
Bayer 图像的无损压缩算法及其硬件实现
2022-06-15 09:06:36黄文俊李富勇魏锡彦
电子设计工程 2022年11期
黄文俊,元 辉,李富勇,魏锡彦
(1.创润量子科技(上海)有限公司,上海 201203;2.山东大学控制科学与工程学院,山东济南 250061;3.中国电信集团系统集成有限责任公司山东分公司,山东济南 250101;4.中国电信集团有限公司山东分公司,山东 济南 250101)
数码相机的成像端采用单片CMOS/CCD 器件采集成像信息。为降低成本,通常在镜头与传感器之间放置色彩滤波阵列(Color Filter Array,CFA),使得每一个成像单元仅需采集单一色彩信息。Bayer 格式[1-4]是目前应用最广的CFA 像素分布格式,相机成像前端通常将采集到的Bayer 格式图像插值为RGB彩色图像[5-6],之后进行各类处理,在该过程中数据量变为原来的3 倍。伴随着各类摄像机分辨率的不断提升,针对RGB 格式的图像信号处理(Image Signal Process,ISP)芯片所需的内存空间也愈加庞大。Bayer 图像的压缩将大大降低成像设备的成本。由于Bayer 图像的特性,主流的彩色静态图像无损编码方案如JPEG-LS[7-8]与JPEG2000[9]对其进行压缩的效果十分有限。
针对Bayer 图像的压缩,许多学者展开了较为深入的研究[10-12]。文献[10]提出了一种分层预测方法,利用不同分量之间的相关性相互预测,然后根据像素周围的梯度值和残差大小来估计预测残差的概率分布。文献[11]提出将Bayer 图像的各分量分别进行整数离散余弦变换,然后使用JPEG2000 对变换系数进行压缩,在有损压缩中取得了优良的性能。这些算法旨在提高压缩性能,复杂度较高。
考虑到Bayer 图像的生成与处理都由成像端硬件完成,过于复杂的算法会消耗更多硬件资源,同时也将降低系统在极端环境中的稳定性。该文针对Bayer 格式图像设计了一套适用于硬件实现的无损编码方法。在不使用变换和量化操作的前提下,设计图像分块预测和熵编码算法,使得Bayer 图像无损压缩性能接近于JPEG2000 标准的性能,并基于FPGA 进行实现和验证。
1 算法分析
1.1 编码结构概述
Bayer 图像的格式如图1 所示,其将红(R)、绿(G)、蓝(B)3 种色彩分量间隔排列,对G 分量采取了更高的采样频率。

图1 Bayer格式图像
Bayer 图像的无损编码方案主要包括4 种专门设计的预测模式和改进的自适应Huffman 编码算法,其结构如图2 所示。首先初始化残差符号的统计分布,存入频数表,根据此频数表对所有符号进行Huffman 编码,得到码字表;同时对输入的Bayer 图像进行分块预测,选出最佳预测模式,将其预测残差进行处理,得到待编码符号值,计算符号值的分布情况并以此更新符号分布表,与此同时以符号值作为索引从码字表中读取码字,至此完成一个图像块的编码。

图2 编码方案框架
1.2 图像分块策略
直接对整幅图像进行预测编码,一方面会造成系统资源浪费,另一方面也会造成预测误差的扩散,Bayer 图像被划分为若干个如图3 所示的M×M子图像块,以此作为编码单元。

图3 Bayer图像块
对于一幅图像,可以将其划分为三类区域:上边界区域、左边界区域以及中间区域。上边界区域为图像上边缘的所有图像块,左边界区域为图像左边缘除去与上边界重合的所有图像块,如图4 所示,每个区域的尺寸都是图像块的整数倍。
在图4 所示的图像块中,Pi,j(0 ≤i≤M-1,0 ≤j≤M-1)表示图像块第i行、j列的像素灰度值。P′i,j表示Pi,j的左邻近图像块中的同色度像素值,P″i,j表示Pi,j的上邻近图像块中的同色度像素值,i,j为Pi,j的预测值。考虑不同图像的纹理特性,该文采用32×32和16×16两种尺寸的分块策略,分别记为Size A与Size B。

图4 图像区域划分
1.3 预测模式
该文参考JPEG-LS 标准中使用的DPCM 预测模型,针对Bayer 图像的特征,提出4 种跨像素预测模式,如图5 所示,分别为垂直跨像素预测(模式0)、水平跨像素预测(模式1)、水平-垂直跨像素预测(模式2)、斜向跨像素预测(模式3),其中Xn为待预测像素,Pn为其预测值。

图5 4种跨像素预测模式
若像素位于图像块上边缘区域或者左边缘区域,需要参照与之相邻的图像块的同色度像素值来进行预测,预测方式如图5(b)所示;若像素位于图像块的中间区域,则可以利用当前块内与之相邻的同色度像素值来预测,预测方式如图5(a)所示。
4 种跨像素预测模式的具体执行方法如表1 所示。处于图像上边界和左边界区域的图像块,对其边缘处的像素的预测方式加以固定。当图像块位于图像的整幅图像的中间区域时,需要考虑当前像素是否位于图像块的边缘,然后使用正确的预测规则。

表1 图像各区域预测方式
对像素Pi,j进行预测的过程记为P(i,j),其预测残差为由于图像的结构和纹理特性,同一个图像块在不同预测模式下的预测准确度往往有很大差别,为了提高整体的预测准确性,需要根据实际预测结果选用一个最准确的预测模式。考虑到系统延时和资源消耗,该文采用真实值与预测值的绝对差和(Sum of Absolute Difference,SAD)来评判各种预测模式的准确度。SAD 越小,预测准确度越高。

为了使解码端获知每个图像块所采用的预测模式,在码流中需要额外增加2 bit 的头信息,用以记录预测模式。
1.4 自适应Huffman编码算法
Huffman 编码[13-14]作为一种可变长编码,能够根据信源中各符号出现的概率来分配码字长度。通过构建Huffman 树,给出现概率高的符号分配较短的码字。在离散无记忆信源条件下,其编码结果接近于信源熵。传统的Huffman 编码需要遍历编码信息以获取所有符号出现的概率,但是存储和传输这些符号的概率信息也将消耗大量资源。自适应Huffman 编码[15]可以在数据流的传输过程中动态地收集并更新各符号的概率信息,据此不断调整Huffman 树,更新各个符号的编码结果。该算法的缺点在于其时间复杂度的倍增,在数字图像信号的编码过程中,由于符号的分布范围较广,会使得该缺点愈加扩大。文中图像编码方案对自适应Huffman 编码算法进行改进,将Huffman 树的逐字符调整改为逐块调整,以降低图像编码时延。
预测残差ΔPi,j通常接近于0,大致服从拉普拉斯分布。为提高编码效率,将ΔPi,j按照式(2)进行处理,得到待编码符号Si,j(0 ≤S≤255)。

计算信源中各符号的概率会消耗大量乘法器资源,并且其结果为浮点型数据,在取值过程中的截断会造成准确度降低。因此使用各符号的统计频数替代概率,在编码过程中同样根据频数构建Huffman树。编码之前,按照式(3)设置各符号的初始频数,对Si,j的频数分布F(S)进行初始化:

式中,k为常数,可设置为1。
为保证解码端构造的Huffman 树与编码端完全一致,该文采用Canonical Huffman 编码算法[16]对S进行编码,其过程描述为:

式中,T(S) 为各符号的编码码字表,H(S,F(S))表示Canonical Huffman 编码过程。
Canonical Huffman 编码在经典Huffman 编码的基础上,对编解码双方增加了一些约束信息,其规定相同长度的码字是连续的,当有多个符号的编码长度相同时,其对应的码字的数值大小必须按照符号值的升序连续递增。同时,长度为i的码字C(i)可以根据长度为i-1 的码字计算获得:
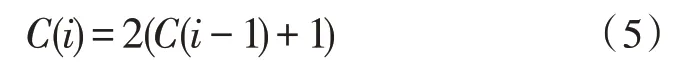
解码器在解码过程中依据各符号出现的频数计算其码字长度,然后按照Canonical Huffman 的编码约定信息可以准确地重建T(S),完成解码。在编码过程中,图像块总数为N,当前编码块的序号为n(0 ≤n<N),其中符号S的出现次数为f(S),编码输出结果为O(S),改进的自适应Huffman 编码算法的伪代码如下所示。


解码器在启动时同样按照式(3)初始化F(S),在解码的过程中逐块更新F(S),因此编码器无需向解码端传递额外信息。该方案改进了传统的自适应Huffman 编码,使用已编码图像的残差分布对当前图像块的预测残差进行编码。经过逐块迭代后,残差分布表将逐渐逼近完整图像预测残差的分布。
2 基于FPGA的硬件实现
2.1 顶层架构
该文使用Xilinx 公司的xc7z030 型FPGA 对所提出的无损编码方案进行实现与验证,该芯片最高工作频率为667 MHz,片上RAM 大小为256 kB。开发平台选用vivado 2018,编写verilog 语言以完成模块设计和仿真验证。系统的硬件结构如图6 所示。

图6 系统硬件结构图
编码方案的实现结构包括预测控制模块、图像预测模块、编码控制模块、Huffman 编码模块以及相关RAM 单元。图像存储ROM 为一个single port ROM 单元,使用20 bit 的地址总线以及8 bit 的数据总线,用于存储测试使用的Bayer 图像数据。预测控制模块负责从ROM 中读取数据,送入图像预测模块,并根据预测结果选用最佳预测模式;图像预测模块实现了该文提出的4 种预测模式,对预测残差进行处理同时并行输出。对于算法中所用到的符号频数表和符号码字表,采用片上的dual port RAM 进行存储。编码控制模块用于控制Huffman 编码模块的启动,同时从频数表存储RAM 中读取各符号的频数送入Huffman 编码模块,由后者完成编码,编码结果存入码字表存储RAM。在下一个图像块的编码周期中,以残差符号值为地址从码字表存储RAM 中读取码字,即作为该符号的编码输出结果。
2.2 图像预测模块
图像预测模块集成了4 种预测模式,每一种预测模式的结构如图7 所示。首先从预测控制模块中获取8 bit 的像素值P以及像素位置坐标,行坐标与列坐标各5 bit 宽度。根据位置坐标计算预测像素的位置,从而得到预测像素在RAM 中的地址Address[5:0],读取该值并按照表1 方法计算预测值P′。将P与P′差分即得预测残差ΔP,然后将ΔP进行处理得到待编码符号S,同时计算该模式下ΔP的SAD,将其送入预测控制模块。
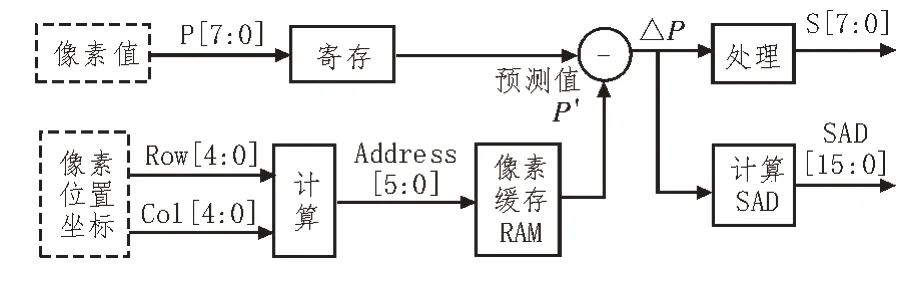
图7 预测模块结构
2.3 Huffman编码模块
Huffman 编码模块结构如图8 所示。

图8 Huffman编码模块结构
模块主要分为排序、构建二叉树、计算码字长度以及分配码字几个部分,实现了Canonical Huffman编码算法的流程。首先从符号频数表RAM 中获取各符号及其频数,对其进行排序,然后根据排序结果构建二叉树,频数越大的符号深度越小。遍历该二叉树,依次计算出所有符号的编码长度,然后依据约束信息为各符号分配码字,最后将其存入码字表RAM。该模块中对一些子流程同样采用了流水线结构和并行方式,提高了编码效率。
3 性能分析
该编码方案的硬件实现消耗资源其各类资源的消耗情况如表2 所示。

表2 系统资源消耗
其中使用查找表(Look Up Table,LUT)2 217 个,触发器(Flip Flop,FF)1 008 个,二者的等效门数约为3 万个;使用块RAM(Block RAM,BRAM)单元1.50个,消耗内存约54 kB。资源消耗远低于基于通用处理器的软件编码方案。
为了评估该方案对于Bayer 图像的压缩性能,将RGB 彩色图像按照Bayer 格式对所有像素点进行单一分量的降采样,将得到的如图9 所示的模拟Bayer图像作为测试对象,测试图像的纹理特性各不相同,其分辨率均为1 024×1 024。

图9 降采样后的部分Bayer图像
将该文所提出方案与JPEG、zip、rar、7z、JPEG 2000多种主流无损编码方案进行对比,评估参数为压缩比,即原图像的比特数与压缩后数据比特数之比,压缩比越大表明编码性能越好。比较结果如表3所示。该文所实现的Bayer 图像无损编码方案的性能接近于JPEG2000。仿真过程中目标器件的时钟频率为250 MHz,编码延时约为40 ms,满足了实时性要求。相比于主流的静态图像编码方案,该文根据Bayer图像特性设计的无损编码方案,适合于在FPGA平台实现,在消耗资源更少,延时更低的情况下获得了接近于主流图像编码方案的无损压缩效果。

表3 文中方法与主流方法压缩比
4 结论
该文考虑了摄像头前端处理系统对于硬件资源成本的敏感性,设计了一种针对8 位Bayer 图像的无损编码方法,并基于FPGA 进行硬件实现与验证。该方法摒弃了复杂度较高的变换编码方法,通过多种预测模式有效降低图像的空间冗余性;改进自适应Huffman 编码算法,降低了时间复杂度与空间复杂度。结果表明,该方案以较低的资源消耗达到了接近于JPEG2000 的压缩性能。
猜你喜欢
装备制造技术(2021年5期)2021-08-14 01:45:28
铁道通信信号(2020年5期)2020-09-21 09:21:26
扬子江诗刊(2018年1期)2018-11-13 12:23:04
计算机应用(2018年8期)2018-10-16 03:13:44
舰船电子对抗(2018年3期)2018-08-28 02:02:56
扬子江(2018年1期)2018-01-26 02:04:06
初中生世界·八年级(2017年3期)2017-03-24 15:36:23
中学生数理化·七年级数学人教版(2016年6期)2016-05-14 13:56:13
初中生世界·八年级(2015年4期)2015-08-04 07:59:48
中国新通信(2015年9期)2015-05-30 16:17:07
