区域,而第二个模型趋向于在多次时间步中选择出不同的较小局部区域,并且总面积最小。
表2总结了不同模型在MNIST数据集上的表现。在相同的步数下,VSRAM比RAM的准确率更高。比如,VSRAM-1用3步达到了1.45%的错误率而RAM用了4步得到1.54%的错误率。同样的,VSRAM-2用5步达到1.23%的错误率而RAM用5步达到1.34%的错误率。

表2 在MNIST数据集上的相关对比Table 2 Comparison to related work on MNIST
CUB-200-2011:本文在CUB-200-2011数据集上与各种已公布的方法进行对比,结果如表3所示。通过观察可以看出双线性CNN(84.1%~84.2%),Spatial Transformer Network(84.1%)和双线性池化网络(84.2%)等方法的准确率基本相近。
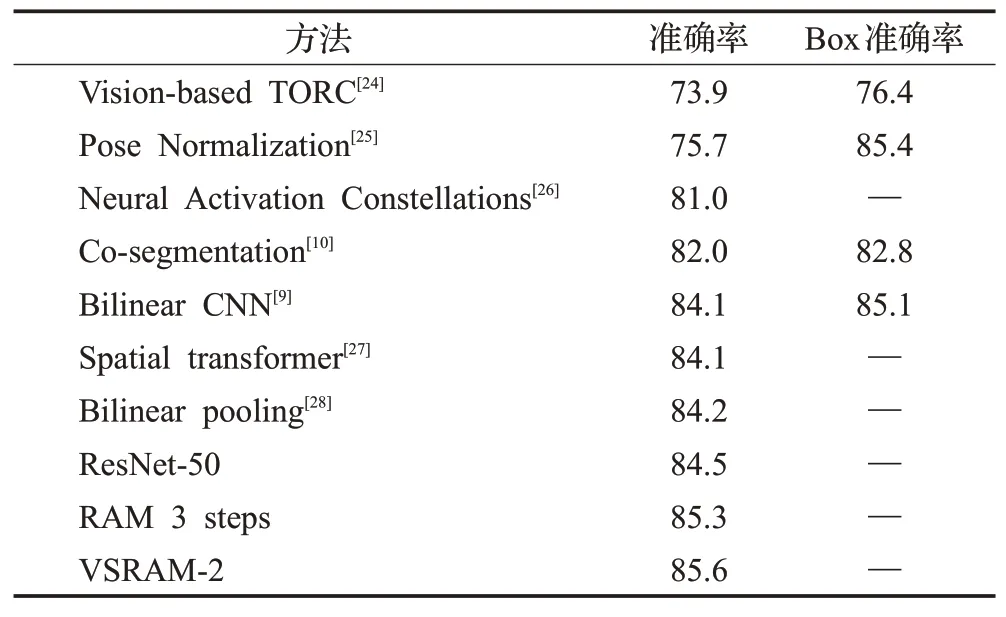
表3 在CUB-200-2011数据集上与各种已公布的方法进行对比Table 3 Comparison to related work on CUB-200-2011 dataset %
另外,经过仔细微调的50层残差网络的准确率是84.5%,超过了绝大多数的方法。通过增加3步的循环注意力模型(RAM)可以达到85.3%,将残差网络的基准提高了0.8个百分点。VSRAM的应用提升了RAM的性能,到达RAM相同的准确率只需要用2步。
Stanford Cars:本文同样在Stanford Cars数据集上做了延伸对比,结果如表4所示。经过微调的50层残差网络在测试集上达到了92.3%的准确率,超过了大部分的模型。这表明没有任何修改或额外边界框注释的深层网络可以成为细粒度识别的首选模型。
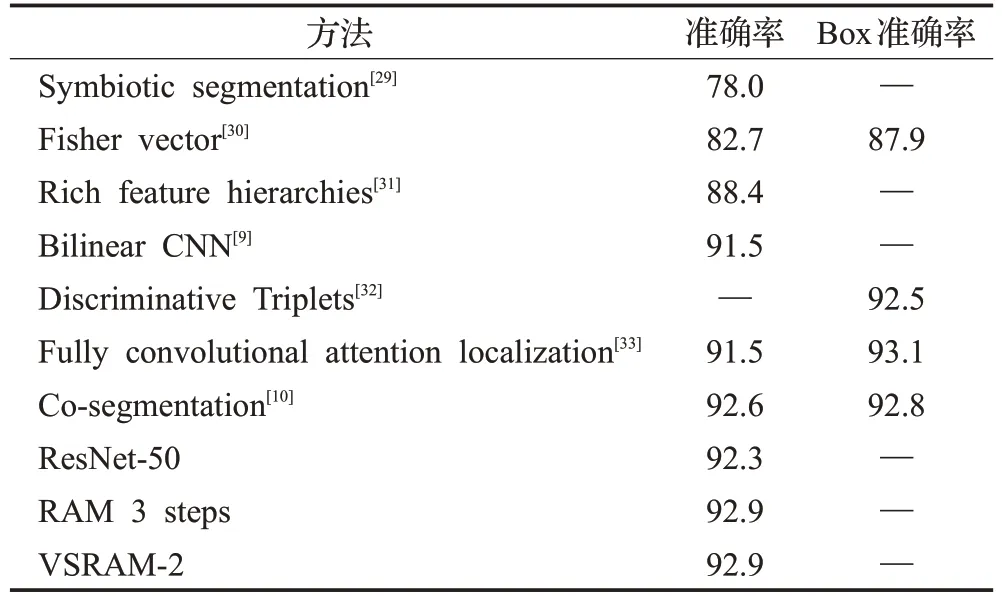
表4 在Stanford Cars数据集上与各种已公布的方法进行对比Table 4 Comparison to related work on Stanford Cars dataset %
将3步RAM应用在残差网络使模型准确率提升到92.9%。VSRAM同样只用2步达到和RAM同样的准确率。同时可以观察到增加RAM模型的准确率提升并不大。
图4为3步VSRAM在Stanford Cars数据集下的效果示意图。可以看出模型可以在每一个时间步中自动寻找图中最有辨识度的局部区域,并且尽可能合理地分配每个时间步的局部区域尺寸从而保证3次局部区域面积的总和最小。

图4 3步VSRAM注意力区域示意图Fig.4 Example of three steps VSRAM attention areas
4 结束语
本文提出一种使用强化学习在推断时动态调节输入图片尺寸简单新颖的方法。将该方法应用在循环注意力模型中并展示了在细粒度图像识别中的效果。相信该方法在将循环神经网络融合到图像识别中的研究有一定的积极影响。未来可以进行更复杂模型的研究,并将模型应用到更复杂的任务中,比如GAN等。
猜你喜欢
红外技术(2022年11期)2022-11-25
小雪花·成长指南(2022年1期)2022-04-09
中华书画家(2021年12期)2022-01-06
散文诗(2020年1期)2020-07-20
安阳工学院学报(2020年2期)2020-06-05
甘肃教育(2020年22期)2020-04-13
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
东方艺术·国画(2016年3期)2017-02-08
第二课堂(课外活动版)(2016年2期)2016-10-21
