
基于常旅客价值的高速铁路客户分类研究
2022-06-15 08:50:40许旺土
铁道运输与经济 2022年6期
郭 星,许旺土,任 冲
(1.厦门大学 建筑与土木工程学院,福建 厦门 361005;2.中铁二院工程集团有限责任公司 交通与城市规划设计研究院,四川 成都 610031)
0 引言
高速铁路常旅客指能够稳定且持续地为铁路运输部门带来利润和价值的乘客,从铁路运输部门的角度看,高速铁路常旅客的价值指其对高速铁路客运营业利润的贡献能力,即常旅客的终身价值,不仅包含当前价值、潜在价值,忠诚度也是常旅客价值的重要组成部分。根据巴莱多定律分析,20%的极少量的优质客户为企业贡献了80%的价值,常旅客价值的分析有助于筛选出利润贡献大的优质客户和潜力升级的客户,以便有针对性地制定服务提升计划[1]。
近年来,高速铁路常旅客分类与客户关系管理的相关问题研究逐渐被重视。在客户关系管理方面,杨亚伟等[2]从分布式工作流的角度分析探讨了铁路大客户系统的构建管理;俞诚成等[3]基于大数据技术和时间序列分析的密度聚类算法构架了可描绘旅客特征的画像系统;李建光等[4]通过结构方差模型对铁路中小运营商科学精细化管理体系的影响因素进行测度分析;郭玉华[5]基于工作流管理和数据仓库等技术开展铁路货运大客户管理系统的设计与研发。在客户价值与分类方面,张斌等[6]在消费时间间隔-消费频率-消费额度(Recency-Frequency-Monetary,RFM)模型的基础上,对铁路货运客户进行细分研究;郝晓培等[7]以客户价值指数为目标并通过神经网络算法,建立计算模型分析旅客的历史价值以及潜在价值以此进行客户分类;帅斌、马小龙等[8-9]改进传统RFM模型分别对铁路客运和货运客户市场的分类进行研究;段力伟等[10]基于潜力模型得出的客户选择偏好性,建立铁路货运客户的分类管理模型;邓程等[11]改进K均值算法对样本的孤立点进行处理。
目前客户分类模型研究中,多是注重大客户的挖掘,较少把常旅客作为目标进行研究分析。为探究高效的常旅客分类方法,把价值度相近的常旅客尽可能地聚集到同一类别。根据RFM模型,提出了一种可以自动确定聚类数目和初始聚类中心的算法,并通过问卷调查所获的常旅客数据对算法的可行性和有效性进行验证,可为铁路运输部门提升服务水平和运营策略提供参考。
1 高速铁路常旅客价值研究
高速铁路客运是一类典型的运输服务业,不同于一般商品的有众多选择,主要与航空和公路之间竞争。高速铁路与公路的竞争主要集中在300 km内的短途客运,而与航空的竞争则集中在500 ~1 000 km的中长途客运[12]。高速铁路出行主观目的性较强,主要取决于乘客自身的选择偏好和其实际的出行需要,故需要基于高速铁路的常旅客的出行数据,主动挖掘出具有较为稳定的高出行需求的常旅客。高速铁路常旅客的价值的高峰值一般处于年龄段25 ~ 45岁之间,该年龄段的常旅客一般有着较为稳定的出行需求。由于高速铁路常旅客的出行需求并不固定,是动态变化的,无法进行较长周期的价值评估与预测,但某个阶段会处于暂时的稳定状态,故一般选取1年作为研究常旅客价值的生命周期的时间跨度。
常用的客户价值评估方法有RFM模型、客户生命周期价值(Customer Lifetime Value,CLV)模型,其中RFM模型简单易懂,灵活方便,可操作性高,能够较为精确且高效地进行客户的分类管理,筛选出优质客户,适用于零售企业和酒店、餐饮、运输、快递等行业;CLV模型多是研究整个生命周期的客户利润变化,主要用于企业客户关系管理中的战略管理层面,但是目前并未形成系统的理论体系,难以对客户的价值进行较为精细的量化分析,模型计算成本相对偏高。故RFM模型较为适合用于评估短期跨度的高速铁路常旅客价值,RFM模型最早是由Hughes提出的, R (Recency)指客户距离最近一次消费时间跨度,F (Frequency)指客户在研究期内消费的次数,M (Monetary)指客户在研究期内总共消费的数额[13]。指标R越小、指标F和指标M越大表示客户忠诚度高,客户的忠诚度对长远的经营利益和价值发挥着至关重要的作用[14],而客户的满意度又很大程度决定忠诚度,客户价值V计算公式为

式中:V(R),V(F),V(M)分别为近期消费跨度、消费次数及消费额度的量化价值;α,β,γ分别为近期消费跨度、消费次数及消费额度3个指标的权重。
RFM模型的3个评价指标可以根据实际需要把每个维度的指标细分为若干层次,然后把3个指标中不同层次的元素进行组合可得到不同类别的组合,以每个维度指标均分2个层次为例,可得到2×2×2 = 8组类别的客户分类,但由于这种分类在多数情况下并不适用于所有情况,只能在特定的数据集中取得较好的分类效果,故RFM模型常常结合其他分类方法进行客户的精细划分。
2 客户分类算法设计
客户分类是指有选择性地根据客户价值、个人消费偏好和特殊需求等指标将客户归类研究,目前聚类分析方法是将一组特定的集合中类似的对象聚集在一起,组成若干个不同类别的一种数据挖掘分析法,其中K均值聚类是最为常用的快速聚类方法,广泛用于各个行业领域市场的客户细分,故选取K均值聚类用于基于常旅客价值的高速铁路客户分类。
2.1 K均值聚类
K均值聚类原理是根据初始设定的聚类数目随机从样本数据中选取K个初始聚类中心,分别计算每个样本点到K个聚类中心的距离(一般为欧几里得距离),按就近原则将各个样本点归到其K个簇中,然后再把K个簇中的中心点设定为新的聚类中心,如此反复迭代至聚类中心位置不再发生改变时完成聚类。因选取的不同评价指标的计量单位不同,数量级别也有一定的差异,若初始指标的数据直接被用来聚类分析,数量级别较小的指标数据影响性将会被削弱,从而使聚类结果误差较大,故在聚类之前一般需要对原始指标的数据作标准化处理。K均值聚类快速高效,但其聚类数目需要预先设定且聚类效果还依赖于初始聚类中心的选择[15]。
为选取较为合理的K值,通常先按分类群体的特征和分类需求,确定一个大致的K值选取范围,后通过引入代价函数,根据不同K值下代价函数的变化趋势来确定一个最佳K值,典型的代价函数有差值平方和函数、轮廓系数等,其中差值平方和函数SSE计算公式为

式中:d(vki,)为第k分类下的第i个数据点的坐标与其所在类的中心坐标的距离。
轮廓系数计算公式为

式中:SC(i)为某个点的轮廓系数;d(i)为某个点与其所在类中其他点的平均距离;b(i)为某个点与其他类的点的平均距离,样本总体的轮廓系数为其所有样本数据的平均轮廓系数,取值范围为[-1,1],当其值越大,说明聚类效果越好。
2.2 算法优化
高速铁路客户分类管理就是将客户价值相似的常旅客归在同一类下,便于定制差别化服务,实现效益最大化。基于此,先把所有维度指标值通过RFM价值模型降成一维的值,即常旅客价值,在一维数组里确定合适的聚类个数和初始聚类中心。由于一维数组可直接按数值大小等分归类,平均值即为其各类的中心点,不需要迭代确定,可直接求代价函数的值,故无需将整个多维指标数据重复选取不同K值聚类多次后确定最佳K值,即可高效地选出合适的K值提高聚类效率。
传统K均值聚类确定最佳K值,当数据量过大或维度较多时,每次设定不同的K值都需要重新迭代计算非常麻烦,若能在样本数据聚类之前得出较合适的K值和初始聚类中心,就能较为有效地提高聚类效率和精准度[16-17]。此外,初始聚类中心选取不同级别价值的数据点,可更有效将性质相似且价值相近的样本聚集在一起,故引入价值偏差度VD用以衡量聚类结果中各类别常旅客价值的差异性大小,作为判定聚类效果的额外条件,价值偏差度VD计算公式为
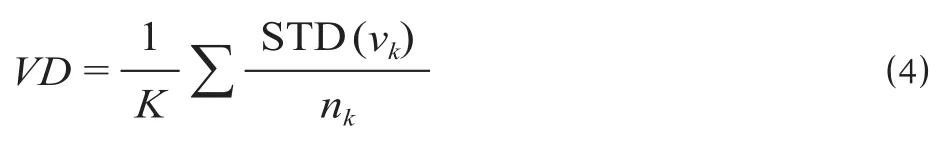
式中:STD (vk)为第k类旅客中价值的标准差;nk为第k类样本中的总数。
基于常旅客价值的高速铁路客户分类算法流程图如图1所示,先是对原始数据做标准化处理,再通过计算常旅客价值达到降维的目的,然后进行算法迭代,找出初始聚类中心并确定聚类个数,最后得出分类结果。通过多组样本数据发现相邻K值的代价函数下降值之间的比值φ值下降到10%以后能够得到较好的聚类结果,可作为程序自动终止的判断条件。自动确定K值和初始聚类中心的原理是初始设定K值为1,最大的分类数目为Kmax,根据价值的数值大小将数组分为K等分,而后计算各分类的K值下的代价函数值,当代价函数值不满足要求时,自动增加1个等分量至代价函数,满足要求时输出最佳分类数目Km,多维数组的初始聚类中心则选取为在Km分类下各类中距离其平均值最近的点,此处选取差值平方和函数SSE作为代价函数。

图1 基于常旅客价值的高速铁路客户分类算法流程图Fig.1 Program flow chart of customer classification algorithm for high speed railway based on frequent rail-traveler value
3 实例分析
3.1 聚类分析
高速铁路的常旅客多出现在城市间有密切经济活动联系的城市路线之间,以城际路线为主,如京津城际铁路(北京南—滨海)、沪宁城际铁路(上海—南京)、成渝城际铁路(成都东—重庆)等路线均存在相当数量的常旅客,高速铁路常旅客数据在城际路线中较为容易获取。因此以福厦高速铁路(福州—漳州)的常旅客为例进行验证分析。
(1)数据收集。为了更全面了解旅客的出行需求和特点,采用线上问卷调查的方式统计共977份福厦高速铁路的常旅客数据,样本人群主要集中于福建户籍人员和福厦高速铁路途经城市的工作人员及福建省内高校大学生。统计信息包括年龄、职业、出行频率、消费额度、出行报销比例等,得到福厦高速铁路常旅客2019年出行数据如表1所示。

表1 福厦高速铁路常旅客2019年出行数据Tab.1 Travel data of frequent rail-travelers for Fuzhou-Xiamen high speed railway in 2019
(2)建立价值评估模型。根据问卷调查反馈,由于铁路出行不同于一般商品的消费,而是根据实际需要选择,与个人的乘车偏好和出行目的有较大关系,外加福厦高速铁路的压倒性竞争优势,原始的RFM模型中“R”指近期消费跨度,由于选取的常旅客研究周期以年为单位,故这一参考价值并不大。此外,绝大部分旅客的乘车偏好均为二等座,选择一等座的不足10%,短途出行中,无人选择商务座。而常旅客的出行报销比例体现了出差率,结合常旅客职业,能在一定程度上反映旅客消费潜能,故选取出行报销比例(R)、出行频率(F)及消费额度(M) 3个指标,建立改进的RFM模型。
(3)RFM模型各指标权重。评分标度取1-9,对3个指标进行专家综合评分,得到RFM模型各指标判断矩阵如表2所示。
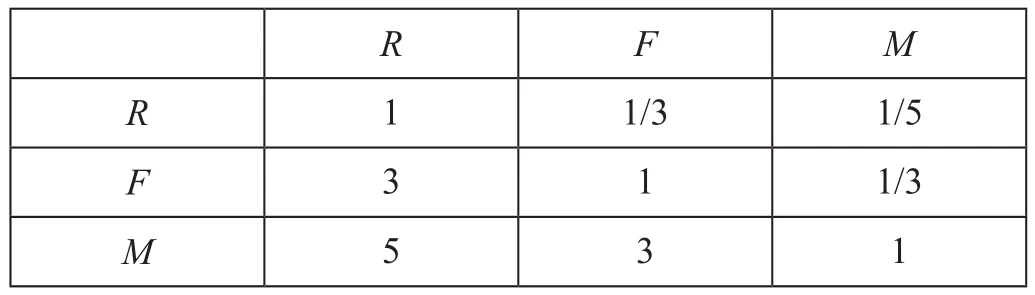
表2 RFM模型各指标判断矩阵Tab.2 Judgment matrix of indexes in RFM model
通过和积法求得R,F,M各指标权重向量为:{α,β,γ} = {0.106 2,0.260 5,0.633 3},得到最大特征值为:λmax= 3.039 0,表明计算结果通过一致性检验。
(4)数据的标准化处理。采用Z-Score法标准化处理数据后,得到报销比例、出行频率、消费额度的量化价值,分别为V(R),V(F),V(M),然后再计算出常旅客价值V。汇总全部旅客标准化数据如表3所示。
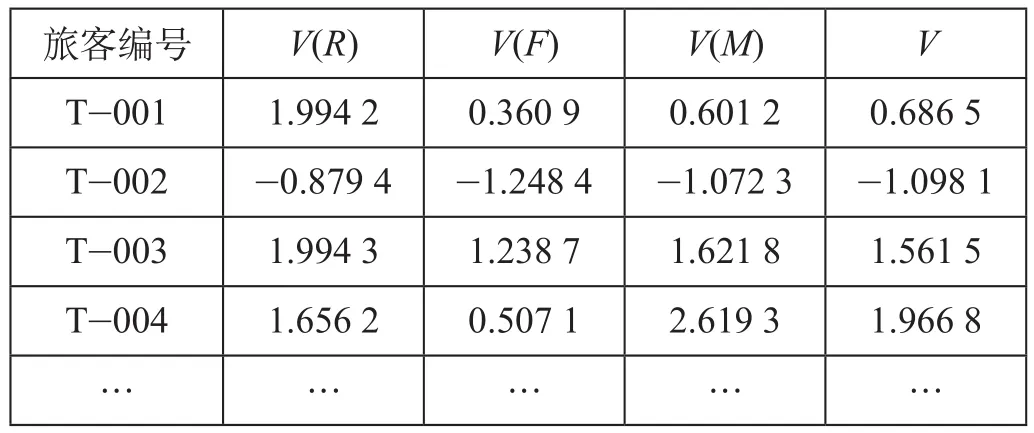
表3 标准化数据Tab.3 Standardized data
(5)K均值聚类。设定Kmax值为10,在程序中输入数据后运行,确定最佳聚类个数Km为4,初始聚类中心为 (3.578 0,3.443 0,3.324 2),(0.506 9,-0.186 1,-0.025 3),(0.799 3,0.372 7,0.548 3),(2.115 6,1.786 3,1.768 5)。
(6)初始聚类中心有效性验证。设定K和初始聚类中心后进行聚类,程序运行17次后算法收敛得到聚类结果如表4所示。
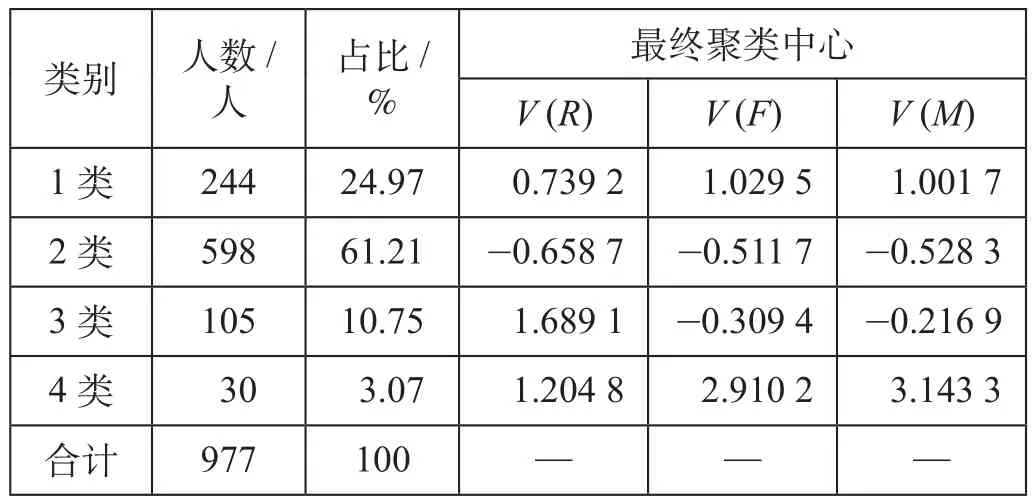
表4 聚类结果Tab.4 Clustering results
而当聚类数据只设定K值,按随机方式选取初始聚类中心时,算法实现收敛在不同的初始聚类中心下迭代的次数有所不同,运行程序20次,得到平均迭代次数为35次,最低迭代次数为21次,最高迭代次数为60次。可见,算法自动选取的初始聚类中心可以提高聚类效率,加快最终聚类中心的收敛。
(7)Km的准确性验证。轮廓系数是用于判断聚类效果的常用指标值,不同K值下的轮廓系数变化趋势如图2所示,可以确定K= 4时,轮廓系数达到最大值,故聚类分为4类的聚类效果是最佳的。
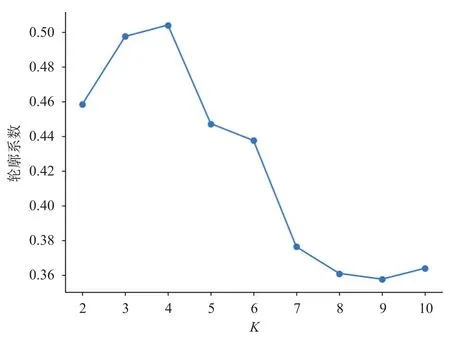
图2 不同K值下的轮廓系数变化趋势Fig.2 Variation trend of silhouette coefficient under different K values
(8)价值偏差性验证。分别在设置初始聚类中心和未设初始聚类中心时,运行程序计算价值偏差度,得到价值偏差度如图3所示,可以看出,设置算法中自动选取的初始聚类中心的情况下价值偏差度更低,能够更有效地选取性质相似且价值更为接近的样本聚集在一起,产生更优的聚类效果。

图3 价值偏差度Fig.3 Value deviation
3.2 结果分析
根据上一节的聚类分析,选取K值为4,聚类得出各类别常旅客特征如表5所示,价值越高的客户群体,25 ~ 45岁旅客所占比例越高,差旅稳定率(职业岗位和差旅需求较为固定的人员所占比例)也越高。4类常旅客中,第Ⅳ类常旅客的价值最高,往后依次是第Ⅰ类、第Ⅲ类、第Ⅱ类。第Ⅳ类常旅客人数最少,各项指标值都非常高,平均每月出行超过2次,对福厦高速铁路运营的贡献度最高,属于贵宾级客户,在配置出行服务资源方案时考虑向这类旅客倾斜,提供专门化的服务。第Ⅰ类常旅客各指标值都处于中上水平,有着较高且稳定的出行需求,属于黄金客户,应当重点发展,提供优质服务。第Ⅲ类常旅客出行频率和消费额度属于中下水平,但出行报销比率较高,差旅稳定率较高,有着较为稳定的出行需求,属于潜在价值高的客户,也需要重视忠诚度的维系。第Ⅱ类常旅客人数占比最高,多为在校学生、低收入从业者和老人,属于低价值客户,只需一般维系,但在校学生具备一定的远期潜在价值。

表5 各类别常旅客特征Tab.5 Frequent rail-traveler characteristics
3.3 常旅客服务策略
福厦高速铁路有较多的时间车次可供选择,不同车次时速和票价略有差异,总体服务水平较高。铁路部门自2017年底推出“铁路畅行”常旅客服务计划,但并未得到较大程度的推广,存在较大的提升空间。根据常旅客分类的结果,建议加快推行针对高价值的第Ⅳ类常旅客的“高端会员专享”服务,同时对不同等级的会员积分采用不同的使用和兑换规则,以体现高级会员专享的差异化服务;对于第Ⅰ类和Ⅳ类高频出差的旅客考虑实施“积分升座”服务计划,因其差旅费均可报销,折扣优惠并不能增加其满足感。“积分升座”既可使得高等级席位客座率增加,又可增强旅客感知服务质量,提高旅客忠诚度;而对于Ⅱ、Ⅲ类价值较低的常旅客,可考虑与高速铁路服务站点的商业合作,提供积分兑换商品抵用券和折扣券等服务以维系旅客忠诚度。
常旅客分类管理的最终目的就是锁定高价值客户,不断挖掘更多的潜在客户,可考虑从以下2个方面进一步提升服务水平。
(1)推出“个性化”服务。对出行需求稳定的异地情侣、探亲者和出游者提供“情侣票”“亲子票”“假日票”等,根据不同类别旅客的价值划分不同等级;同时还可考虑推行积分兑换折扣的功能以及赠送定制有特殊意义的专属纪念品等以提高旅客满意度。此外,不同类别的常旅客对出行感知服务的侧重点有所不同,如考虑为高频出差的高价值旅客提供噪音指数低的专享车厢。
(2)完善客户关系管理系统。建立综合高效的客户关系管理系统,在旅客购买车票时获取更多旅客出行需求、目的和职业等可挖掘客户价值的信息,以便于掌握更全面的常旅客信息进行快速分类管理,同时完善常旅客服务满意度评价反馈系统,及时调整运营服务模式。
4 结束语
对高速铁路常旅客进行客户分类管理,一方面使得铁路运输部门能够通过旅客的分类配置资源,提高运营效率与效益,加速实现高速铁路投入的资金回收;另一方面有助于完善铁路运输部门客户关系管理机制,不断完善客运服务水平,提供高效率、高质量的服务,提升高速铁路在运输市场的占有率。高效的客户关系管理必然要求对旅客价值有着清晰、精准的定位和分析,根据不同层次价值旅客的实际需求制定服务提升方案以提高客户忠诚度和满意度,从而追求长期效益的最大化。基于常旅客价值的客户分类方法有助于铁路运输部门精准定位目标用户,实现对高速铁路客户的高效分类管理。
猜你喜欢
高速铁路技术(2022年2期)2022-05-05 01:18:16
高速铁路技术(2022年1期)2022-03-17 07:45:06
小哥白尼(趣味科学)(2021年3期)2021-07-16 07:47:32
故事大王(2018年3期)2018-05-03 09:55:52
电子测试(2017年15期)2017-12-18 07:19:27
铁道通信信号(2016年2期)2016-06-01 12:10:18
空中之家(2016年1期)2016-05-17 04:47:43
智能系统学报(2015年4期)2015-12-27 09:38:39
河南科技(2015年2期)2015-02-27 14:20:33
电子设计工程(2015年6期)2015-02-27 12:04:53
