
基于知识图谱上下文的图注意矩阵补全
2022-06-09 11:58陈平华
计算机工程与应用 2022年11期
孙 伟,陈平华
广东工业大学 计算机学院,广州 510006
随着电子商务和社交媒体平台爆炸性增长的数据信息,推荐系统已经成为处理这一问题的有效手段,近年来,个性化推荐已经在不同的应用场景中得到广泛应用。矩阵补全[1]是推荐系统中的一个子任务,在这项工作中,将评分矩阵看作用户-项目二部图,图上边的权重表示为用户对项目的评分,将矩阵填充问题转化为边的权值问题[2],通过图自编码器获取图中顶点表达后进行链接预测。现有的方法在编码器上使用传统的图卷积网络,结合邻近节点特征的方式并且依赖于图的结构[3],局限了训练所得模型在其他结构上的泛化能力,邻域之间共享权重,无法很好地区分彼此之间的重要性。
将知识图谱(knowledge graph,KG)纳入推荐的主要挑战是如何有效利用KG之间的实体和图结构之间的关系[4],图神经网络(graph neural network,GNN)的出现正好为这一问题的解决提供了有力的技术支持。尽管基于GNN的推荐方法可以自动捕获KG的结构和语义信息[5],但仍存在以下缺陷:首先,大多数基于GNN的方法对实体进行聚合时缺乏对特定用户偏好的KG中实体的本地上下文(一阶邻居)建模[6];其次,在现有的基于GNN的推荐方法中,KG中实体的非本地上下文(最相关的高阶邻居)没有被明确捕获[4]。现有的基于GNN的方法通过逐层传播特征来解决此限制[7],但这可能会削弱相互连接的实体的影响,甚至带来噪声信息[8]。为了解决上述的这些问题,本文提出基于KG上下文矩阵补全的图注意编码器框架,图注意编码器通过在双向交互图上使用注意力机制进行消息传递来生成用户和项目节点的潜在特征[9],明确利用知识图谱中实体的本地和非本地上下文,分别如下:基于不同用户可能对知识图谱中的同一实体有不同的偏好,提出一种用户特定的图注意力机制来聚合知识图谱的本地上下文信息;为了显示地利用知识图谱中的非本地上下文信息,通过随机游走采样过程来提取实体的非本地上下文,然后采用递归神经网络在知识图谱中对实体及非本地上下文之间的依赖关系进行建模,最后,将知识图谱实体的本地与非本地上下文利用一个门控机制集成,将上述得到的用户和项目表示以及结构化的外部信息(知识图谱)通过双线性解码器有效地重建评分链接[10]。
1 相关工作
1.1 图自编码器
图自编码器凭借其简洁的编码器-解码器结构和高效的编码能力,在很多领域都派上了用场。获取合适的嵌入向量来表示图中的节点不是容易的事,如果找到合适的嵌入向量,就可以以此将其应用到其他任务中。Kipf与Welling提出了基于图的(变分)自编码器[11](VGAE),VGAE通过编码器-解码器的结构可以获取到图中节点的嵌入向量,来支持接下来的任务。通过利用隐变量,让模型学习出一些分布,再从这些分布中采样得到隐表示,这就是编码过程。然后利用得到的隐表示重构出原始图,这个过程是解码阶段。GraphCAR[12]的整体框架基本遵循着图自编码器的框架,即先使用图卷积神经网络获取用户和项目的嵌入表示,然后使用内积来预测用户对项目的偏好评分,并且它直接对用户和项目的交互和边信息一起建模。
1.2 带辅助信息的矩阵补全
矩阵补全的目标是用低秩的评分矩阵来近似评分矩阵,文献[13]用核函数(矩阵奇异值之和)的最小化代替秩最小化,使目标函数变为一个可处理的凸函数。文献[14]提出几何矩阵补全模型通过以用户图和项目图的形式添加辅助信息来引入矩阵补全模型的正则化。RGCNN[15]模型探索基于用户和项目的k近邻图的切比雪夫多项式的频谱图滤波器的应用,本文所提模型直接在交互图上传递信息,直接在编码器-解码器中对评分图进行建模,能够进一步加快训练速度。Ying等人[16]提出PinSage这种高度可扩展的图卷积网络,基于Graph-Sage框架推荐Web规模图,并且对邻域进行二次采样以增强可扩展性。而本文的工作将会专注于基于图的辅助信息建模[17],并进一步引入正则化技术提高泛化能力。
1.3 基于知识图谱的方法
基于嵌入的方法主要是通过图嵌入的方法对实体和关系进行表征,进而扩充原有物品和用户表征的语义信息。其中包括基于Trans系列的图谱嵌入方法和基于异质信息网络的图嵌入方法。例如,Zhang等人[18]提出的CKE模型使用TransR从项目KG导出语义实体表示,Cao等人[9]提出的KTUP模型通过共享项目嵌入来共同训练个性化推荐和KG完成任务,Dong等人[19]利用Metapath2Vec对知识图谱上的节点进行表征,进而扩充推荐系统中物品的表征。但是这些方法缺少知识图谱中语义关系的精确建模。
基于路径的方法主要是挖掘基于图谱用户、物品之间多种连接关系。在文献[20]中,作者使用卷积神经网络对每种不同元路径采样得到的从用户到物品路径进行嵌入表征,进而构造基于元路径的用户偏好特征,并结合NeuMF[21]的算法构建推荐系统。基于元路径的方法虽然可以有很好的推荐效果以及可解释性,但这类方法在构建推荐算法前需要先从数据中抽取、构造大量的元路径或元图。
最近,基于GNN的方法逐渐应用到基于知识图谱的推荐系统中。例如,Wang等人[22]提出KGNN-LS模型采用了可训练的函数,该函数计算每个用户的关联权重,以将KG转换为用户特定的加权图,然后在该图上应用图卷积网络以学习项目嵌入。在Wang等人[23]提出的另外一篇文章中,采用图注意力机制来聚合和传播实体的本地邻域信息,而无需考虑用户对实体的个性化偏好[24]。总而言之,这些基于GNN的方法通过逐层传播隐式地聚合了高阶邻域信息,而不是显式地对实体与其高阶邻居之间的依赖关系进行建模[25]。
2 上下文知识图注意矩阵补全


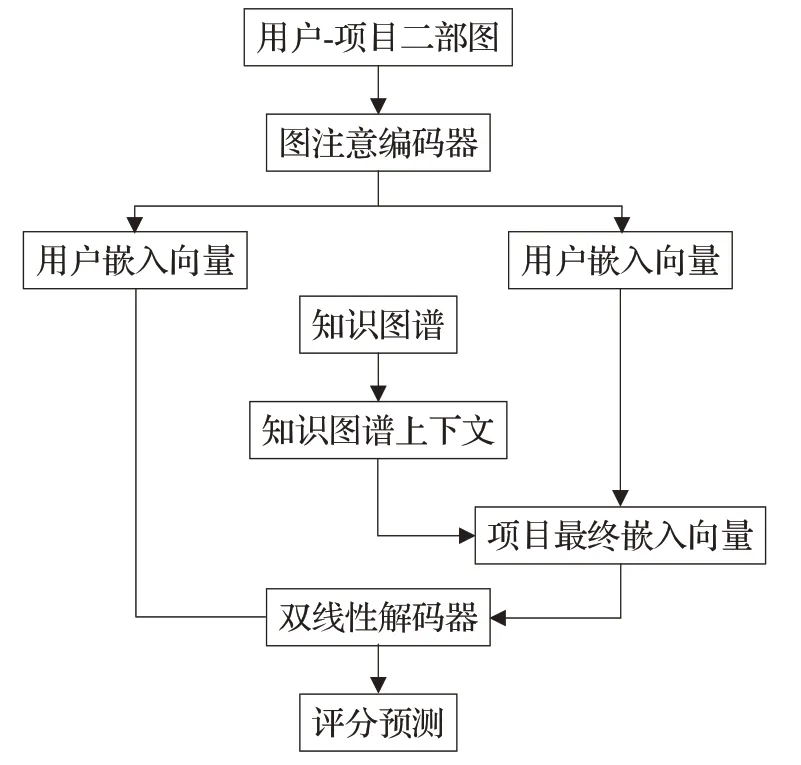
图1 模型框架图Fig.1 Model frame figure
2.1 图注意编码器
本文提出一种图注意编码器,该编码器使用注意力机制为邻域中不同的节点指定不同的权重,既不需要矩阵运算,也不需要事先知道图结构,对相邻节点计算,更加具有鲁棒性以及可解释性。通过该机制编码器还为每一种评分等级类型rˉ∈Rˉ分配单独的处理通道,把这个过程看作是消息传递的一种形式,其中节点向量特征沿着图上的边之间传递和转换。在这种情况下为每个等级分配特定的转换,从项目j到用户i的信息传递被定义为:
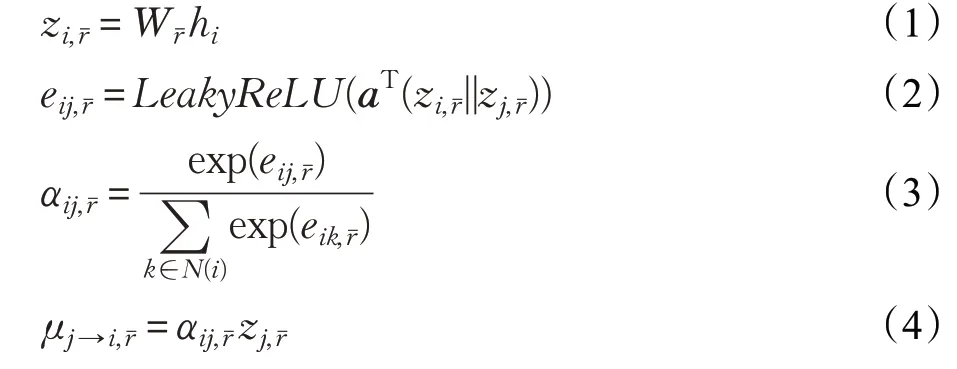
在这里,公式(1)对节点嵌入h i做线性变换,Wrˉ为基于边类型(评分等级)的参数矩阵。公式(2)计算成对节点间的原始注意力分数,它首先拼接了两个节点z的嵌入;随后对拼接好的嵌入以及一个可学习的权重向量a做点积,最后应用了一个LeakyReLU激活函数。公式(3)对一个节点所有入边得到的原始注意力分数使用一个softmax操作,得到注意力权重。公式(4)形似图注意网络的节点特征更新规则,对所有邻节点的特征做了基于注意力的加权求和,N(i)表示用户i的邻居集合。从用户到项目的消息μi→j,rˉ以类似的方式处理。在消息传递完成之后,针对每种类型的边,把所有以i的邻域
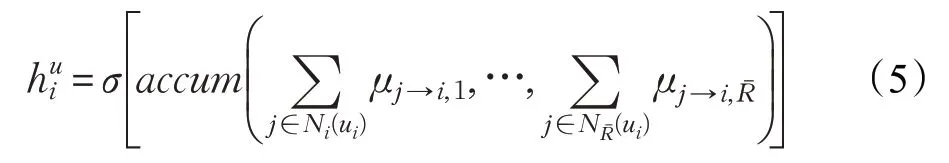
其中,accum(·)表示一个聚合运算,例如stack、sum等,σ(·)为激活函数,为了得到用户u i的最终嵌入向量,对中间输出h加个全连接层变换:

其中,W为参数矩阵,计算项目的嵌入向量的方法和用户的求解类似,只不过是使用两套参数。
2.2 知识图上下文
(1)本地图上下文

(2)非本地图上下文
用户特定的图形注意网络显式地聚合目标实体的本地邻居(一跳)信息,以丰富目标实体的表示。但这并不意味着在知识图谱中捕获实体的非本地上下文(高阶)信息,以及对于知识图谱中连接较少的节点也具有较强的表示能力。为了解决这个问题,提出一种基于GRU模块的偏置随机游走方法,使用GRU建模实体h与其非本地上下文之间的依赖关系,用于聚合实体的非本地上下文信息。
偏置随机游走过程用于提取目标实体h的非本地上下文,为了实现更广泛的深度优先搜索,从h重复偏向随机游走,以获得长度固定为L的M条路径,该遍历以概率p迭代到当前实体的邻居,定义如下:

最后,为了建模项目节点的辅助信息,在对做全连接层变换时,考虑连接知识图上下文向量c h和项目向量,得到项目vi的最终嵌入表示:

图2描述了捕获知识图谱中实体的本地和非本地上下文信息的流程。
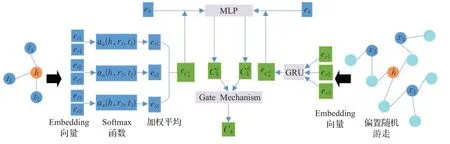
图2 知识图上下文建模Fig.2 Knowledge graph context modeling
2.3 双线性解码器
为了重构二分图上的链接,考虑一个双线性解码器,把用户对项目的评分等级视为多个类别,N表示为用户和项目之间重构的评分矩阵,解码器通过对可能的评分等级进行双线性运算,然后用softmax函数生成一个概率分布:

算法步骤如下:
输入:用户-项目二部图(用户对物品的评分矩阵);知识图谱
输出:预测评分等级
(1)采用带注意力的图自编码器的方法进行消息的传递,设计一种评分等级的转换,对节点的特征沿着边进行传递和转换,最后生成用户和项目节点的潜在特征表示。
(2)对知识图谱实体进行本地和非本地上下文信息提取,采用门控机制对两者进行集成。
(3)对项目节点特征表示与知识图谱中实体上下文信息进行聚合操作,形成最终的项目表征。
(4)采用双线性解码器,把用户对项目的评分等级视为多个类别,生成评分概率分布。
2.4 模型训练
损失函数。在模型训练过程中,将预测评级N̂ij的负对数可能性最小化:
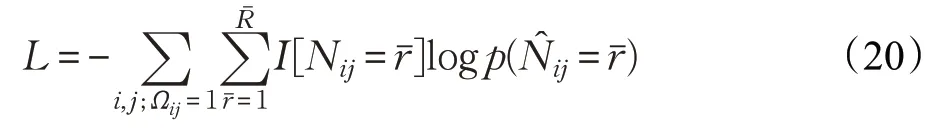
当k=l时,I[k=l]=1,其他情况时为0,矩阵Ω∈{0,1}N u×N v作为未观察到评级的掩码,例如,对应于N中观察到评级对应的元素会出现1,未观察到的评级会出现0,因此,仅对观察到的评级进行优化。
批处理。通过对等式中的损失函数进行抽样批处理,即只采样固定数量的用户和项目对,一来减少训练所需的内存,二来达到正则化的效果;通过实验验证了当调整正则化参数时,mini-batch和full-batch在数据集上得到相似的效果;在大数据集中应用mini-batch,而在小数据中应用full-batch以获得更快的收敛速度。
节点丢弃。为了使模型能够很好地泛化到未观察到的等级,通过去噪设置对模型进行训练,这能够有效地提高模型的鲁棒性。在训练中使用丢弃,以一定概率Pdropout随机删除特定节点的所有消息,将其称为节点丢弃。在初始实验中,发现节点丢弃比消息丢弃更能有效地进行正则化。节点丢弃也会使嵌入表示不受特定用户或项目的影响。
权值共享。并不是所有的用户和项目对于同一个评分等级都有相同的评分,这可能导致在图注意层中权重矩阵的某些列没有其他列优化的频繁。考虑用户对项目打分的非均匀性,防止权重矩阵的列优化不均匀,使用一种在不同评分关系之间进行参数共享的方法:

其中,T s为基础矩阵,评分越高,Wrˉ包含的T s数量越多。
作为正则化的一种有效方法,解码器中的权重矩阵Q rˉ采用一组基于基础参数矩阵的线性组合的参数共享矩阵:

其中,s∈(1,2,…,nb);nb表示基权重矩阵P s的数量;arˉs是可学习参数,这个系数决定了每一个解码器权重矩阵Q rˉ的线性组合;为了避免过拟合并减少参数的数量,基权重矩阵的数量nb应低于评分级别的数量。
3 实验
3.1 实验设置
数据集:
实验将会在三个公共数据集上执行:Last-FM(https://grouplens.org/datasets/hetrec-2011/)、Movielens-1M(https://grouplens.org/datasets/movielens/1m/)和Book-Crossing(http://www2.informatik.uni-freiburg.de/~cziegler/BX)(分别由FM、ML和BC表示)。考虑数据稀疏,将所有FM和BC数据集的评级保留为隐式反馈,对于ML数据集,将大于4的评分保留为隐式反馈。这些数据集的知识图谱是由Microsoft Satori构建,通过仅选择关系名称分别包含“电影”和“书”的三元组,进一步减小ML和BC中知识图谱的大小,对于这些数据集,通过其名称匹配知识图谱中的项目和实体,将与任何实体或多个实体都不匹配的项目删除,表1总结了这些实验数据集的统计数据。
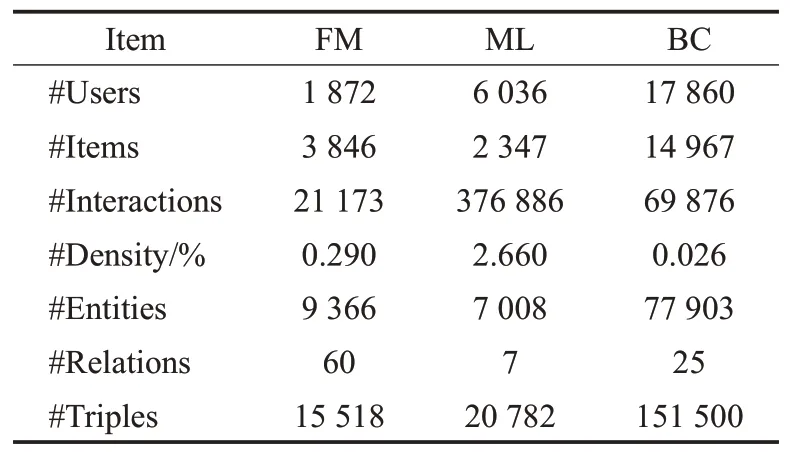
表1 数据集统计信息Table 1 Statistics of experimental datasets
设置和指标:
对于每个数据集,随机选择60%观察到的用户-项目交互来进行模型训练,并选择另外20%的交互来进行参数调整,其余20%的互动作为测试数据,使用两个广泛的评估指标:Precision@K,Recall@K,在实验中,将K设置为10、20。对于每个指标,首先根据测试数据计算每个用户的准确度,然后报告所有用户的平均准确度。
基线方法:
(1)CFKG[26]:将多种类型的用户行为和项目KG集成到一个统一的图中,并采用TransE来学习实体嵌入。
(2)RippleNet[27]:通过沿用户KG沿其历史项目的路径传播用户对实体集合的偏好来利用KG信息。
(3)GCMC[1]:基于矩阵的图自编码器框架。它通过图卷积矩阵完成对用户项二部图进行编码,使用隐式用户项交互来创建用户项二部图。
(4)KGAT[28]:在KG上采用图注意力机制来利用图上下文进行推荐。
实现细节:
对于本模型的参数,潜在空间d的维数从{8,16,32,64,128}中选择,模型训练中使用的实体S的局部邻居数从{2,4,8,16,32,40}中选择,正则化参数λ1和λ2选择{10-6,5×10-6,10-5,5×10-5,10-4,5×10-4,10-3,10-2},学习率η从{10-4,5×10-4,10-3,5×10-3,10-2}中选取,对于所有方法,最佳超参数均由验证数据的性能来确定,并使用Adam优化器来学习模型参数。
3.2 实验结果
表2总结不同数据集上的结果,通过观察,就所有指标而言,本文模型通常会在所有数据集上获得最佳性能,本文模型在知识图谱中显示建模实体之间的上下文信息,考虑用户的个性化偏好建模,结果表明,通过解码器可以有效地将知识图谱上下文信息与用户-项目二部图获得的向量表征融合从而增强推荐的性能。
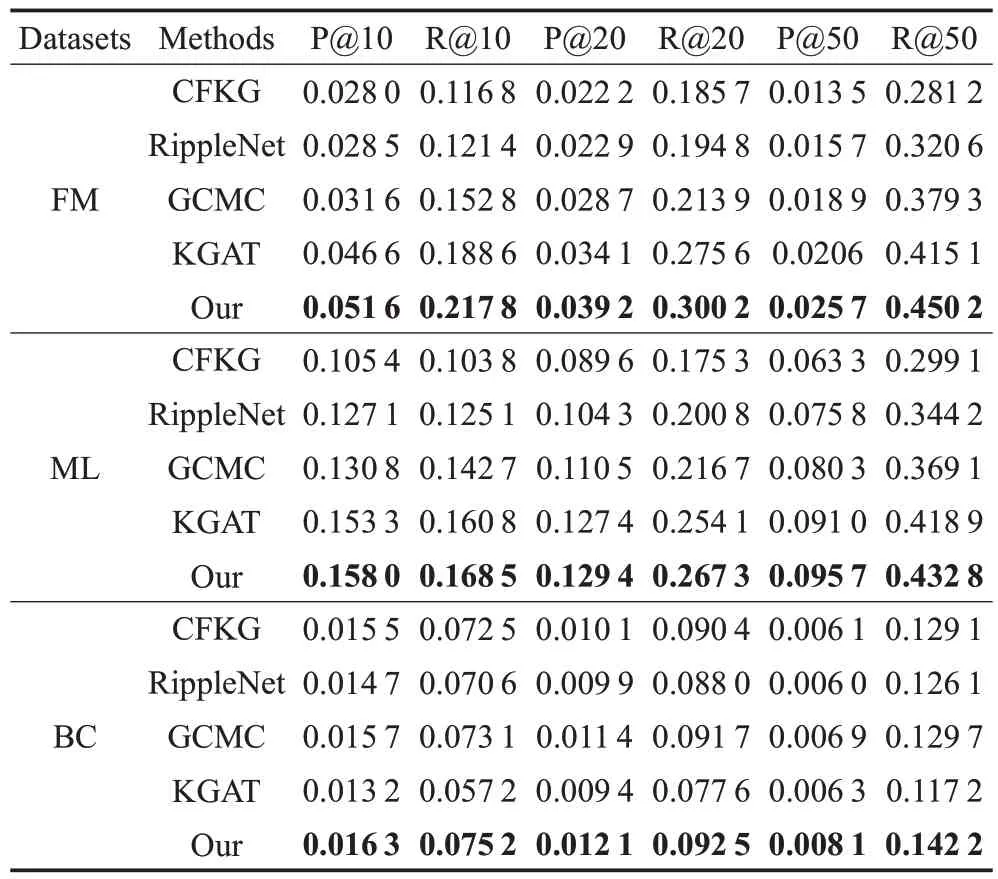
表2 不同推荐算法的性能Table 2 Performances of different recommendation algorithms
3.3 参数敏感性研究
总结本文模型在关键参数不同设置方面的性能,知识图谱中相邻实体的大小通常因不同项目而异,研究固定采样邻居的大小S将如何影响性能,从图3中可以看出,当S设置为4时,模型可获得最佳性能,而更大的S则无助于进一步提高性能。图4显示λ的不同设置下的性能趋势,将λ设置为10-4可以获得比通过将λ设置为0更好的性能。此外,研究随机游走采样路径数M和路径长度L对随机游走模块的影响,从图5可以看出,将M设置为15可以获得最佳性能,这表明通过执行15次随机游走采样来捕获实体的非本地邻居中最相关的实体。如图6所示,将L设置在4到12之间可以获得更好的性能,进一步增加L会增加更多的训练时间,导致推荐性能的下降。
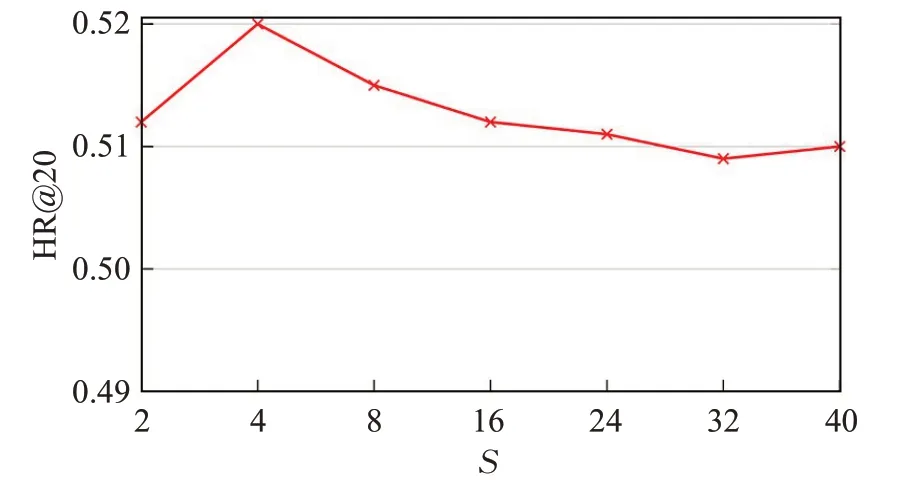
图3 S在ML数据集中对模型性能的影响Fig.3 Performances of model on ML dataset of S
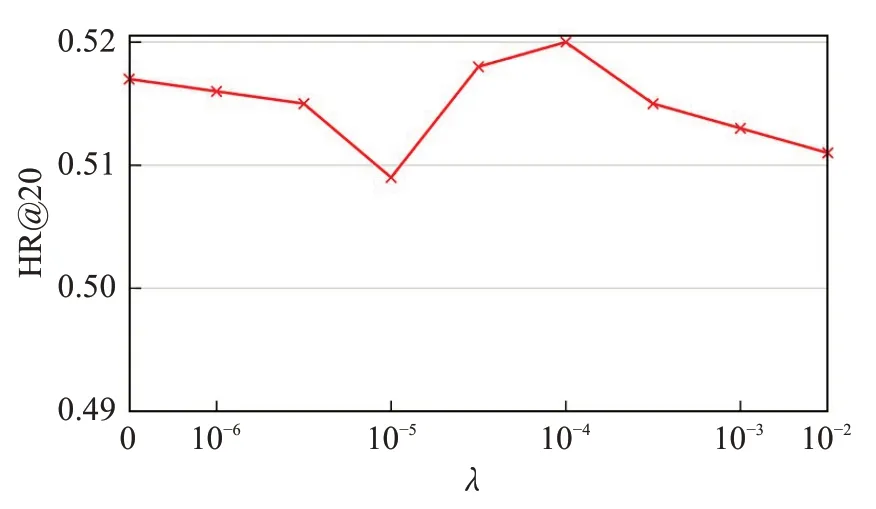
图4 λ在ML数据集中对模型性能的影响Fig.4 Performances of model on ML dataset ofλ
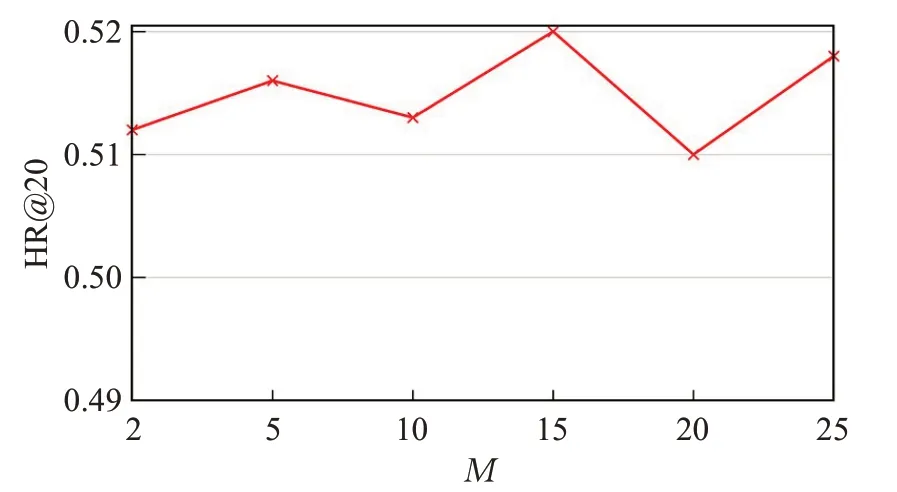
图5 M在ML数据集中对模型性能的影响Fig.5 Performances of model on ML dataset of M
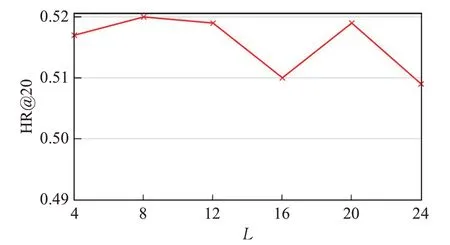
图6 L在ML数据集中对模型性能的影响Fig.6 Performances of model on ML dataset of L
4 结语
本文提出了基于知识图谱的上下文矩阵补全,用于推荐系统中矩阵补全任务的带注意力的图形自动编码框架,并且充分利用知识图谱中本地和非本地上下文信息来增强推荐。具体来说,该模型使用图注意编码器在用户-项目二部图上传递消息并设计一种评分等级转换来构造用户和项目的嵌入,通过特定于用户的图注意机制在知识图谱中聚合本地上下文信息来捕获用户对实体的个性化偏好;使用基于偏差随机游走的采样过程来为知识图谱上目标实体提取重要的非本地上下文信息,并使用GRU模块显式聚合实体嵌入,最后通过一个双线性解码器融合二部图和知识图谱中的信息,本模型的优越性通过与三个数据集上的最新基准进行比较得到验证。在未来的工作中,考虑用户的历史项目在对其不同候选项目的偏好时可能具有不同的重要性,建模用户上下文信息,以提高推荐的准确性。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
世界科学技术-中医药现代化(2021年7期)2021-11-04
科学技术创新(2021年5期)2021-03-17
少先队活动(2020年12期)2021-01-14
——编码器
演艺科技(2020年7期)2020-08-13
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
