
用于智能垃圾分拣的注意力YOLOv4算法
2022-06-09 11:59龚远强刘德峰梅文豪
计算机工程与应用 2022年11期
李 庆,龚远强,张 玮,张 洋,刘 超,李 军,韩 丹,刘德峰,梅文豪,董 雪
1.上海交通大学 中英国际低碳学院,上海 200240
2.海安上海交通大学智能装备研究院,江苏 海安 226600
3.中国天楹股份有限公司,江苏 海安 226600
随着经济的不断发展和人民生活水平的提高,我国生活生产垃圾清运总量逐年上涨,给市民的生活和生态环境保护都带来了一定压力,因此垃圾处理问题迫切需要得到有效的解决。目前垃圾处理主要包括填埋、焚烧发电、生物处理及资源化利用四种手段,其中垃圾填埋占用大量土地资源,垃圾焚烧则造成严重的空气污染。因此对垃圾进行资源化利用已成为趋势,其中智能可回收垃圾分拣系统因能高效地完成分拣任务、加快资源的回收利用而受到广泛关注。
世界上第一个机器人垃圾分拣系统由芬兰的ZenRobotics公司研发,该系统从众多建筑垃圾中识别出可回收利用的物料,并通过机械臂分拣出需要的建筑垃圾。ZenRobotics垃圾分拣系统中传感器包括:三维激光扫描仪、金属探测器、NIR-近红外光谱传感器、可见光谱传感器、高分辨率RGB摄像头等。种类丰富的传感器为ZenRobotics提供了完善的感知信息。ZenRobotics分拣系统在24小时持续工作的情况下一天能够处理约1 000吨建筑垃圾,极大地提高了垃圾分拣和回收利用的效率。而针对建筑垃圾研发的ZenRobotics分拣系统无法用于分拣我国种类繁杂的生活可回收垃圾,且ZenRobotics分拣系统丰富的传感器配置也大大提高了它的成本,限制了它的大规模应用。英国的威立雅环境服务公司研发了一款名叫magpie的垃圾分拣机器人,该款垃圾分拣机器人使用红外线扫描识别垃圾种类,并通过喷射高压气体对垃圾进行分拣回收,这种方法分拣操作简单,但其分拣功能单一且分类结果混乱,难以进行产业化的推广应用。
近年来基于深度卷积神经网络(CNN)的视觉目标检测算法发展迅猛,在自动驾驶、遥感、工业检测等领域均得到了普遍应用。主流的视觉目标检测算法分为一阶段和二阶段两大类,其中二阶段网络主要以Faster RCNN及其变种为主,这类网络通常使用RPN(region proposal network)初步生成目标框,以供最终分类及定位。相比之下,一阶段视觉目标检测模型结构简洁,在工业界得到了广泛的应用。比较著名的一阶段目标检测算法有SSD[1]、YOLO[2]、RetinaNet[3],其中,RetinaNet提出的Focal Loss解决了一阶段网络正负样本不均衡的问题,提高了一阶段网络的精度。YOLOv4[4]网络从网络结构、激活函数、损失函数及数据增强等诸多方面对YOLO网络做出了改进,极大地提高了原网络的精度。
当前,学术界在垃圾检测领域已开展了一系列研究,例如Mikami等人[5]使用SSD算法对垃圾袋进行检测,算法取得的垃圾袋识别平均精度(average precision,AP)为62%。Awe等人[6]应用Faster R-CNN模型对纸张、可回收垃圾及填埋垃圾进行分类,Awe等人使用的数据集为2 500张垃圾图片,数据集中的标注信息为垃圾种类,最终算法取得的平均精度为68%。Yang等人[7]提出了一种基于GoogLeNet的深度学习算法来定位和分类城市垃圾,研究表明算法针对不同类别的垃圾有63%到77%的平均精度。Donovan等人[8]提出了一个使用Tensorflow深度学习框架及摄像头来自动分类垃圾进行回收的系统,遗憾的是,作为一个概念上的项目,Donovan等人并没有给出实验性的结果。Zhang等人[9]收集了681张街道的垃圾图片作为数据集,使用Faster-RCNN模型基于该数据集进行训练,其模型平均精确度为82%。Liang等人[10]建立了一个含有57 000帧图片的垃圾目标检测数据集,基于该并数据集提出了一个多任务学习模型,在IoU为0.5阈值下模型平均精确度达到了81.5%。遗憾的是,Liang等人提出的数据集中四个类别分别为有机垃圾、可回收垃圾、有害垃圾和其他垃圾,数据集并未对可回收垃圾进行进一步的细分类别。袁建野等人[11]基于ResNet18模型开发了轻量的注意力目标检测网络,在2 340张的可回收垃圾数据集上进行训练及验证,最后模型精度在单类别最高达到了89.73%。Ma等人[12]介绍了一种LSSD算法,以克服SSD[1]算法小目标丢失及尺度不一的检测框同时检测单一目标的缺点,建立了一个在多尺度上检测性能更强的特征金字塔,且用Focal Loss函数解决了单阶段目标检测方法正负样本比例严重失衡的问题。然而,该工作所用数据集缺乏遮挡及多目标场景,且网络参数量大,因此离实际应用还有一定距离。Kumar等人[13]建立了一个含6 317张图片的数据集,基于此数据集训练其YoLov4网络,模型平均精度达到94.99%。然而此项研究建立的数据集同样存在场景简单及单张训练图片目标数量少的问题,模型在遮挡及多目标场景下的具体表现还有待考量。总而言之,基于CNN的目标检测算法在可回收垃圾检测领域的研究尚不够充分,且存在数据集规模小、数据集中类别少、算法泛化性能差[5-7,9,11-13]以及对垃圾的视觉特征研究不充分[5-10]等缺点。针对数据驱动的深度学习算法,为了提高算法本身的泛化能力及识别性能,亟需建立一个大规模的可回收垃圾目标检测数据集以满足算法的研究和实际可回收垃圾识别的需求。
为了解决可回收垃圾数据规模小、算法泛化性能及垃圾视觉特征研究不充分的问题,本研究建立了一个大规模的可回收垃圾目标检测数据集,并基于YOLOv4算法提出了Attn-YoLov4模型,在模型骨干网络后加入注意力模块,对特征图从通道及空间上进行重新加权,提高了模型的检测精度,Attn-YOLOv4模型在速度及参数量和YOLOv4模型相当,而其在可回收垃圾数据集上的表现则超过了YOLOv4原网络。
然而,基于CNN的目标检测算法虽然能够获得较好的检测精度与速度[5-6,14-15],但其也存在检测不稳定的现象,时有漏检和误检的出现。而一旦出现漏检及误检,系统的实际分拣效果将大打折扣。为此,本研究借鉴了计算机视觉中的目标跟踪算法,与传统单目标跟踪及多目标跟踪算法的应用场景不同,垃圾分拣流水线上目标稠密且时刻运动,这给跟踪算法的设计带来了很大的困难。SORT[16]和DEEPSORT[17]是当前主流的多目标跟踪算法,它们都基于卡尔曼滤波对物体运动进行预测,这类算法比较依赖目标检测的性能,一旦检测中出现漏检,跟踪算法就很容易出现ID切换,从而导致机械臂抓取目标物体时候重复抓取,严重影响抓取效率。考虑到传送带上物体运动简单,物体本身形变少,基于视觉特征的单目标跟踪方法更为适合当前应用场景。
基于视觉特征的单目标跟踪算法自身能够维持对跟踪框的预测与更新,它只需要目标检测提供一帧的边界框信息进行初始化,即便目标检测算法表现不稳定,它也能保持一个较好的跟踪效果。近年来,MOSSE[18]、KCF[19]及CN[20]等相关滤波类算法表现突出,在速度及精度方面都获得了很好的表现。其中,KCF算法针对MOSSE算法中特征通道为单通道的缺点,使用HOG特征进行跟踪,并使用循环矩阵生成样本训练回归器,提高了训练样本量,并利用循环矩阵傅里叶变换对角化的性质大大降低了计算量,使跟踪速度达到实时。然而,学术界仅仅提出了单目标跟踪相关滤波类算法,对跟踪多个目标、目标删除以及跟踪失败如何处理等问题并没有后续研究。本研究设计了一套基于相关滤波类算法的跟踪框架,对多目标的跟踪、预测、更新及删除策略做了细致的讨论,实现了基于相关滤波类算法的稳定跟踪并评估了其跟踪效果。
本文对垃圾分拣系统的视觉处理算法做了细致的讨论,并给出了相关的实验验证及评估。最终,本研究建立了一套完整的针对可回收垃圾的计算机视觉处理方案,通过整合检测、跟踪、标定和定位等多个模块,以单目相机作为信息输入,实现了对物体的精确识别及视觉定位以及对分拣流水线上可回收垃圾的智能化处理,相比人工大大提高了垃圾分拣的效率。
1 系统构建
1.1 系统整体框架
可回收垃圾智能分拣系统由物料传送装置、视觉信息采集、视觉信息处理、末端执行等模块组成。其中视觉信息采集模块使用单目相机获取传送带上的物料信息,该模块由相机硬件及相应驱动软件实现,获取清晰稳定的图像信息是视觉信息处理的必需条件。综合考虑相机成本、成像质量及使用场景需求,本研究选用英特尔RealSense D435相机实现整个系统的视觉感知。视觉信息处理模块功能框架如图1所示,该模块由目标检测、目标跟踪及后处理部分组成,其中目标检测算法为端到端的深度卷积神经网络,网络输出为边界框的四个坐标,输出值分别是像素平面中的l x、l y、r x及r y。深度卷积神经网络通过学习数据分布来获得数据特征的表征,其泛化能力及检测性能依赖于所采用的数据集质量。因此,想要获得较强的网络泛化能力,不仅需要合理的网络结构设计,还需要进行超参数优化和数据增强,更重要的是建立丰富且完备的可回收垃圾数据集。数据集的建立需要考虑实际生产中会遇到的困难样本,对遮挡、破损、垃圾污渍、低光照等垃圾数据进行全面的采集。目标跟踪模块对多帧目标检测输出的边界框进行关联,确定相邻帧间目标ID,防止因漏检和误检导致执行阶段的漏抓和误抓。视觉信息后处理对跟踪的边界框进行角度计算,为末端执行模块的夹爪式执行器提供位置和角度信息。
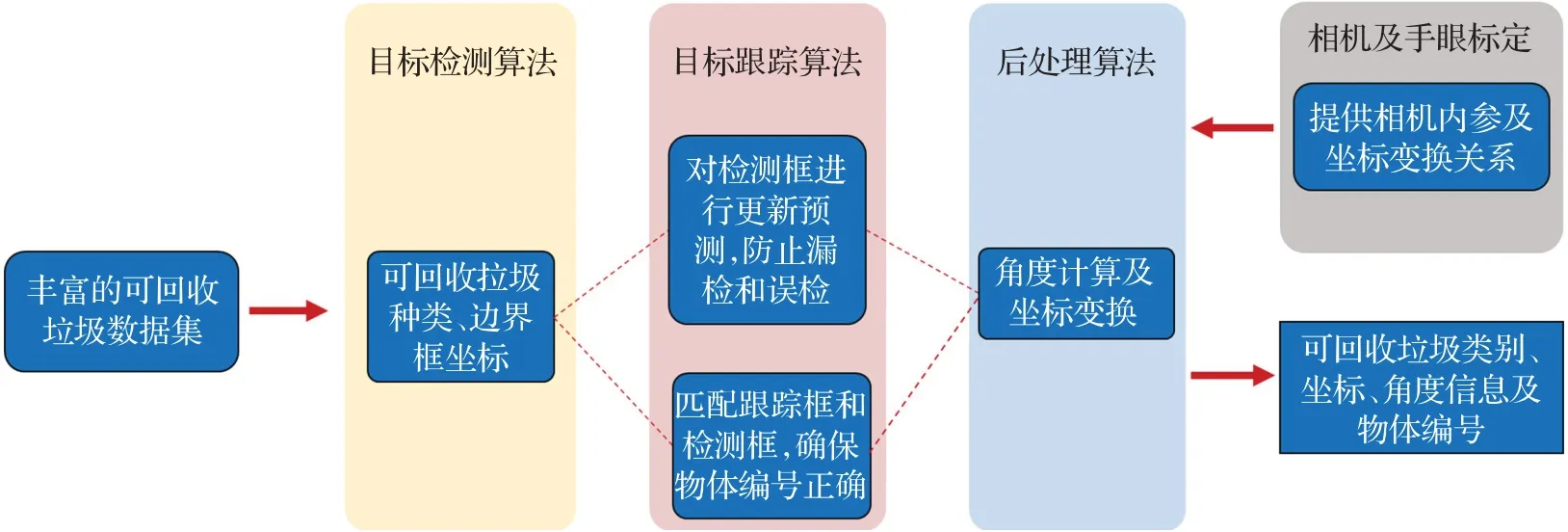
图1 分拣系统框架示意图Fig.1 Schematic diagram of sorting system
上述视觉信息处理模块所做的检测及跟踪均为像素层面的视觉处理,末端执行模块中机械臂对垃圾的分拣操作则需要进行姿态解算以获取垃圾在世界坐标系的定位。像素平面坐标系到机器人基座坐标系的坐标变换矩阵通过两次标定获得,首先需要对相机进行标定以获取相机内参数,相机内参数表示了像素坐标系和相机坐标系间的坐标变换关系;其次需要对机械臂和相机进行手眼标定获得相机坐标系和机器人基座坐标系间的坐标变换关系。最后通过传送带为平面的基本假设求解PnP(perspective n points)问题,以获得传送带到相机的坐标关系,进而通过垃圾在像素平面中的坐标计算出垃圾在机器人基座坐标系下的实际坐标。本研究通过ROS(robot operating system)搭建了上述各个功能模块,实现了模块间的实时通信,最终工控机将垃圾位置通过网络通信发送给机械臂,由机械臂完成对垃圾的分拣。
1.2 可回收垃圾数据集的建立
为提高基于机器视觉的垃圾识别算法的精度,并增强识别模型在实际垃圾分拣场景中的适应能力,本研究在中国多个垃圾分拣厂的流水线上安放了摄像头,拍摄并标注了分拣流水线上的可回收垃圾实景图片36 572帧。为了保证模型的泛化能力,确保检测算法识别精度,本研究采集了不同光照下的可回收垃圾图片,且涵盖的垃圾种类丰富,包括各种颜色的PET、HDPE、PP、PVC、金属可回收垃圾、织物、玻璃、纸类等。数据集中的图片分辨率为1 920×1 080,白天及夜晚两种不同光照条件下的数据各占50%。数据集划分了训练集和测试集,训练集和测试集的图片数量比例为4∶1,数据集中可回收垃圾类别为13类,分别是Plastic_PET_White、
Plastic_PET_Blue、Plastic_PET_Green、Plastic_HDPE_White、Plastic_HDPE_Blue、Metal_Al_Can、Metal_Fe_Can、Glass_Bottle_White、Plastic_PP_Green、Plastic_PP_White、Plastic_PP_Red、Paper及Textile。数据集类别分布如图2。
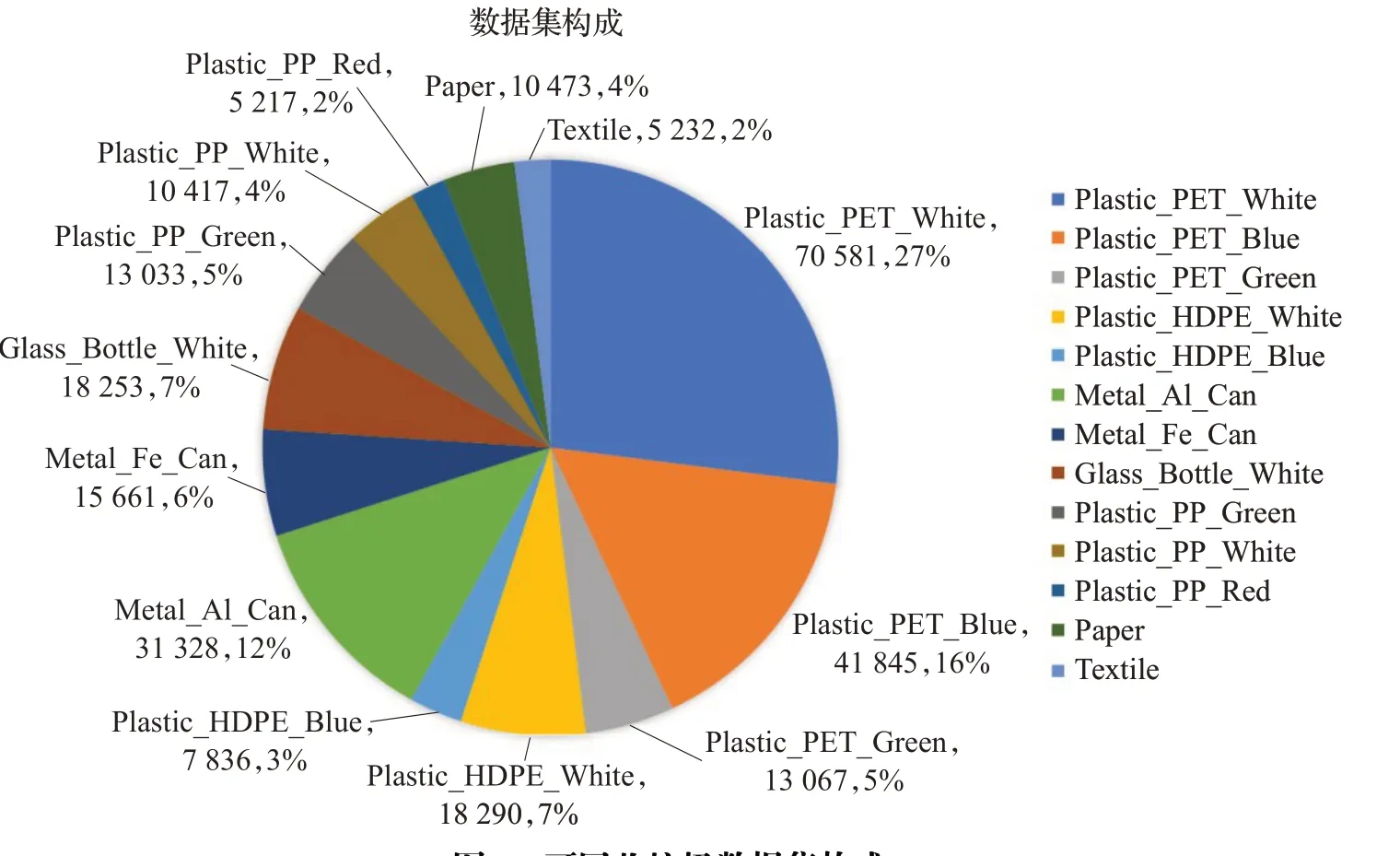
图2 可回收垃圾数据集构成Fig.2 Composition of recyclable garbage dataset
数据集中图片上每个物体都有对应的精确标注信息,标注格式同COCO数据集格式相同,数据集中标注图片样例见图3,标注信息有垃圾的边界框及垃圾类别。数据集中所有垃圾类别均为分拣流水线上的采集的生活类小型可回收垃圾,不包含大型的金属及塑料制品如电器、工厂废铁等。图4展示了数据集中部分图片示例。

图3 数据集中部分标注样例Fig.3 Sample annotations in dataset

图4 数据集中图片示例Fig.4 Samples in dataset
1.3 视觉处理方法
1.3.1 垃圾识别深度学习模型的构建及训练
为了提高模型识别效果,本研究对一阶段模型YOLOv4的网络结构做出改进,提出了Attn-YOLOv4,即在YOLOv4网络的分支网络中添加注意力机制以进行信息整合。本文在算法中加入了两种注意力模块并进行了实验验证,其中SENet[21](squeeze-and-excitation networks)注意力网络结构如图5,该网络通过全局平均池化、全连接层及激活函数获取每个特征通道的权重,从而提高重要特征通道权重并抑制无关特征,由此提高目标检测网络精度。CBAM[22](convolutional block attention module)注意力网络结构如图6所示,该网络通过Sigmoid激活函数对不同通道层进行相应的权重计算,对重要程度不同的单通道特征图乘以不同的权重,使模型更注重于一些特定的通道,提高模型提取特征及信息整合的能力。CBAM方法综合考虑了通道和空间层面的注意力机制,CBAM的channel attention module对通道进行重新加权,而其spatial attention module则针对特征图上每个像素进行了加权,从而使得网络特征图中有物体的区域权重提高,进而提高了网络的检测精度。
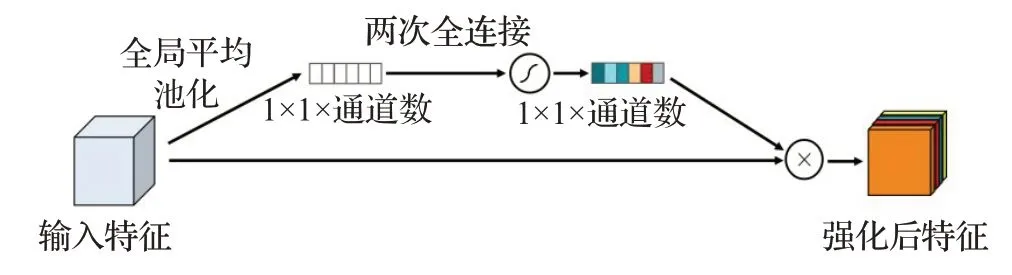
图5 SENet模型示意图Fig.5 Schematic diagram of SENet
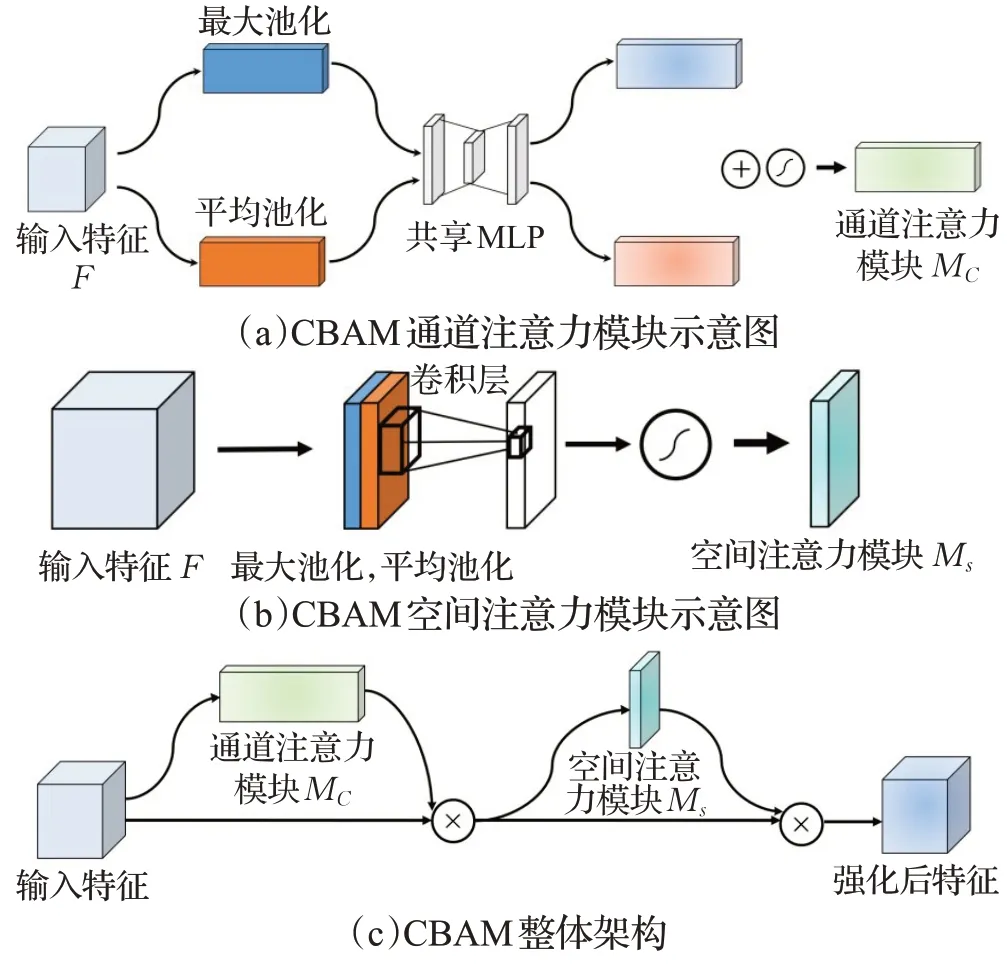
图6 CBAM模型示意图Fig.6 Schematic diagram of CBAM
图7说明了注意力模块添加的位置以及最终的网络结构,本文通过在YOLOv4骨干网络输出的不同分支添加注意力模块,使网络具备对不同级别特征图进行信息整合的能力。并且本文将CBAM模块放置在CSPDarknet53网络后避免了对主干网络结构的修改,通过迁移学习使用预训练权重进行训练,省去了在ImageNet等数据集上进行大规模数据预训练的时间,大大提高了训练效率,进而加快了模型部署的流程。
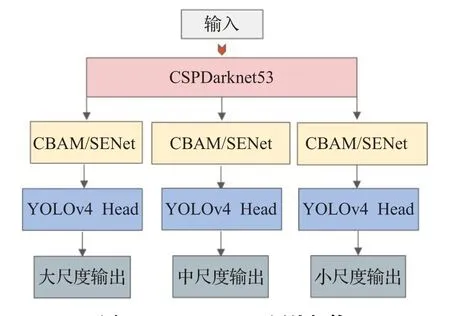
图7 Attn-YOLOv4网络架构Fig.7 Network architecture of Attn-YOLOv4
本文中深度学习网络的训练环境为CentOS 7.4,使用Pytorch框架进行训练;算力为8块NVIDIA Ge-Force GTX 2080Ti GPU显卡。网络训练使用标准的随机梯度(stochastic gradient descent,SGD)训练模型,批量大小(batch size)设置为64,基础学习率为1.25×10-5,动量(momentum)为0.95,重量衰减(weight decay)为0.000 5,训练50个epoch。为了处理数据集中样本不均衡问题,本研究在训练中对少样本类别做了重采样处理,此外为了增强模型鲁棒性及泛化能力。本文采用多种数据增强策略随机组合+Mosaic[4]的方式进行数据扩充。针对流水线上可回收垃圾的污损、变形、运动模糊、亮度变换等场景,本研究引入了以下数据增强策略:水平翻转、垂直翻转、裁剪、仿射变换、高斯模糊、中值滤波、自适应高斯噪声、Dropout(随机移除一定比例像素)、亮度变换、HSV通道变换等。将上述数据增强策略随机组合后对训练样本进行处理。图8展示了数据集中原始样本图片及标注边界框的可视化结果。

图8 数据集中原始图片及边界框可视化结果Fig.8 Original image in dataset and bounding box visualization results
如图9展示了随机组合的数据增强策略生成的多个训练样本。

图9 随机数据增强示意图Fig.9 Diagrams of random data augumentation
最后本研究引入Mosaic数据增强,随机选取四张经上述随机数据增强策略处理后的图片进行裁剪和拼接,将生成的图片及标签作为训练集供模型训练。如图10为马赛克数据增强示意图[4]。

图10 Mosaic数据增强示意图Fig.10 Mosaic data augmentation
如图11为训练过程中整体的数据增强策略,每个batch的训练数据经数据增强后可以得到4×batch size个训练样本,相当于原有数据集规模的四倍,极大提高了模型的泛化能力。
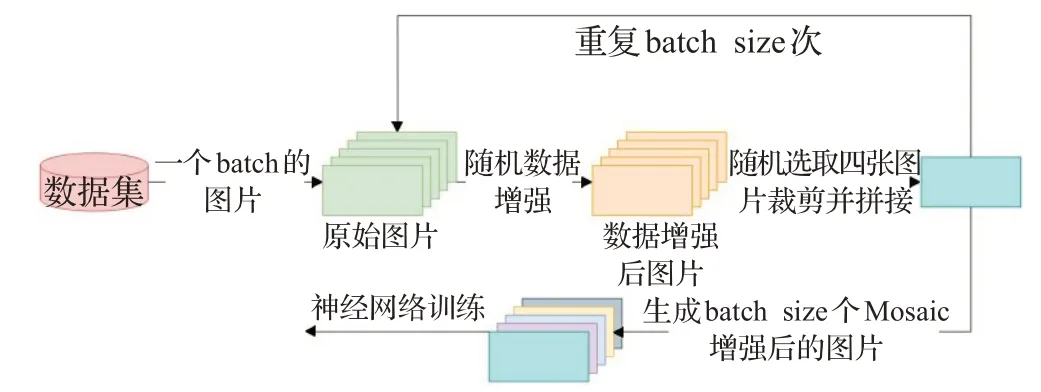
图11 整体数据增强策略Fig.11 Overall data augmentation strategy
1.3.2 目标跟踪
对传送带上多个目标物体的跟踪可由基于多线程的单目标跟踪或者多目标跟踪实现,本研究中末端执行模块对于目标跟踪的要求为边界框跟踪稳定、ID切换少。部分多目标跟踪算法如SORT[16]和DEEPSORT[17]使用卡尔曼滤波对物体运动进行预测,并对跟踪框和目标检测框进行相似度计算以匹配。SORT和DEEPSORT算法比较依赖目标检测算法的性能,目标检测出现的连续漏检及误检很容易导致跟踪算法出现ID切换,从而导致机械臂抓取目标物体时候重复抓取,严重影响抓取效率。
基于视觉特征的单目标跟踪较为简单且不依赖于目标检测的性能,只要有一帧图像被检测到,跟踪器便能初始化并随时间不断更新跟踪框位置。作为单目标跟踪算法的一种,KCF算法跟踪稳定性高,速度快[19],因此本研究采用基于多线程的单目标跟踪算法KCF。本研究使用线程池[23]来管理线程,保证了线程的可复用性,减少了系统开销。
基于多线程的KCF跟踪算法流程如图12,首先使用检测物体和跟踪物体间的IoU作为度量,通过匈牙利算法对跟踪边界框和检测边界框进行匹配,跟踪算法更新匹配后的跟踪框位置并进行后续处理。
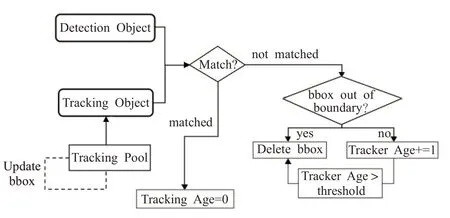
图12 跟踪流程框图Fig.12 Object tracking process
本研究使跟踪器维持一个表征“跟踪器寿命”的变量Tracker Age,该变量定义及更新策略如下:变量初始值为0,当跟踪框匹配上了检测框,KCF更新跟踪框位置并将该变量置0。当跟踪框未匹配检测框,KCF更新跟踪框位置并将该变量加1,当该变量值大于预设定阈值时,则视为跟踪失败,从而将该跟踪器删除。这种策略可以有效减少目标检测漏检导致的ID切换。
1.3.3 角度计算
在部分应用场景下需要使用夹爪对垃圾进行分拣操作,Ku等人[24]使用深度学习算法来搜索可供抓取的物体矩形框,他们对RCNN和auto-encoder两种算法的表现进行了评估,结果表明两种算法分别获得了96%及94%的抓取精度。然而Ku等人使用的深度学习算法需要人工标注大量的抓取矩形框供算法训练,这极大提高了研发成本,且基于深度学习算法的抓取角度计算势必会带来一定程度的时延,降低系统的分拣效率。
本研究提出了一种高效、快速的可回收垃圾角度计算方法如图13,角度计算步骤如下:(1)对跟踪框框出的图像进行裁剪。(2)得到裁剪后的灰度图,对灰度图进行中值滤波,消除图像噪点。(3)随后对灰度图进行图像二值化处理,图像二值化可以对垃圾和单色传送带背景做出初步区分。(4)对图像做形态学处理,先进行膨胀操作随后进行腐蚀,用以使被黑色分割开的白色感兴趣区域联通。(5)一个裁剪后的灰度图上可能存在多个区域的最小外接矩形。求解不同最小外接矩形和跟踪框的IoU,选取IoU最大的外接矩形框为包围瓶身的最小外接矩形。(6)求解得出包围瓶身的最小外接矩形的角度信息后,通过坐标变换可获得机器人基座下的角度。
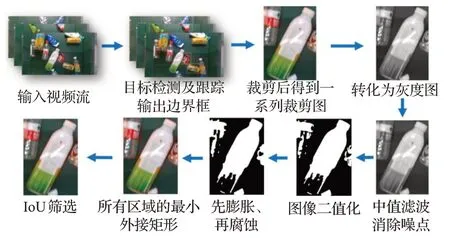
图13 角度计算流程Fig.13 Angle calculation process
1.4 执行系统搭建
为了实现对可回收垃圾的快速高效分拣,本系统采用了两个分拣工位分别使用不同型号的机器人与执行器进行垃圾的分拣工作。其中分拣流水线前端机械臂为ABB公司的IRB 360机器人,该款机器人采用并联结构,执行时间短。本系统使用ABB公司的IRB 1600六轴机器人搭配夹爪对传送带上剩余的小部分瓶状垃圾进行补抓。两款机器人实际分拣场景如图14所示。

图14 机器人实际分拣场景Fig.14 Actual robot sorting scenario
本研究使用ROS搭建了整个系统的消息通信框架,各节点间消息传递关系及消息内容如图15所示。目标检测节点接受相机节点发布的RGB图像,图像通过Attn-YOLOv4网络进行前向推理得到目标置信度、边界框的像素坐标及物体的类别信息。跟踪节点通过1.3.2节所述跟踪过程得到边界框坐标、物体ID及物体类别信息,并将它们发送给后处理节点。后处理节点进行角度计算及坐标变换,并将相应消息发送给机器人控制器,最终由机器人通过垃圾的角度及位置信息执行分拣操作。

图15 ROS节点示意图Fig.15 Diagram about ROS nodes
2 结果与讨论
表1展示了两种Attn-YOLOv4神经网络及原始版本的YOLOv4在测试集上的表现,测试使用的IoU阈值为0.5,不同类别的AP在表1中已列出。结果表明YOLOv4模型的mAP为98.82%,使用SENet模块的Attn-YOLOv4算法相比YOLOv4算法在多个类别上取得了更好的识别精度,模型的mAP为98.88%,而使用了CBAM模块的Attn-YOLOv4算法在绝大多数类别下相比其他算法都取得了更好的表现,模型mAP为98.98%。三类目标检测模型的参数量、浮点计算量及在RTX 2080Ti工控机上计算速度对比见表2。由表可知,由于注意力模块参数量很少,引入的额外计算量少,使得模型推理速度几乎不受影响。基于注意力机制的YOLOv4神经网络在RTX 2080Ti上的运行速度为38 frame/s,满足了分拣系统的实时检测需求。
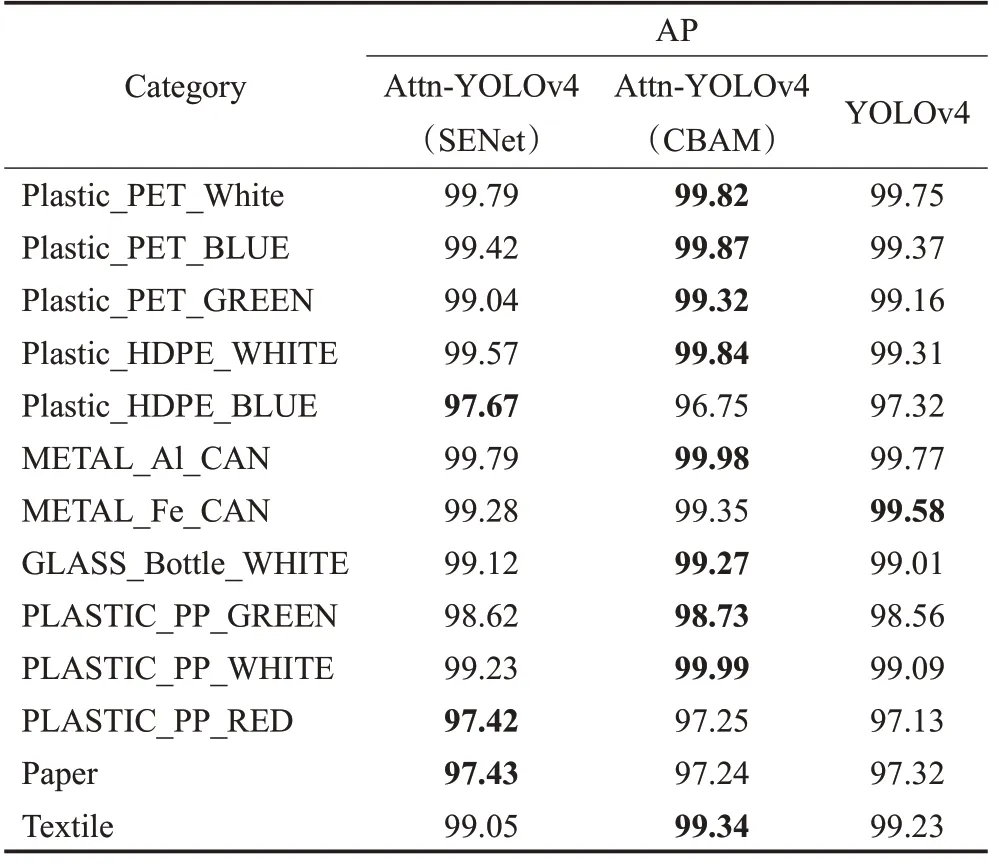
表1 模型评估结果Table 1 Module evaluation results %
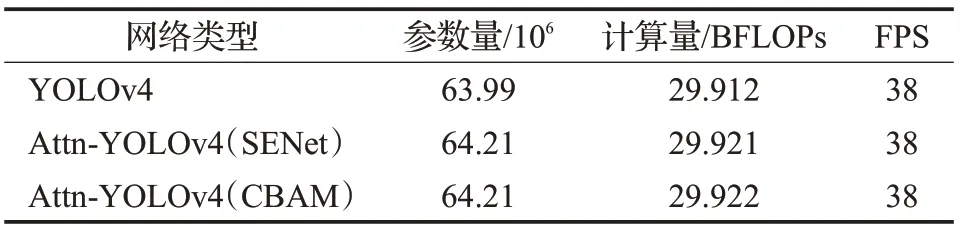
表2 模型复杂度量化结果Table 2 Model complexity measurement results
为了量化基于KCF的目标跟踪效果,本研究使用单目标跟踪领域常用的精确度曲线[19,25-27]来表征跟踪的误差与精度。准确度曲线显示了一个距离阈值范围内正确跟踪帧的百分比,低阈值下的更高精度意味着跟踪器更精确,而跟踪丢失的目标将降低它在较大的阈值范围内的精度。为了评估KCF跟踪算法在传送带上的实际误差及精度,本研究将精确度曲线横轴设置为经过坐标变换后的传送带上实际误差阈值,单位为毫米。通过在传送带速度为2 m/s的实际分拣流水线上对时长为30 min的跟踪误差进行统计,绘制出如图16的精确度曲线。本研究提出的基于多线程的KCF跟踪算法平均速度达到了120 frame/s,满足了实时跟踪的需求,且在20 mm误差范围内达到了0.945的精确度,满足了分拣系统的分拣精度需求。
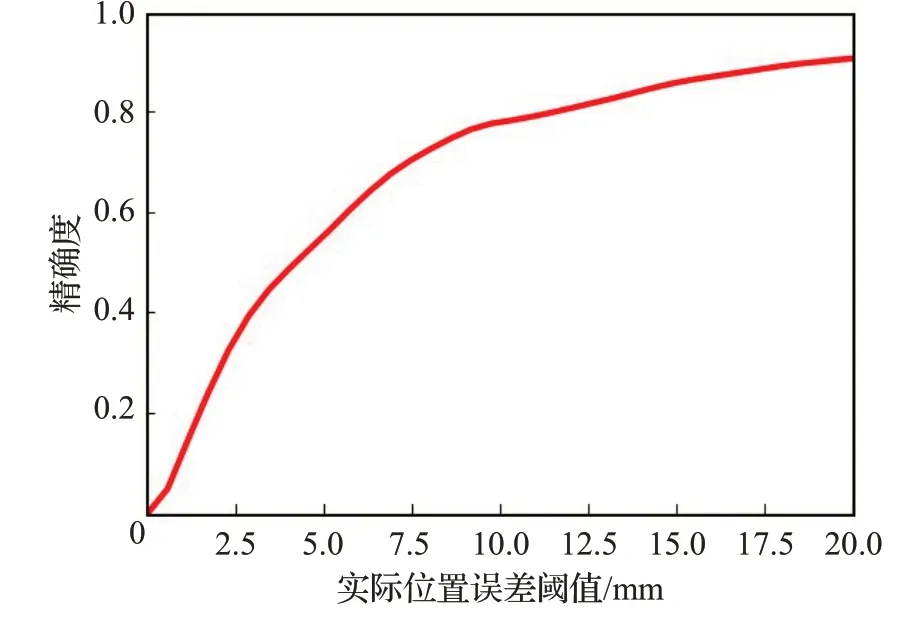
图16 KCF跟踪精确度曲线Fig.16 KCF tracking accuracy curve
对于大部分可回收垃圾而言,垃圾分拣系统使用吸盘分拣Attn-YOLOv4检测到的物体,对于表面易出现凹凸不平的易拉罐等物体,则使用第1.3.1节所述基于最小外接矩形的角度计算方法,为夹爪式末端执行器提供角度信息。本研究选取两个类别的物体各10个,每个物体旋转角度及放置区域随机,每次测量20次,计算角度误差并分类别计算平均值。经实验测量,产线所用夹爪夹取垃圾所需角度误差应小于30°。对实验结果进行统计后发现各类别的角度误差平均在10°以内,完全满足夹爪夹取的精度需求,结果见表3。此外,目标角度计算的精度还受标定矩阵准确性影响。

表3 角度误差统计结果Table 3 Results of angle error
最后,本研究在传送带上连续投放高密度垃圾以测试可回收垃圾分拣系统整体效果,表4给出了可回收垃圾分拣系统实际运行时的性能表现。IRB 360机器人执行速度快、使用吸盘进行吸附,造成分拣失败的主要原因为物体表面凹凸、吸盘无法吸附,IRB 1600分拣速度较慢但工作稳定,可以实现对可回收垃圾的稳定夹取。值得指出的是本文的分拣系统前端进料处机械装置可将垃圾均匀地铺在传送带上,较好地防止了重叠目标的出现。因此本文中的跟踪及抓取结果不包含重叠目标。

表4 机械臂实际分拣测试Table 4 Robot sorting test results
本研究提出的基于计算机视觉的可回收垃圾分拣系统分拣准确率达到了90%以上,Delta机器人的分拣速度可达5 700次/h,六轴机器人的分拣速度达到了1 600次/h,分拣系统具备了在复杂环境下高效、稳定进行可回收垃圾的识别及检测能力。此外,本研究构建的可回收垃圾分拣系统对快递物流、工厂流水线等生产环境中的无人分拣系统也有一定的借鉴意义。
3 结论
本研究建立了一个含36 572帧图片的可回收生活垃圾目标检测数据集,涵盖了可回收生活垃圾的常见类别,包括PET塑料、HDPE塑料、PP塑料、铁制品可回收垃圾、铝制品可回收垃圾、纸张类可回收垃圾及织物类可回收垃圾等。基于此数据集,本文对一阶段深度视觉检测方法进行注意力相关机制研究,研究结果表明,Attn-YOLOv4通过在其骨干网络的三个分支添加注意力模块,相比YOLOv4模型取得了更好的性能,多个类别的可回收垃圾识别精度提高幅度在0.2%到0.9%之间,且带来的速度影响很小。最优化的模型在各类别中的识别精度在测试集上的表现接近了100%的AP。此外,本研究还建立了一套针对动态环境和稠密目标的视觉识别和跟踪系统,通过目标检测、跟踪与匹配及相机标定,实现了对传送带上物体的精确定位及角度计算,跟踪的精确度在20 mm的误差范围内达到了0.945,角度计算误差在10°以内。最后,本研究在连续、高密度进料的传送带上测试了整个可回收垃圾分拣系统的分拣速度及分拣准确率,结果表明本文提出的分拣系统的最大分拣速度达到了5 700次/h,且分拣精度在90%以上,达到了学术界领先水平。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
一重技术(2021年5期)2022-01-18
科普童话·学霸日记(2021年2期)2021-09-05
当代陕西(2019年24期)2020-01-18
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
小太阳画报(2018年10期)2018-05-14
汽车与新动力(2012年1期)2012-03-25
