
中国风景园林领域大数据应用研究思辨
——基于2011 - 2021年相关文献分析
2022-06-21 01:04王中德余林冰
园林 2022年6期
王中德 余林冰 杨 玲
(1.重庆大学建筑城规学院,重庆 400044;2.山地城镇建设与新技术教育部重点实验室,重庆 400044;3.重庆大学艺术学院,重庆 401331)
大数据技术被广泛应用于解决人居环境问题,为风景园林设计与研究带来新技术支持。梳理2011年至2021年间相关文献,通过定性与定量相结合的方式,分析大数据应用在风景园林领域的研究进展与特征。首先,国内风景园林领域大数据研究始于2013年前后,重点应用领域涵盖了公园绿地、街巷空间、时空行为与空间活力、评价与评估等方面。其次,研究发现大数据在利用新的数据源、形成新的研究方法以及拓展定量研究途径几个方面对风景园林设计与研究起到了积极的推动作用。同时,对于大数据不能对学科领域形成全覆盖的局限性应该有清醒的认知,对于以数据分析取代理论构想的趋势,以及相关性取代因果性的思维转变亦需理性看待。
风景园林;大数据;方法与技术;定量化;前沿展望
随着信息技术发展,人类社会进入“大数据时代”。一般而言,大数据具有“4V”属性,即Volume(体量大)、Variety(模态多)、Velocity(速度快)和Value(价值大但密度低)[1]。2008年9月Nature杂志推出“大数据(Big Data)”专刊[2],推进了大数据在各个学科领域的应用。2012年前后,伴随着智慧城市的讨论,国内出现了大数据在风景园林学科领域应用的思考[3]。为推动学科向纵深发展,走向“大风景园林”,结合“高科技”的风景园林设计与研究变得尤为重要[4-5],而大数据及其应用则成为重要手段之一。该应用的开展为理论研究提供了新的数据源、技术方法,同时也带来了部分思维方式的转变[6]。近年来,在风景园林研究领域,大数据方法的创新性与重要性逐渐受到重视,其技术应用涉及到规划设计各阶段:从前期分析中的预测模型[7],到中期的方案推演与设计优化[8],再到建成后的评估与评价[9],以及智慧化管理[10]。这些应用成果在动态研究、非介入式调查、定量分析等方面形成创新,表现出全方位的大数据辅助设计与研究态势。在此背景下,深度挖掘大数据及其应用研究成果数据,剖析研究的相关特点,并对相关问题展开深入探讨,这对于促进学科发展具有一定的现实价值与理论意义。
1 研究概况与数据说明
1.1 研究概况
伴随着大数据应用研究在绿道评价[11]、公园活力[12]、街巷更新[13]、园林管理[14]等领域逐年展开,多种数据应用成果逐渐增多。面对成果累积显露出的研究优劣势,人们开始对大数据及其应用方法本身展开了探讨:提出了新数据造成的空间尺度高精度、时间尺度动态连续、研究粒度以人为本、研究方法开源众包4个变革[15],总结了时空大数据具有客观性、多源性、动态性、现势性、精细性和人本性6个特点[16],提出了在城市研究方法中将大小数据相结合的思路[17]。
随着应用的推进,大数据在实际应用中的一些短板也被发现,如社交网络数据有偏性和延时性[18]、街景数据覆盖欠缺[19]和网络词语语义泛化偏差等[20],对于上述问题,众多学者就大数据本身及其应用方法也作出了深刻思考:彭怀贞等[21]反思了大数据造成的数据论倾向;张波等[22]分析了城市研究中大数据的应用缺陷;赵渺希等[23]思考了智慧城市的技术热潮的利弊;赵守谅[24]认为大数据方法在城市规划领域,还未能从认识论和方法论上取得本质的突破;吴志峰等[25]认为在地理学的应用中大数据技术还不能算作一次革命性变化。
虽然上述思考推动了大数据研究的探索进程,但是这些极具价值的观点大多散布在具体的应用研究中,就风景园林学领域而言,对更系统地思考大数据对学科的积极作用与消极影响、探讨大数据环境下的思维变革,仍存在研究不足。因此,对国内风景园林领域大数据应用研究进行回顾和解读,纵向上分析整体发展情况,横向上总结应用成果和常用分析方法,并更深入地剖析新数据特征与局限性,这对于促进风景园林学科发展具有重要意义。
1.2 方法与数据
1.2.1 研究方法
为客观全面地分析国内风景园林领域大数据及其应用研究现状,既要聚焦本学科的研究成果,也需要了解相关学科领域的整体发展概况。为此,本研究在对文献进行预检索和数据准备后,首先对历年文章发表数量进行统计,分析整体发文量的发展变化。其次,对数据进行人工归纳分类,从研究对象和研究方向两个方面总结已有研究进展与成果。最后,统计常用分析方法和与之对应的大数据类型,剖析大数据分析方法与技术的应用情况(图1)。通过将文献定量分析与成果内容定性分析相结合,客观呈现大数据应用在风景园林领域的研究现状。
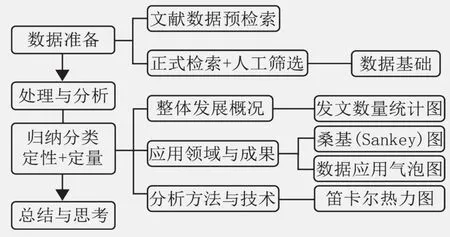
图1 研究方法框架Fig. 1 Framework of research methods
1.2.2 数据准备
结合本文目的,将数据源确定为国内三大主流文献数据库:中国知网(CNKI)、万方数据、维普期刊。对2011年至2021年内同时含有“大数据”和“风景园林”主题词的期刊论文进行检索①在维普期刊的高级检索中不提供主题词检索功能,选择“题名和关键词”检索,因此在维普期刊的检索条件与前两者稍有不同。检索日期均为2022年1月2日。(图2),预检索结果均不超过80篇。这表明了两种可能:一是与风景园林强相关的一些文章,因未出现“风景园林”主题词而被检索排除②主题检索是在数据库标引出的主题字段中进行检索。该字段内容包含一篇文章的所有主题特征,嵌入了专业词典、中英对照词典、停用词表等工具,并采用关键词截断算法,将低相关或微相关文献进行截断。;二是大数据在风景园林领域中的应用研究尚有极大的拓展空间。
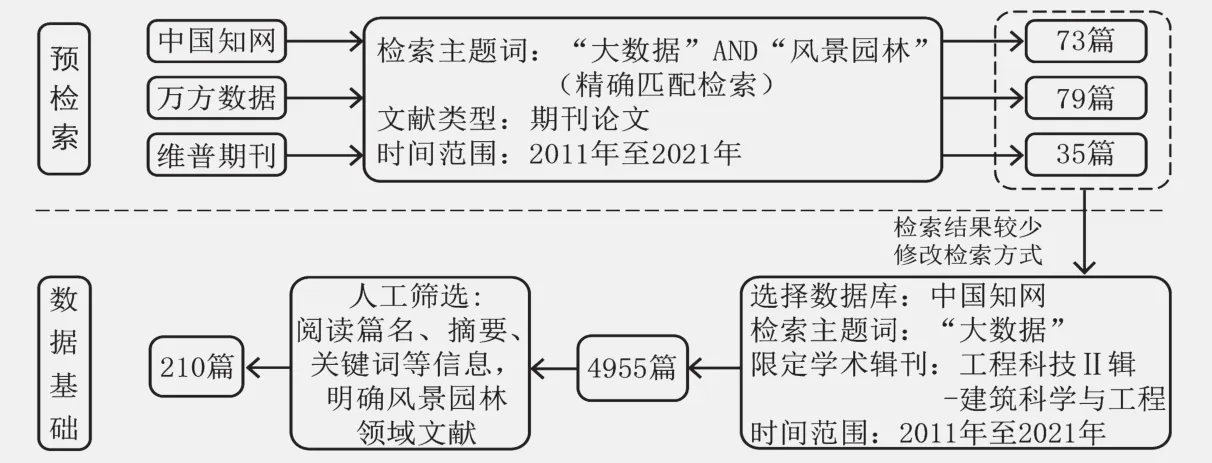
图2 预检索与数据来源说明Fig. 2 Literature pre-search and data sources description
为了更客观地判断,在扩大检索范围同时保证文献与风景园林领域的高相关性,最终在CNKI的高级检索中限定“工程科技Ⅱ辑—建筑科学与工程”作为期刊论文来源③在CNKI的高级检索中左侧的“文献分类导航”下有十大专辑分类,这是CNKI基于中图分类而独创的学科分类检索功能。通过此功能可以明确研究成果的学科类别。,以“大数据”为主题词精确匹配检索,得到4 955篇文献,经人工筛选,剔除期刊导语、综合资讯、工作动态、书评等无效文章,并逐一阅读篇名、摘要、关键词等信息,筛选出210篇较明确归属于风景园林领域范畴的有效文献作为数据基础。
2 国内研究进展与特征分析
2.1 整体发展概况
分别统计4 955篇和210篇文献10年间的发表量,并将前者视为总发文量(图3)。在检索数据中,总发文量在2011年、2012年均为1篇,在被称为“大数据元年”[26]的2013年突增为24篇,至2020年前发文量均呈现逐年递增的趋势。2021年发文数开始下降,说明在一定程度上研究热度有所降低。在风景园林领域的样本数据中,首次发文出现在2013年,此后至2020年研究都保持上升态势,然而与总发文量相比,增长趋势明显较缓,且风景园林领域发文量历年占比均未超过总发文量的10%。该点能够说明预研究中风景园林文章检索数量较少的原因应该是第二个:在建筑学大类学科背景下,风景园林领域的大数据应用研究并不突出,还有很大的拓展空间。
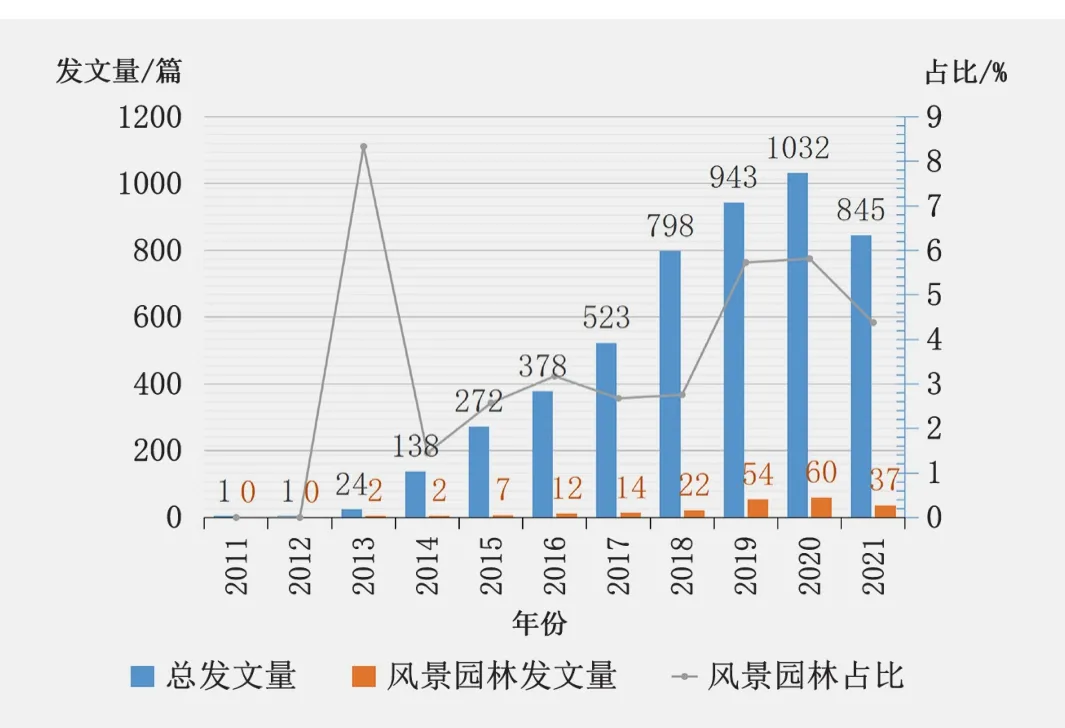
图3 2011-2021年文章数量统计Fig. 3 Statistics on the number of articles from 2011 to 2021
2.2 应用领域与成果
对风景园林领域的研究成果根据研究对象及研究方向进行不完全分类统计,研究对象为8类(图4),研究方向分为12类(图5),将统计数据整理成Excel表格,绘制桑基图来分析文章数量变化。同时,统计每一分类下文章数量超过10篇的研究类别所应用的大数据类型,通过气泡图分析数据类型与研究对象、研究方向的关联性。样本文献中使用的大数据类型可以分为5类,包括三类实时更新的大数据:位置服务数据、动态监测数据、社交网络数据;以及相对而言更新较慢的两类大数据:基础空间数据和社会经济数据①数据分类参考文献[16]进行删减和修改,其中出行轨迹数据包括高德地图导航数据、腾讯宜出行数据、智能手机APP数据、共享单车数据等;交通传感数据包含公交刷卡数据、出租车GPS数据等;社交签到数据主要指微博签到数据。。此外,一些非应用型研究未被统计在上述分析图中,这些研究主要为两类:教学实践(13篇)和数字技术探索(20篇)。
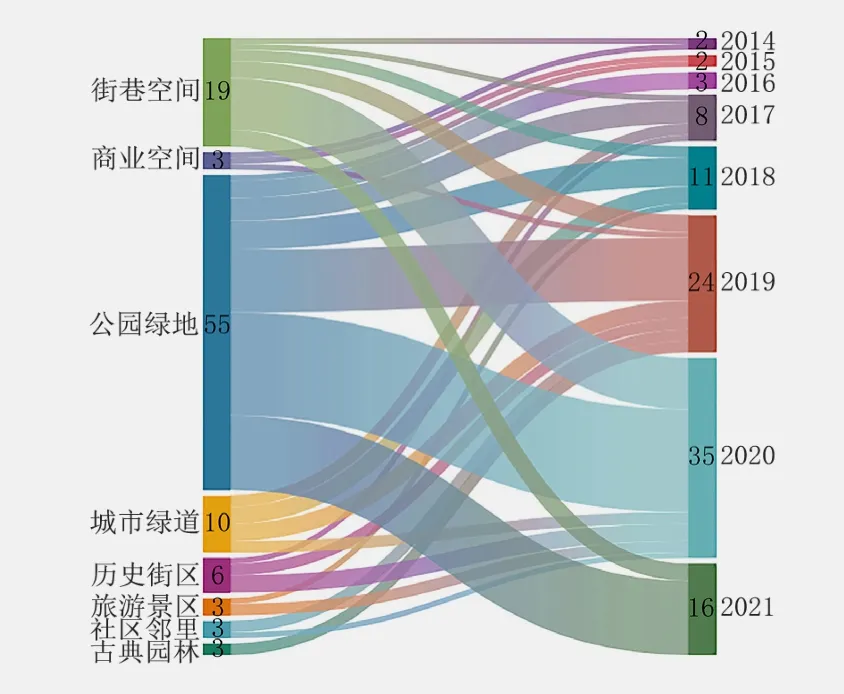
图4 不同研究对象文章数量变化桑基图Fig. 4 Sankey diagram of changes in the number of articles for different research objects
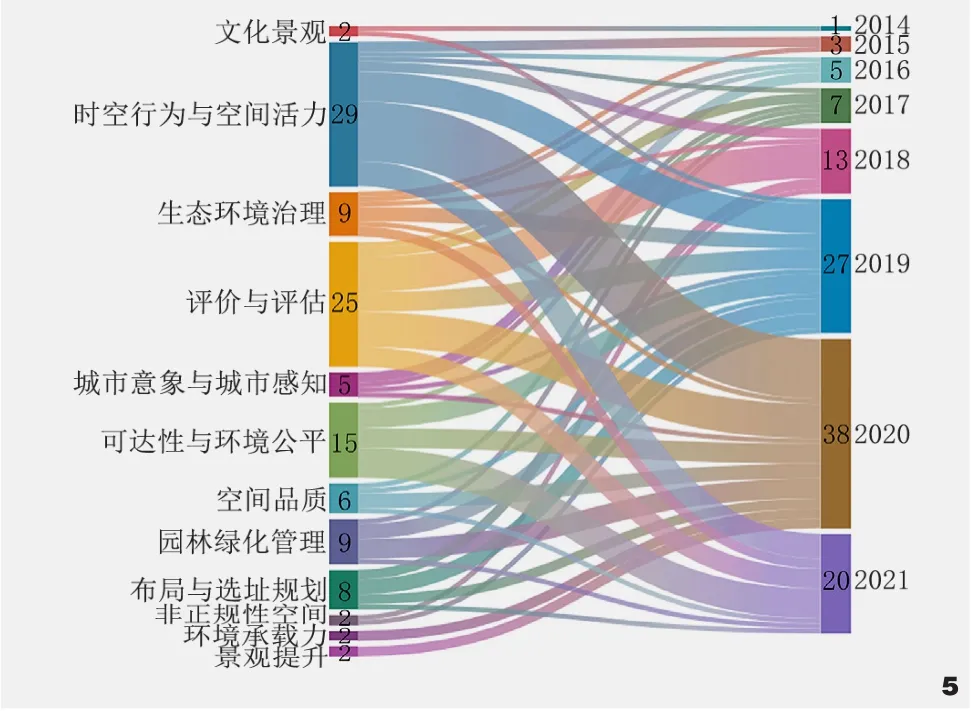
图5 不同研究方向文章数量变化桑基图Fig. 5 Sankey diagram of changes in the number of articles in different research directions
2.2.1 研究对象与研究方向分析
首先,“公园绿地”“街巷空间”“城市绿道”是风景园林领域大数据应用主要研究对象。这其中“公园绿地”达到55篇,从2015年延续至今,且在2018年后研究呈快速上升趋势,这与2018年“公园城市”理念的提出显然具有密不可分的关联。城市绿道的大数据应用研究最早见于2017年,在此后几年发展均衡,研究重点是选线规划。街巷空间中大数据的应用是三者中最早开始发展的,可追溯至2014年对大数据在智慧街道设计[27]中的探索与展望,此后的研究发展极为缓慢。在近年城市更新的过程中,街巷作为极具发展潜力的邻里公共空间,逐渐得到关注,并在2020年迎来了新的发展机遇。与此同时,2019年至2020年研究对象丰富,均达到6类以上,说明这两年是风景园林领域大数据研究发展的重要节点。
同时,“时空行为与空间活力”和“评价与评估”构成了风景园林领域大数据应用的主要研究方向,“园林绿化管理”“生态环境治理”“布局与选址规划”“空间品质”位于第二梯队,“可达性与环境公平”介于二者之间,这些研究方向成果在时序上均表现出较好的延续性。“评价与评估”类研究在2016年和2021年间呈波浪起伏式发展,而“可达性与环境公平”类研究在2017年出现后就一直呈稳定增长状态,并在2021年成为占比最高的研究方向。此外,在成果较少的研究方向中,“文化景观”出现得最早,但之后多年未有新的研究成果出现,这说明大数据在“文化景观”方向可能存在着一定应用局限性。
2.2.2 数据类型应用分析
通过统计上述研究对象成果中应用的大数据类型发现(图6),“公园绿地”研究涉及到了所有类型的新数据源,特别是出行轨迹、手机信令、网络文本和POI数据的应用,使得公园绿地研究在游憩使用、可达性、服务范围和规划应对这4个方面有了较大进展[28]。在“城市绿道”的研究中,出行轨迹数据、交通传感数据、POI数据的应用为分析人群时空行为、基础设施分布,以及最优线路规划提供了重要数据支撑[29]。另外,通过街景图片数据进行空间品质测度为“街巷空间”研究拓展了全新视角[30]。
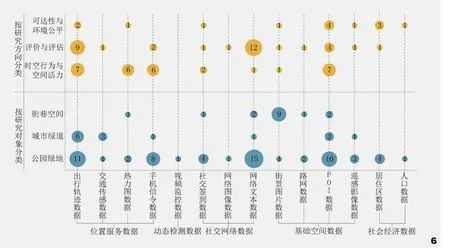
图6 不同研究对象和研究方向应用数据类型气泡图Fig. 6 Different data types used in different research objects and research directions
同样,在“时空行为与空间活力”“评价与评估”“可达性与环境公平”这三个研究方向上,热力图、出行轨迹、手机信令、POI数据因含有空间位置信息,在识别人群分布特征并计算个体行为密度[31]、分析影响空间活力的主导因素[32]等方面得到广泛应用。在“评价与评估”方向上,可以通过非介入方式的网络文本数据,获得更为真实的公众评价[33]。而“可达性与环境公平”方向,主要应用的是POI数据和居住区数据,为研究城市绿地供给的公平性[34]提供了新的数据支撑。
2.3 分析方法与技术
2.3.1 常见研究方法
将样本文献中的大数据类型和与之对应的主要分析方法进行归类统计(图7),结果显示:传统的空间分析法、数学与统计分析法、综合评价分析法在现阶段研究中仍然被大量采用。其中空间分析法中最常见的是GIS空间分析法,如使用带有用户位置信息的微博签到数据,通过核密度法[35]分析人群在公园内的聚集程度,且借助GIS工具将数据做可视化呈现成为近几年一个显著趋势。在数学与统计分析法中,描述统计应用最多,主要通过大数据绘制统计图表,描述空间现象与活动规律[36]。而推断统计中常见的分析手段是综合应用回归分析与相关分析[37],一般用于寻找公园、街巷的空间活跃度影响因子,并结合定量研究中常用的SPSS软件工具验证模型。此外,综合评价分析法是应用最广的方法,几乎所有的大数据类型都可用于建立量化评价指标,由于网络文本、签到、地铁刷卡等行为数据可以反映居民的真实需求,因此可得到更为客观的景观评价结果。需补充说明的是,在具体的应用中,通常是多种分析方法结合运用。
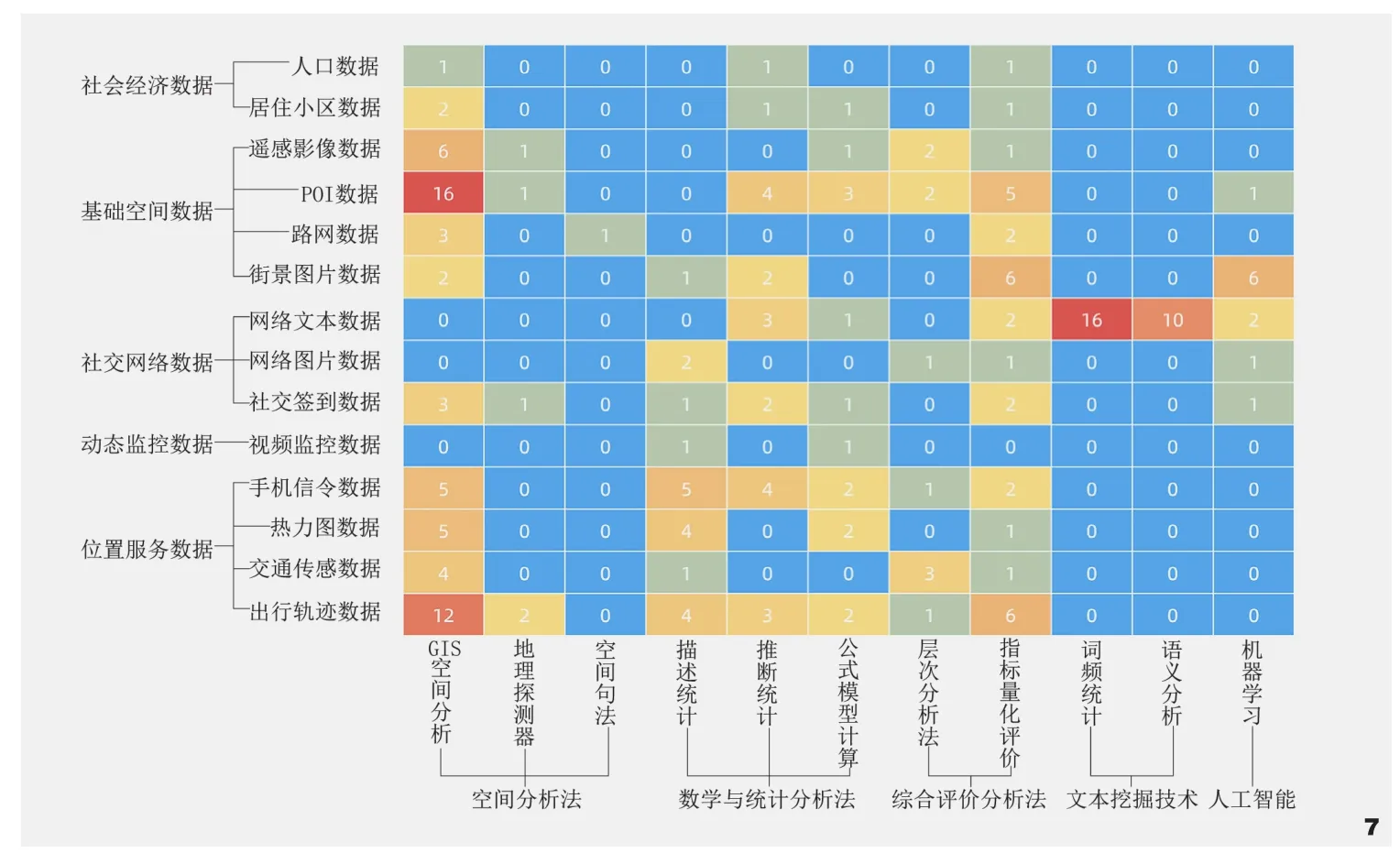
图7 分析方法与技术笛卡尔热力图Fig. 7 The heatmap on Cartesian of the analytical methods
2.3.2 新兴方法与前沿技术
同时,得益于计算机技术的不断发展,也形成了人工智能机器学习、文本挖掘技术等为代表的新兴方法与前沿技术。常用于人居环境研究的人工智能方法有人工生命类、智能随机优化类和机器学习类这三类[38]。本研究的样本文献中统计到了机器学习类,即从样例中学习,如对网络文本进行分类与情感判断[39]、抓取街景数据识别景观要素进行城市修补[40]、利用网络图片对城市意象认知开展实证研究[41]等。此外,与传统空间分析法使用频次同为最高的另一个分析方法是文本挖掘技术,该技术融合了机器学习、自然语言处理等多种技术,特别适用于网络文本数据的处理与分析。但较强的针对性使得其应用场景受限,同时一些研究仅停留在网络文本分词与词频统计阶段,还缺少进一步处理分析手段。
3 大数据及其应用对风景园林学的影响
3.1 推动风景园林科学化发展
新数据环境下,风景园林传统分析方式已不能满足信息时代的城市发展需求。使用大数据技术可以构建风景园林信息矢量化体系、信息化可视平台[42],重新梳理对“以人为本”风景园林设计的理解。本文认为大数据及其技术应用对风景园林的推动作用主要为两个方面:一是新数据属性形成了新研究方法;二是拓展了定量研究的途径。
3.1.1 形成更为科学的新研究方法
前文的研究方法统计中,虽较多仍在沿用传统研究方法,但大数据在数据量、更新频率、数据形式,以及来源等方面具有的显著优势,使得这10年新的研究方法不断涌现。如前所述,利用部分大数据带有时空定位的新数据优势,传统描述性的内容在GIS等工具帮助下以可视化的空间结果呈现,这将更科学地指导规划设计。其次,从人本视角量化城市形态,深度挖掘人们日常生活图片数据背后现实空间的价值而形成了图片城市主义[43]等。同时,在新数据的基础上,利用算法进行深度学习,形成了以人工智能辅助决策为代表的新方法,未来具有很大的发展潜力。在前文分析中发现,由于人工识别视频内容的时间成本较高,视频大数据还未得到广泛应用。但视频大数据在公共空间中对高度动态的人群活动分析具有不可替代的优势,随着人工智能技术的发展和普及,未来视频大数据分析技术将更进一步推动风景园林动态研究。对大数据价值的深度挖掘,突破了数据实证层面的简单利用,将风景园林学科领域研究向更加科学的模式推进。
3.1.2 拓展了风景园林定量研究的途径
围绕大数据处理及分析的应用,在定量研究的测度科学化、规律精确化、人本特征精细化三个方面有了新的发展。首先,空间活力测度的科学化改变了传统测度方法人力成本高而准确性较低的弊端。通过大数据对活动强度进行定量分析,可以为建立公园服务压力评价体系[44]、确定历史街区空间活力影响因子[45]等提供更具说服力的科学依据。其次,改变了传统数据虽可分时段多次收集,但难以实现动态性和实时更新的困境。通过大数据实时监测人口规模及空间分布变化[46],分析出行特征与规律,实现了对人群变化规律的精确化把控。再者,对于人本特征实现了精细化描述。非结构化的网络大数据,是全民参与记录的数据,具有真实性和实时性,通过由用户发布或储存的社交网络数据,在对数据进行清洗后,可以挖掘到用户性别、年龄和社交关系等重要社会特征,并对其进行精细化定量分析。
3.2 大数据应用的局限性与思考
3.2.1 对大数据本身局限性应有清醒认知
首先,大数据虽然数据规模巨大,但仍然不是全样本,即样本偏差仍然存在。如被广泛应用于游憩使用评价的社交网络数据,由于不同社交平台有对应的受众,因此得到的评价数据仅能代表特定的人群。同时,这些被动获取的样本数据也很难像传统实地调研那样,通过数学计算设定样本使其符合总体特征(如年龄、性别比例等),在获取数据中控制不同群体的占比来降低偏差。
其次,大数据价值密度较低等特性带来的影响不能忽视,如何通过机器算法迅速完成大数据价值的“提纯”是亟待解决的难题。在数据处理方面,传统调研数据由于数据量小价值密度高,因此比大数据更易操作。在数据获取、关联性、侧重点方面,两种数据各具不同的优势,如传统数据研究可以通过设计实验来记录被研究者在假定场景中可能产生的行为和情绪,这是大数据研究难以实现的。当然,被动数据和主动数据的得失各有利弊,但从上述分析来看,仍然不能全然否定传统样本数据及传统研究方法。
因此,大数据尚不能对风景园林学科全部领域形成覆盖。从前文总结的研究重点来看,研究对象更多地集中于中观和宏观尺度的城市公共空间,而乡村景观、街角绿地等领域还较少涉及。这与这些区域人群密度较低,或是移动联网设备较少,难以收集时空行为大数据具有直接关联。这就意味着在大数据应用中,研究对象需具有一定的空间尺度和人群规模,而在小尺度设计中具有应用难度。在小场地中即使能获得部分大数据,其准确度及数据价值都已较低,不再具有应用意义,更适合使用传统调研数据。此外,风景园林领域的大数据应用在社区生活圈、公共服务设施、公众参与等方面还鲜有涉及,而目前这些研究方向的大数据应用已从城乡规划学的视角展开,可见在这些方向上大数据方法有一定适用性,今后可从风景园林的视角开创更多相关研究。
3.2.2 大数据应用带来的思维变革仍需理性对待
图灵奖得主Jim Gray提出科学研究经历了实验科学、理论推演和计算机仿真三种范式,目前正在进入数据密集型的“第四范式”[47]。虽然对此仍存争议,但不可否认的是,大数据应用的背后存在着思维模式的转变。而本文认为,对于风景园林学而言,除了研究人员思维和认识的更新以及对大数据专业化应用的洞察之外,尚有以下两点变化值得思考。
第一,由于时空大数据呈现的是群体累积叠加信息,对数据信息的挖掘也就更关注于群体行为模式,即表现为对数据的整体性把控。由此,必然带来研究中由对个体数据的精准性“小数据思维”向整体性的“大数据思维”转变。但大数据再大也不过是现实世界的一个非全样本投影,因而在整体性增强的过程中往往伴随着个体诉求被掩盖,排他性的模糊真相取代多样性差异的客观事实。如在绿地空间布局、绿地供给公平性等研究中,大数据可以反映大多数人的需求,但也造成了对个体诉求、弱势群体诉求的忽视,所以也并未达到完全的空间正义。因此,如何针对不同研究目标对大数据及传统数据进行准确判别,并于其中寻找到平衡点应该是值得认真对待的问题之一。
第二,前述分析结果中存在以描述性统计来直接阐述空间现象的研究倾向。这实际上也是伴随着大数据时代的到来,数量大到难以想象的数据可能会让理论模型变得多余,假说的理论模型将被直接的数据对比所取代的佐证[48]。但如果以数据分析取代理论构想,以“就是这样”来回答“为什么”的提问,实际上也就放弃了对因果关系的渴求[49],放弃了对现象背后动因的探究。而对于风景园林研究而言,我们想要探寻的正是空间现象背后的原因,并将其转化为可操作的要素运用到今后的设计中。同时,考虑到大数据算法其思维模式存在的非黑即白漏洞,我们有理由对这种以相关性研究取代因果性研究的趋势保有警醒。
4 结语
在当下研究领域,大数据释放出的巨大价值使得选择大数据方法不再是一种权衡,而是导向风景园林学科未来发展的重要路径之一,但对直接套用大数据、为了数据而数据的盲目应用研究倾向仍需警醒。放眼全球,近年来相关文章的发表和引用数量呈指数级增长,但研究不足也不容忽视,对照国际研究现状[50],未来应整合多种数据源,开发利用深度学习、云计算等新方法,拓展应用领域,聚焦人类活动与环境的关系。面对大数据本身和思维转变造成的应用局限,应给予传统数据同等关注。大数据和传统数据的结合,由技术中心论转向更加以人为本的精细化、多元化研究将成为未来发展趋势。同时,随着技术突破和跨学科合作深入,未来将建立更加智慧的风景园林服务环境。因此,亟需建立对应的理论框架,形成与时俱进的分析方法与手段,扬长避短,更好地促进学科发展。
本文因聚焦于国内近10年风景园林领域大数据应用研究,而以CNKI中“工程科技Ⅱ专辑”下的“建筑科学与工程”的期刊论文为文献来源,这可能会因为缺少其他文献数据如外文研究文献,而导致部分数据缺失及可能的观点局限性。同时,对于数据分析方法部分,受篇幅所限,本文可能未准确、全面列举所用的技术与手段并充分讨论。上述不足有待在不断文献数据积累基础上,进一步展开横向对比与纵向深入的持续探索。
注:文中图片均由作者绘制。
猜你喜欢
建材发展导向(2022年20期)2022-11-03
房地产导刊(2022年5期)2022-06-01
体育科技文献通报(2022年3期)2022-05-23
建材发展导向(2022年6期)2022-04-18
建材发展导向(2021年22期)2022-01-18
辽金历史与考古(2021年0期)2021-07-29
科技传播(2019年22期)2020-01-14
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
