
基于时序CNN的FPGA数据处理异常点识别研究
2022-06-14 10:06李政清穆继亮莫小琴
计算机仿真 2022年5期
李政清,穆继亮,莫小琴
(1. 三亚学院理工学院,海南 三亚 570200;2. 中北大学仪器与电子学院,山西 太原 030000)
1 引言
在工业生产中,大部分数据都具有时序性,其排列顺序包含着重要的信息。对时序数据进行分析时,常常会有一些特殊的数据与其它 数据呈现的波动规律不同,这些数据被称为异常点,异常点通常是由于系统误差和随机误差造成的。异常点会直接影响到数据预测的结果,因此对异常点的识别与检测非常重要。目前对异常点的判别方法主要有[1-4]:统计方法、距离方法、聚类方法、密度方法和极值理论方法等。时序数据主要通过简洁的方式表示数据的基本特征,因此设计出合适的算法加快数据处理和识别数据处理异常点具有重要的意义。
文献[5]使用多模态数据流技术和大数据流技术分别对异常和滥用进行检测,由模糊规则对异常和滥用的输出结果执行最后的检测,并采用特征向量对数据流的实时运行状态进行描述,该方法能够较全面的反映数据流的基本特征,具有良好的扩展性,但没有对多模态数据流加以考虑。文献[6]对实例进行处理得出线性组合关系,并求出实例的邻近关系矩阵,为了自动选择邻近关系及算法中的参数,采用谱聚类方法对数据的异常点进行识别,将异常点在11个真实数据集上进行比较,结果表明该方法具有较高的稳定性,但计算过程耗时较长。文献[7]提出统计的异常点检测方法,对有增长率的时间序列数据进行预处理,通过正态分布概率密度函数对置信区间外的异常点进行修正,并采用压缩变换函数防止对异常点的过纠正处理,该方法的预测精度具有明显的提升,但还需要对潜在的异常点做进一步的判断。
基于以上研究,针对时序数据处理异常点识别过程卷积计算复杂度较高、模型占用空间大及运行速度慢等问题,本文提出基于时序CNN的FPGA数据处理异常点识别方法。
2 时序数据提取
时序数据的表示形式不统一,不利于直接应用卷积神经网络,因此需要对时序数据进行特征提取。在数据采集和处理过程中,由于设备、系统和外部环境等原因可能造成数据发生错误,因此实际中的数据不仅包含有用的数据,还包含异常的数据。
2.1 时序数据异常点的构建
数据异常点会造成数据质量下降,影响数据的一致性与可靠性。根据错误数据的来源,可将错误数据分为噪声错误和缺失错误两种类型。根据噪声错误中噪声的分布情况,可将其分成若干种类的噪声,如高斯、泊松、散斑、椒盐噪声等噪声的一种。缺失数据一般分为数据片段缺失和部分值缺失两种情况。由于实际中噪声错误和缺失错误比较复杂,若使用添错误的加方法,很容易将错误继续添加到数据中,因此本文从以下几方面加以考虑。
高斯噪声:在通信过程中,通信信道很容易受到自然源的宽带高斯噪声影响,因此在数据采集过程中,由于不良的光照、透射和高温等均会导致传感器上产生高斯噪声,高斯会随着灰阶的概率密度函数发生改变,公式可表示为

(1)
其中,a表示灰阶;σ表示标准差;μ表示均值。
泊松噪声:一般在亮度较低或高倍电子放大电路中存在泊松噪声,泊松分布属于离散概率分布,公式可表示为

(2)
散斑噪声:一般在有源雷达或孔径雷达周围存在散斑噪声,它是一种颗粒状的干扰,主要影响医学超声和光学扫描的质量,散斑噪声是一种乘性噪声,公式可表示为
ρspe=bimag+n*bimag
(3)
其中,n表示指定均值和方差的均值噪声。
椒盐噪声:椒盐噪声通常由图像信号中尖锐的干扰造成的,通过-1、0、1表示稀疏出现的黑白杂点,其可以模拟数据中的随机错误。
数据片段缺失:每段数据均由若干数组组成,可以随机删除数据中的某段,在数据中添加数据片段缺失错误。首先确定需要添加缺失错误的起始位置和终止位置,然后在起始到终止部分的数组中添加错误。
部分值缺失:在录入信息的过程中,经常出现一些数据缺失的情况,因此通过随机删除数据中某些值的方式添加错误。首先通过一个变量确定是否对当前的数据添加错误,若需要添加,随机的确定添加缺失错误的起始位置和终止位置,对起始到终止部分的数据添加错误;若不需要,则不对该段数据处理。
2.2 时序数据处理
由于数据的采样频率不同,为了保证不同数据关联的有效性,需要对各个数据进行对齐处理,并提取出数据的特征。对于各种类型的数据样本,将其转化为可通过枢轴模态的时间戳表示形式,对样本应用合并函数collapse functions进行处理,从而使所有数据具有相同长度。在collapse functions函数处理过程中,会舍弃时间间隔较小的数据序列。首先取出文本中的各个数据,然后将得到的数据进行对齐保存data[i],data[i]表示对齐数据中的第i个单词。通过这样的处理方式,可以清楚的知道每个数据中的单词个数。
原始数据信息量较大,若进行直接计算会占用大量的存储空间,且大量的数据并非都是有用的,导致训练模型难以收敛,因此使用GloVe方法对原始数据中含有明显特征的数据浅层特征进行提取。GloVe算法中融入了先验统计信息,不仅可以提高模型的训练速度,还能控制单词的权重,目标函数用公式可表示为
(4)
其中,ei和ej分别表示单词i和j对应的词向量;xij表示单词j在单词i中出现的次数和;gi和gj表示偏置项;f(xij)表示修正函数。
3 CNN模型处理
在模型训练过程中,对卷积神经网络预处理可以提高运算速度,有利于模型的定点量化。卷积神经网络由输入层、卷积层、激活层和全连接层组成,卷积计算实际上是数据乘积后的累加操作,公式可表示为

(5)


(6)
其中,β表示缩放因子;μ表示均值;σ2表示方差;χ表示较小的正数;δ表示偏置。归一化层的增加对数据训练起到积极作用,但多一层的运算,在一定程度上会降低运算速率,因此将归一化层的参数合并到卷积层的权值参数中,合并后卷积计算公式可表示为

(7)
经过变换后,卷积计算在每次计算过程中都会减少开方和除法的运算操作,可大大提高卷积的运算速率。对激活层采用ReLU函数进行处理,公式表示为

(8)
在FPGA中浮点运算相比定点运算要耗费更多的时间,不同CNN模型的权值在零点两侧呈对称分布,不同卷积层的权值具有动态性,若对其进行定点量化[9],将CNN模型中所有层的参数量化为同一范围,会造成较为严重的精度损失,因此采用动态指数定点方式对参数进行量化。将每层参数分到Arr数组中,且每组中小数部分的位数是相同的,不同组间有差异。将每个网络层分为输入、权重和输出三组,方便覆盖每层参数的动态范围。动态定点量化计算公式可表示为
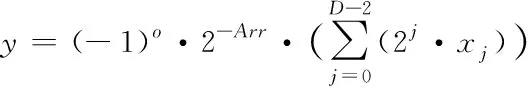
(9)

由于输入层每次传入的数据不一样,每层输出的差异较大,不能确定输入的量化范围,为了减少计算量、保证精度,本文采用散度计算输入参数定点化的尺度。首选构建数据和定点数的映射关系,设置一个阈值H,通过阈值与定点数的最大值计算输入尺度Sin。在选择阈值和尺度时尽量减少数据丢失,可设置矫正数据集对输入尺度进行选择,通过计算最小化散度确定最佳尺度,最小化散度用公式可表示为

(10)
其中,φ[x]和φ[x]表示离散概率分布。当散度为最小值时,可以求出阈值H,进而求出每层参数的尺度Sin,公式可表示为
(11)
4 FPGA的设计
在CNN模型计算中,卷积层的输出由多个嵌套循环卷积组成,导致卷积层计算量大、耗时多,而这种情况非常适合将CNN算法映射到FPGA中实现硬件加速。FPGA框架主要有CNN训练参数和硬件约束参数两组输入参数,主要包含映射阶段和实现阶段。在映射阶段,FPGA框架将CNN训练结果切分成若干细粒度子图,并将其映射到FPGA集群的各个节点上。在实现阶段FPGA的RTL代码生成器根据映射阶段产生的参数配置文件为FPGA节点建立加速器代码。
FPGA框架利用CNN训练结果对若干卷积层特征进行显式划分,将算法简化到可以在多项式的时间要求内求解完毕。FPGA算子图切分分为粗粒度切分和细粒度切分两个步骤。



(12)

大规模集群:卷积引擎的数量为Neng_i,卷积引擎的最大性能为Per(Neng_i),那么卷积引擎的需求和系统处理能力用公式可表示为

(13)
在FPGA集群中,一部分卷积引擎和缓存器可分别采用硬核单元(θNeng_i)和(ϑBufi)构建,另一部分卷积引擎和缓存器可分别采用软核单元((1-θ)Neng_i)和((1-ϑ)Bufi)构建,FPGA的硬件约束条件用公式可表示为:

(14)
其中,f2,…f5表示返回对应模块所占用逻辑资源的个数。
小规模集群:为了使所有的CNN训练加速器都存入小规模集群中,采用模型参数均衡方法,目标函数最小化存储需求用公式可表示为
Nee=max(f6(ϑiBufi)+f7(ϑiBufi,(1-ϑ)Bufi))
(15)
其中,f6和f7表示返回对应模块所占用逻辑资源的个数。采用模型参数均衡方法可以将最后几层FPGA所需的模型参数存储到前几层的远程FPGA上,充分利用前几层FPGA多余空间存储器,对于CNN模型的所有卷积层,仅需使用FPGA片上存储器即可。
5 实验结果与仿真
为了验证基于时序CNN的FPGA数据处理异常点识别方法的有效性,本文选择C语言编写程序在FPGA上实现数据异常点识别的加速计算,选择格式为PascalVOC的人脸数据集进行实验。人脸数据集包含2000张图像数据,随机选取1500张作为训练集,剩余500张作为测试集,CNN模型为15层的卷积网络。
保持每层输入特征值位宽不变的情况下,对权值定点量化,验证人脸数据集每类平均准确率值随量化位宽的变化情况,同时验证平均准确率、精度和召回率随量化位宽的变化情况,实验结果如图1所示。
a.不同类别平均准确率变化
b.平均准确率、精度、召回率变化

图1 权值定点化结果
从图中可以看出,本文方法对权值定点化具有较好的鲁棒性,当权值参数压缩到8bit时,压缩率比较大,数据精度和平均准确率损失较小,说明本文方法可以充分利用FPGA资源,高效读取数据,可充分识别数据处理中的异常点。
提取量化后的模型参数,使用C语言搭建网络模型后,输入量化后的人脸数据训练集,将真生成的文件导入开发板上,输入数据进行验证,得到加速器SoC各个资源的利用情况如表1所示。
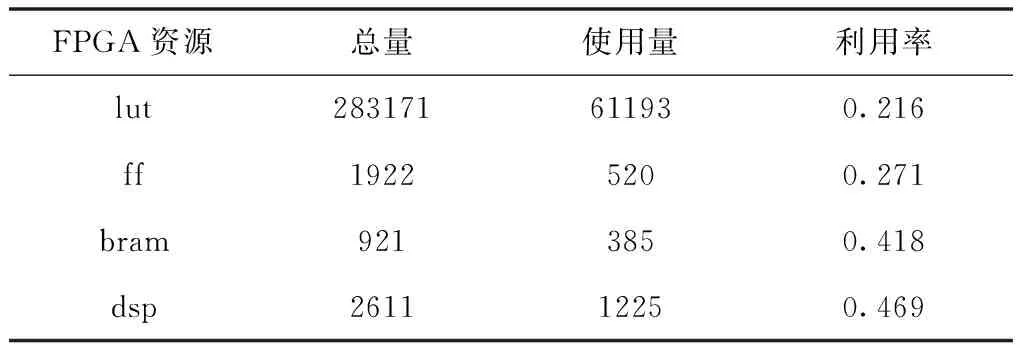
表1 加速器SoC各个资源利用情况
从表中可以看出,处理器与加速器在工作频率为300MHz下,完成单张图片数据所需要的推理时间为118.5ms,与其它FPGA的实现方法相比,在能效和峰值性能上有较大的提升。
6 结束语
本文提出一种基于时序CNN的FPGA数据处理异常点识别方法,设计了卷积计算策略,通过C语言编写程序在FPGA上实现数据异常点识别,选择人脸数据集进行实验。本文方法不仅有较高的运算峰值,还具有较高的FPGA资源利用率,通过人脸识别数据集对平均准确率、精度和召回率进行验证,损失均在1%以内,说明本文方法可有效利用FPGA资源,充分识别数据处理中的异常点。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
科技创新导报(2021年33期)2021-04-17
意林·作文素材(2021年23期)2021-01-22
上海师范大学学报·自然科学版(2019年5期)2019-12-13
智富时代(2019年4期)2019-06-01
