
基于拉普拉斯正则化的药物副作用频率预测
2022-06-20 08:25:02李冰纯徐显嵛
天津科技大学学报 2022年3期
王 林,李冰纯,徐显嵛
(天津科技大学人工智能学院,天津 300457)
药物风险-效益评价是对患者用药后得到的治疗效益与风险之间的评价.在这项评价中,药物副作用频率的估计至关重要[1].目前,计算频率的标准方法是随机对照实验,通过对不同分组实施不同的干预措施,得到不同的结果[2].这种方法容易受到时间、样本量和熟练度的限制,使药物的一些副作用在临床试验中没有发现,而是在上市多年后被发现[3].因此在医疗卫生领域中,药物的副作用仍然是引起其他疾病和死亡的主要原因[4].现有的一些预测药物副作用的计算方法[5-7]大多数只能预测副作用存在与否,不能预测副作用的频率,在一定程度上限制了这些方法在药物风险-效益评价中的应用.
Galeano等[8]提出了利用非负矩阵分解模型(nonnegative matrix factorization,NMF)预测药物的副作用频率,但是该方法对药物副作用关联和频率预测的准确率仍有待提高.在此基础上,本文提出了一种基于拉普拉斯正则化的药物副作用频率预测模 型DSLR(drug-side effect frequency prediction with Laplace regularization),在非负矩阵分解模型中引入拉普拉斯正则化项,以及控制未知副作用标签及其预测值间隔的超参数.实验结果和数据分析表明,DSLR模型不仅能更准确地识别药物的副作用关联,而且能更精确地进行药物副作用频率的预测.
1 数据获取
利用Galeano等[8]和Zhao等[9]使用的基准数据集验证药物副作用频率预测方法的有效性.该数据集包括750种药物和994种副作用,以及来自SIDER数据库[10]的37071个已知频率项.药物副作用依据干预队列,临床试验频率被映射成5个频率(f )区间,即f<0.01%、0.01%≤f<0.1%、0.1%≤f<1%、1%≤f≤10%和f>10%分别定义为罕见、少见、不经常、频繁和非常频繁,并分别用频率值1、2、3、4、5表示.在37071个已知频率项中,罕见、少见、不经常、频繁和非常频繁的占比分别为3.21%、11.29%、26.92%、47.46%和11.12%.用评级矩阵M表示药物和副作用之间的频率,其中矩阵的行和列分别表示药物和副作用,矩阵中的非0值表示特定药物-副作用对的已知频率,0表示未知副作用.评级矩阵M极其稀疏,非零元素仅占4.97%.
2 计算方法
2.2 药物相似性和副作用相似性的构建

2.2 基于拉普拉斯正则化的优化模型


2.3 求解算法
采用乘性更新算法求解模型(4).具体来说,随机初始化W和H,并分别用其Frobenius范数归一化,进而W和H的更新公式为

其中:W0和H0为更新前的矩阵,W和H为更新后的矩阵.基于更新公式(5),模型(4)的目标函数是单调下降的,从而可以保证算法的收敛性.设置最大迭代次数为1000,并且当前后两次迭代目标函数的下降值小于设定阈值时,停止迭代.
算法执行前,首先运用M/5将评级矩阵M归一化,然后采用上述乘性更新算法得到W和H,进而令P=WH,最后通过P×5得到最终的预测矩阵.
2.4 收敛性分析
根据约束最优化理论[11],当目标函数收敛时,最优解满足的Karush-Kuhn-Tucker(KKT)互补条件为

当W=W*且H=H*使模型(4)取得局部极小值时,必须满足式(6)中的KKT互补条件,其中W*和H*表示局部最优解.将式(7)代入式(6),得

结合式(9)不难看出,W和H的更新公式(5)满足KKT互补条件,从而基于式(5)则模型(4)收敛到局部最小值.
2.5 预测性能的度量
预测模型的准确性从两个方面衡量,即识别药物副作用关联的性能和频率预测的性能.对于二分类问题,可以将实例(药物-副作用对)分为正例(有关联)或负例(未知关联).进行预测时,会出现以下4种情况:True Positive(TP),实例是正例并被预测为正例;False Positive(FP),实例是负例并被预测为正例;False Negative(FN),实例是正例并被预测为负例;True Negative(TN),实例是负例并被预测为负例.
准确率(Accuracy)、精确率(Precision)、召回率(Recall)的计算式为

此外两个常用的指标,即Precision-Recall(PR)曲线下面积(area under the precision-recall curve,AUPR)以及接受者操作特征曲线(receiver operating characteristic curve,ROC)下面积(area under curve,AUC)也用来评价关联性能.
对于每个指标,首先计算测试集上每种药物的指标值.对于每种给定的药物,其在测试集中具有已知频率的副作用和其在评级矩阵M中的未知副作用分别被视为正例和负例,然后将所有药物的平均指标值作为结果.
关于频率预测,使用Spearman相关系数(Spearman’s correlation coefficient,SCC)和均方根误差(root mean square error,RMSE)作为评价指标,SCC和RMSE的计算式为

其中:d和e分别表示药物和副作用的遍历,Pd,e和Md,e分别表示药物-副作用对的预测频率和已知频率,r () 表示等级转换,t表示已知频率的药物-副作用对的总数.
3 计算结果与讨论
3.1 化学结构相似的药物有相似的副作用频率
使用开源化学信息Python软件包RDKit,基于拓扑指纹和Tanimoto相似度计算任意两个药物之间的化学结构相似性.对于280875个药物对,其化学结构相似性的中位数为0.24,将相似性≤0.24的药物对定义为化学结构低相似度对,将相似性>0.24的药物对定义为化学结构高相似度对.
对于280875个药物对,计算其副作用频率相似度,即对于任意两个药物,基于其副作用频率谱(评级矩阵M中的两行),利用余弦相似度进行计算.药物对关于副作用频率余弦相似度的箱线图如图1所示.图1给出了化学结构低相似度对和高相似度对的副作用频率相似度分布的箱线图,相对于化学结构低相似度对,化学结构高相似度对具有更大的副作用频率相似度(单边Wilcoxon秩和检验P=5.85× 10-59).

图1 药物对关于副作用频率余弦相似度的箱线图 Fig.1 Box plots of drug pairs with respect to the cosine similarity between their side effect frequency profiles
3.2 10折交叉验证
在数据集中,所有已知药物-副作用对的频率(共计37071个)被随机均匀地分成10折.数据集的其中一折设置为测试集,其余9折则作为训练集,并将每一折测试集的平均指标值作为最终结果.选择现有的副作用频率预测模型NMF[8]和MGPred(prediction using a graph attention network.to integrate multiview data)[9]作为对比,验证本文模型DSLR的有效性.同时,考虑建模副作用频率预测问题为推荐系统,采用基于图神经网络的模型(inductive graphbased matrix completion,IGMC)[12]求解.基于10折交叉验证的比较结果见表1.由表1可知:DSLR模型的AUC、AUPR明显优于其他3个模型,这表明DSLR模型可以对药物副作用关联进行更好地预测;对于评价频率预测性能的指标,DSLR模型的SCC和RMSE明显优于NMF模型,但逊于MGPred模型和IGMC模型.MGPred和IGMC这两个模型的AUC较低,表明其不能准确地预测药物-副作用关联,因此虽然其SCC和RMSE更优,但在实际使用中容易引入假阳性,即未知副作用大多数被预测为有药物-副作用关联.
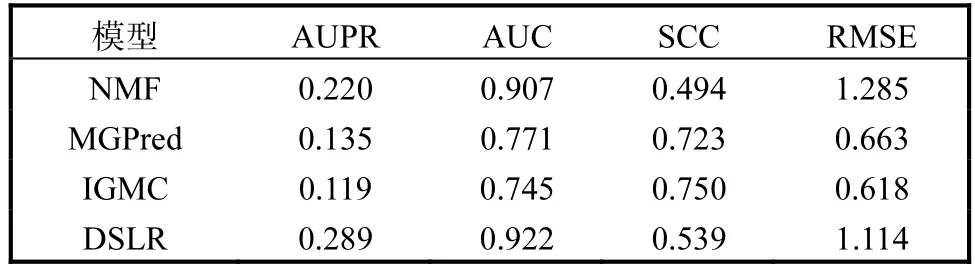
表1 基于10折交叉验证的比较结果 Tab.1 Comparison results based on 10-fold cross validation
使用DSLR模型对单个药物氟伏沙明进行研究.对于10折交叉验证中的1折,测试集中氟伏沙明的已知副作用共35个(正例),未知副作用共694个(负例).选取与正例等量的负例,计算得出Accuracy=0.614,Precision=0.565,Recall=1.0.该药物对于729个副作用预测结果的ROC曲线 (AUC=0.948)和PR曲线(AUPR=0.559)见图2.

图2 药物氟伏沙明副作用预测的ROC曲线和PR曲线 Fig.2 ROC curveand PR curve for the prediction of the side effects of the drug fluvoxamine
为了进行频率类别预测,使用10折交叉验证期间从测试集得到的预测值,收集了所有已知副作用的频率类别及其对应的预测值.对于未知副作用,基于10折交叉验证中的1折,得到未知副作用的预测值.对于未知副作用及已知副作用的每个频率类别,采用核密度估计方法得到其预测值的概率密度函数(probability density function,PDF).每一频率类别预测值的概率密度函数如图3所示,其中频率0~5分别对应副作用频率类别为未知副作用、罕见、少见、不经常、频繁和非常频繁.
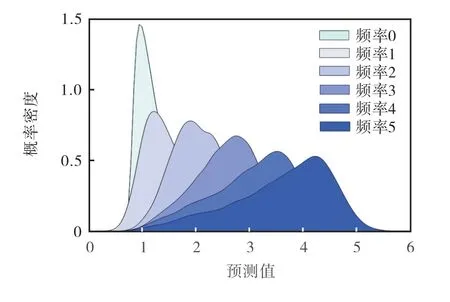
图3 每一频率类别预测值的概率密度函数 Fig.3 PDF of predicted values for each frequency category
根据概率密度函数和最大似然法确定分类决策的边界,得到相邻频率的边界阈值分别为1.15、1.65、2.35、3.05和3.85(图3).对于每一个真实频率类别中的所有副作用,可以得到其预测频率类别.每一频率类别的准确率见表2.表2给出了预测为各个类别的副作用所占的百分比,对于频繁(频率=4)副作用(占总数的47.46%)中的41.89%被正确预测, 79.67%被预测为不经常(频率=3)、频繁或非常频繁(频率=5).
进一步定义精确类和邻居类两个概念.精确类是被预测为自身真实频率的类别,如真实频率为1的副作用被预测为频率类别1.邻居类是指被预测为自身和其邻居真实频率的类别,如真实频率为1的副作用被预测为频率类别1和2,真实频率为2的副作用被预测为频率类别1、2和3.
本研究对单个药物盐酸罗匹尼罗进行了分析,该药物共有396个副作用,频率为1、2、3、4和5的副作用个数分别为0、17、167、209和3.该药物频率为2、3、4和5的精确类准确率分别为11.76%、28.74%、30.62%和33.33%,邻居类准确率分别为41.17%、68.26%、84.21%和66.66%.
3.3 消融实验
在引入拉普拉斯正则化项以及控制未知副作用标签和其预测值间隔的超参数ε后,验证DSLR模型在预测药物副作用频率方面的优越性(表3).对于给定的基准数据集,引入拉普拉斯正则化项对模型预测药物-副作用关联的性能有明显提升;引入超参数ε,在AUC相对稳健的情况下,RMSE显著降低,表明其能更精确地进行频率预测.因此,当拉普拉斯正则化项的权重参数β=0.01、间隔ε=0.195时,AUC=0.922,RMSE=1.114,DSLR模型的预测性能最好.

表3 消融实验的比较结果 Tab.3 Comparison results of ablation experiments
3.4 上市后副作用预测
对于基准数据集的750种药物和994种副作用,本研究发现评级矩阵M的未知副作用中,有9288种药物-副作用关联在SIDER数据库中被标记为“上市后”(以下简称上市后副作用).这些上市后副作用由于在临床试验中并没有发现,被认为频率为1,即罕见的副作用[13].使用M中所有已知频率类别(频率>0)作为训练集训练模型,然后对上市后副作用进行预测.图4给出了未知副作用(频率=0)和上市后副作用预测值的PDF,以及基于10折交叉验证M中罕见(频率=1)副作用预测值的PDF.结果表明:对于9288种上市后副作用,有31.52%被正确地预测为罕见,62.34%被预测为罕见或少见(频率=2),82.82%被识别为有药物-副作用关联,说明DSLR模型对上市后副作用有较好的预测能力.
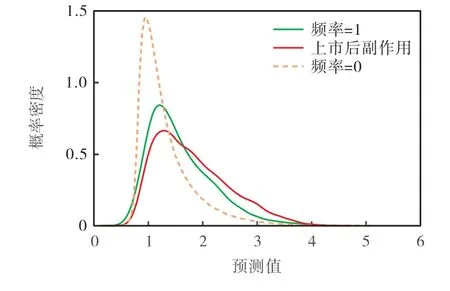
图4 频率=1、频率=0及上市后副作用的概率密度函数Fig.4 PDF of predicted values for frequency=1,frequency=0 and post-marketing side effects
本研究随机选取了药物舒尼替尼,在SIDER数据库中该药物有51个副作用在上市后被发现.对于这些副作用,预测结果表明86.27%被识别为有药物-副作用关联,其中54.9%被识别为罕见(频率=1),21.57%被识别为少见(频率=2),9.8%被识别为不经常(频率=3).
4 结 语
本文提出了一种预测药物副作用频率的机器学习模型DSLR.基于基准数据集,DSLR模型将药物之间的化学结构相似度和药物频率谱的余弦相似度的平均值作为药物的相似度,副作用频率谱的余弦相似度作为副作用的相似度,采用基于拉普拉斯正则化的非负矩阵分解模型,并引入超参数控制未知副作用标签及其预测值的间隔.结果表明,DSLR模型不仅能准确预测药物副作用发生的频率,并且能够对上市后药物副作用进行预测,这有助于指导药物风险-效益评价.
参考文献:[1] GODAT S,FOURNIER N,SAFRONEEVA E,et al.Frequency and type of drug-related side effects necessitating treatment discontinuation in the Swiss Inflammatory Bowel Disease Cohort[J].European journal of gastroenterology & hepatology,2018,30(6):612-620.
[2] CONCATO J,SHAH N,HORWITZ R I.Randomized,controlled trials,observational studies,and the hierarchy of research designs[J].The New England journal of medicine,2000,342(25):1887-1892.
[3] BANDA J M,EVANS L,VANGURI R S,et al.A curated and standardized adverse drug event resource to accelerate drug safety research[J].Scientific data,2016,3(1):160026.
[4] PIRMOHAMED M,JAMES S,MEAKIN S,et al.Ad- erse drug reactions as cause of admission to hospital:prospective analysis of 18 820 patients[J].British medical journal,2004,329(7456):15-19.
[5] CAMI A,ARNOLD A,MANZI S,et al.Predicting adverse drug events using pharmacological network models[J].Science translational medicine,2011,3(114):114-127.
[6] WANG Z,CLARK N R,MA’AYAN A.Drug-induced adverse events prediction with the LINCS L1000 data[J].Bioinformatics,2016,32(15):2338-2345.
[7] CAKIR A,TUNCER M,TAYMAZ-NIKEREL H,et al.Side effect prediction based on drug-induced gene expression profiles and random forest with iterative feature selection[J].The pharmacogenomics journal,2021,21:673-681.
[8] GALEANO D,LI S,GERSTEIN M,et al.Predicting the frequencies of drug side effects[J].Nature communications,2020,11(1):4575.
[9] ZHAO H,ZHANG K,LI Y,et al.A novel graph attention model for predicting frequencies of drug-side effects from multi-view data[J].Briefings in bioinformatics,2021,22(6):239.
[10] KUHN M,LETUNIC I,JENSEN L J,et al.The SIDER database of drugs and side effects[J].Nucleic acids research,2016,44(1):1075-1079.
[11] LI T,DING C.The relationships among various nonnegative matrix factorization methods for clustering [C]//IEEE.Sixth International Conference on Data Mining(ICDM’06).New York:IEEE,2006:4053063.
[12] ZHANG M,CHEN Y.Inductive matrix completion based on graph neural networks[EB/OL].[2022-01-25].https://arxiv.org/abs/1904.12058.
[13] TATONETTI N P,YE P P,DANESHJOU R,et al.Datadriven prediction of drug effects and interactions[J].Science translational medicine,2012,4(125):125-131.
猜你喜欢
企业界(2024年8期)2024-07-05 10:59:04
中小学课堂教学研究(2023年12期)2024-01-05 16:14:43
肝博士(2022年3期)2022-06-30 02:48:28
今日农业(2021年19期)2022-01-12 06:16:32
环境保护与循环经济(2021年7期)2021-11-02 08:10:54
国外核新闻(2020年8期)2020-03-14 02:09:19
家庭医学(下半月)(2019年9期)2019-10-12 08:04:04
数学教学通讯·小学版(2019年7期)2019-09-09 01:07:24
新课程·下旬(2016年3期)2016-05-10 08:59:34
初中生学习·低(2015年6期)2015-05-30 10:48:04
