
基于随机扰动的过拟合抑制算法
2022-06-14 09:49李文举
计算机仿真 2022年5期
李文举,苏 攀,崔 柳
(上海应用技术大学计算机科学与信息工程学院,上海 201418)
1 引言
当前的深度学习模型为了在复杂多变的自然场景下得到的预测更为精准,通常在模型中使用多种网络结构和激活函数,使其能够从输入样本中提取出尽可能多的特征,这些模型在大型数据集上获得了较为优异的预测性能。但是当这样的大型网络模型在小数据集上进行训练时,由于可能存在很多冗余的特征,容易产生过拟合,从而导致模型预测性能不理想。当前针对模型的过拟合问题,主要是在模型的训练过程中对提取的样本特征采用一些正则化方法,例如:Dropout, 归一化[1-4]等,或是直接使用预训练权重进行初始化,然后在新的数据集上进行微调。
其中,Dropout和归一化方法主要针对样本的特征进行操作,除此之外,在2019年和2020年,Yang B[5]、Chen Y[6]分别提出了条件卷积和动态卷积,可以根据输入样本的特征对卷积核参数进行调整。
本文提出了RPM (Random Perturb Module) 模块,在训练过程中,通过向样本特征中添加随机扰动的方法帮助神经网络模型消除冗余特征并强化关键特征。使得网络能够学习到更好的网络权重并显著减轻过拟合。本文所提方法分别在两个交通标志识别数据集(CTSRD和GTSRB)以及一个目标检测数据集(PASCAL VOC 2012)上进行了实验。
交通标志识别对于自动驾驶具有重要意义,准确的识别交通标志可以帮助提升自动驾驶的安全性。然而传统的交通标志识别算法无法满足其对实时性和准确性的要求。随着深度学习的发展,交通标志识别模型的预测性能也得到了快速的提升。2020年,Wang J等[7]提出了一种基于残差网络[8]的交通标志识别算法,其使用ResNet18模型在CTSRD数据集上进行训练,最后获得了91.9%的识别精度。2021年,郑秋梅等[9]在交通标志识别任务中对ResNet34的残差块进行修改,并加入注意力机制,最终在GTSRB数据集上到达了97.7%的识别精度。本文在交通标志识别任务中分别使用了ResNet34和ResNet50两个模型以及其改进算法进行了实验。
目标检测是比图像分类更为复杂的视觉任务,在对目标进行准确分类的同时,还需要找出目标的准确位置。本文所提的RPM模块在经过充分优化的Faster R-CNN[10]、RetinaNet[11]、SSD[12]和YOLOv3[13]四个模型上进行了实验,这更能体现所提模型的有效性。
2 相关工作
2.1 网络训练与过拟合问题
近年来,深度学习模型在计算机视觉领域内占据着主导地位,随着研究的逐渐深入,提出了越来越多的适应不同视觉任务的网络结构,例如残差网络[8]、胶囊网络[14]、注意力机制[15,16]等,使得深度学习模型的学习能力越来越强大,在各种大型数据集上的表现越来越优秀。但是当这些大型模型在一些较小的数据集上进行训练时,在没有预训练权重的情况下就容易产生过拟合问题。
另一种产生过拟合的情况是,模型在长尾数据集上进行训练,样本较多的类别由于过度采样产生过拟合,样本较少的类别则产生欠拟合的问题,最终模型得到较差的预测性能。
过拟合产生的根本原因,是由于训练数据集和模型的学习容量不匹配,导致模型学习到了很多无关的特征,并错误的将其作为样本的必要特征。针对过拟合问题,主要有两种解决方案:一是在模型训练方法上进行改进,例如使用dropout网络层对神经元进行随机丢弃,或是利用在大数据集(例如ImageNet)上训练得到的网络权重进行初始化,然后在小数据集上进行微调,或是使用归一化层在一定程度上减轻过拟合,增强模型的泛化性能;二是直接对训练集进行数据扩充。
鉴于在某些场景下,获取高质量数据是非常昂贵的,因此本文提出了RPM模块,它可以向模型中添加随机扰动,从而减轻模型过拟合。
2.2 深度学习中的卷积计算
最近几年,卷积算子的动态性逐渐成为研究热点。2018到2019年,J Dai等[17,18]分别提出了可变形卷积算法的第一代和第二代算法,可变形卷积可以改变自身卷积核的形状,以适应不同形状的预测目标。Yang B等[5]等则提出了条件卷积,它可以根据输入特征计算卷积核的参数。2020年,Chen Y等[6]提出动态卷积,其可以根据输入样本对多个同一层级的卷积核进行融合并形成一个新的卷积核,然后对输入特征进行卷积。
3 RPM模块
由2.1节,过拟合的产生是由于训练数据集太小或类别样本数不一致而导致的,致使模型将非必要的特征错误的认定为必要特征。本文针对过拟合问题,提出了RPM模块,结构如图1所示,其中X表示输入特征图,Y表示输出特征图。在训练过程中,RPM模块可以通过扰动层(disturbance layer)向模型中添加随机扰动,强化样本的主要特征,弱化无关的冗余特征。
事实上,卡夫卡心中的父亲形象已经超越了一般的伦理概念范畴而开始具有宗教学、社会学等多个层面的含义,他把对父亲的感受和现实世界的运行机制关联起来,由此在他心中也形成了一种蕴含着极其复杂的社会文化内涵和个人情感的体验。卡夫卡的父亲形象与他所认知的世界有着深远的联系,对于父亲形象的描绘和建构,来自于卡夫卡作为一个敏感作家的亲身生存体验,也来自于他的文化记忆和积淀,成为了一个关于现实世界的绝妙比喻。这也是为什么在卡夫卡的许多作品中,世界就像是一个没有人能够窥视到全貌,弄清楚结构的错综复杂的迷宫,人们永远无法真正接近它,却又无时无处不感受到它的威严和压迫。
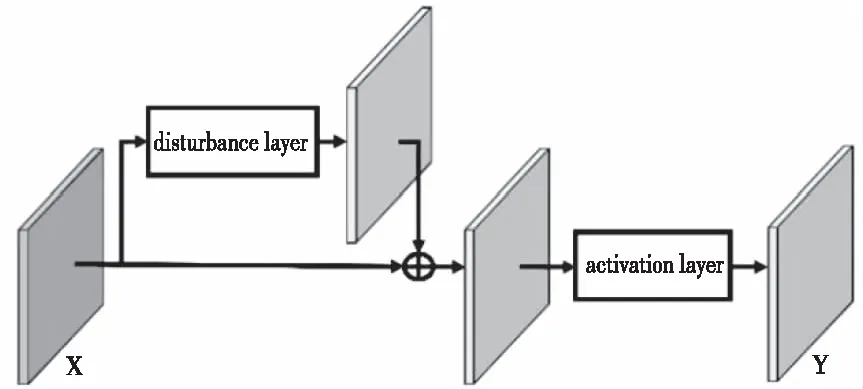
图1 RPM结构图
RPM模块可以根据输入特征计算均值,然后生成高斯分布的随机扰动张量,最后将扰动张量和输入特征图相加,得到输出特征图,如式(1)所示

(1)
其中,x表示RPM的输入特征图,y表示RPM的输出特征图,C是调节因子(默认为2.5),控制扰动的大小,g表示激活函数。随机扰动仅在训练时起作用,在模型的测试阶段不再使用随机扰动,因此对模型的推理速度没有影响。
4 实验结果和分析
这一部分内容对RPM模块在中国交通标志识别数据集CTSRD、德国交通标志识别数据集GTSRB和PASCAL VOC2012数据集上进行了实验。CTSRD是一个交通标志分类数据集,由中科院自动化研究所模式识别国家重点实验室提供,包含58个交通标志类别,共6164张交通标志图片,其中训练集包含4170张,测试集包含1994张;GTSRB是最常用的交通标志识别数据集,包含43个交通标志类别,超过50000张图片。
在交通标志的分类任务中,本文使用ResNet作为基础网络,并在每一个残差块的输出部分加入RPM模块。

图2 改进的残差模块
PASCAL VOC2012数据集是常用的目标检测、语义分割数据集,包含20个类别,17125张图片。本文的实验环境在表1中进行了说明。
表1 实验环境
4.1 交通标志分类实验
为了验证所提RPM模块的有效性,这一部分在ResNet34模型和ResNet50模型的残差块中加入RPM模块,在CTSRD数据集和GTSRB数据集上进行实验。训练时的参数设置如表2所示。

表2 实验参数
如图3所示,由于CTSRD数据集存在长尾效应,因此从CTSRD数据集的58个交通标志类别中挑选了45个类别,训练集中每个类别最少包含14个样本,最多包含446个样本。

图3 CTSRD数据集的类别样本数
由于长尾效应的存在,在训练模型时容易对样本较多的类别产生过拟合,而样本较少的类别产生欠拟合,如图4和图5所示,其中“ours_0”和“ours_1分别表示本文在ResNet34和ResNet50模型基础上加入所提的RPM模块的方法。可以看出,ResNet34和ResNet50模型仅在epoch为3之后就陷入了严重的过拟合。

图4 基于ResNet34模型的实验对比

图5 基于ResNet50模型的实验对比
当ResNet34和ResNet50不使用预训练权重进行初始化时,模型在训练集上的预测精度和测试集上的预测精度存在很大的差距,即存在过拟合现象。但是,当模型中加入RPM模块之后,模型最终在测试集上和训练集上预测精度的差距被缩小,即过拟合现象有所缓解。而GTSRB数据集由于不存在长尾效应,因此在这一数据集上训练得到的模型不存在过拟合问题,实验结果如表3所示,其中带“*”的模型表示使用了本文所提的RPM模块;“预训练权重”表示模型在开始训练之前,使用了预训练权重进行初始化;“随机初始化”表示模型在开始训练之前,权重仅进行随机初始化。无论是采用预训练权重进行初始化还是随机初始化权重进行训练,本文所提的算法均获得了更好的实验效果,其中使用预训练权重的 ResNet50*模型,在CTSRD数据集和GTSRB数据集上分类精度分别达到了96.9%和99.4%。
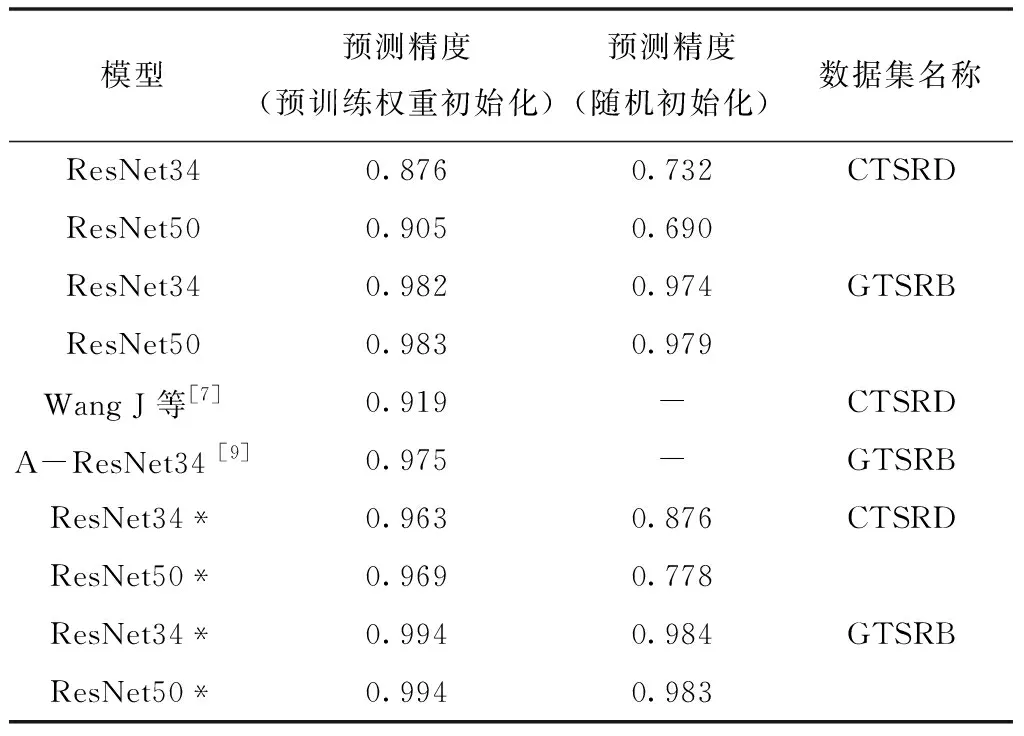
表3 交通标志数据集分类实验结果
实验表明,当模型不采用预训练权重进行初始化,同时数据集又具有长尾效应时,模型容易产生过拟合的问题。所提的RPM模块可以适当缓解模型的过拟合问题,并在一定程度上提高模型的识别精度。
4.2 目标检测任务
目标检测是一种比分类更复杂的视觉任务,不仅要求对图像中的目标样本进行分类,还需要找出目标所在的准确位置。为了更进一步说明RPM模块的有效性,本节分别在Faster RCNN[10],RetinaNet[11],SSD[12]和YOLOv3[13]模型中使用RPM模块进行训练,其中Faster R-CNN、RetinaNet和SSD模型均使用ResNet50作为主干网络,本文所提改进算法和4.1中的分类算法一致,即在残差块的输出部分加入RPM模块;YOLOv3采用Darknet作为主干网络,同样是在残差块的输出部分加入RPM模块。并针对PASCAL VOC 2012目标检测数据集进行了实验。实验时的参数设置如表4所示。
表4 目标检测任务实验参数
实验中所用RetinaNet,YOLOv3和Faster RCNN模型均采用在COCO 2014数据集上预训练的权重进行初始化,SSD模型采用英伟达提供的预训练权重进行初始化,然后在PASCAL VOC 2012目标检测数据集进行实验。由于受显存大小限制,SSD300和SSD300*的批大小设为8,RetinaNet和RetinaNet*的批大小设为2,YOLOv3和YOLOv3*的批大小设为4,Faster R-CNN和Faster R-CNN*的批大小设为4,带“*”的模型表示采用了RPM模块,表5和表6为对比试验结果。
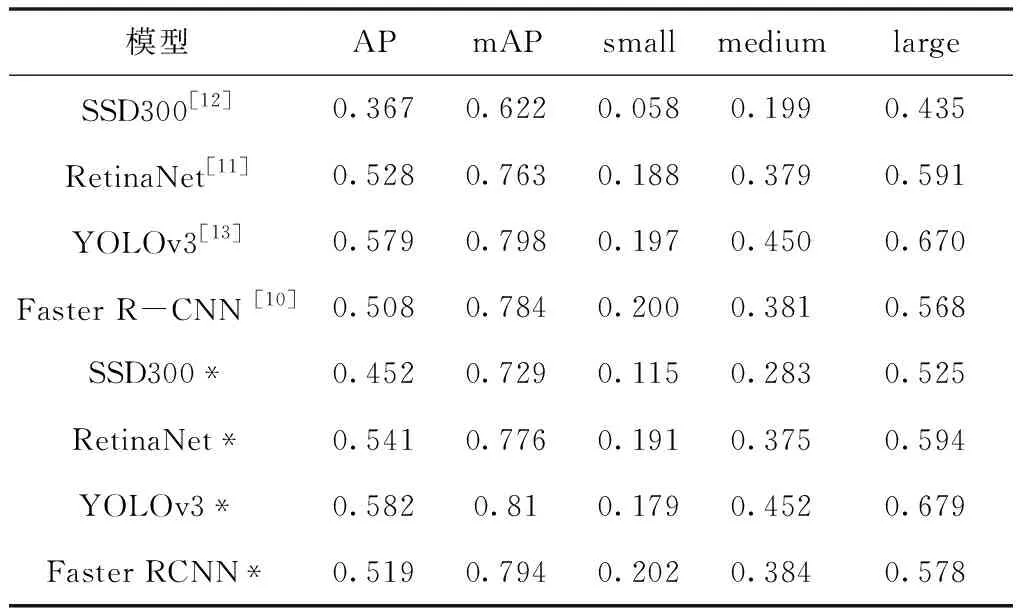
表5 目标检测模型的识别精度
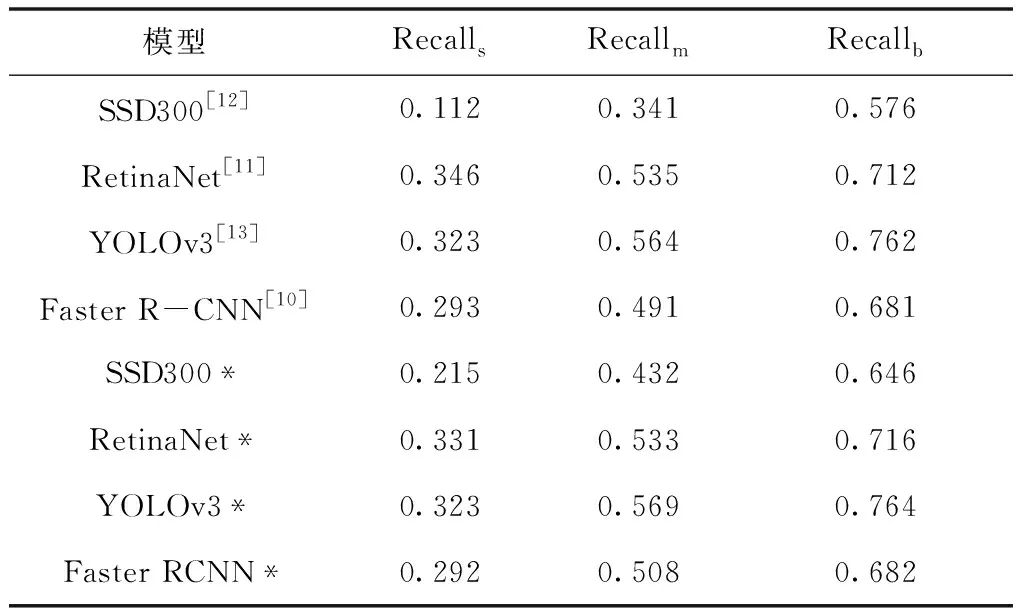
表6 目标检测模型的召回率
根据实验结果,在SSD300、Faster RCNN、YOLOv3和RetinaNet模型中加入RPM模块,使得的AP分别提升了8.5%、1.1%、0.3%和1.3%。RPM模块在SSD300模型上的性能提升最为明显,是因为其预训练权重是在Pascal VOC 2007数据集上训练得到的,这一数据集相比本文实验所用的Pascal VOC 2012数据集相对较小,因此随机扰动更有利于进一步提升模型的性能。而Faster RCNN、YOLOv3和RetinaNet则使用了COCO数据集上预训练的权重,这一数据集相比本文实验所用的Pascal VOC 2012数据集更大,样本复杂度也更高,因此在当前的数据集上进一步进行训练基本不存在过拟合的问题。
因此本文的实验表明,在网络训练过程中,对模型加上适当的噪声干扰可以减轻模型的过拟合问题,并在一定程度上提升预测性能。
5 结论
本文针对神经网络模型在小数据集和长尾数据集上训练容易产生过拟合问题,提出了RPM模块,在训练过程中给样本特征加入随机扰动,使模型可以获得更好的泛化性能。经实验表明,所提的RPM模块可以有效的减小模型在长尾数据集上训练造成的过拟合现象,而且即使是预训练模型,同样可以在一定程度上提高模型的预测性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年9期)2022-05-20
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
小天使·一年级语数英综合(2016年8期)2016-05-14
文苑(2015年9期)2015-09-10
小天使·一年级语数英综合(2014年7期)2014-06-26
新课程学习·中(2013年3期)2013-06-14
中学数学研究(2008年3期)2008-12-09
