
高帧率的轻量级孪生网络目标跟踪
2022-06-17 07:10李运寰闻继伟
计算机与生活 2022年6期
李运寰,闻继伟,彭 力
物联网技术应用教育部工程研究中心(江南大学 物联网工程学院),江苏 无锡 214122
目标跟踪作为计算机视觉的基本任务之一,在过去十年内取得了重大的突破,已经被广泛用于视频监控、自动驾驶、人机交互等众多生活场景中。在实际应用中追求跟踪精度提升的同时,跟踪器的速度也相当重要。
现代跟踪器可以大致分为两个分支。第一个分支是基于相关滤波的跟踪算法,以核循环结构算法(circulant structure kernels,CSK)、核相关滤波(kernelized correlation filter,KCF)为代表的传统相关滤波算法,它可以在线跟踪并同时有效地更新滤波器的权重。然而方向梯度直方图(histogram of oriented gradient,HOG)等手工标注的浅层特征在面对尺度变化、光照变换等挑战时的表现显得不那么稳定可靠。近些年,卷积神经网络在其他计算机视觉任务中大放异彩,相关滤波类算法便开始使用神经网络提取的特征代替那些手工标注的特征,神经网络提取出的特征相比手工标注的特征更具对跟踪目标特征的表达能力,准确度得到一定的提高,但是在模型更新过程中极大地损害速度指标。第二个分支以多域卷积网(multi-domain convolutional neural networks,MDNet)为代表旨在利用离线预训练的深度网络进行特征提取,提升目标的特征表达能力,进而大幅提升跟踪精度,但是由于未使用特定域的信息,这类方法的效果始终不如基于相关滤波的算法的综合效果好,并且该类使用的预训练网络十分庞大,特征维度的升高直接影响跟踪速度的大幅下降,多数算法即使在GPU 上的速度也只有个位数,无法适应现实应用。
最近,遵循相似性度量策略的孪生网络跟踪算法由于其在精度和速度都取得良好的性能获得极大的关注。全卷积孪生网络(fully convolutional siamese networks,SiamFC)作为这类算法框架的开创工作,首先对孪生网络通过大规模且种类丰富的图片对进行离线训练,然后计算待搜索区域与模板图片的相似度,响应最高的位置为目标的估计位置,且跟踪过程中无需更新模型,因此十分高效。在此基础上,为了增强SiamFC 算法的特征表征能力,陆续提出很多高效的跟踪算法。SA-Siam(semantic and appearance siamese networks)构建一个双重孪生网络,提升了基础算法的泛化能力。SiamVGG 使用VGG 网络代替AlexNet,充分使用了深层网络的特征提取能力,提高了基础算法的精确度但是模型参数量的剧增导致跟踪速度下降很多。
在保证算法参数量小,兼顾精度和速度都有大幅提升的前提下,本文以SiamFC 算法框架为基准,提出四点改进策略。首先,使用轻量级卷积神经网络MobileNetV1作为主干网络,比AlexNet更深的网络发掘出的特征对目标特征的表达能力更强。其次,逐层裁剪受到填充影响的特征图,消除填充操作对特征图的影响,提高跟踪精度。紧接着,对选取的主干网络进行调整,选取网络的前9 层,修改网络总步长为8,并且在特征提取层的最后增加通道降维操作。使得为分类问题设计的MobileNetV1 适用于目标跟踪任务。最后,在孪生网络的模板分支最后增加通道注意力模块,加权突出目标的重要信息,抑制无关或次要信息对特征的影响,进一步增强模板分支对目标语义信息的表达能力。
经过本文提出的改进策略,本文算法在OTB2015数据集和VOT2018 数据集上与基准算法相比均有了显著提升。在OTB2015 上,Precision(Prec)提升了5.4%,AUC 提升了4.8%;在VOT2018 上,平均重叠期望(expected average overlap,EAO)提升了26.6%,在精度提升的同时算法在NVIDIA GTX1080Ti 下的平均速度高达120 frame/s,速度提升了39.5%。并且本文算法模型十分轻量,在移动端或嵌入式等算力相对不足的设备中更具竞争力。
1 基于轻量级孪生网络的高速目标跟踪
基于孪生网络的目标跟踪算法的实施是将目标跟踪任务转化为相似性度量问题,如式(1)所示。
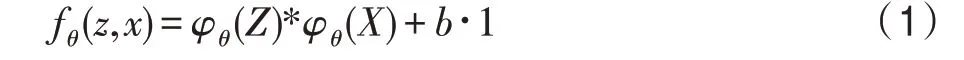
式中,f(,)是相似性度量函数;是视频序列的第一帧,即模板图片;是视频序列的后续帧,即待搜索图片;φ(·)表示经由参数为的卷积神经网络得到的特征图;*表示互相关运算;·1 表示在响应图中每个位置的取值。则跟踪过程可以转变成:模板图片和搜索图片送入孪生网络中,对得到的两个特征图进行互相关运算即以模板分支最后的特征图作为卷积核对搜索分支最后的特征图进行卷积,得到的结果就是得分响应图,得分越高的地方则越可能是待跟踪对象出现的位置,反之得分越低的地方则越不可能出现待跟踪目标,对得分最高的地方进行多尺度变化回溯到原图中。
本文算法框架如图1 所示。相比于SiamFC,本文使用参数量更小、网络更深、特征表达能力更强且便于在嵌入式设备中移植的轻量级网络Mobile-NetV1 作为主干网络。对在进行前向传播过程中受到填充影响的特征图进行裁剪,消除填充带来的消极影响,修改网络的总步长为8,在特征提取层后添加通道降维操作,使其适用于跟踪任务。在模板分支的最后添加通道注意力模块(channel attention module,CAM),增强模板分支特征图对待跟踪目标语义信息的表达能力。
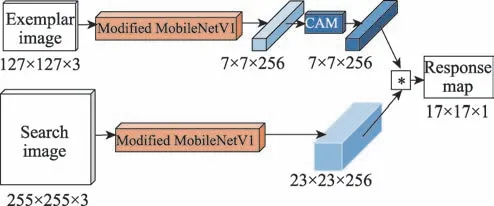
图1 轻量级孪生网络框架Fig.1 Framework of light-weight siamese network
1.1 轻量级网络MobileNetV1
SiamFC 算法由于其在速度和精度都达到较好的水准而备受关注。然而SiamFC 的主干网络使用的是相对较浅的AlexNet,较浅的网络保证其参数量较小,因此SiamFC 的跟踪速度在孪生网络系列算法中占领先位置。可是较浅的神经网络不具备强大的特征提取能力,提取的特征对目标特征的表达能力相对不足。置换更深的卷积神经网络,伴随而来的是结构越加复杂,网络体积逐渐增大,对硬件配置需求逐渐增多。大多神经网络都是在具有强大计算能力、性能优越的服务器平台上运行,普通PC 设备不能完成如此庞大的计算任务,那么算力更加不足的移动端设备就更难以部署了。
为解决在提升主干网络特征提取能力的同时,参数量还能更小以保证跟踪速度和满足特定算力相对不足的场景,本文选用比AlexNet 更深,但是参数量更小的MobileNetV1 作为算法的主干网络。更深的网络保证输出的特征图具有强大的特征表示能力,同时更少的参数量可以保证跟踪器的速度可以高帧率运行。经实验分析,算法的准确度和速度都有了很大的提升。
MobileNetV1 是谷歌提出的一种轻量级卷积神经网络,如表1 所示,参数量和主流的其他神经网络相比十分小,因此可以在移动端或嵌入式设备中应用。不同于表中其他网络的地方在于该网络使用的卷积方式是深度可分离卷积,这是其在较深的网络结构下,参数量却很小的关键。深度可分离卷积是分解卷积的一种形式,它将标准卷积分解为深度卷积和点卷积,点卷积就是卷积核的宽高都是1的标准卷积。
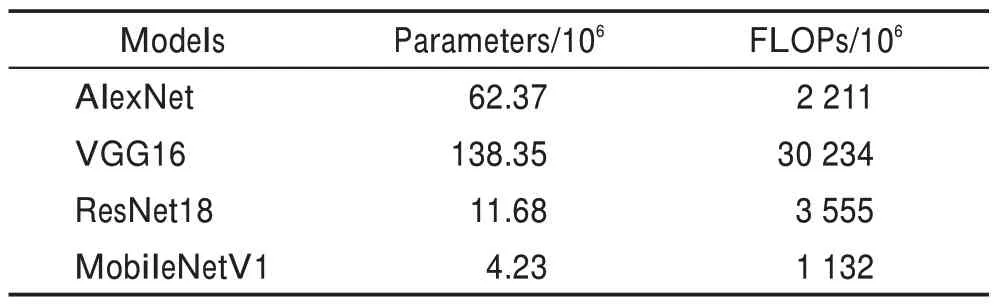
表1 各神经网络参数量对比Table 1 Parameters comparison of various neural networks
标准卷积运算包含了卷积核的计算和合并计算,可直接将输入变成一个新尺寸的输出,如图2 所示。
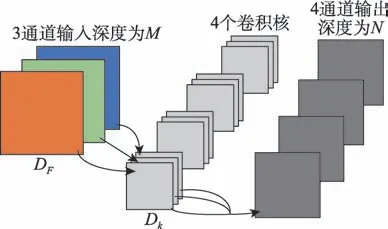
图2 标准卷积Fig.2 Standard convolution
深度可分离卷积操作则分解为两步,先是深度卷积(depthwise convolution,Dw Conv),然后是点卷积(pointwise convolution,Pw Conv)。深度卷积是对输入的每一个通道都有一个卷积核,对每个通道单独运算,然后通过点卷积对深度卷积后的结果进行1×1 的标准卷积运算,合并出一个新尺寸的输出,如图3 所示。这种分解方式可以大大减少参数计算量和模型的大小。
图2、图3 中D表示输入图片的尺寸,D表示卷积核的尺寸,和表示输入输出的通道深度。
则一次标准卷积的计算量可表示为式(2):
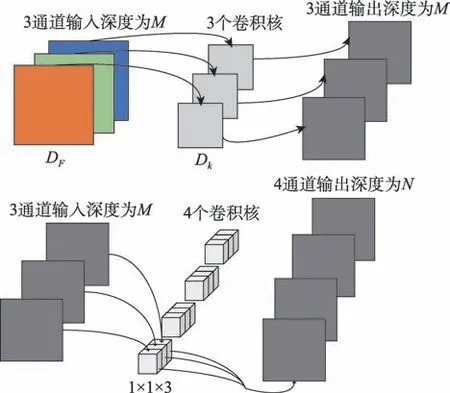
图3 深度可分离卷积Fig.3 Depthwise separable convolution

一次深度可分离卷积的计算量为深度卷积与点卷积的运算量之和,可表示为式(3):
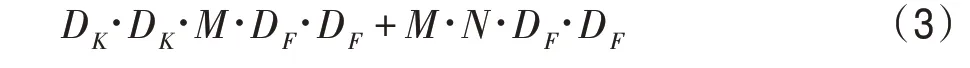
MobileNetV1 中D都是3,则两个运算量的比例可表示为式(4):
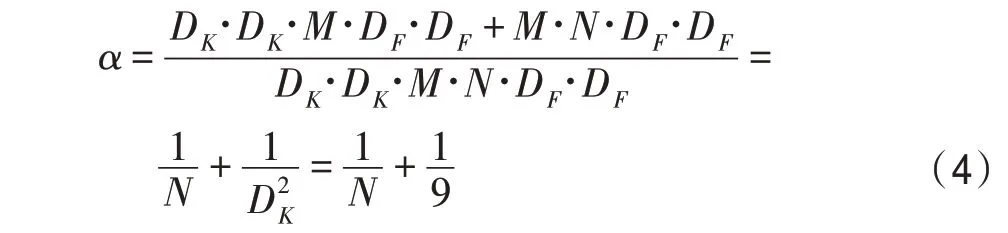
分析可得,理论上,一次标准卷积的运算量是深度可分离卷积的运算量的8 到9 倍。
相对于主流的卷积神经网络模型,MobileNetV1拥有更小的体积,更小的参数计算量,更高的精度,得益其诸多优势,可以更好地在移动端设备部署,因此本文选取MobileNetV1 作为孪生网络的特征提取网络。
1.2 裁剪特征图
SiamFC 使用的特征提取网络AlexNet 是不带填充的全卷积神经网络。通过使用深层神经网络替换AlexNet 以提高提取的特征对目标的表达能力,随着网络深度的增加,为了保证输出特征的尺寸不会因卷积操作而越来越小,不可避免地在卷积层中引入填充(padding)操作。SiamDW中提及大量的填充操作会在模型训练时带来潜在的位置偏差,从而导致跟踪精度下降。例如当目标移动至搜索图片的边界时,跟踪器很难得到一个精准的位置预测,如图4所示。因此需要消除填充所带来的消极影响。
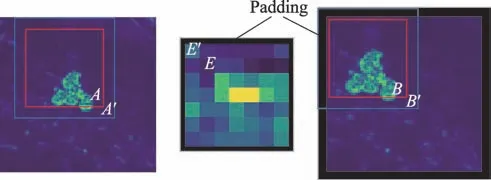
图4 填充的影响Fig.4 Padding influence
以OTB2015 中MotorRolling 序列为例,图4 中间的是模板图片的特征图,′是带有填充的模板图片的特征图,左边是待搜索图片的特征图,右边是移动一定步幅后的目标在边界时的待搜索图片的特征图,红色框的内容与进行互相关操作得到响应R和R,蓝色框的内容与′进行互相关操作得到响应R和R。
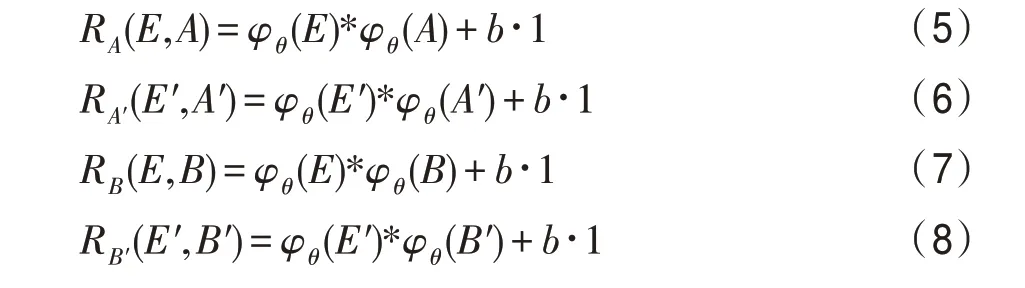
在无填充的情况下,目标运动到边界时,与的内容一致,因此R=R。
在有填充的情况下,目标运动到边界时,′与′的内容不一致,′的边缘包含了大量填充信息,因此R≠R。
分析这两种情况可知,无填充时,相同的物体移动后在响应图中的响应是相同的;有填充时,相同的物体移动后在响应图中的响应是不同的。不同的响应回溯到原图中的位置必然不同,回归框会在目标周围发生偏移,损害跟踪精度。因此在保证得分响应图的大小在合理范围的前提下,如表2 所示,对主干网络的部分层后增加裁剪(crop)操作,消除填充对特征图的消极影响,从而提升跟踪精度。
1.3 调整网络总步长
原有的MobileNetV1 有5 个卷积步长为2 的卷积层,网络总步长设置为32,如此大的网络步长会导致最后一层输出的特征图很小且空间分辨率较低,不能够精准地定位目标。这与本文跟踪任务旨在快速且精确地定位目标位置相违背,因此为分类问题而设计的MobileNetV1 并不适用于跟踪任务。网络总步长决定了最后的输出特征图的大小,太大的特征图对目标的空间位置不敏感,太小的特征图对物体的结构信息不敏感。为了保证最后的输出特征图在合理的范围内,本文将原有的网络进行调整,控制网络的总步长为8,模板分支输出大小为7×7×256,搜索分支输出大小为23×23×256,得分响应图的大小为17×17×1。主干网络细节如表2 所示。表中Crop代表特征图裁剪,Dw Conv 代表深度卷积,Pw Conv代表点卷积。
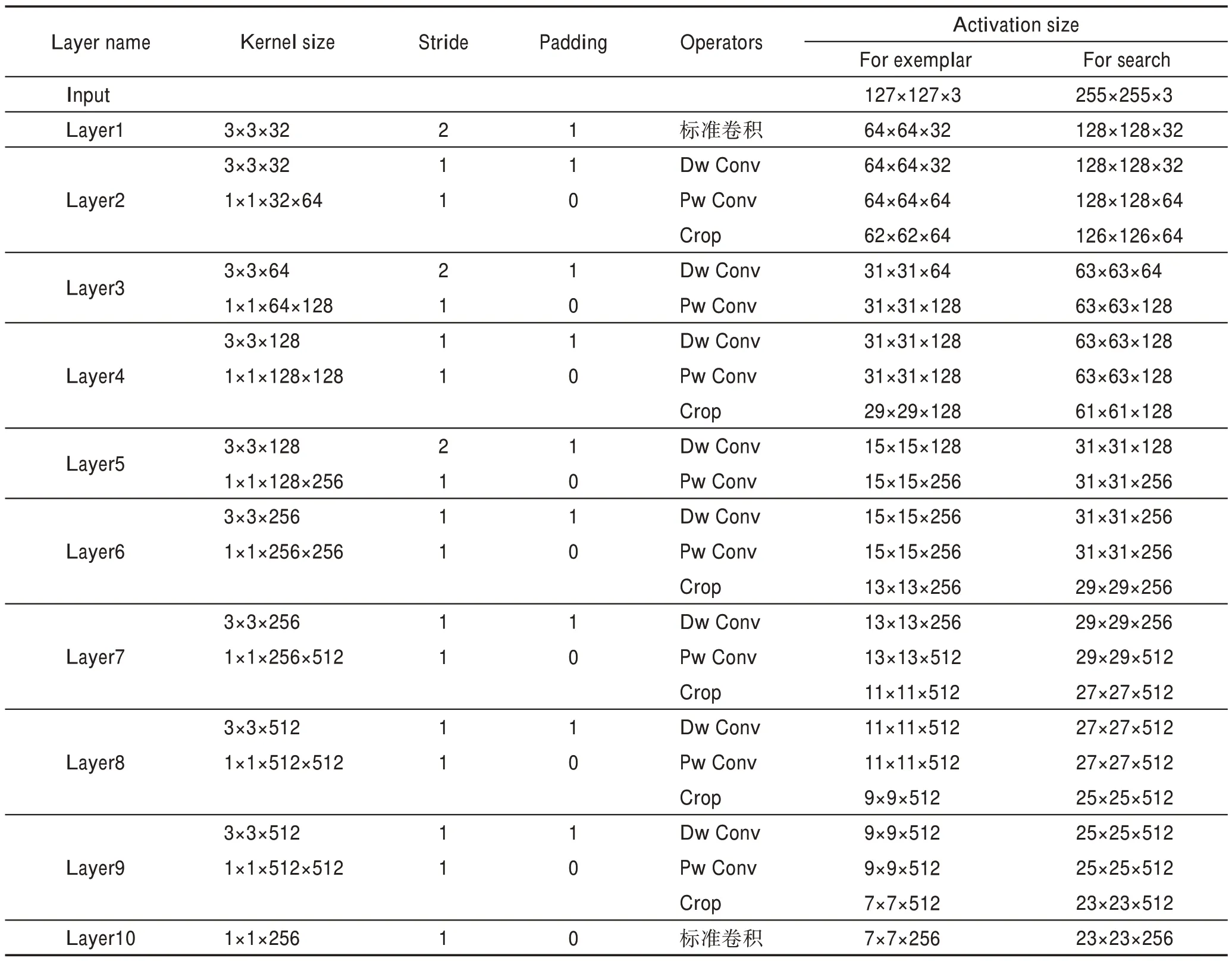
表2 基于MobileNetV1 的孪生网络结构Table 2 Architecture of siamese network based on MobileNetV1
1.4 融合通道注意力机制
基于孪生网络的跟踪算法采取离线训练、在线跟踪的模式,不同于相关滤波算法的在线训练。这就要求网络能够对目标的细节有所提炼,对不同目标的差异表现敏感。然而在互相关计算的过程中,不同通道和不同位置对于相似度计算的贡献是平均的,限制了网络的特征提取能力和对相似目标的判别能力。
为了对跟踪目标特征图中不同通道的重要性进行突出,同时可以更好地利用输入至网络的图片对的背景信息,例如噪声大的背景可能导致跟踪器的漂移。本文通过引入通道注意力模块对目标的重要信息进行加权突出,不相关或无效的信息减小权重进行抑制,提高网络对目标的重要特征的表达能力。通道注意力在改善卷积神经网络性能方面具有巨大潜力,大多数现有的方法如SE(squeeze and excitation)模块、CBAM(convolutional block attention module)模块等致力于开发更复杂的注意力模块以获得更好的性能,不可避免地增加了计算负担。
受ECA-Net 启发,为了契合主干网络选取的轻量级神经网络,本文选取超轻量级的注意力模块,嵌入至搜索分支后,消融实验表明算法的性能有了显著提升。
不同于SE 模块通过全连接层建立一个通道与其他所有通道复杂关系导致模型的超高复杂度和计算量,本文通道间的交互则注重单个通道与相邻通道的交互上,计算量大幅减少。通道注意力模块如图5所示,首先将搜索分支提取的特征全局平均池化,然后在相邻通道之间进行一维卷积,之后由一个Sigmoid 函数来计算出每个通道的权重w。将权重与原特征逐层相乘后再与原特征相加得到一个与原特征尺寸完全相同,但是对目标特征表达能力更强的新特征′。新特征的各个层可由式(9)表述。
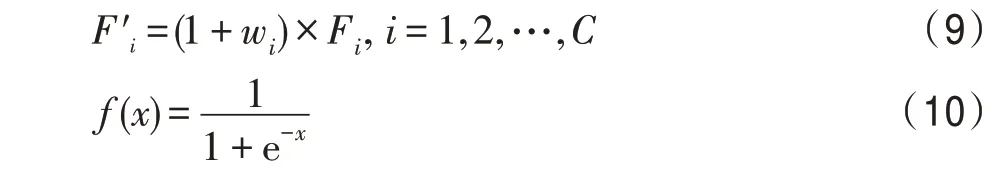
图5 中GAP 代表全局平均池化,代表激活函数由式(10)表述,代表经过一维卷积后1×1×的特征。
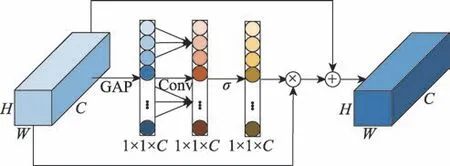
图5 通道注意力模块Fig.5 Channel attention module
2 实验与分析
2.1 实验平台与参数配置
本文算法实验平台配置:CPU 为IntelCorei5-8500,基础频率3.00 GHz,内存16 GB,GPU 为NVIDIA GTX1080Ti,显存11 GB。
训练集选用Got-10K,包含10 000 个视频序列以及150 万个标注的轴对齐的边界框。训练过程中使用MobileNetV1 预训练模型初始化卷积层参数,采用随机梯度下降,训练时的学习率从指数10衰减至10,mini-batches 设置为8,整个训练共经历50 个阶段,本文互相关操作的偏置为0。通道注意力模块中一维卷积的卷积核大小为3,填充为1。
逻辑损失定义为式(11),表示得分图中每个候选位置的得分,其中代表模板图片和搜索图片组成的图片对的相似度得分,∈{+1,-1}代表真值标签。

不同的候选位置有着不同的得分,所有的候选位置构成总得分响应图,代表得分响应图的所有位置。训练时采用所有候选位置的平均逻辑损失来表示损失函数,由式(12)表示。图6 给出训练阶段损失函数的收敛曲线。
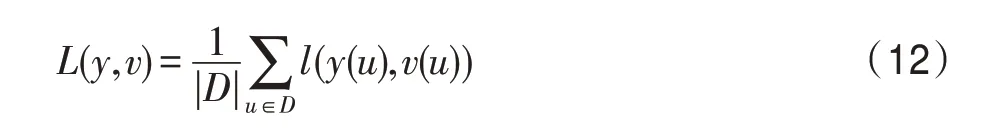
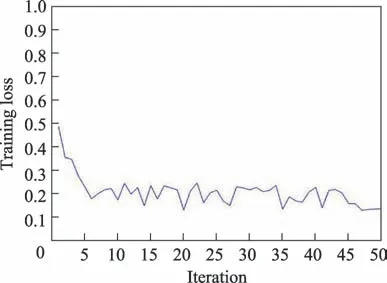
图6 损失函数收敛曲线Fig.6 Loss function convergence curve
2.2 基于OTB2015 的实验
OTB2015 是一种被广泛使用的跟踪数据集,包含100 个完全注释的序列,其中包含26 个灰色序列,76 个彩色序列,不同序列有着不同属性的11 个跟踪挑战。其使用Prec 和AUC 得分作为主要的两种评价指标。前者指标是中心位置偏差,是跟踪框的中心位置和真值之间的欧式距离;后者指标是跟踪框与真值之间的交叠比。两个指标通过设定一定的阈值对跟踪结果进行判定。
为对比分析,本文挑选四个基于孪生网络的算法,使用轻量级网络的SiamSqueeze、SiamTri、Siam-FC、CFNet,三个基于相关滤波的方法SRDCF、Staple、fDSST,包括本文算法共计8 个跟踪器,在OTB2015 数据集表现如表3、图7 所示。本文算法在Prec.和AUC 两项指标上均达到最佳水平,并且在GPU 上运行速度高达120 frame/s。相比于基准算法SiamFC,Prec 提升了5.4%,AUC 提升了4.8%,速度提升了39.5%。
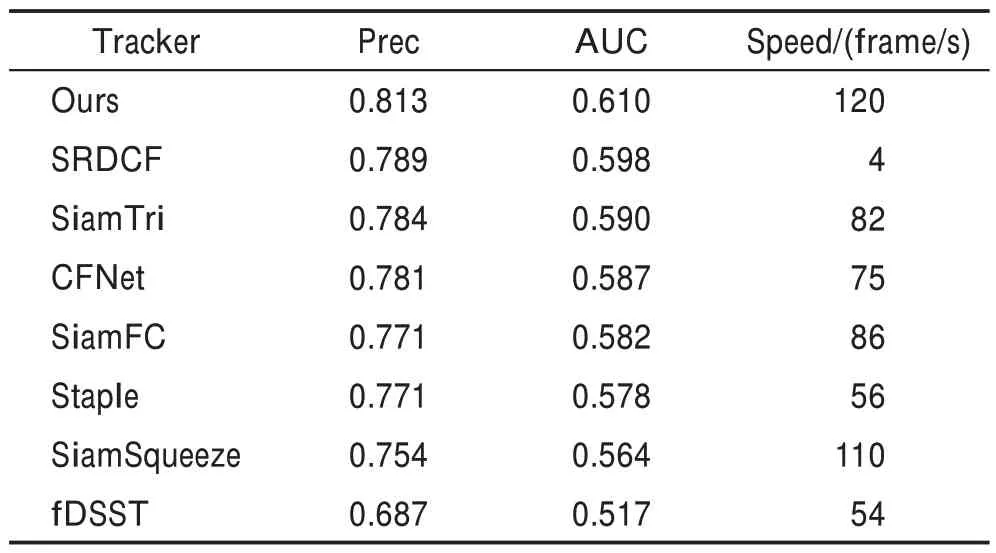
表3 各跟踪器在OTB2015 上的性能对比Table 3 Performance comparison of each tracker on OTB2015
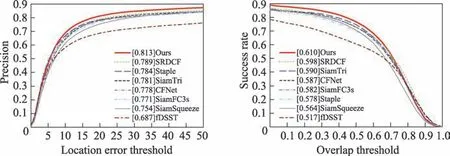
图7 OTB2015 上的精度-成功率对比实验结果Fig.7 Precision-success rate comparison experiment results on OTB2015
与孪生网络类方法相比,本文算法的跟踪成功率和精度较高的原因在于,本文使用的网络更深层,提取出的特征对目标的语义表达能力更强,经过优化策略后的网络更适用于跟踪任务。通道注意力机制的引入使得模板分支提炼的特征充分利用了待跟踪目标以及目标背景的信息,对于目标的光照变化和尺度变化具有一定的鲁棒性。
与相关滤波类方法相比,除去跟踪精度和成功率的大幅增长,跟踪速度有了显著的提升,本文算法的速度比Staple 和fDSST 提升了一倍多。相较于SRDCF,其较好的精度和成功率得益于跟踪器的在线训练和实时更新,但是在线训练过程十分耗时,因此它的速度只有4.3 frame/s,远达不到实时跟踪需求。
本文算法高精度的跟踪效果归功于选用更深层的卷积神经网络进行特征提取,并且对主干网络进行了优化。在高精度的同时保持高速运行则是因为选取的轻量级网络和轻量型注意力模块,大幅减少算法的参数量。
为了与其他跟踪算法进行全面对比,本文使用OTB2015 数据集上的11 个带注释的属性评估各跟踪器。这11 个跟踪难点分别是:(a)快速运动、(b)背景相似目标遮挡、(c)运动模糊、(d)形变、(e)光照变化、(f)平面内旋转、(g)低分辨率、(h)遮挡、(i)平面外旋转、(j)视野内消失、(k)尺度变化。图8、图9 给出各个跟踪器在每个跟踪挑战对应序列上的Prec 和AUC指标。本文算法在8 个跟踪挑战上表现都位列第一,在背景杂乱、形变两个挑战上位列第二。遮挡挑战上位列第五。背景杂乱挑战序列中,本文算法的AUC 是0.580,第一的SRDCF 是0.583。形变挑战序列中,本文算法的AUC是0.548,第一的Staple是0.550,相差十分小。遮挡挑战序列中,本文算法0.540,相较第一的0.559 有一定的差距。
在除去遮挡挑战的10 个跟踪挑战的序列中选择4 个具有代表性的序列,依次是Biker、Couple、Dragon-Baby、ironman,来评估跟踪器在实际跟踪中的性能表现,跟踪效果如图10 所示。在4 个序列中,本文算法表现良好。
对于Biker 测试序列的跟踪,其难点在于低分辨率、快速运动。在前65 帧,骑行者缓速前进正对着摄像头时,各跟踪器均能准确跟踪,在第21 帧目标快速运动至空中,除了本文算法,SiamTri 和SiamSqueeze准确地跟踪到目标,其他跟踪器全部丢失。但是SiamTri 和SiamSqueeze 有着一定程度的偏移,本文算法准确地定位目标,分析可知引入特征图裁剪操作消除了填充对跟踪精度的影响。相对于SiamFC,得益于通道注意力机制的引入,使得特征对目标的重要特征的语义表达能力更强。
对于Couple 测试序列的跟踪,其难点在于背景杂乱以及目标形变,基于孪生网络类的算法表现都优于基于相关滤波类算法。
对于DragonBaby 测试序列的跟踪,其难点在于平面外旋转、平面内旋转、运动模糊。序列中的小男孩旋转两次,并且快速运动导致形状模糊。相对于基准算法,SiamFC 在第一次旋转过后第70 帧就丢失目标,而本文算法在两次旋转后都准确地定位到目标。深层网络提取到的特征相较于浅层网络更具有对目标特征的表达能力。
对于ironman 测试序列的跟踪,其难点在于光照变化、形变。序列中的光照变化十分剧烈,在第94帧,场景亮度变低,准确定位到目标的有本文算法、SiamTri 和SiamSqueeze,但是到第166 帧时,亮度再次变高以及目标的剧烈形变,只有本文算法准确定位到目标,证明本文算法的良好性能。
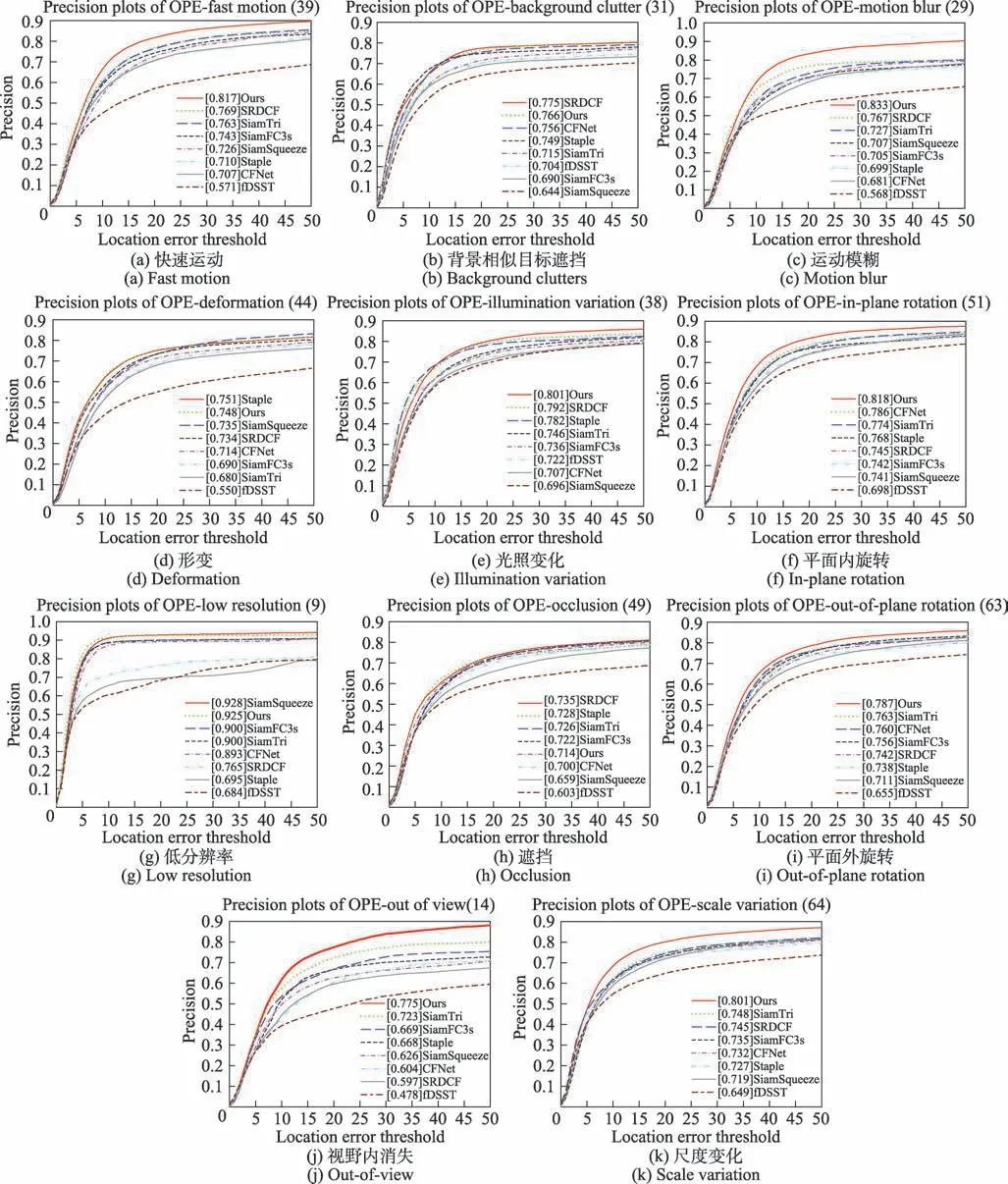
图8 OTB2015 各挑战属性的跟踪精度对比结果Fig.8 Attribute-based precision comparison results on OTB2015
针对表现较差的遮挡挑战,选择遮挡挑战序列中的Bird1,该序列是一群鸟儿飞行,然后穿越云层,之后再次出现,如图11 所给出的三个阶段。在一开始鸟儿正常飞行的时候各跟踪器均能准确跟踪鸟儿的飞行,在第165 帧鸟儿飞进云层里,目标完全丢失,第286 帧飞出云层。分析第286 帧发现只有在线更新模型的Staple 勉强跟踪到鸟儿的边缘,其他相关滤波类算法直接跟丢。基于孪生网络类的跟踪器CFNet、SiamFC、SiamTri、SiamSqueeze 以及本文算法,其中SiamFC、SiamTri 跟丢目标,本文算法和CFNet 漂移到鸟儿的翅膀或者其他鸟儿身上,这则表明基于相似性度量的跟踪算法在面对同类不同个体及相似物上跟踪效果不是很好。
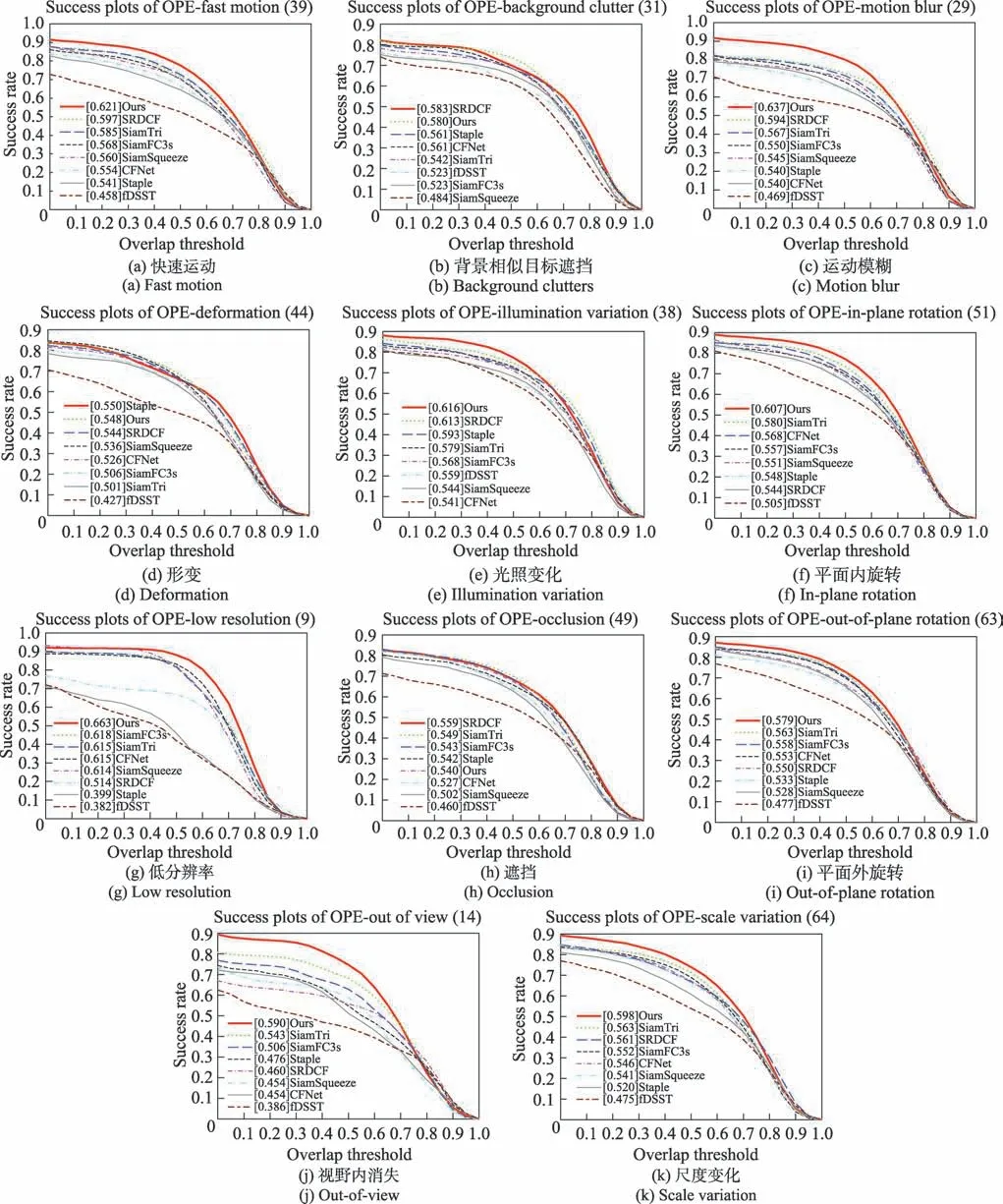
图9 OTB2015 各挑战属性的跟踪成功率对比结果Fig.9 Attribute-based success rate comparison results on OTB2015

图10 OTB2015 上跟踪结果对比Fig.10 Comparison of tracking results on OTB2015

图11 Bird1 序列上跟踪结果对比Fig.11 Comparison of tracking results on Bird1 sequence
基于OTB2015 的实验表明,除去遮挡挑战序列表现相对一般,本文算法在其余10 个挑战上都有着良好的表现。
2.3 基于VOT2018 的实验
为了进一步测试本文算法的通用性,在VOT2018数据集上进行了实验。VOT2018 是更具挑战性的数据集,其包含60 个彩色序列,每个序列的真值由旋转的回归框标记。该测试集的评价指标包含:精度(A),指跟踪器在单个序列下的平均重叠率;鲁棒性(R),指单个测试序列下的失败次数,当重叠率为0 时视为失败;以及最重要的评价指标EAO,是结合了精度和鲁棒性的综合,EAO 指跟踪器在一个短时图像序列上的非重置重叠的期望值。
为了对比分析,挑选了6 个跟踪器,分别是UNet-SiamFC、DSiam、DCFNet、DensSiam、Staple以及本文的基础算法SiamFC。表4 列出了各跟踪器在VOT2018 基准测试的实验结果。在EAO 指标方面,本文算法0.238 最优,相比于基础算法SiamFC 的平均重叠期望是0.188,提升了26.6%。对比Staple 算法,虽然它的精度比本文高0.09,但是在平均重叠期望表现不如本文算法,本文算法优于Staple 40.8%,鲁棒性0.520 相比0.688 低很多,即失败次数少,鲁棒性也相对优秀。图12 给出在butterfly 序列上,本文算法结果与真值的对比。在蝴蝶飞舞过程中,剧烈形变,本文算法能够准确跟踪到目标。
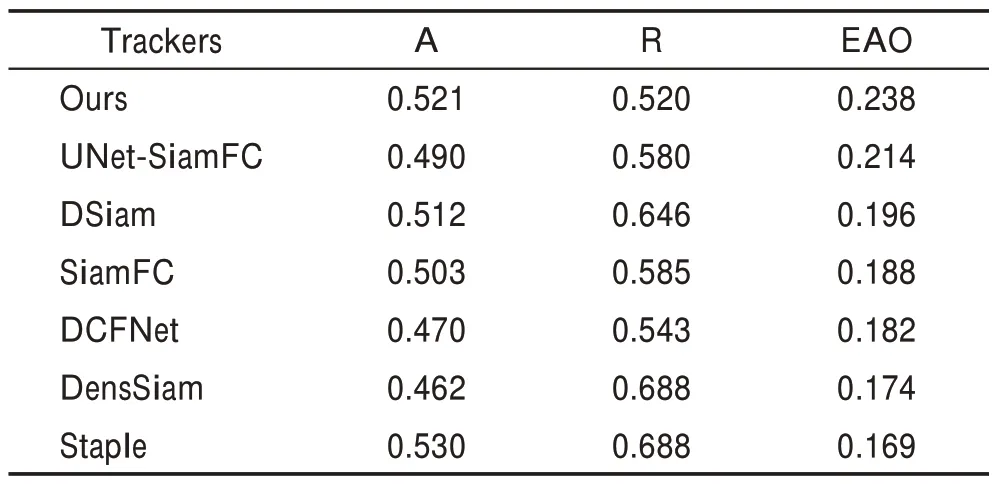
表4 各跟踪器在VOT2018 上的性能对比Table 4 Performance comparison of each tracker on VOT2018

图12 Butterfly 序列上跟踪结果对比Fig.12 Comparison of tracking results on butterfly sequence
2.4 算法有效性分析
为证实本文改进策略的有效性,在OTB2015 上进行了五组对照实验。如表5 所示,SiamFC 是本文的基准算法,实验1 代表基准算法加上通道注意力模块,实验2 代表原MobileNetV1 直接应用至目标跟踪任务中,实验3 代表主干网络换成增加了特征图裁剪和网络总步长调整两个优化策略改进过的Mobile-NetV1,实验4 代表在实验3 的基础上增加通道注意力机制后的算法,即本文提出的总体算法。
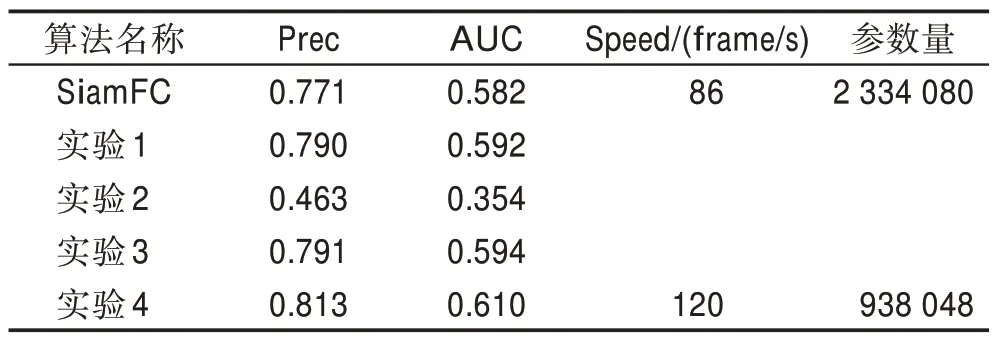
表5 本文方法与基准算法在OTB2015 上的消融实验Table 5 Ablation experiment of proposed algorithm and benchmark algorithms on OTB2015
分析实验1,在基准算法的基础上在模板分支最后添加通道注意力模块,基准算法的跟踪成功率从0.582 提升至0.592,验证了通道注意力模块的引入可以提升算法的跟踪精度。
分析实验2,直接使用原MobileNetV1 至目标跟踪任务中,其AUC 只有0.354,证明其不适用于跟踪任务。对比分析SiamFC 和实验3,AUC 从0.582 提升至0.594,表明经过特征图裁剪和网络总步长调整后的算法有了一定的提升。对比实验3 和实验4,通道注意力机制的加入,算法的两项指标都有了提升,证明加入通道注意力机制增强了模板分支对目标特征的表达能力。如图13 所示,绘制通道注意力机制引入前后的输出响应,分析可得通道注意力机制的引入确实增强了部分通道的响应,也抑制了部分通道的响应。最后对比SiamFC 和实验4,经过本文提出的优化策略后,Prec 提升了5.4%,AUC 提升了4.8%,在精度提升的同时算法平均速度高达120 frame/s,速度提升了39.5%,参数量减少了59.8%。
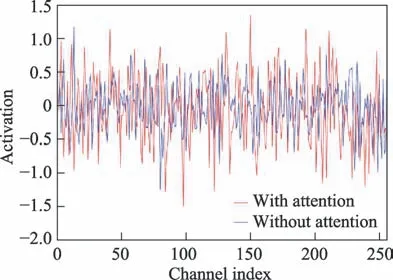
图13 有无注意力机制的每个通道的响应Fig.13 Activation of each channel with attention mechanism or not
3 结论
本文提出了一种轻量级网络MobileNetV1 作为特征提取主干网络,提出两点针对主干网络的优化策略,融合超轻量级通道注意力机制的端到端的跟踪算法。在OTB2015 和VOT2018 测试集上做了大量的实验,证明了算法的良好效果。在OTB2015 测试集上的实验表明,本文算法成功率0.610,跟踪精度达到0.813。在VOT2018 的EAO 可达0.238,且在较好的跟踪精度下,在NVIDIA 1080Ti下的平均跟踪速度可达120 frame/s。在保持良好的跟踪性能同时,超小的参数量在移动端或嵌入式设备的应用场景下相较其他主流算法具有很大的优势。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
太阳能(2022年3期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
甘肃教育(2020年22期)2020-04-13
太阳能(2020年3期)2020-04-08
电子制作(2019年11期)2019-07-04
当代工人·精品C(2019年2期)2019-05-10
北京航空航天大学学报(2018年1期)2018-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
