
结合全局-局部特征和注意力的图像描述方法
2022-06-23 06:24谢琦彬陈平华
计算机工程与应用 2022年12期
谢琦彬,陈平华
广东工业大学 计算机学院,广州 510006
近年来,图像描述(Image Caption)任务在计算机科学领域受到了很多关注,逐渐成为热门话题。图像描述任务是计算机视觉技术和自然语言处理技术结合的产物,其本质是计算机对输入图像的内容进行识别和理解,并自动生成一段用人类语言描述的文本。这项任务不仅节省了对海量的图像进行人工标注花费的时间,还可以应用于盲人导航、儿童早教等多个方面,具有重要的研究意义。图像描述生成任务作为一种跨领域任务,一方面需要模型提取图片中的对象以及对象间的关系,另一方面还需要高度理解图像特征并生成描述正确且逻辑清晰的语句。传统的研究图像描述生成任务的算法主要有以下两大类:基于模板的图像描述方法[1-3],该类方法首先会捕捉图像中的对象、动作、场景,然后把它们填入到固定的句子模板中生成图像的标注,这类方法特点是操作简单,但生成的语句缺乏一定的多样性,与人工标注句子的表述风格相差过大;基于检索的方法[4-5],该类方法将目标图像与经过人工标注图像数据库中的图像进行相似度排序,检索最佳表述,但该方法生成的文本严重依赖图像数据库当中的人工标注,无法生成新颖的语句,缺乏灵活性。近年来随着深度学习的成功,基于编码器-解码器的模型解决了输入输出序列必须等长的限制条件,自然语言领域中的机器翻译、机器写作等任务中大量使用该模型进行研究,且取得了十分优异的效果。研究学者将其应用在图像描述生成任务当中,使用编码器对输入的图像进行特征提取,再通过解码的方法生成最终的文本描述。Mao等在文献[6]中提出使用卷积神经网络(convolutional neural networks,CNN)作为编码器将图像转换为固定长度的向量表示,然后传入到循环神经网络(recurrent neural networks,RNN)中输出相应的文本描述。文献[7]提出了一种端到端训练的神经图像字幕生成器(Google NIC),该模型使用深度卷积神经网络提取目标图像的视觉特征表示,使用长短期记忆神经网络[8](long short-term memory,LSTM)替代RNN生成文本描述,改善了RNN在长文本序列上的梯度弥散问题,提升了描述文本的质量。文献[9]对LSTM进行了改进,将编码器从图像中获取的信息添加到LSTM中进行训练,用于指导描述文本的生成。为了进一步增强模型对图像重要区域信息的捕捉,文献[10]提出了将注意力机制融入到图像描述生成任务中,并提出了两种不同的注意力机制,分别是软注意力(softattention)机制和硬注意力(hard-attention)机制,软注意力机制针对每个划分的图像区域学习注意力权重后进行加权求和,权重系数总和固定为1;在硬注意力机制中,将某一个图像区域的权重设为1,其他区域设置为0,从而达到仅关注某一个区域的目的。文献[11]提出了视觉哨兵的概念,哨兵向量决定模型在每个时间步上生成单词时选择依赖图像信息还是语义信息,以提高描述的正确性。与基于模板和基于检索的方法相比,基于编码器-解码器的方法泛化能力强,所生成的描述文本表达自然。上述方法对图像描述任务做了大量的工作,但是该任务仍然面临着一些急需重点解决的问题:(1)大多数基于神经网络的方法并没有对图像特征进行充分的利用,往往只使用图像全局特征去生成描述文本,在训练过程中会出现对象丢失和预测错误的问题,编码器提取的图像特征与注意力机制没有实时结合,模型只考虑到上一时刻编码器的图像上下文向量而忽略了当前时刻下的图像信息;(2)传统的注意力机制仅使用隐藏层状态去选取合适的图像特征信息,而没有对内部信息做进一步的检验,存在同一时刻下语义特征与图像特征不一致的问题。
针对以上方法存在的问题,本文以增强图像特征提取、改进注意力机制为研究内容,提出了一种结合图像全局-局部特征和注意力机制的图像描述方法,本文的主要特点如下:
(1)分别利用残差网络ResNet101的全连接层和最后一层卷积层分别提取图像的全局特征和局部特征,对两种图像特征在编码阶段做不同的利用。
(2)提出一种实时注意力模型,在每一时刻下根据图像特征和语义特征之间的相似度来计算注意力得分,使得图像特征信息与文本描述信息能具有最大的相关性。
(3)在解码过程中使用双向门控循环单元(gated recurrent unit,GRU)结构替代LSTM,在生成文本时考虑到双向语义,使目标区域与生成语言之间的对齐更加合理,提高图像描述的准确度。
1 结合全局-局部特征和注意力机制的图像描述方法
本文的模型整体结构如图1所示,主要分为图像特征提取模块和文本生成模型两个部分,首先利用特征提取模块对图像进行处理,将编码好的图像向量馈入到文本生成模块生成图像描述文本序列。在测试阶段,本文随机选择若干张图片输入到模型得到对应的描述文本,再与人工标注的句子进行比较,最后得出结论。
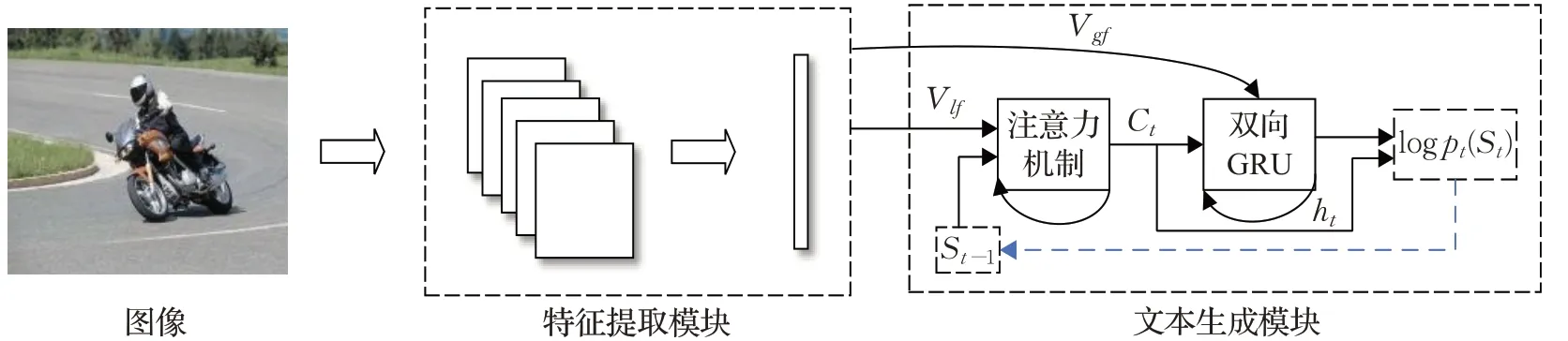
图1 图像描述生成模型Fig.1 Image caption model
1.1 图像特征提取
随着计算能力的提高,深度卷积神经网络在计算机视觉任务当中取得了优异的表现,这些模型最大的优势就是在大型数据集上进行训练后可以直接当作图像的特征提取器,使用深度卷积网络的全连接层提取的特征通常是一维向量,包含的仅是图像的全局语义信息,很容易丢失图像对象间的细节信息,为了使每个特征向量与图像的内容相关联,从预训练的深度卷积神经网络的卷积层中提取特征,将其定义为局部特征,这些局部特征可以帮助模型选择性地使用图像中的对象信息生成对应的字幕。将两种不同粒度的特征作为输入,可以使得目标之间的关系表述得更加合理,更加准确。
在本文中,采用经过预训练的ResNet101作为模型的图像特征提取器,ResNet[12]网络最大的特点就是在每层网络之间添加了残差块,残差块有助于解决随着网络层数的不断增加而造成的梯度消失问题。
ResNet结构如图2所示,其在每一层的输出与下一层输入之间添加了直接映射,将恒等映射关系H(x)=F(x)转化为F(x)=H(x)-x,避免在反向传播过程中梯度趋近于0,有利于训练更深的模型,从而学习到更多的信息。与另一种时下应用广泛的深度卷积神经网络VGG16相比,ResNet网络在性能方面表现更为优异,可以显著提升效果[13]。在本文中,对于给定的图像I,首先抽取ResNet101全连接层提取的特征作为全局特征Vgf,特征向量Vgf会作为整个图像信息直接输入到解码器模块中,将ResNet最后一层卷积层的输出抽取表示为局部特征Vlf={vlf1,vlf2,…,vlfL},其中L代表总共生成的向量个数,局部特征用于注意力机制去训练注意力权重系数,使得模型在每一时刻下的侧重关注区域都有所不同。
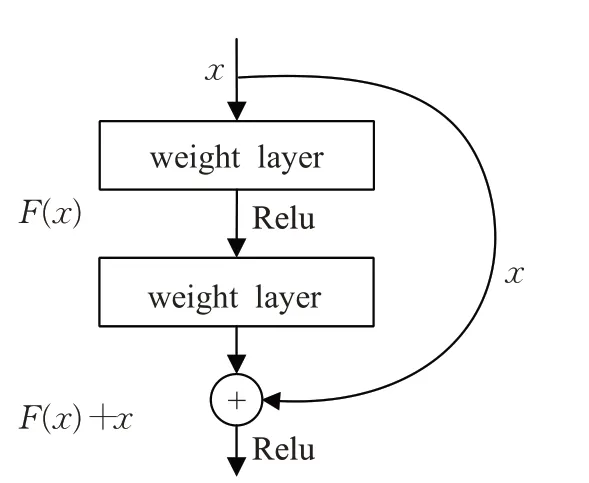
图2 残差结构图Fig.2 Residual structure diagram
1.2 GRU
在图像描述任务中通常使用长短期记忆网络LSTM作为解码器来实现对序列的非线性特征学习,LSTM由一个记忆单元(constant error carrousel,CEC)和三个门(gate)组成,其核心思想是引入了自适应门控机制,记忆单元用于帮助模型保存当前时刻生成的有关图像的隐式信息并传递给下一时刻使用,使得第N个单词的生成不仅与前一个单词相关,而是和前面N-1个单词都相关,这样本文生成准确率就会大幅提高。为了简化LSTM结构,研究学者进而提出了GRU网络结构,GRU原理与LSTM相似,但与LSTM相比最大的特点是将遗忘门和输入门合并为一个更新门,减少了1/3的训练参数,在保证效果相同的情况下加速反向传播算法的效率,提升整个实验的训练性能。图3是GRU的结构图。
在图3中,xt代表t时刻输入的文字信息,序列表示为x={x1,x2,…,xn},ht是更新后的隐藏层状态,r表示控制重置的门控,重置门的作用是判断前一时刻状态ht-1对当前状态ht的重要程度,当rt的值越小时允许模型遗忘更多的信息;z为控制更新的门控,其输出的值始终在(0,1)之间,表示前一时刻隐藏层输出信息被保留到当前状态中的程度,当zt的值越大时,代表记忆前一时刻隐藏层带入的信息越多。具体公式如式(1)~(4)所示:
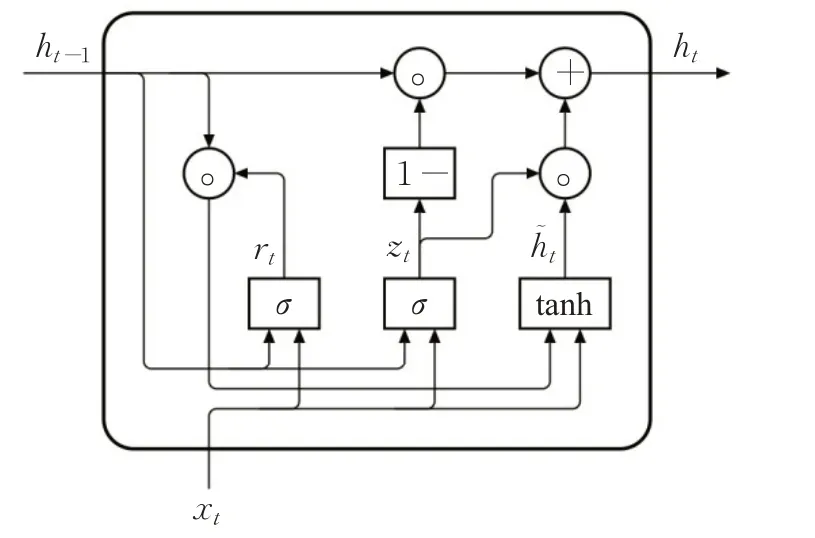
图3 GRU模型Fig.3 GRU model
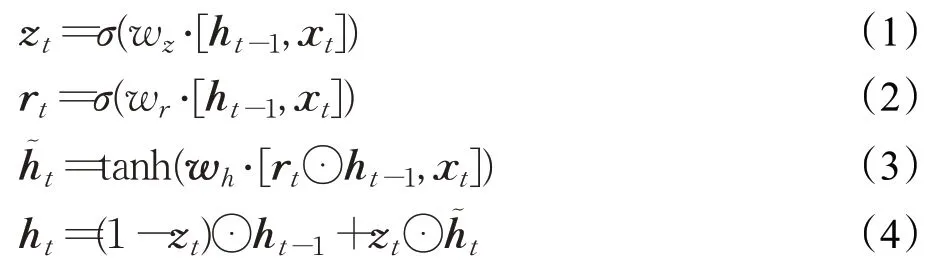
h͂t表示当前时刻候选隐藏层状态信息,也称为记忆信息,由重置门与前一时刻的隐藏层状态信息计算得出。zt⋅h͂t表示对当前时刻候选隐藏层状态信息进行选择性储存,(1-zt)⋅ht-1表示遗忘上一时刻的隐藏状态ht-1中某些维度信息,σ是sigmoid非线性激活函数,tanh是双曲正切S型函数,wz、wr、wh分别表示训练过程当中学习到的一些参数。
单向GRU网络只能通过获取过去序列信息来预测当前的单词,但如果想准确地获取一个语句所表达的意思,未来的序列信息同样是十分重要的。例如在中文文本序列中“重庆市长江大桥视察工作”,当顺序读取语句可以获得“重庆/市长/江大桥”以及“重庆市/长江大桥”两种语义,当反向获取语义信息时,会首先得到“视察工作”这个词组,进而可以推断前面出现的应该是人名而不是物名,最后得出该句子的意思是“重庆/市长/江大桥/视察工作”。因此在获得文本时需要考虑到双向语义才能避免产生歧义,双向GRU包括前向传播和反向传播两种方式,对于每一时刻t,都会训练两个方向相反的GRU,最终输出的向量是前向学习和反向学习拼接的结果:ht=[ht-F,ht-B]其中,ht-F、ht-B分别表示t时刻下GRU前向学习和反向学习的隐藏层状态。
1.3 实时注意力机制
注意力机制参考了人类神经视觉行为特点,例如人类在观察某幅图像的时候首先会将视觉能力聚焦在整幅图像中最显眼的部分,再去观察图像中的其他细节。在某种程度上,可以将注意力模型当作一种资源分配模型,假设在生成描述文本时对图像中所有区域中的信息进行同等程度的处理,就会忽略掉图像中重要的焦点信息,注意力机制的本质是为不同的图像区域赋予不同的权重系数,权重越大表示该图像区域对于生成最终的描述文本有着更重要的意义。在文本中提出了一种新的注意力机制,该机制通过循环结构获取长序列语义,计算语义向量和图像特征向量之间的相似度来获得注意力权重,使得注意力机制在生成图像上下文信息时会考虑到实时的背景信息。实时注意力机制如图4所示。
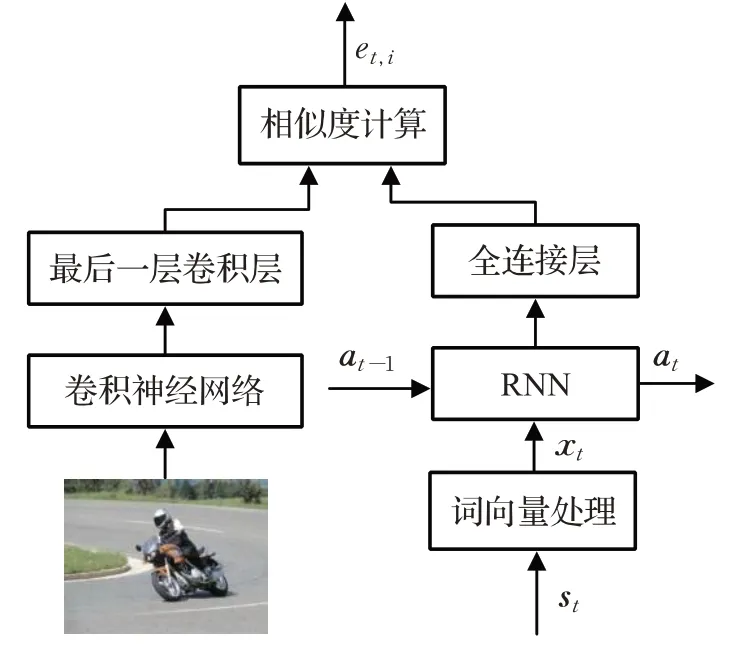
图4 实时注意力机制Fig.4 Real-time attention mechanism
st是表示t时刻输入的单词,它是一个独热编码形式的向量,由于词汇表的维度过于稀疏,因此乘上一个单词嵌入矩阵WE将其转化为到一个较为稠密的向量xt,即xt=WE*st,语义向量at表示在传递过程中保存下来的信息,在t=0时刻初始化为全0的矩阵,at更新公式如式(5)所示:
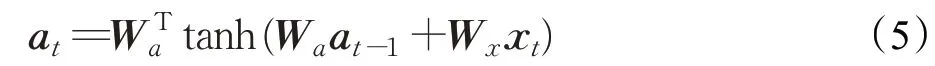
注意力权重系数是通过对语义信息at和图像局部特征Vlf求相似度计算得来的,根据注意力机制的定义可知,当注意力权重越大时,表示语义信息与图像特征信息之间的关联度越大,在式(6)中Wv、Wa分别表示向量的参数矩阵:
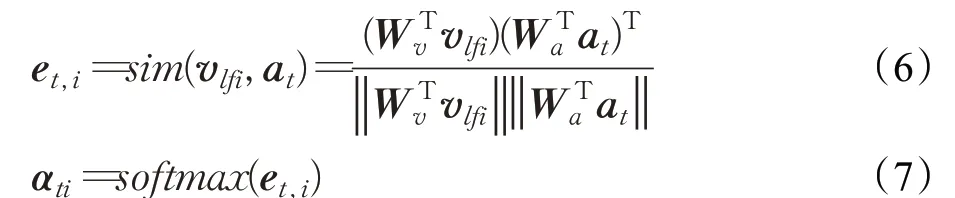
αti表示的是第i个图像区域在t时刻下的注意力权重,最后对图像特征与注意力权重做一个加权整合,得到图像上下文信息:

1.4 全局-局部特征和注意力机制模型的融合
传统的基于注意力网络的图像描述模型如图5所示,图像首先经过卷积神经网络提取得到特征V,将V与长短期记忆网络的隐藏层状态ht-1作为注意力机制网络的输入,注意力结构对图像特征进行权重系数分配后输出图像上下文向量信息Ct,再结合当前时刻的隐藏层状态ht馈入到感知机当中生成单词yt,整个文本序列的生成过程就是对上述过程进行一个不断的循环。
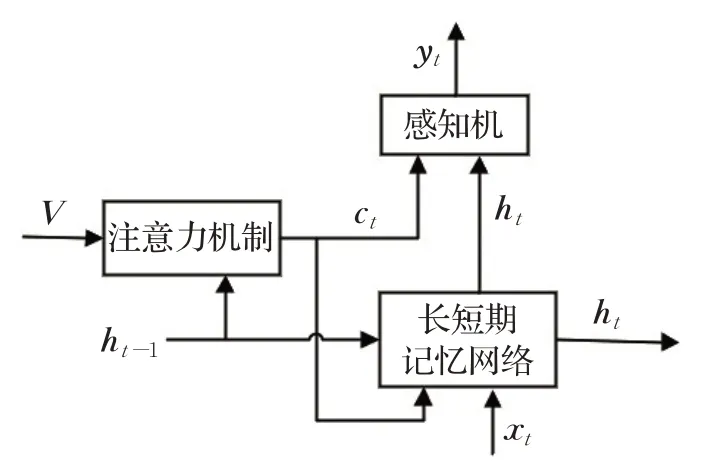
图5 传统的基于注意力的图像描述模型Fig.5 Traditional attention-based image caption model
但是需要注意的是,传统的基于注意力机制的图像描述模型并没有充分利用图像特征,其提取的仅是图像的全局特征而没有利用到图像的局部特征;同时鉴于图像的上下文信息与当前时刻的隐藏层状态应该是紧密相关,本文在传统图像描述生成网络上进行改进,进一步提出结合全局-局部特征和注意力机制的模型,模型如图6所示。
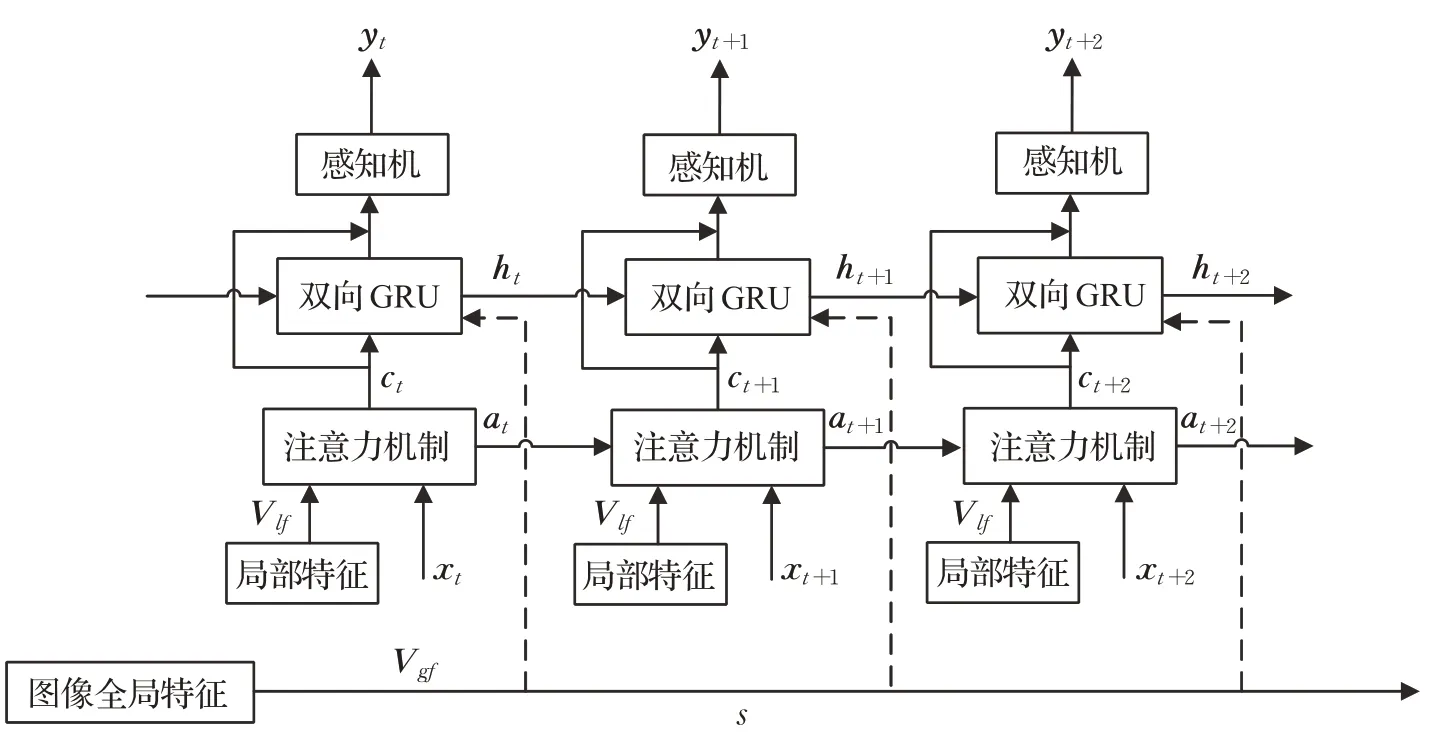
图6 结合全局-局部特征和注意力机制的模型Fig.6 Model combining global-local features and attention
考虑到需要提取细粒度更高的图像视觉信息,本文模型中的注意力机制结构与图5所示方法有所不同,在图6中,注意力机制利用图像局部特征向量和文字特征向量的相似度计算注意力权重,输出的上下文向量ct每时刻都在特定位置利用图像局部特征,因此可以利用ct指导图像的全局特征去生成隐藏层状态向量,GRU以注意力机制的输出ct和图像全局特征Vgf作为输入,公式(1)~(4)是单向GRU更新的过程,双向GRU的输出为前向网络的输出与后向网络输出的一个拼接:ht=[ht-F,ht-B],同时为了加强图像特征与描述文本之间的映射关系,在GRU输出的部分加入了残差模块,避免在训练过程中部分信息的丢失。
文本的算法步骤可以具体表示为:
输入 图像
输出 图像的描述文本
1.for i in[1,N]
2.利用ResNet101网络提取图像的局部特征Vlf,并将图像局部特征向量Vlf与词向量xt输入到注意力机制当中;
3.注意力机制通过计算图像局部特征向量Vlf与词向量xt之间的相似度获取注意力权重,然后将注意力权重与图像特征结合获取上下文向量ct;
4.将获取的上下文向量ct、ResNet101提取的图像全局特征Vgf以及上一时刻的解码器隐藏状态ht-1馈入到双向GRU中,去更新解码器当前时刻下的隐藏层状态ht;
5.利用残差结构将t时刻的隐藏层状态ht和上下文向量ct输入到softmax层得到生成词yt;
6.end
7.获得描述文本
1.5 损失函数
本文模型采用图像描述生成任务中常用的交叉熵进行训练,损失函数形式如下所示:

2 实验及结果分析
2.1 评价指标
为了对生成的图像描述句子的质量进行精确评估,实验需要采用不同的客观量化方法进行验证,本文使用的一些评估指标包括BLEU(bilingual evaluation understudy)[14]、METEOR(metric for evaluation of translation with explicit ordering)[15]、CIDEr(consensus-based image description evaluation)[16],对于所有指标,越高的分数表示性能越好。
BLEU:最初是为机器翻译任务设计的,现在广泛应用于图像描述任务,它通过N-gram计算输出文本和人工标注的一个或多个句子之间的匹配分数,输出值始终在0~1,BLEU又细分为BLEU-1、BLEU-2、BLEU-3、BLEU-4。BLEU-1表示原文有多少词被单独翻译出来,可以用来反映译文的充分性,其余三个指标用于反映译文的流畅性。
METEOR:用于评价机器翻译输出的标准,该方法不仅考虑了准确率,还涉及了召回率。
CIDEr:专门设计用于测量图像描述文本与人类标注的参考语句之间的一致性,它是通过对每个n元组进行TF-IDF权重计算,更能反映所生成句子的质量。
2.2 数据集和参数设置
本文实验部分使用的数据集是微软公司构建的MSCOCO2014[17]数据集。MSCOCO2014数据集由自然场景和人类生活中的常见图像组成,它具有背景复杂、类型较多的特点,常用于图像识别、图像分割、图像描述等任务,其中包含113 287张训练集,5 000张验证集和5 000张测试集,每张图像均有人工添加的5个注解,由JSON格式提供,文本序列长度分布如图7所示。在本文实验中,通过训练集和验证集来调试实验中的参数设置,然后在测试集上进行训练获取指标分数,与其他主流模型比较对比。
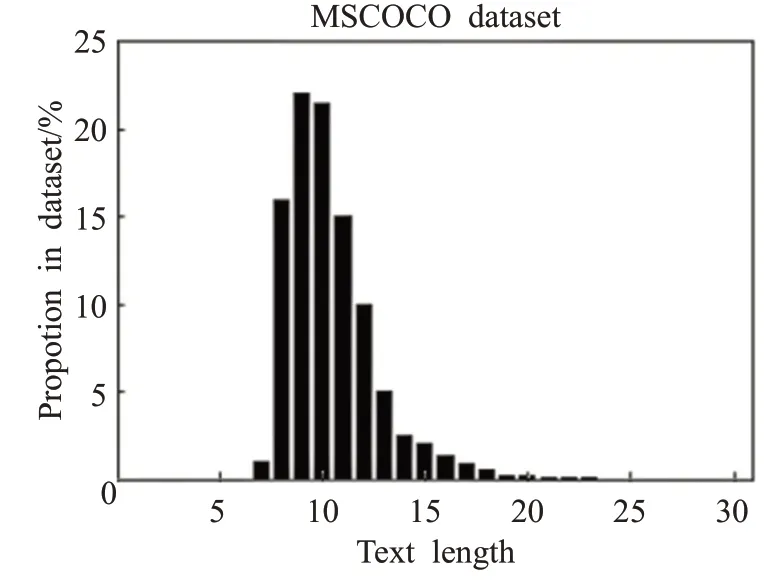
图7 MSCOCO数据集长度分布Fig.7 MSCOCO data set length distribution
在模型训练之前,对输入的文本数据进行如下预处理:将词汇量限制在前5 000个单词,将所有单词全部转化成小写,去掉空格和特殊字符,如“?”和“!”等,设定描述文本的最大长度为16,同时为每个描述都添加

表1 训练超参数Table 1 Training hyperparameters
2.3 实验结果及分析
为了使实验结果体现得较为直观,表2显示的是本文算法与mRNN[6]、GoogleNIC[7]、Soft-Attention[11]、Hard-Attention[11]以及近年来有关于图像全局-局部特征的描述模型[20-21]在MSCOCO数据集下的评估结果。
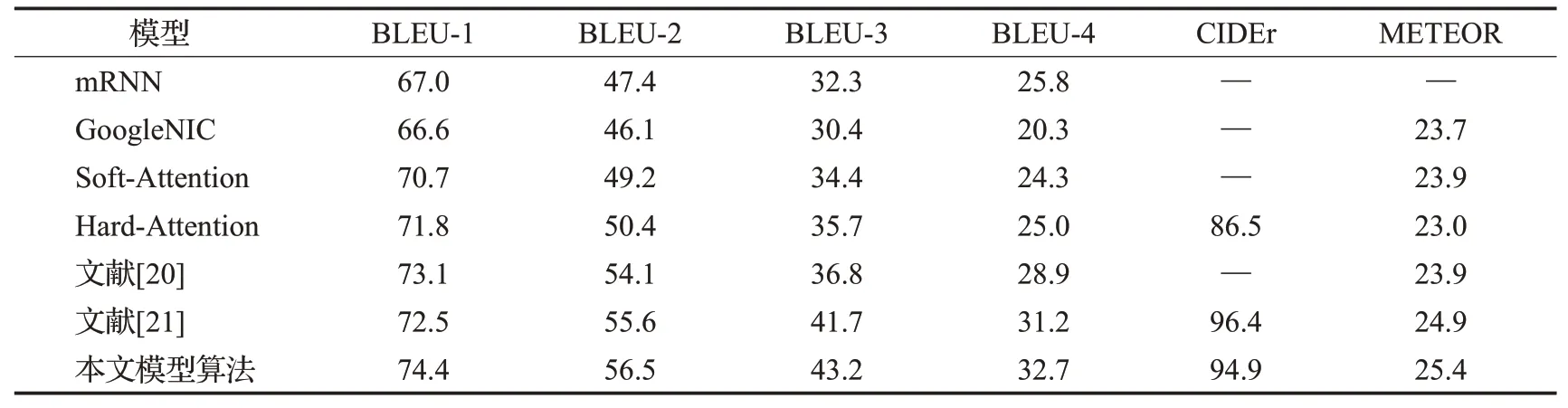
表2 不同算法在MSCOCO数据集上评价指标得分对比Table 2 Different algorithms evaluate comparison of index scores on MSCOCO dataset %
从实验模型分析,性能提升的原因有以下几点:使用基于残差网络的深度卷积神经网络提取图像特征可以有效减少在训练过程当中由于网络层数增加带来的梯度消失问题,其次采用了实时注意力机制能够更好地表征每一时刻下图像特征信息与文字向量信息间的关系,解码时采用的双向GRU网络可以携带不同训练方向的语义信息,能够有效生成通顺、合理的语句。最后在训练过程当中,利用Dropout和Beam Search帮助模型进一步优化模型,提升鲁棒性,获得更好的效果。本文工作也与文献[20-21]进行了比较,文献[20]中提出的是使用InceptionV3和VGG16网络分别去提取图像的局部特征和全局特征,在获得两种特征后拉伸成同一维度,拼接成最终的图像特征向量进行解码,并没有使用注意力机制取处理图像特征与文字向量之间的映射关系;文献[21]则是选用VGG16提取全局特征,Faster R-CNN提取局部特征,通过注意力机制可以选择地关注不同时刻下的显著对象,考虑它们的图像上下文信息。以上两种模型并没有考虑到注意力机制的改进以及解码器输出时的双向语义,因此本文相较于以上的模型有了更进一步的改进,在以上的评价指标中,有一定程度的提升。
为了更直观地证明模型的有效性,在MSCOCO数据集上的一些图像描述结果如图8所示,这些图像定性的分析了文献[7]和本文提出模型的性能。图8(a)是使用文献[7]生成的描述,图8(b)是使用本文算法实现的图像描述。图8(b)不仅对(1)图识别出了大象站在栅栏前的这一动作,而且识别出了“metal fence”对细节的描述更为丰富;图8(b)准确检测出了(2)图中的“the pink house”,而图8(a)则只识别到了建筑物“building”;图8(a)对(3)图仅仅识别出了“a woman”,而忽略了图中的另一个小女孩,对物体“frisbee”错误识别成“kite”;图8(b)对(5)图片的男人和女人并没有准确表达,而只是模糊识别出了“a couple of people”。从上面的结果可以看出,本文算法在描述结果上不仅准确率更高,而且细节表现更佳。

图8 生成图像描述对比结果Fig.8 Generate image caption comparison results
为进一步测试本文模型的效果,在测试集随机选取若干张图像,使用本文提出的算法模型生成描述文本,结果如图9所示。图9中的图片包含有动物、食物、风景、运动等不同风格,通过对这些图片测试的结果可以看出,本文算法在最后的生成描述上具有较为优异的表现,能够准确地表达图片所包含的内容,在细节处理上也较为细致,但是也有极少数图片上存在一些缺陷:例如图9的(2)中没有将花瓶中的假鹅识别出来,仅识别出了花瓶与花这两个物体,而图9的(7)更是错误地将人的手识别为了绳子,提升生成字幕的稳定性、降低错误识别率是后续工作中会继续研究并解决的重点问题。

图9 随机选取图像生成结果Fig.9 Randomly select image caption generation results
3 总结与展望
本文提出一种结合全局-局部特征和注意力机制的图像描述方法,利用图像的局部特征与词向量之间的相似度去计算注意力权重,使注意力机制能够准确捕获图像中的对象以及对象之间的关联,最后利用图像的全局特征和注意力上下文指导单词序列的生成。在MSCOCO2014数据集上的实验结果表明,结合全局-局部特征和注意力的模型取得了较为优秀的评估分数,证明了模型的有效性。本文的主要不足之处在于,模型训练过程中有一些图像生成的字幕并不稳定,表述得不够清楚,下一步将设计更为有效的注意力机制,对全局特征与局部特征做更为紧密的结合,提升模型的泛化能力,以生成表达更为丰富的图像描述字幕。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
甘肃教育(2020年22期)2020-04-13
金桥(2018年4期)2018-09-26
第二课堂(课外活动版)(2016年2期)2016-10-21
小学阅读指南·高年级版(2014年2期)2014-05-27
军事历史(1986年4期)1986-08-21
军事历史(1981年1期)1981-08-21
