
基于知识图谱的双端邻居信息融合推荐算法
2022-06-18 02:09王宝亮潘文采
计算机与生活 2022年6期
王宝亮,潘文采
1.天津大学 信息与网络中心,天津 300072
2.天津大学 电气自动化与信息工程学院,天津 300072
当今社会,随着网络的兴起,用户的选择信息越来越多,为了解决用户的个性化推荐问题,推荐系统应运而生。其中,协同过滤算法通过分析相似用户的行为进行推荐,取得了较大的成功。然而,传统的协同过滤算法存在冷启动和用户交互信息稀疏的问题,因此研究者通过加入辅助信息例如社交网络、物品的属性信息等来缓解该问题。由于知识图谱包含丰富的物品信息,也被应用于推荐算法中。

将知识图谱应用于推荐算法已成为一个热点,例如文献[7]将知识图谱应用于新闻推荐系统,将上下文嵌入、知识图谱实体嵌入和语句嵌入送入CNN网络,从而在语义层次和知识图谱层次学习嵌入表示。文献[8-9]将知识图谱网络中与用户交互的物品的邻居信息聚合到用户上,生成信息丰富的嵌入表示。文献[10-11]将物品的邻居信息聚合到物品上生成物品嵌入表示。
受上述算法启发,本文提出基于知识图谱的用户物品邻居信息融合推荐算法,即将用户邻居和物品邻居信息分别融合,从而产生用户和物品信息均丰富的嵌入表示。在聚合用户信息时,首先根据用户的点击记录得到与用户交互的物品,如图1 所示的左边菱形节点。然后根据物品在知识图谱网络的位置得到一阶邻居。同理,向外传播,得到高阶邻居。然后利用节点和节点之间的关系丰富用户的向量表示。在聚合物品信息时,由于物品通常是知识图谱的某个实体节点,如图1 所示右边的菱形节点,直接得到物品的一阶和高阶邻居,根据KGCN(knowledge graph convolutional networks)模型(一种利用图卷机神经网络和知识图谱的推荐模型)聚合信息生成丰富的物品嵌入表示。最后将得到的用户和物品的向量嵌入表示送入预测环节,得到用户和物品的交互概率。在公开的两个数据集上进行对比实验,验证了本文算法的有效性。

图1 总体框架Fig.1 Overall framework
1 本文算法
1.1 总体框架
本文的总体思路如图1 所示,其中,正方形节点表示用户节点,圆形和菱形节点表示知识图谱中的实体节点,左边的菱形节点表示与用户有交互关系的物品节点。
1.2 用户节点邻居信息融合
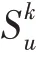
给定用户物品交互矩阵和知识图谱用户的跳实体集合定义如下:
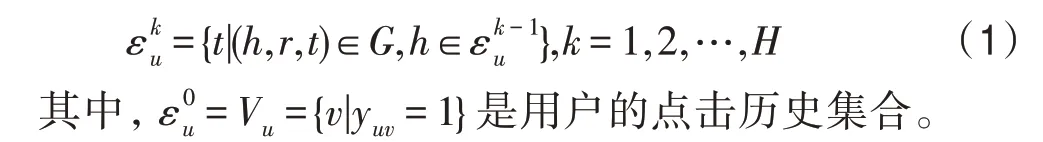
用户的跳的邻居集合如下:
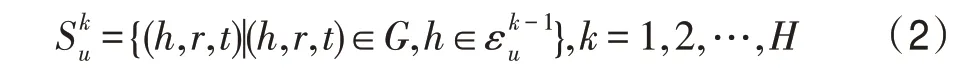
随着跳数的增加,邻居集合的数量会变得十分庞大,因而不会选得很大,当很大时,带来的噪音会比有效信息更多。同时,为了降低集合的数量,每一跳采样固定数量大小的邻居。
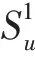

其中,R∈R,h∈R,分别表示关系R和实体head h的嵌入表示,考虑到用户的点击历史是用户的直接兴趣表达,因而将加入权重表达式。
p可以表示在R空间下用户对于h和关系R的喜好程度,也可以表征每个邻居节点和用户的点击历史物品的相似度。
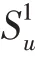

其中,t∈R,是tail t的嵌入向量的表示。
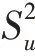
最终的用户的向量表示为:

然而,对于[],随着的增长,离用户的交互历史越来越远,包含的噪音信息会更多,因此不同的路径对模型的影响是不同的,式(5)无法解决该问题,选择文献[12]提出的累加操作,如式(6)所示。
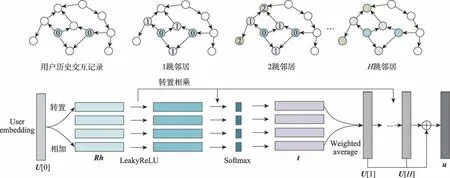
图2 用户节点信息融合Fig.2 User node information aggregation

其中,是参数,用来控制每一跳输出的权重。该操作能够区分不同跳输出的重要性,其偏导如式(7)所示。
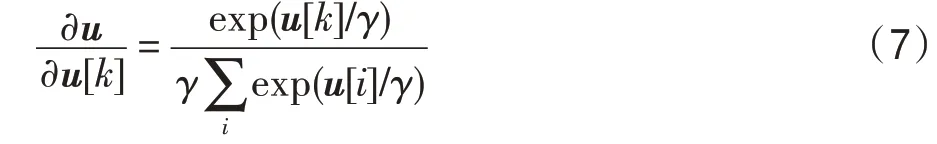
通过控制的大小可以调整每一跳输出的比重。
1.3 物品节点邻居信息聚合
物品邻居节点的聚合采用KGCN模型,其基本框架如图3 所示。
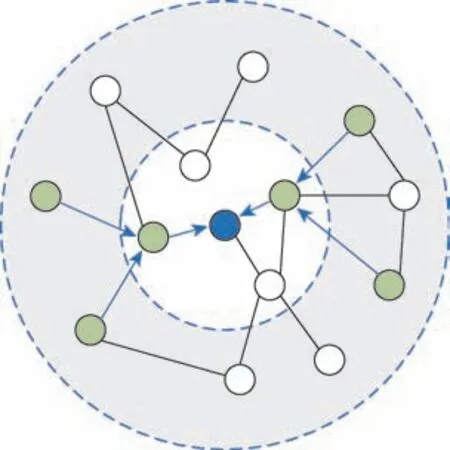
图3 KGCN 模型Fig.3 KGCN model
KGCN 模型在知识图谱中聚合实体特征,从而发掘物品的潜在关联。涉及的概念如下:

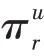

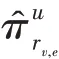

()的规模很大,选择随机采样固定数量邻居的方式降低计算复杂度。

其中,表示采样的数目。
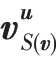
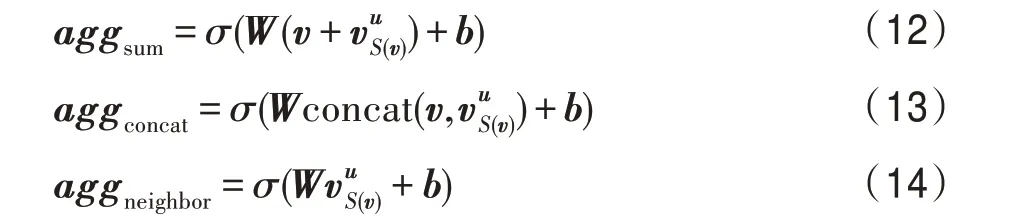
根据文献[10]实验结果,式(12)的聚合效果在三种聚合方式最好,本文根据文献[13]提出的聚合方式,如式(15)所示。
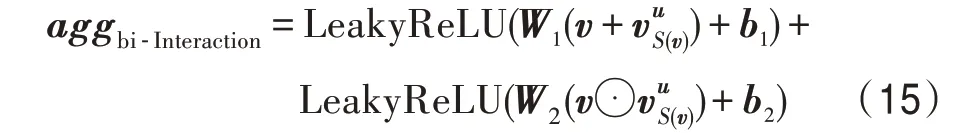
其中,⊙表示element-wise 操作。
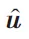

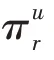

根据式(9)~(11)、(15)~(17),如图3 所示,不断从外向内聚合,将节点的信息聚合到物品节点。最终形成物品节点的向量表示v。
1.4 预测部分
通过1.2 和1.3 节,得到了用户和物品的最终向量表示和v,其中用户向量包含了用户的历史记录信息和其在知识图谱中的邻居信息。物品向量v包含了物品本身和其在知识图谱的邻居信息以及用户对邻居信息的喜好程度。预测函数如式(18)所示。

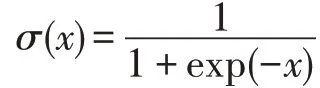
为了比较对向量的不同操作对最终结果的影响,预测函数公式可替换为式(19)。

其中,∈R。
损失函数如式(20)所示。
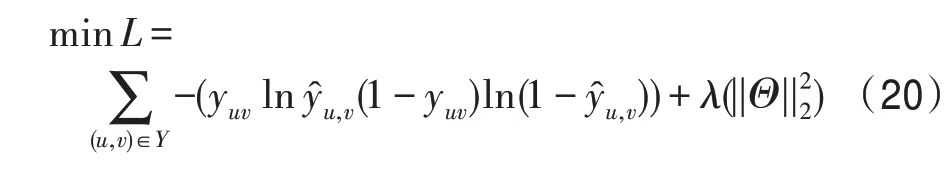
1.5 算法流程
双端邻居信息融合

2 实验部分
2.1 数据集
本文采用的数据集是Book-Crossing(http://www2.informatik.uni-freiburg.de/~cziegler/BX/)和Last.FM(https://grouplens.org/datasets/hetrec-2011/)。其中Book-Crossing数据集来自Book-Crossing 市场,包含100 万个书籍评分信息。Last.FM 数据集来自Last.FM 在线音乐系统,包含2 000 个用户的评分信息。对应于数据集的知识图谱数据从KGCN公开的预处理知识图谱获得(https://github.com/hwwang55/KGCN),该知识图谱信息来自Microsoft Satori。两个数据集经过预处理后的统计数据如表1 所示。
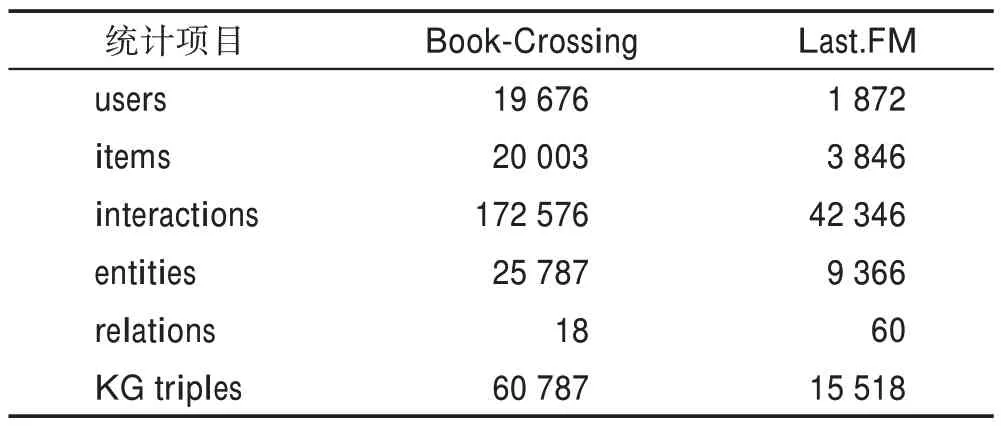
表1 两个数据集的统计数据Table 1 Statistics for two datasets
2.2 实验设置和参数
本文算法将与经典的推荐算法LibFM、Wide&Deep和基于知识图谱的推荐算法RippleNet、KGCN、KGNN-LS进行比较。通过评价指标ACC(accuracy)和AUC(area under curve)来比较各个算法的性能,它们反映了算法在CTR(click-through rate)预测时的性能。
本实验在Windows10 环境下使用python-3.6.5 进行开发,使用的第三方库及版本:tensorFlow-1.12.0、numpy-1.15.4、sklearn-0.20.0。对于每个数据集,按照6∶2∶2 的比例随机构成训练集、验证集和测试集。其他相关的参数如表2 所示。
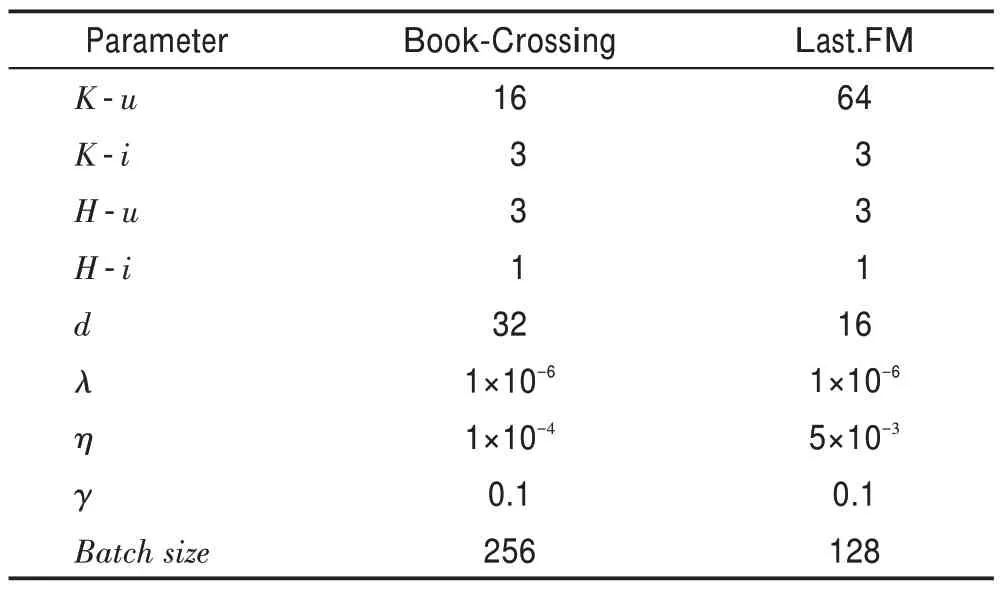
表2 参数的设置Table 2 Parameter setting
表2 中,-表示用户端,-表示物品端。表示邻居采样数量,表示跳数,表示嵌入向量的维度,表示正则化参数,表示训练速率,表示式(6)中的参数,调整每一跳的比重。
KGCN(https://github.com/hwwang55/KGCN)、KGNN-LS(https://github.com/hwwang55/KGNN-LS)的参数设置按照文献[10-11]的设定进行设置。对于RippleNet(https://github.com/hwwang55/RippleNet),其在Last.FM数据集上的设置为=16,=3,=10,=0.02,=0.005;在Book-Crossing 数据集的设置为=4,=3,=10,=0.01,=0.001。
2.3 对比实验结果
各个模型的CTR 预测结果如表3 所示。
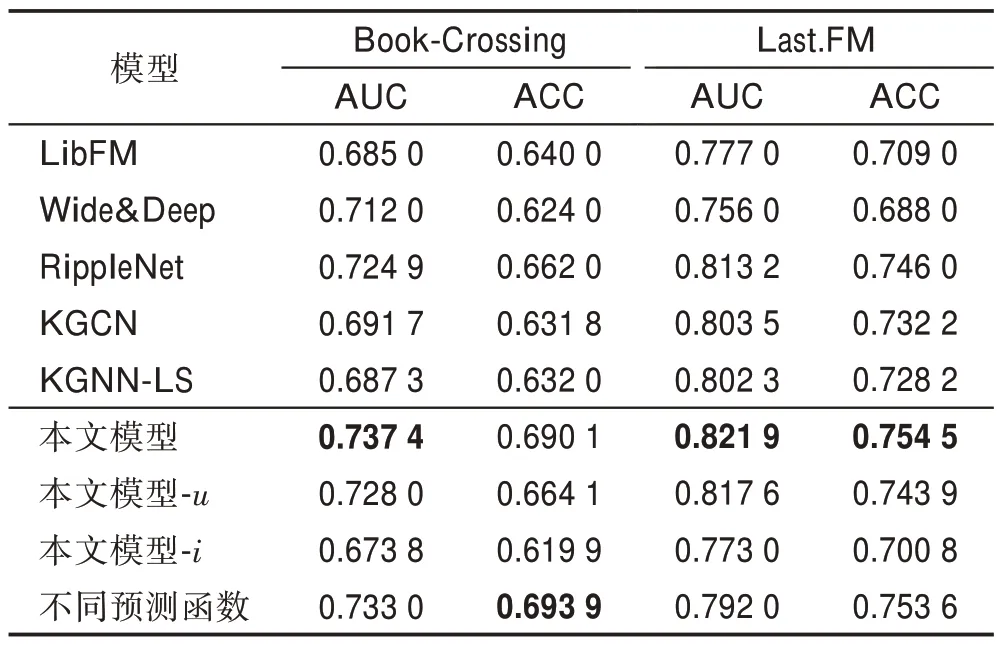
表3 CTR 预测中AUC 和ACC 的结果Table 3 Results of AUC and ACC in CTR prediction
从表3 的结果可以看出,相较于经典的推荐算法LibFM、Wide&Deep 以及在知识图谱中仅聚合用户邻居信息的RippleNet算法和仅聚合物品邻居的KGCN、KGNN-LS 算法,本文算法在两个数据集的性能都有所提升。在Book-Crossing 数据集上,相较于最优基线,AUC和ACC提升1.72%和4.24%;在Last.FM 数据集上,AUC和ACC提升1.07%和1.14%。其中模型-表示本文算法仅聚合用户邻居信息的结果,模型-表示本文算法仅聚合物品邻居信息的结果。通过对比可以看出聚合两者的邻居信息能够提升算法的有效性。同时可以发现,模型-的算法性能下降较为明显,主要原因是本文的物品邻居采样数太少且向外聚合的深度也仅为1 跳,因此得到的信息非常少,从而导致性能效果下降更多,这也从侧面说明邻居信息对算法的性能有较大的影响。
表3 最后一行表示用式(19)作为预测函数的结果。可以看出,式(19)引入额外的无关参数会导致大部分结果变差,因此需要恰当选择合适的预测函数,才能提升模型性能。
2.4 参数敏感性分析
在聚合用户邻居信息时,得到每一跳的结果后,通过值来调整每一跳累和时的比重,当值趋于0时,会选择最重要的一跳信息作为最终用户向量表示,当值趋于无穷时,累和方式类似于对多跳输出取平均值作为最终用户向量表示。由表4 结果可以看出,对于Book-Crossing 数据集和Last.FM 数据集,值取小值时,效果要好于大值。这是由于取小值时,会更倾向于取重要一跳的信息作为最终用户向量表示。表4 中最后一行表示直接累加所有跳的输出的结果,可以看出,利用值调整能够提升算法的有效性。
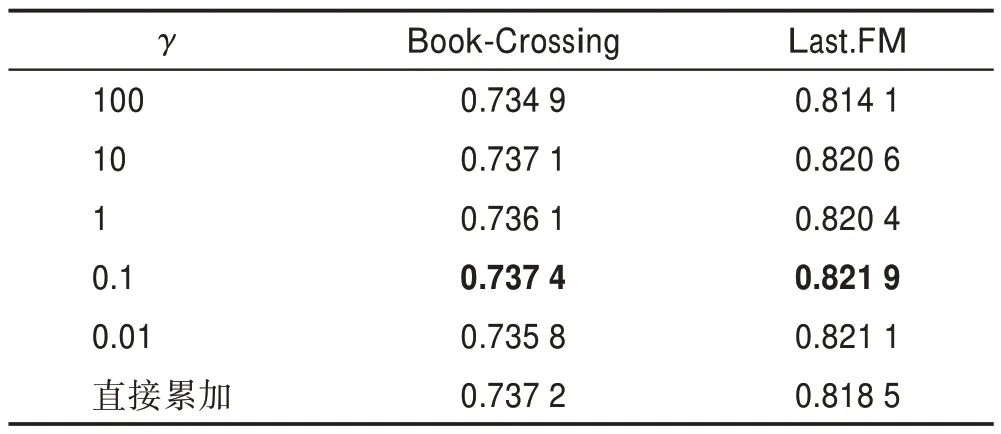
表4 参数γ 对AUC 值的影响Table 4 Influence of parameter γ on AUC value
表5 和表6 表示采样邻居数目对算法的影响。可以看出,当值取过低和过高时,模型的性能都会受到影响。过高时,会带来更多的噪音,过低时无法聚合更多有效的信息。
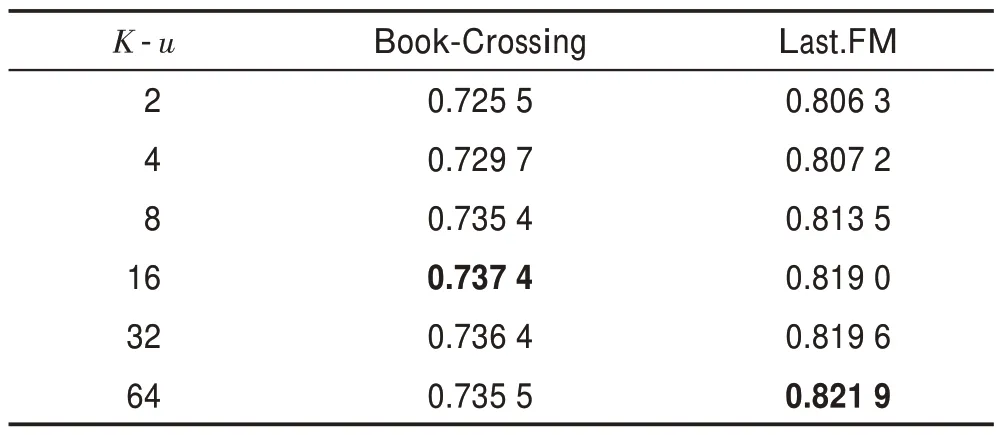
表5 用户端每跳采样值K-u 对AUC 值的影响Table 5 Impact of K-u sampled value per hop on AUC value at user end
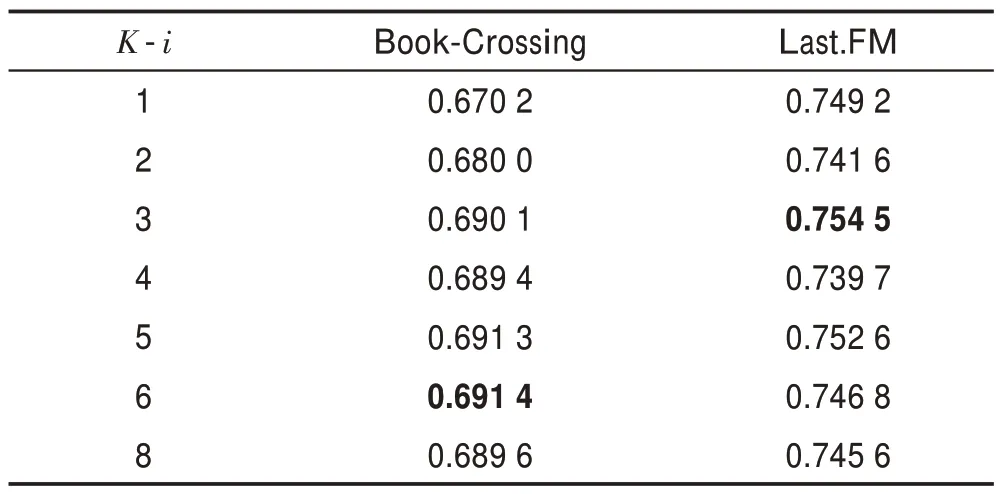
表6 物品端每跳采样值K-i 对ACC 值的影响Table 6 Impact of K-i sampled value per hop on ACC value at item end
表7和表8 表示聚合深度对算法的影响。可以看出本文算法对聚合深度的敏感性更强,特别是对于的性能急剧恶化,说明当跳数增加时,会引入更多的不必要信息,这也符合现实情况。知识图谱中的1 跳邻居信息是对实体的更为直接的描述,有很强的相关性,当跳数增加时,其有效的描述信息会少很多。
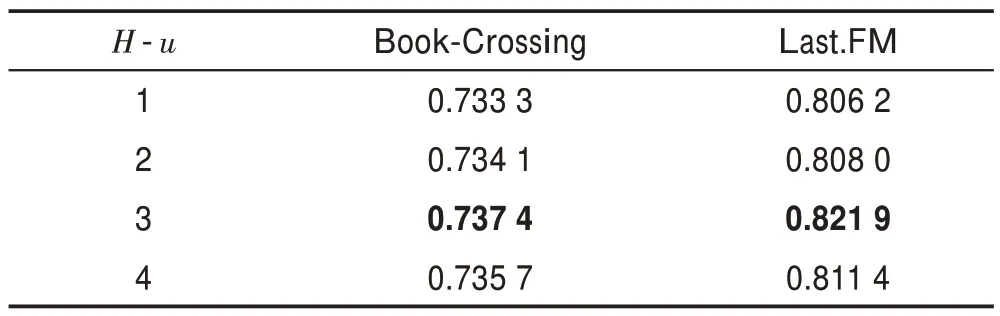
表7 用户端聚合跳数H-u 对AUC 值的影响Table 7 Impact of user end aggregation hops H-u on AUC value
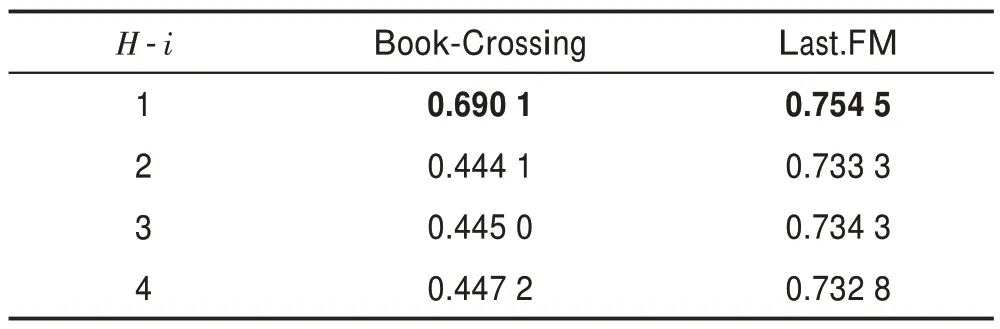
表8 物品端聚合跳数H-i 对ACC 值的影响Table 8 Impact of item end aggregation hops H-i on ACC value
表9 表示向量维度对算法性能的影响。合适的向量维度能够编码有效的信息而不会引入更多的噪音,也能缓解算法的过拟合现象,同时也会减小算法的训练时间。
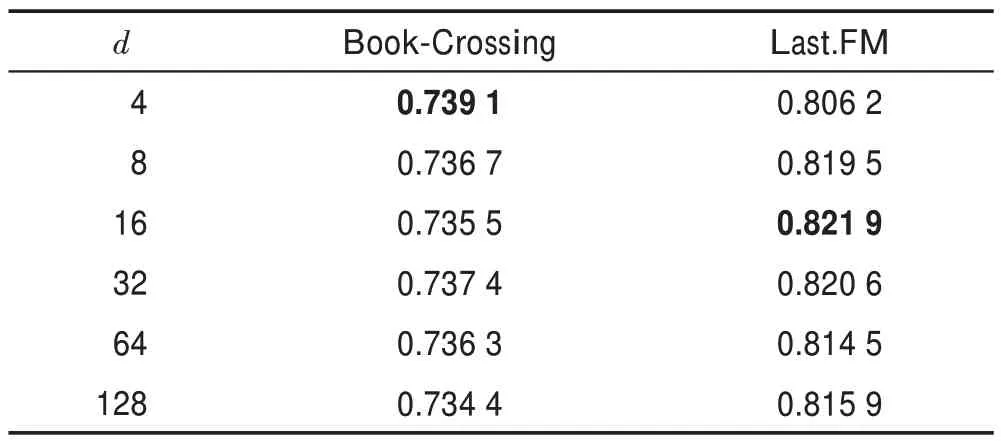
表9 向量维度值d 对AUC 值的影响Table 9 Influence of vector dimension value d on AUC value
3 结束语
针对推荐系统存在的冷启动问题,本文提出了一种基于知识图谱的融合用户邻居信息和物品邻居信息的推荐算法。该算法将知识图谱作为辅助信息,算法首先聚合用户的邻居信息,生成有个性化信息的用户向量,然后将用户向量送入KGCN 模型聚合物品的邻居信息,生成有个性化的物品向量。最后将向量送入预测阶段。在数据集Book-Crossing 和Last.FM 上的实验结果证明了本文算法的有效性,提高了推荐结果的准确性,同时增加了推荐算法的可解释性。下一步将针对知识图谱中存在的不相关实体问题做进一步探究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2022年5期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
疯狂英语·初中天地(2021年11期)2021-02-16
少先队活动(2020年12期)2021-01-14
少年漫画(艺术创想)(2019年2期)2019-06-06
新城乡(2018年6期)2018-07-09
领导科学论坛(2016年9期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
