
面向多表连接查询优化的基数估计方法
2022-06-16 05:24钱文渊荆一楠王晓阳吴振环
计算机工程 2022年6期
钱文渊,荆一楠,王晓阳,吴振环
(1.复旦大学 计算机科学技术学院,上海 200433;2.司法部 信息中心,北京 100020)
0 概述
查询优化是许多关系型数据库管理系统以及其他数据库(如图数据库)领域的一个重要课题[1-3]。查询是用户对数据库信息发起的请求,可以是简单快速的查询,也可以是复杂耗时的查询。查询结果是通过访问相关数据库数据并对其进行操作从而产生的用户所需要的信息。由于数据库结构复杂,对于复杂的查询,其执行时间可能根据处理查询方式的不同而存在较大的差异,从几分之一秒到几小时不等。查询优化是一个自动化的过程,其目的是找到通过最少时间来处理给定查询的方式。不同的查询处理策略对应不同的执行时间,为提高查询效率,进行查询优化具有一定的现实意义[4-6]。
在众多数据库查询操作中,连接(JOIN)操作最为费时,其往往涉及多个表之间大量的数据读取,因此,许多查询优化是针对JOIN 展开的[7-8]。基数估计是对数据表统计信息进行估计,并将其用于后续优化步骤。对原始数据进行基数估计在大多情况下比较费时,而在样本数据上做基数估计,对查询涉及的数据本身进行抽样,使得原本在大规模数据上进行的基数估计计算变为在较小但足够精确的样本数据上进行基数估计,并通过样本数据上的基数估计结果近似估计出原数据集上的基数,从而大幅减少计算时间。
近年来,许多在单表上的抽样算法相继被提出[9-11],同时,学者们也对一些评估抽样结果优劣的方法与标准进行了研究[9,12],这些工作大都聚焦在单表数据分布或是与其他表的主外键关系上,针对每一个单表进行最佳抽样率计算[13-14]。但是,假设数据库含有多个数据表,且对于众多数据表的样本临时数据表存在存储限制,即不能对每个数据表做过多抽样,样本总容量有预算上限,那么如何分配每个数据表的抽样大小就成为一个需要解决的问题。此时,需要找到一个合理的样本分配方案,使得在此样本数据上做基数估计的准确率能够在一定标准下以及一定误差范围内尽可能达到最高。
将多个表的抽样率整体看作一个待分配比例的组合,寻找一个最佳抽样率的分配就成了一个连续空间搜索问题,此时擅长连续空间搜索的贝叶斯优化算法可以发挥优势。本文将贝叶斯优化算法应用到数据库抽样中,提出一种面向多表JOIN 查询优化的基数估计方法。在多表关系型数据库对样本临时表有整体存储限制时,利用贝叶斯优化算法可以快速搜索出不同表之间抽样样本大小的分配比例,且抽样结果可以达到最优,从而实现查询优化的目的。具体地,如果有一组查询负载涉及多个表之间的JOIN 操作,需要将这组查询涉及的所有表进行一定比例的抽样,但抽样样本的总体大小受到限制。此时,将每个表的抽样比例看作一个参数,则整个数据库中所有表的抽样比例形成一个参数组合,所有不超过样本总大小限制的参数组合总体构成参数空间。在一个参数组合对应的抽样方案下,参考文献[12]进行二层抽样做基数估计,得到一个多表整体基数估计准确率。利用贝叶斯优化[15]快速地在参数空间搜索对应基数估计准确率最高的参数组合,即在抽样样本总大小受限的条件下,利用贝叶斯优化算法快速确定对应基数估计准确率最高的多表抽样比例分配方案。
1 问题定义
1.1 多表JOIN 查询优化
在关系型数据库中,最耗时的一类查询往往涉及许多JOIN 操作。不同表之间不同类型(如BroadcastHashJoin、SortMergeJoin)、不同顺序的JOIN 往往数据量大不相同,操作代价也存在很大差异。因此,合理地执行计划(如合理的JOIN 类型、合理的JOIN 顺序)能够大幅优化查询过程,提高查询效率。在查询计划优化器中有一类基于代价的优化器,其根据数据库中数据表上数据统计和代价模型的代价进行估计,计算不同执行计划对应的代价,从而选择最小代价的计划来执行。因此,数据统计结果的精确度会影响基于代价的优化器对执行计划的选择,从而影响查询优化结果。多表JOIN 查询优化表示当查询语句中的JOIN 操作涉及3 张以上的数据表时,数据库管理系统或数据库优化工具根据数据统计信息对JOIN 顺序、JOIN 方式进行合理规划,从而达到缩减查询开销的目标。
1.2 基数估计
本文主要关注基于代价的优化器中的数据统计部分,这一部分通常称作基数估计,其通过数据统计和对数据分布、列的相关性以及连接关系的一些假设,来得到一些中间操作的元组条目数,这些数字会用于代价模型以决定查询计划。理论上讲,只要基数估计准确、后续代价模型估计准确,优化器就能在有限时间内获得全局最优的查询执行计划。
在数据库查询场景下,基数估计指的是对一个操作符产生的结果元组条目数进行估计,这个估计的条目数会用于代价模型预测这一个操作符的操作代价开销,根据操作代价开销的不同,对查询作出不同的物理执行计划,从而达到查询优化的目的。文献[15]指出,在现有的代价模型下,微小的基数估计误差可能会带来最多30% 的代价预测误差。文献[16]对多表JOIN 复杂查询下传统查询优化器的物理执行计划进行研究,其得到了与文献[15]类似的结论。因此,基数估计结果的准确率会严重影响查询优化的效果。
在数据库查询中,最费时的一类查询往往涉及多个JOIN 操作,因此,本文主要关注这一类涉及多表JOIN 的查询优化中所需进行的基数估计。多表JOIN 涉及多张表之间多个列上的基数估计。在实际的数据库优化中,基数估计包括复杂的计算,本文将对基数估计的计算过程进行简化。基数估计的关键步骤是计算结果表中元组的分类计数,本文将基数估计过程转化为一个GROUP BY+COUNT 的查询,以一组特殊设计的查询语句来近似替代单表基数估计进行计算。
定义1(多表基数估计近似查询)对于一个给定的涉及JOIN 的查询(如RJOINP),记这个JOIN 结果为J,令S为J的一个列组合(如{R.a1},{R.a1,P.b2}等),S在一种特殊情况下为空,即S=∅,则对于如下查询结果的估计即为对涉及JOIN 查询的多表基数估计:
SELECTS,COUNT(*)
FROMJ
GROUP BYS
对查询结果的估计,包括了结果条目数的估计以及每一条结果中对COUNT(*)结果的估计。需要注意的是,单表基数估计近似查询是JOIN 查询基数估计近似查询的一个特例。因此,本文讨论涉及JOIN 查询的多表基数估计近似查询。
1.3 基于抽样的多表JOIN 查询基数估计
图1 所示为基于抽样并面向多表JOIN 查询的基数估计问题定义。上文定义的面向多表JOIN 查询的基数估计由于要计算连接后的结果表元组条目数,因此当原始数据表规模很大时计算量巨大。为解决该问题,常用的一个策略是对原始数据表进行一定比例的抽样,在抽样数据表上进行基数估计近似查询,然后根据抽样比例再估算原始数据表上做多表JOIN 查询的基数估计结果。对于多表JOIN 查询,各表上不同的抽样比例会导致JOIN 查询在抽样表上做出的基数估计结果准确率不同。因此,对于一组确定的多表JOIN 查询,本文目标是确定一组使得基数估计准确率最高的抽样方案。
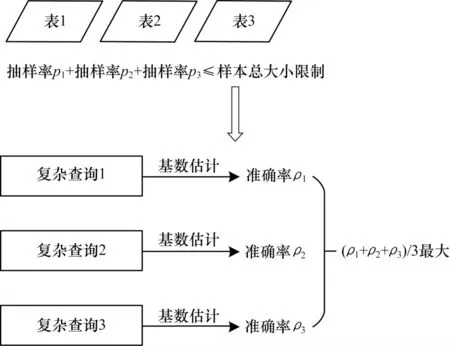
图1 基于抽样的多表JOIN 查询基数估计问题Fig.1 Cardinality estimation problem of multitable JOIN query based on sampling
当限定一个数据库中可以额外存储临时表的空间,即限制数据表可产生的抽样样本表的样本空间时,则必须将有限的样本空间分配给数据库中的每一张需要抽样的数据表,使得每张数据表以一定的抽样率进行样本抽样且样本总和不超过限制的空间大小。在这个空间有限制的总体样本上,本文针对给定的查询负载做基数估计。本文目标是在给定样本空间限制的条件下,找到一种样本抽样在不同数据表上的分配方案,使得查询负载在样本上做出的基数估计准确率最高,即数据库中所有数据表的样本基数估计结果准确率的平均值最大。
2 贝叶斯优化与二层抽样
2.1 贝叶斯优化
贝叶斯优化的目标是一个计算代价昂贵的黑盒函数f[17-19],f的具体函数形式不得而知,但对于一个特定的自变量输入值x,其对应的函数值f(x)是可以获取的。虽然f(x)的值可以获取,但是计算时间会很长,因此,要求得函数f在定义域X上的最大值或最小值,就不能进行穷尽枚举[17]。贝叶斯优化可以在有限步的尝试内,近似搜索到函数f的最大值或最小值,从而大幅缩短函数优化时间[20]。
贝叶斯优化算法是一个迭代执行的过程,x它在每一步迭代时选取一个函数的合法输入值x∈X并评估y=f(x)。在算法的初始阶段,需要随机选取几个输入值x。在迭代过程中,假设函数的一个输入和输出的键值对序列已经在之前的t−1 轮迭代中被选中并评估过,记已评测过的采样点集合为Dt-1=。贝叶斯优化在迭代时使用一个采集函数(acq)来挑选xt,从而近似估计xbest并交由高斯过程(GP)[18,21]去拟合待优化的函数,那么xt和相应的输出(即模型性能)yt=f(xt)将被加到已评测过的采样点集合Dt=Dt-1∪{(xt,yt)}中。在实践中,这个过程不会停止,直到模型性能收敛,或者迭代过程已经执行了一个预设好且数值较大的最大迭代轮数T。
2.2 二层抽样
二层抽样是文献[12]在总结目前用于查询优化中数据表JOIN 结果基数估计的抽样方法后,提出的一种用以估计两表间查询JOIN 结果大小的抽样方法。该文分析了简单独立伯努利抽样(即随机抽样)、关联抽样、端偏抽样(End-biased sampling)的特点与弊端,在此基础上提出了二层抽样方法。
假设需要JOIN 的2 个表分别为A和B,且在列A.a和B.a上做条件JOIN,v为A.a或B.a上的某一 属性值,在A.a中的频数为av,在B.a中的频数为bv。KA和KB为2 个人工设定的系数,则令p(v)=,二层抽样的步骤如下:
1)第一层抽样。确定JOIN 的属性列,并利用一个哈希函数h将属性列上的属性值v映射到h(v)∈[0,1]的区间。若h(v)≤p(v),则属性v对应的表中元组将在第一层抽样中被全部抽取;反之,则不抽取。
2)第二层抽样。对于第一层抽样中抽取的属性值,以概率q进行均匀抽样,同时保证每一类属性值对应的元组中至少有一条被保留。
二层抽样方法考虑了原始数据的分布与连接关系,避免了需要JOIN 的两表间数据属性值匹配不均而带来的基数估计误差。二层抽样方法易于操作,仅需遍历一遍数据即可完成,且可以根据人工参数进行调整,使得在不同抽样样本量条件下样本尽可能地保留连接属性值。
3 算法实现
本文通过形式化的定义,将多表JOIN 查询基数估计问题转化为等价SQL 语句的近似查询问题。基于这一转化,本文提出一种面向多表JOIN 查询基数估计的最佳数据抽样方案搜索算法。
3.1 数据抽样与基数估计
假设有一组(若干条)JOIN 查询,需要对这若干条JOIN 查询都做出基数估计,本文将对若干条JOIN查询做出的基数估计问题称为基数估计查询负载(下文简称为负载)。在实际应用中,数据库中的数据表条目数通常达百万条之多,若是负载中的查询覆盖到数据库中所有的数据表,那么在原数据上做JOIN 查询会是一个数据量巨大的工作。为解决该问题,可以对原数据表进行合理地抽样,然后将负载在抽样后的样本上执行查询,依据结果做基数估计,并用样本上的基数估计来近似原数据表上的基数估计。由于执行的数据表经过了抽样,因此在抽样样本上原始负载的近似基数估计结果也有误差。在不同的抽样率下,基数估计结果也必然不同。因此,需要定义对于确定的负载在抽样样本上做基数统计的结果准确率,具体方法是将样本上做出的基数估计查询结果与实际原始数据上做出的基数估计查询结果进行比较并得出误差。
假设Creal是基数估计查询在真实数据集(未抽样前的原始数据集)上得出的结果表,Csample是基数估计查询在将语句中的数据表替换为样本数据表后在样本数据表上得出的结果表。有如下结论:
命题1对于∀s∈S,如果(s,r)出现在Csample中,则∃r′,使得(s,r′)出现在Creal中,且r′唯一;反之,不一定成立。
证明不妨设某一基数估计查询涉及2 张表R和P的JOIN:
J=RJOINjoinconditionP
那么JOIN 结果J可以用关系代数改写成如下形式:

对R和P分别进行抽样,得到样本数据表R′和P',那么Csample是在抽样样本结果表J′上做查询的结果:

因为R′和P′分别是数据表R和P的抽样结果,所以有:
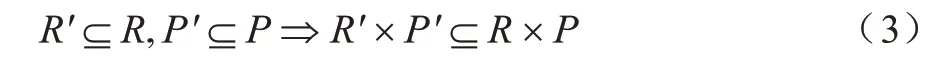
因为J和J′分别是对R×P和R′×P′在同一条件下的选择结果,所以根据式(1)、式(2)有:

则对于∀s在J′中,有如下结论:

由于基数估计查询结果是GROUP BY 后的COUNT(*)结果,因此s和r在结果集中一一对应,即:
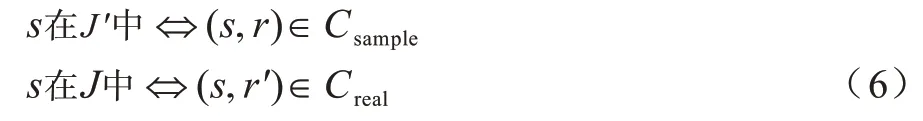
在式(6)中,r和r′是唯一的。由式(5)、式(6)得到:
∀s∈S,如果(s,r)∈Csample⇒
∃唯一的r′,使得(s,r′)∈Creal
上述是2 张表做JOIN 时的情形,同理,可以推广到任意数量的表JOIN 时的情形,即当一个JOIN操作是由R1,R2,…,Rk的JOIN 而成时,令,…,为抽样后的样本数据表,那么式(1)、式(2)可改写为如下形式:
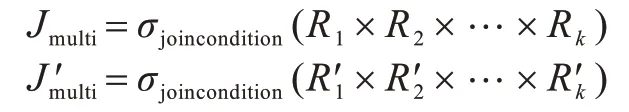
同理,Jmulti和之间的包含关系也如上可证,结论成立。
证毕。
由命题1 可知:∃(s,r0),使得(s,r0)∈Creal,而对∀r∈N+,均有(s,r)∉Csample。由于下文需要定义基数估计查询结果准确率,因此本文将Csample进行如下扩增以得到:对于使得(s,r0)∈Creal,而对∀r∈N+,均有(s,r)∉Csample,对这样的s,将(s,0)加入Csample中,最终获得,即:
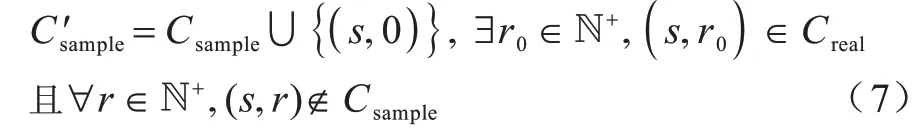
定义2(以样本进行基数估计的准确率)给定一个JOIN 基数估计查询,设原始基数估计查询在原数据表上的结果为Creal,将原数据表的每张表按抽样率p抽样后,在样本数据表上做基数估计查询的结果为Csample,将Csample按式(7)做扩增,得到。记Creal的条目数为|Creal|,则使用样本的基数估计准确率ρ定义为:
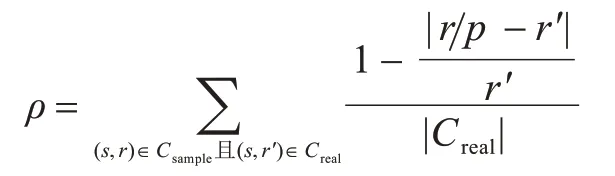
3.2 数据抽样的空间限制
2.1 节所提抽样方法都是在单表下讨论的,在真实场景中,查询往往包括JOIN 操作,这就涉及一个查询语句需要在2 张甚至多张数据表上进行查询计算,因此,需要对涉及的2 张甚至多张表都进行抽样,而这些表上的抽样肯定相关联,能够用以准确进行基数估计的样本结果不会是相互独立的。因此,对于某一个特定的查询问句,需要对其涉及的所有表都进行一次联合抽样,以实现最准确的基数估计。
定义3(数据表的最佳抽样率)设数据库中拥有n张数据表,记为R1,R2,…,Ri,…,Rn。设拥有若干条(m条)查询,记为Q1,Q2,…,Qj,…,Qm。假设在处理查询Qj的过程中需要对表Ri进行抽样率为pij的随机抽样,能够达到最准确的基数估计(即样本基数估计结果准确率ρ的值最大,注意,这里可能查询Qj并不涉及表Ri,在这种情况下pij=0),那么针对由m条查询构成的查询集合,表Ri的最佳抽样率为:
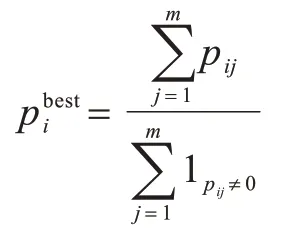
通过定义3 可以得知,假设在随机抽样策略下要达到最准确的基数估计,则整个数据库所有数据表的抽样样本存储大小之和为Hbest,如果数据库本身已经存储了大量数据,所剩存储空间不多,已经不足以存放Hbest大小的抽样样本,就出现了问题。由于整体可产生的抽样样本所占存储空间受到限制,那么针对特定的查询集合,势必无法使得每张表的样本都进行最准确的基数估计,即本文所讨论的情况是在H≤Hbudget 定义4(数据库的整体样本基数估计结果准确率)设数据库中有n张表R1,R2,…,Rn,每张表的抽样率为pi,并且在给定的抽样率条件下,针对给定的查询负载,其样本基数估计结果准确率分别为ρ1,ρ2,…,ρn,则数据库的样本基数估计准确率ρdb定义为: 由定义4 可知,当给定一组抽样率p1,p2,…,pn且满足H=≤Hbudget(Hbudget事先给定)时,可以得到给定查询负载下整体基数估计结果准确率ρdb,误差率为1-ρdb。 由定义3 可知,当查询负载和抽样样本给定时,数据表的样本基数估计结果准确率容易计算。因此,如果将一组在限定空间大小之内的数据表样本抽样分配方案作为自变量,将此时对于给定的查询负载在样本上的整体基数估计准确率作为应变量,在这2 个变量间建立映射关系,那么上述寻找最佳样本抽样分配方案的问题,就可转化为函数最优化搜索问题,则可以引入贝叶斯优化算法进行解决。本文在给定样本总空间大小条件下,将数据库中所有数据表合法的抽样样本组合(即样本总和不超过给定大小的上限)组成整个自变量搜索空间,空间中每一个自变量对应一种合法样本组合(设数据库中有n张表),然后通过贝叶斯优化算法在搜索空间中搜索,以给定查询负载下数据库样本基数估计结果准确率ρdb作为目标函数值,从而优化这一映射关系函数,最终搜索出最高的数据库样本基数估计结果准确率,以及使得数据库样本基数估计结果准确率最高的样本组合,就可求出每张表对应的抽样率。为计算方便,本文将搜索空间适当修改,将合法的样本组合一一对应成合法的抽样率组合,即贝叶斯优化算法需要搜索的搜索空间变为由所有合法的抽样率组合X=(p1,p2,…,pn)(设数据库中有n张表)构成的空间。具体算法描述如算法1所示。 在上述贝叶斯优化搜索的每一步,当假设了每张数据表的抽样率之后,采用二层抽样方法来抽取样本以用于最终的基数估计。在每一轮迭代中,在贝叶斯优化算法推荐的抽样比例下做二层抽样以估算基数估计结果,并按式(8)计算基数估计准确率,将其与历史最优记录进行比较,若该抽样比例方案下基数估计准确率有所提高,则更新历史最优记录。整体算法流程如图2 所示。 图2 面向多表JOIN 查询优化的基数估计方法流程Fig.2 Procedure of cardinality estimation method for multitable JOIN query optimization 原始贝叶斯优化算法在一次迭代中用高斯过程搜索黑盒函数最值点的时间复杂度为Ο(n2),其中,n为观测点数目[22-23]。而在一次迭代中,本文优化算法除了利用高斯过程计算一组推荐抽样率方案之外,还需要根据计算出的抽样率方案对查询负载中的m条多表JOIN 查询计算基数估计准确率,因此,一次迭代的总时间开销为Ο(n2+m)。根据贝叶斯优化算法的特点,算法在进行第n轮迭代时的观测点数目为n,因此,本文算法前n轮的总时间复杂度为Ο(n3+nm)。 在本次实验中,采用TPC-H生成了1 GB的数据集,并选取22 个官方查询模板查询语句中的12 个查询模板语句(这12 个模板均含有多表JOIN 查询,符合本文讨论的范畴),构建查询负载并进行优化。其中,问句均涉及2 张及2 张以上的表的JOIN,并且查询返回时以某一列或某几列做分组(GROUP BY)后的计数(COUNT)作为结果呈现。所有12 个查询问句共涉及数据库中的8 张数据表,以这种类型的查询问句来模拟数据库的查询优化器在分析用户真实查询问句后得出问句涉及具体哪些数据表(对应实验中查询问句的JOIN 部分),以及获取到下一步执行计划优化所需基数估计的列(对应实验中查询问句的GROUP BY 部分)。因此,实验中的查询负载事实上是模拟了真实场景中查询优化器分析需要做何种基数估计的这一步骤。 本文设定允许产生的样本总大小为原始数据大小的0.01%~5%不等,利用贝叶斯优化算法搜索20 步,记录搜索到的8 张表上的最佳抽样率组合以及对应的数据库抽样基数估计误差率的最小值。对于选定的抽样率,以随机抽样或二层抽样的方法重复10 次实验并取最佳结果,同样地,利用随机搜索算法搜索20 步,记录8 张表上的最佳抽样率组合以及对应的数据库抽样基数估计误差率的最小值。实验结果如图3 所示。 图3 各算法在不同抽样比例下的基数估计误差率Fig.3 Cardinality estimation error rate of each algorithm under different sampling proportion 分析图3 可知,对于各表在抽样大小受限条件下的最优抽样率分配方案,采用二层抽样方法总是优于随机抽样方法,而在相同的抽样样本比例限定下(如0.1%),采用贝叶斯优化算法确定的最优样本分配方案在有限步骤内(或有限时间内)总是要比随机搜索确定的最优样本分配方案对应基数估计的误差率要小。在抽样率比例上限为0.01%和5%条件下,采用贝叶斯优化算法得到的基数估计误差率比随机搜索算法得到的基数估计误差率分别降低60.2%和54.8%。 本文设计实验来证明贝叶斯优化算法在解决面向多表JOIN 查询优化基数估计问题上的高效性。通过TPC-H 产生1 GB 原始数据,并设置允许产生的各表样本总大小分别为原始数据的0.01%、0.05%、0.1%、0.5%和1%,分别使用随机搜索和贝叶斯优化算法来确定各表的最优抽样率比例分配方案,抽样方法均采用二层抽样,记录历史最低基数估计误差率,直到历史最低基数估计误差率在10 步迭代内降低不超过1%,则可认为搜索到的最优抽样率比例分配收敛,记录随机搜索和贝叶斯优化算法的收敛时间,每一种抽样比例下进行20 次实验取平均值,结果如图4 所示。 图4 不同抽样比例下搜索到最优抽样分配方案的收敛时间Fig.4 Convergence time of searching the optimal sampling allocation scheme under different sampling proportion 分析图4 可知,在不同的抽样数据规模下,利用贝叶斯优化算法搜索最优抽样分配方案时,收敛时间少于随机搜索算法。因此,贝叶斯优化算法在解决面向多表JOIN 查询优化的基数估计问题时具有高效性。 本文提出一种面向多表JOIN 查询优化的基数估计方法。对于一组给定的查询负载,需要在查询优化前对其进行基数估计,而对于庞大的原始数据,又需要在基数估计前进行样本总大小有限的多表联合抽样。本文利用贝叶斯优化算法快速搜索多张数据表之间可能的抽样样本比例分配组合,采用二层抽样方法在有限时间内确定多表联合抽样率分配方案,使得给定查询负载平均基数估计结果误差率最小,从而实现精准且快速的基数估计。实验结果表明,该方法能有效提升涉及多表JOIN 复杂查询的基数估计计算效率,且误差率相比随机搜索算法大幅降低,实现了查询优化的效果。下一步考虑将元学习、强化学习等算法应用于查询优化与基数估计任务中,结合传统基于数据统计的计算方法与基于强化学习的模型,以提高数据查询效率并提升数据库优化的整体水平。
3.3 贝叶斯优化与空间有限数据抽样

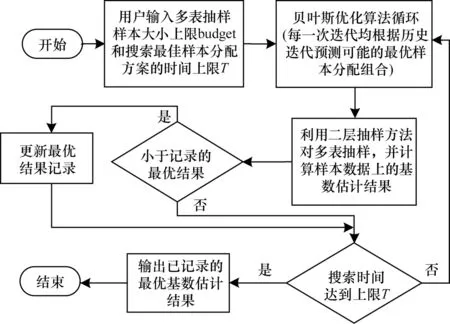
3.4 时间复杂度分析
4 实验评估
4.1 实验设置
4.2 误差率对比实验
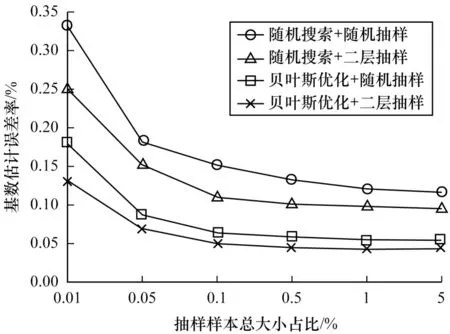
4.3 搜索效率对比实验
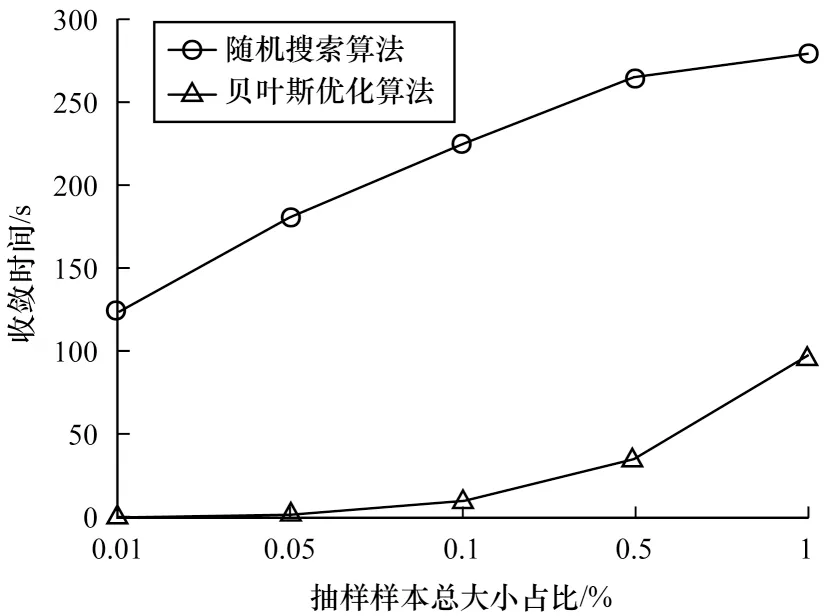
5 结束语
猜你喜欢
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
健康大视野(2020年1期)2020-03-02
无锡职业技术学院学报(2019年4期)2019-12-27
科技创新与应用(2019年26期)2019-10-24
文萃报·周五版(2019年13期)2019-09-10
小学生必读(中年级版)(2018年6期)2018-09-05
电脑知识与技术(2017年2期)2017-04-25
中小企业管理与科技·中旬刊(2016年6期)2016-06-20
