
图卷积网络增强的非负矩阵分解社区发现方法
2022-06-09 11:57郑裕龙陈启买贺超波张晓雨
计算机工程与应用 2022年11期
郑裕龙,陈启买,贺超波,2,刘 海,张晓雨
1.华南师范大学 计算机学院,广州 510631
2.仲恺农业工程学院 信息科学与技术学院,广州 510225
真实世界中广泛存在着各种各样的复杂网络,例如社交网络、作者合著关系网络、论文引用网络以及蛋白质交互网络等。社区发现是复杂网络分析的重要研究话题,它的任务在于将复杂网络划分成多个子网络,并且要求各子网络内部节点之间连接紧密,而不同子网络的节点之间连接稀疏[1]。有效发现复杂网络存在的社区结构有助于理解整个网络的结构特征和支持许多基于复杂网络的数据分析应用,例如用户兴趣点推荐[2]和发现电信诈骗团伙[3]。
在过去几十年,各类社区发现方法不断涌现,其中包括基于图划分的方法[4-5]、基于谱聚类的方法[6]、基于模块度优化的方法[7-8]、基于标签传播的方法[9-10]以及基于深度学习的方法等[11]。值得指出的是,非负矩阵分解(NMF)因其简单、易扩展和可解释性强也被广泛应用于社区发现[12]。目前,已提出许多基于NMF的社区发现方法,例如,基于朴素非负矩阵分解的社区方法[13]、基于对称NMF的社区发现方法SNMF[14]、基于半监督的NMF社区发现方法SNMF-SS15]、基于节点相似度和模块度的NMF社区发现方法M-NMF[16]等。尽管现有基于NMF的社区发现方法都获得了不同程度的性能提升,但由于NMF本质上是线性模型,因此这些方法仍然属于线性方法,其表达能力较弱,对于包含大量非线性特征的真实世界复杂网络,常常无法获得满意的社区发现性能。
近年来,深度神经网络(如卷积神经网络)因其强大的非线性特征学习能力被广泛应用于自然语言处理和计算机视觉领域[17]。然而,传统的深度神经网络只能应用于欧式空间的数据,如图像、语音以及文本等数据,而无法有效应用于更为常见的图数据,因为图是一种典型的非欧式空间数据结构。针对该问题,图神经网络[18]被提出将神经网络模型拓展到图数据处理领域。目前图神经网络发展迅速,并产生了许多变种,其中图卷积网络GCN[19]由于既具有传统卷积网络的优势又能应用于图数据而备受关注。现有的研究工作表明,GCN比传统的深度神经网络(包括卷积网络)更适合处理图数据,并且具有强大的图数据非线性特征学习能力[20]。由于复杂网络本质上可以很自然地建模为图结构数据,因此应用GCN可以期待更好地提升各类复杂网络分析任务的性能,其中就包括本文关注的社区发现。基于以上分析,本文提出应用GCN增强NMF社区发现方法的性能,所做的主要工作包括:
(1)设计了一种非线性的NMF社区发现方法NMFGCN,该方法通过结合NMF和GCN的各自优势,使得其同时具备复杂网络的非线性特征学习及社区发现能力。
(2)通过设计NMF和GCN的联合优化框架,提出一个联合训练的损失函数,在考虑网络结构的同时也充分利用社区信息,使得GCN可以学习到更有利于NMF社区发现结果的网络节点表示,从而促进社区发现性能的提高。
(3)通过在人工合成网络和真实网络下进行大量实验,结果表明NMFGCN优于现有基于NMF的社区发现方法及常用的网络表示学习方法:DeepWalk[21]和LINE[22]。
1 相关工作
1.1 基于NMF的社区发现算法

NMF被证明与K-means和谱聚类模型具有近似等价关系[24],因此NMF具备良好的数据聚类能力。此外,社区发现本质上也是节点聚类问题,所以NMF也适合应用于社区发现。目前,已有许多基于NMF的社区发现方法,主要是通过扩展基本NMF模型解决各种复杂网络的社区发现问题,例如,基于对称NMF的社区发现方法SNMF[14,25]、基于联合NMF的社区发现方法S2-j NMF[26]、基于半监督NMF的社区方法SPOCD[27]、SMpC[28]以及基于深度NMF的社区方法DANMF[29]等。尽管这些方法在不同程度上获得了一定的性能提升,但由于NMF本质上是线性模型,所以这些方法仍然属于线性方法,不具有非线性表达能力,在处理包含大量非线性特征的复杂网络社区发现问题上仍然有待进一步改进。
1.2 图卷积网络
卷积神经网络在图像处理和自然语言处理上效果显著,主要归功于其中的卷积运算可以学习到数据对象多层次的非线性表示。然而,卷积神经网络的卷积运算只能定义在图像、文本以及序列等欧式空间数据,而无法定义在属于非欧式空间数据结构的图上。为了将卷积运算推广到图数据,Bruna等人提出了谱域图卷积网络Spectral GCN[30]。Spectral GCN通过计算图的拉普拉斯矩阵的特征分解,利用卷积定理[31],在傅里叶域中定义卷积运算。然而,Spectral GCN由于需要计算图拉普拉斯矩阵的特征值,因而具有较高的时间复杂度。为了提高Spectral GCN的计算效率,Levie等人[32]提出了切比雪夫网络ChebyNet。ChebyNet利用切比雪夫展开来近似卷积运算,使得图卷积运算的效率大大提升。Kipf等人[19]进一步将切比雪夫网络简化到一阶,提出了图卷积网络GCN。GCN的核心思想是节点通过聚合邻居节点和自身节点的表示来定义卷积操作,从而得到自身节点的表示。由于简单有效,GCN已经成为目前图卷积网络的基本模型。
图卷积网络是半监督方法,通常需要知道部分节点的标签信息来训练网络参数。然而,真实世界的网络大多是没有标签信息的,因此传统的图卷积不能直接用于处理社区发现任务。图自编码器(graph auto-encoder,GAE)[33]是GCN的一个变种,GAE不需要节点的标签信息来监督训练网络参数,其核心思想是通过图卷积学习到的节点低维表示来重构网络,并在训练过程中使得重构网络接近于原始的网络。GAE是一种无监督网络表示学习方法,可以应用于没有真实标签的复杂网络任务中,为此本文提出将图卷积自编码器与NMF结合的社区发现方法。
2 非线性社区发现方法NMFGCN
2.1 问题定义
不失一般性,对于给定的包含n个节点的复杂网络,可以建模为无向图G=(V,E),其中节点集为V={v1,v2,…,v n},无向边集合为E={eij|vi∈V,v j∈V}。G对应的邻接矩阵A为二值矩阵。

G中的每个节点拥有d维的特征向量x∈ℝ1×d,G的n个节点的特征向量构成了节点特征矩阵X∈ℝn×d。设k为网络的社区数,C={c1,c2,…,ck}表示G的社区划分,其中ci是属于第i个社区的节点集合,例如c2={1,2,5}代表属于第2个社区的节点为v1、v2、v5。基于以上定义,本文致力于解决的问题是:对于给定的G=(V,E),设计非线性的无监督社区发现方法NMFGCN,学习到社区成员表示矩阵U∈ℝn×k+,0≤uij≤1,从而预测给定网络的社区划分C,以提升基于NMF的社区发现方法的性能。其中,U的第i行U i是节点i隶属于k个不同社区的概率,且具体地,u4,2=0.6代表节点4隶属于社区c2的概率为0.6。
2.2 NMFGCN社区发现模型
NMFGCN的模型框架如图1所示,它主要包括2个模块:GCN Module和NMF Module。GCN将邻接矩阵A和节点的特征矩阵X作为输入,输出节点表示Z∈ℝn×m+,m为GCN输出层维度。NMF以节点表示Z作为输入,输出节点的社区成员表示矩阵U。下面分别介绍各模块的具体实现。
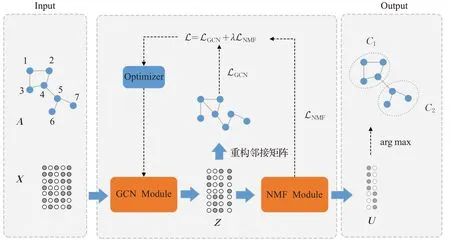
图1 NMFGCN模型框架Fig.1 Framework of NMFGCN
(1)GCN Module。GCN Module的输入是邻接矩阵A和节点的特征矩阵X,其目标是学习到节点的低维表示矩阵Z。考虑L层的GCN,对于第1至L-1层,节点的隐藏层表示计算公式如下:

通过图卷积学习到节点的表示Z后,使其与ZΤ做内积以重构邻接矩阵:

重构邻接矩阵的目的是使A′近似于A,从而可以用低维稠密的矩阵Z来表示图的信息。为此,需要使用一个损失函数来衡量A与A′的误差,并通过最小化误差来使得A′近似于A,本文使用交叉熵作为损失函数:

重复迭代使用式(14)和式(15)分别更新U和V,直到LNMF收敛,则U为节点的社区成员表示矩阵,uij∈U为节点i隶属于社区c j的概率。算法1描述了通过节点表示Z得到社区成员表示矩阵U的过程,具体如下:
算法1NMF获取社区成员表示算法


2.3 损失函数构建与优化
(1)损失函数。本文处理的问题是无监督社区发现,仅使用LGCN作为损失函数训练图卷积得到的节点表示不能很好地用作社区表示,因此本文采用LGCN与LNMF联合训练的方式:

在实际进行迭代优化求解过程中,可以通过设置外部迭代次数控制GCN的更新,同时设置内部迭代次数控制NMF的更新。当L函数收敛或超过外部迭代次数时停止迭代,得到节点社区成员表示矩阵U。矩阵U的第i行U i为节点i的社区表示。U ij为节点i隶属于社区c j的概率。取U i中最大值所对应的下标j,则c j为节点i所属的社区。根据该思路,NMFGCN社区发现算法设计如算法2所示。
算法2NMFGCN社区发现算法


2.4 时间复杂性分析
分析算法1和算法2,容易得出NMFGCN有两个核心步骤:第一步是迭代优化图卷积网络和NMF,第二步是从社区成员表示矩阵U中得到社区划分结果C。根据算法2,第二步的时间复杂度显然为O(nk),以下主要分析第一步的时间复杂度。
在具体实现上,使用2层的GCN。为了简单起见,GCN每一层输出的维度均用m表示。假设网络的节点数为n,边数为 |E|,社区数为k,节点的特征维度为d,模型迭代次数为T,NMF内部迭代次数为t,邻接矩阵A用稀疏矩阵存储,那么GCN的时间复杂度可表示为O(md|E|)。迭代优化NMF的时间主要花费在式(14)、(15)对社区成员矩阵U和社区特征矩阵V的更新上,其时间复杂度为O(tnmk)。因此模型训练的总时间复杂度为O(T(md|E|+tnmk)),其中k≪m,m≪d。大多数真实网络由于关系复杂,节点之间连接比较稠密,网络节点数n通常远小于其边数 ||E。因此,NMFGCN的时间复杂度主要取决于网络的边数 ||E。
3 实验分析
为了验证NMFGCN的有效性,本文在人工合成网络和真实网络上与多种代表性方法进行对比分析。实验硬件平台为Intel Core i7-9700 CPU,主频2.4 GHz,内存32 GB,操作系统为Windows 10,各对比方法均使用Python 3.7实现。
3.1 对比方法
本文选择多个基于NMF的社区发现方法进行对比,此外还选择目前广泛使用的基于网络表示学习的社区发现方法DeepWalk和LINE进行比较,所有这些对比方法简要介绍如下:
NMF[13]:该方法采用基本的NMF模型,直接分解邻接矩阵A获得矩阵U和V,||A-U V||2F,其中U作为社区成员表示矩阵。
SNMF[14]:SNMF基于对称非负矩阵分解模型(sym-其中H可以直接表示社区成员隶属强度。
M-NMF[16]:M-NMF是一种基于模块度的NMF社区检测模型,该模型将网络的社区结构融入到网络嵌入中,联合优化基于非负矩阵分解的社区检测模型和基于模块度的社区检测模型。
ONMF[34]:ONMF基于正交非负矩阵分解模型(orthogonal NMF,ONMF),其基本思想是在NMF模型基础上,对W施加正交约束,使得WTW=I。
HPNMF[35]:HPNMF基于图正则化NMF模型,可以集成网络的拓扑结构以及节点的同质性信息进行社区发现。
NSED[36]:NSED基于联合NMF模型,包含一个编码器和一个解码器,可以通过编码器获得社区成员表示矩阵。
DeepWalk[21]:DeepWalk是一种经典的网络表示学习方法,该方法的核心思想是通过随机游走的方式在图中进行采样,使用图中节点之间的共现关系来学习节点的低维表示。
LINE[22]:LINE也是一种网络表示学习方法,其通过保留节点的一阶和二阶相似度来获得网络节点的低维表示。
需要指出的是,对于基于NMF的社区发现方法,即NMF、SNMF、ONMF、M-NMF、HPNMF以及NSED,可以直接通过社区成员表示矩阵获得社区发现结果,而对于基于网络表示学习的方法DeepWalk和LINE,可以使用这些方法先学习到节点的低维表示,再通过K-means对低维表示进行聚类,聚类结果作为最终的社区发现结果。
3.2 数据集
实验使用的数据集包括人工合成网络和真实网络两部分,这些数据集介绍如下。
(1)人工合成网络。本文使用LFR基准网络合成工具[37]生成带有真实社区标签的人工网络,LFR工具有多个可调参数(表1)。本文通过固定部分参数,变化剩余参数来生成多组不同的人工网络。具体地,首先通过固定n、k、maxk、minc、maxc,使mu从0.1变化到0.3,且每次增加0.05共生成一组5个网络。接着通过固定k、maxk、minc、maxc及mu,使节点数量n从1 000增加到5 000,每次递增1 000生成另外一组5个网络。两组网络的具体参数设置如表2所示。

表1 LFR的可调节参数Table 1 Adjustable parameters of LFR
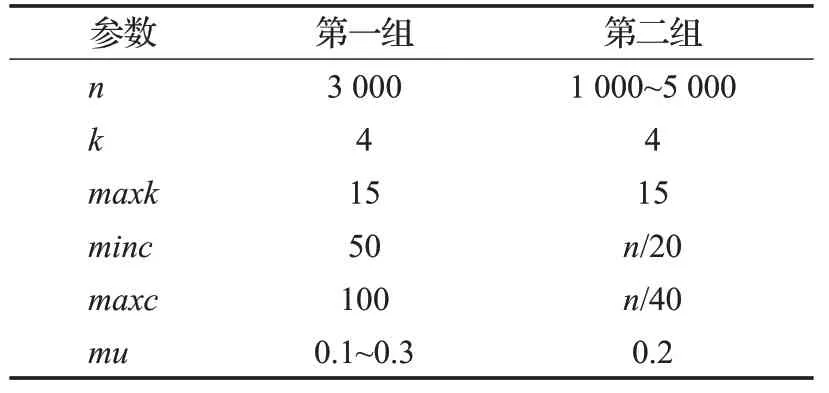
表2 人工合成网络参数设置Table 2 Parameters setting of synthetic networks
(2)真实网络。本文选择4个真实网络的数据集,分别是WebKB、Cora、Citeseer和Pubmed[38]。真实数据集的具体参数如表3所示。以上四个数据集均可在https://linqs.soe.ucsc.edu/data下载获得。
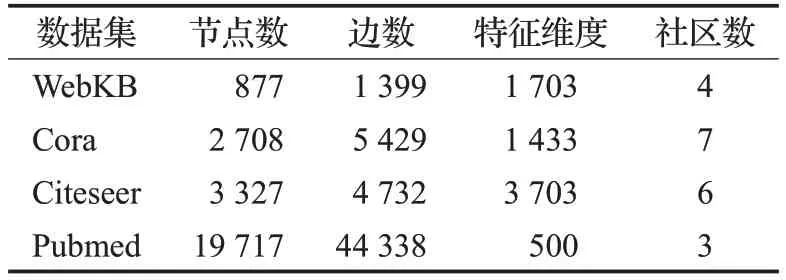
表3 真实网络参数Table 3 Parameters of real networks
考虑到对比方法大多数是针对非属性网络的无监督社区发现方法,为了公平起见,在真实网络和合成网络中,与对比方法进行比较时,NMFGCN的输入特征X使用NMF分解邻接矩阵A得到。
3.3 评价准则与参数设置
为评价社区发现结果的性能,本文使用4个目前普遍采用的评价准则:互信息(normalized mutual information,NMI)、调整兰德指数(adjusted rand index,ARI)、准确率(accuracy,ACC)及模块度Q,这些评价准则的具体定义可以参考文献[39]关于社区发现性能评价准则的综述。对于人工合成网络,本文均采用NMI、ARI、ACC及模块度Q进行结果评价。对于真实网络,由于没有真实的社区划分标签,本文使用模块度Q进行结果评价。对于所有评价准则,值越大预示着性能越好,反之则相反。
为了公平比较,实验中所有对比方法的参数均参考其在原文中的默认值。具体地,对于M-NMF,设置其正则化参数α=1,β=5;对于HPNMF,置其正则化参数λ=1;对于DeepWalk,设置窗口大小ω=10,迭代次数γ=80,walk_length=40,特征维度d=128;对于LINE,保留二阶相似度,设置负样本数量k=5,特征维度d=128;对于NMFGCN,设置损失权衡系数λ=1。GCN Module使用2层的图卷积,第1层、第2层的输出维度分别设置为256和128。此外,实验中对于每个方法均运行10次,并取各评价指标的平均值进行评价。
3.4 人工合成网络实验结果与分析
在表2所示的两组人工合成网络数据集上进行了对比分析,其中第一组网络的实验结果如表4所示。
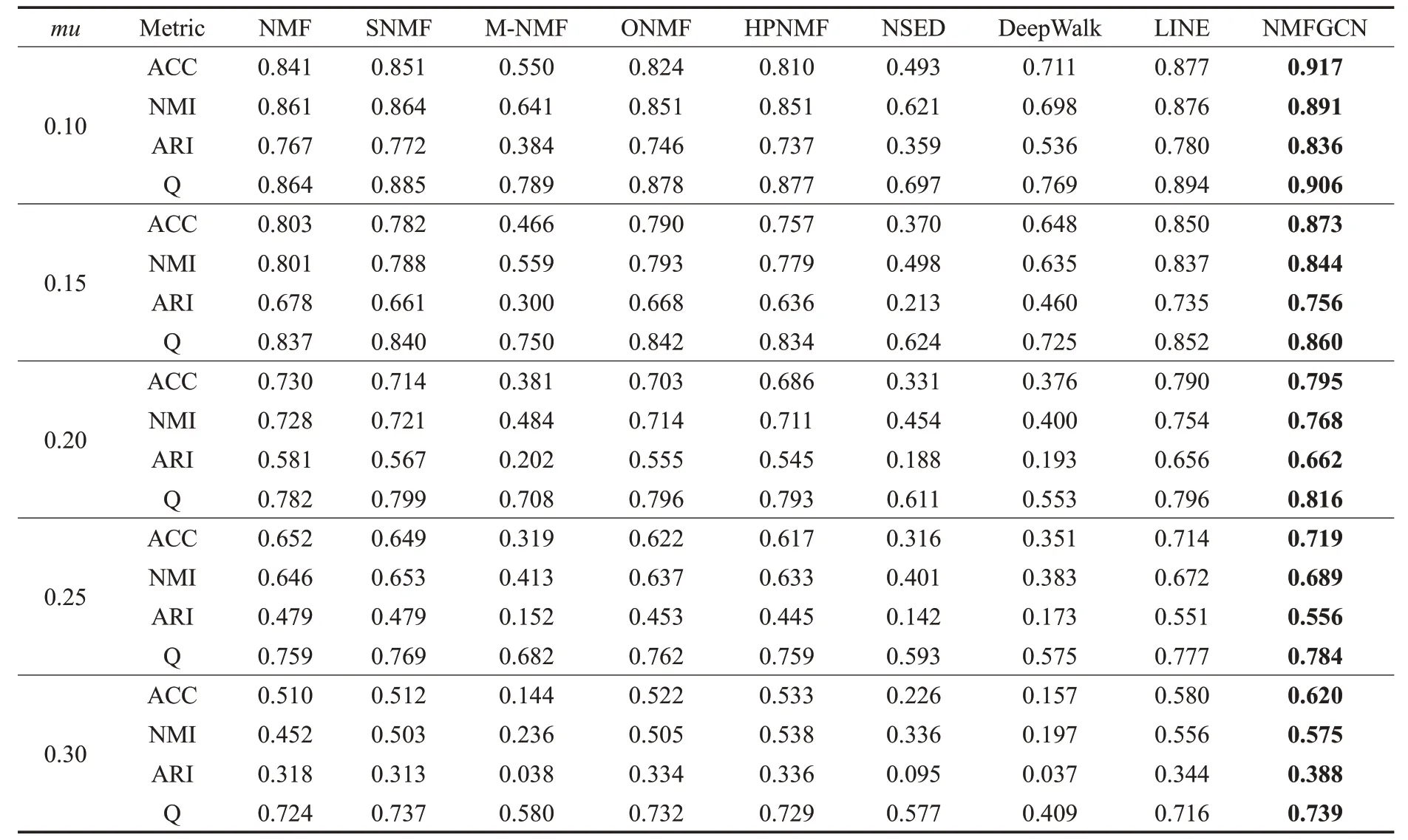
表4 具有不同混淆系数mu的人工合成网络性能比较Table 4 Performance comparison of synthetic networks with different mu
从表4可以看出,随着混淆系数mu的增大,网络的社区结构越来越不清晰,检测社区的难度不断加大,各个方法的性能都有着较为明显的下降趋势,但本文方法NMFGCN在各个网络上的表现都优于其他模型。例如,当mu=0.1时,与基于NMF表现最好的社区发现算法SNMF相比,NMFGCN的ACC、NMI、ARI和模块度Q分别提升了7.7%、3.1%、8.2%、2.4%。与基于图表示学习表现最好的社区发现算法LINE相比,NMFGCN的ACC、NMI、ARI和模块度Q分别提升了4.6%、1.7%、7.1%、1.3%。不同的数据集上,NMFGCN在四个评价指标上也有不同程度的提升。第二组人工合成网络上的实验结果如图2所示,从中也可以看出NMFGCN在所有具有不同节点数量的网络均获得最好的性能。
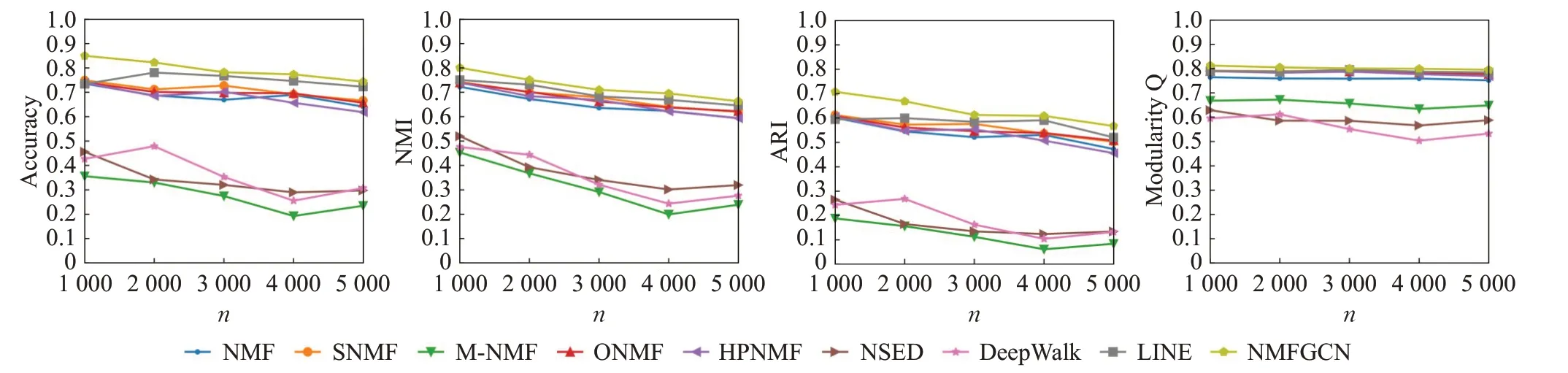
图2 具有不同节点数量n的人工合成网络性能比较Fig.2 Performance comparison of synthetic networks with different n
以上在人工合成网络上的实验结果表明,NMFGCN比现有基于NMF的社区发现方法具有更好的性能,GCN增强NMF社区发现性能的设想得到了初步验证。
3.5 真实网络实验结果与分析
为进一步验证NMFGCN的有效性,在4个真实网络上进行比较分析,实验结果如表5所示。可以看出,NMFGCN在各真实网络上的结果均优于各对比方法。在WebKB、Cora、Citeseer、Pubmed上,NMFGCN与基于NMF表现最好的方法HPNMF相比,模块度分别提升了5.4%、1.5%、9.3%、1.3%,与基于图表示学习表现最好的方法LINE相比,模块度分别提升了58.4%、19.6%、6.4%、2.4%。真实网络通常比合成网络更加复杂,包含更多非线性的节点特征,在合成网络上表现较好的模型SNMF、LINE,在三个真实的数据集中表现较差,而NMFGCN是一种非线性的社区发现模型,在真实网络和合成网络中表现都比其他模型好,上述结果进一步证明NMFGCN通过集成GCN与NMF模块,可以增强网络非线性特征的表示能力,进而提升NMF社区发现的性能。

表5 真实网络模块度Q比较Table 5 Modularity Q comparison on real networks
3.6 NMFGCN的联合优化效果验证
如前所述,NMFGCN通过联合优化NMF和GCN模块,可以得到更好的社区划分结果。为进一步验证NMFGCN的联合优化效果,对NMFGCN与GCN+NMF的性能进行对比分析。
对于GCN+NMF,先通过GCN学习节点的表示Z,再使用NMF分解Z得到社区划分结果。由于不再进行联合训练,GCN的损失函数只有重构邻接矩阵的损失LGCN,而不再考虑NMF分解的损失LNMF,即其损失函数为L=LGCN。
对比实验中,分别在真实网络与人工合成网络(表2第二组数据)中进行实验比较,并在每个网络数据集上均运行10次并取平均值。合成网络的实验结果如图3所示,真实网络的实验结果如图4所示。可以看出,NMFGCN在四个真实数据集上的模块度Q均高于GCN+NMF。其原因是NMFGCN在训练的同时考虑了邻接矩阵重构的损失和NMF分解的损失,从而可以同时利用网络的拓扑结构信息和社区信息,并使得NMF与GCN可以相互促进存进:GCN能够学习到更有利于NMF的节点表示,NMF也能获得更好的社区划分结果。在人工合成网络上,随着节点数的增加,NMFGCN和GCN+NMF的四个指标上的值均有所下降,但NMFGCN的表现仍优于GCN+NMF。以上两组实验充分证明了NMFGCN进行联合优化的有效性。
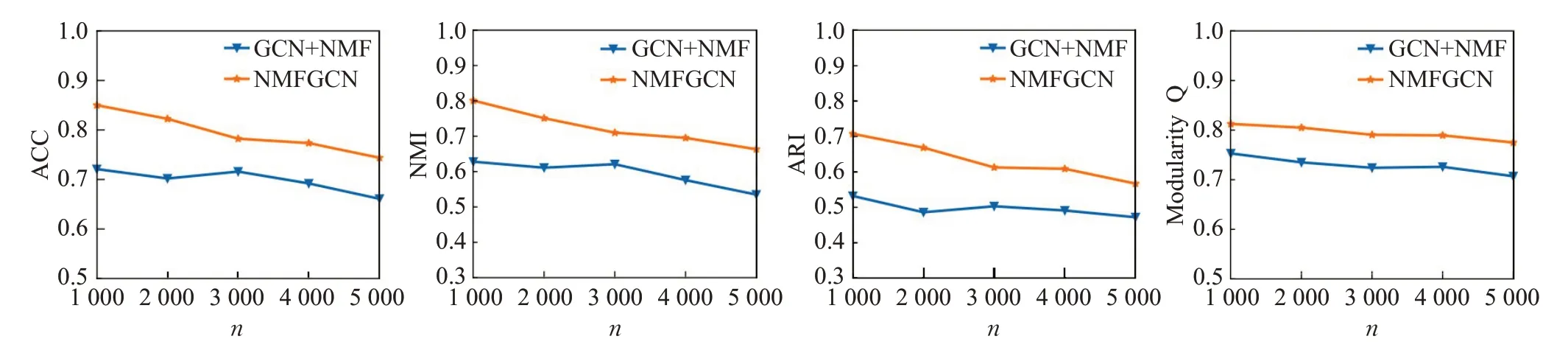
图3 人工合成网络的联合优化对比Fig.3 Comparison of joint optimization on synthetic networks
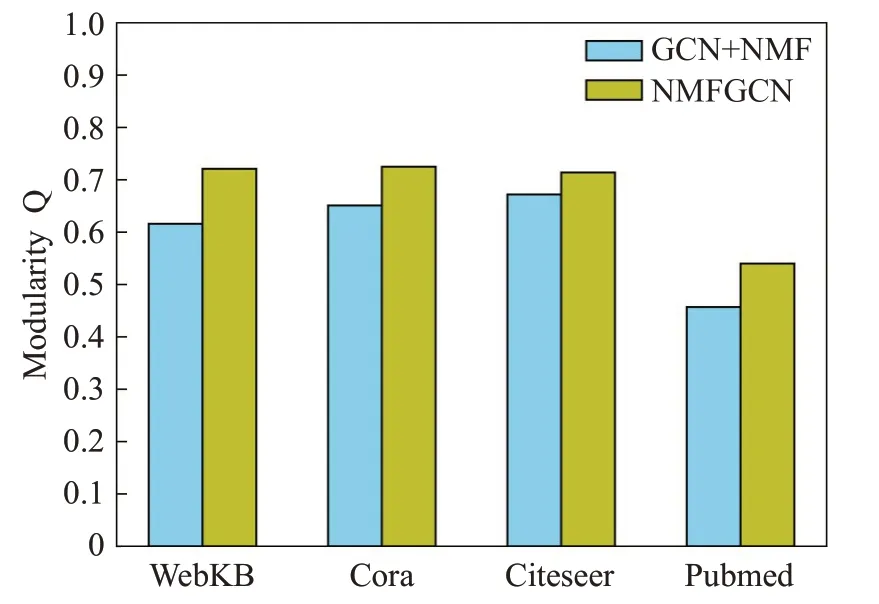
图4 真实网络的联合优化对比Fig.4 Comparison of joint optimization on real networks
3.7 社区划分可视化分析
为更清楚地展示NMFGCN的社区划分效果,本文利用t-SNE[40]工具对社区成员表示向量在二维平面进行可视化分析实验。实验选择Cora和Citeseer作为数据集,同时选择NMF和HPNMF作为对比方法。通过为不同社区的节点标识不同的颜色,可以对可视化结果进行对比分析(图5和图6)。从图5可以看出,在Cora上,NMFGCN的相同颜色节点更加集中,社区边界更清晰,而NMF和HPNMF不同颜色的节点聚集混合明显,社区边界较为模糊。从图6可以看出,在Citeseer数据集上,NMF划分的数据集几乎不能看清楚边界,HPNMF划分的社区虽然能够看清边界,但是属于同一社区的节点比较分散,而NMFGCN在该数据集上不仅社区边界清晰,而且同一社区的节点也相对集中。这些结果进一步表明NMFGCN具有更好的社区划分性能。
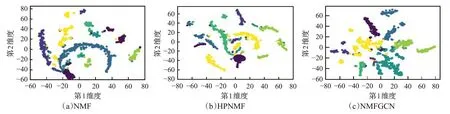
图5 Cora的社区划分可视化Fig.5 Community partitioning visualization on Cora
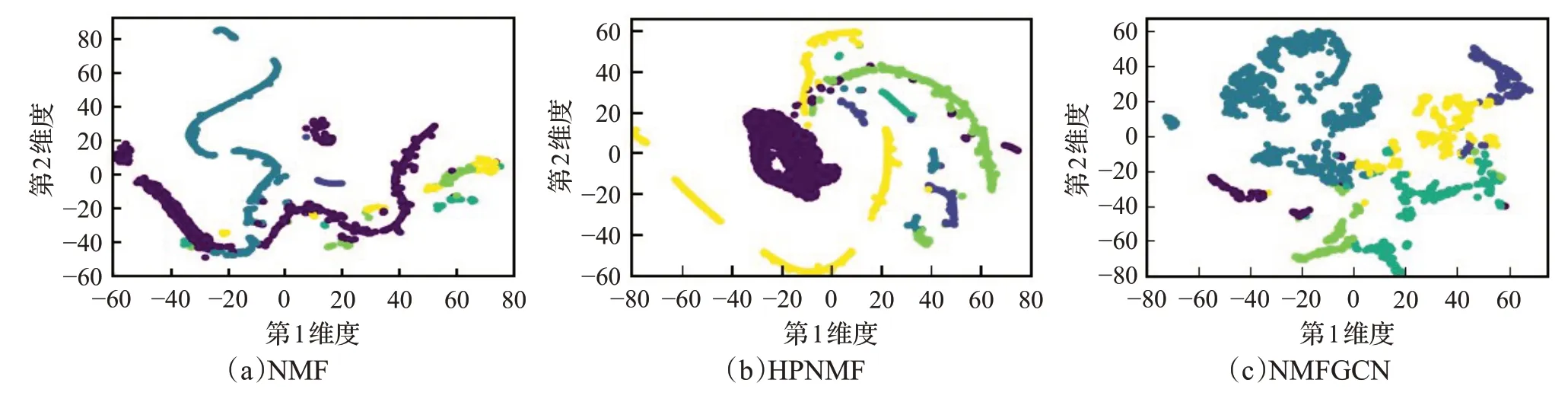
图6 Citeseer的社区划分可视化Fig.6 Community partitioning visualizations on Citeseer
为进一步观察NMFGCN的社区划分能力,将其在Cora和Citeseer上不同迭代次数(分别取1、5和10)的社区划分结果进行可视化,结果如图7和图8所示。可以看出随着迭代次数的增加,NMFGCN的社区边界越来越清晰,并且不需要太多的迭代次数就可以获得较好的社区划分效果,这在一定程度上也说明了NMFGCN具有较好的社区发现效率。
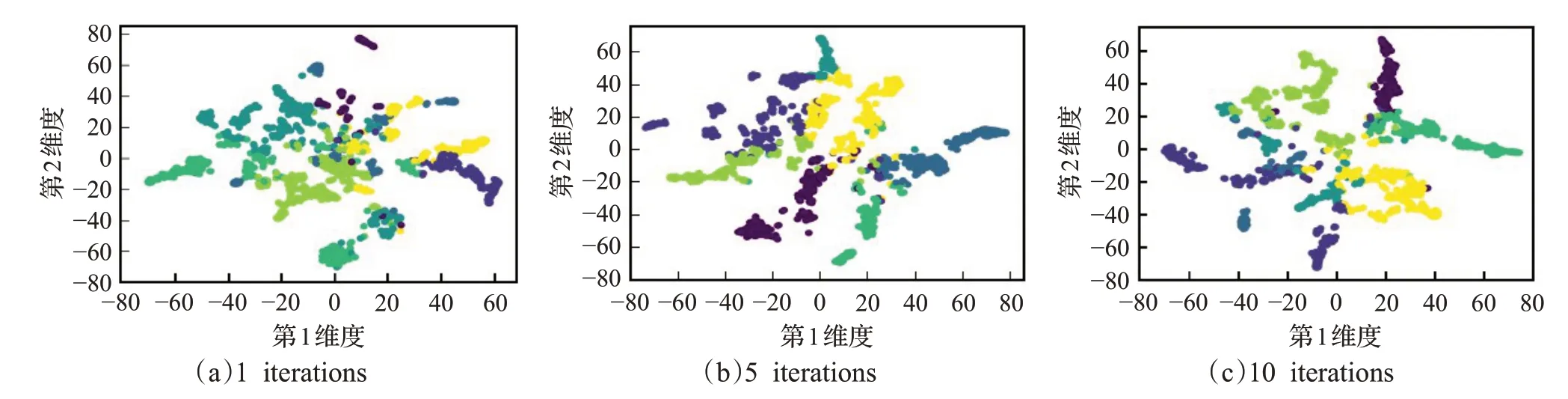
图7 NMFGCN在Cora上不同迭代次数的社区划分可视化Fig.7 NMFGCN community partitioning visualizations with different iterations on Cora
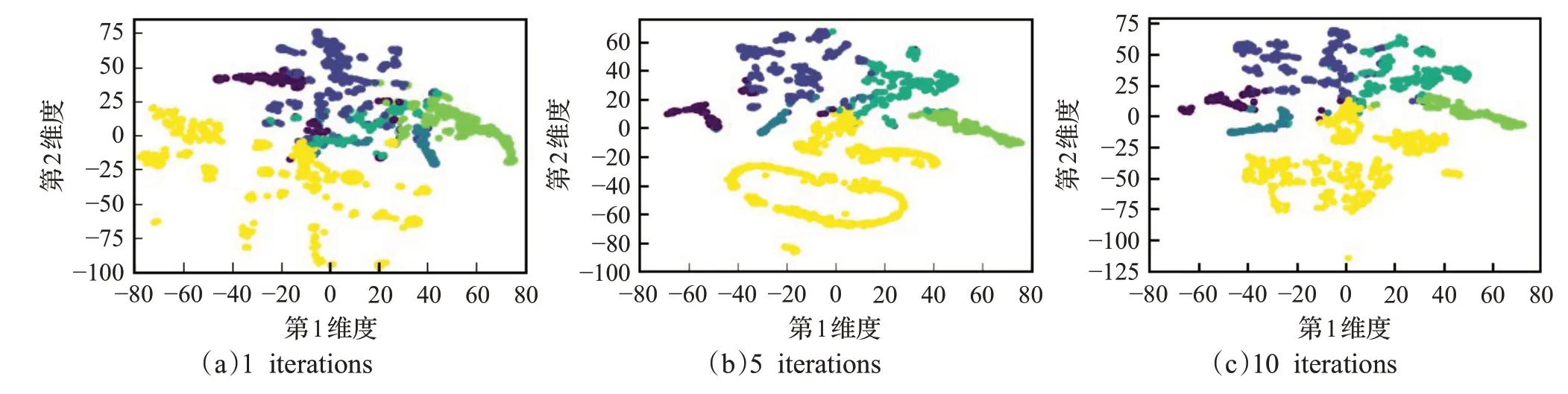
图8 NMFGCN在Citeseer上不同迭代次数的社区划分可视化Fig.8 NMFGCN community partitioning visualizations with different iterations on Citeseer
3.8 λ设置
在式(12)中,NMFGCN的损失函数为L=LGCN+λLNMF,其中λ用来平衡NMF损失。为获得λ的合理设置,本文选择表2的第二组人工合成网络中节点数量n为3 000的数据集进行实验,通过将λ在{10-3,10-2,10-1,100,101,102,103}依次取值并计算相应的NMI、ARI、ACC以及模块度Q,结果如图9所示。可以看出,λ在[10-3,1]取值时,各性能评价指标表现平稳。当λ大于10时,随着λ增大,各性能评价指标略有下降趋势,但并不明显。在不同数据集上,λ的取值也在[10-3,1]内取得最好的结果。整体而言,NMFGCN对参数λ是不敏感的。为了使NMFGCN得到较好的性能,λ可以在[10-3,1]内取值,如本文中的所有实验,都将λ设置为1。
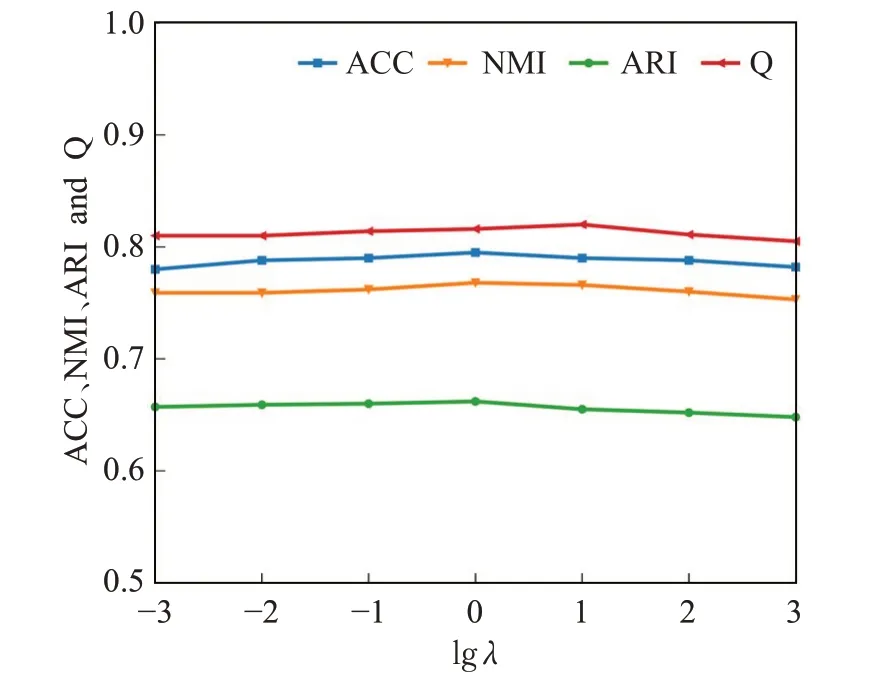
图9 不同λ取值对NMFGCN性能的影响Fig.9 Performance of NMFGCN with differentλ
3.9 运行效率分析
在2.4节中,本文分析得出NMFGCN的时间复杂度为O(T(md|E|+tnmk)),但迭代次数T是不确定的。为了探索NMFGCN获得最好的社区划分结果所需要的最小迭代次数。本节选择真实网络Pubmed作为实验数据,选择基于NMF的社区发现方法NMF、SNMF、M-NMF、ONMF、HPNMF、NSED进行对比,测试并记录每个方法在获得最好社区划分结果时所需要的最少迭代次数T m以及相应所花费的时间S。实验结果如图10所示,可以看出,在运行时间上,NMF和SNMF由于模型简单,运行效率更高,因而获得最好社区划分结果所花费的时间更少。ONMF所花费的时间最长,主要是由正交约束计算复杂度高所导致。HPNMF由于计算相似度矩阵导致模型复杂度高,且相应的Tm值较大,因此所花费的时间仅次于ONMF。NMFGCN的Tm为11,相比于其他模型,NMFGCN能够在更小的迭代次数下获得理想的社区划分结果。在运行时间上,相比于ONMF和HPNMF,NMFGCN具有较为明显的优势。
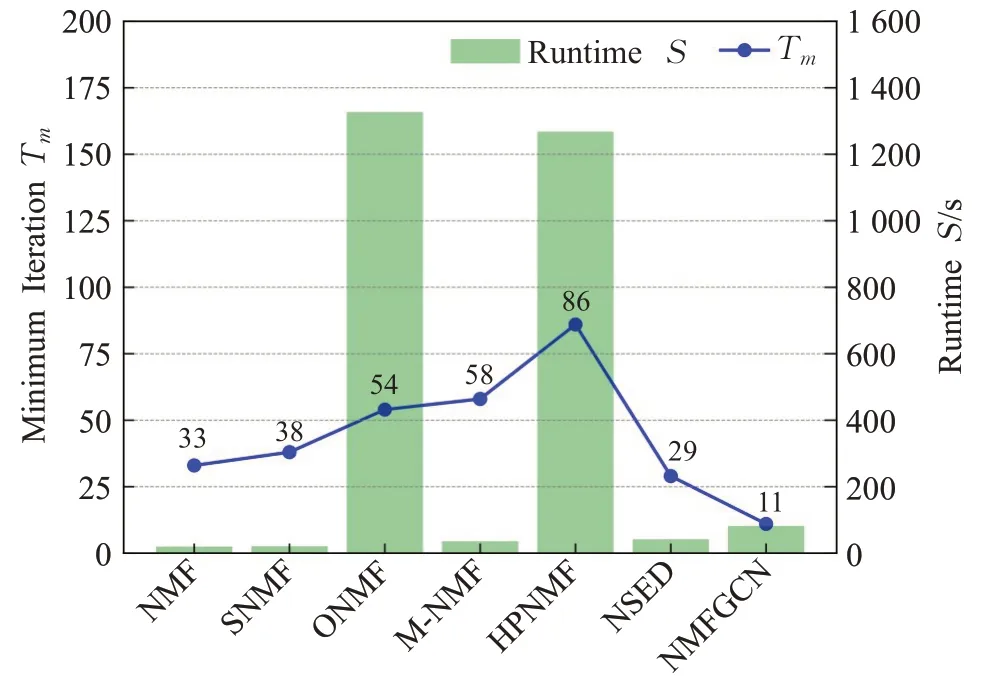
图10 运行时间比较Fig.10 Runtime comparison
4 总结和展望
为了提升基于NMF的社区发现方法性能,本文提出了一种GCN增强的非线性NMF社区发现方法NMFGCN,利用GCN强大的网络节点非线性特征学习能力提升NMF社区发现性能。为了验证NMFGCN的有效性,本文在人工合成网络和真实网络进行了大量的对比实验,结果表明NMFGCN优于现有基于NMF的社区发现方法,也优于常用的网络表示学习方法DeepWalk和LINE,很好地解决了现有NMF社区发现方法由于属于线性模型而导致非线性网络节点特征难于处理、社区发现性能受限的问题。
需要指出的是,尽管相比于现有的基于NMF的社区发现模型和一些常用的图表示学习方法,NMFGCN都获得了不小的提升,但其仍存在需要改进的地方,具体表现在两个方面:
(1)NMFGCN的运行效率不高,训练大型网络花费时间较长。NMFGCN的训练时间主要花费在图卷积层学习节点表示Z以及NMF分解Z上。其中后者可以通过减小图卷积层的输出维度的大小和减少NMF迭代次数来减少训练时间。
(2)由于图卷积是一种直推式图表示学习方法,当网络中增加节点或者改变拓扑关系时需要重新训练模型。为了解决该问题,在下一步工作中将会考虑借鉴归纳式图表示学习方法GraphSAGE[41]来学习节点的表示Z。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
北京航空航天大学学报(2021年9期)2021-11-02
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
