
基于多特征融合的轻量化无锚人脸检测方法
2022-06-09 11:59黄思维李志丹程吉祥刘安东
计算机工程与应用 2022年11期
黄思维,李志丹,程吉祥,刘安东
西南石油大学 电气信息学院,成都 610500
人脸检测是指在输入图像中确定所有人脸的位置、大小和位姿的过程,是人脸信息处理中一项关键技术。目前,人脸检测技术已成为计算机视觉领域研究十分活跃的课题[1],并广泛地应用于公共安全、企业办公、教育和人机交互等领域。
现有人脸检测方法可分为传统方法和基于深度学习的方法。传统的人脸检测方法普遍基于人工特征提取[2]或增强学习算法[3],这些方法依赖于人工提取的特征且需要对检测模型的各个组件进行单独优化,虽然在实时性和可移植性上都有不错的表现,但其计算过程复杂、对于复杂场景下检测准确率仍较低的不足限制了这类方法的广泛运用。深度学习是近年来机器学习领域的研究热点之一并在目标检测、计算机视觉、自然语言处理等各领域成效卓然[4],深度学习算法通过深度卷积神经网络处理计算机视觉类任务,它将特征提取、特征选择和特征分类融合在同一模型中,从整体上进行功能优化,增强了特征的可分性,显著提升了各类视觉任务的准确率[5]。
当前人脸检测方法使用深度卷积神经网络进行特征提取,这些网络称为骨干网络(backbone)。为提取更为丰富的特征,研究者们设计出层次更深、结构更复杂的骨干网络。根据使用场景不同,可将骨干网络分为两类:其一为注重检测准确性的深度网络模型,以VGG[6]和ResNet[7]等为代表,其二为注重降低模型复杂度的轻量化网络模型,其典型网络为MobileNets[8]和ShuffleNet[9]。采用高效的特征提取网络,近期人脸检测方法的效果也在不断提升。基于深度学习的人脸检测方法可根据检测阶段和根据是否使用锚框(anchor box)分类。根据检测阶段可分为一阶段法和二阶段法。一阶段法的思想是,图片直接通过单一的前向卷积神经网络产生特征图,随后在特征图上预测出目标的定位,最后通过回归算法得到目标包围框,该方法优点为模型结构简洁,检测速度快,但对于复杂人群的检测效果不够理想,其典型算法为YOLO[10]。二阶段法先使用区域候选网络抽取一系列候选区域,再将这些区域送入卷积神经网络进行检测,该方法优点是目标定位精确度和检测准确率更高,但由于检测分为两部分进行,其过程相对复杂,计算量更大,典型方法为R-CNN[11]。另外根据检测网络中是否使用锚框,可分为基于锚框的检测(anchor-based)方法和无锚框的检测(anchor-free)方法。基于锚框的方法通过在网络预测阶段预设锚框使检测器可以同时预测多个检测目标,以加强目标回归效果,典型方法有SSH[12]和RetinaFace[13]。无锚检测方法在预测时不使用附加锚框,通过直接回归目标关键点来预测目标位置,相比于基于锚框的人脸检测,无锚检测有以下优点:(1)网络流程更为简洁。(2)不需要人工设置锚框大小、比例等超参数。(3)有更快的检测速度。(4)对小目标的检测效果好。无锚检测典型方法有CornerNet[14]以及ExtremeNet[15]等。
目前基于深度学习的人脸检测方法如SSH和Retina-Face等大多使用深层骨干网络且采用设置锚框的检测方法,其参数量大,计算和训练过程耗时长,不能满足实时检测要求。另外,对于现有的人脸检测方法如MTCNN[16],该方法使用三个不同的卷积网络分别处理不同大小尺寸的图像,虽然做到了模型轻量化,但其检测过程不够简洁。针对上述问题,本文提出一种使用轻量化卷积网络并改进特征融合的无锚人脸检测方法。该方法是一种端到端的人脸检测网络,首先采用了轻量化卷积网络作为特征提取的骨干网路;然后使用本文提出的特征处理方式进行特征融合,其过程如下:对于提取出的特征层,首先经过大小不同的空洞卷积处理以增强感受野,然后对每层特征附加权重使特征图自适应地融合,接着使用通道混洗模块对融合后的特征层进行混洗操作以增强不同特征图间的信息交互并减少一定计算量;最后使用中心点定位的无锚检测方法对融合的特征进行计算和预测,从而确定图片中人脸位置。实验结果表明,本文方法在保证模型轻量化的同时兼顾了检测准确率。与现有人脸检测方法比较,本文方法在检测准确率和检测效果上都有较好表现,验证了本文方法的有效性。
1 相关工作
1.1 轻量化卷积网络
轻量化卷积网络通过设计更高效的网络计算方式,减少网络的参数量和计算量,使网络在不损失性能的前提下改善网络运行效率。典型的轻量化卷积网络为MobileNets,其主要使用深度可分离卷积[17]和逆残差线性瓶颈层构建网络模型。
1.1.1 深度可分离卷积
MobileNets将深度可分离卷积模块应用到卷积网络模型中,有效地降低了网络参数量与计算量。图1给出了普通卷积和深度可分离卷积过程的比较。
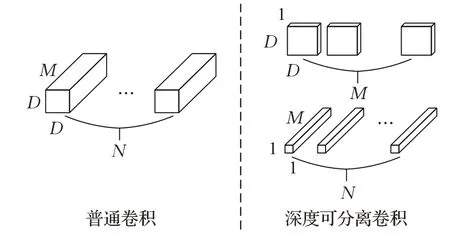
图1 普通卷积和深度可分离卷积Fig.1 Normal convolution and depthwise separable convolution
图中,N表示卷积核个数,M表示卷积核通道数,D×D表示卷积核大小。普通卷积使用N个卷积核逐步对图片进行卷积计算。深度可分离卷积将普通卷积分为深度卷积和逐点卷积两个过程,其先使用M个通道数为1、大小为D×D的卷积核进行深度卷积(depthwise convolution),然后使用N个通道数为M,大小为1×1的卷积核进行逐点卷积(pointwise convolution)。假设输入为D F×D F×M的特征图,普通卷积核为D×D×N,采用Same Padding,将得到输出D F×D F×N的特征图,其计算量为D F×D F×D×D×N×N,卷积核参数量为D×D×N。当使用深度可分离卷积时,计算量为D F×D F×D×D×M+D F×D F×N×N,卷积核参数为D×D×M+M×N。分离后的计算量与普通卷积计算量占比为卷积神经网络在特征提取过程中通道数往往呈增大趋势,并且卷积核一般都大于1×1,由此可知深度可分离卷积对比普通卷积在计算量和参数量的占比都远小于1,因此网络的计算速度得以加快。
1.1.2 逆残差线性瓶颈层
逆残差线性瓶颈层模块是mobilenetV3网络中常用的卷积模块,如图2所示。该模块包含普通卷积、维度扩充卷积、深度可分离卷积、残差结构以及SE轻量注意力模块[18](squeeze and excitation module)。逆残差线性瓶颈层模块使用多种卷积层处理图片特征,其计算量和参数量远低于普通卷积,是一种紧凑而高效的卷积计算方式。另外,该模块使用的残差结构和轻量注意力模型SE模块让深层网络梯度更容易传递的同时增强了特征的表示能力。
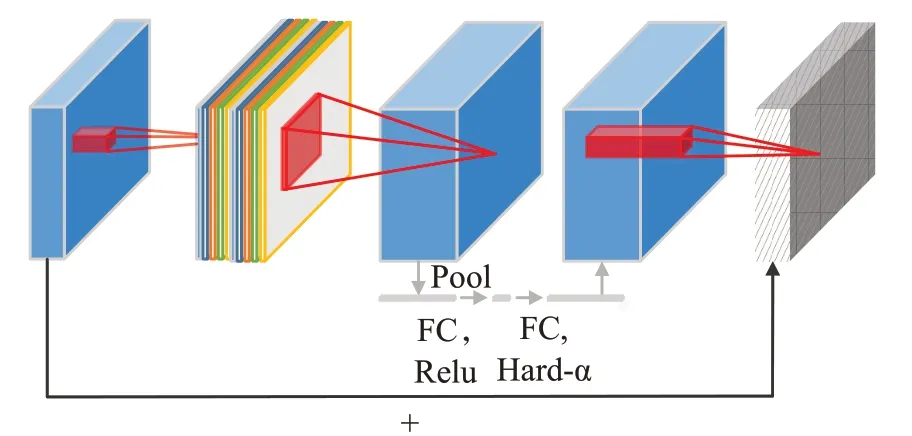
图2 逆残差线性瓶颈层模块Fig.2 Inverted residual and linear bottleneck
1.2 特征金字塔网络
特征金字塔网络[19](feature pyramid networks,FPN)主要用于解决检测问题中目标多尺度的问题。与图像金字塔相比,特征金字塔网络运算量更少并且精度更高。图像金字塔和特征金字塔网络结构如图3所示。
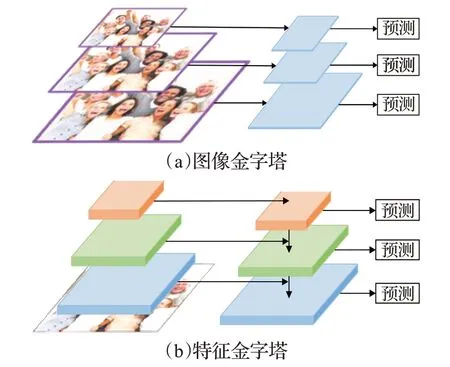
图3 图像金字塔和特征金字塔Fig.3 Image pyramid and feature pyramid
由卷积网络特性可知,卷积神经网络在提取图片特征过程中,其底层特征图含有语义信息少,但是目标位置准确;高层特征图语义信息丰富,但目标位置粗略。特征金字塔网络通过横向连接从骨干网络中取出特征图,再经过自上而下的下采样将顶层特征图与底层相融合,以同时获得目标丰富的语义信息和准确的位置。最后对每一层融合后的特征图进行独立输出预测,以增强对尺度变化的鲁棒性。
2 本文方法
为解决深层卷积网络带来的计算量大以及特征层融合不充分的问题,本文提出一种端到端的轻量化多特征融合人脸检测方法。通过使用轻量化网络和无锚检测来提升检测速度,使用多种特征融合处理方法提升检测精度。本文方法特点包括:(1)采用轻量化骨干网络作为特征提取层,引入感受野增强模块、附加权重的特征融合模块和通道混洗融合模块处理图片特征,以及使用中心点定位的无锚检测方法对特征进行后处理并预测人脸位置。(2)与现有方法对比,在保持检测准确率的前提下,显著降低了模型参数量和计算复杂度。(3)能处理大规模人群检测,对于遮挡、多姿态及多尺度等复杂人群有较好的检测效果。基于上述方法构建的网络模型如图4所示,整体流程分为基于轻量化骨干网络的特征提取、多特征融合和使用无锚检测的预测三部分。
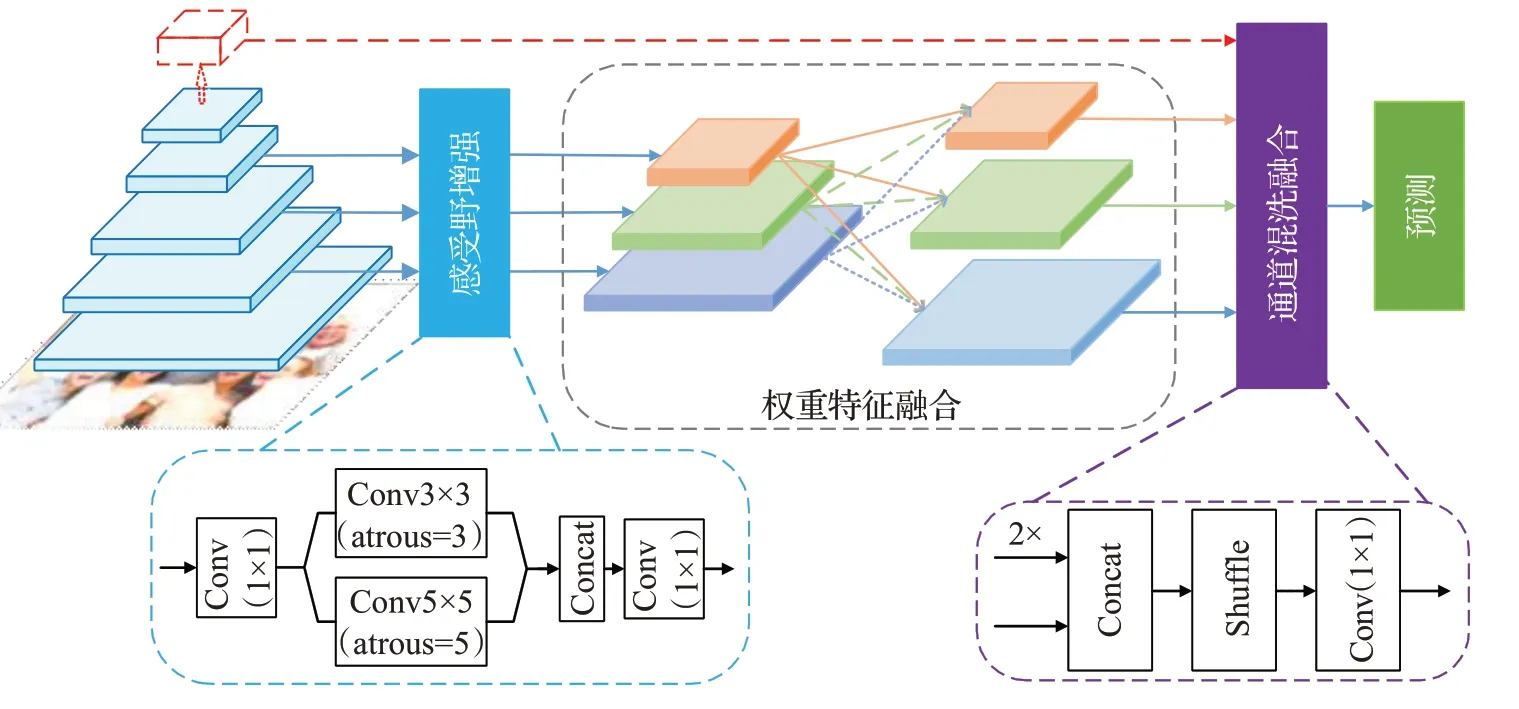
图4 检测模型整体结构Fig.4 Overall structure of detection model
2.1 基于轻量化骨干网络的特征提取
图片的特征提取过程依赖于模型的骨干网络,为使网络模型轻量化的同时保证检测性能,本文采用MobileNetV3small构建骨干网络。该网络的模型结构由平台感知网络结构搜索(platform-aware NAS)和网络自适应方法(net adapt)搜索得到,首先使用一层步长为2、卷积核大小为3×3的普通卷积对图片进行下采样,然后使用11个逆残差线性瓶颈层模块(简写为Bneck)对图片进行卷积操作,其中前三个Bneck使用卷积核大小为3×3的卷积,后8个Bneck卷积核大小为5×5,并且第1、2、4、9个Bneck使用步长为2的卷积进行下采样,第1、4~11个Bneck中嵌入SE轻量注意力模块。整个网络由两种不同逆残差线性瓶颈层堆叠而成,通过使用通道扩充卷积增加特征层通道数并使用步长为2的卷积对特征层进行下采样操作。为简化计算过程,本文方法在所有卷积操作后均使用ReLU激活函数,在骨干网络最后一层使用卷积核大小为3×3、步长为2的卷积对特征层作最后一次下采样操作。
2.2 多特征融合
普通的特征金字塔网络在融合特征时对特征层进行上采样和元素相加操作,这种结构一定程度上解决了多尺度特征层融合的问题。本文方法在特征金字塔基础上引入感受野增强模块(receptive field enhancing module,REM)、权重特征融合模块(weight-feature fusion module,WFM)和通道混洗模块(channel shuffle module,CSM)进一步增强特征融合,以满足复杂场景下人脸检测精度的要求。
(1)感受野增强模块
轻量化网络作为特征提取的骨干网络,其结构简洁,但提取出的特征有限,对此引入感受野增强模块对其进行处理。对于感受野增强模块的输入I,进行卷积核大小为3×3、5×5的空洞卷积的操作:
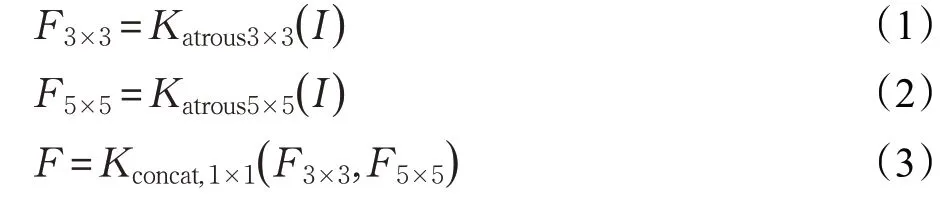
式中,I表示特征金字塔的各个特征层,Katrous3×3(I)、Katrous5×5(I)分别表示大小为3×3、5×5的卷积核对各特征层的卷积操作;F3×3、F5×5分别表示经过对应卷积操作后得到的特征图;Kconcat,1×1表示对两个特征层使用concat和1×1卷积操作。所有卷积操作后都使用批归一化和ReLU激活函数,并且经过感受野增强模块处理后的特征层在尺度和通道数上与原特征层保持一致。感受野增强模块使用不同大小的空洞卷积对特征进行计算,将不同尺度空洞卷积核得到的图像特征进行融合,有利于后续处理融合信息充分的特征图,以增强检测效果。
(2)权重特征融合模块
为加强特征融合效果,使每层特征能被检测网络充分利用进而提升检测精度,引入附加权重的特征融合模块。对经过感受野增强模块处理后的特征层,首先将顶层特征上采样与底层特征融合,然后将每一层特征通过上采样或下采样方式分别与其他层进行加权融合。假设原特征层表示为f i,在特征融合时每层特征做加权计算,所得特征F i可表示为:
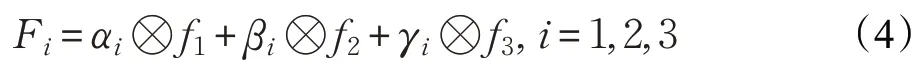
式中,超参数αi、βi、γi为每层特征的附加权重,由网络训练得到。原特征层的每一层特征在与其他层相融合时分别赋予不同权重,从而得到新的特征层网络,所得网络在尺度和通道上都与原特征保持一致。以该种融合方式进行训练可以让模型自适应选择有利于目标定位和回归的特征层,从而提升检测准确率。
(3)通道混洗融合
为加快模型检测速度,本文方法在预测阶段并不使用多层检测头分别预测,而是使用经过通道混洗模块处理的单一特征层作为检测头进行预测。对于附加权值的特征层,首先对顶层做上采样处理,然后与下一层进行通道拼接,之后使用通道混洗操作和卷积操作进行处理,其过程表示如下:
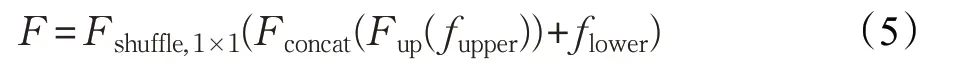
式中,fupper表示上层特征层输入,flower表示下层特征层输入,Fup为采样倍数为2的双线性上采样操作,Fshuffle,1×1表示使用通道混洗和卷积核为1×1的卷积操作。经过上述方法得到的新特征层再与下一层进行相同操作,直到计算出最终特征层用于预测。另外,在通道混洗融合最上层加入原骨干网络的特征层映射以保持原图片特征信息。
2.3 无锚检测预测过程


2.4 损失函数
本文采用Lin等人[20]提出的Focal Loss作为人脸检测分类损失函数。对比交叉熵损失(cross entropy loss),Focal Loss更有利于解决检测网络中样本比例失衡以及前景和背景分类问题。Focal Loss表示为:

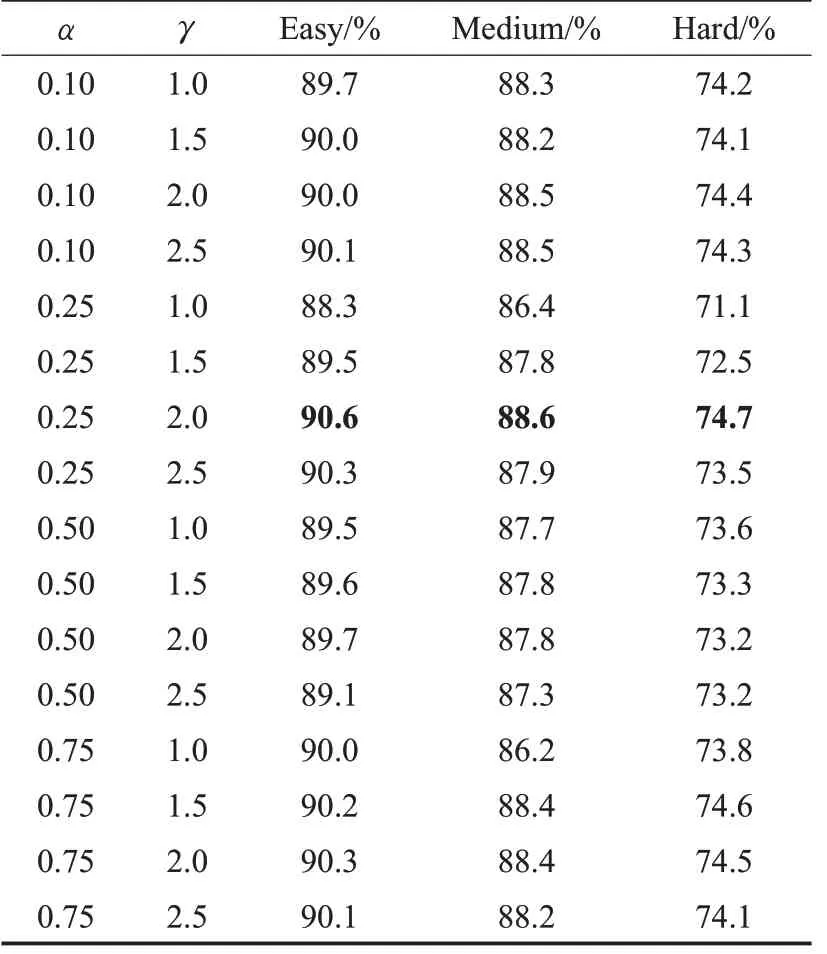
表1 不同α和γ对算法精度的影响Table 1 Varyingαandγfor algorithm
在回归目标包围框时,本文采用GIoU Loss[21]。GIoU Loss是对普通交并比损失函数的改进,其表达式如下:
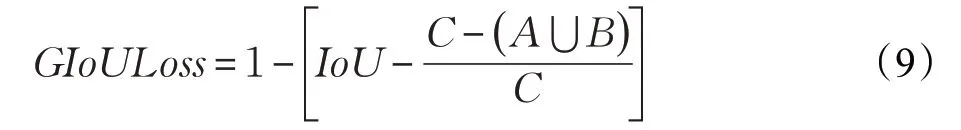
其中,A为检测器预测框,B为数据集标注的真实框,C为包围预测框和真实框的最小面积。IoU表示为预测框和真实框的交并比,其表达式如下:

在对包围框回归计算时,GIoULoss不仅关注预测框和真实框的重叠面积,同时也关注两框的非重叠区域,即C-(A∪B),因此可以使检测器更加关注两框之间的重合度,从而使最终得到的目标包围框更加趋于真实框大小。
3 实验结果及分析
3.1 实验环境
本文算法使用的实验环境为Ubuntu16.04LTS操作系统,采用深度学习框架Pytorch进行网络搭建以及模型训练、测试和验证,使用cuda10.0和cudnn7.6.2用于算法加速。本文方法采用的硬件设备为Inteli7-9700K@3.6 GHz处理器,32 GB运行内存,NVIDIA Geforce RTX2080Ti显卡。
3.2 实验设置
3.2.1 数据集
本文方法使用的数据集为WIDERFACE[22]人脸数据集。该数据集总计32 203张图片,包含393 703张带标注的人脸,并且大多数图片都呈现密集的人群环境,其标注的人脸具有多姿态、多尺度、高遮挡等特点。WIDERFACE数据集以61种事件对图片进行分类,对每一类图片都按不同比例分为训练集、测试集和验证集并将每个子集的检测图片都设置简单(Easy)、中等(Medium)和困难(Hard)三种难度。不同难度下的数据图片中包含数人到数百人不等,且涵盖大部分自然场景中的人群分布情况。
3.2.2 参数设置
在训练阶段,训练集中的图片统一缩放成大小尺寸为768×768的图片,并使用随机翻转、色彩抖动和光照变换等数据增强方法。训练时batch size设置为16,epoch设置为200,使用Adam优化器并在不同阶段使用不同大小的学习率。学习率设置如下:0~30 epoch的学习率设置为0.001,31~50 epoch的学习率设置为0.002,51~100 epoch的学习率设置为0.005,101~150 epoch的学习率设置为0.000 1,151~200 epoch的学习率设置为0.001。同时,在训练时使用正态分布的随机初始化对网络中的权重进行初始化。
3.3 检测结果
本文首先对比了使用不同特征处理模块对检测模型检测准确率的影响;然后与其他基于深度学习的人脸检测方法进行比较,并通过检测准确率和精确度召回率曲线图(precisionand recall,PR curve)给出实验结果。最后给出了本文方法在WIDERFACE数据集中的一些检测效果作为示例。
3.3.1 特征处理模块有效性分析
为验证所提方法的有效性,本文使用不同特征处理模块分别进行了多种融合实验,所有检测模型均在WIDERFACE训练集上进行训练,在其验证集上进行验证,并且训练时的参数设置均保持一致。验证时,阈值大小设置为0.5,得到的检测准确率以及模型权重大小如表2所示。
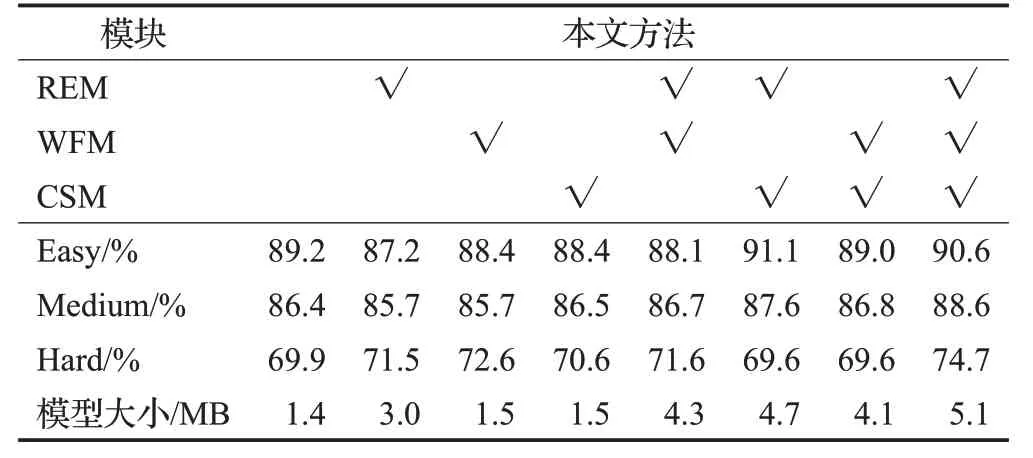
表2 不同特征处理模块检测准确率及模型大小Table 2 Detection accuracy and model weight with different feature processing modules
由表2可以看出,当仅使用一种特征处理模块时,在Easy和Medium难度的检测准确率有略微降低,但在Hard难度下的准确率有较大提升。当使用两种模块组合时,使用REM和WFM的模型仅在Hard难度下准确率提升较多,使用REM和CSM的模型在Easy和Medium难度下有较大提升,使用WFM和CSM的模型检测准确率和基准方法的准确率几乎一致,并且使用两种模块组合时模型权重达到了4.1 MB、4.3 MB和4.7 MB。同时使用三种模块时,检测模型在三种难度下的检测准确率都有较大提升,在hard难度下提升最大,达到了4.8个百分点,并且模型权重只有5.1 MB。综上可知,本文提出的不同特征处理模块对于提升检测结果均是有效的,使用三种模块的检测模型在参数量上比使用两种模块的模型只多了不到1 MB,但其检测准确率具有明显提升。
为验证本文方法优势,与文献方法在相同数据集下进行比较,结果如表3所示。
从表3中可以看出,本文方法在WIDERFACE验证集检测准确率上均优于Faceness、Multiscale Cascade CNN、LDCF+、Multitask Cascade CNN等方法。在对比ScaleFace和文献[26]时,在Easy和Medium难度上的准确率有较大提升,但Hard上的准确率稍显不足。比较于SSH检测方法时,本文方法在Easy和Medium难度上准确率上相差3个百分点左右,在Hard难度相差较大,在10个百分点左右。
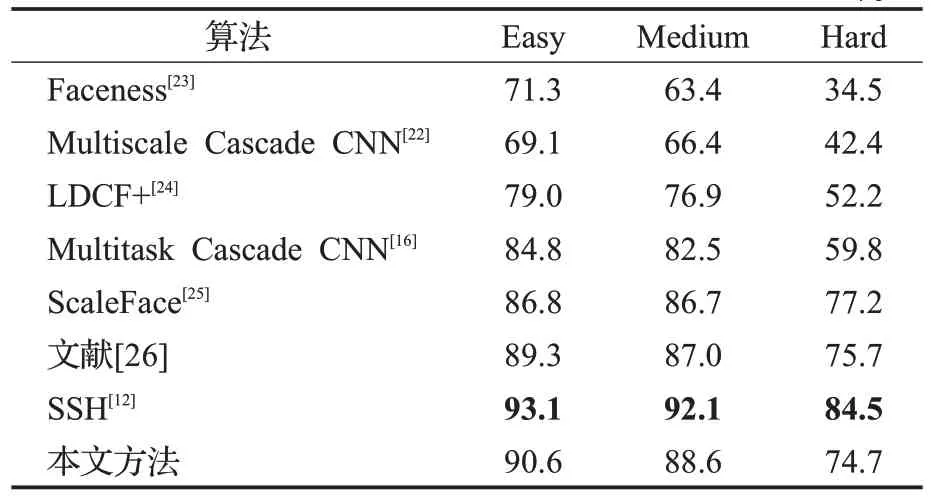
表3 WIDERFACE验证集检测准确率对比Table 3 Accuracy comparison on WIDERFACE validation set %
然而,文献所提方法均未使用轻量化骨干网络作为特征提取网络,其模型计算量和参数量巨大,本文所提方法使用轻量化网络,模型权重仅有5.1 MB,做到了检测精度和模型大小的权衡。各方法模型权重大小如表4所示。
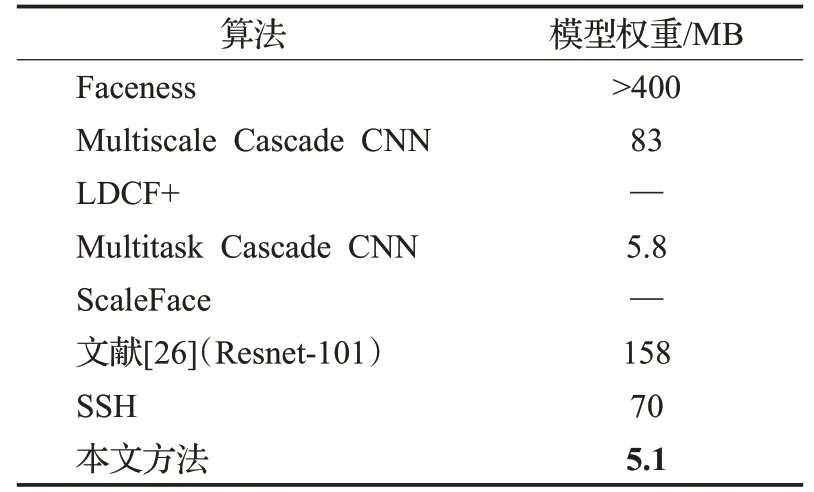
表4 模型权重大小Table 4 Weight of each model
从表4可以看出,本文方法在模型轻量化上具有显著优势。与Multitask Cascade CNN比较,模型权重大小相差不大,但是检测精度提升了许多。与SSH方法相比,本文方法检测精度稍显不足但模型权重约为SSH的十四分之一。因此,本文方法无论从检测准确率还是模型轻量化方面均有显著优势。另外,WIDERFACE数据集使用PR曲线作为人脸检测的性能评估标准。遵循其评估协议。对比方法和本文方法在验证集上的检测PR曲线如图5所示。从曲线也可看出,本文方法精确度优于除SSH外的其他对比方法。
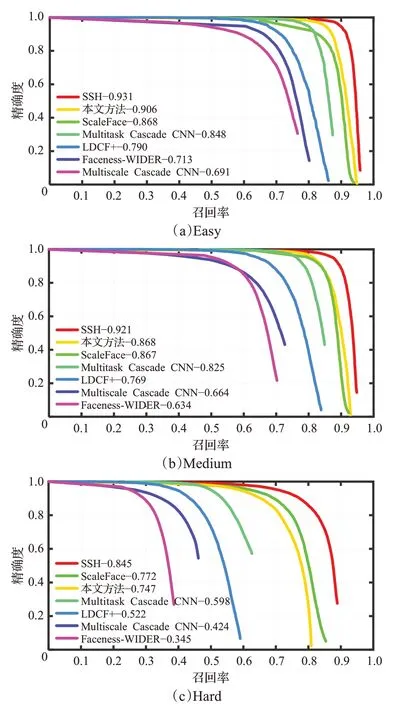
图5 检测PR曲线图Fig.5 Detection PR curves
3.3.2 检测效果
图6给出了本文方法的一些检测效果图例,检测到的人脸均用矩形框标注。从检测效果可以看出,本文方法可以有效地检测出复杂场景的人群,且能很好地解决大规模人群中多姿态、多尺度和高遮挡下的人脸检测的难题。

图6 检测效果图Fig.6 Detection results
4 结束语
针对基于深度学习的人脸检测算法使用深层神经网络带来的计算复杂、参数量大以及复杂场景中检测准确率低的问题,本文提出一种基于多特征融合的轻量化无锚人脸检测算法。该方法利用轻量化骨干网络提取图片特征,使用感受野增强模块、权重特征融合模块和通道混洗模块处理金字塔特征层,使特征融合更为充分,最后使用无锚检测方法进行网络训练并预测出人脸位置。实验结果显示本文引入的特征处理模块能有效提升检测精度,与文献方法相比,在检测精度上和检测效率上具有较为明显的优势,显示了本文方法的简洁性与高效性。如今注意力机制和Transformer模型广泛应用于计算机视觉任务中并取得了显著的效果,下一步工作将会从上述两方面着手构建人脸检测网络,进一步加强模型对复杂人群的检测效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年5期)2018-08-21
