
引入轻量注意力的孪生神经网络目标跟踪算法
2022-06-23 06:24洪培钦罗灵鲲胡士强
计算机工程与应用 2022年12期
洪培钦,罗灵鲲,刘 冰,方 元,胡士强
1.上海交通大学 航空航天学院,上海 200240
2.中国航空无线电电子研究所,上海 200241
目标跟踪技术在智能视频监控、安防侦察、自动驾驶、可疑目标追踪、人员搜救等场景有广泛的应用。目标跟踪技术通过对用户感兴趣的目标进行提取和分析,在连续的视频帧中,实时跟踪目标,反馈目标的边界框,即目标的位置和尺寸信息,从而为视频分析提供可靠的依据。
目标跟踪算法主要分为生成式模型和判别式模型。生成式模型如光流法[1]、均值漂移[2]等难以抵抗目标跟踪中尺度变化、目标形变、相似干扰等基本难题。而判别式模型很好地进行了解决,主流的判别式目标跟踪算法主要分为相关滤波算法和深度学习算法。
基于相关滤波的目标跟踪算法中,MOSSE[3]、CSK[4]、KCF[5]、DSST[6]等都是最具代表性的算法,其中KCF在CSK的基础上引入高斯核函数,使用岭回归的方法训练滤波模板,用循环矩阵的方式简化计算,大幅提升了运算速度。
基于深度学习的目标跟踪算法有许多研究方向。近年来,孪生神经网络被广泛研究,DTCNNMI[7]算法使用孪生神经网络解决发动机失火检测问题,Fatima等[8]使用孪生神经网络检测黑胡椒中的木瓜种子掺假问题,DASNet[9]使用孪生神经网络解决卫星图像变化检测的问题。SINT[10]是目标跟踪领域使用孪生神经网络的开山之作,SiamFC[11]算法在SINT的基础上,使用AlexNet作为特征网络,引入全连接的卷积思想,通过模板图特征对搜索图特征做卷积,获得相似度得分,但是仍然采用金字塔解决多尺度问题,影响了跟踪效率。DSiam[12]提出了一个快速的通用变换学习模型,能够有效地在线学习目标外观变化并抑制背景,但是在线学习损失了模型的实时能力。RASNet[13]探索了不同类型的注意力机制在SiamFC方法中模板图特征上的作用效果,包括一般注意力、残差注意力、通道注意力,但是RASNet没有在搜索图特征上做注意力网络的探索。SA-Siam[14]提出了双特征分支,分别为语义分支和外观分支,有效地提高了算法的泛化性,但是两个分支单独训练,仅在推理的时候组合,丧失了耦合性。SiamRPN[15]在SiamFC的基础上引入了区域提议网络(region proposal network,RPN),区域提议网络将孪生神经网络提取的特征送入分类分支和回归分支,使用预定义的锚框作为边界框回归值的参考,速度和精度上有很大的提高,SiamRPN算法还有一定的改进空间。SiamMask[16]在SiamRPN的基础上引入分割分支,获取目标的像素级位置,能在测试数据集中获得更高的重叠率,但是模型比较复杂,严重影响了算法实时性。SiamRPN++[17]在SiamRPN的基础上改进网络模型和训练数据,使用分层的RPN网络融合方法,使用ResNet作为特征网络提高算法精度,SiamAttn[18]、TrSiam[19]、TransT[20]、ThrAtt-Siam[21]、SCS-Siam[22]分别在孪生神经网络的基础上引入了注意力网络,这些算法的改进对算法性能有提升,但是引入的网络带来很大运算消耗,算法实时能力严重下降,没有做到准确率和实时性的平衡。
综上,基于相关滤波的目标跟踪算法在实时性上表现较好,但是由于提取的特征属性比较单一,准确率难以提升;现有的孪生神经网络目标跟踪算法准确率高,但是算法的网络复杂度高,运算速度受限,实时性表现差。本文针对以上问题,提出了一种引入轻量注意力的孪生神经网络目标跟踪算法,命名为SiamNL。具体贡献如下:(1)针对跟踪算法实时性受限的问题,在SiamRPN的基础上,引入了深度级卷积相关,减少了网络的参数量和运算量,提升了跟踪算法的运算速度;(2)针对跟踪算法准确率受限的问题,引入轻量注意力网络Non-Local,增强了特征图的自编码和互编码能力,提升算法准确率且同时保证了实时性;(3)将所设计的算法SiamNL在现有的主流目标跟踪数据集上进行测试,测试结果表明,算法在准确率和鲁棒性上有很大的提升,并且有很好的实时性。
1 本文算法
本文提出的SiamNL算法,借鉴了SiamRPN算法的网络结构。SiamNL算法的完整流程如图1所示,主要流程分为以下四步:
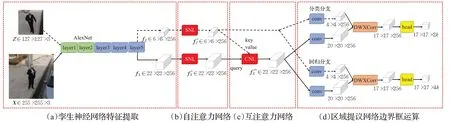
图1 SiamNL算法完整流程图Fig.1 Complete flow chart of SiamNL algorithm
(1)孪生神经网络特征提取。输入模板图Z和搜索图X,两者经过权值共享的五层AlexNet网络,分别输出模板图特征fZ和搜索图特征fX。
(2)自注意力网络。fZ和fX各自通过SNL注意力网络,完成空间注意力和通道注意力的自相关运算,分别得到f*Z和f*X。
(3)互注意力网络。以搜索图特征f*X为原矩阵,模板图特征f*Z为编码矩阵,输入CNL注意力网络,得到互相关编码的搜索图特征f**X。
(4)区域提议网络(region proposal network,RPN)边界框运算。f*Z和f**X进入区域提议网络,分类分支中进行一层卷积和深度级相关,最终得到分类得分结果;回归分支中同样进行一层卷积和深度级相关,最终得到边界框的回归结果。
1.1 深度级交叉相关
孪生神经网络目标跟踪算法SiamRPN借鉴了SiamFC的基本网路结构。网络的输入为模板图Z和搜索图X,其中模板图Z在跟踪过程中不做更新。模板图和搜索图经过权值共享的特征网络φ,将编码对应的模板图特征和搜索图特征,然后将两个特征输入区域提议网络。
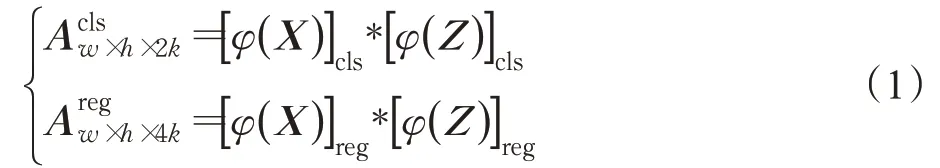
其中,“*”代表交叉相关运算(本质是卷积运算),“*”之前为被卷积矩阵,“*”之后为卷积核;“cls”为分类分支,“reg”为回归分支,两个分支最终都输出特征图A,特征图的宽高为w=17,h=17,其中k为锚框数量,为可调节参数,可参考FasterR-CNN[23]中的区域提议网络有关理论。
SiamRPN网络的结构中,特征网络使用AlexNet,区域提议网络使用2k个模板图卷积核对搜索图特征进行卷积交叉相关,如图2(a)所示。当k=5时,经过逐步累加推算,原SiamRPN网络的网络参数量为2.263 3×107,点运算量为5.790 GFLOPS,其中网络参数量约有75%的比例在区域提议网络中,仅做边界框回归用途的区域提议网络可以降低参数量。本文使用深度级交叉相关(depth-wisecross correlation,DWXCorr)代替普通交叉相关(cross correlation,XCorr),如图2(b)所示。普通交叉相关运算即普通卷积,如图3(a)所示。深度级交叉相关运算即深度级卷积,如图3(b)所示,卷积核和被卷积矩阵通过深度级分离,按照通道数各自分离成C层二维矩阵,每层对应进行卷积,卷积结果再进行拼接。
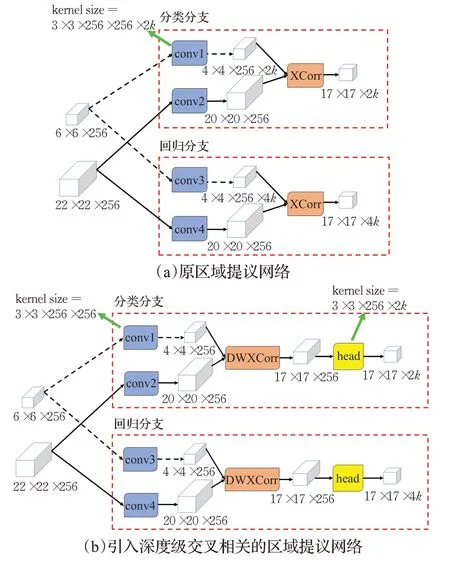
图2 区域提议网络修改对比图Fig.2 Region proposal network modification comparison chart
此处以分类分支为例说明深度级交叉相关对参数量的降低作用,两种交叉相关的最终目的都是获得17×17×2k的分类分支输出。普通交叉相关和深度级交叉相关的运算过程对比如图4所示。
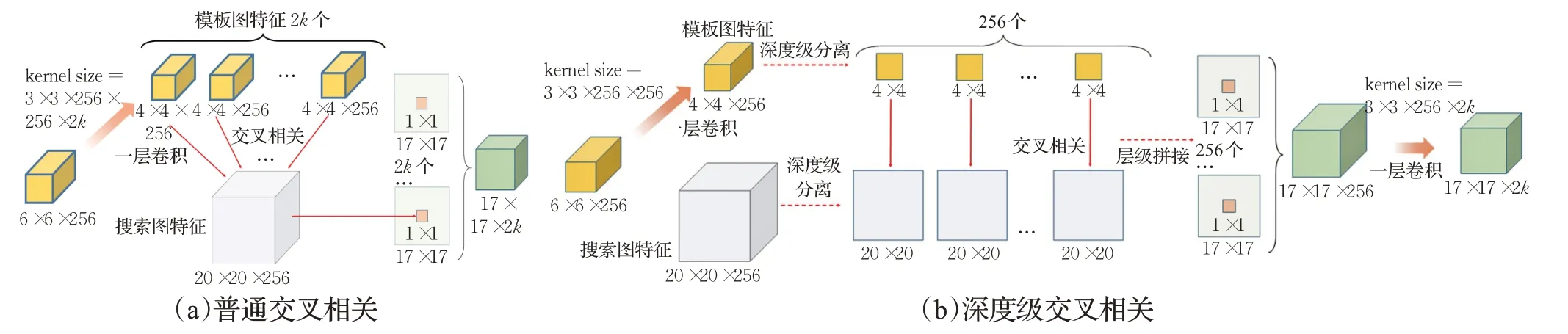
图4 深度级交叉相关和普通交叉相关对比图Fig.4 Comparison of depth-wise cross correlation and ordinary
在普通交叉相关中,为了获得17×17×2k的输出,需要2k组形如图3(a)的卷积对,即需要2k个4×4×256的卷积核,这些卷积核由一个6×6×256的模板图特征得来,则中间一层卷积的卷积核尺寸为3×3×256×256×2k。综上,普通交叉相关需要的参数量为3×3×256×256×2k。
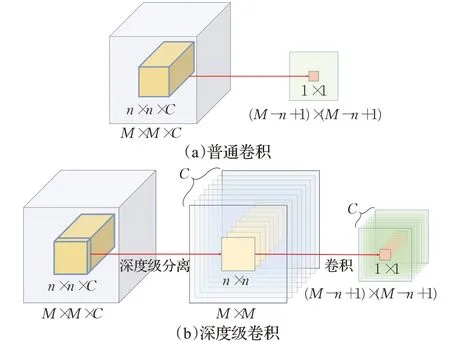
图3 深度级卷积和普通卷积对比图Fig.3 Comparison of depth-wise convolution and ordinary
在深度级交叉相关中,直接使用1个4×4×256的卷积核就可以通过深度级分离和交叉相关得到17×17×256的结果矩阵。为获得1个4×4×256的卷积核,中间一层卷积的卷积核尺寸为3×3×256×256。为了在最终得到17×17×2k的输出,17×17×256的结果矩阵需要经过通道压缩,需要的卷积核尺寸为3×3×256×2k。综上,深度级交叉相关需要的参数量为3×3×256×(256+2k)。
各个卷积核对应的参数量同时标注在图2中,当k较小时,深度级交叉相关的参数量约为普通交叉相关的1/2k。
所以,当深度级交叉相关都用于分类分支和回归分支后,区域提议网络的参数量约降低为原有的1/2k。
最终,通过修改区域提议网络内部的卷积细节,将普通卷积替换为深度级卷积,当取k=5时,将整体网络参数量由2.263 3×107下降为6.251×106。
1.2 轻量级注意力网络Non-Local
区域提议网络经过深度级卷积改进后的SiamRPN算法在实时性上有很大的提升,但是准确率依然受限。
为了提高算法的准确率,提高特征矩阵的表达能力是最有效的方法,骨干网络AlexNet难有改进空间,因此使用注意力网络可以进一步提高骨干特征的表达能力。
注意力网络借鉴了人类观察事物的注意力机制,如图5(a)所示,在该海报中,人类优先观察宝宝的脸和文本标题、文本正文开头等关键元素,注意力网络的训练目的就是使得目标图像的关键元素对输出结果产生增益。如图5(b)所示,在目标跟踪任务中,当跟踪目标为中间的运动员时,特征矩阵中表征目标运动员的元素其数值将得到增强,从而增加跟踪的准确率。
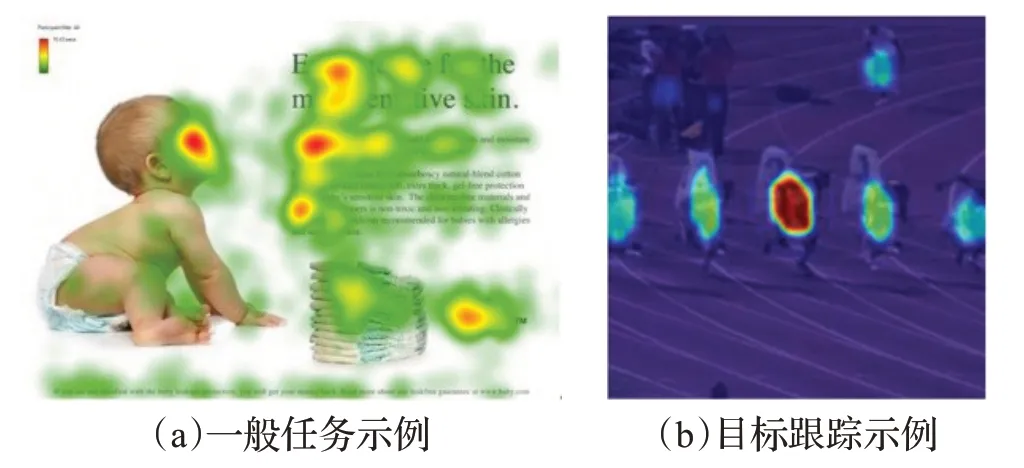
图5 注意力网络理论效果Fig.5 Comparison of score heat maps
本文注意力网络的模型方案主要包括自注意力和互注意力。自注意力可以编码特征自身元素和通道之间的相关性,在目标跟踪任务中,可以帮助特征更好地突出对跟踪任务有益的特征元素。互注意力可以编码两个不同特征之间的元素相关性,在目标跟踪任务中,作用于搜索图特征和模板图特征,提前让搜索图的特征元素针对模板图特征元素的影响,完成一次权重分配,更有利于交叉相关结果的准确率。
同时,考虑到对实时性的影响,所以本文引入的轻量级注意力网络是Non-Local,引入的网络在参数量和浮点运算量上都将产生极小的影响,且能够有效地提高骨干特征的表达。
Non-Local[24]是一种非局部网络操作,所谓非局部操作,即与卷积、循环运算等局部操作相反,Non-Local可以捕获输入特征中每个元素的长距离依赖,是一种信息极其丰富的依赖关系。结构图如图6所示,分别有输入A∈HA×WA×C和B∈HB×WB×C,可以是同一个矩阵或不同矩阵。矩阵A输入后与B进行残差矩阵的运算。残差矩阵运算的输入有query、key、value三个矩阵,其中query矩阵由A赋值,key和value矩阵由B赋值,分别经过1×1×C的卷积核编码,然后做矩阵维度变换,经过两次矩阵相乘运算和最后的1×1×C卷积运算,输出为残差矩阵A+,与原矩阵A进行相加运算得到最终的输出A*。各个运算步骤的表达式如下:
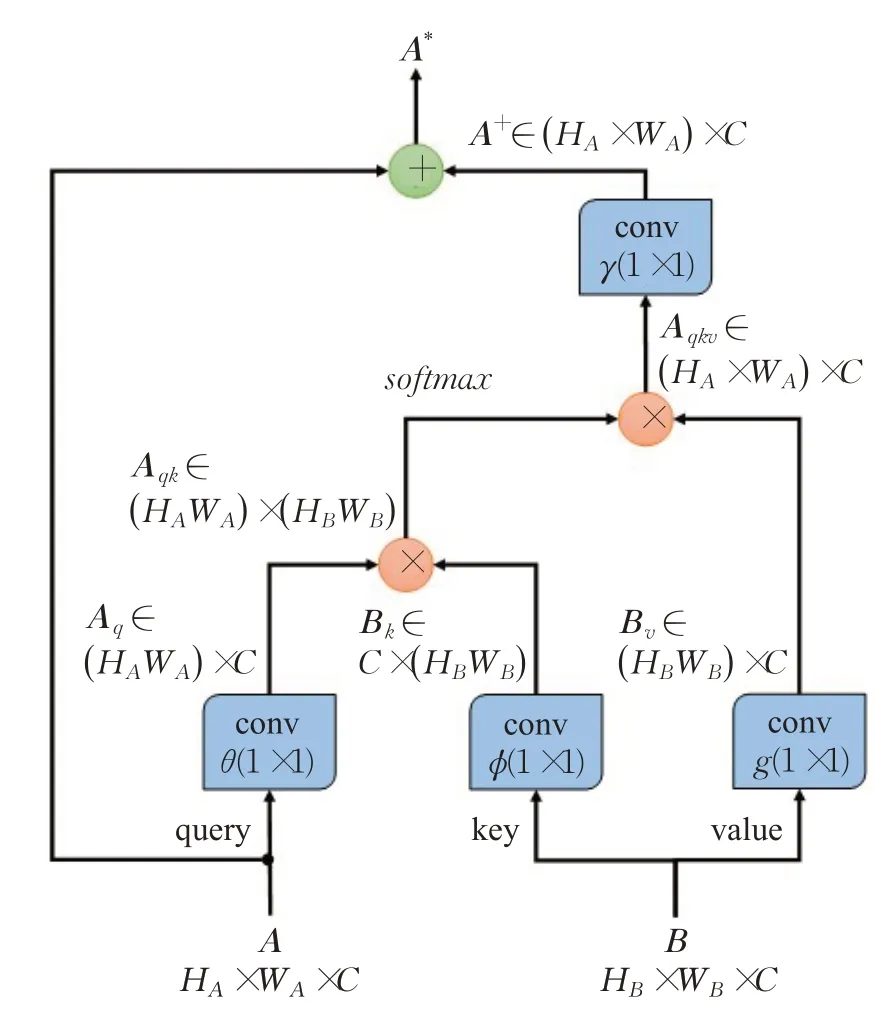
图6 Non-Local网络结构图Fig.6 Non-Local neural network structure diagram
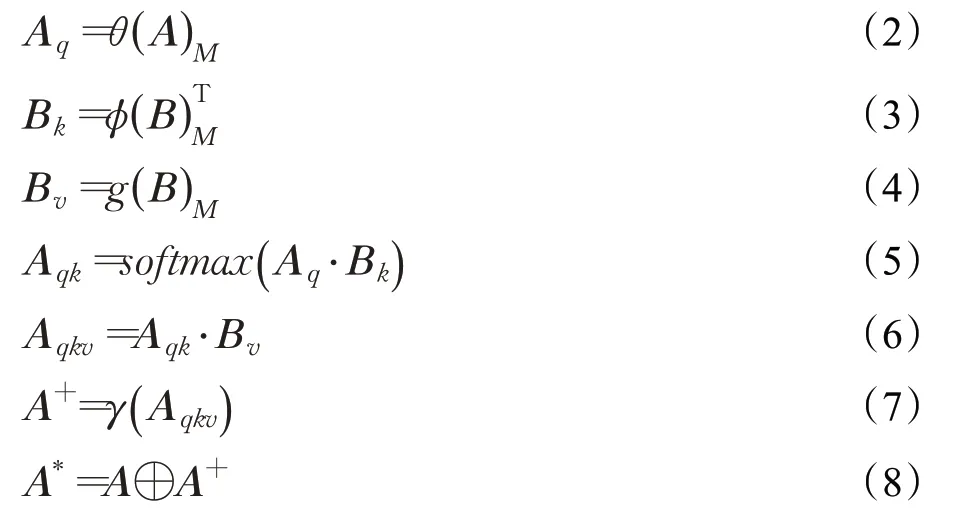
其中“⋅”为矩阵相乘,“⊕”为矩阵逐元素相加,“T”为矩阵转置。“(⋅)M”代表矩阵第一维和第二维组合。θ、φ、g分别为query、key、value三个输入的卷积运算子。


1.2.1 自注意力网络SNL
本文所设计的自注意力网络(self-non-local,SNL)是将特征矩阵自身做注意力相关。具体地,在图1中,将模板图特征和搜索图特征分别各自做SNL运算。以模板图特征为例,输入矩阵A和B都是模板图特征fZ,对于模板图特征fZ和搜索图fX特征的SNL网络,表达式如下:
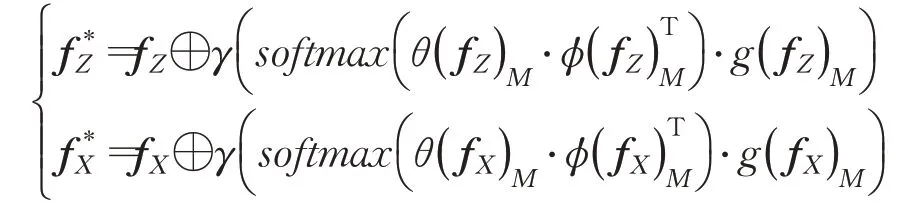
其中f*Z是SNL注意力编码后的模板图特征,f*X是SNL注意力编码后的搜索图特征。
特征矩阵fZ被SNL网络编码后,自身的每个特征元素与其余元素都进行了相关性计算,得到f*Z。相比没有编码前的特征矩阵fZ,f*Z中具备跟踪目标语义信息的元素被增强,从而在分类分支中获得更好的得分,f*Z中的背景元素被削弱,对分类分支的得分结果产生更小的干扰。最终目标语义信息丰富的元素,其特征数值被放大,无关元素的特征数值被缩小。自注意力所表示的元素间的相关性影响,映射到原图中,如图7所示。

图7 自注意力元素关系例图Fig.7 Example diagram of element relationships of self-attention
图7所示的原图,其特征矩阵被SNL网络编码后,蝴蝶的核心语义元素(图中黄色点)经过周围元素的注意力影响,发生数值增强,而编码背景的元素被削弱,这使得特征更加关注核心元素,有利于提高目标物中心位置在分类分支上的得分结果。
1.2.2 互注意力网络CNL
互注意力网络(cross-non-local,CNL)把搜索图特征作为query,模板图特征作为key和value,输入到Non-Local网络中,网络使搜索图特征f*Z编码模板图特征f*X对它的注意力影响,模板图中的有关元素将对搜索图中的核心语义元素产生特征增强,表达式如下:
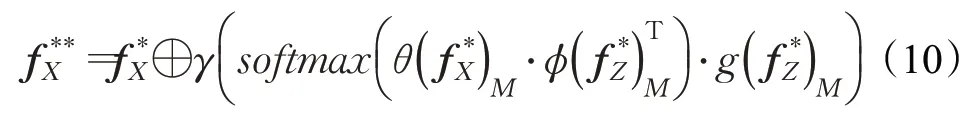
其中f**X是经过CNL编码后的搜索图特征,f*X是经过SNL编码后的搜索图特征,f*Z是经过SNL编码后端模板图特征。
特征矩阵f*X被CNL网络编码后,其自身的每个元素都与f*Z的每个元素进行了相关性计算,得到输出f**X。相比f*X,f**X中具备跟踪目标语义信息的元素受到f*Z的影响而增强,无关的背景元素被削弱,并且相当于在进行区域提议网络的交叉相关之前,搜索图特征提前感知了模板图特征的属性,提高了搜索图特征的泛化能力。此后,f*Z和f**X将分别进入设计了深度级卷积的分类分支和回归分支。
图8所示的搜索图原图,其特征矩阵被CNL网络编码后,蝴蝶的核心语义元素(图中黄色点)经过模板图特征元素的注意力影响,发生数值增强,而编码背景的元素被削弱,这使得特征更加关注搜索图特征中的核心元素,有利于提高目标物中心位置在分类分支上的得分结果,同时在回归分支中的结果更加准确。
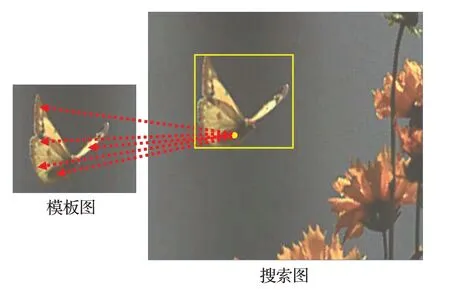
图8 互注意力元素关系例图Fig.8 Example diagram of element relationships of cross-attention
1.2.3 融合的注意力网络
融合的注意力网络由图1网络结构中的(b)、(c)两个模块组合表示。融合的注意力模块首先使用SNL网络将模板图特征fZ编码为f*Z,将搜索图特征fX编码为f*X,之后CNL网络将f*X和f*Z作为输入,输出编码了模板图相关影响的搜索图特征f**X。所使用的融合注意力网络一方面增强了模板图特征和搜索图特征各自的目标特征语义,一方面让模板图中的目标对搜索图中的目标元素产生有利于跟踪的影响,总体上来说可以增加跟踪的准确率。
融合注意力网络具有极低的运算量。SiamNL算法的浮点运算量为5.670 GFLOPS,其中模板图的SNL网络所占浮点运算量为0.010 GFLOPS,搜索图SNL网络所占浮点运算量为0.247 GFLOPS,而CNL网络占0.077 GFLOPS。即所引入的注意力网络共需要0.334 GFLOPS的运算量,占总运算量的5.89%,所以可以说所引入的注意力网络是轻量级的。
2 实验结果及分析
2.1 实验环境和算法参数
本文算法基于pytorch深度学习框架进行搭建,所使用的硬件为单卡NVIDIAGeForceGTX 1080显卡,显存8 GB。使用预训练的AlexNet网络作为孪生骨干网络,仅微调后两层参数,区域提议网络使用锚框数量k=5。使用交叉熵损失函数,其中分类损失权重为1,回归损失权重为1.2。学习率从0.01开始递减至0.000 5,训练epoch为50,batch为256。
2.2 数据集和对比算法
训练数据集为ILSVRC2015[25]和COCO[26],使用漂移、尺度变化、模糊、颜色变化等训练数据增强方法进行训练。所用测试数据集包括VOT2016[27]、VOT2018[28]、OTB100[29]、VisDrone[30]。
将提出的SiamNL算法分别与KCF[5]、Staple[31]、ECOHC[32]、C-COT[33]、MDNet[34]、SiamFC[11]、SiamRPN[15]、C-RPN[35]、CMKCF[36]、ThrAtt-Siam[21]、SCS-Siam[22]、GradNet[37]、DensSiam[38]、DSiam[39]、CFNet[40]、StructSiam[41]进行了对比,对比结果通过表格给出。
2.3 评价指标
2.3.1 VOT数据集评价指标
与以往的目标跟踪测试数据集不同的是,VOT数据集引入了重启机制,即在跟踪器跟丢目标后重新初始化跟踪器,这样可以充分利用数据集的所有视频帧。
VOT数据集采用的评价指标包括准确率(Accuracy),鲁棒性(Robustness),EAO。准确率用来评价跟踪器的准确度,其数值越大说明跟踪器跟踪得越准确。在每一帧图像中,跟踪的准确率由交并比(IoU)来表示,定义为:

其中AG代表人工标注的边界框,AT代表跟踪器预测的边界框。
鲁棒性用来评价跟踪器的稳定性,跟踪器重启次数越多,鲁棒性数值越大,说明跟踪器越不稳定。EAO则是根据所有视频序列跟踪的交并比、重启间隔和次数等综合评价得出的一个指标,可以反映跟踪器的综合性能。
2.3.2 OTB数据集评价指标
OTB100数据集和VisDrone数据集的评价指标相同,分别为成功率(success)和精确率(precision)。成功率即所有视频帧中跟踪成功的比率,设定阈值,使用交并比来判断是否成功。精确率则注重算法预测的目标中心位置与标注中心位置是否相近,当两者距离小于阈值代表精确,并评估所有帧中精确的比率。
为了更好地反映算法性能,成功率图(success plot)和精确率图(precision plot)是一种直观的方法,将所设置的不同阈值对应的成功率或精确率结果绘制成曲线,方便进行对比,从而避免固定阈值带来的偶然对比误差。为了使用单一指标来反映跟踪器的能力,将曲线中的所有关键点坐标做数值平均,得到平均成功率和平均精确率。
2.4 定量分析实验结果
2.4.1 VOT2016数据集
VOT2016数据集总共包含60个视频序列,所有视频序列均由以下视觉属性标注:遮挡、光照变化、运动变化、尺寸变化、摄像机运动。VOT2016所采用的标注方法是像素级分割标注和最贴合边界框,其中最贴合边界框并非以往的横向对称边界框,而是斜向边界框,由分割标注换算而来。
本文的提出的SiamNL算法在VOT2016数据集上同时对比了多项目标跟踪算法,结果如表1所示。在VOT2016数据集的对比结果中,SiamNL相比SiamRPN算法,准确率提高了0.051,鲁棒性提高了0.052,EAO指标提高了0.032,同时比C-RPN提高了0.013的EAO指标。
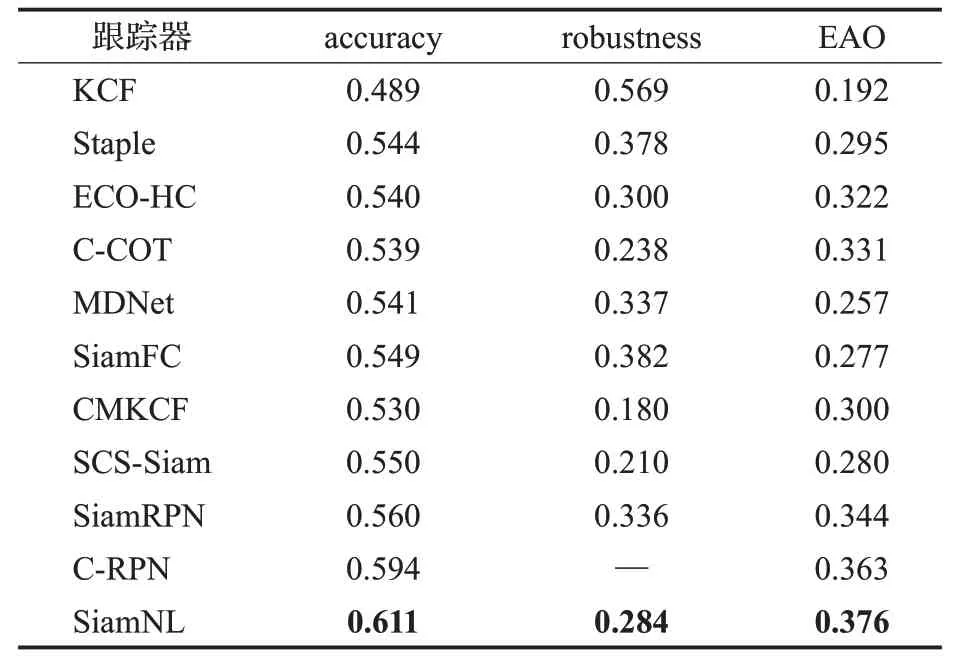
表1 VOT2016数据集实验结果Table 1 Experimental results of VOT2016 dataset
2.4.2 VOT2018数据集
VOT2018数据集继续保持60个视频序列,其中一部分保留了2016年的序列,另一部分用新序列替代了原先不具有挑战性的序列。而视觉属性上仍然保持五种基本属性。所有视频标注都进行了调整和优化。
SiamNL算法在VOT2018数据集上的测试对比结果如表2所示。SiamNL算法获得了最好的结果,相比SiamRPN算法,准确率提高了0.062,鲁棒性提高了0.006,EAO提高了0.020。
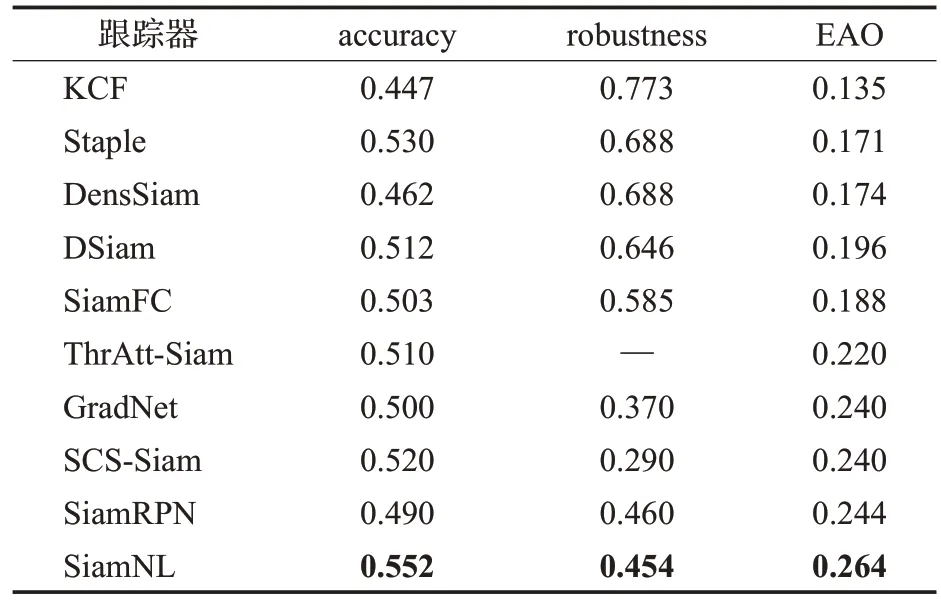
表2 VOT2018数据集实验结果Table 2 Experimental results of VOT2018 dataset
2.4.3 OTB100数据集
OTB100数据集共有98个视频序列和100个标注对象,所采用的标注方法是左右对称的矩形边界框。本文提出的SiamNL算法在OTB100数据集上的对比结果如表3所示。从实验结果看出,SiamNL在OTB100数据集上相比SiamRPN算法,在成功率上有提升,在精确率上保持相当。
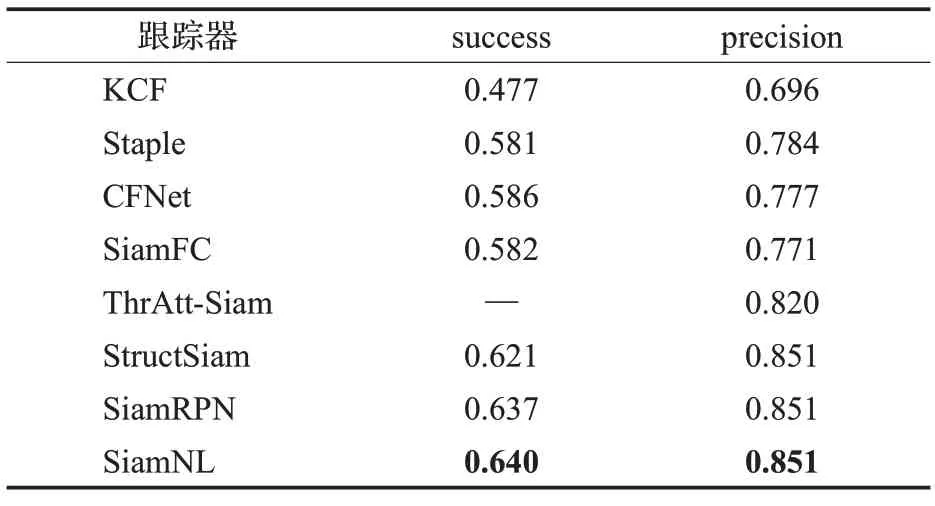
表3 OTB100数据集实验结果Table 3 Experimental results of OTB100 dataset
2.4.4 VisDrone数据集
VisDrone单目标跟踪数据集包含多种视觉属性标注,本文所提出的SiamNL算法在面对背景干扰、低分辨率、高速运动等视觉属性问题上,相比SiamRPN算法有一定的提升,对比结果如表4所示。
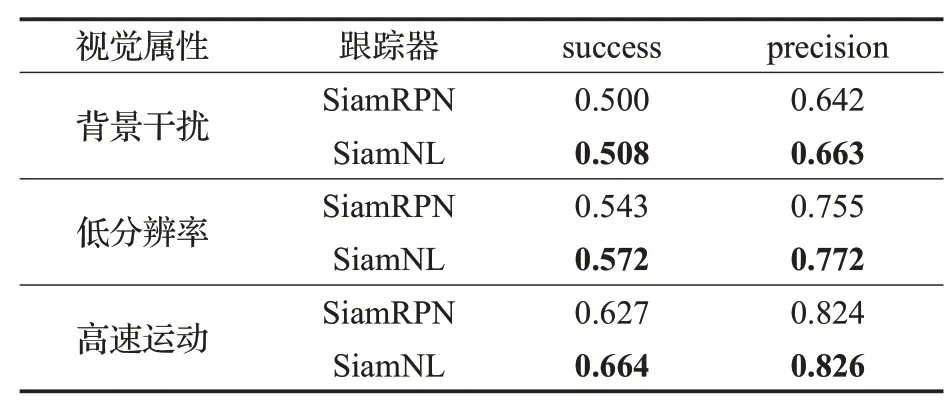
表4 VisDrone数据集实验结果Table 4 Experimental results of VisDrone dataset
在VisDrone数据集中,带有的背景干扰属性的数据集在SiamNL上的平均成功率高出SiamRPN 0.008,平均
SiamNL算法相比于其他的目标跟踪算法,在VOT2016、VOT2018、OTB100三个权威数据集的平均指标结果上都有提升,这主要由于所设计的轻量级注意力网络结构SNL和CNL增强了模板图特征和搜索图特征中核心语义元素的表达,从而提升了跟踪过程中跟踪框框取的精确度(通过VOT数据集的accuracy、OTB数据集的success和precision指标反映),并降低了跟踪的丢失概率(通过VOT数据集的robustness指标反映)。精确率高出0.021;带有低分辨率属性的数据集在SiamNL上的平均成功率高SiamRPN 0.029,平均精确率高了0.017;带有高速运动属性的数据集在SiamNL上的平均成功率高SiamRPN0.037,平均精确率高0.002。结果说明,SiamNL算法由于引入了注意力网络进行了特征的影响系数分配,核心语义元素的系数提高,使得其在面对常见的目标跟踪难题场景下能更好地表达语义并定位跟踪目标,从而拥有比SiamRPN更好的表现。
2.4.5 实时性实验
所提出的SiamNL算法相比SiamRPN有很好的实时性提升,并且参数量大幅度下降,运算量和参数量对比如表5所示。

表5 运算量和参数量对比表Table 5 Comparison table of calculation amount andparameter amount
表5中所示结果由255×255×3和127×127×3尺寸的模板图和搜索图作为输入,可以看到SiamNL算法在参数量上约为原有参数量的30%,运算量降低了0.012 GFLOPS,其中SiamNL的运算量中仅5.89%为所引入的轻量注意力网络带来。SiamNL和SiamRPN算法在PC及嵌入式平台上的运算速度测试结果如表6所示。

表6 运算速度实验结果Table 6 Experimental results of computing speed
所测试的PC平台显卡为NVIDIAGeForceGTX 1080,所测试的嵌入式平台为NVIDIAJetsonXavierNX。所设计的算法能够在NX开发板中充分地实时运行,而且SiamNL算法占用内存相比SiamRPN更低,有助于嵌入式平台接入更多运算需求。
2.4.6 实验结果总结
在背景干扰、低分辨率、高速运动的挑战场景中,使用VisDrone数据集为标杆,与SiamRPN算法进行对比,各场景的平均指标结果都有提升。在背景干扰的场景中,可能存在复杂背景和相似目标等问题,注意力网络可以削弱背景特征元素的值,从而减少背景对跟踪效果的影响。在低分辨率的场景中,目标占据较少的像素点,细节特征不足,但是注意力网络可以增强目标特征元素的语义表达,从而更加准确地判别跟踪目标。在高速运动的挑战场景中,目标产生运动模糊,细节特征将会被弱化,注意力网络同样可以增强目标的语义表达能力,在模糊状态下也能准确地获取跟踪目标。所以在各种目标跟踪挑战数据集中,注意力网络都能体现出它增强目标弱化背景的优势,而在实时目标跟踪任务中,由于轻量注意力网络所占运算量极低,跟踪算法具有较好的实时性,高速运动带来的帧间目标大距离位移将很少出现,这同样有利于跟踪算法更准确地跟踪目标。
在实时性实验中,SiamNL算法主要对比于SiamRPN算法,由于设计了深度级卷积的网络结构,使用更小的运算量在区域提议网络中完成了相似的特征矩阵卷积相关运算,使得SiamNL算法的参数量和运算量下降,体现在运算速度上带来明显的提升。在嵌入式平台中也进行了运算速度实验,更好地说明了所设计跟踪算法的实时性效果。
2.5 定性分析实验结果
2.5.1 跟踪序列对比
为了验证所设计的算法在实际视频序列中的有效提升,选取了一些具有复杂干扰元素的视频序列作为可视化结果,并进行定性分析,如图9所示。

图9 视频序列跟踪结果对比Fig.9 Comparison of video sequence tracking results
第一段Biker序列中,中间帧出现目标头盔的高速移动,产生运动模糊,其中SiamRPN、KCF、Staple都出现了跟踪丢失,只有SiamNL完全地跟踪在了目标头盔上。第二段Freeman序列由灰度图片组成,跟踪到最后只有SiamNL没有发生丢失,Staple发生漂移,其余跟踪器都丢失了目标。第三段Girl序列跟踪目标为骑滑板车的女孩,背景是一处公园,跟踪过程中会发生遮挡和背景干扰等情况,而SiamNL算法全程跟准目标,其余跟踪器都产生了跟踪漂移和跟踪丢失。第四段Jump序列,由于运动员目标的形状多变,跟踪框内的背景极易对跟踪产生影响,实际说明SiamNL算法抵抗干扰的能力很强,可以很好地跟踪目标。第五段Liquor序列跟踪目标为酒瓶,视频序列中多个酒瓶都对目标产生相似性干扰,SiamNL算法准确跟踪目标的同时,跟踪框精准度很高,而其他跟踪算法在跟踪过程中都被相似目标所干扰。
综上分析,SiamNL算法有很好地抵抗背景干扰、相似干扰等影响的能力,所设计的注意力网络的作用得到了印证。
2.5.2 特征图对比
从区域提议网络的匹配得分图上分析SiamNL的提升效果,本文选取了三个跟踪帧进行对比,将得分平滑地映射到搜索图上,如图10所示。
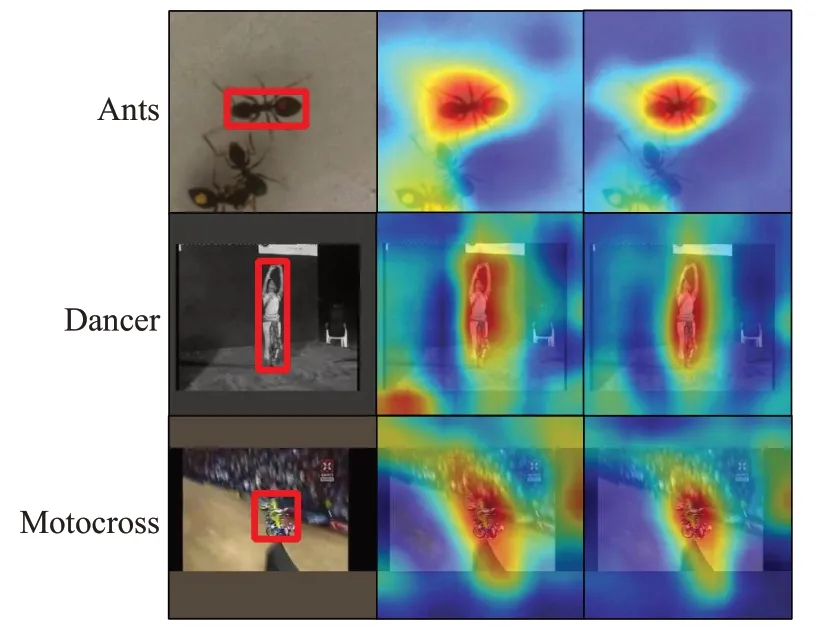
图10 得分热力图对比Fig.10 Comparison of score heat maps
所选取的三个序列包含不同的主要属性特征。第一段序列Ants的属性为相似目标,SiamRPN算法被相似目标干扰严重,而SiamNL则没有;第二段序列Dancer的属性为灰度颜色空间,SiamNL对灰度图像的抗干扰能力较好;第三段序列Motocross的属性为高速运动,SiamNL算法的得分热力图比SiamRPN更加集中。综合以上热力图对比结果,可以知道SiamNL算法引入注意力网络后可以更好地重视核心区域元素,对各种干扰因素有更好的抵抗能力。
3 结束语
本文设计了引入轻量注意力网络的孪生神经网络目标跟踪算法SiamNL。在SiamRPN算法的基础上,使用深度级卷积改进区域提议网络模型,减少了参数量和运算量。在孪生神经网络提取的特征图后增加了自注意力网络和互注意力网络,自注意力网络增加了模板图和搜索图的自编码能力,经过自编码的模板图和搜索图突出了图像的核心目标区域;互注意力网络增加了模板图对搜索图的互编码,在进入分类分支和回归分支之前,搜索图提前编码了模板图的有用信息,从而提升了分类分支当中目标区域的交叉相关得分。引入的注意力网络对运算量的影响很小,所以认为是轻量级的。
本文在VOT2016、VOT2018、OTB100、VisDrone数据集上进行了对比测试,并做了实时性分析和视频序列、热力图的定性分析。实验结果表明,SiamNL算法在SiamRPN的基础上,降低了运算资源占用,提高了运算速度,提升了跟踪效果。所设计的SiamNL算法由于在各种挑战场景下有很好的跟踪效果,且表现出了在准确率和实时性上很好的平衡性。本文的下一步工作将对SiamNL算法的特征提取骨干网络AlexNet进行改进,设计具备更好的特征提取能力且运算高效的骨干网络。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
小学生学习指导(中年级)(2021年12期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
汉字汉语研究(2020年2期)2020-08-13
甘肃教育(2020年22期)2020-04-13
电子制作(2019年22期)2020-01-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
疯狂英语·新读写(2018年3期)2018-11-29
北京航空航天大学学报(2018年1期)2018-04-20
