
Cooley-Tukey FFT 算法高性能实现与优化研究
2022-06-17 07:10:40郭金鑫张广婷张云泉陈泽华贾海鹏
计算机与生活 2022年6期
郭金鑫,张广婷,张云泉,陈泽华,贾海鹏
1.太原理工大学 大数据学院,太原 030024
2.中国科学院 计算技术研究所 计算机体系结构国家重点实验室,北京 100190
快速傅里叶变换(fast Fourier transform,FFT)是处理器基础软件生态最关键的算法之一,是计算离散傅里叶变换(discrete Fourier transform,DFT)或其逆运算的快速算法,并将算法复杂度由()降为了(lb)。FFT 算法被用于物理、天文学、工程、应用数学、密码学和计算金融等许多不同的领域。如在国际大科学工程——平方公里阵列射电望远镜(square kilometer array,SKA)项目中,FFT 是数据处理的五大算法之一,其计算量占总计算量的40%。由于各应用领域的急速发展及其实时性能的要求持续提高,FFT 在ARM(特别是ARMv8)和X86-64 架构平台上高性能的实现和优化有着重要的研究意义和应用价值。
虽然FFT算法在ARM和X86-64平台上已经有比较成熟的实现,如ARMPL(ARM performance library)、Intel MKL(math kernel library)和FFTW(fastest Fourier transform in the West)。但是由于FFT 算 法的复杂性和多样性,依然有许多工作值得深入研究。例如在库利-图基FFT 算法这一目前应用最为广泛和流行的快速傅里叶算法中,依然存在蝶形网络复杂、蝶形计算复杂多样等问题。特别是对于大基的实现,虽然大基通过减少访存提升性能,但是大基蝶形实现依然存在汇编实现复杂、寄存器不够用等问题。本文针对这些问题,研究FFT 算法在不同架构CPU 上的高性能实现方法,突破以上问题导致的性能瓶颈,从而实现了一个高性能FFT 算法库。
在本文的研究中,FFT 算法的实现和优化主要从如下三方面进行:(1)蝶形网络重构,优化不同基特别是一些大的基,降低蝶形网络级数,减少访存提升蝶形网络性能;(2)利用DFT 矩阵性质,提取蝶形计算公共项,将大基蝶形计算化到最简;(3)蝶形计算汇编实现,汇编SIMD(single instruction multiple data)优化,寄存器复用策略制定和堆栈内存使用解决寄存器不够用等。通过以上优化方法的使用,本文在ARMv8和X86-64 计算平台上突破了大基寄存器不够用的性能瓶颈,实现和优化了一个高性能快速傅里叶变换算法库。实验结果表明本文实现的FFT 算法库相较FFTW、ARMPL 以及Intel MKL 性能有较大提升,相较算法中小基性能也有较大提升。
本文的主要贡献如下:
(1)总结和重构蝶形网络,同时利用DFT 矩阵的对称性和周期性,大幅降低了大基蝶形计算的复杂度;
(2)总结设计了基14、基20 等大基FFT 蝶形计算方法特别是寄存器使用策略,解决了由于寄存器不够用导致的性能瓶颈;
(3)提出了一套FFT 算法在ARMv8 及X86-64 架构上的实现策略和优化方案,并构建了一个可跨平台移植的高性能FFT 算法库。
1 相关背景
1.1 Cooley-Tukey FFT 算法
离散傅里叶变换是一种用于进行傅里叶分析的基本离散变换,定义如下:



Cooley-Tukey 算法是在许多实际应用中应用最广泛的快速傅里叶变换(FFT)算法。采取分而治之的方法,通过递归将大的DFT 分解为小的DFT。

为简化DFT 运算,利用DFT 矩阵的对称性周期性将计算时间复杂度由()降到(lb)。
1.2 ARMv8 架构
ARM 是一种负载存储体系结构,是RISC 处理器的典型。ARMv8 是ARMv7 之后的下一个旗舰架构,向后兼容ARMv7,是首次支持64 位指令集的ARM处理器架构,引入64 位体系结构的同时保持了与现有32 位系统结构的兼容性。
ARMv8 提供了31×64 bit 通用寄存器及32 个128 bit 浮点寄存器V0~V31(如图1),浮点寄存器在执行指令时一条指令可以操作多个操作数,可以提高指令的执行效率,提高性能。在SIMD 优化中,浮点寄存器起着重要作用。
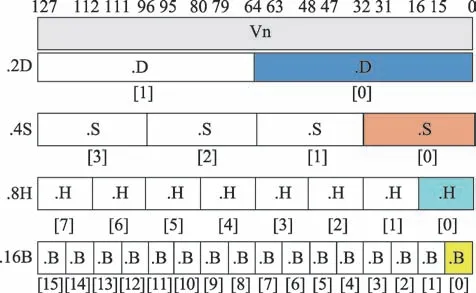
图1 ARMv8 架构浮点寄存器图Fig.1 ARMv8 architecture float register
1.3 X86-64 架构
X84-64 又 称Intel 64 或AMD64,是X86 指令 集64位版本。Haswell 架构是因特尔公司首个支持AVX2的X86 架构。X86-64 处理器架构提供了17×64 bit通用寄存器(RDI、RSI、RDX、RCX、R8-R15、RAX、RBX、RBP、RSP、RIP),其中RDI、RSI、RDX、RCX、R8、R9作为函数输入参数;提供了16个256 bit浮点寄存器YMM0~YMM15。Haswell 向后兼容,寄存器低128 bit 可作为128 bit 浮点寄存器XMM0~XMM15。其中XMM0~XMM7 可作为函数输入参数。XMM 寄存器每条指令可同时处理4 个float 浮点数,YMM 寄存器每条指令可处理8 个float 浮点数。在SIMD 优化,浮点寄存器起着重要作用。
2 相关工作
FFT 算法的研究以主流FFT 库为主,在特定的硬件架构上实现高性能,包括FFTW、ARMPL、Intel MKL、AOCL(AMD optimizing CPU libraries)、CUFFT(CUDA fast Fourier transform library)等。
2.1 FFTW
FFTW 是MIT 的Frigo 和Johnson 开发的自适应优化FFT 软件包,用于计算一维或多个维度、任意输入大小、实数和复数数据以及偶数和奇数数据的离散傅里叶变换DFT。同时支持共享存储多线程并行和MP(Imessage passing interface)并行,其运算性能远远领先目前已有的其他FFT 软件。FFTW 性能可移植,在大多数架构上性能良好,并且自FFTW3.3.1 开始针对ARM 平台实现了较高的性能。
2.2 ARMPL
ARMPL 性能库是ARM 公司针对ARMv8 平台推出的高性能商业库。为ARM 处理器上的高性能计算应用程序提供了标准核心数学库,包含优化的BLAS(basic linear algebra subprograms)、LAPACK(linear algebra package)和FFT,为FFT 计算提供了与FFTW3 相同的接口。
2.3 MKL
MKL 是一个用于科学、工程和金融应用程序的包含快速傅里叶变换的优化数学例程库。Intel MKL FFTW 是因特尔公司在FFTW 基础上二次开发的商业FFT 性能库,是目前X86 平台上性能最好的FFT 商业库,但其只用于X86 架构,可移植性差。
3 FFT 算法的实现和优化
3.1 蝶形网络优化
在Cooley-Tukey FFT 算法中,蝶形网络决定了数据访问模式和蝶形计算执行顺序。DFT 是逐级求解的,每级重复处理蝶形计算,因此蝶形网络的组织方式影响整个优化。相同的蝶形网络,不同的实现和优化可能导致不同的性能。依照蝶形因子在计算中出现的不同位置,实现该算法有两种方式:时域抽取(decimation-in-time,DIT)和频域抽取(decimation-infrequency,DIF)。时域抽取时,蝶形因子在计算输入端,输入向量需位反转,输出自然顺序;频域抽取则相反,蝶形因子在计算输出端,输入向量自然顺序,输出需位反转。
传统蝶形网络存在位反转操作,如图2 所示,增加了额外的内存成本,还增加了混合基建立的困难度,对SIMD 不友好。本文采用了如图3所示的Stockham蝶形网络结构。
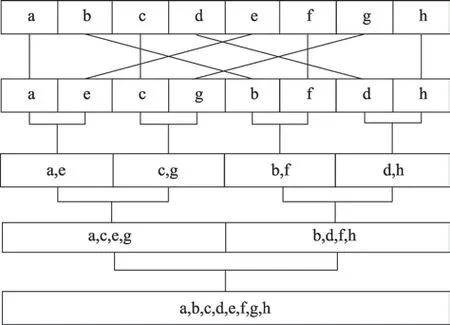
图2 时域抽取Fig.2 DIT network

图3 Stockham 蝶形网络Fig.3 Stockham butterfly network
Stockham 蝶形网络结构相比传统蝶形网络:(1)去除了位反转排列,DIT 时域抽取需要将输入序列重新排序为位反转顺序,位反转排列引入了额外的不连续的内存访问,不连续的内存访问会导致统一输入输出的内存访问困难。Stockham 蝶形网络各级计算的输入输出都是自然顺序,消除了位反转排列,统一了蝶形网络的访存行为。(2)SIMD 友好,SIMD 为一条指令作用在多个数据操作上,为了有效使用SIMD,从内存中加载和存储到内存中的数据应是连续的,Stockham 蝶形网络结构中,蝶形网络的输入输出是连续定位的,在同一级内SIMD 并行化友好。(3)混合基友好,由于每级的输入输出都是自然顺序,不同RADIX 算法采取统一的方式,可以完美融合在一起。
为了得到更好的性能,将第一级蝶形网络单独优化。第一级蝶形网络的旋转因子为1,没有必要从内存中读取和计算,降低了不必要的内存访问和计算成本。第一级输出结果的写入并不连续,在汇编优化时需要再进行数据重组和转置。
蝶形网络带宽依赖较高,由于每一级内存访存写入,蝶形网络级数过多会增加数据访问量。使用大基参与FFT 计算可降低蝶形网络的级数,减少数据访问量。虽然大基参与蝶形网络计算,寄存器不够用,一定程度上降低了蝶形网络性能,但使用大基参与计算带来的性能增益优于性能损耗。
3.2 蝶形计算优化
在FFT 计算过程中,蝶形计算反复调用,蝶形计算的性能将直接影响FFT 算法的最终性能。因此,本节将介绍如何将FFT 蝶形计算的复杂度降到最低。根据离散傅里叶变换式(1),基(Radix-)的蝶形,本质上就是长度为的DFT 计算,而DFT 计算的实质即DFT 矩阵与输入矩阵向量乘法。
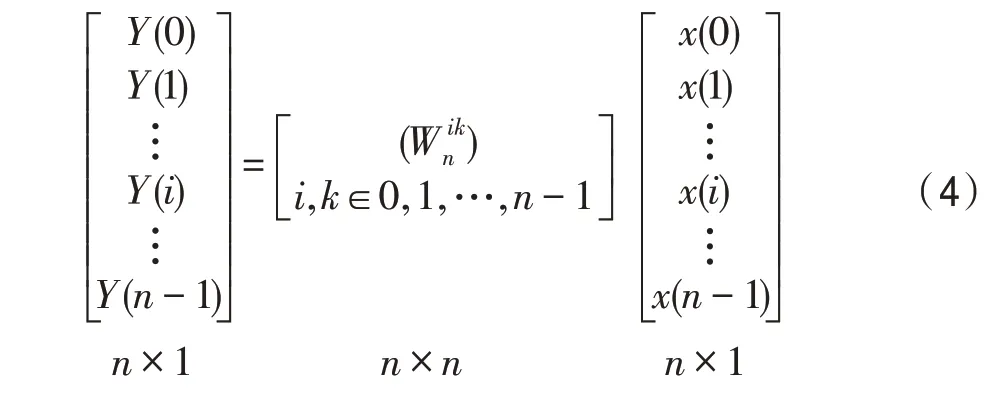
由于当基较小时已经有了成熟的计算方案,本文将研究大基的高性能实现方法,如基14 和基20。
下面将详细地分析Radix-14 的蝶形计算方法。Radix-14 蝶形计算本质上是数据规模为14 的DFT计算。
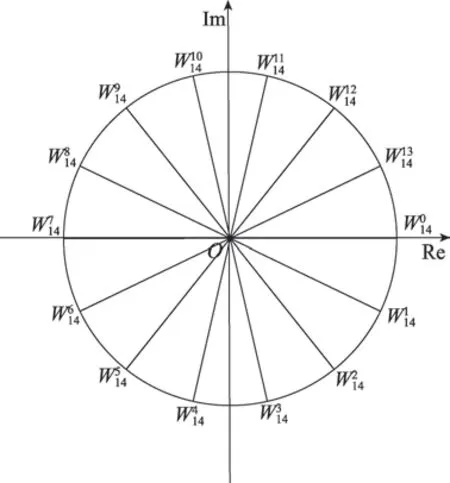
图4 Radix-14 旋转因子复平面分布图Fig.4 Radix-14 twiddles complex plane distribution
根据Radix-14 在如图4 所示复平面上的分布旋转因子关于轴和轴对称:实部相同虚部互为相反数;虚部相同实部互为相反数。
式(1)旋转因子具有如下性质:
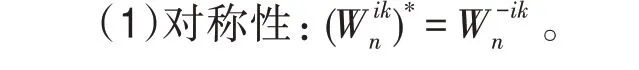



通过提取和预计算公因子,可以减少浮点计算和代码冗余,将蝶形计算的时间复杂度降到最低。

3.3 SIMD 优化
ARMv8 提供了32 个128 位的浮点寄存器,每个浮点寄存器可以存储4 个32 位的单精度float 浮点数或2 个64 位双精度double浮点数,一条指令最多可以同时并行处理4 个数据。在ARMv8 体系结构中,使用2个128位寄存器分别容纳4个复数的实部和虚部。
X86-64 架构提供了16 个256 位的浮点寄存器,X86 架构SSE 指令可以用128 位通路XMM 浮点寄存器处理4 个32 位的运算或处理2 个64 位的运算。X86-64 AVX 指令是SSE 的两倍,可操作16 个YMM 256 位浮点寄存器。并行操作1~8 个单精度float 浮点数,1~4 个双精度double 浮点数。在Haswell X86-64 体系结构中,使用一个256 位寄存器交错容纳4 个复数的实部和虚部。
FFT 计算时,每个蝶形计算相互独立。如图5 所示SIMD 优化同时处理4 个蝶形计算,提高了程序的并行效率。

图5 SIMD 优化Fig.5 SIMD optimization
高级语言程序,一般由编译器负责寄存器使用。为提高FFT 算法性能,本文蝶形计算过程采用汇编语言。通过寄存器使用优化,可提高算法的性能。寄存器使用的主要思想是寄存器分组。浮点寄存器的使用分为输入寄存器in,旋转因子寄存器twiddles,中间结果寄存器scratch 及输出结果寄存器out。ARM 架构复数实部虚部需要×2 个in 寄存器,(-1)×2 个tw 寄存器,×2 个输出out寄存器;X86-64架构需要个in寄存器,-1 个tw寄存器,个out寄存器。随着基数的增长,4 组寄存器需要更多的向量寄存器,寄存器资源无法独立完成蝶形计算。
寄存器优化分为两部分:一部分为寄存器复用;一部分为极大基临时存入堆栈或内存。寄存器复用策略:复用旋转因子临时寄存器tmptw,输入和旋转因子数据相互独立,寄存器使用紧张时分批加载旋转因子,完成复数乘法后,继续复用tmptw,在全部完成旋转因子输入乘法后,释放tmptw;复用临时输入寄存器tmpin,在加载部分输入后,计算中间变量,释放tmpin 以复用;复用临时寄存器tmp,在乘法等运算时需要临时寄存器,这时的临时寄存器需及时复用处理运算;复用tmpout 输出寄存器,在获得输出后,立即存储在内存,释放tmpout以复用。
(1)在大基的情况下如Radix-14,浮点寄存器的合理充分利用,直接影响FFT计算程序性能。ARM架构寄存器合理复用的同时存在不够用的情况。需将公共因子临时存入堆栈,计算输出结果时载入寄存器。
ARM 架构中,Radix-14 的Kernel 计算:中间结果scratch 实部虚部分别需要26 个浮点寄存器。输入数据和旋转因子成对载入,输入数据乘以旋转因子后载入下一对数据时计算中间结果,复用旋转因子和输入数据寄存器;计算中间结果后,+类中间结果寄存器可复用计算;计算过程中将通过寄存器分配无法分配溢出的中间数据+,-存入堆栈,计算输出out 时取出;蝶形计算结果及时输出释放复用输出寄存器。寄存器复用中间处理足够多的指令可消除相邻指令寄存器依赖,达到蝶形计算寄存器最大化合理利用。
X86-64 架构中,Radix-14 的Kernel 计算:中间结果scratch 需要26 个YMM,旋转因子寄存器在乘以输入后重复复用;输入寄存器计算中间结果后释放复用为中间结果寄存器。通过寄存器合理复用即可实现Radix-14 蝶形计算。
(2)在极大基的情况下,如Radix-20,X86-64 架构提供的16 个YMM 寄存器,ARM 架构提供的32 个V0~V31 浮点寄存器远不够用。通过复用寄存器,寄存器仍不够用,此时需要使用堆栈或内存指令暂时保存相关数据,蝶形计算需要时取出载入寄存器。
ARM 架构中,Radix-20 的Kernel 计算:中间结果scratch 实部虚部分别需要50 个浮点寄存器。数据载入时分奇偶序列分开载入;输入寄存器和旋转因子乘运算后,复用旋转因子寄存器;输入数据载入后及时计算,复用输入数据占用的寄存器;计算过程中寄存器占满32 个,通过寄存器分配策略将计算输出频繁用到的S 类中间数据存入堆栈释放所需寄存器,需要使用时再取出;蝶形计算结果及时输出释放复用寄存器。
X86-64 架构中,Radix-20 的Kernel 计算:中间结果scratch 需要50 个YMM。数据成对载入,及时计算中间变量,复用输入寄存器;寄存器分配策略将无法占用寄存器的相关数据存入内存,计算输出结果时载入寄存器;蝶形网络计算第一级输出结果存储转置时,还需将部分输出结果存入内存,数据操作时载入寄存器。
指令选择时,选择延迟低吞吐量高的指令。X86-64 选择vfnmadd231ps 和vfmadd231ps 乘加指令,ARMv8 选择fmla 和fmls 乘加乘减指令。AVX2 还提供了vaddsubps 指令来完成交错模式下的复数乘法。如图6 列出了几种运算的指令对比。在ARM NEON中支持ld2、st2 高效的加载存取指令,因此ARMv8 使用ld2、faddp、st2 等指令进行复数算数运算。

图6 计算指令对比Fig.6 Instruction comparison

图7 顺序执行与指令重排对比Fig.7 Sequential execution and instruction rearrangement
相邻指令间没有依赖关系时可指令重排,避免了流水线stall。指令重排和顺序指令相比并不影响计算结果,但性能会有一定提升。如图7 是基14 指令重排对比图,顺序执行过长时间占用寄存器,寄存器还不够使用,寄存器得不到有效利用,指令重排将载入数据的顺序调整后及时计算中间结果。在中间结果计算后,释放输入寄存器的占用,供输出结果复用。在Radix-14、20 这类大基计算时,指令重排配合寄存器的合理分配优化,一定程度上提高了算法的计算性能。
4 性能评估
4.1 测试环境
本文采用华为鲲鹏920 CPU和IntelXeonCPU E5-2640 V4 作为性能测试平台。华为鲲鹏920 CPU采用ARMv8 架构,IntelXeonCPU E5-2640 V4 采用X86 架构。本文实验条件如表1 所示。
由于FFTW、ARMPL、Intel MKL 是应用最广泛、最成熟的FFT 算法库,将OpenFFT 的性能与这些库进行了比较。采用FFTW3.3.8 和ARM 公司的商业库ARMPL20.0.0 在ARMv8 平台上进行性能对比;采用FFTW3.3.8 和Intel MKL 在X86-64 平台进行对比。本文实现的高性能FFT 算法库为OpenFFT。
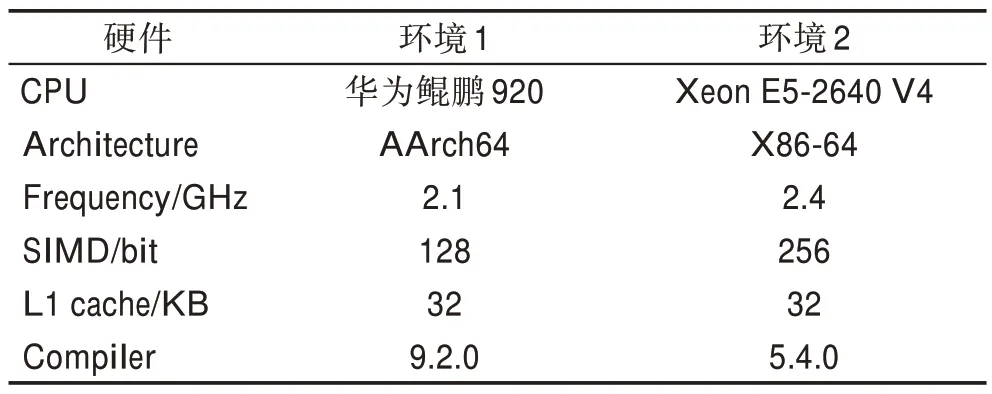
表1 实验环境Table 1 Experimental environment
4.2 性能分析
本文测试数据维度为一维,数据规模为14×20×(以下性能分析图横坐标),输入输出均为复数序列。性能评估以每秒所执行的浮点次数(giga floating-point operation per second,Gflops)为单位(以下性能分析图纵坐标)。
图8给出了OpenFFT、ARMPL和FFTW在ARMv8体系结构上的一维C2C 的性能。对于单精度和双精度序列,OpenFFT 算法库的性能整体高于FFTW 和ARMPL 两个算法库。
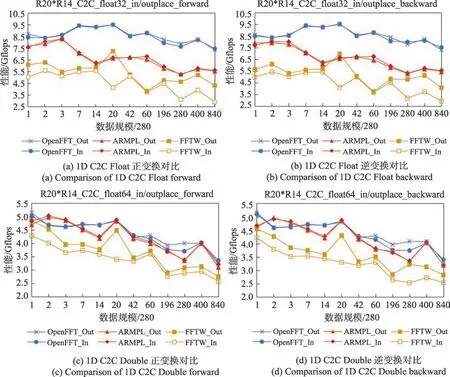
图8 ARM 1D C2C FFT 性能对比Fig.8 Performance comparison of ARM 1D C2C FFT
(1)单精度Float
如图8(a)所示,OpenFFT 在ARMv8 下一维C2C FFT 变换优化结果中,相对于ARMPL 实现了平均31.90%的加速比,最大加速比为51.00%,最小加速比为3.58%;相对于FFTW 实现了平均95.50%的加速比,最大加速比为145.80%,最小加速比为31.00%。图8(b)所示相对于ARMPL 实现了平均32.00%的加速比,最大加速比为51.00%,最小加速比为4.00%;相对于FFTW 实现了平均98.00%的加速比,最大加速比为155.00%,最小加速比为36.10%。
通过比较OpenFFT、ARMPL、FFTW 性能曲线,三者在性能走势上大致相同,从图8(a)、图8(b)可知,OpenFFT 性能在输入规模为5 600 时,开始下降,主要原因在于,数据规模较小时,数据可存储在Cache中,增加了Cache 命中率,减少了访存开销,导致小规模性能整体高于大规模。
(2)双精度Double
如图8(c)所示,OpenFFT 在ARMv8 下一维C2C Double FFT 变换优化结果中,相对于ARMPL 实现了平均4.30%的加速比,最大加速比为19.10%,最小加速比为1.81%;相对于FFTW 实现了平均27.90%的加速比,最大加速比为42.80%,最小加速比为2.90%。图8(d)所示相对于ARMPL 实现了平均5.36%的加速比,最大加速比为22.20%,最小加速比为0.70%;相对于FFTW 实现了平均35.00%的加速比,最大加速比为47.60%,最小加速比为8.00%。
从图8 可知,双精度加速性能相对于单精度要低。主要原因在于SIMD 优化,双精度Double 为64位,ARM 浮点寄存器为128 位,只能循环展开2 次,寄存器一次处理两个数据;再有ARM 部分Double 浮点数指令性能低。图8(c)、图8(d)在数据规模为560、840 存在性能低于ARMPL 的情况,原因在于Cache命中率低,访存开销大且延迟高,再有数据预取不恰当,这些都有可能造成性能不高。
图9 给出了OpenFFT、MKL 和FFTW 在X86-64体系结构上的一维C2C 的性能。对于单精度和双精度序列,OpenFFT 算法库的性能同样整体高于FFTW和MKL 两个算法库。

图9 X86-64 1D C2C FFT 性能对比Fig.9 Performance comparison of X86-64 1D C2C FFT
(1)单精度Float
如图9(a)所示,OpenFFT 在X86-64 下一维C2C FFT变换优化结果中,相对于MKL实现了平均26.00%的加速比,最大加速比为76.00%,最小加速比为0.92%;相对于FFTW 实现了平均70.00%的加速比,最大加速比为155.00%,最小加速比为3.60%。图9(b)所示相对于MKL 实现了平均29.40%的加速比,最大加速比为55.20%,最小加速比为3.60%;相对于FFTW 实现了平均81.80%的加速比,最大加速比为175.00%,最小加速比为11.10%。
通过比较OpenFFT、MKL、FFTW 性能曲线,三者在性能走势上大致相同,OpenFFT 性能走势最高,其次是MKL,性能最低的是FFTW。从图9(a)、图9(b)可知,OpenFFT 性能在输入规模为3 920 时达到最高点,随后随着规模的变大整体性能略下降后趋于稳定。小规模性能高在于数据能存在Cache 中,增加了Cache命中率,因此小规模性能整体高于大规模。
(2)双精度Double
如图9(c)所示,OpenFFT 在X86-64 下一维C2C Double FFT 变换优化结果中,相对于MKL 实现了平均45.00%的加速比,最大加速比为126.00%,最小加速比为18.80%;相对于FFTW 实现了平均50.50%的加速比,最大加速比为113.00%,最小加速比为6.50%。图9(d)所示相对于MKL 实现了平均33.80%的加速比,最大加速比为96.00%,最小加速比为1.50%;相对于FFTW 实现了平均52.70%的加速比,最大加速比为110.00%,最小加速比为2.98%。
表2 总结了在ARMv8 和X86-64 架构在数据规模为14×20×一维C2C 复数序列下,OpenFFT 分别与FFTW、ARMPL 和MKL 算法库性能对比的平均加速和最大加速。实验表明OpenFFT 性能明显优于FFTW、ARMPL 和Intel MKL FFT 算法库。

表2 OpenFFT 平均和最大加速Table 2 Average and maximum speedups of OpenFFT %
图10、图11 给出了OpenFFT 在ARMv8 体系结构和X86-64 体系结构上同一数据规模大基Radix-14、Radix-20 和中小基Radix-10、Radix-7 等一维C2C性能对比。对于单精度和双精度序列,同一数据规模OpenFFT 大基性能总体优于小基性能,大基对于总体性能的提升大于大基带来的性能损耗。
(1)ARMv8 大小基性能对比
①Float 如图10(a)所示,OpenFFT 在ARMv8 下单精度一维大基C2C FFT 变换,相对于小基实现了平均0.16%的加速比,最大加速比为8.70%;大基跟小基在性能走势上大致相同,在数据规模达到54 880性能优于中小基。从图10(a)可知,大基在输入规模为560、840、11 760、16 800,即为Radix-2 或Radix-3时,性能低于中小基,主要原因是ARM 体系结构单精度下Radix-2、Radix-3 对性能的影响,数据规模分解方式不唯一,ARM 单精度下异常性能的数据规模Radix-20*Radix-14*Radix-2 或Radix-3 不是最优分配造成的性能差异。
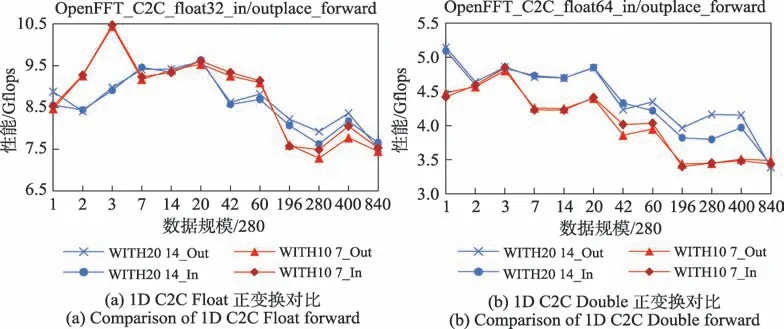
图10 ARMv8 1D C2C FFT 性能对比Fig.10 Performance comparison of ARMv8 1D C2C FFT

图11 X86-64 1D C2C FFT 性能对比Fig.11 Performance comparison of X86-64 1D C2C FFT
②Double 如图10(b)所示,OpenFFT 在ARMv8下双精度一维大基C2C FFT 变换,相对于中小基实现了平均10.00%的加速比,最大加速比为20.70%;大基跟中小基相比,性能优于中小基。
(2)X86-64 大小基性能对比
①Float 如图11(a)所示,OpenFFT 在X86-64 下单精度一维大基C2C FFT 变换,相对于小基实现了平均17.00%的加速比,最大加速比为35.90%;大基性能优于中小基,在数据规模超过16 800,大基性能优势再次拉大。
②Double如图11(b)所示,OpenFFT 在X86-64 下双精度一维大基C2C FFT 变换,相对于中小基实现了平均33.30%的加速比,最大加速比为72.80%;大基跟中小基相比,性能优于中小基,性能优势明显。
实验结果表明,大基虽然存在寄存器不够使用,计算复杂的问题,一定程度上降低了蝶形计算性能,但大基减少了计算过程中的访存,一定程度提升了性能,大基性能增益明显大于性能的损耗。
5 结束语
本文在原有FFT 基础上,通过蝶形网络优化、大基网络级数降低减少访存、大基蝶形计算优化、SIMD 优化寄存器分配等优化方式,突破了快速傅里叶变换在ARMv8 与X86-64 硬件平台上的算法性能,形成了一套FFT 算法在ARMv8 及X86 架构上的实现策略和优化方案,实现了一个跨平台的高性能FFT 算法库。同时对ARMv8 及X86-64 平台上程序优化提供了思路。下一步的工作将实现和优化快速傅里叶变换列主序,完善OpenFFT 高性能算法库,形成一套实用完善的高性能FFT 算法库。
猜你喜欢
火控雷达技术(2023年2期)2023-07-15 14:00:06
导航定位学报(2022年2期)2022-04-11 03:17:34
光通信研究(2022年2期)2022-03-29 03:19:18
计算机应用(2020年5期)2020-06-07 07:06:44
铁道通信信号(2019年4期)2019-10-10 03:42:38
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
电测与仪表(2015年18期)2015-04-12 00:45:24
电子设计工程(2015年3期)2015-02-27 12:03:45
装备制造技术(2013年6期)2013-06-26 11:38:08
网络安全与数据管理(2011年24期)2011-08-08 02:31:52
