
基于可逆金字塔和平衡注意力的工业裂缝分割
2022-06-23 06:25董红月张兴忠赵杰伦
计算机工程与应用 2022年12期
董红月,张兴忠,赵杰伦
太原理工大学 软件学院,太原 030024
由于工业结构(如道路、桥梁、电力元件等)长期工作于疲劳应力、周期性载荷等恶劣环境中,其结构表面上极易出现裂缝。裂缝会降低局部刚度并导致材料断裂、性能下降等问题的出现,严重影响工业系统的安全运行。高效精准的裂缝检测可以及时发现缺陷并进行处理,对工业系统的安全运行具有重要意义[1-2]。
以输配电线路中的瓷瓶为例,瓷瓶是输配电线路中实现电气绝缘和机械固定的重要部件,长期工作于强电立场、强机械应力、风吹日晒等共同构成的恶劣环境中,极易出现裂缝。目前瓷瓶裂缝检测主要依赖于人工巡检,检查员徒步行走并借助双筒望远镜目视检查瓷瓶,存在巡检效率低、劳动强度大、发现缺陷难,且特殊地形和气象条件下巡检困难等问题[3-4]。其他工业结构也多采用人工检测方法,效率低且漏检严重。传统的裂缝检测方法已无法满足日益增长的工业安全需求。
近几年来,随着图像处理技术的发展和无人机等数据获取设备的实现,国内外研究者对基于数字图像的裂缝检测进行了大量深入的研究[5]。数字图像处理技术(阈值提取法、边缘检测算法、滤波器等),根据裂缝光度、对比度等特征设定阈值,将裂缝与背景简单分类。文献[6]提出了一种基于二次阈值分割技术的裂缝检测方法,通过阈值分割算法去除道路标记并进行图像分割;文献[7]通过改进的Canny算子抑制干扰物边缘点,并设置相对阈值去除噪声;该类方法难以选定通用的阈值,准确度不高,且对光照、阴影、噪声等敏感,在背景复杂时性能有限。机器学习方法(支持向量机(support vector machine,SVM)、随机森林等),通过人工设计裂缝特征,对提取的特征进行分类。文献[8]提出了一种基于随机结构森林的道路裂缝检测框架CrackForest,该框架提出了一种裂缝描述子来描述裂缝并将其与噪声进行区分;文献[9]利用基于多重特征的噪声滤波方法以及基于SVM的特征分类法对裂缝图像各成分进行分类提取;该类方法需要人工设计裂缝特征,难以设计出适用于所有路面的通用特征,导致算法的适应性和扩展性较差。
基于深度学习的图像处理技术主要包括目标检测和语义分割。目标检测使用滑动窗口卷积网络,预测是否包含裂缝。文献[10]提出了一种基于视觉的方法,利用卷积神经网络来检测裂缝,不需要缺陷特征计算方法但需要大量的训练数据来训练一个鲁棒分类器;文献[11]提出一种基于卷积神经网络(convolutional neural network,CNN)的裂缝分类模型,结合窗口滑动算法对裂缝进行检测;该类方法以矩形框精准定位裂缝,但由于裂缝的分布路径、形状和密度是不规则的,无法提供裂缝的高精度测量信息。语义分割是像素级检测,基于图像的每一个像素进行预测。文献[12]提出了特征金字塔和层次增强网络(feature pyramid and hierarchical boosting network,FPHBN),对样本进行重新加权,以平衡简单样本和困难样本对损失函数造成的影响;文献[13]提出了一种端到端可训练的深度卷积神经网络DeepCrack,该网络由全卷积网络和深度监督网络组成,并采用引导滤波细化结果,在所提出的数据集上取得了很好的结果;该类方法为进一步测量裂缝相关信息提供可能性,但由于语义分割基于独立的像素进行检测,无法提供足够的上下文信息引导预测,存在对细小裂缝检测性能不足、孤立噪点等问题。
针对以上问题,本文提出了一种新的工业裂缝分割网络——可逆金字塔和平衡注意力网络(reversible pyramid and balanced attention network,RPBAN)。首先基于U-Net[14]进行改进,构建小样本、像素级的检测模型,解决数据不足的问题并为高精准的裂缝测量提供可能性;其次提出可逆金字塔模块(reversible pyramid model,RPM),在编码器-解码器阶段引入特征金字塔(feature pyramid module,FPM)[15]与进行改进后的倒-特征金字塔(inverted feature pyramid module,IFPM),加深全局特征与细节特征的融合,解决细小裂缝检测性能不足的问题;然后在解码阶段引入平衡注意力模块(balanced attention model,BAM),将平衡特征作为引导信息,解决孤立噪点的问题;最后选取Focal Loss[16]作为损失函数,控制正负样本在训练中所占的权重,使模型更专注于裂缝样本,解决类不平衡带来的“虚假”损失率的问题。通过在自建的输配电线路瓷瓶裂缝数据集和三个具有挑战性的公开裂缝数据集上对本文提出的RPBAN进行验证和测试,实验表明,与其他基准方法相比,RPBAN能够实现更高精度的工业裂缝语义分割。
1 工业裂缝分割网络RPBAN
为实现高效精准的工业裂缝分割,本文提出的工业裂缝分割网络RPBAN采用了编码器-解码器框架,如图1所示。RPBAN由4部分组成:
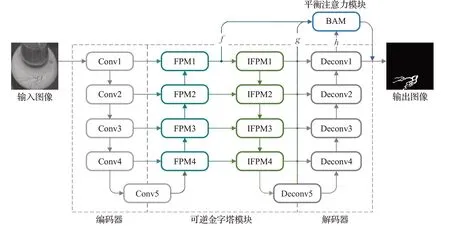
图1 工业裂缝分割网络RPBAN结构Fig.1 Architecture of RPBAN
(1)基于U-Net的编码器体系结构(Conv1~Conv5),用于分层特征提取;
(2)可逆金字塔模块RPM(FPM1~FPM4,IFPM1~IFPM4),用于特征融合;
(3)平衡注意力模块BAM,用于检测引导;
(4)基于U-Net的解码器体系结构(Deconv1~Deconv5),用于特征解析,得到预测结果。
RPBAN的特点主要表现在2个方面:
(1)RPM基于FPM进行改进,将深层的语义特征融入到浅层的细节特征中,并将更新后的浅层特征提取、融合复用;
(2)BAM将平衡特征分支引入注意力机制中,使不同层级的特征有效连接以平衡深层特征与浅层特征,进而在计算过程中增强引导信息。
在构建模型时,由于存在工业裂缝图像不易获取、数据不足的问题,选取了U-Net网络作为基础网络,其网络的实用性以及从少量数据中学习的能力,可以有效解决工业裂缝数据少的问题。U-Net网络基于编码器-解码器结构,通过拼接的方式实现浅层信息与深层信息的特征融合,在每个阶段都允许解码器学习编码器的特征,保留在池化中丢失的相关信息。U-Net网络的核心思想是跳跃连接机制,将前后层级跨层连接,使得细节特征在网络流动中得到保留。在搭建本文所提网络时,利用跳跃连接机制将不同模块按级别跨层连接,加强全局特征与细节特征的保留,将模型各部分高效整合,并使信息在整个网络流动起来,使得检测性能得到有效提升。
将裂缝图像输入编码器网络,以提取不同深度的特征。不同深度对应着不同层次的语义特征,浅层网络分辨率高,学的更多是细节特征;深层网络分辨率低,学的更多是语义特征。编码器模块包括5个卷积层Conv1~Conv5。该模块输入图像尺寸为256×256×1,每个卷积层都采用了两个3×3的卷积核,通道数分别为64、128、256、512和1 024。每经过一个卷积层,输出特征图尺寸缩小为输入特征图的1/2,通道数增加一倍。该模块输出特征图尺寸为16×16×1 024。
解码器模块包括5个反卷积层Deconv1~Deconv5。每个反卷积层都采用了两个3×3的卷积核,通道数分别为1 024、512、256、128和64。该模块每层的输入为其他模块对应层级输出特征图的连接结果。每经过一个反卷积层,输出特征图尺寸扩大为输入特征图的2倍,通道数缩减1/2。最后一层采用了三个3×3卷积与一个1×1卷积,获取最终的裂缝检测结果,输出图像尺寸为256×256×1。
1.1 可逆金字塔模块
实验中存在细小裂缝检测性能不足的问题,其产生原因是语义分割基于独立像素检测缺少全局特征,且计算过程中包含一系列卷积、池化操作容易损失细节特征,而裂缝在图像中呈细长状,在检测时需要同时兼顾全局特征与细节特征。针对以上问题,本文构建了可逆金字塔模块,该模块基于特征金字塔进行改进,RPM将特征金字塔功能性倒置转化为倒-特征金字塔,并将两者按特定规则结合在一起。在模块中,特征金字塔提取分层特征并将深层特征引入到浅层,将深层包含的上下文信息融入浅层的细节信息中;倒-特征金字塔连接在特征金字塔之后,利用更新后的分层特征再次进行特征提取,并与特征金字塔进行功能合并操作,加深上下文信息与细节信息的融合,使模型在保留细节特征的同时,增强全局特征,有效提升细小裂缝的检测性能。
RPM包括FPM和IFPM,其网络结构如图2所示。FPM主要包括自底向上和自顶向下两个过程。自底向上过程主要利用卷积、池化对输入图像C1进行前馈计算,形成一个分辨率递减、维度递增的特征金字塔{C2,C3,C4,C5}。自顶向下过程则以{C1,C2,C3,C4,C5}为输入,通过上采样和横向连接的方式构建与自底向上特征金字塔逐级对应的特征图{F1,F2,F3,F4,F5}。IFPM以FPM输出的特征图{F1,F2,F3,F4,F5}为输入,通过下采样和横向连接的方式构建与自顶向下特征金字塔逐级对应的特征图{I1,I2,I3,I4,I5}。
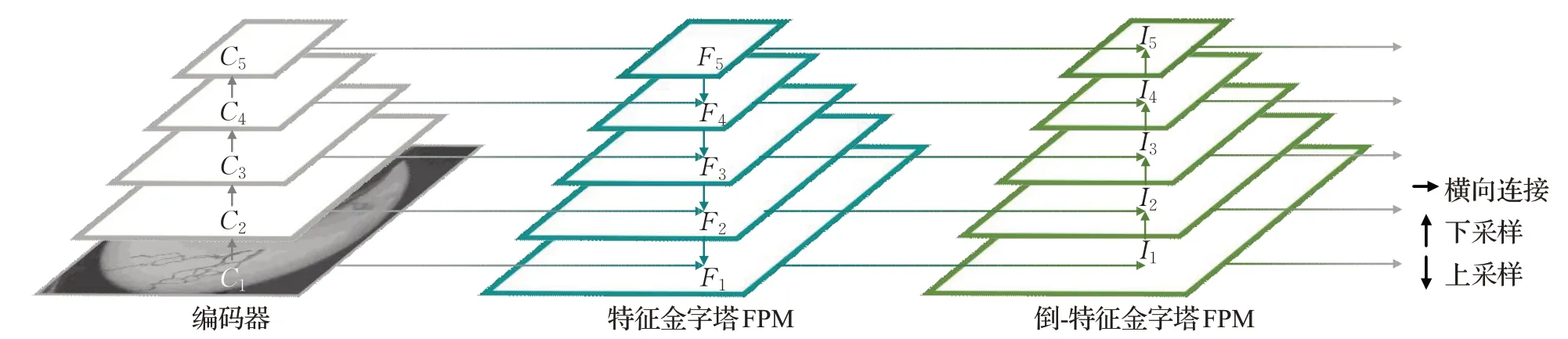
图2 可逆金字塔结构Fig.2 Architecture of RPM
FPM与编码器逐级相连,包括FPM1~FPM4四层,每层都采用了一个3×3的卷积核,通道数分别为512、256、128和64。其每层的输入为编码器对应层级输出特征图与特征金字塔邻近层输出特征图的连接结果,连接操作如图3所示(以FPM3为例)。其输入是编码器对应层级Conv3输出的特征图C3(尺寸为64×64×256)和金字塔邻近层FPM4输出的特征图F4(尺寸为32×32×512),首先对F4进行上采样操作,然后将其结果与C3连接,生成特征图F3'(尺寸为64×64×512)输入到FPM3中。
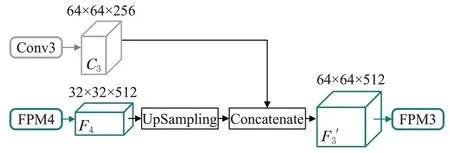
图3 特征金字塔的连接操作Fig.3 Connection operation of FPM
IFPM与FPM逐级相连,包括IFPM1~IFPM4四层,每层都采用了一个3×3的卷积核,通道数分别为64、128、256和512。其每层的输入为编码器对应层级输出特征图、特征金字塔对应层级输出特征图与倒-特征金字塔邻近层输出特征图的连接结果,连接操作如图4所示(以IFPM3为例)。其输入是编码器对应层级Conv3输出的特征图C3(尺寸为64×64×256)、特征金字塔对应层级FPM3输出的特征图F3(尺寸为64×64×256)和倒-金字塔邻近层IFPM2输出的特征图I2(尺寸为32×32×512),首先对I2进行下采样操作,然后将其结果与C3、F3连接,生成特征图I3'输入到IFPM3中。
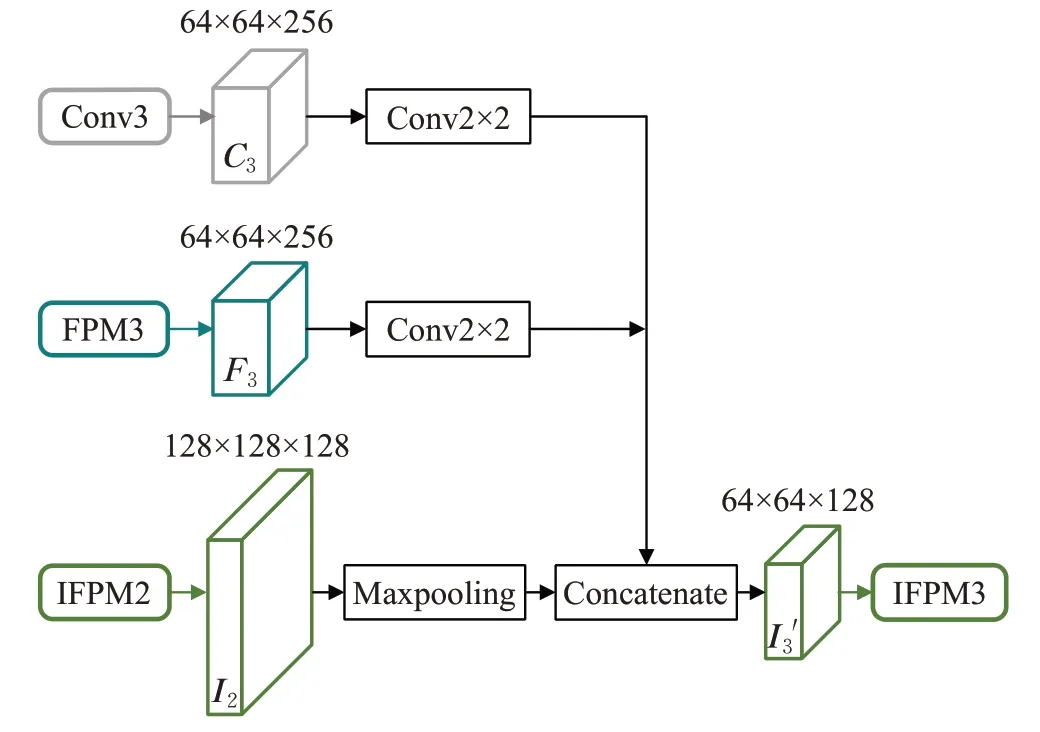
图4 倒-特征金字塔的连接操作Fig.4 Connection operation of IFPM
RPM的输出特征图表示为:
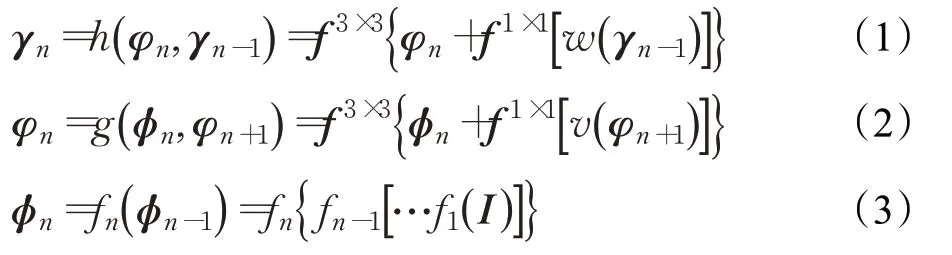
式中,γn为第n个经IFPM结构融合后的特征图;h(⋅)为IFPM结构函数;w(⋅)是双线性采样函数;φn为第n个经FPM结构融合后的特征图;g(⋅)为FPM结构函数;v(⋅)是双线性插值函数;f1×1为卷积核为1×1大小的卷积层;f3×3为卷积核为3×3大小的卷积层;φn为特征提取网络的第n层特征图;I为原始图像;fn为特征提取网络的第n个卷积函数。
1.2 平衡注意力模块
实验中发现裂缝检测存在孤立噪点的问题,其产生原因是独立像素级分类模型基于局部特征提取相关信息,无法很好地描述裂缝区域的空间关系,缺少全局特征。为了解决这个问题,引入了平衡注意力机制,在特征图中平衡细节特征与语义特征,加强获取全局相关性的能力,进而在计算过程中增强引导信息消除孤立噪点。
BAM基于注意力机制[17]进行改进,并将其与平衡特征分支[18]及RPM相结合,其结构如图5所示。BAM共包含f、g、h三个子分支,其中f子分支为特征金字塔分支,输出为FPM1输出的特征图Bf(即F1);g子分支为平衡特征分支,输出为平衡特征图Bg;h子分支为解码器分支,输出为Deconv1输出的特征图Bh。首先将f和g子分支用于计算注意力特征图Ba,该图包含每个成对的局部块的交互信息;其次将h子分支用于获取图像的常规卷积特征图Bh;然后将Ba与Bh相乘,获取最终的平衡注意力特征图Bs。
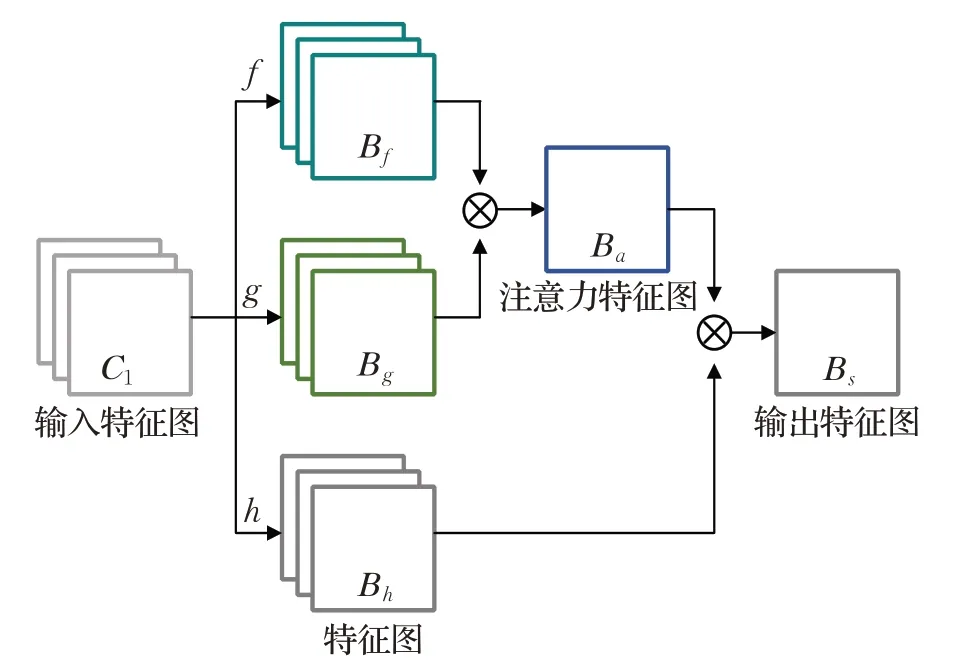
图5 平衡注意力结构Fig.5 Architecture of BAM
平衡特征分支作为g子分支,将不同层级的特征连接,平衡语义特征与细节特征,使得特征图中深层特征与浅层特征相互补充,增强裂缝注意力,提升检测性能,其结构如图6所示。首先将不同层级的特征图{I1,I2,I3,I4,I5}经过上采样操作后生成尺寸相同的特征图层,然后将特征图层进行连接,并对连接结果进行特征提取,生成特征图Bg(尺寸为256×256×64)。
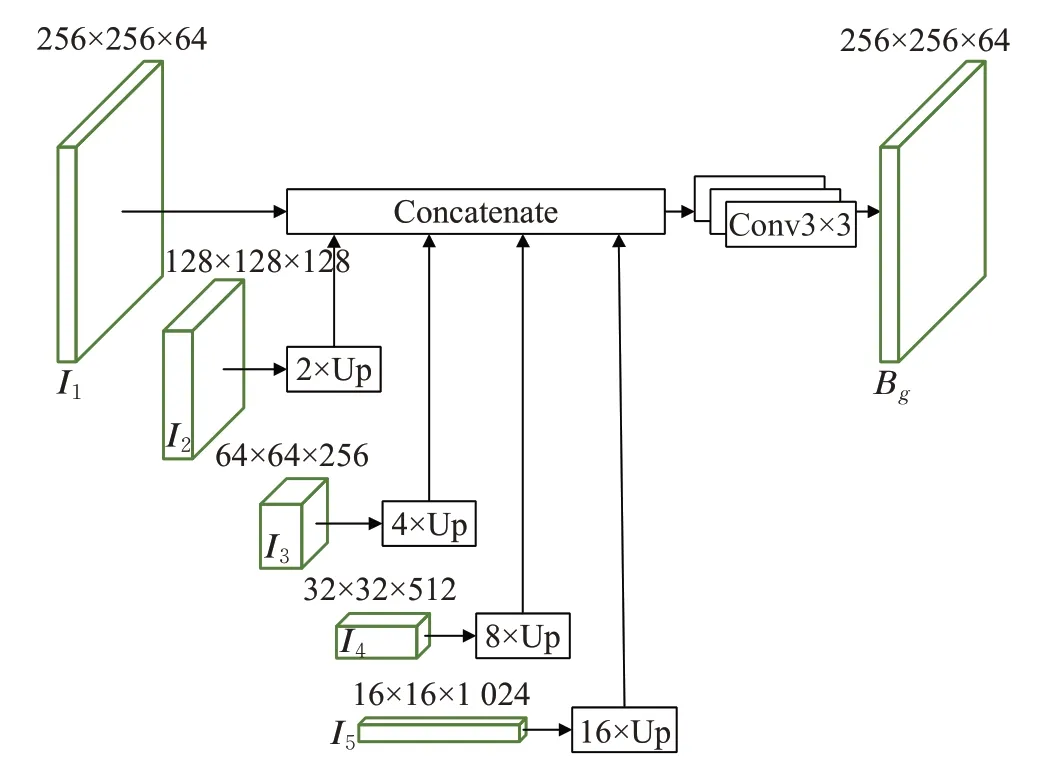
图6 平衡特征分支结构Fig.6 Architecture of balanced feature branch
BAM的输出特征图表示为:

式中,x∈RD×N是编码层输出的特征,即原始特征;v是超参数,用于平衡原始特征与自我注意特征;o是自我注意特征,按照以下过程计算。首先设f、g、h三个子分支的映射公式分别为式(5)~(7),式中Wf、Wg、Wh为三个子分支的权重矩阵,bf、bg、bh为偏差,用于提高自我注意机制的表达能力。将原始特征按照式(5)~(7)分别进行不同的特征映射得到新的特征图。

然后按照式(8)、式(9)计算图像中不同局部区域之间的关系,s(i,j)表示f(x)与g(x)两个特征图形成的特征组合,r(j,i)表示模型在表示第j块时对第i块的关注程度。

2 实验结果与分析
2.1 实验数据
为验证RPBAN的有效性和通用性,本文在一个瓷瓶裂缝数据集InsulatorCrack和三个公共裂缝数据集CrackForest-Dataset(CFD)[8]、CrackTree200[19]和AEL[20]上进行了测试。在实际使用数据时,首先对其进行resize处理统一数据大小,然后输入网络进行训练,resize处理后图像尺寸为256×256×1,如图7。
2.1.1 InsulatorCrack数据集
本文首先对国家电网公司无人机巡检过程中所拍摄的瓷瓶巡检照片进行采集整理,将图像大小统一调整为512×512像素。其次,在巡检专家指导下使用Labelme标注工具对整理后的114张瓷瓶巡检图像进行标注。该数据集命名为InsulatorCrack,分为84张训练图像、15张验证图像和15张测试图像,部分示例见图7(a)。由于图像数量有限,对现有数据进行了数据增强,通过对图像进行微小的改变(旋转、移位、翻转、缩放等),在扩增数据的同时,还可以阻止神经网络学习不相关的特征,从根本上提升整体性能。
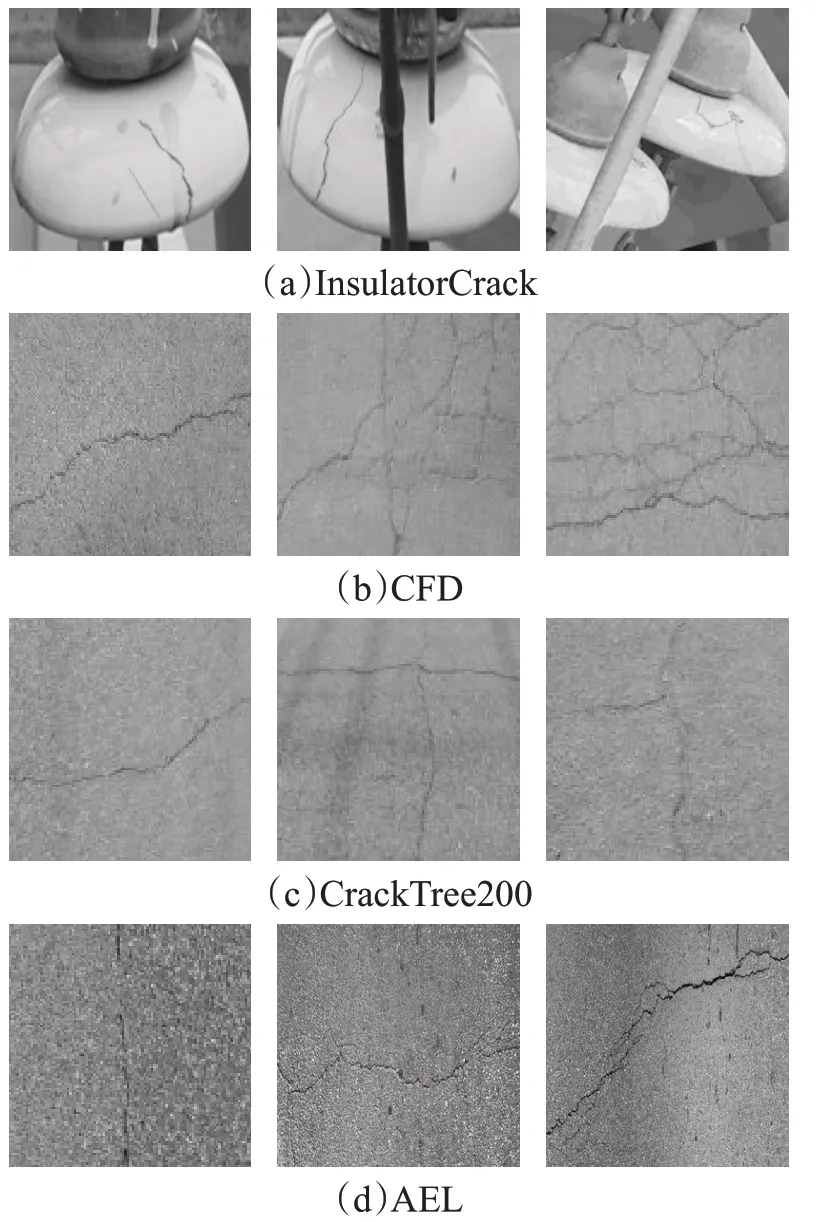
图7 工业裂缝数据集Fig.7 Industrial crack dataset
2.1.2 公共裂缝数据集
CFD数据集由118张北京城市路面裂缝图像组成,每个图像大小为480×320像素,其中训练集包含88张图像,验证集包含15张图像,测试集包含15张图像,部分示例见图7(b)。
CrackTree200数据集包含206张裂缝图像,每个图像大小为800×600像素,面临阴影、遮挡、低对比度等挑战,其中训练集包含166张图像,验证集包含20张图像,测试集包含20张图像,部分示例见图7(c)。
AEL数据集包含58张路面裂缝图像,其中训练集包含38张图像,验证集包含10张图像,测试集包含10张图像,部分示例见图7(d)。
2.2 实验设置
2.2.1 实验方法
本文实验采用RedHat 4.8.5-39操作系统、GeForce RTX 2080 Ti显卡进行模型训练。所提出的方法基于TensorFlow和Keras实现,其中,TensorFlow采用2.1.0版本,keras采用2.3.1版本,CUDA采用10.1版本,CUDNN采用7.6.5版本。在训练过程中,初始学习率设置为0.000 1,优化器选用Adam,损失函数采用Focal Loss函数,α设置为0.25,η设置为2。
为验证RPBAN在工业裂缝检测中的有效性,将本文模型与其他模型进行了比较,包括U-Net、FPHBN和DeepCrack。U-Net与本文基础网络保持一致;FPHBN基于HED引入特征金字塔与分层提升模块,按照文献[12]设置;DeepCrack基于U-Net引入分层卷积模块,按照文献[13]设置。这3种模型数据增强和训练方法均采用上述方法。
2.2.2 损失函数
实验中存在损失率很小但精确度不高的问题,这是由于工业裂缝图像中裂缝所占比例极小且特征复杂,而非裂缝占图像的大部分且多容易分类,正负样本极度不平均,负样本Loss值主导整个梯度下降,因此模型的优化方向并不是人们所希望的那样。针对这个问题,本文利用Focal Loss来有效优化检测模型。Focal Loss通过控制正负样本在训练中所占的权重,对小类别给予较大惩罚因子并对大类别给予较小惩罚因子,使得模型更专注于裂缝样本,模型对裂缝具有更高的灵敏度,缓解了样本不平衡带来的问题。Focal Loss定义为式(11):
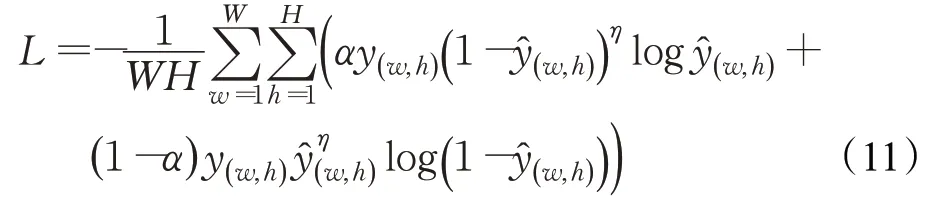
式中,W与H分别表示图像的宽度与高度,y(w,h)与ŷ(w,h)分别表示图像中(w,h)像素的标签与预测,α与η是两个超参数,用于控制权重。实验发现当α设置为0.25,η设置为2时取得最优结果。
2.2.3 评估指标
本文采用精确率(precision,P)、召回率(recall,R)与交并比(intersection over union,IoU)作为评估指标对瓷瓶裂缝检测结果进行定量分析。精确率P是正确预测为真的样本数占全部预测为真的样本数的比例,衡量“找的对”程度,定义为:

召回率R是正确预测为真的样本数占全部实际为真的样本数的比例,衡量“找的全”程度,定义为:

交并比IoU是预测为真与实际为真样本的交并比,衡量裂缝预测结果与真实情况的重叠程度,定义为:
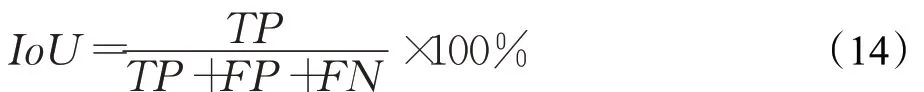
其中,TP、FP、FN分别表示真正例(true positive)、假正例(false positive)、假反例(false negative),其定义如表1所示。

表1 分类结果混淆矩阵Table 1 Confusion matrix
2.3 实验结果
2.3.1 消融实验结果
对RPBAN中Focal Loss、RPM和BAM这3个模块的有效性进行了实验验证和分析,实验结果如表2所示。比较表2结果可以发现,采用Focal Loss损失函数,模型在指标R、IoU方面分别提升了13.69、3.11个百分点;增加RPM模块,各指标分别提升了0.56、1.86、1.99个百分点;增加BAM模块,各指标分别提升了3.57、2.85、5.62个百分点,本文所提出的RPBAN与基础网络U-Net相比各指标分别获得了3.58、18.4、10.72个百分点的增量,证明了本文提出的各模块在瓷瓶裂缝检测中的有效性。其部分对比结果如图8(e)~(h)所示。从图中可以看出,加入RPM和BAM模块后的检测模型裂缝检测更完整,细节更丰富,尤其是细小裂缝检测性能不足与孤立噪点的问题都得到了有效解决,以上实验结果验证了所提出组件的有效性。
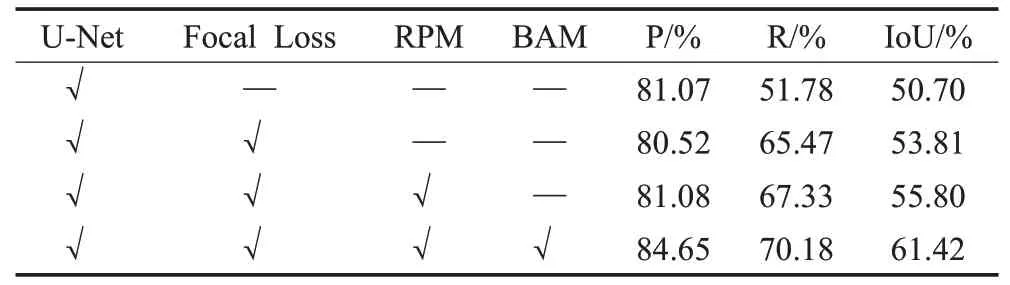
表2 消融实验定量比较结果Table 2 Quantitative comparison results of ablation experiments
本文方法的训练过程损失变化图与指标变化图分别如图9与图10。该方法共训练50个epoch,每个epoch训练300代,共迭代15 000次,各损失在训练过程中趋于收敛。随着训练的进行,IoU指标稳步上升,最终达到61.42%。
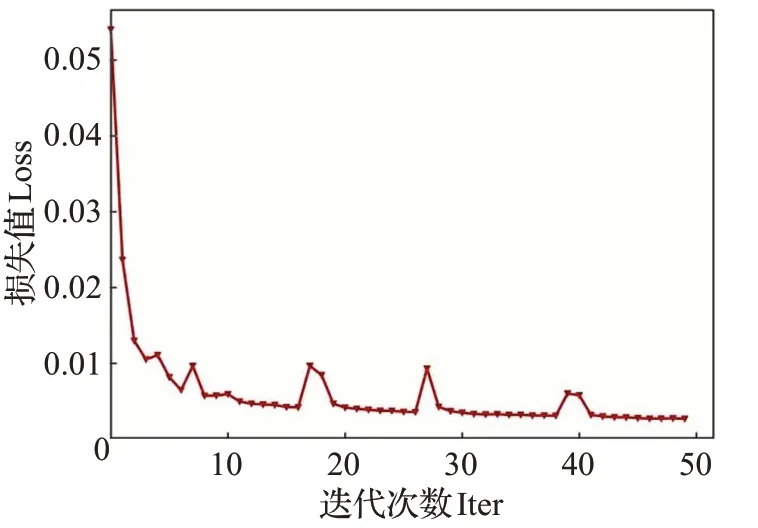
图9 RPBAN训练过程损失变化图Fig.9 Changes in loss during RPBAN training
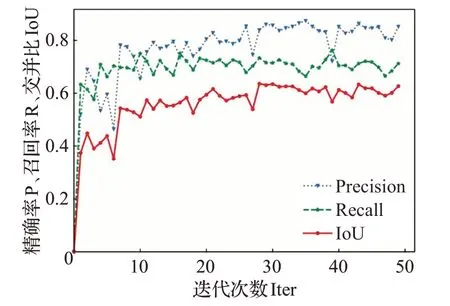
图10 RPBAN训练过程各指标变化图Fig.10 Changes in precision,recall,IoU during RPBAN training
2.3.2 对比实验结果
各对比方法在InsulatorCrack测试集上裂缝检测结果的定量比较如表3所示。从表中可以看出,RPBAN的指标P、R、IoU皆为对比模型中最高,其中指标P分别比其他模型高3.58、2.38、10.48个百分点,指标R分别高18.4、2.38、5.65个百分点,IoU分别高10.72、3.92、8.73个百分点,验证了本文模型在瓷瓶裂缝检测中的优越性。图8(c)~(e)、(h)是各模型在InsulatorCrack测试集上的部分检测结果。在图像裂缝清晰且干扰较少时,U-Net、FPHBN、DeepCrack和RPBAN都能够较准确地检测出裂缝,如图8中第1~2行所示,但当图像中裂缝较复杂或背景干扰较大时,各模型出现了不同程度的裂缝检测不连续或孤立噪点,如图8中第3~6行所示,但本文模型RPBAN则基本能够保持裂缝的完整性,细节表现更好。InsulatorCrack数据集上各对比方法IoU指标变化如图11所示,从图中可见RPBAN瓷瓶裂缝检测性能最好。

图8 InsulatorCrack数据集上定性比较结果Fig.8 Qualitative comparison results on InsulatorCrack dataset
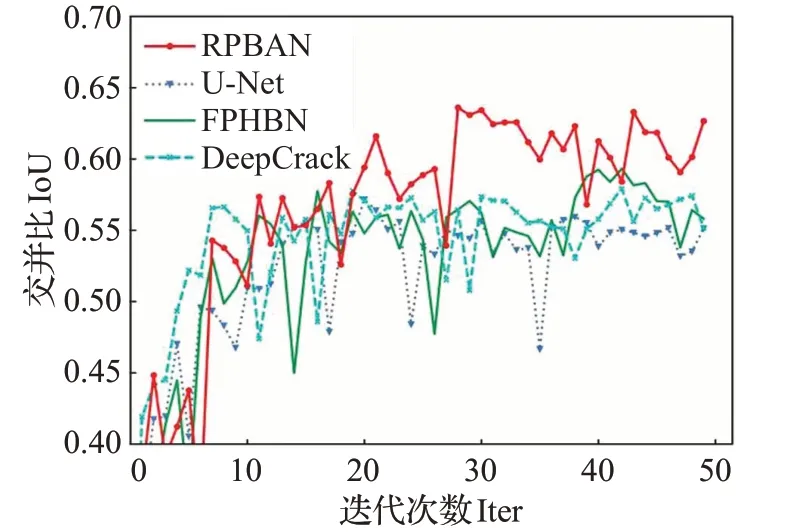
图11 InsulatorCrack数据集上IoU指标变化图Fig.11 Changes in loss on InsulatorCrack dataset
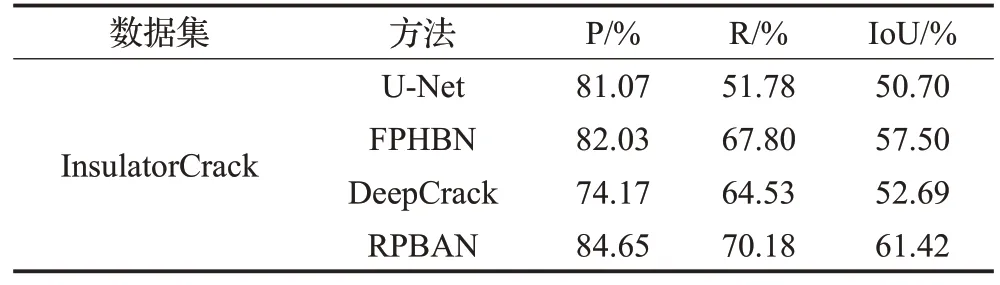
表3 InsulatorCrack数据集上定量对比结果Table 3 Quantitative comparison results on InsulatorCrack
为了验证RPBAN的有效性与通用性,分别在CFD、CrackTree200和AEL数据集上将训练好的RPBAN与U-Net、FPHBN、DeepCrack方法进行比较分析。各对比方法定量比较结果如表4所示。从表中可以看出,RPBAN的指标IoU在各数据集上分别达到了58.36%、64.45%、53.44%,与各模型相比仍保持优势,说明了本文模型在裂缝检测中的有效性与优越性。图12所示为各数据集上部分定性比较结果,前5行是CFD数据集,中间5行是CrackTree200数据集,后5行是AEL数据集。从图中可以看出CFD数据集上,各对比方法细节损失较为严重,与之相比RPBAN细节表现更好;CrackTree200数据集上,对比方法检测结果存在孤立噪点与细小裂缝消失问题,RPBAN与真实结果更为接近;AEL数据集上,对比方法受背景噪声影响尤为严重,与之相比RPBAN检测结果更好。由此可见RPBAN在细小裂缝检测与孤立噪点消除方面较其他模型更为优异。以上实验结果均证明了所提出方法的有效性和优越性。
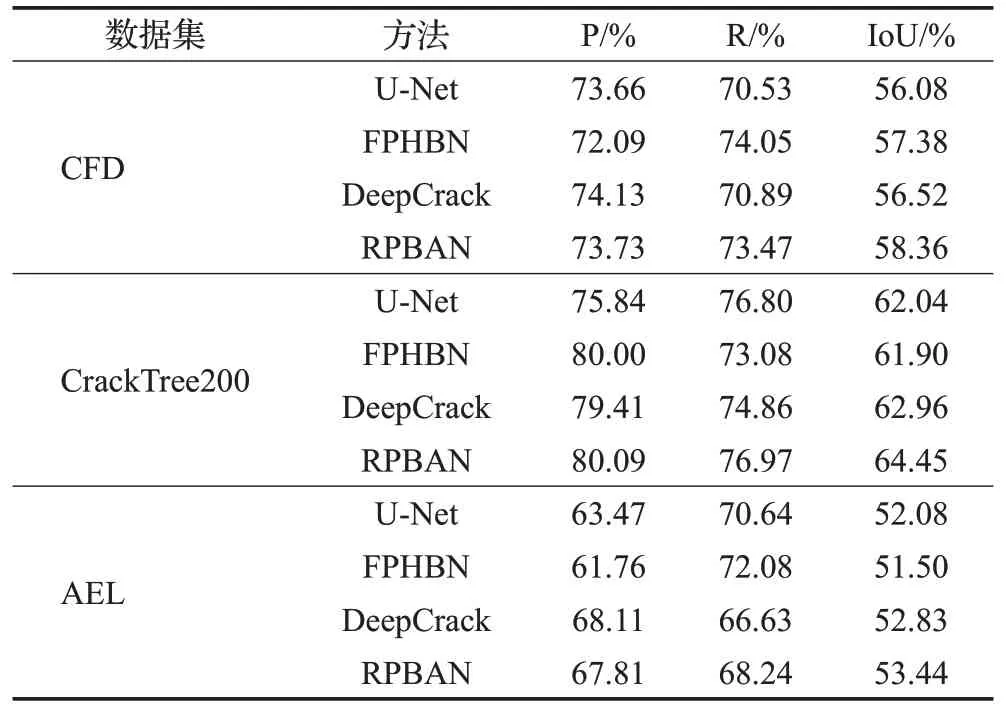
表4 公开数据集上定量对比结果Table 4 Quantitative comparison results on public datasets
3 结束语
本文提出了一种新的工业裂缝分割网络RPBAN,实现了高效精准的工业裂缝语义分割。RPBAN基于U-Net网络,在编码器与解码器之间增加可逆金字塔模块,在解码阶段引入平衡注意力模块,建立小样本、像素级的工业裂缝分割网络,解决了孤立噪点、细小裂缝检测性能不足的问题;同时选取Focal Loss作为损失函数,解决了类不平衡带来的“虚假”损失率的问题。最后,在四个数据集上进行评估,实验结果验证了所提方法的有效性、优越性与通用性。下一步将在本文所提方法的基础上继续进行瓷瓶裂缝测量的相关研究,对瓷瓶裂缝相关信息进行精细化测量。
猜你喜欢
环球时报(2022-09-19)2022-09-19
北京航空航天大学学报(2021年9期)2021-11-02
石油与天然气地质(2021年3期)2021-06-29
考试与评价·七年级版(2020年4期)2020-10-23
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
意林·全彩Color(2018年7期)2018-08-13
北京航空航天大学学报(2018年1期)2018-04-20
小学教学研究·新小读者(2017年9期)2017-10-25
海峡姐妹(2016年6期)2016-02-27
