
FPGA加速器深度卷积神经网络优化计算方法
2022-06-14 09:49梁修壮
计算机仿真 2022年5期
梁修壮,倪 伟
(合肥工业大学微电子设计研究所,安徽 合肥 230601)
1 引言
深度学习理论的应用越来越广泛,多种深度学习网络模型应运而生。其中,卷积神经网络使用最为广泛,实质上是一种人工神经网络模型,简称为CNN,与其它人工神经网络模型相比较,CNN模型具备层间连接的稀疏性与权重共享结构,更加接近生物神经网络结构,能够直接处理图像数据,加大的简化了数据处理过程。同时,CNN模型具有识别精度高、适应性强、复杂度低的优点,广泛应用于人脸识别[1]、医疗检测[2]、图像鉴别[3]等领域中,其中Hinton与Krizhevsky设计的用于图形分类的AlexNet[4]模型,以37.5%的识别错误率获得了ILSVRC比赛的冠军,相较于传统模型来看,AlexNet模型具备更加优异的成绩,许多学生投身到AlexNet模型研究中。
随着卷积神经网络的应用,其潜在的问题也逐渐显现,面对大规模卷积计算时,会受到GPGPU和GPCPU等通用处理器上计算能力的限制,为此FPGA等硬件加速深度卷积神经网络优化计算方法的研究很有必要[5]。FPGA具备灵活性高、计算速度快、针对性强、成本低、逻辑资源丰富的优势,属于一种半定制电路,芯片内部的DSP单元可以极大的提升FPGA加速器的大规模卷积计算能力,并且FPGA的存储器还可以为卷积计算中间结果提供临时缓冲区,由此可见,采用FPGA加速器优化深度卷积神经网络计算能力是可行的。希望通过FPGA加速器的应用,提升深度卷积神经网络的计算能力,满足快速进行大规模卷积计算的需求,为其应用发展助力[3]。
2 AlexNet模型分析
AlexNet模型由五层卷积层与三层全连接层构成,共8层,具备池化、激活函数、填充、局部相应归一化等处理功能。AlexNet模型能够对规格为227×227×3的三通道RGB格式图像进行处理,得到1000个用于分类的值,利用特定函数获取这些图像的概率分布。

图1 AlexNet模型
AlexNet模型(见图1)第一层输入为规格为227×227×3的RGB格式图像,以步长4为单位通过11×11卷积核进行卷积计算,输出96个规格为55×55的特征图;第二层将第一层输出特征图分为两组,对池化后特征图增加两个单位的0元素,规则变为31×31,以步长1为单位通过5×5卷积核进行卷积计算,输出128个规格为27×27的特征图。经过池化、激活共获得256个规格为13×13的特征图。依据上述流程,继续进行第三层、第四层以及第五层卷积计算,最终得到256个规格为6×6的特征图,将其与第一层全连接层参数计算可得4096个输出值,通过第二层、第三层全连接层参数计算得到1000个用于图像分类的数值,详细的Alexnet络模型参数如表1所示。

表1 Alexnet网络模型参数表
Alexnet模型中共有三种不同规格的卷积核,占据了整个网络90%的计算量,其计算结果需要经过特定函数激活,并不同卷积层需要经过池化或者填充处理。当深度卷积神经网络模型训练结束后,全连接层占比为96%以上。
上述过程完成了深度卷积神经网络模型Alexnet的分析,为下述硬件加速架构设计提供基础支撑。
3 硬件加速架构设计
AlexNet模型每个卷积计算模块包含多个卷积处理单元、线性缓存单元、池化单元与激活单元。为了优化深度卷积神经网络计算能力,引入FPGA设计加速器,对各个卷积计算单元加速,具体深度卷积神经网络优化计算过程如下所示。
3.1 FPGA加速器设计
FPGA加速器是由GPU与FPGA共同构成的异构计算框架[6]。其中,GPU能够将相关指令和数据发送给FPGA加速器,FPGA芯片能够根据收到的指令实现对应的任务。FPGA芯片由外接存储器、缓存单元以及计算单元组成。其中,计算单元有多个,各个单元都能实现对该层数据的激活、卷积以及池化等各种任务。缓存单元的功能是保存计算中间结果,使模型计算过程不间断;外接存储器的功能是保存训练好的AlexNet模型参数。
应用FPGA加速器后,可以使深度卷积神经网络模型计算能力充分发挥,极大的提升深度卷积神经网络模型的效率。

图2 模型计算流程
依据图1所示深度卷积神经网络Alexnet模型计算流程,分别对每个卷积计算模块中的卷积处理单元、线性缓存单元、池化单元与激活单元进行优化处理。
3.2 卷积处理单元加速
卷积处理单元是AlexNet模型的核心计算环节,负责单个卷积核对特征图的计算,该单元处理效率绝大程度上决定着加速器对AlexNet模型的计算能力。
对于卷积神经网络模型来说,卷积需要处理的数据众多,常用的二维卷积计算结构如文献[7]所示,使用移位寄存器增加数据在计算单元的停留以减少内存的访问,一部分寄存器用于计算时加载数据,一部分用于对齐数据,当初始数据加载完成每一个时钟周期可以得到一个结果,当卷积核和特征图尺寸较大时,这种单一的计算结构极其容易浪费资源,为此将大矩阵拆分成若干个小矩阵的乘加运算结构,利用“⊗”表示卷积计算。
规格为P×Q的特征图与N×M的卷积核矩阵进行卷积计算,通过拆分将其转化为R×C的特征图与T×S的卷积核矩阵的卷积计算。原有的计算单元拆分为若干个K×L小矩阵计算,其中,K与L分别表示的是行与列的拆分单位。需要注意的是P与N能够被K整除,Q与M能够被L整除,若不能满足上述条件,需要对填充卷积核矩阵和特征图,以一列或一行作为整体,利用0元素实现素扩展填充,使特征图与卷积核矩阵规格满足拆分的资格[8]。
为了降低AlexNet模型的数据处理量级, 用若干个小卷积乘加计算方法代替大卷积计算,可以极大的降低,并且K×L小卷积计算可以利用并行方式进行处理,极大的减少了卷积运算的规模,节省了硬件资源—FPGA加速器的应用,使得深度卷积神经网络模型计算数据传递更加便利。
为了详细介绍卷积处理单元加速策略,以AlexNet模型第一层卷积计算为例实施卷积拆分策略,具体实施过程如下所示。
将AlexNet模型第一层计算单元的11×11卷积核矩阵采用0元素扩充为12×12的卷积核矩阵,再次将其拆分为9个4×4的小卷积计算。将小卷积当成整体,改变卷积框的位置,并计算其权重,把得到的权重值相加并将结果输出[9]。
未拆分之前,AlexNet模型第一层卷积计算输出值为
Y=X⊗W
(1)
式(1)中,Y表示的是未拆分AlexNet模型第一层卷积计算输出值;X表示的是输入特征图相应卷积框的矩阵;W表示的是权重矩阵。
执行卷积拆分策略,得到AlexNet模型第一层卷积计算输出值为
Y′=X1⊗W1+X2⊗W2+X3⊗W3+X4⊗W4+X5⊗W5
+X6⊗W6+X7⊗W7+X8⊗W8+X9⊗W9
(2)
其中,Y′表示的是拆分后AlexNet模型第一层卷积计算输出值;Xi与Wi分别表示的是拆分后的输入特征图与权重矩阵。
拆分后的小卷积矩阵相互独立,利用并行方式处理。需要注意的是,由于填充元素为0,Y与Y′的数值相同。
由上述过程可知,通过卷积拆分策略可以极大的加速卷积处理单元。
3.3 线性缓存单元加速
对于深度卷积神经网络计算来说,每个输出值均需要遍历全部的输入特征图,为此卷积层计算不能并行。为了使不同卷积层以流水线方式进行计算,整体提升AlexNet模型的吞吐率,设计乒乓缓存结构加速线性缓存单元。乒乓缓存结构示意图如图3所示。
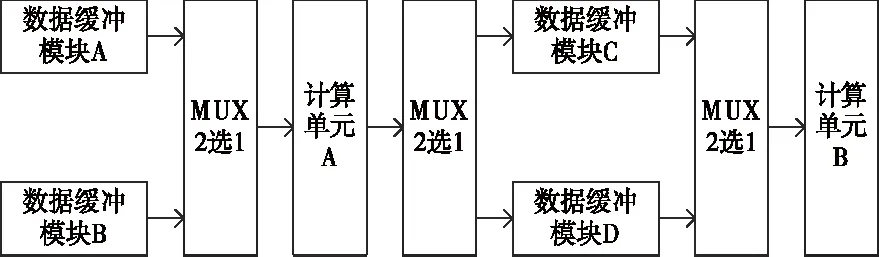
图3 乒乓缓存结构示意图
如图3所示,该单元对应的是卷积层数据,功能是对特征图与权重进行保存。将一个卷积计算过程记为一个周期。该单元流程如下:周期一,复用器MUX自动加载数据缓冲模块A数据,将其传送至计算单元A,将输出的中间结果存储于缓冲模块C;周期二,加载数据缓冲模块B数据,并将其传递给计算单元A中,与此同时,将计算产生的中间特征图存储于数据缓冲模块D。另外,将第一个周期结果加载到计算单元B中处理;周期三,重复周期一整个流程。综上所述,对周期一到三进行重复切换,利用复用器调用数据缓冲模块的数据,使计算单元时刻处于计算状态,计算资源利用率达到最佳。
3.4 激活单元加速
AlexNet模型采用的是ReLU激活函数实现激活单元的任务,ReLU激活函数具有电路简单的优势,通过一个比较电路激活输出值,使输出值中不包含0元素,主要通过与0元素比较输出最大值来实现。
ReLU激活函数硬件电路如图4所示。
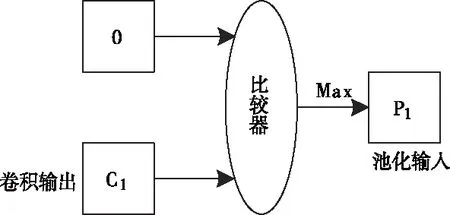
图4 ReLU激活函数硬件电路图
对于激活单元来说,其输入值为卷积层计算结果,输出值连接池化单元,为池化单元的输入提供数据支撑。若没有池化层,将激活单元输出数据直接传递给全连接层。
3.5 池化单元加速
池化单元的任务对象是经过激活处理的卷积层结果,通过池化操作输出最大值或者平均值,并将其传递给下一层继续完成池化操作。卷积计算是比较复杂的,而池化操作相对简单。因此,大多数网络都是通过池化进行加速的。最大池化单元计算流程如图5所示。

图5 最大池化单元计算流程图
如图5所示,最大池化单元规格为3×3,包含2个比较器与2L+4个寄存器,L表示的是卷积层输出特征图的行长度。
在匹配池化操作窗口移动过程中,利用2L+1个寄存器匹配数据,并且缓存匹配数据。对于步长为2的池化单元,若输入数据到达2L+1个寄存器中最后一个寄存器时,每加载一个数据,比较器通过对比将最大值传递给下一个寄存器,直至与窗口移动步长一致为止,输出结果即为最大池化结果。
上述池化单元加速策略可以在保障效率需求的情况下,节省硬件资源的使用,对于平均池化结构也同样适用。
通过上述设计实现了FPGA加速器深度卷积神经网络计算的优化,为AlexNet模型应用发展助力。
4 深度卷积神经网络计算能力实验分析
4.1 实验准备
为了保障实验的顺利进行,AlexNet模型参数的准确性,在Nvidia GeForce GTX 1080 Ti显卡上,基于经典训练数据集ImageNet 2012图像集,利用梯度下降方法对提出的AlexNet模型进行训练,部分训练结果如表2所示。

表2 部分训练结果表
如表2数据显示,迭代次数为400000次时,训练损失达到最小;迭代次数为380000次时,训练准确率最高。通过对比研究后,选取迭代次数为380000时的模型参数进行实验,其参数规模为235MB。
深度卷积神经网络计算能力由单层加速效果、FPGA资源消耗以及MAC效率决定,具体深度卷积神经网络计算能力实验过程如下所示。
4.2 单层加速效果分析
在时钟频率为100MHz下,采用XC7V2000T设备统计FPGA加速器深度卷积神经网络优化计算方法5个卷积层计算延迟,并与Intel Xeon @2.20GHz CPU对比,得到加速比结果如图6所示。

图6 加速效果
对于AlexNet模型来说,不同的卷积层拥有不同的计算资源和计算量,那么,同样的加速效果具有一定的差异,在远低于和CPU运行频率下相比,加速4.41~10.87倍,平均单层加速8.04倍。
4.3 FPGA资源消耗分析
FPGA加速器由查找表、触发器、DSP与存储器构成。资源消耗见表3所列。由于AlexNet网络模型权重和中间结果的数据量比较大,全部采用32-bit浮点数会需要大量的硬件资源,根据文献[10]研究结果可知,高准确率识别不需要太高精度的神经网络参数,降低神经网络参数的数据精度对识别的准确率影响不大。所以权重和中间结果采用的是16位定点数表示。共使用了1336块18 kb的BRAM,主要用于中间数据缓存,930块的DSP用于卷积中大量的乘法计算,还使用了大量寄存器缓存来自片外的权重数据和从BRAM读取的数据。
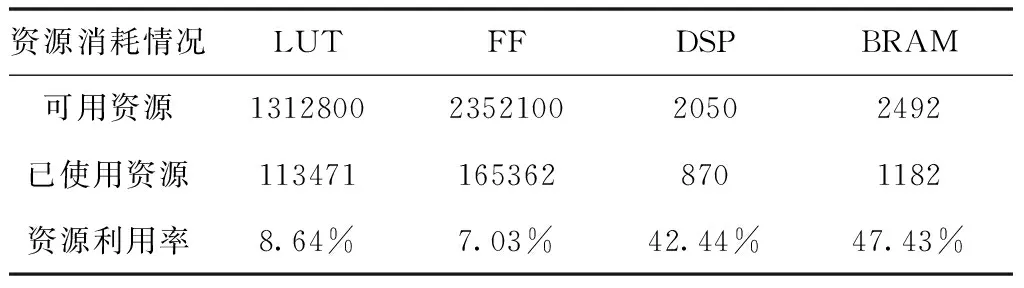
表3 资源消耗
4.4 MAC效率分析
MAC效率由每个卷积层加载MAC数据处理量的延迟时间判定,延迟时间越短,表明MAC效率越高。通过实验得到MAC效率数据如表4所示。
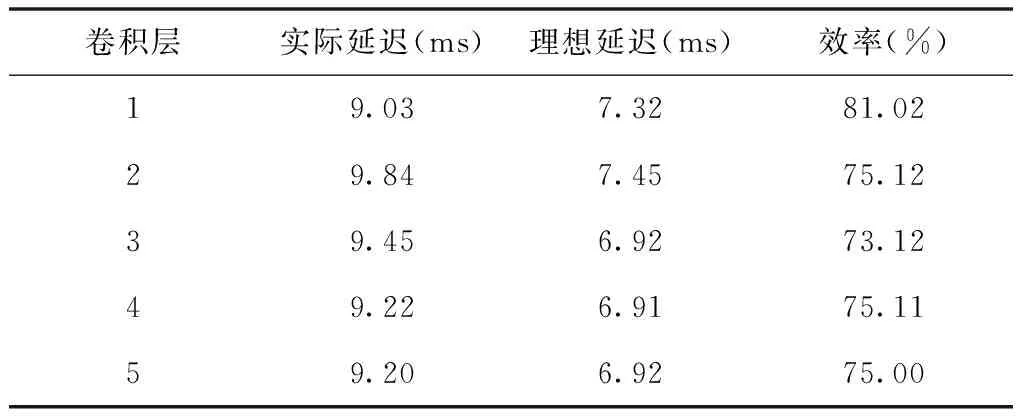
表4 MAC效率数据表
如表4所示,MAC效率范围为73.12%~81.02%,对于不同的卷积层来说,MAC的效率是不同的,表4中的理想时延表示的是不将卷积计算考虑进去时,数据加载及对齐过程所需要的时延,通过单个层的MAC计算量除以配置DSP 数量获得,但是实际延迟一定会大于理想延迟。
4.5 同类实现对比分析
与其文献[11]、[12]实现的AlexNet 5个卷积层相比,结果见表5所列。DSP的消耗数量与计算性能密切相关,通常消耗DSP数量越多实现计算性能越高,但不同的计算结构表现的计算性能会有差异,文献[11]采用的是64-bit 浮点精度,消耗了2600个DSP,浮点数据计算资源消耗过高,与文献[12]的实现相比,表明优化设计的流水并行计算方式具有明显优势。

表5 与其它AlexNet网络实现的对比
5 结论
为了解决传统方法计算能力能力不佳、加速器加速效果不明显等问题。本文设计一种FPGA加速器深度卷积神经网络优化计算方法。引入FPGA设计加速器,利用拆分计算将卷积过程分解为更细粒度的并行计算,利用FPGA加速器实现优化计算。通过实验得出以下结论:
1)本文方法能够有效提升加速效果,当卷积层为5层时,100 MHz下数据加速比能达到8.04平均值。
2)本文方法的,MAC效率较高。5个卷积层整体MAC效率达到76.08%。
3)本文方法能够在低资源消耗率的情况下实现较高的吞吐量,在使用1020个DSP的情况下实现130.43 GOPS吞吐量,优于同类设计。
猜你喜欢
现代装饰(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
现代仪器与医疗(2022年3期)2022-08-12
现代仪器与医疗(2022年2期)2022-08-11
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
读与写·教育教学版(2017年10期)2017-11-10
中国新通信(2017年9期)2017-05-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
